Периодически на Хабре проскакивают статьи, где проверяется двоичная совместимость контроллеров GD32 с их аналогом STM32. Так получилось, что нам довелось поймать пусть и не на двоичном уровне, а на уровне исходников, ситуацию, где одно и то же проявление проблемы (теряются сетевые пакеты) было вызвано не одной, не двумя, а сразу тремя причинами, из которых две оказались признаками несовместимости с STM32. Вот о том, как мы эти причины ловили, я и хочу сегодня рассказать. Будет детектив, аналогичный тому, какой я приводил в своей старенькой статье про поддельную «голубую пилюлю». Ну, и выводы, куда же без них. Они тоже будут.

Как обычно, всё начиналось буднично. Заказчик хотел получить «прошивку», обеспечивающую функцию, суть которой настолько тривиальна, что не стоит упоминания в статье. Единственная интересная вещь в проекте заключалась в том, что Заказчик запросил, чтобы всё было реализовано на контроллере семейства GD32F450. Само собой, с полной лицензионной чистотой. То есть на базе GD-шного SDK и собранное с помощью обычного GCC, не имеющего никакого отношения к ST-шной среде разработки.
Плюс в основу проекта обязательно должна была лечь собственная UDP-библиотека, написанная нашим коллегой для STM32F4 в ходе одного из предыдущих проектов для того же Заказчика. От любимого многими LwIP она отличается компактностью и уменьшенным количеством копирований данных в памяти. Сколько раз буфер копируется при типовом внедрении LwIP – страшно посмотреть! А ведь чтение и запись памяти в микроконтроллерах – довольно медленная операция.
Использование этой библиотеки для Заказчика позволяло убедиться, что она работает и на GD32, а для нашего повествования, благодаря ей, нам удалось опуститься на самый нижний уровень программирования сетевых вещей.
Итак. Зевнув, мы перелопатили код библиотеки, заточенный на конкретный проект, раскидав его так, чтобы им можно было пользоваться из произвольной программы. Потом, не просыпаясь, мы сделали проблемно-ориентированную часть проекта. И чисто для проформы прогнали несколько тестов. Вот тут-то рутина и кончилась…
Если откинуть функциональные детали и перейти к терминам UDP протокола, обмен с устройством выглядел так:
1) ПК шлёт пакет в устройство;
2) устройство обрабатывает пакет и шлёт ответ;
3) ПК получает ответ, проверяет его содержимое и переходит к шагу 1.
На практике, на шаге 3 ответ иногда не приходил. Наверняка кто-то уже пошёл писать комментарий, что мы ничего не смыслим в UDP, там потери пакетов – это норма. Комментарии – это хорошо, комментарии я люблю. Но дело в том, что устройство было подключено к выделенной сетевой плате прямым кабелем. И, как видим, всегда в каждом направлении идёт один пакет. Очереди переполняться негде! Пакетам теряться негде! В данном конкретном случае, в правильно работающей системе потери исключены.
Мало того, мы собрали из тех же исходников прошивку для платы NUCLEO-F429ZI, на которой коллега делал свою библиотеку. Тот же тест на той плате отработал 10 часов без единой потери пакета! Тогда мы взяли типовой китайский пример для GD32, выполняющий функцию UDP эха на базе LwIP, и убедились, что он на плате с GD32 вполне себе пакеты теряет, как и наш код, собранный для этого контроллера. Так что на GD-шке всё плохо не только у нас. Но что является причиной?
Как я уже говорил, использование условно своей библиотеки и возможность неограниченно приставать к её автору с вопросами – это очень полезная штука в плане образования. Пользуясь случаем, расскажу всем, как принимаются пакеты в контроллере STM32/GD32. Там используется механизм прямого доступа к памяти (ПДП, далее, в терминах из фирменной документации — DMA). Контроллер DMA может работать в одном из нескольких режимов. В нашем случае (справа на рисунке), в памяти выделяется массив структур. Структура – это дескриптор для одного буфера.

Когда аппаратура DMA достигла конца массива дескрипторов, она автоматически переходит к его началу. Слева на рисунке показано, что дескрипторы не обязательно должны храниться в массиве. Они могут образовывать и связный список. Но автор нашей библиотеки сделал массив, поэтому дальше работаем только с ним.
Что мы видим из всего вышесказанного? А видим мы то, что задержки «прошивки» не могут приводить к потере данных. Как я уже говорил, у нас передача данных идёт по принципу запрос-ответ. Всегда в пути не больше одного пакета. Пока он не будет обработан – новый в сеть не уйдёт. Да, там в сети иногда бегают всякие вспомогательные пакеты, запущенные операционной системой. Вот на логах сниффера один вклинился в протокол нашего обмена:

Но повторю, сетевой адаптер в ПК, на котором ведутся опыты, – выделенный. Левые пакеты через него бегают крайне редко. Их количество обычно не превышает 3-5 штук. А буферов в разные периоды отладки было от девяти до семнадцати. Переполнение просто исключено!
Зато знание принципа размещения принимаемых данных позволило здорово упростить отладку. Адреса всех возможных буферов данных в памяти GD32 известны. В каждый пакет мы на уровне протокола добавили его идентификатор. Поэтому мы легко и непринуждённо можем отобразить в отладочной среде Eclipse те слова памяти, куда попадут эти идентификаторы. В итоге, при срабатывании точки останова сразу видно, какие пакеты успели пробежать по сети (если номера странные – ну значит, в соответствующем буфере лежит тот самый левый пакет, но такое бывало крайне редко и выявлялось по отображаемым сигнатурам, которые из рисунка для статьи я выкинул, они только отвлекают). Вот пример:
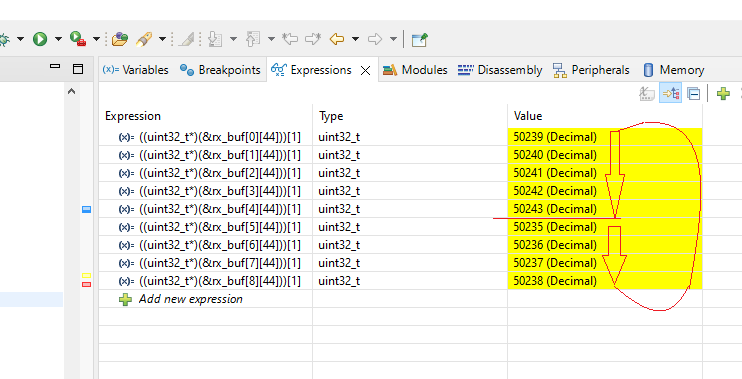
Когда какого-то идентификатора не хватает – это сразу заметно!
Опыты велись на двух платах. Первая – очень навороченная плата от самой фирмы GD. Вот такая красавица:

Штука классная, но у её тестового разъёма шаг 2.0 мм. Поэтому Ардуиновскими проводочками к ней толком не подключишься. Пока эта плата была в цепких лапах Почты России, мы вели опыты на плате, изготовленной безвестными китайцами. Сама по себе плата универсальная. На неё могут быть припаяны контроллеры разных семейств и даже разных производителей (STM и GD), что следует из шелкографической маркировки на ней:

У неё нет своего PHY, но на скорую руку ребята сделали лазерно-утюжную нахлобучку с типовой платой PHY от WaveShare. Просто большая плата ожидалась со дня на день, тратить время на полноценный заказ не имело смысла, но каждый день был для нас, программистов важен, так что делать стоило. Получилось как-то так:

Ой, как этот бутерброд нам помог! Но обо всём по порядку…
Итак, у нас теряются данные. Самый главный вопрос: а в каком месте это происходит? Что они ушли из Windows, мы видим по показаниям WireShark. Что они не пришли в контроллер – мы видим по отсутствию оных в буферах DMA. А ушли ли они из драйвера Windows в сетевой адаптер ПК? Ушли ли они из адаптера в кабель? Приняты ли из кабеля в устройстве?
Самое простое, что можно сделать – это подключиться в устройстве к линиям, идущим от микросхемы PHY к микроконтроллеру. Как я уже говорил, к большой плате подключаться не очень сподручно – там шаг разъёма 2.0 мм. А у имеющегося анализатора контакты для штырей с шагом 2.54 мм. Нет, конечно, можно что-то придумать, но это же человеко-часы. Зачем их расходовать зря? Вот тут-то и пригодилась плата с внешним PHY. На неё был установлен дополнительный разъём, к которому сделаны отведения нужных сигналов. Правда, у сигналов частота 50 МГц. Тут нельзя просто так взять и сделать отвод. Отводящие провода будут создавать эхо, что приведёт к жутким помехам на линиях. Поэтому к дорожкам были припаяны отвязывающие резисторы, а уже их второй контакт пошёл к разъёму.

В «прошивку» был добавлен код, который взводит ножку GPIO, если идентификаторы внутри принимаемых пакетов идут не один за другим. По этому сигналу мы останавливаем процесс накопления данных анализатором. В буфере будет снимок, на котором видно, что творилось незадолго до и сразу после этого момента. Ну что, давайте разглядывать времянки?
А времянки – очень красивые. Вот как работа интерфейса RMII выглядит в документации:

А вот – на анализаторе. Найдите хотя бы одно отличие…
Общий вид:
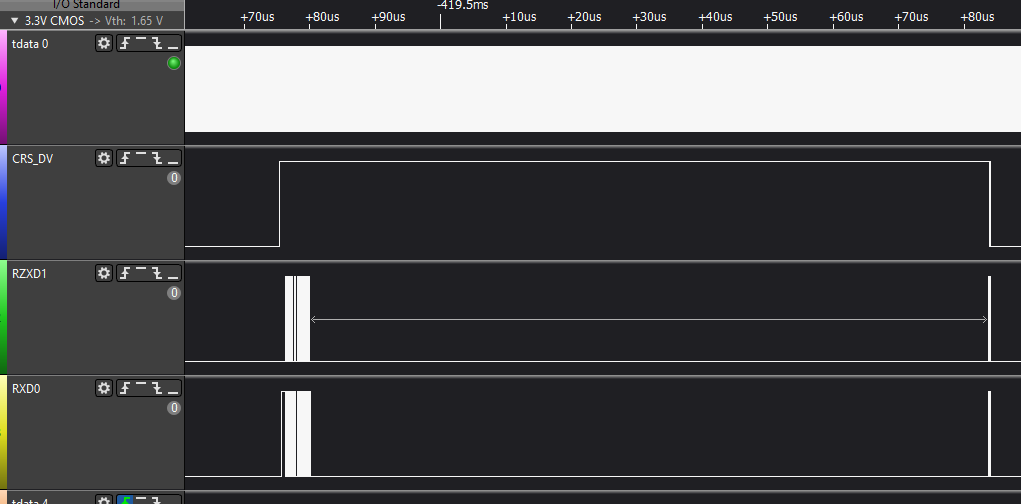
Начало:

Конец:

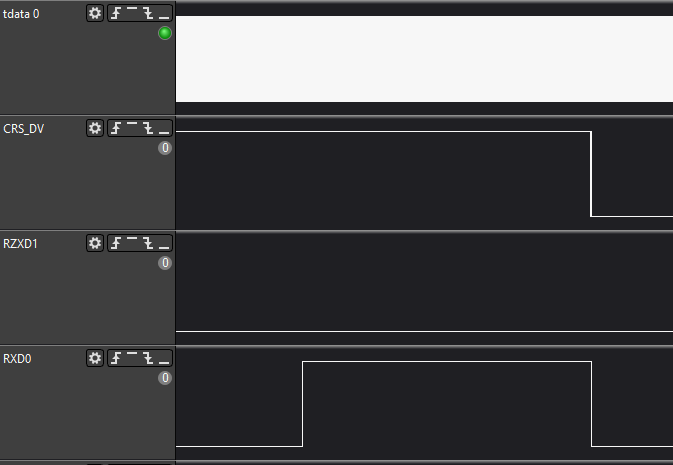
Красота! Обратите внимание, что все данные меняются по обратному фронту тактовой частоты! Никаких гонок нет в принципе! Вот я добавил пару зелёных курсоров, идущих от обратных фронтов линии CLK.
Но проблемы ловятся моментально! Я просто запускаю вот такую программу на ПК:
И менее, чем за секунду получаю остановку с вот таким набором буферов:
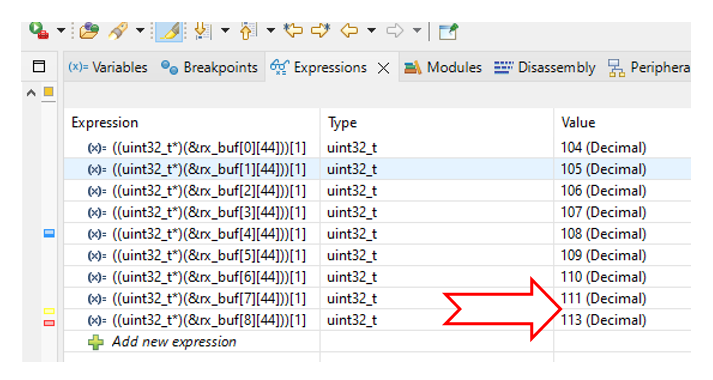
Пропущен буфер номер 112. На самом деле, это ещё удачный вариант попался при подготовке иллюстраций. Иногда при реальной работе по два-три буфера пропущено было!
На времянках ничего не видно… Если точнее, то видно, конечно, потом покажу, что именно. Но их так много, что сразу и не разглядишь! Поэтому мы написали программу, которая восстанавливает из логов логического анализатора данные, пробегающие по шине. И вот тут-то вся правда и открылась. Вот как выглядит хороший буфер:

А вот так — концовка плохого буфера:
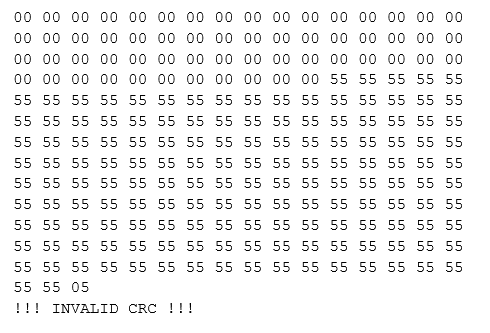
Зная это, можно найти проблемный участок и на времянках:
То есть данные переходят в постоянное состояние. И длина пакета увеличивается на один ниббл.
Кстати, если слать данные не от ПК, а замкнуть PHY в режим LoopBack, проблема не возникает никогда. У нас тест молотил почти сутки.
Опущу процесс поиска. Расскажу, почему это происходит уже в форме обнаруженного факта.
Что в нашем случае представляет собой микросхема PHY? Это обычный посредник, который преобразует данные из одного формата в другой. С одной стороны у него наш контроллер и интерфейс RMII, с другой – трансформаторы, за которыми тянутся провода витой пары.
И вот при приёме (а у нас ведь сбоит приёмная часть, с точки зрения контроллера) возникает очень интересная проблема. Со стороны витой пары данные идут в соответствии со скоростью, которую задаёт тактовый генератор где-то вдали (в нашем случае, в ПК). Там скорость задана, и данные будут идти в полном соответствии с нею. Ни быстрее, ни медленнее. Мы не можем попросить ПК сделать паузу. Мы обязаны принимать пакет от начала до конца. Давайте как-то подкрепим это рисунком.

А вот из микросхемы PHY данные забираются в соответствии с тактированием от генератора, который расположен где-то на плате, но вне микросхемы. На рисунке в документации это внешний генератор. Ниже мы узнаем, что в теории, это может быть и источник опорной частоты внутри контроллера. В общем, этот генератор – внешний по отношению к PHY, и он тактирует как нашу микросхему, так и блок, ответственный за работу с сетью (обычно уровень MAC) в контроллере. Давайте я подкрашу его красным цветом.

И протокол RMII устроен так, что если мы начали передачу пакета, сделать паузу невозможно. Можно только сказать, что пакет передан полностью.
Итак. Приёмный тракт нашей микросхемы имеет дело с двумя частотами, каждая из которых задана извне. Я долго думал, какую жизненную аналогию привести… Все требуют каких-то натяжек. Давайте рассмотрим аналогию с выплатой кредита. В ней натяжек будет меньше всего.
Допустим, дядя Вася взял кредит и теперь выплачивает его равными порциями. Причём дядя Вася живёт в мире, где каждый месяц равен тридцати дням. Так будет проще. Зарплата у дяди Васи пятого, платёж надо вносить десятого. Получается, что частота входящего сигнала совпадает с частотой исходящего. Просто они чуть разнесены по фазе. Деньги поступают, пять дней лежат у дяди Васи в кубышке, затем – идут на выход. Красота!
Но это – недостижимый идеал. В реальности, частота генератора имеет небольшую погрешность, полученную в процессе производства. Мало того, она зависит от окружающей среды. Да хоть от той же температуры. Поэтому частоты генераторов, задающих входной и выходной сигналы, будут чуть-чуть различаться.
Пусть у дяди Васи выросла частота входящего сигнала. Частота растёт – период уменьшается. Деньги стали поступать не каждые 30, а каждые 29 дней. А выплачивать их надо по-прежнему, каждые 30. Тогда в первый месяц дядя Вася получил деньги пятого и держал в кубышке 5 дней. В следующий месяц – четвёртого и держал в кубышке уже 6 дней. Потом – 7, 8, 9 и т.д. дней. Однажды набег составил целых 30 дней. А ещё через месяц у него в один день появилось сразу две суммы. Одна лежит уже месяц, вторая – получена прямо сегодня. Ещё через месяц двойная сумма будет в наличии уже целый день. Потом размер накоплений ещё вырастет… И так – пока не кончится срок выплаты кредита (а в нашей сетевой задаче — не кончится пакет). Эта проблема устраняется очень просто – достаточно дяде Васе завести сейф подходящего размера и хранить сумму там. С точки зрения аппаратуры – это очередь, она же FIFO.
Интереснее ситуация, если частота входящих данных станет меньше частоты исходящих. Пусть зарплату начали платить каждые 31 день. Тогда первый месяц она будет шестого, потом – седьмого, потом – восьмого, девятого, десятого… А когда она станет одиннадцатого числа, у дяди Васи начнутся проблемы с банком. В нашем же случае, контроллер не получит данных. Мы же уже выяснили, что протокол RMII не предусматривает пауз в передаче данных. Начал передавать – гони весь пакет! Не пришло данных – всё, пакет искажён. Его корректный приём невозможен. Данные обязаны идти!
Чтобы решить эту проблему, дядя Вася должен сначала несколько месяцев просто копить все входящиеданные деньги. Только накопив некоторую резервную сумму… Ну, скажем, на три месяца вперёд, он берёт кредит и начинает выплаты. Частота поступления оказалась меньше? Через некоторое время запас уменьшится с трёх до двух порций. Потом – до одной. Главное – чтобы в запасе было столько элементов, чтобы он точно не опустошился до конца пакета выплат.
Собственно, мы только что познакомились с эластичным буфером. Микросхема PHY сначала с упреждением копит некоторое заданное количество бит в FIFO, а только затем начинает выдавать их в RMII. Если данные приходят быстрее, чем отдаются, очередь будет расти. Если медленнее –уменьшаться. Вот что говорит документация на микросхему DP83848:

Считается, что при точности генератора плюс-минус 100 тактов на миллион, для разной длины буфера надо сделать ту или иную предвыборку, чтобы запаса хватило на весь пакет. Почему не стоит делать всегда большую предвыборку? Чем она больше, тем выше латентность системы. Ведь N тактов данные не передаются в контроллер, а буферизируются. И потом эти же самые N тактов (ну, если генератор точный) они будут выдаваться по линиям RMII, когда в витой паре уже тишина. А зачем нам задержка? Так что чем меньше данных предварительно кладём в эластичный буфер, тем лучше!
Ну, а в нашем случае, частоты различаются сильнее. Не знаю, почему, но сильнее. И двух битов, которые копятся по умолчанию, для нормальной работы не хватает.
Почему всё работает на плате с STM32? Ну, там и генератор иной, и микросхема PHY другой фирмы. Причём я не нашёл, какой размер предвыборки для того PHY. Может просто значение предвыборки по умолчанию там выше.
Почему работает в режиме LoopBack? Потому что в том случае используется один и тот же генератор для приёма и для передачи. Нет разбега частот – нет этой проблемы.
В общем, добавляем в код строку:
И проблема уходит для нашего PHY в связке с ПК… Система перестаёт вылетать в тот же миг… Но… Но детальные тесты показывают, что проблема остаётся!
Радуясь, что можно вернуться к большой плате (а для целевой функциональности у контроллера на малой не хватало ног), мы переключили железо, и у нас возникло ощущение дежавю. Проблема никуда не ушла. Но теперь мы были уже умные, мы уже знали как суть проблемы, так и то, что у PHY есть отладочные регистры, откуда можно считать как число ошибок, так и сведения фактах опустошения буфера. На малой плате ничего такого не возникает, на большой – буфер опустошается даже если его предзаполнять ну совсем по максимуму. Из документации следует, что целых 16 килобайт можно принять. А вот по факту – и полтора килобайта не проскочат.
Собственно, разница между большой и малой плат невелика. На малой мы используем стороннюю плату PHY от WireShark. Она тактируется от генератора:

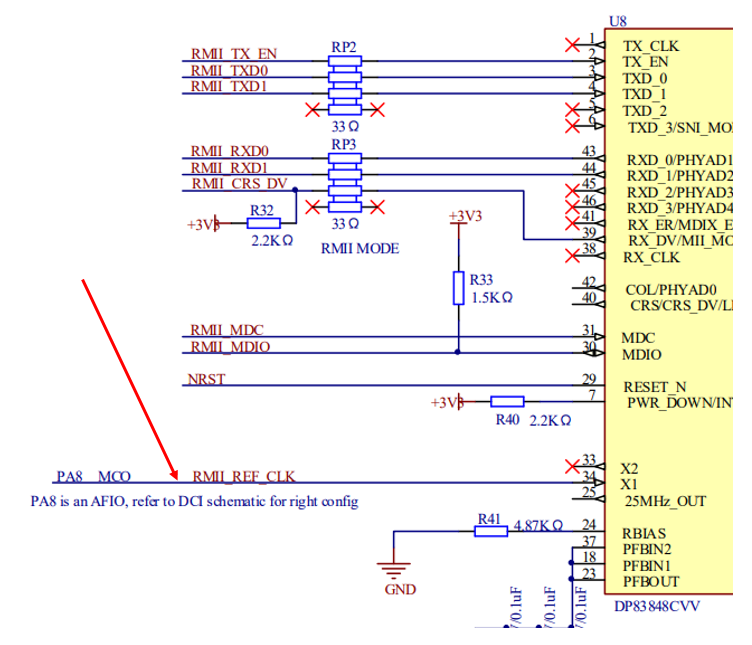
А в большой плате – всё веселей. Там PHY тактируется от порта A8 контроллера:
На порт PA8 программно подаётся выход PLL, предназначенный специально для тактирования Ethernet. У нас нет высококлассных измерительных устройств. Нет, мой осциллограф имеет полосу пропускания 200 МГц, но знаю я эти китайские мегагерцы! Невозможно с их помощью проверить качество генератора с частотой 50 МГц. Но всё-таки давайте просто проведём сравнение поведения двух плат.
Если взяться моим осциллографом за линию, идущую с генератора, то 95% времени мне показывают частоту 50 МГц:

И только иногда частота вдруг на мгновение спрыгивает на 52,632 МГц:

Но в известном анекдоте заяц смог выбить достаточно большое количество зубов медведю, а медведь зайцу – всего четыре. Потому что у зайца всего столько было. Вот и тут. Похоже, никаких иных значений мой осциллограф на такой частоте уже выдать не в состоянии, хоть там и гигагерц прогрессивной дискретизации. Либо 50, либо 52.632. Причём второе значение мигает так, что его можно поймать только, поставив развёртку на паузу. Ну ладно, запомним это.
Для платы, где частоту формирует GD32, мигают те же самые две частоты, но они сменяют друг друга хаотично и постоянно. Причём смена идёт так часто, что здесь нужно останавливать развёртку, чтобы увидеть любое из них. Нет такого, чтобы какое-то значение долго находилась на экране.
В общем, как фактическое поведение системы, так и результаты грубых измерений — всё говорит о том, что кривая частота на линии A8 получается. Иначе как объяснить, что PHY жалуется и на ложные несущие (False Carrier), и на ошибки в целом, и на опустошение буфера, а точно такая же микросхема на плате с генератором – прекрасно работает? При всём при этом, плата Nucleo тактируется от того же самого порта A8 настоящего ST-шного контроллера. И у неё, как я уже отмечал, с приёмом всё нормально. Так что перед нами вторая проблема именно контроллера GD32.
В общем, если у вас проблемы, проверьте, не PLL ли их создаёт. Возможно, стоит потратиться на внешний генератор именно для PHY.
Ну ладно, откладываем пока большую плату, проверяем малую. На ней же генератор в порядке, предвыборка в буфер достаточная. На ней же всё будет хоро… Ой! Не хорошо! Опять данные теряются! Причём на этот раз нет в логах никаких констант 55! Но теряются, теряются, теряются! Пришлось навалиться на бедную плату уже не вдвоём, а втроём!
Сначала мы шли по ложному пути и прекращали опыты после первого же сбоя, анализируя проблемный пакет. Но там всё просто идеально! Времянки – хоть на ВДНХ посылай! CRC сходится! Мы уж добавили в декодер отображение массы параметров. Например, сдвиг фронта CRS_DV относительно фронта CLK. Просто пару раз эти два сигнала одновременно взлетали для плохого пакета. Оказалось, что это нормально, у тысяч других пакетов такая же разность фаз, но те пакеты не были потеряны. В общем, ну всё у проблемного пакета так же, как у сотен и тысяч других. Никакой параметр не выбивается из статистики!
И вдруг случайно возникла идея собрать сведения не только о первом, а о большом количестве проблемных пакетов. Тут-то вся правда и открылась. Судите сами. Первый проблемный пакет появляется в случайный момент, а вот последующие… Ууууу! Заметите закономерность? Вот лог, где отображаются идентификаторы потерянных пакетов (напомню, идентификатор в каждом следующем пакете увеличивается на единицу):
ID каждого последующего отличается от предыдущего ровно на 65536. То есть, на 0x10000. Масса экспериментов показала, что это выполняется всегда.
Ещё полдня ушло на поиски, что же происходит каждые 65536 пакетов. А происходит следующее. Вот заголовки двух подряд идущих пакетов. Раз:

Два:

Голубым подсвечено поле Identification. Операционная система сама увеличивает его в каждом следующем пакете. Мы на это повлиять не можем. Прочие поля заголовка остаются неизменными. Раз поле Identification увеличивается, а прочие поля остаются, поле контрольной суммы заголовка пакета (подсвечено жёлтым) уменьшается. Вот оно прошло через значения 0002, 0001… В следующем пакете оно станет равно 0000… Вот этот пакет, восстановленный из логов анализатора:

А из памяти контроллера этот пакет взять не удастся! Потому что он будет отброшен, как проблемный! При этом в счётчиках ошибок в недрах GD32 этот факт зафиксирован не будет!
Именно поэтому первый сбой всегда случайный. Мы же не знаем, какое сейчас у системы придумано значение поля Identification для нас. А дальше – если в поток не вклинятся дополнительные пакеты, нулевое поле КС будет для каждого 0x10000-ного пакета. Ларчик просто открывался!
У STM32 такого нет! Только у GD32.
Собственно, отключаем в настройках MAC проверку КС заголовка, и всё становится хорошо. Целостность пакета всё равно будет контролироваться по его CRC. Ну, а КС заголовка, если очень хочется, можно проверить и программно. А можно и не проверять, наверное.
Уффф. А всё начиналось, как очень скучный, рутинный проект, где надо было просто отрефакторить чужой код и добавить абсолютно типовой функционал…
В статье рассмотрен случай, когда одно и то же проявление проблемы (теряются пакеты в сети) было вызвано сразу тремя причинами. Устранение двух любых не решает проблемы в целом. Также в статье показано отличие поведения блока ENET контроллера GD32 от блока ETH контроллера STM32. Ну, и указано на ошибку в модуле ENET.
Выявлено, что:
Введение
Как обычно, всё начиналось буднично. Заказчик хотел получить «прошивку», обеспечивающую функцию, суть которой настолько тривиальна, что не стоит упоминания в статье. Единственная интересная вещь в проекте заключалась в том, что Заказчик запросил, чтобы всё было реализовано на контроллере семейства GD32F450. Само собой, с полной лицензионной чистотой. То есть на базе GD-шного SDK и собранное с помощью обычного GCC, не имеющего никакого отношения к ST-шной среде разработки.
Плюс в основу проекта обязательно должна была лечь собственная UDP-библиотека, написанная нашим коллегой для STM32F4 в ходе одного из предыдущих проектов для того же Заказчика. От любимого многими LwIP она отличается компактностью и уменьшенным количеством копирований данных в памяти. Сколько раз буфер копируется при типовом внедрении LwIP – страшно посмотреть! А ведь чтение и запись памяти в микроконтроллерах – довольно медленная операция.
Использование этой библиотеки для Заказчика позволяло убедиться, что она работает и на GD32, а для нашего повествования, благодаря ей, нам удалось опуститься на самый нижний уровень программирования сетевых вещей.
Итак. Зевнув, мы перелопатили код библиотеки, заточенный на конкретный проект, раскидав его так, чтобы им можно было пользоваться из произвольной программы. Потом, не просыпаясь, мы сделали проблемно-ориентированную часть проекта. И чисто для проформы прогнали несколько тестов. Вот тут-то рутина и кончилась…
Суть проблемы
Если откинуть функциональные детали и перейти к терминам UDP протокола, обмен с устройством выглядел так:
1) ПК шлёт пакет в устройство;
2) устройство обрабатывает пакет и шлёт ответ;
3) ПК получает ответ, проверяет его содержимое и переходит к шагу 1.
На практике, на шаге 3 ответ иногда не приходил. Наверняка кто-то уже пошёл писать комментарий, что мы ничего не смыслим в UDP, там потери пакетов – это норма. Комментарии – это хорошо, комментарии я люблю. Но дело в том, что устройство было подключено к выделенной сетевой плате прямым кабелем. И, как видим, всегда в каждом направлении идёт один пакет. Очереди переполняться негде! Пакетам теряться негде! В данном конкретном случае, в правильно работающей системе потери исключены.
Мало того, мы собрали из тех же исходников прошивку для платы NUCLEO-F429ZI, на которой коллега делал свою библиотеку. Тот же тест на той плате отработал 10 часов без единой потери пакета! Тогда мы взяли типовой китайский пример для GD32, выполняющий функцию UDP эха на базе LwIP, и убедились, что он на плате с GD32 вполне себе пакеты теряет, как и наш код, собранный для этого контроллера. Так что на GD-шке всё плохо не только у нас. Но что является причиной?
Как STM32/GD32 принимает пакеты
Как я уже говорил, использование условно своей библиотеки и возможность неограниченно приставать к её автору с вопросами – это очень полезная штука в плане образования. Пользуясь случаем, расскажу всем, как принимаются пакеты в контроллере STM32/GD32. Там используется механизм прямого доступа к памяти (ПДП, далее, в терминах из фирменной документации — DMA). Контроллер DMA может работать в одном из нескольких режимов. В нашем случае (справа на рисунке), в памяти выделяется массив структур. Структура – это дескриптор для одного буфера.
Когда аппаратура DMA достигла конца массива дескрипторов, она автоматически переходит к его началу. Слева на рисунке показано, что дескрипторы не обязательно должны храниться в массиве. Они могут образовывать и связный список. Но автор нашей библиотеки сделал массив, поэтому дальше работаем только с ним.
Что мы видим из всего вышесказанного? А видим мы то, что задержки «прошивки» не могут приводить к потере данных. Как я уже говорил, у нас передача данных идёт по принципу запрос-ответ. Всегда в пути не больше одного пакета. Пока он не будет обработан – новый в сеть не уйдёт. Да, там в сети иногда бегают всякие вспомогательные пакеты, запущенные операционной системой. Вот на логах сниффера один вклинился в протокол нашего обмена:
Но повторю, сетевой адаптер в ПК, на котором ведутся опыты, – выделенный. Левые пакеты через него бегают крайне редко. Их количество обычно не превышает 3-5 штук. А буферов в разные периоды отладки было от девяти до семнадцати. Переполнение просто исключено!
Зато знание принципа размещения принимаемых данных позволило здорово упростить отладку. Адреса всех возможных буферов данных в памяти GD32 известны. В каждый пакет мы на уровне протокола добавили его идентификатор. Поэтому мы легко и непринуждённо можем отобразить в отладочной среде Eclipse те слова памяти, куда попадут эти идентификаторы. В итоге, при срабатывании точки останова сразу видно, какие пакеты успели пробежать по сети (если номера странные – ну значит, в соответствующем буфере лежит тот самый левый пакет, но такое бывало крайне редко и выявлялось по отображаемым сигнатурам, которые из рисунка для статьи я выкинул, они только отвлекают). Вот пример:
Когда какого-то идентификатора не хватает – это сразу заметно!
Макетные платы
Опыты велись на двух платах. Первая – очень навороченная плата от самой фирмы GD. Вот такая красавица:
Штука классная, но у её тестового разъёма шаг 2.0 мм. Поэтому Ардуиновскими проводочками к ней толком не подключишься. Пока эта плата была в цепких лапах Почты России, мы вели опыты на плате, изготовленной безвестными китайцами. Сама по себе плата универсальная. На неё могут быть припаяны контроллеры разных семейств и даже разных производителей (STM и GD), что следует из шелкографической маркировки на ней:
У неё нет своего PHY, но на скорую руку ребята сделали лазерно-утюжную нахлобучку с типовой платой PHY от WaveShare. Просто большая плата ожидалась со дня на день, тратить время на полноценный заказ не имело смысла, но каждый день был для нас, программистов важен, так что делать стоило. Получилось как-то так:
Ой, как этот бутерброд нам помог! Но обо всём по порядку…
Добавляем логический анализатор
Итак, у нас теряются данные. Самый главный вопрос: а в каком месте это происходит? Что они ушли из Windows, мы видим по показаниям WireShark. Что они не пришли в контроллер – мы видим по отсутствию оных в буферах DMA. А ушли ли они из драйвера Windows в сетевой адаптер ПК? Ушли ли они из адаптера в кабель? Приняты ли из кабеля в устройстве?
Самое простое, что можно сделать – это подключиться в устройстве к линиям, идущим от микросхемы PHY к микроконтроллеру. Как я уже говорил, к большой плате подключаться не очень сподручно – там шаг разъёма 2.0 мм. А у имеющегося анализатора контакты для штырей с шагом 2.54 мм. Нет, конечно, можно что-то придумать, но это же человеко-часы. Зачем их расходовать зря? Вот тут-то и пригодилась плата с внешним PHY. На неё был установлен дополнительный разъём, к которому сделаны отведения нужных сигналов. Правда, у сигналов частота 50 МГц. Тут нельзя просто так взять и сделать отвод. Отводящие провода будут создавать эхо, что приведёт к жутким помехам на линиях. Поэтому к дорожкам были припаяны отвязывающие резисторы, а уже их второй контакт пошёл к разъёму.
В «прошивку» был добавлен код, который взводит ножку GPIO, если идентификаторы внутри принимаемых пакетов идут не один за другим. По этому сигналу мы останавливаем процесс накопления данных анализатором. В буфере будет снимок, на котором видно, что творилось незадолго до и сразу после этого момента. Ну что, давайте разглядывать времянки?
Проблема номер 1 не в GD32, а в PHY
А времянки – очень красивые. Вот как работа интерфейса RMII выглядит в документации:
А вот – на анализаторе. Найдите хотя бы одно отличие…
Общий вид:
Начало:
Конец:
Красота! Обратите внимание, что все данные меняются по обратному фронту тактовой частоты! Никаких гонок нет в принципе! Вот я добавил пару зелёных курсоров, идущих от обратных фронтов линии CLK.
Но проблемы ловятся моментально! Я просто запускаю вот такую программу на ПК:
int f3() { QRandomGenerator rnd (1234); QUdpSocket socket; static const int portRemapper [uart_cnt] ={0,1,2,3,4,5}; socket.bind(QHostAddress::Any,27600); static int reqId = 1; QElapsedTimer timeOutCatcher; while (true) { uint8_t datagram [2048]; memset (datagram,0,sizeof(datagram)); uart_frame_tx* out = (uart_frame_tx*)datagram; out->magic_number = 'SELF'; out->request_id = reqId++; socket.writeDatagram((char*)datagram,1300, QHostAddress("169.254.156.232"), 27500); QThread::msleep(2); } }
И менее, чем за секунду получаю остановку с вот таким набором буферов:
Пропущен буфер номер 112. На самом деле, это ещё удачный вариант попался при подготовке иллюстраций. Иногда при реальной работе по два-три буфера пропущено было!
На времянках ничего не видно… Если точнее, то видно, конечно, потом покажу, что именно. Но их так много, что сразу и не разглядишь! Поэтому мы написали программу, которая восстанавливает из логов логического анализатора данные, пробегающие по шине. И вот тут-то вся правда и открылась. Вот как выглядит хороший буфер:
А вот так — концовка плохого буфера:
Зная это, можно найти проблемный участок и на времянках:
То есть данные переходят в постоянное состояние. И длина пакета увеличивается на один ниббл.
Кстати, если слать данные не от ПК, а замкнуть PHY в режим LoopBack, проблема не возникает никогда. У нас тест молотил почти сутки.
Опущу процесс поиска. Расскажу, почему это происходит уже в форме обнаруженного факта.
Пара слов про эластичный буфер
Что в нашем случае представляет собой микросхема PHY? Это обычный посредник, который преобразует данные из одного формата в другой. С одной стороны у него наш контроллер и интерфейс RMII, с другой – трансформаторы, за которыми тянутся провода витой пары.
И вот при приёме (а у нас ведь сбоит приёмная часть, с точки зрения контроллера) возникает очень интересная проблема. Со стороны витой пары данные идут в соответствии со скоростью, которую задаёт тактовый генератор где-то вдали (в нашем случае, в ПК). Там скорость задана, и данные будут идти в полном соответствии с нею. Ни быстрее, ни медленнее. Мы не можем попросить ПК сделать паузу. Мы обязаны принимать пакет от начала до конца. Давайте как-то подкрепим это рисунком.
А вот из микросхемы PHY данные забираются в соответствии с тактированием от генератора, который расположен где-то на плате, но вне микросхемы. На рисунке в документации это внешний генератор. Ниже мы узнаем, что в теории, это может быть и источник опорной частоты внутри контроллера. В общем, этот генератор – внешний по отношению к PHY, и он тактирует как нашу микросхему, так и блок, ответственный за работу с сетью (обычно уровень MAC) в контроллере. Давайте я подкрашу его красным цветом.
И протокол RMII устроен так, что если мы начали передачу пакета, сделать паузу невозможно. Можно только сказать, что пакет передан полностью.
Итак. Приёмный тракт нашей микросхемы имеет дело с двумя частотами, каждая из которых задана извне. Я долго думал, какую жизненную аналогию привести… Все требуют каких-то натяжек. Давайте рассмотрим аналогию с выплатой кредита. В ней натяжек будет меньше всего.
Допустим, дядя Вася взял кредит и теперь выплачивает его равными порциями. Причём дядя Вася живёт в мире, где каждый месяц равен тридцати дням. Так будет проще. Зарплата у дяди Васи пятого, платёж надо вносить десятого. Получается, что частота входящего сигнала совпадает с частотой исходящего. Просто они чуть разнесены по фазе. Деньги поступают, пять дней лежат у дяди Васи в кубышке, затем – идут на выход. Красота!
Но это – недостижимый идеал. В реальности, частота генератора имеет небольшую погрешность, полученную в процессе производства. Мало того, она зависит от окружающей среды. Да хоть от той же температуры. Поэтому частоты генераторов, задающих входной и выходной сигналы, будут чуть-чуть различаться.
Пусть у дяди Васи выросла частота входящего сигнала. Частота растёт – период уменьшается. Деньги стали поступать не каждые 30, а каждые 29 дней. А выплачивать их надо по-прежнему, каждые 30. Тогда в первый месяц дядя Вася получил деньги пятого и держал в кубышке 5 дней. В следующий месяц – четвёртого и держал в кубышке уже 6 дней. Потом – 7, 8, 9 и т.д. дней. Однажды набег составил целых 30 дней. А ещё через месяц у него в один день появилось сразу две суммы. Одна лежит уже месяц, вторая – получена прямо сегодня. Ещё через месяц двойная сумма будет в наличии уже целый день. Потом размер накоплений ещё вырастет… И так – пока не кончится срок выплаты кредита (а в нашей сетевой задаче — не кончится пакет). Эта проблема устраняется очень просто – достаточно дяде Васе завести сейф подходящего размера и хранить сумму там. С точки зрения аппаратуры – это очередь, она же FIFO.
Интереснее ситуация, если частота входящих данных станет меньше частоты исходящих. Пусть зарплату начали платить каждые 31 день. Тогда первый месяц она будет шестого, потом – седьмого, потом – восьмого, девятого, десятого… А когда она станет одиннадцатого числа, у дяди Васи начнутся проблемы с банком. В нашем же случае, контроллер не получит данных. Мы же уже выяснили, что протокол RMII не предусматривает пауз в передаче данных. Начал передавать – гони весь пакет! Не пришло данных – всё, пакет искажён. Его корректный приём невозможен. Данные обязаны идти!
Чтобы решить эту проблему, дядя Вася должен сначала несколько месяцев просто копить все входящие
Собственно, мы только что познакомились с эластичным буфером. Микросхема PHY сначала с упреждением копит некоторое заданное количество бит в FIFO, а только затем начинает выдавать их в RMII. Если данные приходят быстрее, чем отдаются, очередь будет расти. Если медленнее –уменьшаться. Вот что говорит документация на микросхему DP83848:
Считается, что при точности генератора плюс-минус 100 тактов на миллион, для разной длины буфера надо сделать ту или иную предвыборку, чтобы запаса хватило на весь пакет. Почему не стоит делать всегда большую предвыборку? Чем она больше, тем выше латентность системы. Ведь N тактов данные не передаются в контроллер, а буферизируются. И потом эти же самые N тактов (ну, если генератор точный) они будут выдаваться по линиям RMII, когда в витой паре уже тишина. А зачем нам задержка? Так что чем меньше данных предварительно кладём в эластичный буфер, тем лучше!
Ну, а в нашем случае, частоты различаются сильнее. Не знаю, почему, но сильнее. И двух битов, которые копятся по умолчанию, для нормальной работы не хватает.
Почему всё работает на плате с STM32? Ну, там и генератор иной, и микросхема PHY другой фирмы. Причём я не нашёл, какой размер предвыборки для того PHY. Может просто значение предвыборки по умолчанию там выше.
Почему работает в режиме LoopBack? Потому что в том случае используется один и тот же генератор для приёма и для передачи. Нет разбега частот – нет этой проблемы.
В общем, добавляем в код строку:
phy_write(0x17,0x23);
И проблема уходит для нашего PHY в связке с ПК… Система перестаёт вылетать в тот же миг… Но… Но детальные тесты показывают, что проблема остаётся!
Проблема номер 2 – PLL в GD32 не торт
Радуясь, что можно вернуться к большой плате (а для целевой функциональности у контроллера на малой не хватало ног), мы переключили железо, и у нас возникло ощущение дежавю. Проблема никуда не ушла. Но теперь мы были уже умные, мы уже знали как суть проблемы, так и то, что у PHY есть отладочные регистры, откуда можно считать как число ошибок, так и сведения фактах опустошения буфера. На малой плате ничего такого не возникает, на большой – буфер опустошается даже если его предзаполнять ну совсем по максимуму. Из документации следует, что целых 16 килобайт можно принять. А вот по факту – и полтора килобайта не проскочат.
Собственно, разница между большой и малой плат невелика. На малой мы используем стороннюю плату PHY от WireShark. Она тактируется от генератора:
А в большой плате – всё веселей. Там PHY тактируется от порта A8 контроллера:
На порт PA8 программно подаётся выход PLL, предназначенный специально для тактирования Ethernet. У нас нет высококлассных измерительных устройств. Нет, мой осциллограф имеет полосу пропускания 200 МГц, но знаю я эти китайские мегагерцы! Невозможно с их помощью проверить качество генератора с частотой 50 МГц. Но всё-таки давайте просто проведём сравнение поведения двух плат.
Если взяться моим осциллографом за линию, идущую с генератора, то 95% времени мне показывают частоту 50 МГц:
И только иногда частота вдруг на мгновение спрыгивает на 52,632 МГц:
Но в известном анекдоте заяц смог выбить достаточно большое количество зубов медведю, а медведь зайцу – всего четыре. Потому что у зайца всего столько было. Вот и тут. Похоже, никаких иных значений мой осциллограф на такой частоте уже выдать не в состоянии, хоть там и гигагерц прогрессивной дискретизации. Либо 50, либо 52.632. Причём второе значение мигает так, что его можно поймать только, поставив развёртку на паузу. Ну ладно, запомним это.
Для платы, где частоту формирует GD32, мигают те же самые две частоты, но они сменяют друг друга хаотично и постоянно. Причём смена идёт так часто, что здесь нужно останавливать развёртку, чтобы увидеть любое из них. Нет такого, чтобы какое-то значение долго находилась на экране.
В общем, как фактическое поведение системы, так и результаты грубых измерений — всё говорит о том, что кривая частота на линии A8 получается. Иначе как объяснить, что PHY жалуется и на ложные несущие (False Carrier), и на ошибки в целом, и на опустошение буфера, а точно такая же микросхема на плате с генератором – прекрасно работает? При всём при этом, плата Nucleo тактируется от того же самого порта A8 настоящего ST-шного контроллера. И у неё, как я уже отмечал, с приёмом всё нормально. Так что перед нами вторая проблема именно контроллера GD32.
В общем, если у вас проблемы, проверьте, не PLL ли их создаёт. Возможно, стоит потратиться на внешний генератор именно для PHY.
Проблема номер 3 – контрольная сумма
Ну ладно, откладываем пока большую плату, проверяем малую. На ней же генератор в порядке, предвыборка в буфер достаточная. На ней же всё будет хоро… Ой! Не хорошо! Опять данные теряются! Причём на этот раз нет в логах никаких констант 55! Но теряются, теряются, теряются! Пришлось навалиться на бедную плату уже не вдвоём, а втроём!
Сначала мы шли по ложному пути и прекращали опыты после первого же сбоя, анализируя проблемный пакет. Но там всё просто идеально! Времянки – хоть на ВДНХ посылай! CRC сходится! Мы уж добавили в декодер отображение массы параметров. Например, сдвиг фронта CRS_DV относительно фронта CLK. Просто пару раз эти два сигнала одновременно взлетали для плохого пакета. Оказалось, что это нормально, у тысяч других пакетов такая же разность фаз, но те пакеты не были потеряны. В общем, ну всё у проблемного пакета так же, как у сотен и тысяч других. Никакой параметр не выбивается из статистики!
И вдруг случайно возникла идея собрать сведения не только о первом, а о большом количестве проблемных пакетов. Тут-то вся правда и открылась. Судите сами. Первый проблемный пакет появляется в случайный момент, а вот последующие… Ууууу! Заметите закономерность? Вот лог, где отображаются идентификаторы потерянных пакетов (напомню, идентификатор в каждом следующем пакете увеличивается на единицу):
Lost Pkt! 49711 Lost Pkt! 115247 Lost Pkt! 180783 Lost Pkt! 246319 Lost Pkt! 311855 Lost Pkt! 377391
ID каждого последующего отличается от предыдущего ровно на 65536. То есть, на 0x10000. Масса экспериментов показала, что это выполняется всегда.
Ещё полдня ушло на поиски, что же происходит каждые 65536 пакетов. А происходит следующее. Вот заголовки двух подряд идущих пакетов. Раз:
Два:
Голубым подсвечено поле Identification. Операционная система сама увеличивает его в каждом следующем пакете. Мы на это повлиять не можем. Прочие поля заголовка остаются неизменными. Раз поле Identification увеличивается, а прочие поля остаются, поле контрольной суммы заголовка пакета (подсвечено жёлтым) уменьшается. Вот оно прошло через значения 0002, 0001… В следующем пакете оно станет равно 0000… Вот этот пакет, восстановленный из логов анализатора:
А из памяти контроллера этот пакет взять не удастся! Потому что он будет отброшен, как проблемный! При этом в счётчиках ошибок в недрах GD32 этот факт зафиксирован не будет!
Именно поэтому первый сбой всегда случайный. Мы же не знаем, какое сейчас у системы придумано значение поля Identification для нас. А дальше – если в поток не вклинятся дополнительные пакеты, нулевое поле КС будет для каждого 0x10000-ного пакета. Ларчик просто открывался!
У STM32 такого нет! Только у GD32.
Собственно, отключаем в настройках MAC проверку КС заголовка, и всё становится хорошо. Целостность пакета всё равно будет контролироваться по его CRC. Ну, а КС заголовка, если очень хочется, можно проверить и программно. А можно и не проверять, наверное.
Уффф. А всё начиналось, как очень скучный, рутинный проект, где надо было просто отрефакторить чужой код и добавить абсолютно типовой функционал…
Заключение
В статье рассмотрен случай, когда одно и то же проявление проблемы (теряются пакеты в сети) было вызвано сразу тремя причинами. Устранение двух любых не решает проблемы в целом. Также в статье показано отличие поведения блока ENET контроллера GD32 от блока ETH контроллера STM32. Ну, и указано на ошибку в модуле ENET.
Выявлено, что:
- Микросхеме DP83448 следует увеличить число предвыбираемых битов эластичного буфера.
- На плате GD32450-EVAL тактовый сигнал для микросхемы PHY, вырабатываемый в PLL контроллера GD32, настолько некачественный, что постоянно приводит к опустошению эластичного буфера PHY и состоянию False Carrier.
- Уровень MAC контроллера GD32 считает ошибочными пакеты, для которых контрольная сумма заголовка равна нулю. При этом контрольная сумма корректная. Она действительно равна нулю! У STM32 такой проблемы нет. Для устранения проблемы, следует отключить проверку контрольной суммы заголовков. При этом, целостность пакетов по-прежнему будет осуществляться путём проверки CRC32.
