
SQL пробуждается и наносит ответный удар силам тьмы — NoSQL
С самого начала компьютерной эры человечество собирает экспоненциально растущие объемы данных, и вместе с этим растут требования к системам хранения, обработки и анализа данных. Из-за этого в последнее десятилетие разработчики ПО отказались от SQL как от устаревшей технологии, которая не могла масштабироваться вместе с растущими объемами данных — и в результате появились базы данных NoSQL: MapReduce и Bigtable, Cassandra, MongoDB и другие.
Однако сейчас SQL возрождается. Все основные поставщики облачных услуг предлагают популярные управляемые сервисы реляционных баз данных: Amazon RDS, Google Cloud SQL, база данных Azure для PostgreSQL (запущена буквально в этом году) и другие. Если верить компании Amazon, ее совместимая с PostgreSQL и MySQL база данных Aurora стала «самым быстрорастущим сервисом в истории AWS». Не теряют популярности и SQL-интерфейсы поверх платформ Hadoop и Spark. А в прошлом месяце поддержку SQL запустила и Kafka. Авторы статьи скромно признаются, что и сами разрабатывают новую базу данных временных рядов, которая полностью поддерживает SQL.
В этой статье мы попробуем разобраться, почему маятник качнулся назад в сторону SQL и чего ждать специалистам по разработке и анализу баз данных.
Переведено в Alconost
Часть 1. Новая надежда
Чтобы понять, почему SQL возвращается, давайте вернемся в самое начало и разберемся, почему эта технология вообще появилась.

Как и все хорошие истории, наша начинается в 70-е
Эта реляционная база данных родилась в подразделении IBM Research в начале 70-х гг. В то время языки запросов основывались на сложной математической логике и не менее сложной нотации. Два свежеиспеченных кандидата наук, Дональд Чемберлин и Раймонд Бойс, впечатлились реляционной моделью данных, но при этом увидели, что используемый язык запросов будет препятствовать ее распространению. Они решили разработать новый язык запросов, который, по их словам, будет «более удобным для пользователей, не прошедших курс математики или компьютерного программирования».

Языки запросов до SQL (пп. А, Б) в сравнении с SQL (источник)
Просто представьте себе: еще не было ни Интернета, ни персональных компьютеров, «Cи» только-только вышел в свет, а два молодых специалиста в области вычислительных систем уже поняли, что «успех компьютерной отрасли в большей степени зависит от развития категории пользователей, а не категории обученных компьютерных специалистов». Им нужен был язык запросов, который читается так же легко, как английский, но при этом дает возможность администрировать базы данных и работать с ними.
В результате появился SQL, впервые представленный миру в 1974 году, и в следующие несколько десятилетий он станет очень популярным. Поскольку в отрасли ПО обосновались реляционные базы данных (например, System R, Ingres, DB2, Oracle, SQL Server, PostgreSQL, MySQL и многие другие), SQL широко распространился как язык взаимодействия с БД и стал общепринятым в экосистеме, которая становилась все более конкурентной.
(К сожалению, Раймонду Бойсу не удалось увидеть успех SQL: он умер от аневризмы мозга через месяц после одного из первых докладов по SQL — в возрасте всего 26 лет; у него остались жена и маленькая дочь.)
Некоторое время казалось, что SQL выполнил свою задачу и все идет хорошо… Но тут появился Интернет.
Часть 2. NoSQL наносит ответный удар
Разрабатывая SQL, Чемберлин и Бойс не знали, что в Калифорнии работают над другим перспективным проектом, который впоследствии широко распространится и станет угрожать существованию SQL. Этот проект — ARPANET, дата его рождения — 29 октября 1969 г.

Создатели сети ARPANET (не все), которая в итоге превратилась в современный Интернет (источник)
Некоторое время SQL вел спокойное существование — пока в 1989 году еще один инженер не изобрел Всемирную паутину.

Физик, изобретший Интернет (источник)
Веб и Интернет росли и распространялись, как сорняк, бесчисленными способами меняя привычный мир, но у специалистов по базам данных появилась вполне конкретная головная боль: новые источники, генерирующие данные в гораздо больших объемах и намного быстрее, чем раньше.
С ростом сети Интернет разработчики ПО обнаружили, что реляционные базы данных не могут справиться с такой нагрузкой. Произошло возмущение в Силе, как будто миллионы баз данных вскрикнули от ужаса и так же внезапно умолкли, перегруженные.
Затем два новых интернет-гиганта совершили прорыв — разработали собственные распределенные нереляционные системы, предназначенные для решения проблемы с возрастающими объемами данных: MapReduce (публикация 2004 г.) и Bigtable (публикация 2006 г.) от компании Google и Dynamo (публикация 2007 г.) от компании Amazon. Упав на благодатную почву, опубликованные статьи дали хороший урожай нереляционных баз данных: Hadoop (на основе статьи по MapReduce, 2006 г.), Cassandra (авторы вдохновлялись статьями по Bigtable и Dynamo, 2008 г.), MongoDB (2009 г.) и др. Новые системы были написаны преимущественно с чистого листа, поэтому они тоже не использовали SQL, что привело к росту «движения NoSQL».
Творение компаний Google и Amazon распространилось, похоже, гораздо шире, чем предполагали сами авторы. И понятно, почему так случилось: NoSQL-системы были в новинку; они обещали масштабирование и мощь; казалось, что это — быстрый путь к успешной разработке. И тут начали вылезать проблемы.

Разработчик, поддавшийся искушению NoSQL. Не делайте так.
Вскоре разработчики обнаружили, что отсутствие SQL на самом деле существенно ограничивает. У каждой базы данных NoSQL был собственный уникальный язык запросов, а это означало следующее: нужно было изучать больше языков (и обучать своих коллег); подключать эти базы данных к приложениям было сложнее, что заставляло писать тонны неустойчивого связующего кода; отсутствие сторонней экосистемы — а значит, компаниям приходилось разрабатывать собственные инструменты для визуализации и работы с БД.
Языки NoSQL только появились, поэтому их нельзя было назвать полными и завершенными: в реляционных БД, к примеру, многие годы работали над добавлением в SQL необходимых функций (JOIN, например). Такая незрелость означала бо́льшую сложность на уровне приложения. Отсутствие операторов JOIN также приводило к денормализации, итогом чего было «раздувание» данных и недостаток гибкости.
Некоторые базы данных из лагеря NoSQL добавили собственные SQL-подобные языки запросов — например, CQL в БД Cassandra. И часто становилось только хуже: использование интерфейса, который почти совпадает с чем-то более распространенным, по факту требовало больше умственных усилий, ведь в этом случае заранее неизвестно, какие из знакомых функций поддерживаются, а какие — нет.

SQL-подобные языки запросов — это как «Праздничный спецвыпуск» для «Звездных войн». Избегайте подражания. (И ни в коем случае не смотрите «Праздничный спецвыпуск».)
Кое-кто из специалистов уже на раннем этапе видел проблемы в NoSQL (например, ДеВитт и Стоунбрейкер — в 2008 г.). С течением времени к ним присоединялось все больше разработчиков ПО, которые прочувствовали эти проблемы на собственном горьком опыте.
Часть 3. Возвращение SQL
Соблазнившись поначалу «темной стороной», разработчики ПО вскоре узрели свет и понемногу начали возвращаться к SQL.
Сначала поверх платформ Hadoop и (чуть позже) Spark появились SQL-интерфейсы, благодаря чему в отрасли под «NoSQL» начали понимать «не только SQL» (хорошая попытка, ага).
Затем появились NewSQL — «новые SQL», масштабируемые базы данных с полной поддержкой SQL. Одной из первых масштабируемых БД с оперативной обработкой транзакций (OLTP) стала H-Store (публикация 2008 г.) Массачусетского технологического института и Брауновского университета. И снова не обошлось без разработок Google: своей первой статьей про Spanner (публикация 2012 г., среди авторов есть и создатели MapReduce) компания возглавила движение в сторону георепликационных БД с SQL-интерфейсом, и за ней последовали другие пионеры — например, CockroachDB (2014 г.).
В это же время начало возрождаться сообщество PostgreSQL: появились важные улучшения, например, тип данных JSON (2012 г.), а также винегрет из новых функций — в версии PostgreSQL 10: улучшенная встроенная поддержка секционирования и репликации, поддержка полнотекстового поиска для JSON и многое другое (вышла в октябре этого года). Другие разработчики, например, CitusDB (2016 г.) и авторы этих строк (TimescaleDB, выпущена в этом году) нашли новые способы масштабирования PostgreSQL для специализированных рабочих нагрузок.

Дорога, по который мы шли, разрабатывая TimescaleDB, очень похожа на путь отрасли в целом. В ранних внутренних версиях TimescaleDB имела собственный SQL-подобный язык запросов «ioQL» — да, темная сторона соблазнила и нас: казалось, что собственный язык запросов — это огромное преимущество. Поначалу это не казалось сложным, но вскоре мы поняли, что работы на самом деле предстоит намного больше, чем мы ожидали: например, нужно было определиться с синтаксисом, разработать «соединители», обучить этому языку пользователей и т. д. А еще обнаружилось, что мы — в собственноручно разработанном языке! — постоянно ищем правильный синтаксис для запросов, которые можем спокойно выразить через SQL.
Таким образом, однажды мы поняли, что разрабатывать собственный язык запросов — бессмысленно. Это привело нас к переходу на SQL и оказалось одним из лучших сделанных нами технологических решений: нам открылся совершенно новый мир. Сегодня нашей БД нет еще и 5 месяцев, а пользователи уже могут применять ее в работе и сразу «из коробки» иметь множество замечательных возможностей: инструменты визуализации (Tableau), соединители для популярных ORM, множество инструментов и вариантов резервного копирования, руководства и подсказки по синтаксису и т. д.
Не обязательно верить на слово нам — давайте посмотрим, что делает Google.

Более десятка лет компания Google находится, без сомнений, на переднем крае разработок в области разработки баз данных и соответствующей инфраструктуры. Поэтому следует уделять пристальное внимание тому, что они делают.
Взглянув на вторую крупную публикацию Google по БД Spanner, которая вышла совсем недавно (Spanner: Becoming a SQL System — «Spanner становится SQL-системой», май 2017 г.), вы обнаружите, что она подтверждает выводы, к которым мы пришли самостоятельно.
К примеру, инженеры Google начал надстраивать свою систему над Bigtable, но обнаружили, что отсутствие SQL создает сложности:
«Эти системы давали некоторое преимущество как базы данных, однако им не хватало многих традиционных функций БД, на которые часто полагаются разработчики приложений. Ключевой пример — отсутствие продуманного языка запросов, из-за чего разработчикам приложений для обработки и агрегирования данных приходилось писать сложный код. В итоге мы решили превратить Spanner в полнофункциональную SQL-систему, в которой выполнение запросов тесно связано с другими архитектурными особенностями БД (например, строгая согласованность и глобальная репликация)».
Далее в статье они подробнее обосновывают переход от NoSQL к SQL:
«У исходного API-интерфейса базы данных Spanner были методы NoSQL для точечного поиска и поиска по диапазонам отдельных и перемежающихся (англ. «interleaved») таблиц. Методы NoSQL упрощали запуск системы и по-прежнему удобны в простых задачах поиска, однако у SQL есть значительные преимущества при записи более сложных шаблонов доступа к данным и вычислениях на данных».
В статье также рассказывается, что переход на SQL не остановился на проекте Spanner, а по сути распространился на остальные технологии компании, где сегодня общий диалект SQL используется в нескольких системах:
«SQL-ядро БД Spanner использует «стандартный SQL» совместно с несколькими другими системами Google, в число которых входят и внутренние (среди них — F1 и Dremel), и внешние системы (например, BigQuery)…
Для пользователей внутри компании такой подход снижает барьер при работе с несколькими системами. Разработчик или специалист по анализу данных, который пишет SQL-запросы в Spanner, может использовать свои навыки в системе Dremel, не беспокоясь о тонкостях синтаксиса, обработке NULL и т. д.».
Успех такого подхода говорит сам за себя. Сегодня Spanner является платформой для основных систем Google, в числе которых AdWords и Google Play, и при этом «потенциальные клиенты облачных платформ в подавляющем большинстве заинтересованы в использовании SQL».
Весьма примечательно, что компания Google, которая помогла родиться движению NoSQL, сегодня возвращается в лоно SQL. (Поэтому кое-кто задался вопросом: «Разработчики Google сбили отрасль «больших данных» с истинного пути на 10 лет?»)
Будущее отрасли обработки данных: SQL как узкое место
В компьютерных сетях существует такое понятие, как «узкое место».
Эта идея возникла для решения главной задачи, которую можно сформулировать следующим образом. Возьмем какое-либо сетевое устройство и представим себе своеобразный «пирог» из слоев оборудования снизу и слоев программного обеспечения сверху. Сетевые устройства могут быть самыми разными; так же бывает и множество различных приложений и ПО. Задача состоит в том, чтобы ПО имело возможность подключаться к сети, какое бы оборудование не использовалось; а сетевое оборудование должно знать, как обрабатывать запросы сети, независимо от ПО.
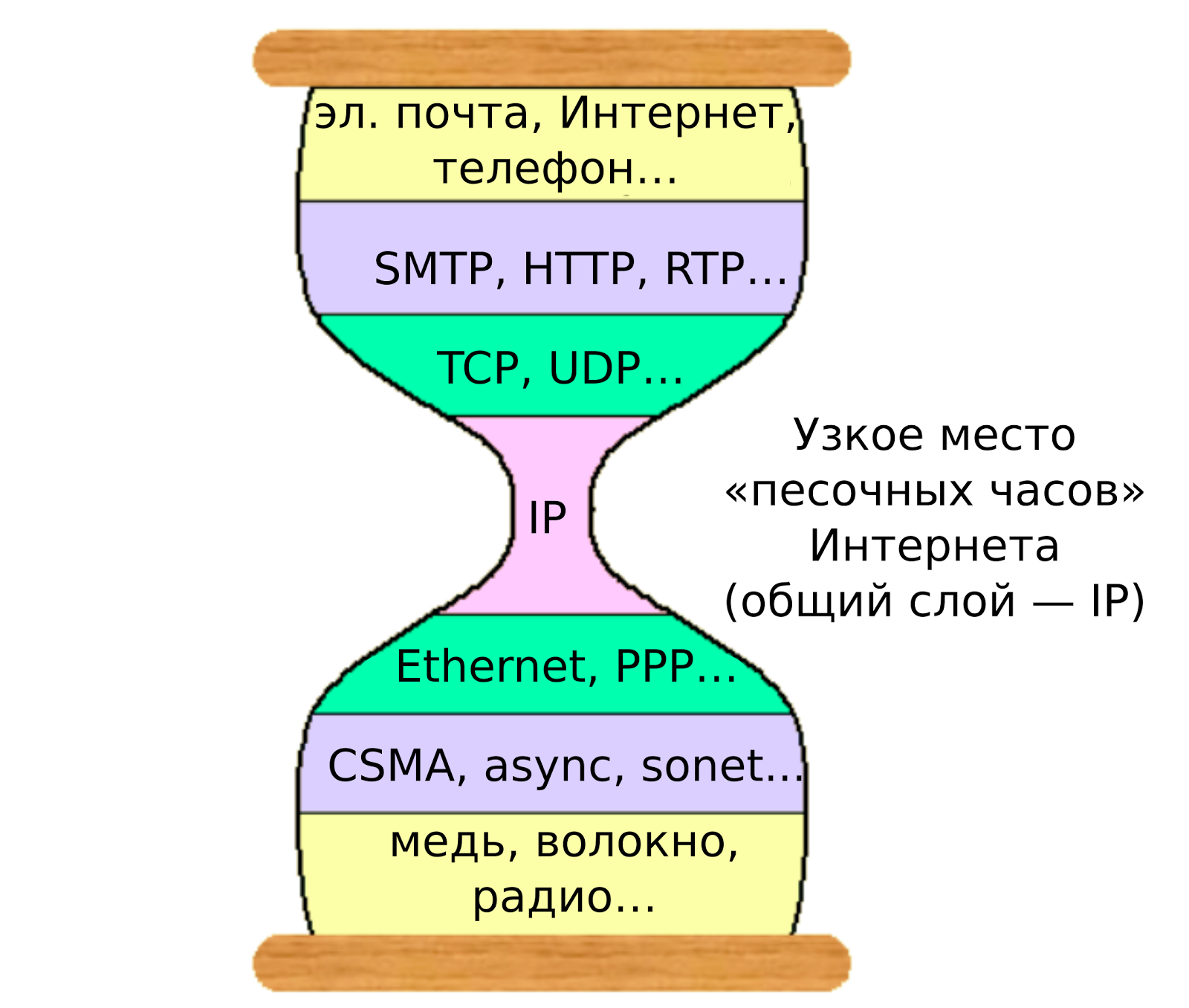
«Узкое место» сетевых технологий (источник)
В сетях узкое место — протокол IP: он выступает в качестве общего интерфейса между сетевыми протоколами низкого уровня, предназначенными для локальной сети, и прикладными и транспортными протоколами высокого уровня. (Вот одно неплохое разъяснение.) И, если упрощать, этот интерфейс стал общепринятым для компьютерных систем: он позволяет объединять сети и обмениваться данными между устройствами. И эта «сеть сетей» превратилась в многогранный, полный различной информации Интернет, каким мы его знаем сегодня.
Авторы этой статьи полагают, что SQL стал узким местом в анализе данных.
Мы живем в эпоху, когда данные становятся «самым ценным ресурсом в мире» (The Economist, май 2017 г.). В результате мы имели удовольствие наблюдать «кембрийский взрыв» специализированных БД (OLAP, базы данных временных рядов, БД для документов, графов и т. д.), инструментов обработки данных (Hadoop, Spark, Flink), шин передачи данных (Kafka, RabbitMQ) и т. д. Появилось и большое число приложений, которые работают на такой инфраструктуре данных, будь то сторонние инструменты визуализации (Tableau, Grafana, PowerBI, Superset), веб-фреймворки (Rails, Django) или специально разработанные приложения, использующие БД.
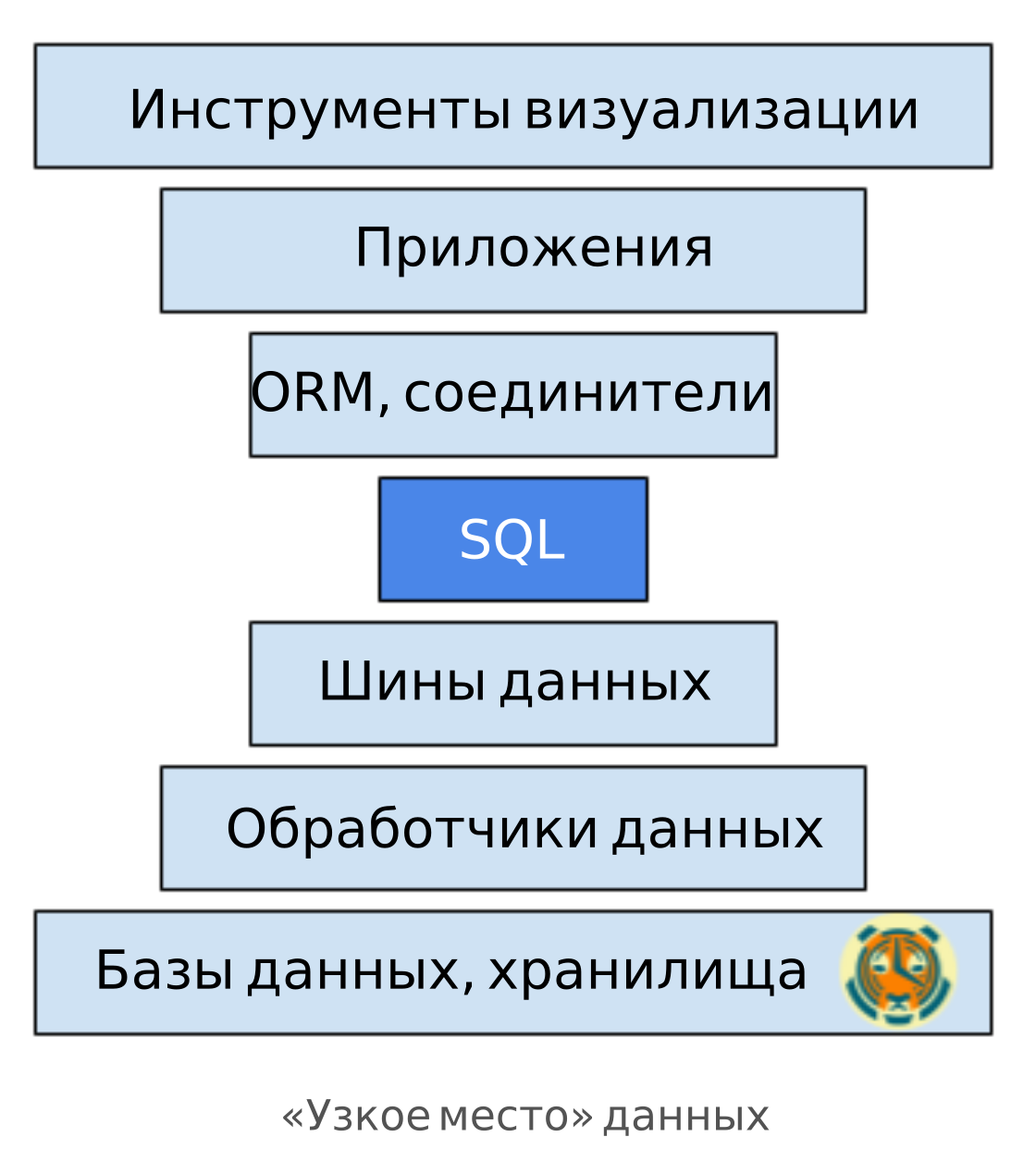
Как и в случае компьютерных сетей, у нас есть сложный «пирог» с инфраструктурой в самом низу и приложениями вверху. Как правило, чтобы этот пирог работал, нам приходится писать много связующего кода. Но такой код ненадежен: его нужно старательно поддерживать.
Необходим общий интерфейс, который позволит частям этого пирога друг с другом взаимодействовать. Лучше всего — что-то, что уже является стандартом в отрасли. Что-то, что позволит менять местами различные слои с минимальными усилиями.
И здесь как раз самое место для SQL: как и IP, SQL — это общий интерфейс.
Но SQL все же универсальнее протокола IP: данные приходится анализировать и людям, а запросы на языке SQL, как и было задумано, могут быть прочитаны человеком.
Безупречен ли SQL? Нет. Но именно этот язык знаком большинству специалистов по базам данных. Конечно, где-то уже ведутся работы над интерфейсом, в большей степени ориентированным на естественный язык, но к чему будут подключаться такие системы? К SQL.
Таким образом, на самой вершине пирога есть еще один слой, и этот слой — мы.
SQL возвращается
SQL возвращается — и главная причина этого не в том, что писать связующий код для подключения NoSQL-инструментов надоедает. И не в том, что обучать специалистов множеству новых языков — это сложно. И не в том, что стандарты должны быть продуманными.
Главная причина в том, что наш мир полон данных: они окружают нас, связывают нас. Когда-то мы для их обработки полагались на собственные органы чувств и нервную систему. Теперь же и наши аппаратные системы и ПО становятся достаточно умными, чтобы помогать нам. Мы хотим лучше понимать окружающий мир, и для этого собираем все больше и больше данных — поэтому сложность систем хранения, обработки, анализа и визуализации этих данных будет только расти.

Мастер обработки данных Йода
У нас есть выбор: жить в мире хрупких систем и миллионов интерфейсов — или вернуться к SQL и восстановить нарушенное равновесие Силы.
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 68 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
Подробнее: https://alconost.com
