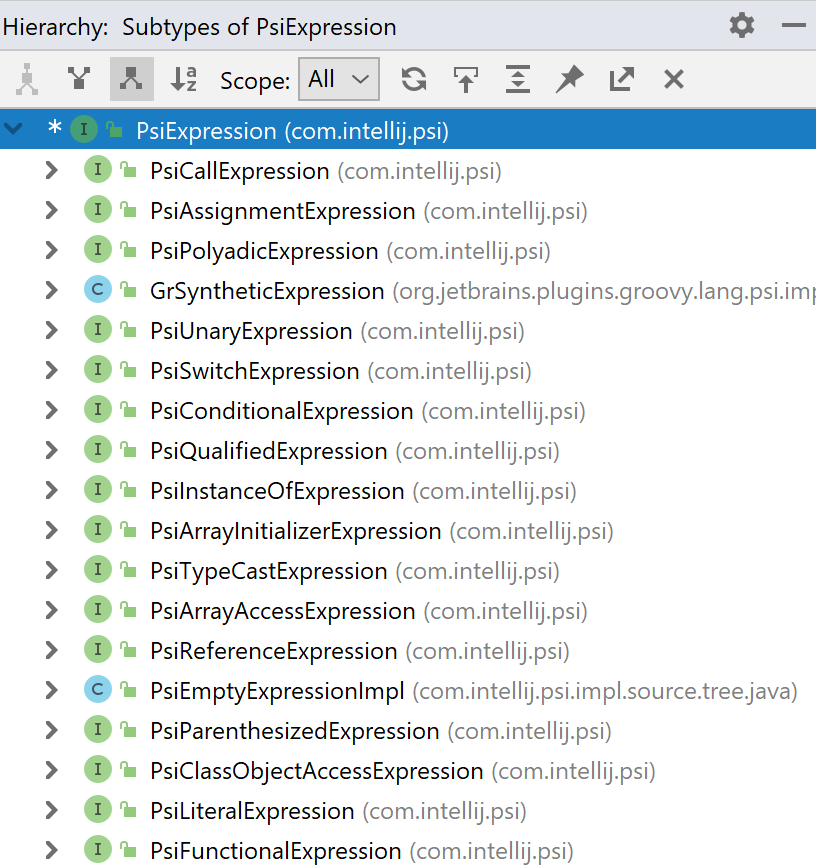
 Code search and navigation are important features of any IDE. In Java, one of the commonly used search options is searching for all implementations of an interface. This feature is often called Type Hierarchy, and it looks just like the image on the right.
Code search and navigation are important features of any IDE. In Java, one of the commonly used search options is searching for all implementations of an interface. This feature is often called Type Hierarchy, and it looks just like the image on the right.
It's inefficient to iterate over all project classes when this feature is invoked. One option is to save the complete class hierarchy in the index during compilation since the compiler builds it anyway. We do this when the compilation is run by the IDE and not delegated, for example, to Gradle. But this works only if nothing has been changed in the module after the compilation. In general, the source code is the most up-to-date information provider, and indexes are based on the source code.
Finding immediate children is a simple task if we are not dealing with a functional interface. When searching for implementations of the Foo interface, we need to find all the classes that have implements Foo and interfaces that have extends Foo, as well as new Foo(...) {...} anonymous classes. To do this, it is enough to build a syntax tree of each project file in advance, find the corresponding constructs, and add them to an index. There is, however, an intricacy here: you might be looking for the com.example.goodcompany.Foo interface, while org.example.evilcompany.Foo is actually used. Can we put the full name of the parent interface into the index in advance? It can be tricky. For example, the file where the interface is used may look like this:
// MyFoo.java
import org.example.foo.*;
import org.example.bar.*;
import org.example.evilcompany.*;
class MyFoo implements Foo {...}By looking at the file alone, it's impossible to tell what the actual fully qualified name of Foo is. We'll have to look into the content of several packages. And each package can be defined in several places in the project (for example, in several JAR files). If we perform proper symbol resolution when analyzing this file, indexing will take a lot of time. But the main problem is that the index built on MyFoo.java will depend on other files as well. We can move the declaration of the Foo interface, for example, from the org.example.foo package to the org.example.bar package, without changing anything in the MyFoo.java file, but the fully qualified name of Foo will change.
In IntelliJ IDEA, indexes depend only on the content of a single file. On the one hand, it is very convenient: the index associated with a specific file becomes invalid when the file is changed. On the other hand, it imposes major restrictions on what can be put into the index. For example, it does not allow the fully qualified names of parent classes to be saved reliably in the index. But, in general, it's not that bad. When requesting a type hierarchy, we can find everything that matches our request by a short name, and then perform the proper symbol resolution for these files and determine whether that's what we are looking for. In most cases, there won't be too many redundant symbols and the check won't take long.
 Things change, however, when the class whose children we are looking for is a functional interface. Then, in addition to the explicit and anonymous subclasses, there'll be lambda expressions and method references. What do we put into the index now, and what is to be evaluated during the search?
Things change, however, when the class whose children we are looking for is a functional interface. Then, in addition to the explicit and anonymous subclasses, there'll be lambda expressions and method references. What do we put into the index now, and what is to be evaluated during the search?
Let's assume we have a functional interface:
@FunctionalInterface
public interface StringConsumer {
void consume(String s);
}The code contains different lambda expressions. For instance:
() -> {} // a certain mismatch: no parameters
(a, b) -> a + b // a certain mismatch: two parameters
s -> {
return list.add(s); // a certain mismatch: a value is returned
}
s -> list.add(s); // a potential matchIt means we can quickly filter out lambdas that have an inappropriate number of parameters or a clearly inappropriate return type, for example, void instead of non-void. It is usually impossible to determine the return type more precisely. For instance, in s -> list.add(s) you will have to resolve list and add, and, possibly, run a regular type inference procedure. It takes time and depends on the content of other files.
We’re lucky if the functional interface takes five arguments. But if it only takes one, the filter will keep a huge number of unnecessary lambdas. It's even worse when it gets to method references. By the way it looks, one cannot tell whether a method reference is suitable or not.
To get things straight, it might be worth looking at what surrounds the lambda. Sometimes, it works. For instance:
// declaration of a local variable or a field of different type
Predicate<String> p = s -> list.add(s);
// a different return type
IntPredicate getPredicate() {
return s -> list.add(s);
}
// assignment to a variable of a different type
SomeType fn;
fn = s -> list.add(s);
// cast to a different type
foo((SomeFunctionalType)(s -> list.add(s)));
// declaration of a different type array
Foo[] myLambdas = {s -> list.add(s), s -> list.remove(s)};In all these cases, the short name of the corresponding functional interface can be determined from the current file and can be put into the index next to the functional expression, be it a lambda or a method reference. Unfortunately, in real-life projects, these cases cover a very small percentage of all lambdas. In most cases, lambdas are used as method arguments:
list.stream()
.filter(s -> StringUtil.isNonEmpty(s))
.map(s -> s.trim())
.forEach(s -> list.add(s));Which of the three lambdas can contain StringConsumer? Obviously, none. Here we have a Stream API chain that only features functional interfaces from the standard library, it can't have the custom type.
However, the IDE should be able to see through the trick and give us an exact answer. What if list is not exactly java.util.List, and list.stream() returns something different from java.util.stream.Stream? Then we'll have to resolve list, which, as we know, cannot be reliably done based only on the content of the current file. And even if we do, the search should not rely on the implementation of the standard library. What if in this particular project we have replaced java.util.List with a class of our own? The search must take this into account. And, naturally, lambdas are used not only in standard streams: there are many other methods to which they are passed.
As a result, we can query the index for a list of all Java files that use lambdas with the required number of parameters and a valid return type (in fact, we only search for four options: void, non-void, boolean, and any). And what's next? Do we need to build a complete PSI tree (a kind of a parse tree with symbol resolution, type inference, and other smart features) for each of these files and perform proper type inference for lambdas? For a big project, it will take ages to get the list of all interface implementations, even if there are only two of them.
So, we need to take the following steps:
- Ask index (not costly)
- Build PSI (costly)
- Infer lambda type (very costly)
For Java 8 and later, type inference is an extremely costly operation. In a complex call chain, there might be many substitutional generic parameters, the values of which have to be determined using the hard-hitting procedure described in Chapter 18 of the specification. For the current file, this can be done in the background, but processing thousands of unopened files this way would be an expensive task.
Here, however, it is possible to slightly cut corners: in most cases, we don’t need the concrete type. Unless a method accepts a generic parameter where the lambda is passed to it, the final parameter substitution step can be avoided. If we have inferred the java.util.function.Function<T, R> lambda type, we don't have to evaluate the values of the substitutional parameters T and R: it is already clear whether to include the lambda into search results or not. However, it won't work for a method like this:
static <T> void doSmth(Class<T> aClass, T value) {}This method can be called with doSmth(Runnable.class, () -> {}). Then the lambda type will be inferred as T, substitution still required. However, this is a rare case. We can actually save some CPU time here, but only about 10%, so this doesn't solve the problem in its essence.
Alternatively, when the precise type inference is too complicated, it can be made approximate. Unlike the specification suggests, let it work only on the erased class types and make no reduction of the set of constraints, but simply follow a call chain. As long as the erased type does not include generic parameters, everything is fine. Let's consider the stream from the example above and determine whether the last lambda implements StringConsumer:
listvariable →java.util.ListtypeList.stream()method →java.util.stream.StreamtypeStream.filter(...)method →java.util.stream.Streamtype, we don't have to considerfilterarguments- similarly,
Stream.map(...)method →java.util.stream.Streamtype Stream.forEach(...)method → such a method exists, its parameter hasConsumertype, which is obviously notStringConsumer.
And that's how we could do without regular type inference. With this simple approach, however, it is easy to run into overloaded methods. If we do not perform proper type inference, we cannot choose the correct overloaded method. Sometimes it's possible, however: if methods have a different number of parameters. For example:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));Here we can see that:
- There are two
CompletableFuture.supplyAsyncmethods; the first one takes one argument and the second takes two, so we choose the second one. It returnsCompletableFuture. - There are two
thenRunAsyncmethods as well, and we can similarly choose the one that takes one argument. The corresponding parameter hasRunnabletype, which means it is notStringConsumer.
If several methods take the same number of parameters or have a variable number of parameters but look appropriate, we'll have to search through all the options. Often it's not that scary:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));new StringBuilder()obviously createsjava.lang.StringBuilder. For constructors, we still resolve the reference, but complex type inference is not required here. Even if there wasnew Foo<>(x, y, z), we would not infer the values of the type parameters since onlyFoois of interest to us.- There are a lot of
StringBuilder.appendmethods that take one argument, but they all returnjava.lang.StringBuildertype, so we do not care about the types offooandbar. - There's one
StringBuilder.charsmethod, and it returnsjava.util.stream.IntStream. - There's a single
IntStream.forEachmethod, and it takesIntConsumertype.
Even if several options remain, you can still track them all. For example, the lambda type passed to ForkJoinPool.getInstance().submit(...) may be Runnable or Callable, and if we are looking for another option, we can still discard this lambda.
Things get worse when the method returns a generic parameter. Then the procedure fails and you have to perform proper type inference. However, we have supported one case. It is well showcased in my StreamEx library, which has an AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> abstract class which contains methods like S filter(Predicate<? super T> predicate). Usually people work with a concrete StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> class. In this case, you can substitute the type parameter and find out that S = StreamEx.
That's how we've got rid of the costly type inference for many cases. But we haven't done anything with the construction of PSI. It's disappointing to have parsed a file with 500 lines of code only to find out that the lambda on line 480 does not match our query. Let's get back to our stream:
list.stream()
.filter(s -> StringUtil.isNonEmpty(s))
.map(s -> s.trim())
.forEach(s -> list.add(s));If list is a local variable, a method parameter, or a field in the current class, already at the indexing stage, we can find its declaration and establish that the short type name is List. Accordingly, we can put the following information into the index for the last lambda:
This lambda type is a parameter type of aforEachmethod which takes one argument, called on the result of amapmethod which takes one argument, called on the result of afiltermethod which takes one argument, called on the result of astreammethod which takes zero arguments, called on aListobject.
All this information is available from the current file and, therefore, can be placed in the index. While searching, we request such information about all lambdas from the index and try to restore the lambda type without building a PSI. First, we'll have to perform a global search for classes with the short List name. Obviously, we will find not only java.util.List but also java.awt.List or something from the project code. Next, all these classes will go through the same approximate type inference procedure that we used before. Redundant classes are often quickly filtered out. For example, java.awt.List has no stream method, therefore it will be excluded. But even if something redundant remains and we find several candidates for the lambda type, chances are none of them will match the search query, and we will still avoid building a complete PSI.
Global search could turn out to be too costly (when a project contains too many List classes), or the beginning of the chain could not be resolved in the context of one file (say, it's a field of а parent class), or the chain could break as the method returns a generic parameter. We won't give up and will try to start over with global search on the next method of the chain. For example, for the map.get(key).updateAndGet(a -> a * 2) chain, the following instruction goes to the index:
This lambda type is the type of the single parameter of anupdateAndGetmethod, called on the result of agetmethod with one parameter, called on aMapobject.
Imagine we're lucky, and the project has only one Map type—java.util.Map. It does have a get(Object) method, but, unfortunately, it returns a generic parameter V. Then we'll discard the chain and look for the updateAndGet method with one parameter globally (using the index, of course). And we are happy to discover that there are only three such methods in the project: in AtomicInteger, AtomicLong, and AtomicReference classes with parameter types IntUnaryOperator, LongUnaryOperator, and UnaryOperator, respectively. If we are looking for any other type, we have already discovered that this lambda does not match the request, and we don't have to build the PSI.
Surprisingly, this is a good example of a feature which works slower with time. For example, when you are looking for implementations of a functional interface and have only three of them in your project, it takes ten seconds for IntelliJ IDEA to find them. You remember that three years ago their number was the same, but the IDE provided you with the search results in just two seconds on the same machine. And though your project is huge, it has grown only by five percent over these years. It's reasonable to start grumbling about what the IDE developers have done wrong to make it so terribly slow.
While we might have changed nothing at all. The search works just as it used to three years ago. The thing is that three years ago, you just switched to Java 8 and only had a hundred lambdas in your project. By now, your colleagues have turned anonymous classes into lambdas, have started using streams or some reactive library. As a result, instead of a hundred lambdas, there are ten thousand. And now, to find the three necessary ones, the IDE has to search through a hundred times more options.
I said “we might” because, naturally, we get back to this search from time to time and try speeding it up. But it's like rowing up the stream, or rather up the waterfall. We try hard, but the number of lambdas in projects keeps growing very fast.
