Comments 95
Enumerable#pluck возвращает коллекцию, содержащую значения, выбранные из исходной коллекции по указанному ключу — хорошая, полезная штука. Проблема в том, что этот метод сам по себе не решает никакой практической задачи.
Можно поподробнее, почему наличие этого метода в Enumerable плохо? Я не Ruby разработчик и могу быть далек от реалий Rails, но мне казалось, что наличие удобных методов для работы с коллекциями — это всегда хорошо.
Потому что другая библиотека тоже может добавить такой метод, и если сигнатуры будут отличаться — то случится ой. Они же его не локально для себя добавляют, а для всех тех сотен гемов, которые в зависимостях.
То есть вы (автор) предлагаете не расширять функционал потому что это может сломать совместимости со сторонними библиотеками?
Я не автор, я переводчик. Автор, судя по всему, предлагает расширять функционал без добавления методов в базовые классы и без модификации поведения «на лету» (monkey-patch).
Вот к чему приводит бездумное расширение функционала базовых классов:
Просто задумайтесь, что здесь произошло.
> require 'active_record'
=> true
> {a:1, b:2}.sum
=> [:a, 1, :b, 2]
Просто задумайтесь, что здесь произошло.
Я только-только начинаю интересоваться руби, расскажите что не так? Насколько я понимаю произошло преобразование из хэша в массив, как методом .to_a?
Произошло много чего внутри рельсы, чего не должно происходить, о чем можно только догадываться, или идти разбираться в дебрях их кода. Если смотреть на результат, то они вам в приложение всем объектам всех классов, которые наследуются от Hash (или ещё от чего-то, если #sum у хеша тоже наследуется), добавили неработающий метод #sum. По идее, от этого волосы должны встать дыбом. Такое загрязнение namespace очень напоминает практики PHP4. Объяснить, почему это плохо и к чему это ведёт, поможет хороший ВУЗ или многолетний опыт программирования.
У меня мало опыта с руби, но сразу вспомнился prototype.js, который пошёл тем же путём, расширяя стандартные JavaScript-объекты типа Array. Когда-то он был популярен, а jQuery только набирался сил. По-моему, многие отказывались от prototype.js в основном потому, что он начал в неожиданных местах ломать другой сторонний код, который никак не подозревал, что в его внутренних объектах что-то новое появилось.
Использование правильных версий библиотек друг с другом никто не отменял. Bundler нам на это в помощь.
Вышла новая версия? Куда-то добавили новый функционал? Остальные библиотеки должны быть адаптированы, чтобы работать вместе. Или использовать связку старых версий. Так было всегда, даже когда библиотеки были «черными ящиками».
Вот представим — через некоторое время такой же метод добавят уже не в Rails, а в сам Ruby. И что?
Вышла новая версия? Куда-то добавили новый функционал? Остальные библиотеки должны быть адаптированы, чтобы работать вместе. Или использовать связку старых версий. Так было всегда, даже когда библиотеки были «черными ящиками».
Вот представим — через некоторое время такой же метод добавят уже не в Rails, а в сам Ruby. И что?
Суть критики в том, что фрэймворк (библиотека) изменяет базовые классы языка (платформы), на котором он написан. Добавление метода как такового не страшно, страшно, что посредством monkey patching может и подменить метод (как показано в комментарии выше). А это сломает другие библиотеки, полагающиеся на этот базовый метод.
Разработчики сторонних библиотек могут вообще не знать про Rails и уж точно не должны адаптировать свои творения под подобные патчи. Да и разве за всем уследишь?
Разработчики сторонних библиотек могут вообще не знать про Rails и уж точно не должны адаптировать свои творения под подобные патчи. Да и разве за всем уследишь?
Этот метод хорошо смотрится в той библиотеке, в которой вводится Enumerable — или в единственной библиотеке, расширяющей Enumerable.
Но не в библиотеке для обработки HTTP-запросов.
Но не в библиотеке для обработки HTTP-запросов.
Я как разработчик со стороны, воспринимаю Ruby достаточно позитивно. Просто нужно понимать, какая цель у языка, а все очень просто. Это язык ориентированный на очень быстрый старт проектов, т.к. время это деньги и многие проекты умирают так не закончившись, то у проекта на руби намного больше шансов быть законченным в короткий срок. Сделанный проект имеет больше шансов выстрелить, чем проект который колупается долгое время, но в коде у него все хорошо, только прибыли он не приносит.
Проблема то не в руби, а в рельсах, которые популяризировали плохие способы решения задач(monkey patch, ActiveRecord). Писать не rails way не значит писать медленно.
А чем плох эктиврекорд? Как паттерн конечно же, а не как рубишный гем.
Паттерн ActiveRecord плохо подходит для приложений с развитой бизнес логикой, коих на самом деле большинство. А плох он, потому что смешивает две ответственности воедино:
Что ведет к таким последствиям:
- работу с базой данных(получение, обновление данных)
- отображение записи из таблицы на объект
Что ведет к таким последствиям:
- Бизнес логика смешивается с работой с базой, что усложняет поддержу кода
- Доступ к полям объекта может приводить к запросам к бд и вы можете долго этого не замечать.
- Невозможно полностью абстрагироваться от БД. Это, например, ведет к тому что нельзя писать быстрые тесты. К примеру в паттерне Data Mapper эти две ответственности отделены на сущности(отображение данных из бд на объект) и репозитории(доступ к бд). Используя data mapper я могу написать альтернативную реализацию репозиториев, которые будут работать без доступа к БД(in memory repositories). Не обращаясь к БД тесты будут проходить мгновенно. А чтобы быть уверенным, что приложение работает и с реальными репозиториями, я покрою репозитории отдельными тестами, которые будут поочередно прогонять тесты для двух реализаций(реальной и той что работают без доступа к бд).
Вообще можно долго писать к чему приводит использование ActiveRecord, об этом много написано. Но действительно понять, что лучше его не использовать можно лишь попробовав его не использовать:)
Дзен-комментарий. Я согласен и по сути, но форма тут просто прекрасна!
Есть разные задачи, и для каких-то подходит Active Record, а для каких-то Data Mapper.
Можно пример задач, для которых идеально подходит Active Record и категорически не подходит Data Mapper?
Разве я употреблял слова «идеально» и «категорически»?
Пускай будет «лучше» и «хуже».
Например, AR лучше подходит для случаев, когда доменная модель соответствует структуре базы данных.
Использование встраиваемых СУБД (SQLite к примеру). Особенность этих СУБД заключаются в том, что затраты на передачу данных по сети отсутствуют — а значит, большая серия мелких запросов может даже выиграть по времени у запроса крупного. В итоге причина номер 2 из списка выше исчезает.
Пункты же 1 и 3 не всегда являются критическими недостатками — иногда стоимость разработки важнее стоимости поддержки.
таким образом, областями, где AR однозначно выигрывает у DM, являются (как минимум) небольшие write-only утилиты, работающие со встраиваемой СУБД.
Пункты же 1 и 3 не всегда являются критическими недостатками — иногда стоимость разработки важнее стоимости поддержки.
таким образом, областями, где AR однозначно выигрывает у DM, являются (как минимум) небольшие write-only утилиты, работающие со встраиваемой СУБД.
Чисто теоретически у него два недостатка:
— две ответственности (пускай и хорошо разделенных, с низкой связностью по умолчанию): доступ к данным в БД и бизнес-логика
— точное повторение структуры базы данных
На практике второй недостаток обычно не замечают даже, пока не приходит пора оптимизировать не запросы, а схему, а даже если замечают, то считают само собой разумеющимся, что глобальный рефакторинг схемы базы данных приводит к глобальному рефакторингу бизнес-логики, потому что мозги так заточены (давеча общаясь с одним из наших джунов, выяснил, что им прямо сейчас преподают в вузе проектирование от данных как основной способ разработки — «продумайте какие данные есть по задаче, как их лучше хранить (по умолчанию SQL-база, причём нормализованная до упора), создайте схему, а уж потом пишите код)». То есть второй недостаток многие вообще не замечают.
Первый же недостаток намного фатальнее на практике. При реализации бизнес-логики очень многие разработчики начинают смешивать её с логикой хранения, причём руководствуясь вроде лучшими (вернее некоторыми из лучших) практиками ООП и модульной разработки — сокрытие деталей реализации, уменьшение дублирование кода и т. п., — руководствуясь соображениями вроде «это же один объект, значит я могу из любого его метода вызывать любой его метод», «каждый раз после вызова этого метода, сильно изменяющего состояние объекта, я буду вызывать метод сохранения в базе данных, поэтому я его туда и включу», «в данных бизнес-кейсах мне не нужен полный граф зависимостей, но в каждом нужны разные зависимости, значит не буду нагружать базу лишними запросами, с одной стороны, а с другой, не буду выносить наружу знания о том, в каком кейсе какие зависимости нужны, а инкапсулирую их — это же один объект, или хотя бы слой — модель» (отнесение к модели в MVC логики хранения — ещё одна частая ошибка)и т. п. В результате объект получается с сильной связностью логики хранения и бизнес-логики.
— две ответственности (пускай и хорошо разделенных, с низкой связностью по умолчанию): доступ к данным в БД и бизнес-логика
— точное повторение структуры базы данных
На практике второй недостаток обычно не замечают даже, пока не приходит пора оптимизировать не запросы, а схему, а даже если замечают, то считают само собой разумеющимся, что глобальный рефакторинг схемы базы данных приводит к глобальному рефакторингу бизнес-логики, потому что мозги так заточены (давеча общаясь с одним из наших джунов, выяснил, что им прямо сейчас преподают в вузе проектирование от данных как основной способ разработки — «продумайте какие данные есть по задаче, как их лучше хранить (по умолчанию SQL-база, причём нормализованная до упора), создайте схему, а уж потом пишите код)». То есть второй недостаток многие вообще не замечают.
Первый же недостаток намного фатальнее на практике. При реализации бизнес-логики очень многие разработчики начинают смешивать её с логикой хранения, причём руководствуясь вроде лучшими (вернее некоторыми из лучших) практиками ООП и модульной разработки — сокрытие деталей реализации, уменьшение дублирование кода и т. п., — руководствуясь соображениями вроде «это же один объект, значит я могу из любого его метода вызывать любой его метод», «каждый раз после вызова этого метода, сильно изменяющего состояние объекта, я буду вызывать метод сохранения в базе данных, поэтому я его туда и включу», «в данных бизнес-кейсах мне не нужен полный граф зависимостей, но в каждом нужны разные зависимости, значит не буду нагружать базу лишними запросами, с одной стороны, а с другой, не буду выносить наружу знания о том, в каком кейсе какие зависимости нужны, а инкапсулирую их — это же один объект, или хотя бы слой — модель» (отнесение к модели в MVC логики хранения — ещё одна частая ошибка)и т. п. В результате объект получается с сильной связностью логики хранения и бизнес-логики.
«продумайте какие данные есть по задаче, как их лучше хранить [...], создайте схему, а уж потом пишите код)»
У меня видимо мозги уже тоже «заточены». Как нужно правильно?
Разделить бизнес-задачу и задачу доступа к хранилищу данных. Проще говоря, писать код модели (если говорить о МВЦ и ко), минимально думая о том в какой таблице, что хранится. Бизнес-код в идеале ничего не должен знать о том, что данные вообще где-то хранятся, кроме графа объектов в памяти. Когда бизнес-код получает управление, то он должен оперировать только обычными объектами в памяти, нужные ему объекты из хранилища должны быть либо загружены заранее, либо обеспечена ленивая прозрачная загрузка, создаваемые им объекты (непосредственно или через фабрики) он должен либо возвращать как обычные объекты, либо помещать в обычные свойства или коллекции, ничего не зная о том, что их нужно сохранить. Только после возврата управления от бизнес-кода, нужно начинать думать о сохранении. Если говорить о паттернах типа ActiveObject, то в них недопустимо в одном методе реализовывать бизнес-логику и обращения к БД. Любое обращение к БД или их последовательность, если без него никак не обойтись, должно быть заключено как минимум в отдельный метод. Если это метод сохранения/изменения данных в БД, то крайне желательно вызывать его не напрямую из бизнес-кода, а путем событий типа «моё свойство такое-то изменилось» или «я добавил новый объект в коллекцию такую-то» (или хотя бы чего-то выглядящего как такие события, псукай это банальное переименование «saveAll», выполняющего в цликле save по каждому элменту коллекциии в «onAllChanged»).
Любой рефакторинг схемы БД делается ради оптимизации времени выполнения запросов — но при такой оптимизации главным объектом оптимизации являются сами запросы к БД. Изменение схемы БД — это не причина изменения бизнес-логики, а ее следствие.
Не только. Ещё, например, для ускорения внедрения новых фич, пускай и ценой падения производительности на старых
Зависит от чего пляшем при проектировании. Если сначала рисуем (пускай даже в уме) таблицы и столбцы, потом привязываем к ним жестко бизнес-логику (как это делает активикс), то из необходимости рефакторинга схемы (напрмиер для увеличеняи сокрости выполнения запросов или горизонтального масштабирвоания для надежности), следует необходимость рефакторинга бизнес-логики. Обратное тоже верно, но случаи бывают разные, необходимость может возникнуть с любой стороны жесткой связи, даже если это банальное переименование поля объекта или столбца таблицы.
Зависит от чего пляшем при проектировании. Если сначала рисуем (пускай даже в уме) таблицы и столбцы, потом привязываем к ним жестко бизнес-логику (как это делает активикс), то из необходимости рефакторинга схемы (напрмиер для увеличеняи сокрости выполнения запросов или горизонтального масштабирвоания для надежности), следует необходимость рефакторинга бизнес-логики. Обратное тоже верно, но случаи бывают разные, необходимость может возникнуть с любой стороны жесткой связи, даже если это банальное переименование поля объекта или столбца таблицы.
UFO just landed and posted this here
Недословная цитата из «Clean Coder» Uncle Bob'а:
Если конечно это не какой нибудь одноразовый сайт, который пишется за две недели, выполняет свою задачу и идет в /dev/null
Doing mess is not fast
Если конечно это не какой нибудь одноразовый сайт, который пишется за две недели, выполняет свою задачу и идет в /dev/null
Я знаю, что в корпоративном сегменте пишутся монстры годами на других языках, я также не лучшего впечатления о таких проектах, потому что они часто закрываются или не заканчиваются. Там бардака с годами накапливается не меньше.
Бардака там конечно тоже хватает. Но в руби сообществе проблема в том, что Rails — это стандарт де факто. Люди просто не знают, что можно писать под другому. Этому почти никто не учит в руби. Если же сравнивать с той же явой, то здесь есть именитые разработчики(Martin Fowler, Robert Martin, ...) которые пропагандируют как писать действительно правильно
На руби тоже можно писать правильно конечно же. Мартин тоже пропагандирует)
Выступление старенькое но актуальности не потеряло Keynote: Architecture the Lost Years by Robert Martin
Выступление старенькое но актуальности не потеряло Keynote: Architecture the Lost Years by Robert Martin
А теперь представьте, что было бы, если бы в корпоративном сегменте был бы манкипатчинг)
Согласен с автором. Но есть еще большая проблема. Использование monkey patch и ActiveRecord, ведут к тому, что разрабатывая на рельсах решаешь задачи не как «написать правильно», а как «написать на рельсах правильно”.
Такой разработчик, придя в другой язык, вынужден начинать все с нуля, потому что то, что он применял в рельсах уже совсем не подходит под новый язык/платформу.
В новом языке нет AсtiveRecord, а приложение разрабатывают не на фреймворке, а строят архитектуру для приложения используя фреймворк. Годы опыта потраченные на изучение рельс будут потрачены зря.
Такой разработчик, придя в другой язык, вынужден начинать все с нуля, потому что то, что он применял в рельсах уже совсем не подходит под новый язык/платформу.
В новом языке нет AсtiveRecord, а приложение разрабатывают не на фреймворке, а строят архитектуру для приложения используя фреймворк. Годы опыта потраченные на изучение рельс будут потрачены зря.
а как «написать на рельсах правильно”
По мне так очень много задач — как написать костыль, чтобы gem1, gem2, ..., gemN хотя бы работали вместе и о «как написать на рельсах правильно» уже речи и не идет. Попробуйте в том же active admin сделать что то посложнее, чем обычный CRUD с примитивными полями. И манкипатчинг играет в причинах этому не последнюю роль)
Проблема monkey patching в Ruby решена при помщи refinements.
Как думаете, refinements спасут данную ситуацию или станет только хуже?
Я некомпетентен в этом вопросе, с Ruby знаком поверхностно. Полагаю, всё зависит от того, в какой степени в Rails они перейдут на использование refinements. Если целиком, то данная проблема будет решена.
Ну и тут еще надо отдавать себе отчет, что статья весьма паническая. В мире Ruby всё не так плохо, как из нее может показаться. И Rails — это потрясающий инструмент, позволяющий решать задачи со скоростью и удобством, недоступными другим языкам и их фрэймворкам.
Проблемы есть у любого решения. Идеала не существует, и у любой монеты есть обратная сторона. Подумайте, чего вы лишаетесь, отказываясь от Rails, и стоит ли оно того. В большинстве случаев может оказаться, что не стоит.
А Rails никуда не денется. Не умрет. Да, его hype прошел, и все сейчас дрочат на Node и новомодные языки вроде Elixir, Crystal, Nim… Но вот Node уже сколько лет, по меркам вэб-индустрии он уже далеко не новичок. И где удобные, продуманные решения на Node? Где фрэймворк, который хоть немножко может сравниться с Rails по проработке типичных задач? Я тут глянул Sails и Loopback из интереса и обнаружил, что ни в том, ни в другом нет миграций БД. Что за детский сад?
Ну и тут еще надо отдавать себе отчет, что статья весьма паническая. В мире Ruby всё не так плохо, как из нее может показаться. И Rails — это потрясающий инструмент, позволяющий решать задачи со скоростью и удобством, недоступными другим языкам и их фрэймворкам.
Проблемы есть у любого решения. Идеала не существует, и у любой монеты есть обратная сторона. Подумайте, чего вы лишаетесь, отказываясь от Rails, и стоит ли оно того. В большинстве случаев может оказаться, что не стоит.
А Rails никуда не денется. Не умрет. Да, его hype прошел, и все сейчас дрочат на Node и новомодные языки вроде Elixir, Crystal, Nim… Но вот Node уже сколько лет, по меркам вэб-индустрии он уже далеко не новичок. И где удобные, продуманные решения на Node? Где фрэймворк, который хоть немножко может сравниться с Rails по проработке типичных задач? Я тут глянул Sails и Loopback из интереса и обнаружил, что ни в том, ни в другом нет миграций БД. Что за детский сад?
Простите, я все слова понял, но смысл одного предложения от меня ускользает: «Я тут глянул Sails и Loopback из интереса и обнаружил, что ни в том, ни в другом нет миграций БД».
Я в Sails и Loopback вообще не заглядывал, но как JS фреймворки должны быть связаны с миграцией БД??
Я в Sails и Loopback вообще не заглядывал, но как JS фреймворки должны быть связаны с миграцией БД??
Я (фронтендщик) в одной компании столкнулся с тем, как SQL-сниппеты миграций пересылались по скайпу, и созвоны для сопоставления структуры БД между разработчиками были рутиной.
Будучи привыкшим к хорошему в Rails, я был повергнут в шок такой практикой. И это был далеко не единственный изъян их workflow и кодовой базы. Просто один из множества.
Так что можно сказать, что поискав миграции в фичах фрэймворка, я заглянул в зубы коню. Если зубов нет, то остальной конь тоже, скорее всего, не очень. ;)
Будучи привыкшим к хорошему в Rails, я был повергнут в шок такой практикой. И это был далеко не единственный изъян их workflow и кодовой базы. Просто один из множества.
Так что можно сказать, что поискав миграции в фичах фрэймворка, я заглянул в зубы коню. Если зубов нет, то остальной конь тоже, скорее всего, не очень. ;)
Когда я слышу «миграция БД», для меня это с различной степенью вероятности может означать:
1) Смена архитектуры SQL <-> NoSQL.
2) Смена системы: MySQL <-> Oracle
3) Смена движка: MyISAM <-> InnoDB
4) Смена мажорной версии системы: MSSQL 2008 > MSSQL 2012
5) Смена железа: апгрейд, или смена между физическим-облачным сервером.
И никак я не могу понять как, и главное зачем чем-либо из этого заниматься JS фреймворку?
1) Смена архитектуры SQL <-> NoSQL.
2) Смена системы: MySQL <-> Oracle
3) Смена движка: MyISAM <-> InnoDB
4) Смена мажорной версии системы: MSSQL 2008 > MSSQL 2012
5) Смена железа: апгрейд, или смена между физическим-облачным сервером.
И никак я не могу понять как, и главное зачем чем-либо из этого заниматься JS фреймворку?
Редактирование структуры БД?
Глянул в Rails (секунд 40). «Если не хватает AR хелперов пользуйте чистый коннектор и синтаксис БД» Я в AR даже foreignkey пока не увидел… Подозреваю что можно сэкономить кучу времени вообще не изучая нового синтаксиса, используя родной синтаксис БД через коннектор.
Я к тому что это «фича» вне зависимости от степени имплементации — оверхед по изучению языка, и кмк редактирование БД вообще всегда должно производится нативными инструментами, иначе существует ненулевая вероятность внесения ошибок в workflow.
Глянул в Rails (секунд 40). «Если не хватает AR хелперов пользуйте чистый коннектор и синтаксис БД» Я в AR даже foreignkey пока не увидел… Подозреваю что можно сэкономить кучу времени вообще не изучая нового синтаксиса, используя родной синтаксис БД через коннектор.
Я к тому что это «фича» вне зависимости от степени имплементации — оверхед по изучению языка, и кмк редактирование БД вообще всегда должно производится нативными инструментами, иначе существует ненулевая вероятность внесения ошибок в workflow.
Не хочу вас обидеть, но вы не в теме — ни касательно Rails, ни касательно вообще современного процесса разработки.
Цитирую статью по ссылке выше:
По этой причине важно, чтобы разработка схемы БД шла рука об руку с разработкой бэкенда. Это какбе один процесс, а не два независимых. К примеру, миграции в Rails версифицируются вместе с кодом бэкенда в одной репе, и при переключении между ветками можно мигрировать базу туда-сюда.
И если фрэймворк не предоставляет для этого удобных инструментов, то я предпочту обойти его стороной.
Повторюсь, это не решающий критерий в выборе бэкенда, а просто поверхностный взгляд на него, заглядывание в зубы коню.
Цитирую статью по ссылке выше:
When developing software applications backed by a database, developers typically develop the application source code in tandem with an evolving database schema. The code typically has rigid expectations of what columns, tables and constraints are present in the database schema whenever it needs to interact with one, so only the version of database schema against which the code was developed is considered fully compatible with that version of source code.
По этой причине важно, чтобы разработка схемы БД шла рука об руку с разработкой бэкенда. Это какбе один процесс, а не два независимых. К примеру, миграции в Rails версифицируются вместе с кодом бэкенда в одной репе, и при переключении между ветками можно мигрировать базу туда-сюда.
И если фрэймворк не предоставляет для этого удобных инструментов, то я предпочту обойти его стороной.
Повторюсь, это не решающий критерий в выборе бэкенда, а просто поверхностный взгляд на него, заглядывание в зубы коню.
По поводу Rails я абсолютно не в теме, именно прэтому и читаю статьи подобно этой: интересно. А вот по поводу —
Расскажите мне, как современный процесс разработки приложений взаимодействующих с SQL БД представляет себе отсутствие функционала foreignkey? Я не нашёл ни каскада ни рестрикта в Rails AR. А как вы себе представляете современный процесс разработки с SQL БД без хранимых процедур? Неизбежно изучать и использовать нативный синтаксис БД? А зачем тогда вообще нужен AR?
Но даже если/когда всё это в Rails и появится, вы в цепочку обработки данных вставляете дополнительное звено. Но зачем? В чём выигрыш?
ни касательно вообще современного процесса разработкиможете мне кроме Rails привести пример где правилом хорошего тона считается редактирование структуры БД прямо из приложения? Я до сегодняшнего дня таких примеров вообще не знал.
Расскажите мне, как современный процесс разработки приложений взаимодействующих с SQL БД представляет себе отсутствие функционала foreignkey? Я не нашёл ни каскада ни рестрикта в Rails AR. А как вы себе представляете современный процесс разработки с SQL БД без хранимых процедур? Неизбежно изучать и использовать нативный синтаксис БД? А зачем тогда вообще нужен AR?
Но даже если/когда всё это в Rails и появится, вы в цепочку обработки данных вставляете дополнительное звено. Но зачем? В чём выигрыш?
можете мне кроме Rails привести пример где правилом хорошего тона считается редактирование структуры БД прямо из приложения? Я до сегодняшнего дня таких примеров вообще не знал..NET, Entity Framework Code First
А как вы себе представляете современный процесс разработки с SQL БД без хранимых процедур?Э… INSERT, UPDATE, DELETE?
EF может себе позволить абстрагироваться от БД, учитывая что список совместимых БД клонится к родному MSSQL. Простое гугление показывает что с тем-же Oracle надо доставать бубны. Я рад что узкоспециальные энтерпрайз решения теперь можно называть «правилом хорошего тона в современной разработке ПО».
Но за информацию спасибо, давно не читал туториалов с Visual C#, аж ностальгия пробрала :)
Но за информацию спасибо, давно не читал туториалов с Visual C#, аж ностальгия пробрала :)
Э… INSERT, UPDATE, DELETE?
Вы со мной спорите или с Rails?
There is however a trade-off: db/schema.rb cannot express database specific items such as triggers, stored procedures or check constraints.
Я неправильно читаю их гайды?
Неправильно. schema.rb — это просто образец структуры БД, написанный на человекопонятном декларативном DSL, который читать удобнее, чем имеративный и раздутый дамп SQL.
В миграциях schema.rb не используется.
В миграциях schema.rb не используется.
Разве при регулярном переключении между версиями не приходится делать rake db:reset? Пересоздание БД не содержащее в себе данных о функционале fk (ну вот лично я практически постоянно использую RESTRICT, например, а как его описать в AR — не нашёл) и теряющее/не затрагивающее изменения хранимых процедур… Так-себе решение. Придётся использовать сторонние утилиты (для Postgres вы squirm упоминали) либо нативный синтаксис БД. Учить/использовать и то и другое вместо одного — лично мне кажется неэффективно. И как не крути — это теоретически небезбаговый инструмент, следовательно если я вижу необходимость хотя-бы иногда использовать нативный синтаксис, я и ограничусь нативным синтаксисом, для собственного спокойствия.
Вы со мной спорите или с Rails?С вами. Зачем вообще нужны хранимые процедуры в многоуровневой архитектуре?
> можете мне кроме Rails привести пример где правилом хорошего тона считается редактирование структуры БД прямо из приложения? Я до сегодняшнего дня таких примеров вообще не знал.
Да во всех приличных фрэймворках они есть. Rails, Padrino (кстати, это пример, что в мире Ruby — не Rails единым), Django, Yii, Symphony… В Elixir'овском Phoenix они тоже есть. Уверен, можно легко нагуглить еще десяток или даже два.
Вы сами подумайте. В процессе разработки вы рано или поздно столкнетесь с необходимостью переключаться между ветками, которые полагаются на разную структуру БД. Что вы тогда будете делать, если в вашем фрэймворке задача миграций не решена? Будете настраивать по отдельной базе для каждой ветки и вручную редактировать конфиг базы при каждом переключении? Или напишете какой-нибудь скриптик на коленке, который вам всё похерит?
> Расскажите мне, как современный процесс разработки приложений взаимодействующих с SQL БД представляет себе отсутствие функционала foreignkey?
Да где вы такое взяли? Я не бэкендщик, но мне известно, что в Rails можно выбирать, на какой стороне has many relationship'а хранить foreign key.
> А как вы себе представляете современный процесс разработки с SQL БД без хранимых процедур?
Прекрасно представляю. Ради гипотетического выигрыша в производительности (неизвестно, какой он будет и будет ли вообще) придется мириться с тем, что stored procedures сложнее в написании и не поддаются версифицированию.
Хотя при большом желании можно в Rails использовать stored procedures. Вот, к примеру, gem'чик для Postgres: github.com/norman/squirm_rails
> А зачем тогда вообще нужен AR?
> В чём выигрыш?
> По поводу Rails я абсолютно не в теме, именно прэтому и читаю статьи подобно этой
Вот вместо того, чтобы читать хейтерские статьи, вы бы лучше почитали, чем Rails хорош.
Ато это похоже на обсирание мэрседесов за то, что у них бортовой компьютер всё контролирует. Другое дело жигули, там хоть во время езды можно карбюратор регулировать. И всё это аргументируется при помощи success story чувака, который пять лет отъездил на мэрседесе, плевался, а потом пересел на приору и стал счастлив. :trollface:
Да во всех приличных фрэймворках они есть. Rails, Padrino (кстати, это пример, что в мире Ruby — не Rails единым), Django, Yii, Symphony… В Elixir'овском Phoenix они тоже есть. Уверен, можно легко нагуглить еще десяток или даже два.
Вы сами подумайте. В процессе разработки вы рано или поздно столкнетесь с необходимостью переключаться между ветками, которые полагаются на разную структуру БД. Что вы тогда будете делать, если в вашем фрэймворке задача миграций не решена? Будете настраивать по отдельной базе для каждой ветки и вручную редактировать конфиг базы при каждом переключении? Или напишете какой-нибудь скриптик на коленке
> Расскажите мне, как современный процесс разработки приложений взаимодействующих с SQL БД представляет себе отсутствие функционала foreignkey?
Да где вы такое взяли? Я не бэкендщик, но мне известно, что в Rails можно выбирать, на какой стороне has many relationship'а хранить foreign key.
> А как вы себе представляете современный процесс разработки с SQL БД без хранимых процедур?
Прекрасно представляю. Ради гипотетического выигрыша в производительности (неизвестно, какой он будет и будет ли вообще) придется мириться с тем, что stored procedures сложнее в написании и не поддаются версифицированию.
Хотя при большом желании можно в Rails использовать stored procedures. Вот, к примеру, gem'чик для Postgres: github.com/norman/squirm_rails
> А зачем тогда вообще нужен AR?
> В чём выигрыш?
> По поводу Rails я абсолютно не в теме, именно прэтому и читаю статьи подобно этой
Вот вместо того, чтобы читать хейтерские статьи, вы бы лучше почитали, чем Rails хорош.
Ато это похоже на обсирание мэрседесов за то, что у них бортовой компьютер всё контролирует. Другое дело жигули, там хоть во время езды можно карбюратор регулировать. И всё это аргументируется при помощи success story чувака, который пять лет отъездил на мэрседесе, плевался, а потом пересел на приору и стал счастлив. :trollface:
В спор не ввязываюсь, просто уточняю, поскольку являюсь разработчиком Padrino. В Padrino как таковом нет миграций. Они есть в ОРМах, которые к нему можно подключить. Отвязка от прослоек к этим rake-таскам (миграциям) и генерация этих прослоек в проект при инициализации — одна из висящих задач.
Я, слава богу, успел только туториалов почитать, и эту статью, ниразу не сказал что Ruby или Rails плох. Лично мне просто непонятно почему отсутствие (на самом деле я даже не смотрел ни Sails ни Loopback, полагаюсь на вашу оценку что там такого нет; может тоже просто костыль приделать — и будет) редактирования БД сразу является недостатком?
Как по мне — так Rails может быть просто супер-пупер языком, но не на основании того что в нём есть или нет AR. Как минимум отсутствие аналога AR в других фреймворках точно никак не показатель плохих зубов у коня.
Как по мне — так Rails может быть просто супер-пупер языком, но не на основании того что в нём есть или нет AR. Как минимум отсутствие аналога AR в других фреймворках точно никак не показатель плохих зубов у коня.
Дело не в DSL, а в возможности версионирования. Пусть это будут просто SQL файлы, но у них есть версия и всегда можно узнать какие миграции есть в БД, а каких нету.
Ну так практически любой SVC тул и дамп БД с патчем на нативном языке. Всё.
Как вы будете сливать (merge) дампы БД?
Дамп один. Структура БД с лимитом на что-нибудь вроде 1000 строк на таблицу.
Патчей — сколько угодно, можно в хранимых процедурах, и вызывать те комбинации которые нужны.
Патчей — сколько угодно, можно в хранимых процедурах, и вызывать те комбинации которые нужны.
а что при этом делать с самими данными? В миграции рельсы можно прописать как будут вести себя данные при прохождении этой самой миграции как в одну, так и в другую сторону. Мне кажется рано или поздно с дампами вы сами себя обмануть можете, а не вы, так кто-то из команды.
Если в миграции рельсы можно прописать изменение структуры/содержания/поведения данных, то рельсы полюбому должны это потом имплементировать в нативном коде БД, правильно? Просто я не представляю ситуации где я выучив синтаксис AR буду знать как описать миграцию таблицы, но не смогу описать те-же фишки SQL синтаксисом. Откатится назад вероятно будет легче в Rails, через db:rollback, особенно если он умеет восстанавливать данные например в дропнутые таблицы. Иначе — я всё ещё не вижу в нём added-value, чтобы я мог самому себе обосновать необходимость усложнения жизни дополнительным инструментом.
Вроде никто не спорит. Можно и синтаксисом SQL всё сделать.
Дропать данные врядли вы будете, имея хоть малую надежду того, что эти данные возможно еще понадобятся. Скорее всего эти данные будут как то преобразованы, перенесены, конвертированы, выгружены в конце концов. Именно это и позволяет сделать миграция, описать всё это используя Ruby (в случае Rails). Кстати SQL код тоже вполне работает в миграциях.
А вот организацию работы, особенно в команде, с вашим подходом я себе представляю очень напряженно. Понятно, что можно, но не так удобно. Ведь по сути вы будете делать тоже самое, просто удобным вам способом. Вы ведь будете хранить состояние базы в определенный момент времени. А где-то даже сами данные, судя по тому, что вы пишете.
Дропать данные врядли вы будете, имея хоть малую надежду того, что эти данные возможно еще понадобятся. Скорее всего эти данные будут как то преобразованы, перенесены, конвертированы, выгружены в конце концов. Именно это и позволяет сделать миграция, описать всё это используя Ruby (в случае Rails). Кстати SQL код тоже вполне работает в миграциях.
А вот организацию работы, особенно в команде, с вашим подходом я себе представляю очень напряженно. Понятно, что можно, но не так удобно. Ведь по сути вы будете делать тоже самое, просто удобным вам способом. Вы ведь будете хранить состояние базы в определенный момент времени. А где-то даже сами данные, судя по тому, что вы пишете.
похоже «assume-unchanged» не все умеют пользоваться…
Да не является это недостатком. Я уже третий раз говорю, что это как смотреть в зубы коню. Знаете такую поговорку?
Если у коня гнилые зубы — это еще не значит, что конь плохой. Он может быть гоночным здоровяком в самом расцвете сил. Но как правило, если у коня гнилые зубы, то значит за ним плохо ухаживают, и у него обнаружится много других проблем: как со здоровьем, так и выносливостью.
Так же и с фрэймворком: если ни у кого из авторов и пользователей фрэймворка не возникло потребности наладить в нем миграции, значит что-то в нем не так. Либо они презирают миграции, что указывает на далекий от эффективного agile'а workflow, либо просто фрэймворк незрелый, и задачу решить еще не успели, либо в их экосистеме принято полагаться на какие-то сторонние тулзы, что, конечно, не добавляет фрэймворку удобства и целостности.
(хотя на самом деле состояние зубов коня является индикатором его возраста, а не здоровья, но в контексте вэб-разработки это не важно)
Если у коня гнилые зубы — это еще не значит, что конь плохой. Он может быть гоночным здоровяком в самом расцвете сил. Но как правило, если у коня гнилые зубы, то значит за ним плохо ухаживают, и у него обнаружится много других проблем: как со здоровьем, так и выносливостью.
Так же и с фрэймворком: если ни у кого из авторов и пользователей фрэймворка не возникло потребности наладить в нем миграции, значит что-то в нем не так. Либо они презирают миграции, что указывает на далекий от эффективного agile'а workflow, либо просто фрэймворк незрелый, и задачу решить еще не успели, либо в их экосистеме принято полагаться на какие-то сторонние тулзы, что, конечно, не добавляет фрэймворку удобства и целостности.
(хотя на самом деле состояние зубов коня является индикатором его возраста, а не здоровья, но в контексте вэб-разработки это не важно)
> можете мне кроме Rails привести пример где правилом хорошего тона считается редактирование структуры БД прямо из приложения? Я до сегодняшнего дня таких примеров вообще не знал.
http://laravel.com/docs/5.1/migrations
http://www.yiiframework.com/doc-2.0/guide-db-migrations.html
http://symfony.com/doc/current/bundles/DoctrineMigrationsBundle/index.html
https://docs.djangoproject.com/en/1.8/topics/migrations/
http://www.sinatrarb.com/faq.html#ar-migrations
http://www.davidhayden.me/blog/asp.net-mvc-4-and-entity-framework-database-migrations
Ну и т.д. Первые ссылки в гугле по данному запросу для всех фреймов, которые мне удалось припомнить. Честно, мне не удалось припомнить такого фрейма, где их НЕ нашлось.
Представляете, лет за 10 работы на С++ и Java при работе с БД ниразу не видел подобных решений. А в тех проектах где лет пять назад писали на C# — делали так чтобы смена СУБД не была проблемой, видимо поэтому не использовали EF.
Вот серьёзно не шучу. Только сегодня узнал что такой функционал вообще нашёл свою нишу. Наверное неправильные приложения пишу :)
Вот серьёзно не шучу. Только сегодня узнал что такой функционал вообще нашёл свою нишу. Наверное неправильные приложения пишу :)
На плюсах даже единого пакетного менеджера нет нормального (не считая VS нюгет или юникосвые аптгет и проч), так что как бы не были они круты (а в этом никто не сомневается, вон сколько всего на них написано), но по инфраструктуре язык довольно сильно отсталый, по-моему. А для джавы, ну например: http://flywaydb.org/
И проблема не в смене БД, а в версионировании БД в проектах, с более чем одним человеком. Это как git\mercurial, только для структуры БД, некоторые о VCS вообще не слышали за много лет работы, и такое бывает.
И проблема не в смене БД, а в версионировании БД в проектах, с более чем одним человеком. Это как git\mercurial, только для структуры БД, некоторые о VCS вообще не слышали за много лет работы, и такое бывает.
удалено
Именно поэтому я не стал переходить с Java на Ruby.
Красиво, быстро…
Но когда нужно что-то понять в этом огромном множестве библиотечного динамического кода…
И никакая IDE тебе не поможет, ибо она, в основном, оперирует статикой, т.к. анализировать динамику очень долго.
IMHO, динамические конструкции хорошо подходят для написания мощных framework'ов, но они чрезвычайно вредны для бизнес-логики практически любой предметной области.
Предметная область и так достаточно сложна, чтобы привносить в нее дополнительные технические сложности.
IMHO, наиболее крутым было бы решение, которое бы имело два режима: framework и business.
Причем режим framework должен быть доступен только при инициализации приложения, а при переходе к business-коду уже ничего не должно меняться в мета-структуре языка.
Тогда этого позволило бы нашим IDE прогнать весь код из framework, построить индексы по всем получившимся mixin'ам и т.д., и в коде основной business-логики после этого уже можно бы было ориентироваться.
Если framework меняется нечасто (хотя и чаще, чем появляются новые версии языков программирования :-) ), то такой подход позволит сочетать в себе плюсы и динамики, и статики.
Красиво, быстро…
Но когда нужно что-то понять в этом огромном множестве библиотечного динамического кода…
И никакая IDE тебе не поможет, ибо она, в основном, оперирует статикой, т.к. анализировать динамику очень долго.
IMHO, динамические конструкции хорошо подходят для написания мощных framework'ов, но они чрезвычайно вредны для бизнес-логики практически любой предметной области.
Предметная область и так достаточно сложна, чтобы привносить в нее дополнительные технические сложности.
IMHO, наиболее крутым было бы решение, которое бы имело два режима: framework и business.
Причем режим framework должен быть доступен только при инициализации приложения, а при переходе к business-коду уже ничего не должно меняться в мета-структуре языка.
Тогда этого позволило бы нашим IDE прогнать весь код из framework, построить индексы по всем получившимся mixin'ам и т.д., и в коде основной business-логики после этого уже можно бы было ориентироваться.
Если framework меняется нечасто (хотя и чаще, чем появляются новые версии языков программирования :-) ), то такой подход позволит сочетать в себе плюсы и динамики, и статики.
А 3rd parties вы бы к какой категории отнесли? Нередко приходится поковыряться внутри гемов и если они написаны при помощи замечательной методики Eval Driven Development, тут не только IDE, и разработчику сложно разобраться, откуда ноги растут
О, холивар намечается!
Вы Java сравниваете же?
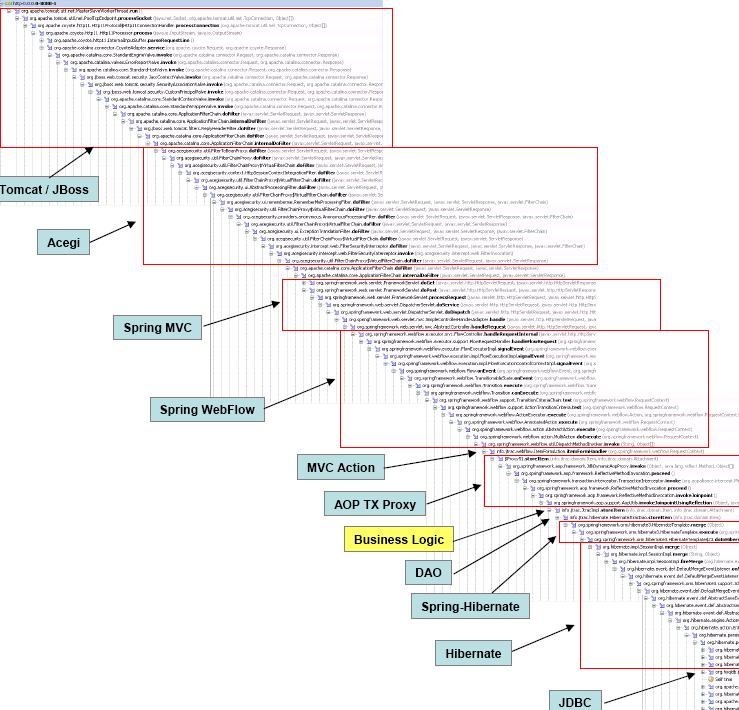
Но когда нужно что-то понять в этом огромном множестве библиотечного динамического кода…
Вы Java сравниваете же?
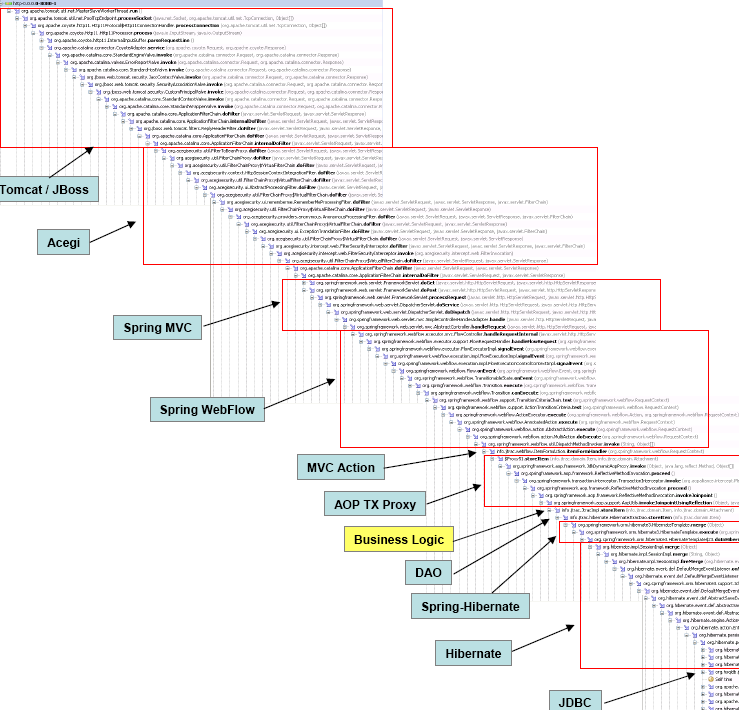
А при чем тут джава? И подняться по дереву эксепшенов очень легко и быстро. Как видно они группируются. Или вы предпочитаете руками ковыряться в кордампе?)
Не эксепшены, конечно, а дерево вызовов. У которого такая сложность возникает из-за кучи слоев архитектуры (без которых можно обойтись, но это другой вопрос). Да и в 95% не надо смотреть на уровни выше своего кода и как раз умные IDE прекрасно разбираются, что из этого относится к коду приложения, а что к обвязке.
На самом деле ruby не хватает чего-то типа «прекомпилятора» мета-кода, хотя задача не такая сложная, как выглядит. Это же руби, можно воспользоваться манки-патчингом, чтобы избавиться от манки-патчинга: надо всего-лишь изменить class_eval и module_eval методы.
Частично согласен, но не столько по поводу рельс, сколько про 3rd party-gems, добавляющих свои мета-методы в Object >_<, по умолчанию загружающих кучу ненужных модулей, или идущих в комплекте с поддержкой всех-всех ORM (что вообще дико бесит, нет чтобы вынести поддержку ORM в другой гем). С другой стороны гемы-то полезные, велосипед не приходится изобретать. Я в последнее время, перед тем как добавить что-то в Gemfile, делаю форк стабильной версии и добавляю ветку «magicless», где тупо выпиливаю весь «магический» код. Где-то такая практика избавила меня от memory leak.
Это типа как расширять Object.prototype в JavaScript? Все НАСТОЛЬКО плохо?
Нет, не настолько.
Во-первых, это гораздо безопаснее, чем в JS. а) В Ruby нет IE8, которых к таким расширениям относится плохо. б) В Ruby в качестве хэша/словаря/ассоциативного массива используется класс Hash, а не Object, и там нет проблемы итерации по свойствам родительского класса (расширение Object.prototype в JS у меня ломало Facebook SDK, потому что тамошние умники не сделали
Во-вторых, в Ruby есть Refinements (на использование которых Rails, еще, видимо, не перешли). Refinements позволяют разным частям приложения использовать разные манки-патчи. При этом конфликт имен возможен только в том случае, если вам из одной точки в коде потребуется использовать одновременно оба конфликтующих манки-патча.
Во-первых, это гораздо безопаснее, чем в JS. а) В Ruby нет IE8, которых к таким расширениям относится плохо. б) В Ruby в качестве хэша/словаря/ассоциативного массива используется класс Hash, а не Object, и там нет проблемы итерации по свойствам родительского класса (расширение Object.prototype в JS у меня ломало Facebook SDK, потому что тамошние умники не сделали
if (foo.hasOwnProperty(bar)) return;.Во-вторых, в Ruby есть Refinements (на использование которых Rails, еще, видимо, не перешли). Refinements позволяют разным частям приложения использовать разные манки-патчи. При этом конфликт имен возможен только в том случае, если вам из одной точки в коде потребуется использовать одновременно оба конфликтующих манки-патча.
Но суть похоже я понял правильно.
> В Ruby нет IE8, которых к таким расширениям относится плохо.
На сервере тоже нет (и не было) IE8, а на клиенте нету ruby.
> Refinements позволяют разным частям приложения использовать разные манки-патчи.
Похоже на образцовое костылестроение. Почему просто не отказаться от манки-патчей? Это же «манки-патчи» в конце-концов, уже само название нечет резко негативный оттенок, настолько это общеизвестная плохая практика.
> В Ruby нет IE8, которых к таким расширениям относится плохо.
На сервере тоже нет (и не было) IE8, а на клиенте нету ruby.
> Refinements позволяют разным частям приложения использовать разные манки-патчи.
Похоже на образцовое костылестроение. Почему просто не отказаться от манки-патчей? Это же «манки-патчи» в конце-концов, уже само название нечет резко негативный оттенок, настолько это общеизвестная плохая практика.
UFO just landed and posted this here
Если не сложно, добавьте пожалуйста ссылку на исходную статью
Скрытый текст

Дело в том что в мобильном приложении этот заголовок выглядит немного не так, в частности в нем нету ссылки. Так что думаю что моя просьба весьма обоснованна.
О как. Это, видимо, ТМ надо посмотреть. Boomburum?
Sign up to leave a comment.
Перевод. Срезаем углы: почему rails может убить ruby