Люди встречаются, люди ссорятся, добавляются и удаляют друзей в социальных сетях. Этот пост о математике и алгоритмах, красивой теории, любви и ненависти в этом непостоянном мире. Этот пост о поиске компонент связности в динамических графах.
Большой мир генерирует большие данные. Вот и на нашу голову свалился большой граф. Настолько большой, что мы можем удержать в памяти его вершины, но не ребра. Кроме того, относительно графа приходят обновления – какое ребро добавить, какое удалить. Можно сказать, что каждое такое обновление мы видим в первый и последний раз. В таких условиях необходимо найти компоненты связности.
Поиск в глубину/ширину здесь не пройдут просто потому, что весь граф в памяти не удержать. Система непересекающихся множеств могла бы сильно помочь, если бы ребра в графе только добавлялись. Что же делать в общем случае?
Задача. Дан неориентированный граф
Решение задачи состоит из трех ингредиентов.
- Матрица инцидентности как представление.
- Метод стягивания как алгоритм.
-сэмплирование как оптимизация.
Реализацию можно посмотреть на гитхабе: link.
Матрица инцидентности как представление
Первая структура данных для хранения графа будет крайне неоптимальна. Мы возьмем матрицу инцидентности
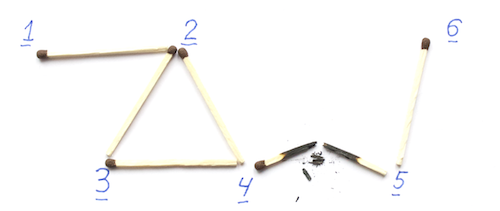
Как пример, посмотрим на граф на картинке ниже.

Для него матрица инцидентности будет выглядеть так.
Невооруженным глазом видно, что у такого представления есть серьезный недостаток – размер
Есть и неявное преимущество. Если взять множество вершин
Например, если взять множество
Ненулевые значения стоят у ребер
Стягивание графа как алгоритм
Поймем, что такое стягивание ребра. Вот есть у нас две вершины
Интересная особенность: в терминах матрицы инцидентности, чтобы стянуть ребро
Теперь алгоритм. Возьмем граф и для каждой неизолированной вершины выберем соседа.

Стянем соответствующие ребра.

Повторим итерацию

Заметим, что после каждой итерации стягивания компоненты связности нового графа взаимно-однозначно сопоставляются компонентам старого. Мы можем даже помечать, какие вершины были слиты в результирующие, чтобы потом восстановить ответ.
Заметим также, что после каждой итерации, любая компонента связности хотя бы из двух вершин уменьшается как минимум в два раза. Это естественно, поскольку в каждую вершину новой компоненты было слито как минимум две вершины старой. Значит, после
Переберем все изолированный вершины и по истории слияний восстановим ответ.
-сэмплирование как оптимизация
Все было бы замечательно, но приведенный алгоритм работает что по времени, что по памяти
От скетча потребуется три свойства.
Во-первых, компактность. Если мы строим скетч для вектора
Во-вторых, сэмплирование. На каждой итерации алгоритма, нам требуется выбирать соседа. Мы хотим способ получать индекс хотя бы одного ненулевого элемента, если такой есть.
В-третьих, линейность. Если мы построили для двух векторов
Мы воспользуемся решением задачи
Задача. Дан вектор нулевой вектор
1-разреженные вектор
Для начала мы решим более простую задачу. Пусть у нас есть гарантия, что конечный вектор содержит ровно одну ненулевую позицию. Будем говорить, что такой вектор – 1-разреженный. Будем поддерживать две переменных
Обозначим искомую позицию через
Можно вероятностно проверить, является ли вектор 1-разреженным. Для этого возьмем простое число
Очевидно, что если вектор действительно 1-разреженный, то
и тест он пройдет. В противном случае, вероятность пройти тест не более
Почему?
В терминах многочлена, вектор проходит тест, если значения полинома
%20%3D%20%5Csum_i%20a_i%20%5Ccdot%20z%5Ei%20-%20S_0%20%5Ccdot%20z%5E%7BS_1%20%2F%20S_0%7D)
в случайно выбронной точке равно нулю. Если вектор не является 1-разреженным, то
равно нулю. Если вектор не является 1-разреженным, то ) не является тождественно равным нулю. Если мы прошли тест, мы угадали корень. Максимальная степень полинома –
не является тождественно равным нулю. Если мы прошли тест, мы угадали корень. Максимальная степень полинома –  , значит, корней не более , значит, вероятность их угадать не более
, значит, корней не более , значит, вероятность их угадать не более  .
.
в случайно выбронной точке
Если мы хотим повысить точность проверки до произвольной вероятности
 -разреженный вектор
-разреженный вектор
Теперь попробуем решить задачу для
Возьмем случайную 2-независимую хэш-функцию
Подробнее про хэш-функции
В алгоритмах есть два принципиально разных подхода к хэш-функциям. Первый основывается на том, что данные более менее случайные, и наша любимая хэш-функция размешает их правильно. Второй, на том, что данные может подбирать злой противник, и единственный шанс спасти алгоритм от лишних вычислений и прочих проблем – это выбирать хэш-функцию случайно. Да, иногда может работать плохо, но зато мы можем померять, насколько плохо. Здесь идет речь о втором подходе.
Хэш-функция выбирается из семества функций. Например, если мы хотим размешать все числа от до
до  , можно взять случайные
, можно взять случайные  и
и  и определить хэш-функцию
и определить хэш-функцию
%20%3D%20a%20%5Ccdot%20x%20%2B%20b%20%5Ctext%7B%20mod%20%7D%20p.)
Функции для всех возможнных![a, b \in [p]](http://tex.s2cms.ru/svg/a%2C%20b%20%5Cin%20%5Bp%5D) задают семейство хэш-функций. Случайно выбрать хэщ-функцию – это по сути случайно выбрать те самые и . Выбираются они обычно равновероятно из множества
задают семейство хэш-функций. Случайно выбрать хэщ-функцию – это по сути случайно выбрать те самые и . Выбираются они обычно равновероятно из множества ![[p]](http://tex.s2cms.ru/svg/%5Bp%5D) .
.
Замечательное свойство у приведенного примера, что два любых различных ключа распределяются случайно независимо. Формально, для любых различных![x_1, x_2 \in [p]](http://tex.s2cms.ru/svg/x_1%2C%20x_2%20%5Cin%20%5Bp%5D) и любых, возможно одинаковых,
и любых, возможно одинаковых, ![y_1, y_2 \in [p]](http://tex.s2cms.ru/svg/y_1%2C%20y_2%20%5Cin%20%5Bp%5D) вероятность
вероятность
![\textbf{Pr}\left[ h(x_1) = y_1 \text{ and } h(x_2) = y_2 \right] = p^{-2}.](http://tex.s2cms.ru/svg/%5Ctextbf%7BPr%7D%5Cleft%5B%20h(x_1)%20%3D%20y_1%20%5Ctext%7B%20and%20%7D%20h(x_2)%20%3D%20y_2%20%5Cright%5D%20%3D%20p%5E%7B-2%7D.)
Такое свойство называется 2-независимостью. Иногда, вероятность может быть не , а
, а  , где
, где  какая-то разумно маленькая величина.
какая-то разумно маленькая величина.
Есть обобщение 2-независимости — -независимость. Это когда функция распределяет не 2, произвольных ключей независимо. Полиномиальные хэш-функции с случайными коэффициентами обладают таким свойством.
-независимость. Это когда функция распределяет не 2, произвольных ключей независимо. Полиномиальные хэш-функции с случайными коэффициентами обладают таким свойством.
%20%3D%20%5Csum_%7Bi%20%3D%200%7D%5E%7Bk%20-%201%7D%20a_i%20%5Ccdot%20x%5Ei%20%5Ctext%7B%20mod%20%7D%20p)
У-независимости есть одно неприятное свойство. С ростом функция занимает все больше памяти. Это свойство не зависит от какой-то конкретной реализации, а просто общее информационное свойство. Поэтому чем меньшей независимостью мы можем обойтись, тем легче на жить.
Хэш-функция выбирается из семества функций. Например, если мы хотим размешать все числа от
Функции для всех возможнных
Замечательное свойство у приведенного примера, что два любых различных ключа распределяются случайно независимо. Формально, для любых различных
Такое свойство называется 2-независимостью. Иногда, вероятность может быть не
Есть обобщение 2-независимости —
У
Возьмем хэш-таблицу размера
Можно посчитать, что для отдельной ячейки, вероятность что там произойдет коллизия хотя бы по двум ненулевым координатам будет не более
Почему?
Вероятность, что другой элемент не попадет в ячейку к нам ) . Вероятность, что все не попадут к нам:
. Вероятность, что все не попадут к нам: %5E%7Bs-%201%7D) . Вероятность, что хоть кто-нибудь попадет
. Вероятность, что хоть кто-нибудь попадет %5E%7Bs%20-%201%7D) . Можно заметить, что это функция монотонно возрастающая. Я здесь просто приведу картинку:
. Можно заметить, что это функция монотонно возрастающая. Я здесь просто приведу картинку:
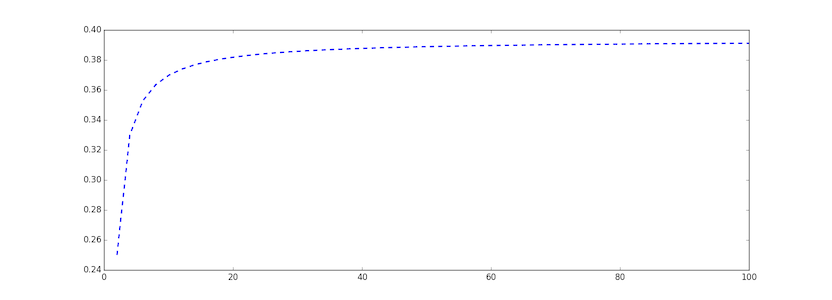
В пределе функция дает значение .
.

В пределе функция дает значение
Пусть мы хотим восстановить все координаты с вероятностью успеха

Итоговый алгоритм таков. Берем
Каждое обновление
По завершении, извлекаем из всех успешно отработавших 1-декодеров по координате и сливаем их в один список.
Максимум, в общей таблице будет
Еще одно хэширование для общего случая
Последний шаг в
Будем говорить, что обновление
Запустим алгоритм для
Найдем первый уровень с наибольшим
Есть несколько моментов, на которые хочется вкратце обратить внимание.
Во-первых, как выбирать
Это определяет выбор
Во-вторых, из
Итого, мы научились выбирать случайную ненулевую позицию согласно равномерному распределению.
Смешать, но не взбалтывать
Осталось понять, как все совместить. Нам известно, что в графе
При добавлении ребра
Когда ребра закончатся и нас спросят про компоненты, запустим алгоритм стягивания. На
Все. В конце просто проходим по изолированным вершинам, по истории слияний восстанавливаем ответ.
Кто виноват и еще раз что делать
На самом деле тема этого поста возникла не просто так. В январе к нам, в Питер в CS Клуб, приезжал Илья Разенштейн (@ilyaraz), аспирант MIT, и рассказывал про алгоритмы для больших данных. Было много интересного (посмотрите описание курса). В частности Илья успел рассказать первую половину этого алгоритма. Я решил довести дело до конца и рассказать весь результат на Хабре.
В целом, если вам интересна математика, связанная с вычислительными процессами aka Theoretical Computer Science, приходите к нам в Академический Университет на направление Computer Science. Внутри научат сложности, алгоритмам и дискретной математике. С первого семестра начнется настоящая наука. Можно выбираться наружу и слушать курсы в CS Клубе и CS Центре. Если вы не из Питера, есть общежитие. Прекрасный шанс переехать в Северную Столицу.
Подавайте заявку, готовьтесь и поступайте к нам.
