
Я знаю, что существует множество статей о
flow и channelFlow, в которых часто подчёркивается, что channelFlow по сути использует Channel. Но что это на самом деле значит для мобильных разработчиков? Когда это различие действительно имеет значение? Можно ли добиться такого же поведения с помощью flow без использования Channel, и какие уникальные возможности предлагает ChannelFlow, которых нельзя достичь с помощью обычного Flow?Ключ к этому вопросу лежит в понимании основной концепции
Channel. Концептуально Channel и Flow служат разным целям. Каналы (Channels) облегчают взаимодействие между корутинами, в то время как потоки (Flows) больше направлены на эффективное производство и распределение данных.ChannelFlow использует Channel для своих операций, что делает его мощным инструментом в сценариях, включающих сложную обработку данных или требующих одновременного выброса данных из нескольких корутин. Однако что же это такое?Рассмотрим реальный сценарий, в котором приложения образуют связанную сеть, обнаруживая близлежащие приложения (устройства) через Bluetooth или локальную сеть и одновременно получая информацию о близлежащих устройствах с удалённого сервера. В этом случае каждому приложению может потребоваться отправить данные из трёх различных источников, которые работают независимо и непрерывно.
val nearbyDevices = channelFlow {
launch {
send(LANHelper.discoverConnectableHosts())
}
launch {
send(BluetoothHelper.discoverConnectableDevices())
}
launch {
send(NetworkHelper.getRegisteredDevices())
}
}
// At the place you need the data
nearbyDevices.collect { data ->
// Do something
}Все три источника живут в своих собственных корутинах и передают значения в один и тот же канал, который можно потреблять без дополнительных ухищрений.
Можно ли добиться аналогичного поведения с помощью простого
Flow? Да, вы можете разделить сетевые запросы и обнаружение Bluetooth на несколько различных потоков, а затем объединить данные с помощью специальной функции.fun networkDataFlow() = flow {
emit(LANHelper.discoverConnectableHosts())
}
fun bluetoothDiscoveryFlow() = flow {
emit(BluetoothHelper.discoverConnectableDevices())
}
fun registeredDevicesNearbyFlow() = flow {
emit(NetworkHelper.getRegisteredDevices())
}
// At the place you need the data
merge(
networkDataFlow(),
bluetoothDiscoveryFlow(),
registeredDevicesNearbyFlow()
) { networkData, bluetoothData, registeredDevices ->
// React to the data
}.collect { combinedData ->
println(combinedData)
}Разница пока что лежит скорее на уровне архитектуры.
Использование обоих на таких простых приложениях будет работать одинаково, если у вас нет высокоскоростной эмиссии.
Производительность
Flow также является важным фактором. Я нашёл неплохую статью — в ней описано множество случаев использования Flow и ChannelFlow, а также приведены некоторые данные о производительности.Спустя год с момента выхода статьи я повторил тест на Pixel 7a (10 раз для каждого потока и затем вычислил среднее время для каждого запуска) и получил аналогичные результаты (так что никакой оптимизации не произошло… хе-хе).
flow
1000 -> 0.012513591
10000 -> 0.091140584
100000 -> 0.411128418
1000000 -> 8.215107670
10000000 -> 40.605143168
100000000 -> 403.867435622
channelFlow
1000 -> 0.040344645
10000 -> 0.300058228
100000 -> 12.407572719
1000000 -> 106.307522798
10000000 -> 310.608283640
I stopped waiting after an hour of calculations :)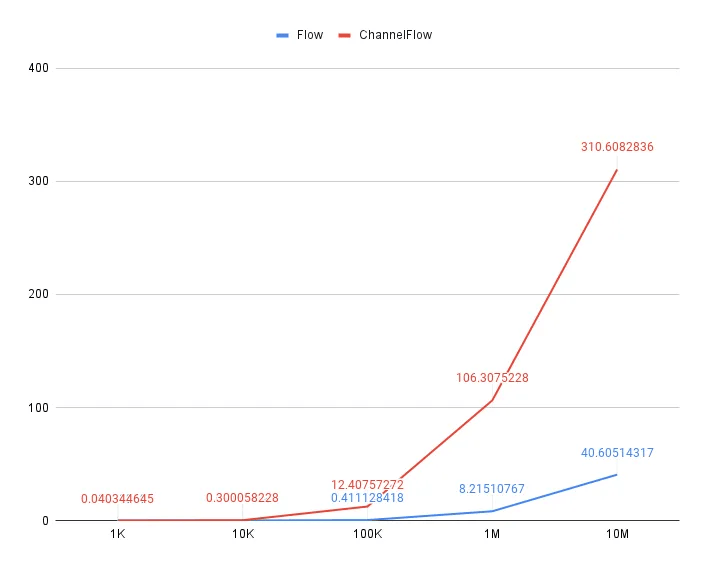
Как видите,
channelFlow в три раза медленнее базового Flow на 1000 выбросов, и эта разница растёт в геометрической прогрессии.Но… Так ли это для мобильной разработки? Если приложение производит сто тысяч вычислений в секунду и передаёт их на потребление — вероятно, что-то не так. В тесте использовался примитивный тип, но использование реальных объектов увеличит время. Одно дело — передать значение, но и потреблять его нужно с такой же скоростью. В противном случае мы увидим снижение производительности всего приложения.
Вот что происходит в меньшем масштабе — от 25 до 1000 переданных значений. Я добавил небольшую задержку в 10 мс, имитирующую сетевые запросы, что влияет на ситуацию.
Вот код из статьи, которую я упоминал, с добавленной задержкой:
val time = measureNanoTime {
channelFlow {
for (i in 1..count) {
send(i)
delay(10)
}
}.collect {}
}Результат:
flow
25 -> 0.270430624
50 -> 0.558355266
75 -> 0.859869426
100 -> 1.187430339
250 -> 3.382514854
500 -> 6.320075401
750 -> 10.442842698
1000 -> 13.770569424
channelFlow
25 -> 0.276624023
50 -> 0.591518759
75 -> 1.06053414
100 -> 1.362990153
250 -> 3.417985678
500 -> 7.18098564
750 -> 11.00395154
1000 -> 14.33561907
Разница заметна, и она превышает пороговый уровень для выброса более 100 в секунду.
Я нашёл хороший пример, когда
channelFlow действительно крут. Он пришёл мне в голову, когда я пытался найти то, что мы не можем сделать с помощью Flow.suspend fun launchAdditionalProducer(scope: ProducerScope<String>) {
scope.launch {
repeat(5) { index ->
delay(50)
scope.send("Message $index from Main Additional Producer")
}
}
}
fun mainFlow() {
val channel = channelFlow {
launch {
repeat(20) { index ->
delay(100)
send("Message $index from Main Producer")
if (index == 2) {
launchAdditionalProducer(this@channelFlow)
}
if (index >= 5) {
cancel()
}
}
}
launch {
repeat(20) { index ->
delay(33)
send("Message $index from Secondary Producer")
}
}
}
CoroutineScope(Dispatchers.Default).launch {
channel.collect { value ->
println(value)
}
}
}В этом примере код запускает
channelFlow с двумя корутинами, которые передают значения. Когда первая корутина отправляет «2», запускается новая корутина и начинает производить значения. В момент «5» первый «Main producer» отменяется, и дополнительный producer отменяется вместе с главной корутиной.19:03:53.254 I Message 0 from Secondary Producer <- Secondary producer ~3 times faster than Main producer
19:03:53.289 I Message 1 from Secondary Producer
19:03:53.322 I Message 0 from Main Producer
19:03:53.325 I Message 2 from Secondary Producer
19:03:53.359 I Message 3 from Secondary Producer
19:03:53.394 I Message 4 from Secondary Producer
19:03:53.424 I Message 1 from Main Producer
19:03:53.429 I Message 5 from Secondary Producer
19:03:53.464 I Message 6 from Secondary Producer
19:03:53.504 I Message 7 from Secondary Producer
19:03:53.525 I Message 2 from Main Producer <-- Additional coroutine launches
19:03:53.538 I Message 8 from Secondary Producer
19:03:53.572 I Message 9 from Secondary Producer
19:03:53.577 I Message 0 from Main Additional Producer
19:03:53.606 I Message 10 from Secondary Producer
19:03:53.626 I Message 3 from Main Producer
19:03:53.628 I Message 1 from Main Additional Producer
19:03:53.641 I Message 11 from Secondary Producer
19:03:53.676 I Message 12 from Secondary Producer
19:03:53.681 I Message 2 from Main Additional Producer
19:03:53.711 I Message 13 from Secondary Producer
19:03:53.728 I Message 4 from Main Producer
19:03:53.733 I Message 3 from Main Additional Producer
19:03:53.745 I Message 14 from Secondary Producer
19:03:53.781 I Message 15 from Secondary Producer
19:03:53.792 I Message 4 from Main Additional Producer
19:03:53.815 I Message 16 from Secondary Producer
19:03:53.837 I Message 5 from Main Producer <- Main producer and Additional coroutine get cancelled.
19:03:53.852 I Message 17 from Secondary Producer
19:03:53.889 I Message 18 from Secondary Producer
19:03:53.924 I Message 19 from Secondary ProducerЭто, пожалуй, самый важный момент.
ChannelFlow позволяет разработчикам не только асинхронно производить данные из разных источников, но и даёт полный контроль над тем, как должны выглядеть жизненные циклы корутинов независимо друг от друга. В случае ChannelFlow можно гибко балансировать нагрузку на оборудование во время выполнения. В то же время Flow использует стандартный механизм параллелизма и асинхронного управления, защищённый от разработчика. Так почему же по умолчанию используется
Flow, а не ChannelFlow?- Он быстрее на высокоскоростных эмиссиях.
- Не приходится долго думать о поведении потоков данных.
- Его поведение и жизненный цикл такие же, как и у любой другой базовой реализации в Kotlin. Если вы видите
flow {}, вы знаете, что все они ведут себя одинаково.ChannelFlow, в то же время, является сигналом, что здесь может быть сложная логика или структура корутинов, которые производят один поток данных. - Потенциально это сложнее проверить.
Поделитесь, как вы используете ChannelFlow и почему.

