
Привет!
История становления и развития свойственна не только людям. Совершенствуя себя, мы совершенствуем и те вещи, которые делаем.

Не исключение и наш Банк, со временем обросший паутиной многочисленных IT-решений, в центре которой находится автоматизированная банковская система Equation (АБС). Меня же зовут Кирилл Диброва. Я занимаюсь функциональным и архитектурным развитием Equation — огромного и весьма важного для Банка программного комплекса; совсем не похожего на типичные реализации современного разработчика.
В этом посте хочу рассказать вам о той вынужденной «промышленной революции», которую пришлось осуществить devops-инженерам АБС. Итак…
Давным-давно, в забытом 2002-ом, в «далекой-далекой галактике», разработчики нашего Банка начали дорабатывать «свежевнедренную» и вполне популярную на тот момент АБС Equation. Как оказалось, это такой огромный бизнес-монолит, крутящийся под мейнфреймом IBM, именуемым, на тот момент, AS/400. И использовали они для этого вполне “современный” на то время IDE – терминальный редактор SEU (source entry utility)
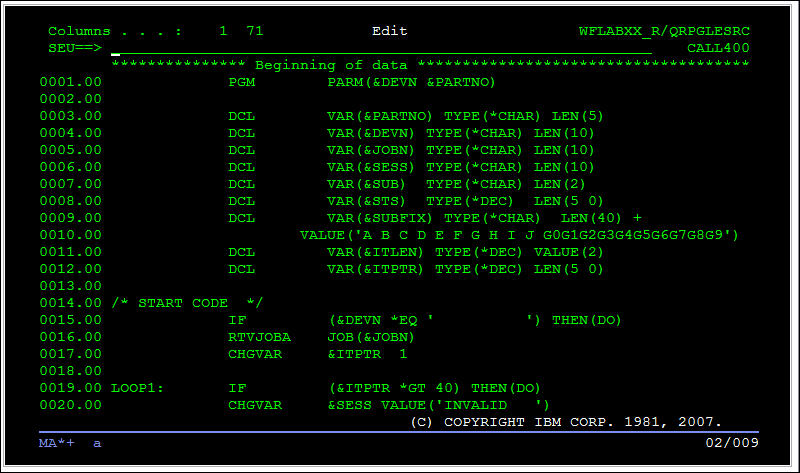
SEU, «современный» редактор исходных текстов для IBM i
Согласитесь, сейчас выглядит, как спецэффекты в “Звездных войнах” 78-го года — сурово и беспощадно.
Где-то в середине нулевых компания IBM все же смилостивилась над свои разработчиками и выпустила «Rational Application Developer for iSeries» (позже Rational Develop for I или сокращенно Rdi). Жить стало веселей — это и современные оконный интерфейс, и довольно удобный инструментарий для взаимодействия с сервером, и поддержка синтаксиса основного языка разработки RPGLE. Но, тем не менее, код все так же хранился и правился в рамках специализированной файловой системы мейнфрейма. А без полноценной истории изменений и иных важных фишек SCM работать над кодом совместно было весьма сложно.
Впрочем, терпимо при скромном коллективе в восемь человек.
В таких условиях подразделение разработки вышло во второе десятилетие.
Банк развивался – развивалась и увеличивалась и команда развития АБС. При приближении к двум десяткам разработчиков начали всплывать очевидные проблемы: найти актуальный код довольно проблематично, одновременная правка одного и того же файла стала неразрешимой задачей. Отдельная история была со сборкой и развертыванием. Ведь ставилось приложение скриптом. И при этом разработчики часто копипастили нужные куски кода из одного «батника» в другой, забывая изменить их под свои особенности развертывания.
Такие побочные затраты на мелочь могли пройти незамеченными. Но наступил 2013 год., и разработчиков стало уже 50. При этом каждый тратит примерно час в неделю на привычную рутину — сборку кода в поставку, запуск отладочных тестов, «doc»-и технической спецификации. Как оказалось, в месяц эти «мелочи» сложились в сотни человеко-часов. А devops-стихия докатилась, наконец, и до нашего Банка.
Что хотелось сделать, когда перед нами поставили задачу «автоматизировать»?
Ну, для начала хотелось получить единое и, что немаловажно, удобное хранилище исходного кода. Желательно с опытом работы у большинства разработчиков, чтобы не тратить время на обучение. И ура — в это время в Банке как раз развернули Atlassian-стек со Stash-ом (оболочка для git, сейчас называется Bitbucket), под постепенную замену svn. На волне всеобщего перемещения туда же “заехали” и мы.
Супер! Одна хотелка воплотилась в жизнь.
Но остался один нюанс — тексты по-прежнему должны были быть скопированы на сервер для компиляции и развертывания. При использовании RDi это можно было сделать без особых проблем. Правда, вести одновременно проект в RDi и git довольно неудобно. RDi работает с «родной» файловой структурой сервера и накладывает свои ограничения на структуру проекта.
Попробовали iProject, который наследует эту специфику. Да, он позволяет работать с исходниками на локальных машинах, имеет встроенную поддержку git. Но ограничен исключительно линейной структурой проекта, отягощен метаданными для совместимости с родной файловой системе IBM i.
Одним словом, полно всяких ограничений и в целом также неудобно как и работа с SEU.
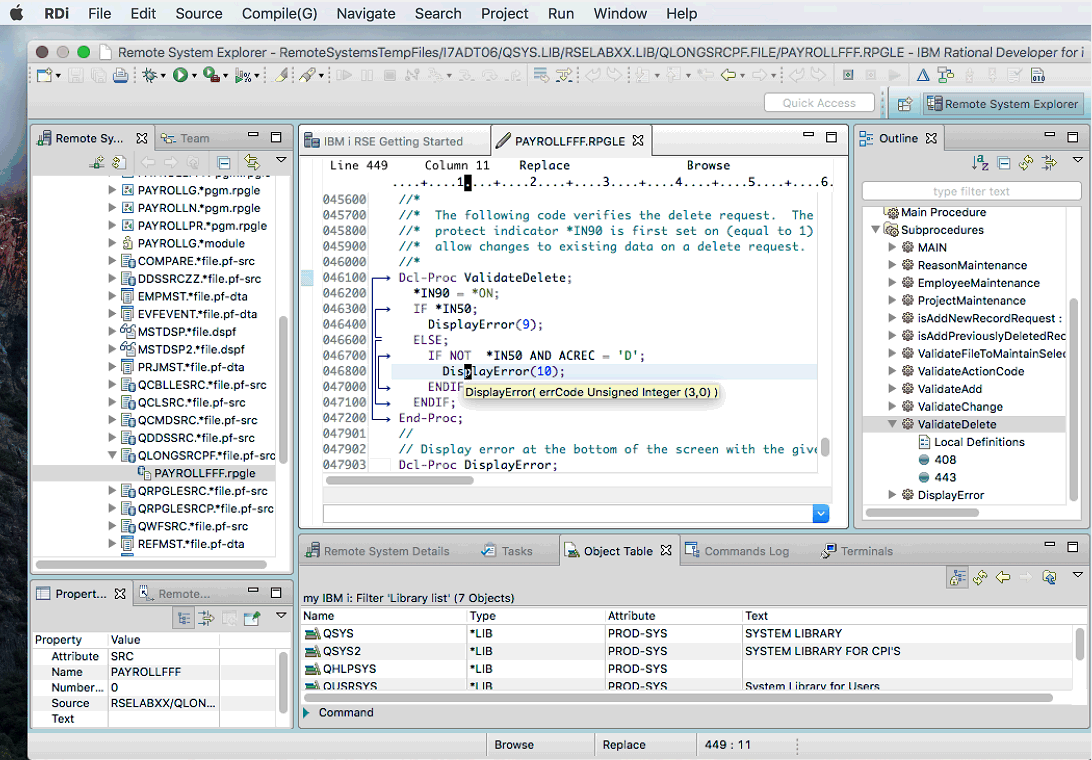
Так выглядит RDi — IDE от IBM
Надо искать дальше.
Следующая хотелка — сделать конфигурацию развертывания унифицированной. Главное, с минимальной спецификой или вовсе «без самодеятельности». Пришлось подбирать комплексный инструмент для Continuous Integration.
На рынке готовых к использованию инструментов не оказалось. Везде нужно приспосабливаться, существенно тратиться на начальную адаптация и дальнейшую поддержку CI.
Наши требования были следующими:
В целом все коммерческие продукты отличаются поддержкой распространенных инструментов. Но сложности начинаются, когда дело доходит до особенностей интеграции в конкретных условиях организации. Продукты от ключевых поставщиков IBMi-автоматизации — компаний ARCAD и UrbanCode, к сожалению, разочаровали. Прежде всего отсутствием гибкой интеграции с нашим сервером. Адаптировать внешние решения под уже используемые нами инструменты компиляции было либо слишком дорого, либо вовсе невозможно.
Оценив сложности, перспективы и необходимые вложения, решили пойти собственным путем — построить свой лунапарк, с “инсами” и автотестами.
Начали вроде бы с простого, с определения языка нотации, на котором будем описывать сборку. Изначально пробовали JSON. Он прост и понятен, очень распространен.
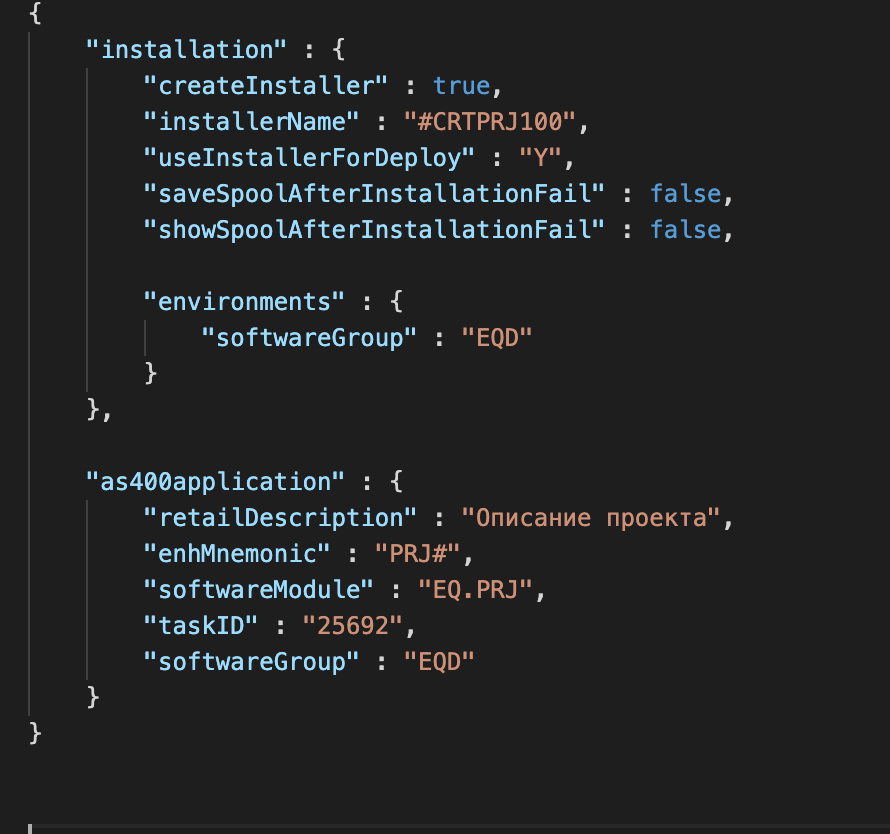
JSON-декларатив для проекта
Но при этом для JSON пришлось бы писать собственный парсер конфига и реализовывать все сборочные фичи «с нуля». Выглядело не очень впечатляюще.
Поштормив разные варианты, пришли к выводу, что лучше использовать уже готовый инструмент, предоставляющий базовые “плюшки из коробки”. Но при этом адаптируемый под наши требования. Остановились на сборщике последнего поколения – gradle. Наследует возможности и maven, и ant, прост в конфигурировании, расширяется плагинами, обладает гибкостью сборки по зависимостям, вполне скоростной, т.к. поддерживает кэширование в инкрементальных сборках.
В итоге через 4 месяца удалось выпустить первую версию собственного gradle-плагина для сборки и развертывания приложений под мейнфрейм IBM i.
Сборщик выполнил свою функцию на «ура»! Спрятал в себе всю «кухню» доставки кода на сервер и компиляции, опубликовав потребителю типичные task-и: «собрать и развернуть на dev», «сформировать и опубликовать поставку», «развернуть поставку на среде». Стоит отдать дань уважения IBM за публикацию пакета jt400.jar, который позволяет полноценно работать со всеми сервисами IBMi через java-интерфейс.
Из ручного скрипта развертывания на командном языке операционки:
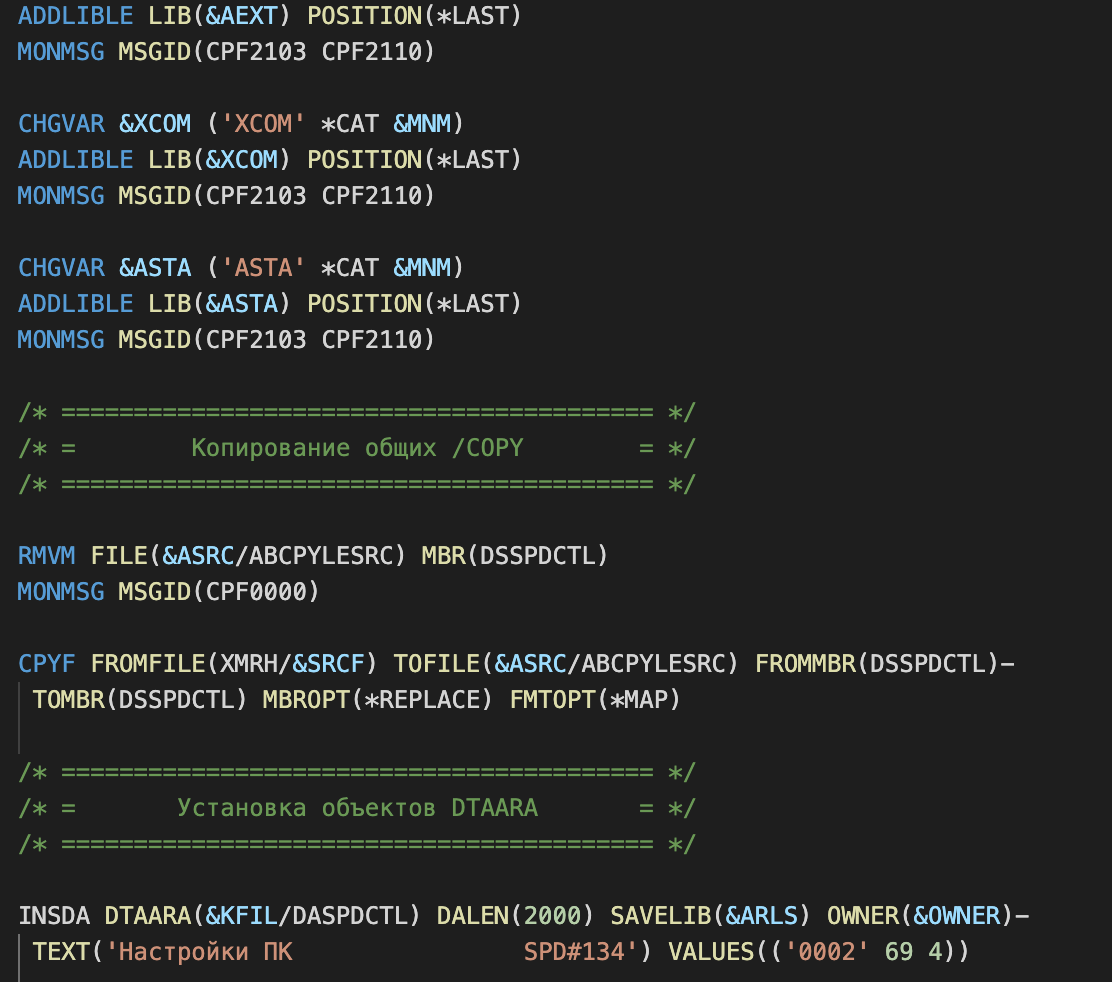
CL — основной язык для скриптов развертывания на сервере
перешли на совершенно новый уровень описания build-а.
Описание сценария стало «красивым», но не перестало занимать время. Только через несколько месяцев «мучений» перешли на декларативное описание приложения и «экономный» build.gradle:

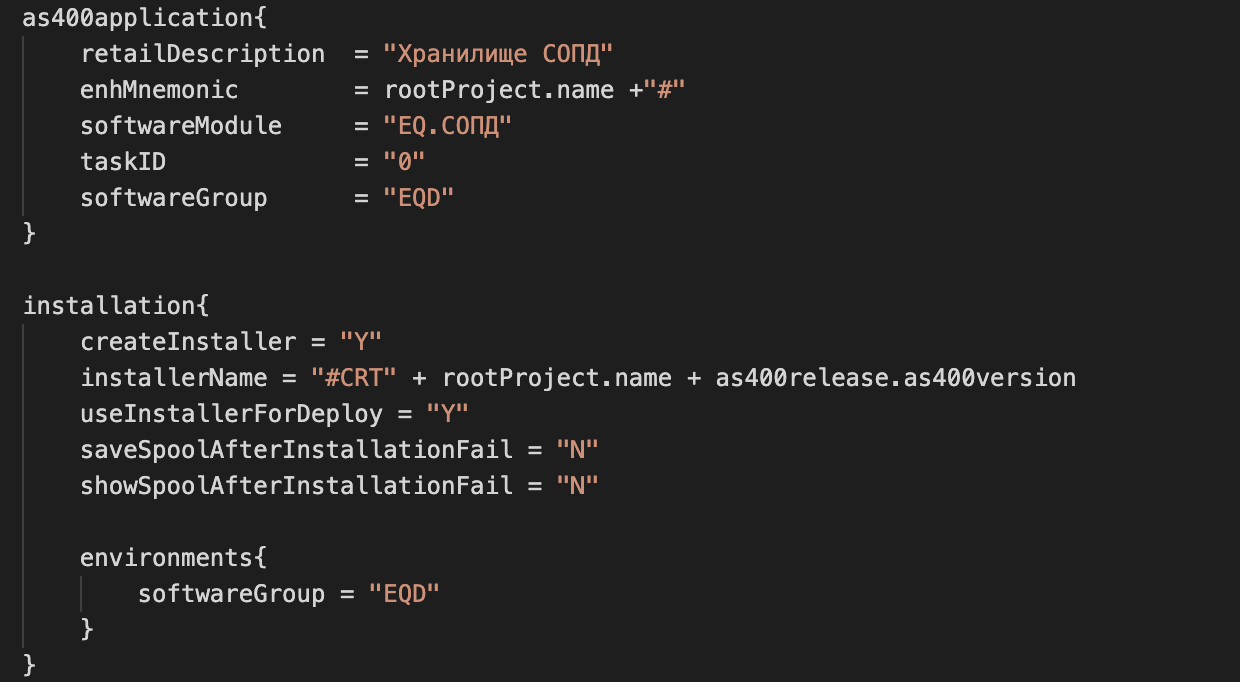
Вот такие «накопительные» скрипты теперь пишут разработчики
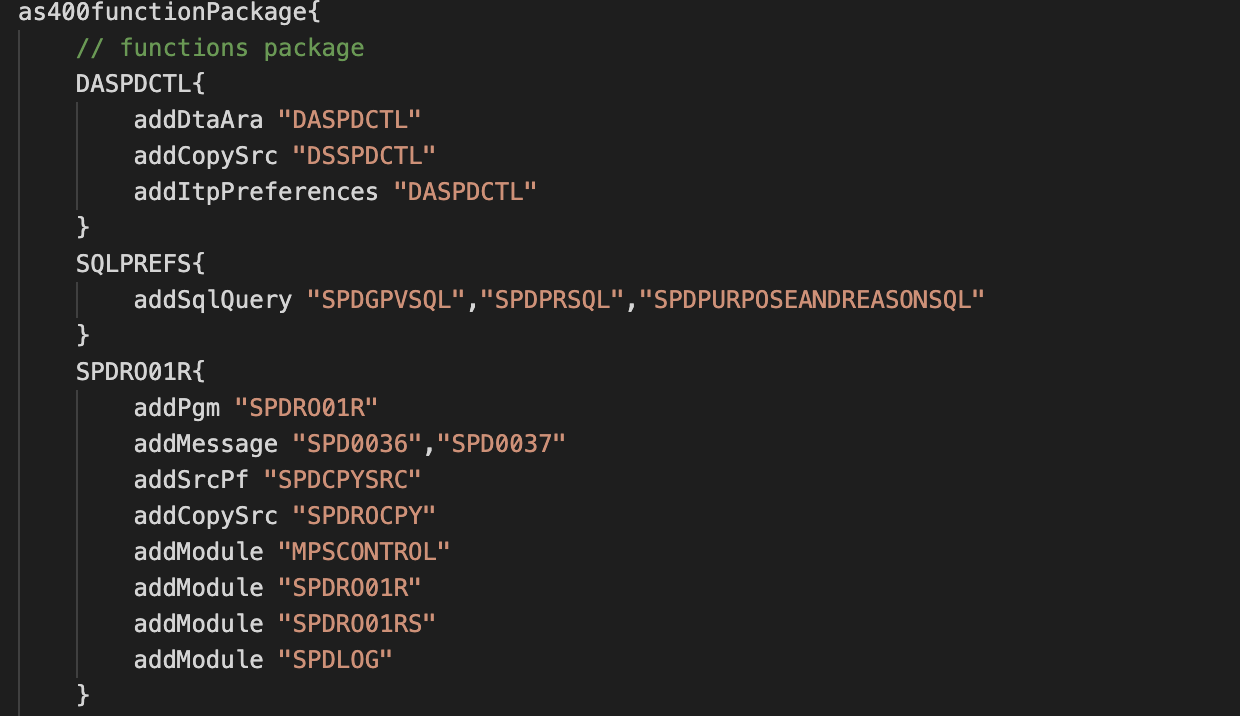
А еще через некоторое время пришли и к поддержке модульности:
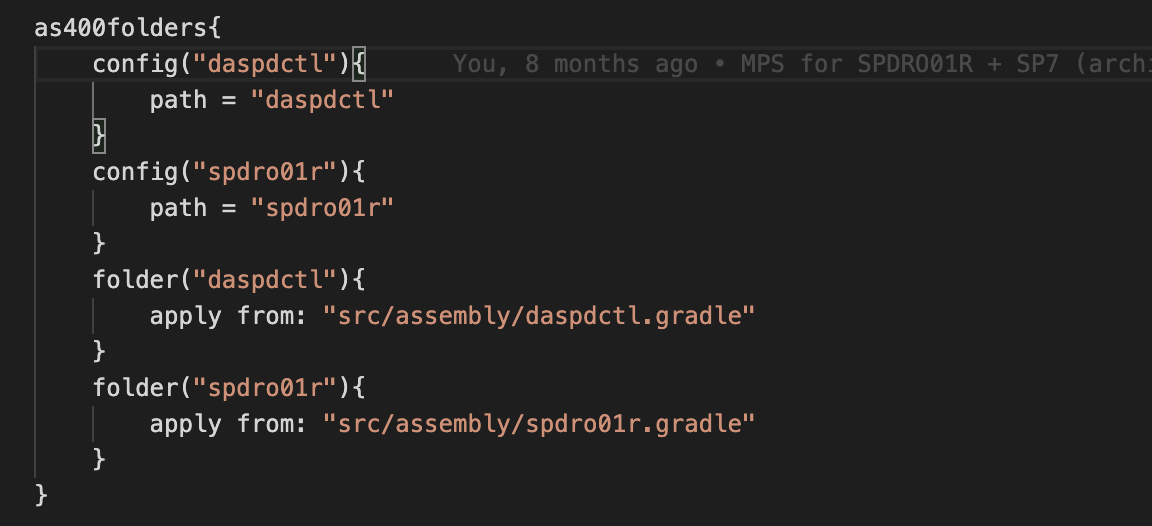
С делением на модули стало проще организовывать большой проект
Не обошлось, конечно, без сложностей переезда. Нужно было и активно развивать новый инструмент по нужды трудящихся, и переводить этих самых трудящихся на новые инструменты, и допиливать множество уже существовавших на тот момент утилит под новые «рельсы» (ведь раньше разработчик лично запускал их, а теперь это делает автомат). Конечно, самым непростым моментом была миграция разработчиков на новые стандарты, новые инструменты. Вовсю приходилось бороться с силой привычки и годами накопленным консерватизм.
Стоит отметить, что, как и во многих иных организациях, сформировать постоянно выделенную на devops-нужды команду нам не удалось. В итоге поддержка и доработка CI-инструментов осуществляется всем сообществом IBMi-разработчиков. По крайней мере мы стараемся прийти к распределенной и сбалансированной «контрибуции». Если кому-то нужна какая-то доработка, он делает это сам.
Таким образом, освоив и стабилизировав базовый CI-функционал, вспомнили про автоматизированное управление качеством. Сборка есть, доставка — есть, тестов нет. Чего-то внятного и распространенного, как оказалось, для платформы нет. Есть опять же ARCAD, но от него отказались еще на прошлом этапе. Мы вполне понимали, что добавление автотестирования — это весьма важный эволюционный шаг, без которого не бывает полноценного Continuous Integration; должных скорости и качества без этого не достичь. Также сразу учитывали, что придется менять многолетние привычки по кодированию тестов, и это отдельная история, которую предстояло пройти.
В Альфе развитие автотестирования развивалось двумя параллельными историями: автотесты пользовательских интерфейсов через GUI и тестирование без GUI (мы же все-таки backend-разработчики). При этом продуктовые команды самостоятельно пилили инструменты, в первую очередь под свои нужды.
Тут стоит упомянуть, что ввиду большого количества разработчиков и разброса их по регионам обмен опытом и информацией далеко не моментальный. Поэтому когда команды что-то там пилили для себя, мало кто об этом знал. Подобные реализации документировались и тиражировались слабо. Часто нужно было проявить недюжинные волю и упорство для добычи информации и правильного применения «чужого» инструмента.
В распространении новых веяний среди сообщества нам очень помогли ставшие уже традиционными митапы IBMi-разработчиков. Первый прошел еще в декабре 2017 года. Причем совсем не в том скучном формате «партийного собрания», когда один вещает о «пятилетке», а остальные спят или хлопают. Вот как это было на последнем митапе —
На мероприятии команды могут познакомить других разработчиков со своими наработками, получить фидбэк, наладить межкомандные взаимодействия. Митап стал неким рынком-супермаркетом: у всех есть что-то интересное, что можно попробовать другим; а если уже успели попробовать, то обсудить дальнейшее развитие и, возможно, получить соответствующую помощь. Кроме сообщества Альфа-Банка участвуют еще и разработчики из других компаний. Поэтому ежегодный IBMi Dev MeetUp стал для нас важной информационной площадкой, двигателем прогресса в сообществе, местом обмена знаниями и технологиями.
На текущий момент развитие производственного инструментария самим сообществом — это основной двигатель прогресса в автоматизации разработки на стеке IBM i. Каждый может прийти с предложением, каждый может поучаствовать в развитии CI/CD и этим прокачать свои «скилы». Мы часто говорим о мотивации. Говорим, что нас заставляют заниматься шаблонными задачами в угоду бизнеса. В нашем же случае речь про другое. Речь про творческую, исследовательскую работу. Здесь разработчики могут, соблюдая определенные рамки, сам принимать решения что делать и что не делать, их не надо заставлять работать больше или меньше. Все делается «по вштыру». В итоге же получается не продукт, который можно гордо положить в стол. Совсем нет. Получается продукт, которым пользуются все коллеги в организации. А сейчас мы применяем подход, когда продуктом могут пользоваться (и покупать) другие компании. Проходим сертификацию Роспотребнадзора. Вот, например, наша публикация про софт, который прошел такую сертификацию.
Инструментарий CI/CD активно продолжает развиваться и оптимизироваться. Например, продолжается работа над системой зависимостей между объектами внутри одного проекта так и между проектами. IBM тоже не стоит на месте и внедряет новые, удобные фишки в свои средства разработки.
Возможно, кто-то из читателей не только заинтересуется нашим опытом, но предложит дельные идеи по дальнейшему пути совершенствования. Будем только рады вашей поддержке.
Спасибо.
История становления и развития свойственна не только людям. Совершенствуя себя, мы совершенствуем и те вещи, которые делаем.

Не исключение и наш Банк, со временем обросший паутиной многочисленных IT-решений, в центре которой находится автоматизированная банковская система Equation (АБС). Меня же зовут Кирилл Диброва. Я занимаюсь функциональным и архитектурным развитием Equation — огромного и весьма важного для Банка программного комплекса; совсем не похожего на типичные реализации современного разработчика.
В этом посте хочу рассказать вам о той вынужденной «промышленной революции», которую пришлось осуществить devops-инженерам АБС. Итак…
Начало пути
Давным-давно, в забытом 2002-ом, в «далекой-далекой галактике», разработчики нашего Банка начали дорабатывать «свежевнедренную» и вполне популярную на тот момент АБС Equation. Как оказалось, это такой огромный бизнес-монолит, крутящийся под мейнфреймом IBM, именуемым, на тот момент, AS/400. И использовали они для этого вполне “современный” на то время IDE – терминальный редактор SEU (source entry utility)

SEU, «современный» редактор исходных текстов для IBM i
Согласитесь, сейчас выглядит, как спецэффекты в “Звездных войнах” 78-го года — сурово и беспощадно.
Где-то в середине нулевых компания IBM все же смилостивилась над свои разработчиками и выпустила «Rational Application Developer for iSeries» (позже Rational Develop for I или сокращенно Rdi). Жить стало веселей — это и современные оконный интерфейс, и довольно удобный инструментарий для взаимодействия с сервером, и поддержка синтаксиса основного языка разработки RPGLE. Но, тем не менее, код все так же хранился и правился в рамках специализированной файловой системы мейнфрейма. А без полноценной истории изменений и иных важных фишек SCM работать над кодом совместно было весьма сложно.
Впрочем, терпимо при скромном коллективе в восемь человек.
В таких условиях подразделение разработки вышло во второе десятилетие.
Познай себя
Банк развивался – развивалась и увеличивалась и команда развития АБС. При приближении к двум десяткам разработчиков начали всплывать очевидные проблемы: найти актуальный код довольно проблематично, одновременная правка одного и того же файла стала неразрешимой задачей. Отдельная история была со сборкой и развертыванием. Ведь ставилось приложение скриптом. И при этом разработчики часто копипастили нужные куски кода из одного «батника» в другой, забывая изменить их под свои особенности развертывания.
Такие побочные затраты на мелочь могли пройти незамеченными. Но наступил 2013 год., и разработчиков стало уже 50. При этом каждый тратит примерно час в неделю на привычную рутину — сборку кода в поставку, запуск отладочных тестов, «doc»-и технической спецификации. Как оказалось, в месяц эти «мелочи» сложились в сотни человеко-часов. А devops-стихия докатилась, наконец, и до нашего Банка.
Тренировка
Что хотелось сделать, когда перед нами поставили задачу «автоматизировать»?
Ну, для начала хотелось получить единое и, что немаловажно, удобное хранилище исходного кода. Желательно с опытом работы у большинства разработчиков, чтобы не тратить время на обучение. И ура — в это время в Банке как раз развернули Atlassian-стек со Stash-ом (оболочка для git, сейчас называется Bitbucket), под постепенную замену svn. На волне всеобщего перемещения туда же “заехали” и мы.
Супер! Одна хотелка воплотилась в жизнь.
Но остался один нюанс — тексты по-прежнему должны были быть скопированы на сервер для компиляции и развертывания. При использовании RDi это можно было сделать без особых проблем. Правда, вести одновременно проект в RDi и git довольно неудобно. RDi работает с «родной» файловой структурой сервера и накладывает свои ограничения на структуру проекта.
Попробовали iProject, который наследует эту специфику. Да, он позволяет работать с исходниками на локальных машинах, имеет встроенную поддержку git. Но ограничен исключительно линейной структурой проекта, отягощен метаданными для совместимости с родной файловой системе IBM i.
Одним словом, полно всяких ограничений и в целом также неудобно как и работа с SEU.

Так выглядит RDi — IDE от IBM
Надо искать дальше.
Следующая хотелка — сделать конфигурацию развертывания унифицированной. Главное, с минимальной спецификой или вовсе «без самодеятельности». Пришлось подбирать комплексный инструмент для Continuous Integration.
На рынке готовых к использованию инструментов не оказалось. Везде нужно приспосабливаться, существенно тратиться на начальную адаптация и дальнейшую поддержку CI.
Наши требования были следующими:
- должен поддерживаться git в качестве хранилища исходных кодов;
- должен быть инструмент для автоматизации процесса в целом как, например, jenkins или atlassian bamboo, или поддержка использования вышеупомянутых комплексов;
- проект должен иметь гибкую файловую структуру проекта а-ля maven от apache;
- сценарии доставки должны быть гибкими и позволять использовать по-максимуму уже существующие инструменты для компиляции и развертывания;
- инструментарий должен позволять писать тестовые сценарии разного уровня.
В целом все коммерческие продукты отличаются поддержкой распространенных инструментов. Но сложности начинаются, когда дело доходит до особенностей интеграции в конкретных условиях организации. Продукты от ключевых поставщиков IBMi-автоматизации — компаний ARCAD и UrbanCode, к сожалению, разочаровали. Прежде всего отсутствием гибкой интеграции с нашим сервером. Адаптировать внешние решения под уже используемые нами инструменты компиляции было либо слишком дорого, либо вовсе невозможно.
Оценив сложности, перспективы и необходимые вложения, решили пойти собственным путем — построить свой лунапарк, с “инсами” и автотестами.
Начали вроде бы с простого, с определения языка нотации, на котором будем описывать сборку. Изначально пробовали JSON. Он прост и понятен, очень распространен.

JSON-декларатив для проекта
Но при этом для JSON пришлось бы писать собственный парсер конфига и реализовывать все сборочные фичи «с нуля». Выглядело не очень впечатляюще.
Поштормив разные варианты, пришли к выводу, что лучше использовать уже готовый инструмент, предоставляющий базовые “плюшки из коробки”. Но при этом адаптируемый под наши требования. Остановились на сборщике последнего поколения – gradle. Наследует возможности и maven, и ant, прост в конфигурировании, расширяется плагинами, обладает гибкостью сборки по зависимостям, вполне скоростной, т.к. поддерживает кэширование в инкрементальных сборках.
В итоге через 4 месяца удалось выпустить первую версию собственного gradle-плагина для сборки и развертывания приложений под мейнфрейм IBM i.
Сборщик выполнил свою функцию на «ура»! Спрятал в себе всю «кухню» доставки кода на сервер и компиляции, опубликовав потребителю типичные task-и: «собрать и развернуть на dev», «сформировать и опубликовать поставку», «развернуть поставку на среде». Стоит отдать дань уважения IBM за публикацию пакета jt400.jar, который позволяет полноценно работать со всеми сервисами IBMi через java-интерфейс.
Из ручного скрипта развертывания на командном языке операционки:

CL — основной язык для скриптов развертывания на сервере
перешли на совершенно новый уровень описания build-а.
Описание сценария стало «красивым», но не перестало занимать время. Только через несколько месяцев «мучений» перешли на декларативное описание приложения и «экономный» build.gradle:



Вот такие «накопительные» скрипты теперь пишут разработчики
А еще через некоторое время пришли и к поддержке модульности:

С делением на модули стало проще организовывать большой проект
Не обошлось, конечно, без сложностей переезда. Нужно было и активно развивать новый инструмент по нужды трудящихся, и переводить этих самых трудящихся на новые инструменты, и допиливать множество уже существовавших на тот момент утилит под новые «рельсы» (ведь раньше разработчик лично запускал их, а теперь это делает автомат). Конечно, самым непростым моментом была миграция разработчиков на новые стандарты, новые инструменты. Вовсю приходилось бороться с силой привычки и годами накопленным консерватизм.
Развитие
Стоит отметить, что, как и во многих иных организациях, сформировать постоянно выделенную на devops-нужды команду нам не удалось. В итоге поддержка и доработка CI-инструментов осуществляется всем сообществом IBMi-разработчиков. По крайней мере мы стараемся прийти к распределенной и сбалансированной «контрибуции». Если кому-то нужна какая-то доработка, он делает это сам.
Таким образом, освоив и стабилизировав базовый CI-функционал, вспомнили про автоматизированное управление качеством. Сборка есть, доставка — есть, тестов нет. Чего-то внятного и распространенного, как оказалось, для платформы нет. Есть опять же ARCAD, но от него отказались еще на прошлом этапе. Мы вполне понимали, что добавление автотестирования — это весьма важный эволюционный шаг, без которого не бывает полноценного Continuous Integration; должных скорости и качества без этого не достичь. Также сразу учитывали, что придется менять многолетние привычки по кодированию тестов, и это отдельная история, которую предстояло пройти.
В Альфе развитие автотестирования развивалось двумя параллельными историями: автотесты пользовательских интерфейсов через GUI и тестирование без GUI (мы же все-таки backend-разработчики). При этом продуктовые команды самостоятельно пилили инструменты, в первую очередь под свои нужды.
Тут стоит упомянуть, что ввиду большого количества разработчиков и разброса их по регионам обмен опытом и информацией далеко не моментальный. Поэтому когда команды что-то там пилили для себя, мало кто об этом знал. Подобные реализации документировались и тиражировались слабо. Часто нужно было проявить недюжинные волю и упорство для добычи информации и правильного применения «чужого» инструмента.
В распространении новых веяний среди сообщества нам очень помогли ставшие уже традиционными митапы IBMi-разработчиков. Первый прошел еще в декабре 2017 года. Причем совсем не в том скучном формате «партийного собрания», когда один вещает о «пятилетке», а остальные спят или хлопают. Вот как это было на последнем митапе —
На мероприятии команды могут познакомить других разработчиков со своими наработками, получить фидбэк, наладить межкомандные взаимодействия. Митап стал неким рынком-супермаркетом: у всех есть что-то интересное, что можно попробовать другим; а если уже успели попробовать, то обсудить дальнейшее развитие и, возможно, получить соответствующую помощь. Кроме сообщества Альфа-Банка участвуют еще и разработчики из других компаний. Поэтому ежегодный IBMi Dev MeetUp стал для нас важной информационной площадкой, двигателем прогресса в сообществе, местом обмена знаниями и технологиями.
На текущий момент развитие производственного инструментария самим сообществом — это основной двигатель прогресса в автоматизации разработки на стеке IBM i. Каждый может прийти с предложением, каждый может поучаствовать в развитии CI/CD и этим прокачать свои «скилы». Мы часто говорим о мотивации. Говорим, что нас заставляют заниматься шаблонными задачами в угоду бизнеса. В нашем же случае речь про другое. Речь про творческую, исследовательскую работу. Здесь разработчики могут, соблюдая определенные рамки, сам принимать решения что делать и что не делать, их не надо заставлять работать больше или меньше. Все делается «по вштыру». В итоге же получается не продукт, который можно гордо положить в стол. Совсем нет. Получается продукт, которым пользуются все коллеги в организации. А сейчас мы применяем подход, когда продуктом могут пользоваться (и покупать) другие компании. Проходим сертификацию Роспотребнадзора. Вот, например, наша публикация про софт, который прошел такую сертификацию.
Планы на будущее
Инструментарий CI/CD активно продолжает развиваться и оптимизироваться. Например, продолжается работа над системой зависимостей между объектами внутри одного проекта так и между проектами. IBM тоже не стоит на месте и внедряет новые, удобные фишки в свои средства разработки.
Возможно, кто-то из читателей не только заинтересуется нашим опытом, но предложит дельные идеи по дальнейшему пути совершенствования. Будем только рады вашей поддержке.
Спасибо.
