Main idea
The idea of the principal component analysis (PCA) is to replace the basis in order to reduce the dimension of the input data with minimal loss in informativeness. In other words, we will try to introduce new predictors for the old data so that the information content of the new predictors is maximum. At the same time, we do not discard part of the data, but make some composition of features, which eventually become fewer. The idea is easier to understand from the image below.
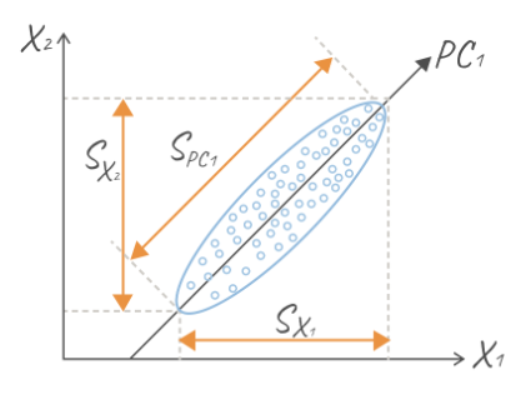
The blue dots forming, conditionally, an ellipse are data (each object has a pair of features). It seems like it's logical that along the line, the data change is most significant, isn't it? Why do we think so? But because along this straight line, obviously, the spread from the average (conditionally, from the center of the ellipse) is the largest. As a result, according to our idea, it is assumed that the greater the sample variance along the axis, the better the data changes. By itself, the idea of building a new coordinate system is not new, it echoes the idea and experience in analytical geometry: choose a convenient coordinate system, and the task will be solved many times easier.
line, the data change is most significant, isn't it? Why do we think so? But because along this straight line, obviously, the spread from the average (conditionally, from the center of the ellipse) is the largest. As a result, according to our idea, it is assumed that the greater the sample variance along the axis, the better the data changes. By itself, the idea of building a new coordinate system is not new, it echoes the idea and experience in analytical geometry: choose a convenient coordinate system, and the task will be solved many times easier.
Construction of the first main component
Definition 1. Centering – subtracting from each coordinate of each object the average of the values of this coordinate for all objects.
To begin with, it is always better to center the data, in fact, it has little effect, because we just shifted the center of the coordinate system, but this will simplify future calculations.
Let's consider some set of objects having two attributes. This means that each object
having two attributes. This means that each object can be identified with a vector having two coordinates
can be identified with a vector having two coordinates  that is,
that is,  .
.
After changing the power of the basis to one, each object will correspond to a single coordinate
will correspond to a single coordinate .
.
Then the new coordinates of all objects can be written as a column vector
Since we want to draw a new line so that the new coordinates differ from each other as much as possible, we will use sample variance as a measure of difference
 , where
, where  - sample average.
- sample average.
Definition 2. A straight line passing through the origin, the coordinates of the projections of the centered source objects on which have the largest sample variance, is called the first main component and is denoted 
Definition 3. The guiding vector of the first main component, having length 1, is called the vector of weights of the first main component.
of the first main component, having length 1, is called the vector of weights of the first main component.
To find the new coordinate  the line
the line  with the basis vector
with the basis vector  you can use the scalar product, which is defined as follows:
you can use the scalar product, which is defined as follows: where
where is the angle between the vectors
is the angle between the vectors and
and Considering that
Considering that  Or you can use
Or you can use  See the picture below.
See the picture below.
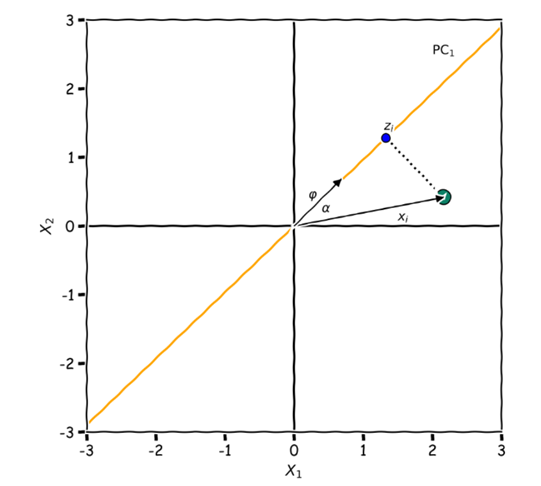
So, our task is to find such weights that is, to find a way to draw a straight line so that the coordinates of the projections of points on this line differ the most, that is, they have the greatest sample variance. We will discuss this a little later.
that is, to find a way to draw a straight line so that the coordinates of the projections of points on this line differ the most, that is, they have the greatest sample variance. We will discuss this a little later.
The second and subsequent main components
Let the initial feature space have dimension p >= 2 and it is necessary to construct not one, but k principal components. The first main component is constructed similarly to the example considered. The second and subsequent Main components are constructed so that they also pass through the origin, orthogonally to all previously constructed main components. The requirement of orthogonality of the main components ensures that there is no correlation between the new features of objects. At the same time, the next main component is constructed so that the sample variance of projections is maximal.
Finding the vector of weights of the first main component
Definition 4. Let n objects have p features each, that is,
have p features each, that is,  Then we will call the matrix of the initial data a matrix of size [n*p] of the form
Then we will call the matrix of the initial data a matrix of size [n*p] of the form

where in the i-th row of the matrix F are the corresponding features of the i–th object.
Next, we assume that the matrix F is obtained as a result of centering some initial matrix of objects F’.
Remark. Since we have p features, the guiding vector (the vector of weights) will also have p features:  And since the length of the vector is equal to one, then
And since the length of the vector is equal to one, then

In matrix notation, we will write the coordinates of the vector in the form of a column
in the form of a column
vector of the same name: 
Definition 5. The vector of accounts of the first main component is a column vector of the form
 consisting of the coordinates of projections of centered source data on the
consisting of the coordinates of projections of centered source data on the
vector of weights of the first main component. In other words, the vector of accounts of the first main component is the new coordinates of objects relative to the first main component.
Theorem 1. Let

be a matrix consisting of centered source data, and let be a vector of weights of the first principal component. Then the vector of accounts of the first principal component can be obtained from the relation
be a vector of weights of the first principal component. Then the vector of accounts of the first principal component can be obtained from the relation Provided that the sample variance of the resulting set is maximal.
Provided that the sample variance of the resulting set is maximal.
Let me remind you that the sample variance of the sample can be found by the following
sample can be found by the following
formula:  Note that the right side of this difference can be
Note that the right side of this difference can be
transformed as follows:


But taking into account the fact that the features are centered, which means their sample
are centered, which means their sample
averages are zero, that is we get that each term in
we get that each term in
the last sum is zero.  Returning to the sample variance,
Returning to the sample variance,
we get:  in other words, we are looking for a vector of
in other words, we are looking for a vector of
weights such that the square of the length of the vector of accounts
of the vector of accounts is maximal.
is maximal.
That is,  provided that
provided that
Finding an arbitrary main component
Let the first main component be constructed. The straight line passing through the origin orthogonally to the first main component
be constructed. The straight line passing through the origin orthogonally to the first main component the coordinates of the projections of the centered source objects on which have the greatest sample variance, is called the second main component and is denoted
the coordinates of the projections of the centered source objects on which have the greatest sample variance, is called the second main component and is denoted
And in general, let  main components
main components be constructed. The line passing through the origin orthogonally to each main component, the coordinates of the projections of the centered source objects on which have the largest sample variance, is called the k-th main component and is denoted
be constructed. The line passing through the origin orthogonally to each main component, the coordinates of the projections of the centered source objects on which have the largest sample variance, is called the k-th main component and is denoted
Similarly, as in the previous case, definitions of the guiding vector, the vector of accounts are introduced, and the formula for calculating the vector of accounts of the k-th main component remains the same.
A small conclusion on the calculation of the k-th main component
Summing up, the search for the k-th main component or, what is the same thing, the vector of weights  and, as a consequence, the vector of accounts
and, as a consequence, the vector of accounts  is carried out according to the following algorithm:
is carried out according to the following algorithm:
1) It is stated that the vector has unit length, that is 
2) It is stated that the vector is orthogonal to each of the vectors of weights
is orthogonal to each of the vectors of weights 
3) Then we solve the problem

4) After, using the formula  we calculate the vector of accounts of the k-th main component.
we calculate the vector of accounts of the k-th main component.
Example of finding the first main component
Suppose we have a table of elements that contain two attributes each:
Result (x(i)) | attribute 1 (X’(1)) | attribute 2 (X’(2)) |
1 | 9 | 19 |
2 | 6 | 22 |
3 | 11 | 27 |
4 | 12 | 25 |
5 | 7 | 22 |
Let's perform centering of features:
result (x(i)) | attribute 1 (X’(1)) | attribute 2 (X’(2)) |
1 | 0 | -4 |
2 | -3 | -1 |
3 | 2 | 4 |
4 | 3 | 2 |
5 | -2 | -1 |
According to the written table, we will make a matrix:

Further, under the condition and by the formula, we have
and by the formula, we have

Now, we need to maximize the sample variance Then, we get
Then, we get

Let's open the brackets and give similar terms. We find
We find
that when  the largest value of the function is reached.
the largest value of the function is reached.
Given a condition we find 2 pairs of solutions:
we find 2 pairs of solutions: or
or  We can choose any pair, since the difference is only in the direction. And now, we can calculate the new coordinates of the objects, relative to the first main component:
We can choose any pair, since the difference is only in the direction. And now, we can calculate the new coordinates of the objects, relative to the first main component:

Since the direction of the first main component is given by the vector of weights it is possible to construct an equation of a straight line:
it is possible to construct an equation of a straight line:

Choosing the number of main components
Definition 9. A nonzero vector is called an eigenvector of the theta matrix if the relation is satisfied for a certain number of lambda:
vector is called an eigenvector of the theta matrix if the relation is satisfied for a certain number of lambda: In this case, the lambda number is called the eigenvalue of the theta matrix.
In this case, the lambda number is called the eigenvalue of the theta matrix.
Let's consider the sequence of actions for finding the main components. Let F be a centered matrix containing information about n objects with p features.

1) Find a sample covariance matrix from the ratio
2) Find the eigenvalues of matrix
of matrix
3) Find the orthonormal eigenvectors of matrix
of matrix corresponding to the eigenvalues
corresponding to the eigenvalues
4) Select the required number of main components. At the same time, as the vector of weights of the first main component, it is reasonable to take the eigenvector of the theta matrix corresponding to the largest eigenvalue of this matrix (so that the loss of initial information is the least). As a vector of weights, the second main component is an eigenvector corresponding to the second largest eigenvalue, and so on.
5) Find new coordinates of objects in the selected basis by performing multiplication  given that the coordinates of the selected eigenvectors are columns of the matrix
given that the coordinates of the selected eigenvectors are columns of the matrix , and in the first column
, and in the first column are the coordinates of the vector of weights corresponding to the largest eigenvalue of the theta matrix, in the second – the coordinates of the vector of weights corresponding to the second largest eigenvalue, and so on.
are the coordinates of the vector of weights corresponding to the largest eigenvalue of the theta matrix, in the second – the coordinates of the vector of weights corresponding to the second largest eigenvalue, and so on.
Remark. Note that the eigenvalues for the selected main component are equal to the sample variances of the i-th accounts.
the selected main component are equal to the sample variances of the i-th accounts.
Definition 10. Let  be the eigenvalues of the covariance matrix, and the eigenvectors of the covariance matrix corresponding to the largest eigenvalues
be the eigenvalues of the covariance matrix, and the eigenvectors of the covariance matrix corresponding to the largest eigenvalues  are taken as the vectors of the weights of the first k main component. The value
are taken as the vectors of the weights of the first k main component. The value

is called the proportion of the explained variance.
Remark. It is easy to notice that it takes values from zero to one and shows which part of the variance is taken into account when using the first k main components relative to the entire variance. In other words, the closer it is to unity, the less information we lose about the original objects.
it takes values from zero to one and shows which part of the variance is taken into account when using the first k main components relative to the entire variance. In other words, the closer it is to unity, the less information we lose about the original objects.
Example of finding the first main component
Suppose we have a table of elements that contain two attributes each:
Result (x(i)) | attribute 1 (X’(1)) | attribute 2 (X’(2)) |
1 | 9 | 19 |
2 | 6 | 22 |
3 | 11 | 27 |
4 | 12 | 25 |
5 | 7 | 22 |
Let's perform centering of features:
result (x(i)) | attribute 1 (X’(1)) | attribute 2 (X’(2)) |
1 | 0 | -4 |
2 | -3 | -1 |
3 | 2 | 4 |
4 | 3 | 2 |
5 | -2 | -1 |
According to the written table , we will make a matrix:

Let's make a selective covariance matrix:
covariance matrix: 
Let's find the eigenvalues of this matrix. Recall that the eigenvalues are found from the condition that the determinant of the difference and
and is zero:
is zero: where E is the unit matrix. In our case:
where E is the unit matrix. In our case:

We get the following roots:

Since we choose the maximum among all eigenvalues for the first principal component and by definition we get
we get

And, accordingly, we will find the roots of this equation:

Then, if then we get the following expression for the accounts of the first main component:
then we get the following expression for the accounts of the first main component:

Let’s find the proportion of the explained variance if we leave one main component:

We got about 0.8, a good result.
Conclusion
In this article, we examined the key idea of the principal component analysis, learnt how to find the vectors of the weights of the principal components, how to determine how much information we lost during transformation, and considered a couple of examples.
