

Посвящается моему коллеге и наставнику по Informatica Максиму Генцелю, который умер от COVID-19 21.01.2021
Привет! Меня зовут Баранов Владимир, и я уже несколько лет администрирую Informatica в «Альфа-Банк». В статье я поделюсь опытом работы с Informatica PowerCenter. IPC это платформа, которая занимается ETL (Extract, Transformation, Loading). Я сосредоточусь на описании конкретных кейсов и решений, расскажу о некоторых тонкостях и постараюсь дать пищу для ума.
В работе приходится часто сталкиваться с проблемами производительности и стабильности платформы, при этом глубоко во всё вникая, поэтому лично я при работе с Informatica получаю огромное удовольствие. Во-первых, потому, что даже IPC сам по себе не такой уж маленький, а у Informatica целое семейство продуктов. Во-вторых, ETL находится на стыке разных систем, надо знать всего понемногу – базы данных, коннекторы, линукс, скриптовые языки и системы визуализации и мониторинга. В-третьих, это общение с большим количеством разных людей и много интересных задач.
Запуск клиента информатики
Забавно, но даже тут можно наступить на некоторые грабли. Да, прямо на старте и с размахом.
У информатики есть следующие клиенты: Workflow Manager, Workflow Monitor, Repository Manager, Designer и Developer Client. Параметры подключения к репозиториям хранятся в файле domains.infa, который обычно задаётся переменной окружения:
SET INFA_DOMAINS_FILE=C:\Informatica\9.5.1\clients\PowerCenterClient\domains.infa
Но если версий информатики несколько, то файл рано или поздно будет «побит», а клиент информатики будет ругаться при попытке сохранения добавленного репозитория.
Что делать? Создать батники для каждой версии клиента вида:
SET INFA_DOMAINS_FILE=C:\Informatica\9.5.1\clients\PowerCenterClient\domains.infa
cd C:\Informatica\9.5.1\clients\PowerCenterClient\client\bin\
start pmdesign.exeПоследние две строчки попортили мне очень много крови, так как изначально я запускал клиента так:
C:\Informatica\9.5.1\clients\PowerCenterClient\client\bin\pmdesign.exeИ батник прекрасно работал ровно до того момента, пока я не обновился с 9.5.1 до 10.1.1 и не начал пытаться подключаться через клиент информатики к SAP.
Disigner должен был показывать коннекты из файла sapnwrfc.ini, но показывалась пустота, хотя файл лежал в нужном каталоге клиента IPC. Я даже успел немного посидеть с отладчиком над клиентом, но в итоге мне помогла индианка из службы поддержки.
Что ещё можно сказать о файле domains.infa и создании подключений? Вы не сможете единовременно добавить два репозитория с одинаковым именем, даже если они находятся на разных серверах.
Файл domains.infa также используется при использовании консольных команд для подключения к репозиторию* (pmrep), имейте это в виду. Но об этом чуть позже.
*На самом деле не обязательно, смотрите на описание ключей команды.
Настраиваем окружение
Что важного может быть в окружении Informatica? Если вы обратитесь в поддержку Информатики, то первым делом вас попросят показать вывод команд:
ulimit –Ha / ulimit –Sa. Soft и hard ограничения пользователя, под которым запущена информатика). stack size 10240
open files (-n) 500000
Сколько ставить open files? Поддержка Informatica как-то утверждала, что у нас одна из самых высоконагруженных и сложных инсталляций в России – при этом нам хватает 500к open files, с запасом примерно в 150-250к.
На многих серверах стоит по 120-180к, и этого хватает. Со временем (и в случае нашего банка это происходит очень быстро) приходится увеличивать.
Однажды видел, как ведёт себя Oracle, если ему не хватает максимально открытых файлов. Он периодически начинает ощутимо тормозить, клиенты от него отваливаются. Но при этом он оставался работать и не падал.
Если вы не знаете, какое текущее значение у уже запущенного процесса:
cat /proc/pid/limitsmax user processes (-u) 4134885
Важный параметр, но ничего особенно интересного про него рассказать не могу.
core file size (blocks, -c)
Потенциально опасный параметр. Дампы памяти от падаюших сервисов или потоков можно проанализировать (иногда помогает поиск по ключевым словам в базе знаний информатики), их также требует поддержка Informatica. По умолчанию они будут падать в $INFA_HOME/server/bin/ и главное — core могут быть очень большими.
Имеет смысл следить за этим каталогом и аккуратно его чистить.
Теперь не такое очевидное:
/etc/systemd/system.conf, /etc/systemd/user.conf
DefaultTasksMax=40000
DefaultLimitNOFILE=500000Более подробно о TasksMax:
To control the default TasksMax= setting for services and scopes running on the system, use the system.conf setting DefaultTasksMax=. This setting defaults to 512, which means services that are not explicitly configured otherwise will only be able to create 512 processes or threads at maximum.
For thread- or process-heavy services, you may need to set a higher TasksMax value. In such cases, set TasksMax directly in the specific unit files. Either choose a numeric value or even infinity.
Similarly, you can limit the total number of processes or tasks each user can own concurrently. To do so, use the logind.conf setting UserTasksMax (the default is 12288).
Как можно посмотреть текущее значение:
admin@serv:/etc/systemd> systemd-analyze dump|grep -i DefaultLimitNPROC|sort -n -k2
admin@serv:/etc/systemd> systemctl show -p DefaultLimitNOFILE
admin@serv:/proc/38757> systemctl show -p DefaultLimitNPROC
cat /sys/fs/cgroup/pids/user.slice/user-*.slice/pids.max
cat /sys/fs/cgroup/pids/user.slice/user-*.slice/pids.currentЕсли интересно, что это такое — гуглить «linux cgroup slices»:
Что будет в системных логах, если TaskMax недостаточен:
2020-01-01T03:23:30.674392+03:00 serv kernel: [5145583.466931] cgroup: fork rejected by pids controller in /user.slice/user-*.slice/session-2247619.scope
Кстати
*Вообще, думаю что имеет смысл прочитать требования к окружению при установке разных БД — там очень дельные предложения по окружению. Было немного обидно, когда ровно на следующей день после обнаружения проблемы с TaskMax я прочитал о них в гайде по установке Teradata.
/etc/sysctl.conf
fs.file-max = 6815744Тут тоже особо не заостряю внимания.
Сеть, sysctl, net.core, net.iipv4
Чтобы что-то тут менять — надо очень хорошо понимать, как работает сеть, ядро, сокеты. Бездумное изменение параметров может сделать только хуже. Не буду здесь приводить конкретных настроек, так как у меня до сих пор фрагментированное понимание этой части sysctl. Хотелось бы, чтобы гайды о сетевой части sysctl сопровождали примерами из netstat -sn и netstat -an.
Кейсы по архитектурным ошибкам
Всё, что я напишу ниже, следует читать осторожно, сознавая что обычный разработчик, который работает с Informatica каждый день, может обладать куда большей экспертизой, чем я.
1. GRID
Информатика может иметь все сервисы на одной машине, а может существовать в виде кластера и балансировать нагрузку между нодами. Даже если вы в ближайшем будущем не планируете использовать кластер, всё же крайне желательно, чтобы разработка велась так, как будто это может произойти в будущем. Вертикальная масштабируемость конечна, сидеть на ней без возможности в любой момент переключиться на горизонтальную — это как сидеть на пороховой бочке.
Я не имел личного опыта работы с гридом, но много людей отзывались о нём негативно. Грид определённо не только решает проблемы, но и добавляет новые. Тем не менее, я знаю организации, у которых всё работает именно на гриде. Надеюсь, у меня будет возможность познакомиться с ним поближе и набить уже своих шишек.
Очень наглядный гайд по созданию грида видел у nutanix.
2. Pushdown
К разработке может быть несколько подходов:
- Всю работу по части ETL выполнять на стороне информатики, постоянно подтягивая в неё данные.
- Всю работу по части ETL выполнять на стороне СУБД приёмника/таргета, использовать дблинки.
Второй вариант и есть так называемый pushdown optimization. Тут сразу уточню, что у информатики есть свои крутые механизмы для pushdown optimization, которые позволяют, например, переносить логику трансформации на source/target — но я говорил не про эти механизмы, а про общие принципы.
Ведь как правило незачем тягать данные на сервер информатики и нагружать его, если source & target находятся в пределах одной БД — лучше сделать процедуру.
На Хабре выходила отличная статья от DIS, где они рассказывали про pushdown на русском, рекомендую к прочтению.
3. Информатика как шедулер
Большинство компаний используют информатику в качестве эдакого шедулера для запуска потоков и не перекладывают на неё вычисления, если это можно сделать на стороне БД. И во всех организациях присутствует дополнительная сущность в виде базы данных, которая используется в качестве управляющего механизма. Это очень удобно для выстраивания логики работы потоков и параметров их запуска (нам же нужно знать, например, какие даты мы уже успешно загрузили, успешно ли отработали потоки и т.д).
В итоге в информатике выстраивается сложная схема, когда один поток запускает десятки других потоков, в это время второй поток дожидается выполнения третьего и пятого потока, а многие-многие сессии запускают sh-файлы, которые взаимодействуют с управляющим механизмом. В некоторых потоках может быть и 1500+ запусков sh-файлов (и до 200-300 запусков одновременно).
На этапе использования sh-файла для обращения к управляющему механизму в некоторых компаниях может закладываться бомба замедленного действия, т.к в одном таком файле может быть до 4 соединений посредством sqlplus (пример работы: проверили, включен ли поток; взяли параметры запуска; записали, что поток отработал и.т.д). И это довольно неплохой способ устроить своеобразную DDoS-атаку штормом коннектов на сервер БД.
Как минимум поэтому сервер БД метаданных информатики и сервер БД управляющего механизма не должны быть в опасной близости друг от друга. И конечно, бест практик не размещать сервер БД, хранящий метаданные информатики, на одной площадке*.
*На самом деле, не так уж это и критично. Но по возможности лучше этого избегать. Я видел примеры с высоконагруженными серверами информатики, где сервера БД были на этом же хосте.
4. «Оптимизация» как угроза
Если какой-нибудь поток выйдет за рамки SLA то у разработчиков и саппорта после доработки хинтами может быть большой соблазн увеличить количество параллелей, т.к это путь наименьшего сопротивления. Пересмотром запросов или архитектуры займутся в последнюю очередь, как наиболее трудозатратное. Возможно стоит мониторить как меняются параллели у потоков.
5. Параметризация
При разработке желательно подумать о том, что вот прямо завтра сервер может переехать на другой хост или в другой каталог. У потока также может сменится репозиторий или интеграционный сервис (с дева на тест, с теста на прод, например). Смену каталога тоже принято делать при обновлении IPC.
Может так сложиться, что вы решите перенести сервис на хост, где будет несколько инстансов информатики.
Посмотрим, нет ли у нас абсолютных путей до информатики в метаданных репозитория:
Предостережение: Даже селекты из метаданных информатики могут быть опасны и у поддержки IPC есть кейсы когда это реально вредило стабильности IPC. Разрешено использовать только view, список которых есть в Repository Guide.
select * from REP_NAME_TST.OPB_TASK_VAL_LIST where pm_value not like '%PMRoot%':
/informatica/pc10/server/bin/pmrep objectexport -f DMQAS_DWH -u В некоторых запущенных случаях можно обнаружить комбо:
pmcmd startworkflow -sv INT_TT_PROD -d DOMAIN_TT_PROD -u Userlogin -p MyPass -f FLOW_CONTROL_D -wait WF_CTL_ В данном случае поток запускали под пользовательской учёткой, с указанием пароля и инт.сервис+домен не был параметризирован.
С sh-файлами необходимо придерживаться тех же самых правил. Конфиги должны быть отдельно от скриптов, абсолютных путей быть не должно, только относительные. Недопустимо указание инт.сервиса, хостов и других явно зашитых параметров в sh-скрипте.
6. Репозитории, интеграционные сервисы, файловая система и лукапы
Репозитории достаточно просто переносятся с сервера на сервер, я расскажу подробнее в главе «Работа в консоли, девопс». На самом деле сущность репозитория вообще не имеет отражения на уровне файловой системы — репозиторий находится в БД-слое.
А вот интеграционные сервисы, которые привязываются к репозиторию, требуют инфраструктуры каталогов:
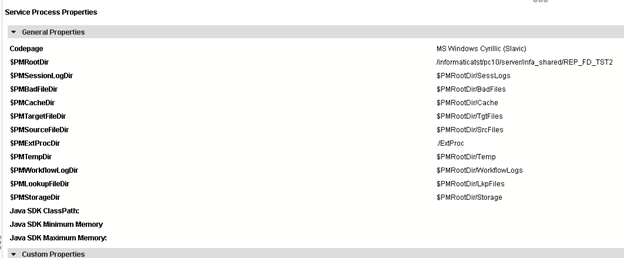
По возможности лучше разделять проекты в разные репозитории, чтобы было проще их переносить, масштабировать, актуализировать и понимать, сколько ресурсов они потребляют.
Я бы с самого начала посоветовал сделать как минимум два подкаталога с лукап кэшами. В первом каталоге можно хранить кэши временные, во втором – постоянные (persistent) кэши (не путать с именованными). И ещё, информатика обладает неприятным поведением при падениях – она не чистит за собой старые лукапы.
В «Альфа-Банке», например, раньше часть больших кэшей лежала на медленных дисках, а остальные на быстрых. Кэши в разных каталогах это довольно удобно — в любой момент можно перекинуть часть кэшей на другой массив, оставив симлинк. Это проще, чем когда все кэши находятся в одном месте.
В
$PMCacheDir по умолчанию создаются временные кэши, но это не значит, что при создании лукапа нельзя указать, например, $PMRootDir/New_Cache.Также хочу обратить внимание, что в случае, когда у персистент-лукапов добавляются или меняются поля – эти лукапы будут полностью перестраиваться, создавая в каталоге свою полную копию (*.bak). Это может сыграть злую шутку, если лукап весит 300-500 гб. В целом, грамотное использование лукапа значительно увеличивает производительность.
Обратите внимание на именование лукапов, которые создаёт информатика на уровне ФС:
ls PMLKUP629*
PMLKUP629_21_0_247034L64.dat0
PMLKUP629_21_0_247034L64.dat1
PMLKUP629_21_0_247034L64.idx0
PMLKUP629_21_0_247034L64.idx1 В начале названия файлов идёт префикс (PMLKUP), который означает, что это лукап-кэш. Помимо лукапов в CacheDir создаются джойнеры, сортировка, агрегатор и rank transformation.
Насколько я помню, после префикса идёт session_id — и это даёт возможность получить сессию, которая с ним работает в данный момент.
Определяем, кто работает с файлом кэша (возьму любой из занятых).
admin@server:/informatica/pc10/server/infa_shared/Cache> lsof +D $(pwd)
/informatica_cache/Cache/PMLKUP144968_4_0_74806582L64.idx0Греп по session_id в процессах:
ps -ef|grep 144968Отформатирую и порежу вывод, чтобы остановить ваше внимание на самых важных вещах, которые мы можем увидеть, посмотрев pmdtm-процесс.
| admin 64719 5995 pmdtm -PR –gmh server_name –gmp 2031 | UID, PID, PPID, хост Этот ID может пригодиться, если у вас было падение инт.сервиса и в системе остались старые процессы, которые будут намертво лочить запуски новых процессов, но об этом позже. |
| -s DZMTFR:WF_ N.s_m_TT_ELTA_PROQQ_DELTA | Папка в репозитории, из которого запущен workflow; Поток; сессия |
| -dn Session task instance [s_m_TT_ELTA_PROQQ_DELTA] | Инстанс |
| -run 317_87429_74806582_1_0_0_0_144968_1175115_0_ | Тут видим session id, который взяли из названия лукапа и по которому мы грепали |
-u techadmin – |
имя пользователя в информатике, запустившего поток |
| -svn INT_TT_TST | Имя int сервиса |
-dmn DOMAIN_TT_TST |
Имя домена |
| -nma server_name:5001 | Самый главный порт домена |
| -rsn REP_TT_TST | Репозиторий |
Смотрим, какие файлы занял процесс:
ls -l /proc/64719/fd/ |grep -i PMLKUP144968
/informatica_cache/Cache/PMLKUP144968_4_0_74806582L64.dat0И раз уж я начал рассказывать про pmdtm — не могу не поделится крутым параметром для отладки, которые задаётся в Custom-параметрах интеграционного сервера.
DelayDTMStart=<секунды>Чтобы ещё больше не увеличивать эту статью, просто дам ссылку.
7. Система версионности в информатике
По кейсам в базе знаний сложилось стойкое впечатление, что с ней лучше дел не иметь.
8. Логи сессий и потоков
Подробнее о логах мы говорим позже, но хочется обозначить следующее. Будьте готовы, что в большой инсталляции логи будут занимать десятки гигабайт, и количество логов сессий свободно может перевалить за 1-2 млн в зависимости от выбранной вами стратегии log-rotate.
Я не могу с уверенностью сказать, что большое количество файлов на xfs в одном каталоге влияет на производительность их загрузки, копирования или удаления в случае прямого обращения к ним, без масок. Подозреваю, что на удаление должно уходить больше времени.
При большом количестве файлов с ls могут быть проблемы (Argument list too long), но всегда есть find и exec rm, который работает значительно надёжнее, чем ls.
for i in $(ls *.mp3); do # Неправильно!
some command $i # Неправильно!
done
for i in $(ls) # Неправильно!
for i in `ls` # Неправильно!
for i in $(find . -type f) # Неправильно!
for i in `find . -type f` # Неправильно!
files=($(find . -type f)) # Неправильно!
for i in ${files[@]} # Неправильно!Хотя и к find есть вопросы по использованию памяти — не могу не порекомендовать замечательную и глубокую статью seriyPS.
Поэтому, если вы хотите обеспечить более удобный доступ к логам, лучше хранить их в разных каталогах. Как вариант — создать каталоги по имени папок в репозитории.
Пока писал это всё — появилась идея попробовать зайти на сервер по scp через far, предварительно отключив в фаре сортировку. Интересно, ускорится ли загрузка каталога и попытается ли FAR использовать ls -f (отключение сортировки) для получение списка?
Логи сессий и потоков необходимо периодически чистить.

Внимание вопрос: какая опция наиболее опасна?
В следующей части поговорим о запуске сервера, развернем репозиторий с интеграционным сервисом, изучим немного полезных консольных команд, обсудим бэкапы и узнаем, где лежат логи и как искать ошибки.
Полезные ссылки
- База знаний Informatica
- Хороший блог по Informatica с кучей годных запросов к метаданным
- Канал Informatica Support
- Куча годных видео по PowerCenter
- Пост от Ростелекома «От ежедневных аварий к стабильности» — в этой статье в доступной форме они описали что такое IPC и из каких сервисов она состоит.
