Привет! Время идет, k8s и docker стали неотъемлемой частью нашей рабочей среды, но, по моему наблюдению, многие компании до сих пор считают что решить проблему deployment bottleneck возможно кучей bash скриптов или отдельным чатиком в телеграмме, в который нужно сообщать всем о новых деплоях.
Что за проблема такая, deployment bottleneck? Легче всего объяснить на примере, который вероятно покажется вам знакомым.
Пример, показывающий что такое deployment bottleneck
Представим Компанию ООО "Хорошая компания". В ней работает всего 2 человека, назвавшихся СТО и СЕО. Один из них раньше работал синьором в компании ООО "Не очень хорошая компания" и в один момент, встретившись с человеком при деньгах, будущим СЕО - они решают создать свою, хорошую компанию. СТО прекрасно знает что их компания будет успешной, а продукт максимально востребованным, поэтому изначально развивает микросервисную архитектуру их проекта. Он также хорошо знаком со всеми новыми технологиями и практиками - докеры, куберы, логи в stdout и все в этом духе. И вот спустя несколько месяцев ребята готовы показать МВП своим пользователям, которых за время разработки нашел СЕО.
Давайте слегка остановимся на этом моменте и подытожим то что имеем.
Пайплайн разработки выглядит как одна ветка master в каждом из 4 микросервисов, которые раскатаны в кластере k8s. Именно такая простота выкатывания новых фич и позволила им закончить МВП всего за пару месяцев. Тут все круто, ребята красавцы!

Проект действительно начал привлекать новых пользователей, и вот в компании работает уже 4 бекэнд и 2 фронтэнд разработчика, 1 мануальный тестировщик, проект менеджер, СТО и СЕО. Все ребята очень мотивированы и теперь их можно назвать настоящей IT компанией! У них уже 2 кластера - один для разработчиков, а другой для пользователей. Пайплайн их разработки выглядит как-то так: есть 2 одинаковые ветки - master и develop, ребята создают свою feature-ветку от develop и делают свою магию, а затем вливают все свои фичи в develop и раскатывают на dev-кластер. Именно там тестирует все мануальный тестировщик и после сообщения "ок" в телеграмме - develop вливается в мастер и самый старший по званию программист нажимает кнопку "Deploy to production" в каком-нибудь gitlab-ci. Процессы! Ребята снова красавцы!

И вот компания растет еще больше, пользователей становится много, они предлагают кучу разных новых фич и хорошие ребята из Хорошей компании с радостью их реализуют. Теперь у них в штате целых 8 бекэнд, 4 фронтэнд, 2 QA инженера, проектный менеджер и все те же, но уже менее худые, СЕО и СТО. Их кластера работают отлично, но вот незадача - их пользователи начинают все чаще жаловаться на баги, а разработчики почему-то все чаще жалуются на свою жизнь. Они проводят митинги, пытаются понять в чем же проблема, а достаточно было просто глянуть на то, как разрабатывается их проект.
8 бекэнд разработчиков работают над 8 разными задачами, их фичи из develop часто возвращают бдительные QA инженеры и git hist выглядит ну прям совсем ужасно. При вливании в мастер возникают огромные конфликты из-за критических багфиксов, которые приходится чинить самому невезучему из команды (тот что на картинке), по пути перетирая новые фичи и создавая еще больше багов.
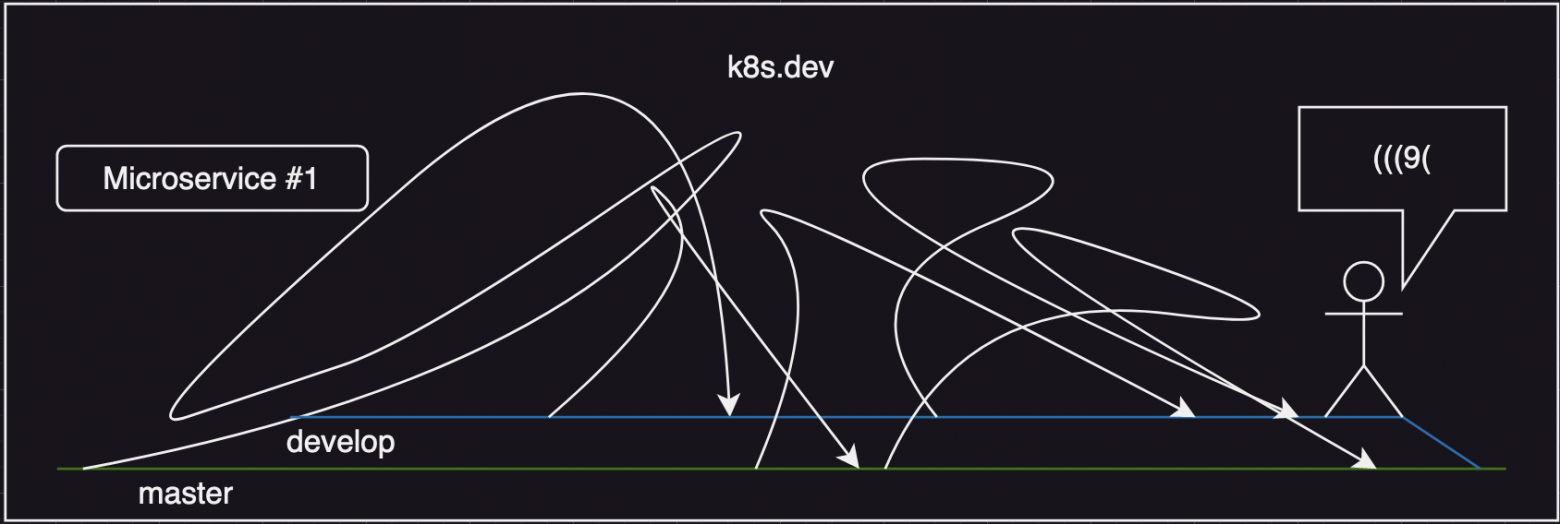
Это значит что наши ребята из Хорошей компании столкнулись с проблемой deployment bottleneck - когда желающих раскатить свои правки одновременно слишком много. Они и раньше с ней сталкивались, но "затыкали" эту проблему созданием ветки develop и не очень масштабируемым git-flow, даже не подозревая к чему это приведет.
Но как же решить эту проблему?
Проблему мы уже описали, теперь нужно понять из-за чего она возникает. Программисты - это люди (пока что), а люди - совершают ошибки. Когда вы сваливаете в одну ветку develop сразу несколько фич с потенциальными багами. Потом пытаетесь решить конфликты в коде, который вы видите первый раз в жизни так как его написал ваш коллега, а вместе с этим другой ваш коллега исправляет свой баг, который ему вернул QA и перетирает ваши исправления конфликтов. Весь ваш гит-флоу превращается в кашу.
Подожди, но ведь можно деплоить на дев кластер отдельную ветку каждой фичи. Да, можно. Но ведь это вас не избавит от начальной проблемы, из-за которой вы создали эту ветку develop. Вы столкнетесь с проблемой, когда один и тот же сервис пытаются раскатать с разными тегами на один и тот же кластер - deployment bottleneck.
И тут на сцену выходят stage-окружения (либо чатик в телеграмме, в котором разработчики "бронируют" свободный слот, чтобы проверить их фичу на дев кластере).
Если коротко, то stage-окружения это нужные для конкретной фичи набор сервисов, который можно полноценно протестировать или показать заказчику. А теперь давайте перейдем к практике.
Сперва предлагаю установить следующий гит-флоу: мы создаем ветку от мастера, в ней разрабатываем фичу, после этого создаем merge request в мастер и вливаем если все ок. Из мастера мы можем раскатать все на dev кластер, а потом, отбив тег, раскатать в прод к нашим пользователям.
Вместе с этим гиф-флоу необходимо добиться сборки докер образа вашего сервиса для каждой ветки и возможность деплоя этих образов как отдельные, независимые друг от друга окружения. По итогу мы должны получить: на проде крутятся образы с релизными тегами, на деве крутятся образы из мастера (или просто latest), а так же у каждой созданной ветки должен быть свой докер-образ.

Самое сложное позади!
Как правильно и быстро раскатывать эти branch-based образы - комплексная проблема, которую решают по разному, но я решил собрать сахар в кучу и сделать небольшой open-source проект, который и сам буду использовать во всех своих проектах. Проект я назвал k8sbox и он позволяет, составив одну toml спецификацию, раскатывать ваши микросервисы по вашему кластеру.
Объединив термины и слегка подумав я получил самый простой и понятный интерфейс для этой спецификации. У нас есть окружение (environment), в котором находятся некие коробки (boxes), внутри которых лежат наши микросервисы (applications).
И вот как выглядит примерная toml спецификация:
id = "${TEST_ENV}" # It could be your ${CI_SLUG} for example name = "test environment" namespace = "test" variables = "${PWD}/examples/environments/.env" [[boxes]] type = "helm" chart = "${PWD}/examples/environments/box1/Chart.yaml" values = "${PWD}/examples/environments/box1/values.yaml" name = "first-box-2" [[boxes.applications]] name = "service-nginx-1" chart = "${PWD}/examples/environments/box1/templates/api-nginx-service.yaml" [[boxes.applications]] name = "deployment-nginx-1" chart = "${PWD}/examples/environments/box1/templates/api-nginx-deployment.yaml" [[boxes]] type = "helm" chart = "${PWD}/examples/environments/box2/Chart.yaml" values = "${PWD}/examples/environments/box2/values.yaml" name = "second-box-2" [[boxes.applications]] name = "service-nginx-2" chart = "${PWD}/examples/environments/box2/templates/api-nginx-service.yaml" [[boxes.applications]] name = "deployment-nginx-2" chart = "${PWD}/examples/environments/box2/templates/api-nginx-deployment.yaml" [[boxes]] type = "helm" chart = "${PWD}/examples/environments/ingress/Chart.yaml" name = "third-box" values = "${PWD}/examples/environments/ingress/values.yaml" [[boxes.applications]] name = "www-ingress-toml" chart = "${PWD}/examples/environments/ingress/templates/ingress.yaml"
Вся документация доступна и находится в ссылках в конце этой статьи, но тут вроде бы и так все понятно, достаточно лишь взглянуть на пример (который полностью лежит в репозитории гитхаба).
Вместе с этим чартом - мы можем запустить наш инструмент k8sbox и он раскатит данное окружение на вашем k8s кластере. Как-то так:
$ k8sbox run -f environment.toml
А если вдруг наш QA нашел баг и нам требуется перезалить окружение - мы просто выполняем ту же самую команду run. Он удалит все предыдущие чарты и установит их заново, причем сделает это очень быстро. Вот так:

Вы также всегда сможете посмотреть какие окружения вы уже раскатали на кластере и узнать подробности, с помощью команд
$ k8sbox get environment // list of saved environments $ k8sbox describe environment {EnvironmentID} // describe the environment
Ну, а если ваш QA инженер сказал "ОК", то мы сможем легко отчистить кластер от нашего окружения, выполнив команду:
$ k8sbox delete -f environment.toml
Все ваши сервисы раскатываются на ВАШЕМ k8s кластере, а это значит вы сможете настроить любые желаемые параметры для них. А так же из плюсов - готовые докер образы с entrypoint как раз на k8sbox. То есть вы сможете легко интегрировать данный инструмент в любые ваши CI-пайплайны.
Этот инструмент позволит вам решить проблему deployment bottleneck очень простым способом - разделив разработку новых фич, дав разработчикам возможность делать свою магию параллельно и независимо друг от друга.
Полезные ссылки:
Статья про deployment bottleneck в которой советуют реже деплоить -_-
