В ходе разработки IDE 1С:Enterprise Development Tools у нас возникла необходимость быстро оперировать с довольно большими (несколько гигабайтов) объемами данных. Если не вдаваться в детали: при интерактивной работе пользователя с IDE при переключении с одной ветки репозитория на другую нам нужно сохранить текущее состояние проекта и загрузить состояние проекта из новой ветки. Детали (и объяснение – почему счет идет на гигабайты) — в конце статьи, непосредственно к Java это отношения не имеет, кому интересно – прочтет. Ну а что касается Java, то задача выглядит так: быстро сохранить несколько гигабайт информации на диск и быстро считать несколько гигабайт информации с диска. Как мы решали эту задачу, с какими трудностями столкнулись и как их преодолели – под хабракатом.

Очевидно, что хранить данные на диске лучше сжатыми (например, зазипованными) – во-первых, экономится дисковое пространство, во-вторых – уменьшается время на чтение и запись (т.к. операции будут проводиться с данными меньшего размера). Таким образом, задача разбивается на три подзадачи:
Приступим!
Одна из идей ускорения чтения и записи сжатых данных – это использование многопоточности для ускорения чтения и записи ZIP-архива на диск.
В стандартной Java-библиотеке для работы с архивами, к сожалению, нет опции для работы в многопоточном режиме. Готовых сторонних библиотек для этой задачи мы тоже не нашли. Хотя, теоретически, ZIP файл можно писать в несколько потоков, если при этом кэшировать сжатые куски данных в оперативной памяти, а на диск писать последовательно.
Мы решили развить эту идею, чтобы не держать много данных в оперативной памяти, а как можно скорее записывать их на диск. При этом мы использовали такие стандартные механизмы Java:
Самый важный тут механизм – это каналы Java. Они позволяют производить запись на диск сжатых кусков данных в режиме, когда блокировка происходит только при обновлении позиции канала записи или размера файла. Таким образом, механизм сжатия данных делает следующее:
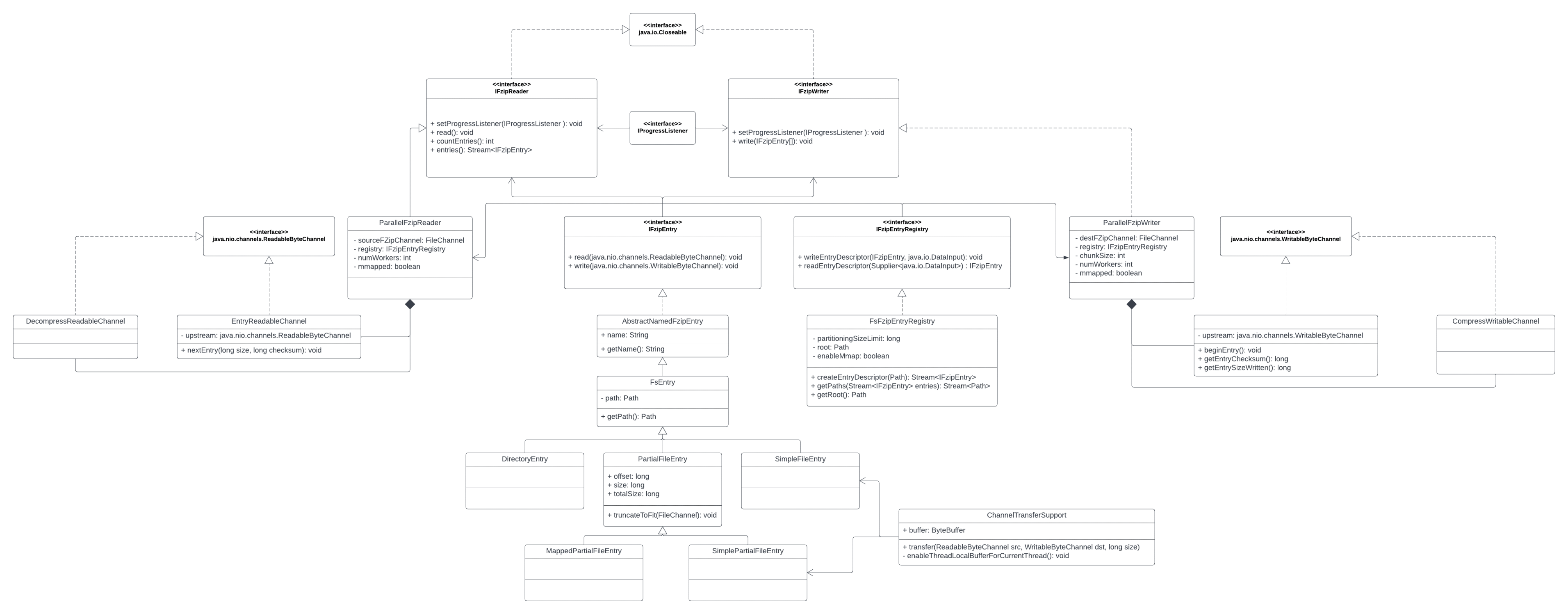
Данному механизму внутри проекта мы дали имя fzip, его архитектура отображена на диаграмме классов (полный размер):

Обычно для работы с ZIP-архивами в Java используется библиотека zlib с алгоритмом deflate. Это довольно старый алгоритм, предоставляющий хороший баланс между скоростью и степенью сжатия данных – именно поэтому его используют уже много лет.
Тем не менее мы нашли ещё два алгоритма сжатия, более новых, чем deflate:
Мы искали алгоритмы с хорошим балансом между скоростью и степенью сжатия данных. Поэтому мы отсеяли алгоритмы LZ4 и Snappy, имеющие высокую скорость, но невысокую степень сжатия (для нашей задачи). Также мы отсеяли алгоритм LZMA – из-за низкой скорости компрессии (ниже, чем у deflate).
Посмотрев на сравнение zstd и brotli, мы решили, что для нашей задачи оптимальным выбором будет zstd, потому что у него скорость записи выше, чем Brotli (хотя zstd и несколько проигрывает по степени сжатия brotli).
Для использования этого алгоритма мы выбрали библиотеку zstd-jni. На наш взгляд она имеет несколько недостатков: переусложненное и плохо адаптируемое API и использование finalize, многопоточность есть только на сжатие и при работе с обычными
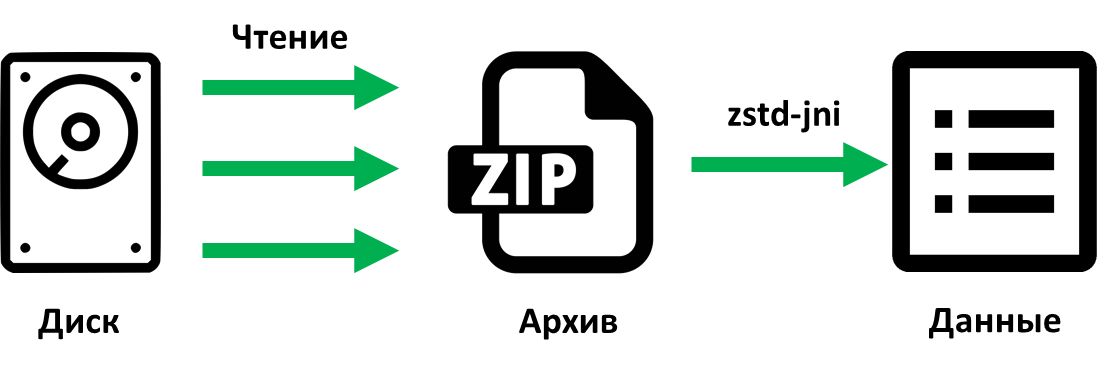
zstd-jni предоставляет возможность параллельного сжатия данных, что для нас немаловажно. Чтобы понять возможности библиотеки мы провели ряд экспериментов. Эксперименты показали, что если использовать однопоточную версию zstd-jni вместе с ранее сделанным нами распараллеливанием записи ZIP-архива на диск для алгоритма deflate, то результаты оказываются намного лучше, чем если использовать многопоточную версию zstd-jni, но производить запись данных в один поток. Видимо, это обусловлено тем, что операция ввода/вывода гораздо медленнее, чем операция сжатия данных. Поэтому, используя многопоточный вариант сжатия при записи файла в один поток, мы получили намного худший результат.
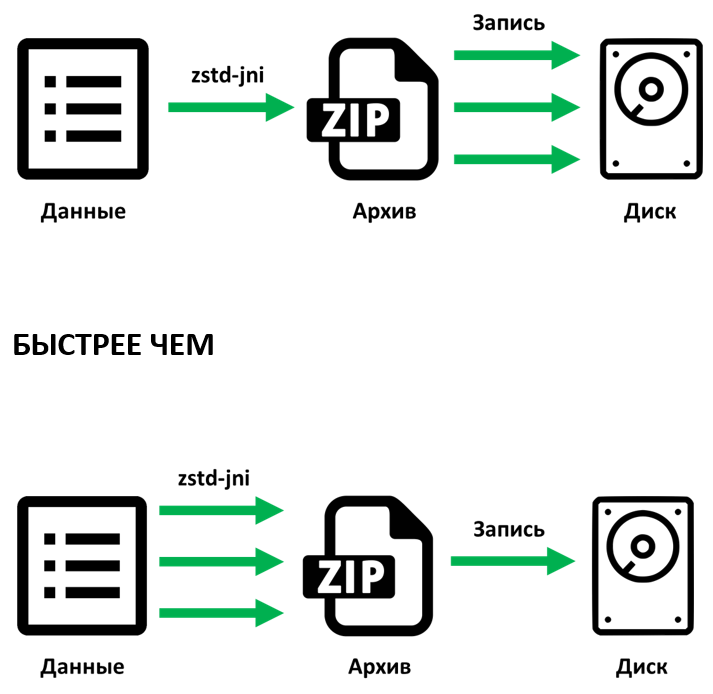
Читаем мы так:
Как мы и ожидали, оптимизация получилась существенная.
Условия проведения тестов:
Результаты тестов:
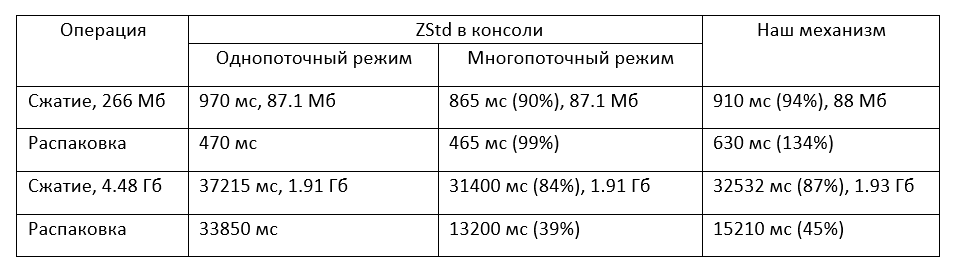
Также мы провели сравнительные тесты полученной библиотеки с консольным приложением zstd. Консольный ZStd запускался на той же машине из-под Windows, проценты указаны по сравнению с однопоточным вариантом ZStd.
Надеемся, наш подход к ускорению сжатия и записи данных пригодится Java-разработчикам, решающим аналогичные задачи.
Ну а теперь – почему перед нами встала эта задача.
Коротко: у нас есть IDE для разработки бизнес-приложений, создан на основе Eclipse, написан на Java. Называется 1С:Enterprise Development Tools (сокращённо EDT).

Исходники бизнес-приложений бывают большими, до нескольких гигабайт (зависит от функциональности бизнес-приложения). Помимо собственно исходников EDT создает некоторый объем служебной информации (размер её прямо пропорционален размеру проекта). Служебная информация нужна для комфортной работы – быстрой навигации по проекту, проверки кода по мере его написания и т.д.
Когда мы переключаемся между проектами нам нужно получить служебную информацию для проекта. Раньше мы перестраивали всю служебную информацию, но это занимало существенное время. В новой версии EDT при переключении между проектами мы сохраняем служебную информацию на диск, чтобы при возврате к проекту не пересчитывать её заново. Но даже сохранение и считывание нескольких гигабайт информации – процесс длительный.
Под катом – детали. Но главное мы уже сказали.
Что делать?
Очевидно, что хранить данные на диске лучше сжатыми (например, зазипованными) – во-первых, экономится дисковое пространство, во-вторых – уменьшается время на чтение и запись (т.к. операции будут проводиться с данными меньшего размера). Таким образом, задача разбивается на три подзадачи:
- Быстрое сжатие данных в ZIP-архив
- Быстрая запись архива на диск
- Быстрое чтение архива с диска
Приступим!
Ускорение чтения и записи сжатых данных
Одна из идей ускорения чтения и записи сжатых данных – это использование многопоточности для ускорения чтения и записи ZIP-архива на диск.
В стандартной Java-библиотеке для работы с архивами, к сожалению, нет опции для работы в многопоточном режиме. Готовых сторонних библиотек для этой задачи мы тоже не нашли. Хотя, теоретически, ZIP файл можно писать в несколько потоков, если при этом кэшировать сжатые куски данных в оперативной памяти, а на диск писать последовательно.
Мы решили развить эту идею, чтобы не держать много данных в оперативной памяти, а как можно скорее записывать их на диск. При этом мы использовали такие стандартные механизмы Java:
- Синхронизация
- Direct ByteBuffer
- Memory-mapped IO
- Каналы Java: java.nio.channels.FileChannel как безопасный и производительный инструмент для записи и чтения файла из нескольких потоков
Самый важный тут механизм – это каналы Java. Они позволяют производить запись на диск сжатых кусков данных в режиме, когда блокировка происходит только при обновлении позиции канала записи или размера файла. Таким образом, механизм сжатия данных делает следующее:
- Запускает максимальное возможное в системе число потоков в одном процессе
- Каждый поток берет порцию данных для сжатия, размечает канал для их помещения, сжимает и записывает их
Данному механизму внутри проекта мы дали имя fzip, его архитектура отображена на диаграмме классов (полный размер):
- Реализации интерфейсов для чтения и записи архива работают в многопоточном режиме, также можно указать нужно ли использовать
java.nio.MappedByteBufferпри записи и чтении элементов архива (IFzipEntry) для их ускорения. - Для удобства чтения и записи элементов архива реализовали специальные каналы
EntryReadableChannelиEntryWritableChannelс возможностью валидации контрольной суммы элементов архива для определения целостности данных. Целостность данных определяем по CRC-32, вычисляя контрольную сумму с помощьюjava.util.zip.Adler32. - Архив может состоять из элементов нескольких типов:
- Директории (
DirectoryEntry) - Обычные файлы (
SimpleFileEntry) - Части большого файла (
PartialFileEntry) – разбиение крупных файлов нужно для более эффективного использования многопоточности
- Директории (
- Для доступа к элементам архива используем интерфейс
IFzipEntryRegistry. - В качестве оптимизации перемещения данных с одного канала в другой реализовали класс ChannelTransferSupport, который использует большой (1 Мб) прямой
ByteBuffer, избегая массовых аллокаций. Дело в том, чтоFileChannel#transferFrom(ReadableByteChannel, long, long)иFileChannel#transferTo(long, long, WritableByteChannel)из OpenJDK 11 аллоцируют новые, не прямыеByteBufferна каждый вызов, когда они вызываются из специальных «untrusted» каналов.ChannelTransferSupportже связывает каждый поток с одним прямымByteBuffer, что ускоряет работу по передачи данных между каналами. - Для сжатия данных используются классы
CompressWritableChannelиDecompressReadableChannel, данные классы могут использовать в себе следующие библиотеки для сжатия данных – Brotli, Deflate, ZStd.
Ускорение сжатия данных
Обычно для работы с ZIP-архивами в Java используется библиотека zlib с алгоритмом deflate. Это довольно старый алгоритм, предоставляющий хороший баланс между скоростью и степенью сжатия данных – именно поэтому его используют уже много лет.
Тем не менее мы нашли ещё два алгоритма сжатия, более новых, чем deflate:
Мы искали алгоритмы с хорошим балансом между скоростью и степенью сжатия данных. Поэтому мы отсеяли алгоритмы LZ4 и Snappy, имеющие высокую скорость, но невысокую степень сжатия (для нашей задачи). Также мы отсеяли алгоритм LZMA – из-за низкой скорости компрессии (ниже, чем у deflate).
Посмотрев на сравнение zstd и brotli, мы решили, что для нашей задачи оптимальным выбором будет zstd, потому что у него скорость записи выше, чем Brotli (хотя zstd и несколько проигрывает по степени сжатия brotli).
Для использования этого алгоритма мы выбрали библиотеку zstd-jni. На наш взгляд она имеет несколько недостатков: переусложненное и плохо адаптируемое API и использование finalize, многопоточность есть только на сжатие и при работе с обычными
java.io.OutputStream, при работе с ByteBuffer многопоточность не поддерживается, но библиотека весьма надежная. Её используют несколько крупных проектов – Hazelcast, Apache Spark, Presto.zstd-jni предоставляет возможность параллельного сжатия данных, что для нас немаловажно. Чтобы понять возможности библиотеки мы провели ряд экспериментов. Эксперименты показали, что если использовать однопоточную версию zstd-jni вместе с ранее сделанным нами распараллеливанием записи ZIP-архива на диск для алгоритма deflate, то результаты оказываются намного лучше, чем если использовать многопоточную версию zstd-jni, но производить запись данных в один поток. Видимо, это обусловлено тем, что операция ввода/вывода гораздо медленнее, чем операция сжатия данных. Поэтому, используя многопоточный вариант сжатия при записи файла в один поток, мы получили намного худший результат.
Читаем мы так:
Результаты
Как мы и ожидали, оптимизация получилась существенная.
Условия проведения тестов:
- Объем сжимаемых данных: 3 Гб
- Характеристики используемого оборудования:
- Процессор: Intel® Core(TM) i7-7700 CPU 3.60GHz, 8 логических ядра, в тестах использовали 4 из них
- Оперативная память: DDR3, 16 ГБ
- Жесткий диск: чтение/запись — 560 МБ/с / 520 МБ/с, интерфейс — SATA 6Gb/s
Результаты тестов:
- Deflate(zlib)
- Запись: 25 998 мс
- Чтение: 6 537 мс
- Размер архива: 1 064 МБ
- zstd
- Запись: 15 528 мс (быстрее на 40%)
- Чтение: 6 497 мс (идентично)
- Размер архива: 856 МБ (меньше на 20%)
Также мы провели сравнительные тесты полученной библиотеки с консольным приложением zstd. Консольный ZStd запускался на той же машине из-под Windows, проценты указаны по сравнению с однопоточным вариантом ZStd.
Надеемся, наш подход к ускорению сжатия и записи данных пригодится Java-разработчикам, решающим аналогичные задачи.
Почему гигабайты? Немного про 1C:Enterprise Development Tools и про 1С
Ну а теперь – почему перед нами встала эта задача.
Коротко: у нас есть IDE для разработки бизнес-приложений, создан на основе Eclipse, написан на Java. Называется 1С:Enterprise Development Tools (сокращённо EDT).
Исходники бизнес-приложений бывают большими, до нескольких гигабайт (зависит от функциональности бизнес-приложения). Помимо собственно исходников EDT создает некоторый объем служебной информации (размер её прямо пропорционален размеру проекта). Служебная информация нужна для комфортной работы – быстрой навигации по проекту, проверки кода по мере его написания и т.д.
Когда мы переключаемся между проектами нам нужно получить служебную информацию для проекта. Раньше мы перестраивали всю служебную информацию, но это занимало существенное время. В новой версии EDT при переключении между проектами мы сохраняем служебную информацию на диск, чтобы при возврате к проекту не пересчитывать её заново. Но даже сохранение и считывание нескольких гигабайт информации – процесс длительный.
Под катом – детали. Но главное мы уже сказали.
Детали
Для незнакомых с разработкой на 1С: разработка ведется на высокоуровневом языке, близком к предметной области бизнес-приложений (DSL, Domain Specific Language), что позволяет добиться высокой скорости разработки. Существуют порядка 20 встроенных типов объектов, и все новые объекты, которые разработчик создает, должны принадлежать к одному из этих типов. Большая часть этих типов описывают объекты из сферы учетной деятельности – справочники, документы, планы счетов и т.д. Другая часть типов объектов – технологические, например, Web- и HTTP-сервисы; они позволяют программам 1С общаться с внешним миром. Многое в разработке делается мышкой в мастерах (wizards), но есть и язык программирования, на котором можно писать код там, где нельзя обойтись свойствами объектов. Подробнее можно прочесть в этой статье, раздел «Язык приложений ERP».
Изначально разработка велась (и до сих пор ведется) в IDE Конфигуратор, написанном на С++. Но, как у многих легаси систем с длинной историей, у Конфигуратора есть ряд ограничений, преодолеть которые стоит очень дорого с точки зрения ресурсов, затраченных на разработку (невозможность написания плагинов, работа только с проприетарным хранилищем исходников и т.д.). Поэтому мы написали новую IDE, 1С:Enterprise Development Tools (EDT). EDT создан на основе свободной интегрированной среды разработки модульных кроссплатформенных приложений Eclipse, написан на Java.
Несмотря на концепцию LowCode, лежащую в основе разработки на 1С, серьезные бизнес-решения уровня ERP довольно внушительны по объему. Так, например, решение 1С:ERP Управление предприятием содержит:
Полный объем решения – 5 Гб.
А ещё, как было сказано выше, при загрузке проекта EDT создает служебную информацию для удобства разработчика – динамическая (по мере написания) проверка кода, быстрая навигация по проекту, Code completion и т.д.
Очень распространенный в разработке сценарий – переключение между разными ветками репозитория:
Иногда переключаться между ветками приходится несколько раз в день. При каждом переключении надо получить служебную информацию проекта. Благодаря новому механизму время переключения между ветками ускорилось примерно на порядок.
Изначально разработка велась (и до сих пор ведется) в IDE Конфигуратор, написанном на С++. Но, как у многих легаси систем с длинной историей, у Конфигуратора есть ряд ограничений, преодолеть которые стоит очень дорого с точки зрения ресурсов, затраченных на разработку (невозможность написания плагинов, работа только с проприетарным хранилищем исходников и т.д.). Поэтому мы написали новую IDE, 1С:Enterprise Development Tools (EDT). EDT создан на основе свободной интегрированной среды разработки модульных кроссплатформенных приложений Eclipse, написан на Java.
Несмотря на концепцию LowCode, лежащую в основе разработки на 1С, серьезные бизнес-решения уровня ERP довольно внушительны по объему. Так, например, решение 1С:ERP Управление предприятием содержит:
- 1 Гб программного кода
- 8 000 экранных форм
- 17 000 объектов метаданных
- 1 600 ролей безопасности
- 800 отчетов
Полный объем решения – 5 Гб.
А ещё, как было сказано выше, при загрузке проекта EDT создает служебную информацию для удобства разработчика – динамическая (по мере написания) проверка кода, быстрая навигация по проекту, Code completion и т.д.
Очень распространенный в разработке сценарий – переключение между разными ветками репозитория:
- Разработчик ведет разработку новой функциональности в отдельной ветке репозитория (отпочкованной от релизной ветки продукта).
- Разработчику присылают на фикс критичную ошибку, найденную на последнем релизе, и просят поправить её как можно скорее.
- Разработчику необходимо переключиться на релизную ветку и исправить ошибку.
- Разработчик возвращается к разработке новой функциональности в отдельной ветке репозитория.
Иногда переключаться между ветками приходится несколько раз в день. При каждом переключении надо получить служебную информацию проекта. Благодаря новому механизму время переключения между ветками ускорилось примерно на порядок.

{kind=link}