
Привет! Меня зовут Андрей, я Head of Platform в финансовом маркетплейсе Banki.ru.
Напомню, что в первой части статьи мы рассказывали о том, как внедряли площадки разработки и тестирования со времен одного монолита, что делали, чтобы поддержать переход на сервисно ориентированную архитектуру, и о многочисленных проблемах «Склянок 2.0», которые в итоге пришлось как-то решать. Под катом рассказ о том, как мы решили проблемы и что у нас получилось.
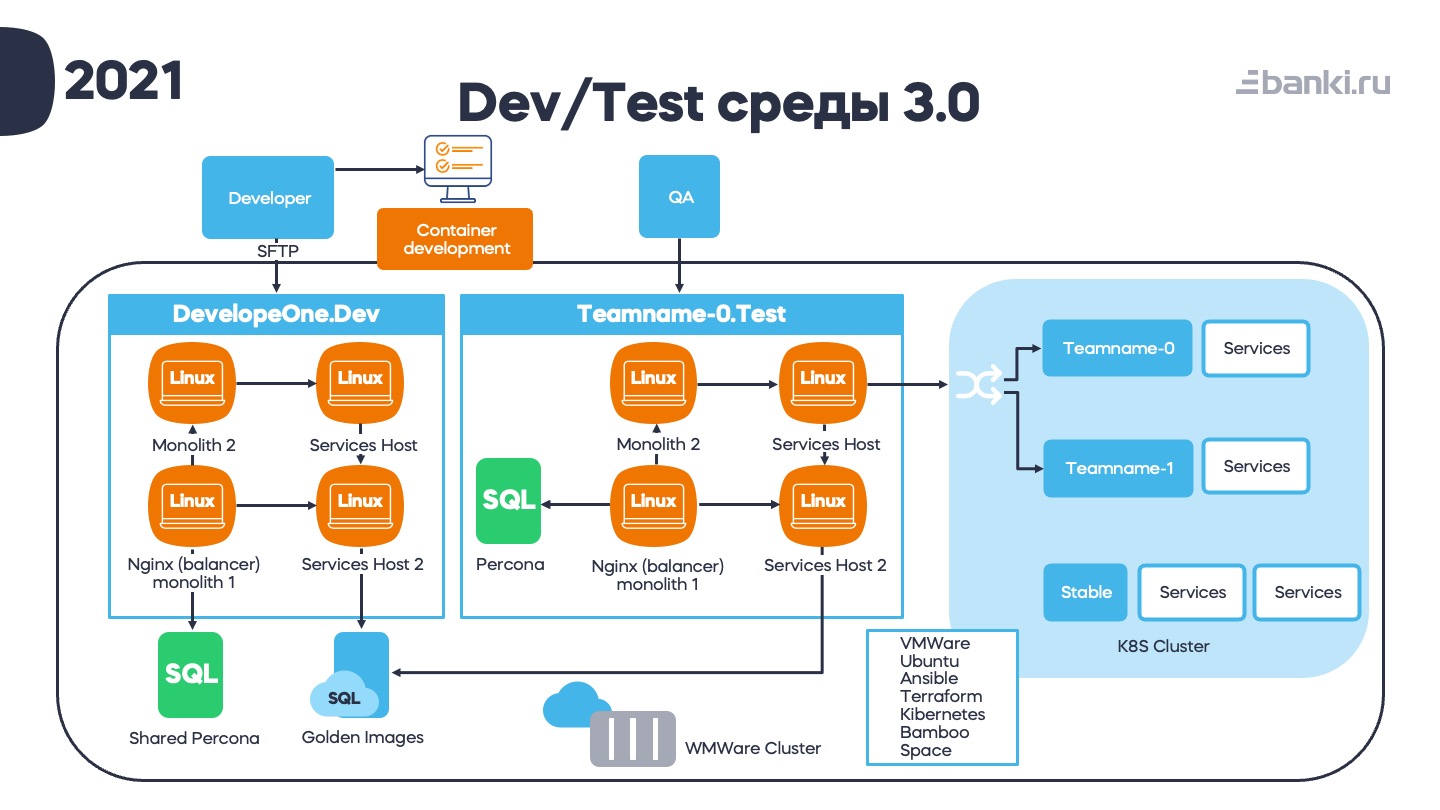
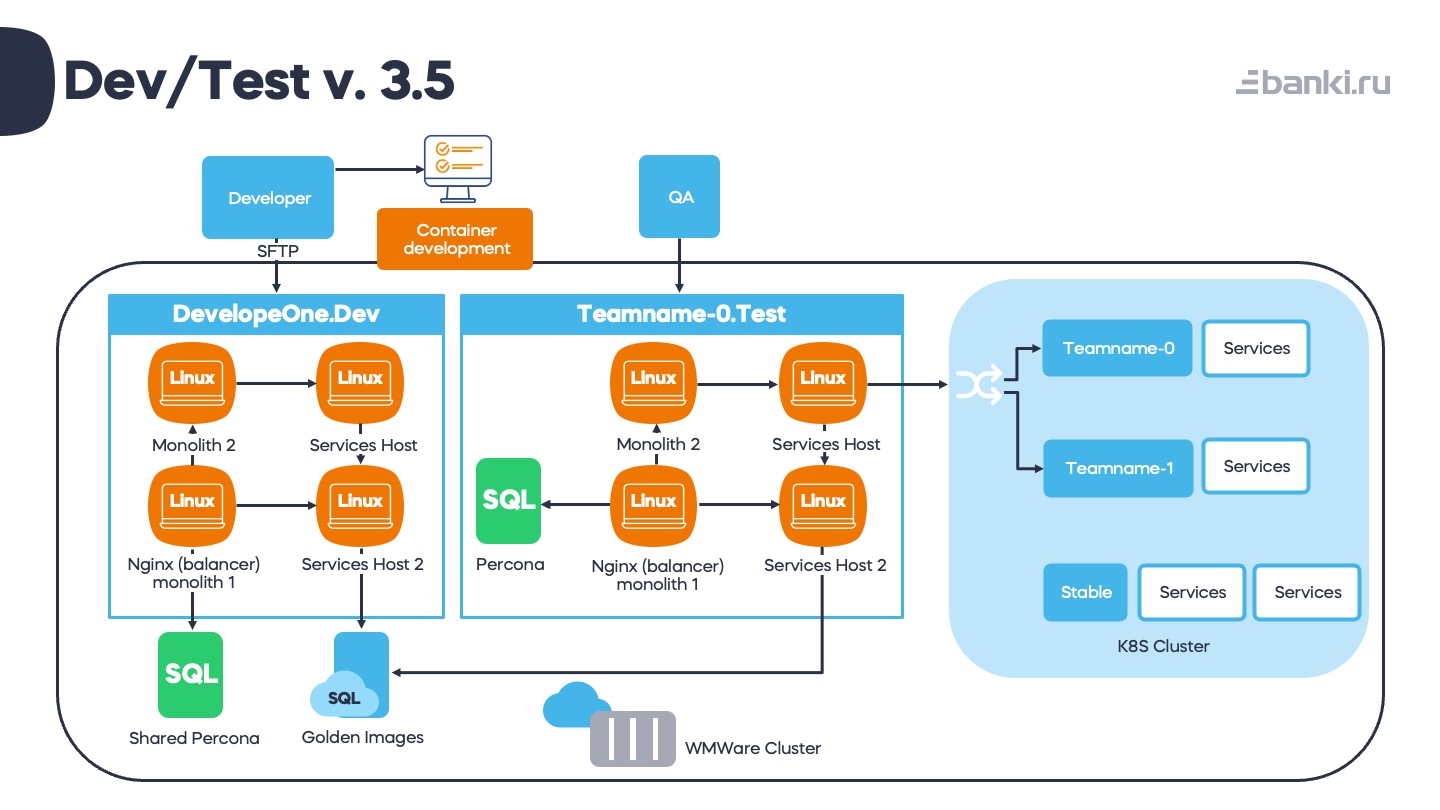
Итак, вот что мы получили в 2021 году с учетом многих проведенных изменений. Титаническими усилиями сократили площадку разработчика до 4 виртуалок: монолит-1, монолит-2, 2 сервисных хоста. Пришлось пойти на такой компромисс из-за процесса миграции с одной системы управления конфигурациями на другую. Хост-2 был добавлен для этой гибридной среды. При этом одна из баз данных поставляется с помощью своеобразного Shared Percona сервиса, потому что миграции в него исчезающе редки.
Тестовая среда тоже немного похудела. Перкону решено было поставлять отдельным инстансом, так как она сильно влияет на производительность.
Для postgres ребята сделали систему «золотых образов». О ней расскажу чуть ниже.
Все это вертится на VMWare Cluster (отдельный от продакшена, конечно). В случае падения гипервизора VMWare сама всё перетащит на свободные за несколько минут. Если вдруг где-то нужны ресурсы, можно легко мигрировать площадки.
Разработку сервисов для кубера разработчики ведут локально. Для тестирования мы нарезали тестовые неймспейсы по числу «склянок». Это тонкие окружения, в которые деплоятся только те сервисы, которые нужно тестировать. А полный список находится в Stable-окружении, в которое маршрутизируются запросы, если некому их обработать в рамках неймспейса. В Stable мы автоматически выкладываем все сервисы после успешной выкладки в Production (и, если вдруг пришлось откатить, то и там тоже).
Стек преобразовался и стал полностью виртуализованным, на основе VMWare + Ubuntu. Управление через Terraform и Ansible, контейнеры в Kubernetes, CI/CD автоматизировано через Bamboo Specs.
Bamboo Specs — расширение типа «пайплайны как код». Сборочные планы и развертывание площадок управляются через коммиты в репозитории. Появилась эта штука в 6-й версии и очень помогла нам быстрее развивать платформу.
На тот момент мы сохранили количество виртуалок на уровне 5 штук. Можно сказать, что это — победа, потому что количество сервисов у нас выросло более чем в 20 раз. Если бы виртуалки росли следом, то такими темпами у нас было бы 10к виртуалок и 10 дата-центров. Никакая скорость онбординга не оправдает такие расходы.
«Золотые образы»
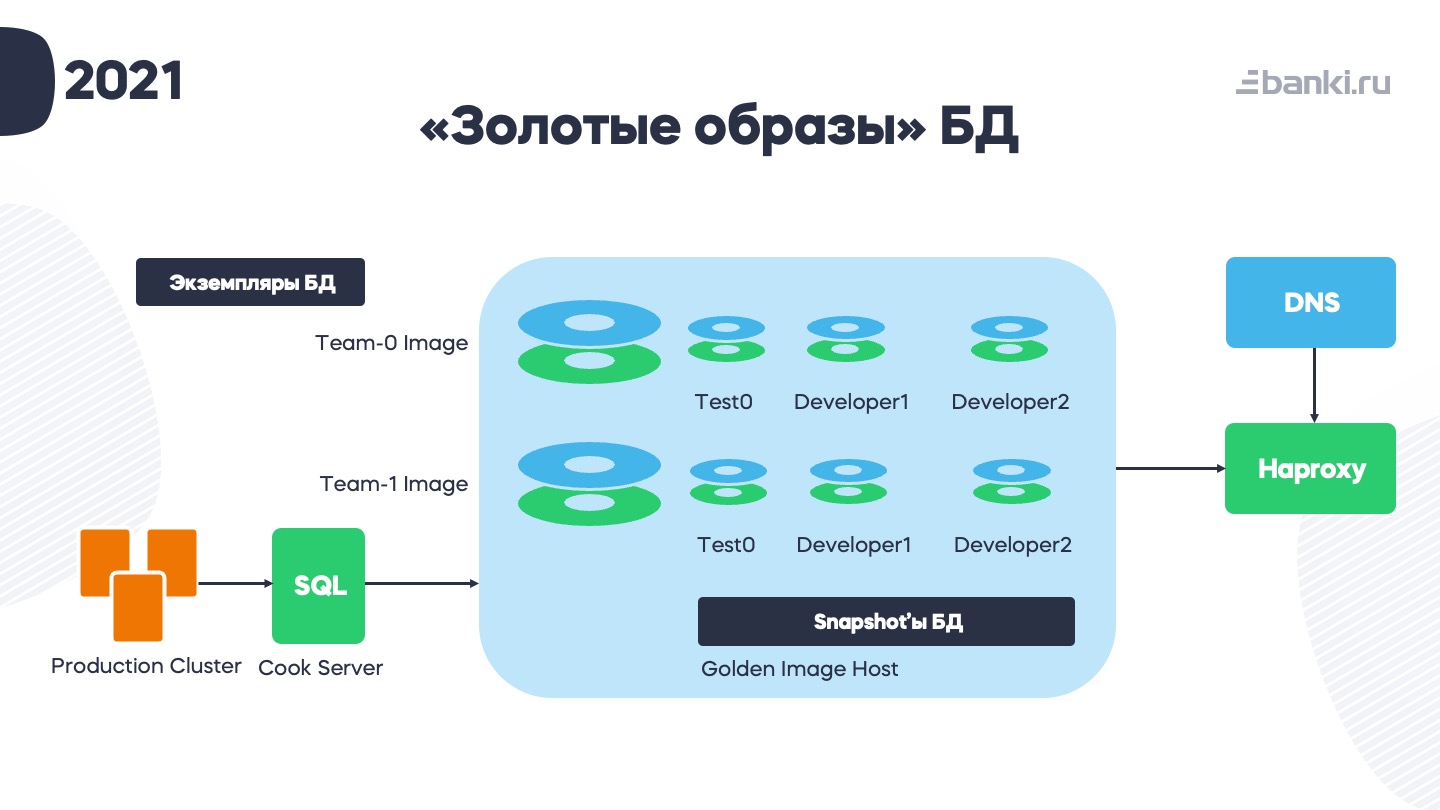
Расскажу про «Золотые образы». Основная идея заключается в том, чтобы заменить изолированные инстансы СУБД для площадок «тонкими копиями» эталонной базы (которая как раз и называется «золотым образом»). Мы реализовали идею снятия snapshot с баз данных. Схема такая: есть production cluster базы данных, с него бэкапится всё на Barman, оттуда ночью льётся дамп на кук-сервер, где база «готовится». То есть накатываются скрипты минификации, деперсонализации, добавляются тестовые пользователи и так далее.
Экземпляры БД привязаны к команде: в каждой команде может быть несколько разработчиков и до 6 «склянок». Планы Bamboo делают snapshot базы, а с этим snapshot уже работает разработчик.
На сервере с «золотыми образами» работает HAProxy, который по домену определяет, на какой именно snapshot нужно вести разработчика.
Система появилась почти случайно, после общения с интеграторами, которые приезжали и вдохновенно рассказывали про классный продукт, который они нам могут продать. Мы решили, что тоже такое можем. Подозреваю, что суммарно мы потратили примерно половину этих денег в человеко-часах, но зато у нас есть свое решение, и мы точно знаем, как оно работает и как его чинить.
Что мы делали с оверхедом по сборке и деплою
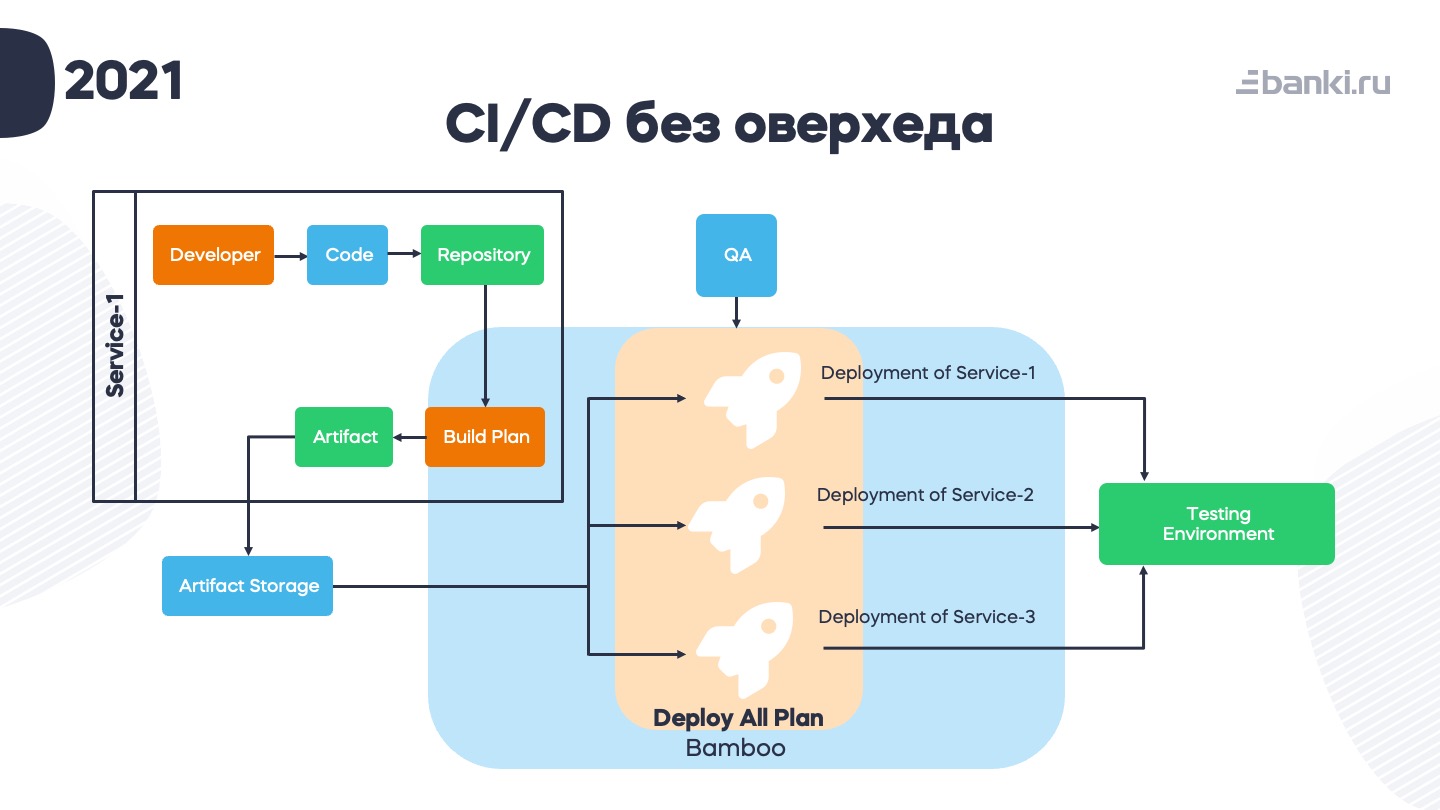
Разработчик пишет код. Код попадает в репозиторий. В Bamboo триггерится build plan (манифест плана тоже хранится в репозитории), результат — какой-то артефакт — пушится в артефакт-storage (Nexus). Когда QA-инженер хочет задеплоить себе тестовое окружение, запускается план Deploy All. Там под капотом отдельные деплои, которые берут этот артефакт из Нексуса и перекладывают его на тестовую среду. В конце Bamboo пишет в слак, что площадка готова. И есть небольшие health-check тесты, которые запускаются и проверяют, что все работает. Если что-то не так – об этом скрипт тоже сразу пишет в слак.
После многих лет использования схемы с Deploy All можно отметить главный плюс: простая и понятная одна кнопка для того, чтобы накатить себе сразу готовое рабочее окружение, воспроизвести какую-то проблему или протестировать целый комплекс задач совместно.
Что еще мы добавили:
- Понятные сообщения. Раньше, когда планы падали, они выдавали сложные трейсы, в которых даже девопсы разбирались с трудом.
- Правильная маршрутизация проблем. Добавили к сообщениям в слак указатель, к кому нужно обращаться в случае той или иной проблемы.
Для работы гибридной «склянки», где и виртуалки, и контейнеры, придумали такую схему.
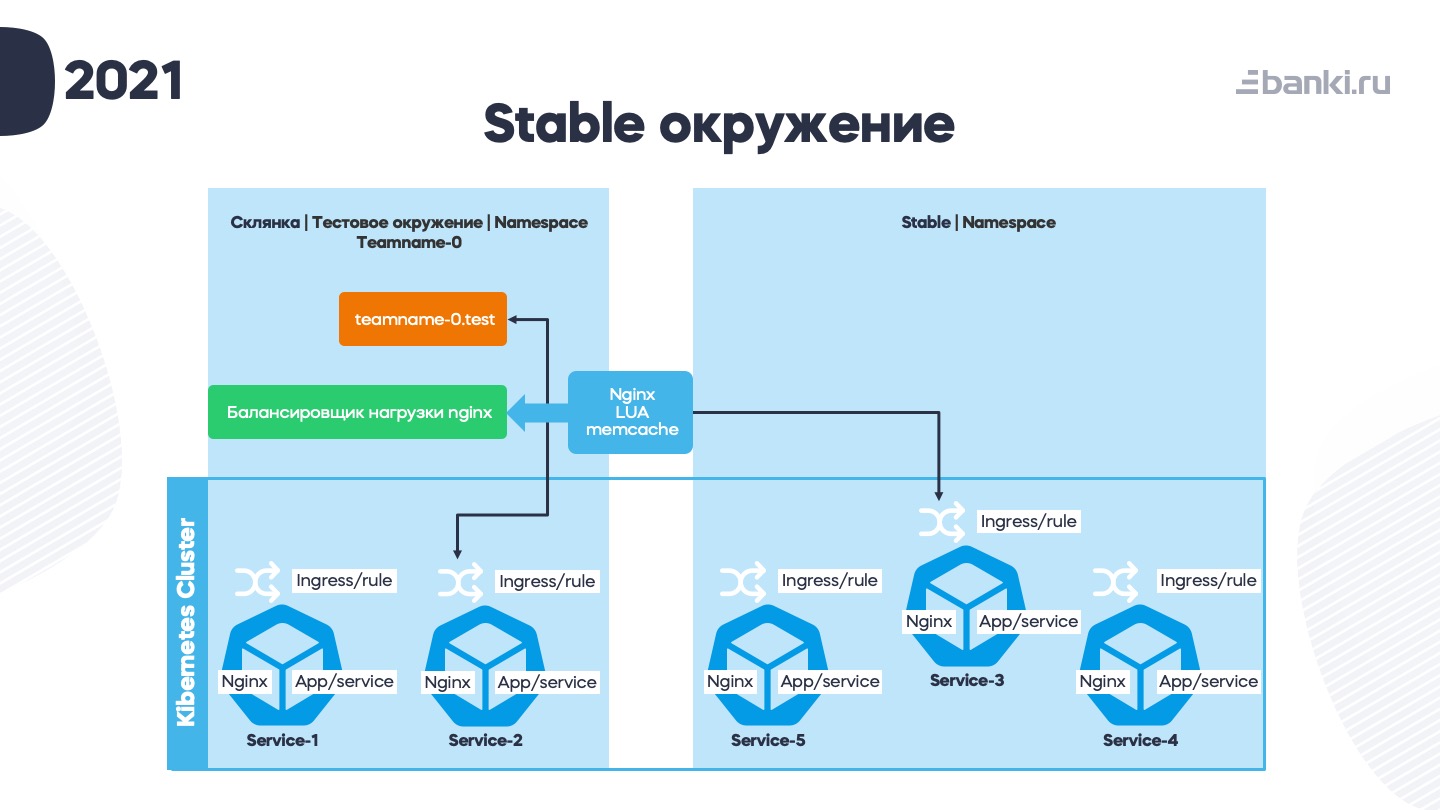
Есть тестовый кубер-кластер, в нем нарезаны тестовые окружения (неймспейсы как часть «склянки»). Они привязаны к названию команды. У каждой «склянки» есть внешний балансировщик на виртуалке – для взаимодействия с тем, что еще не в контейнерах. На балансировщике мы написали скриптов на LUA, которые маршрутизируют запросы. Это позволило нам сделать по-настоящему «тонкие» площадки, которые быстрее деплоятся. Потом схему с LUA заменили на хитрый алгоритм с DNS и ingress, который немного громоздко выглядит по конфигам, но довольно просто реализуется.
Если вернуться к картинке с тестовыми средами, то всё вместе выглядит вот так:
Как мы экономили ресурсы
Мы решили, что слишком щедро раздали ресурсов и на тестовые среды, и на разработческие. Плюс в том, что среды ближе к продакшену, чем, например, контейнерная разработка, и можно протестировать взаимодействие между виртуальными машинками. А минус в том, что из-за особенностей виртуализации у нас есть всегда какой-то оверпровижининг, когда виртуальных машин работает чуть больше, чем есть ресурсов на гипервизорах. При активной работе «склянки» периодически начинали затыкаться. Если на одной хост-машине у нас выкладывалось сразу несколько релизов, или всё пересобиралось, или гонялись какие-то автотесты, то в итоге почти всегда VMWare cluster (для дев-теста) мигал красненьким и мешал заметить что-нибудь важное.
Поэтому мы решили попробовать оставить для площадки одну виртуалку: и отлаживать, и чинить проще. В чатах поддержки площадок были бесконечные сообщения, иногда по десятку в день – о том, что «кончилось место на площадке». И все эти площадки надо было проверять. Много времени, много простоев, много выгорания.
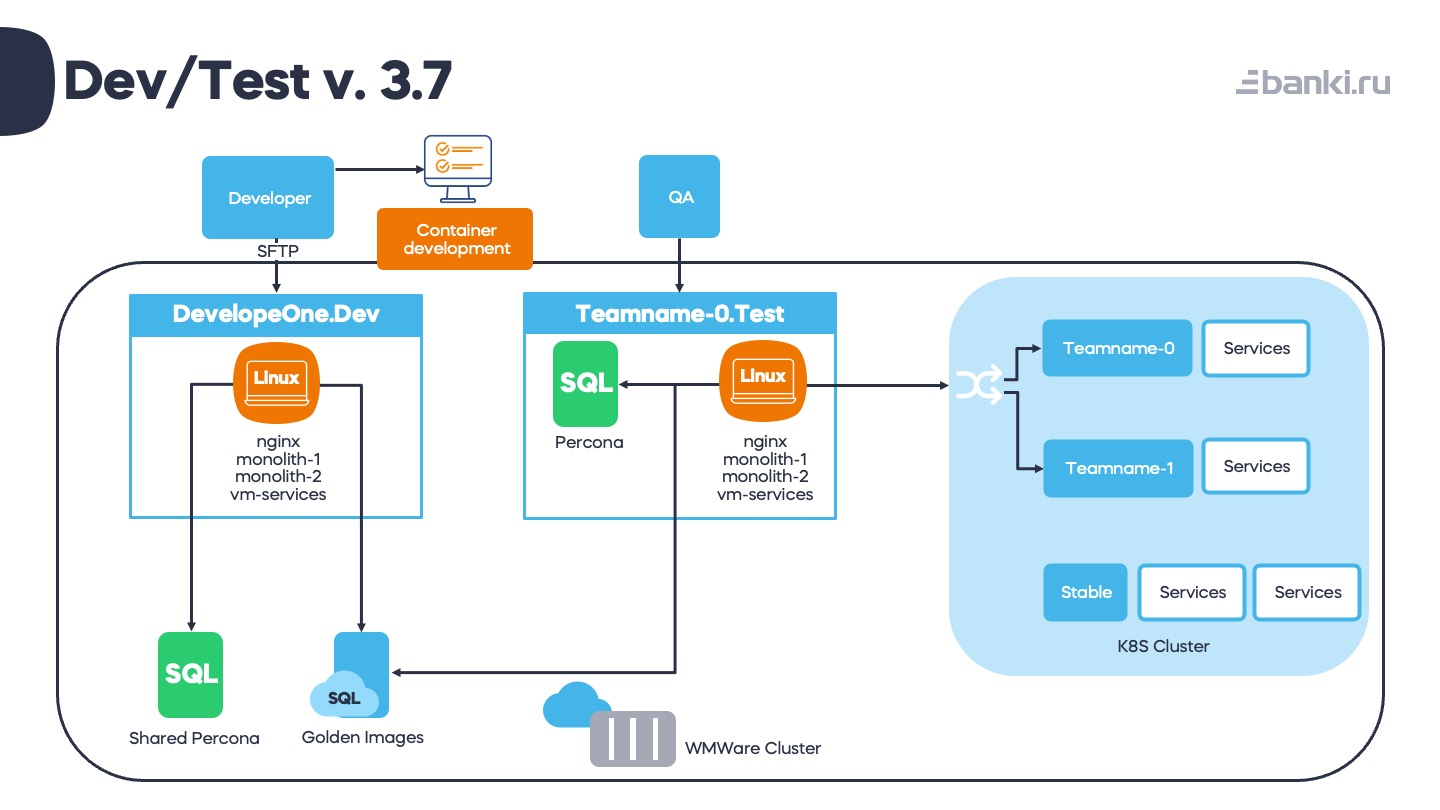
В итоге примерно за 3 месяца мы сделали несколько пилотных площадок, потом перевели все площадки на одну схему. На одной виртуалке находится nginx, все монолиты, все сервисы. Соответственно, на площадке у нас находятся 3 версии php (5.6, 7.0, 7.2). Для разработчика оставили одну виртуалку, для тестировщиков – две: инстанс Перконы нужен, чтобы тестировать миграции данных.
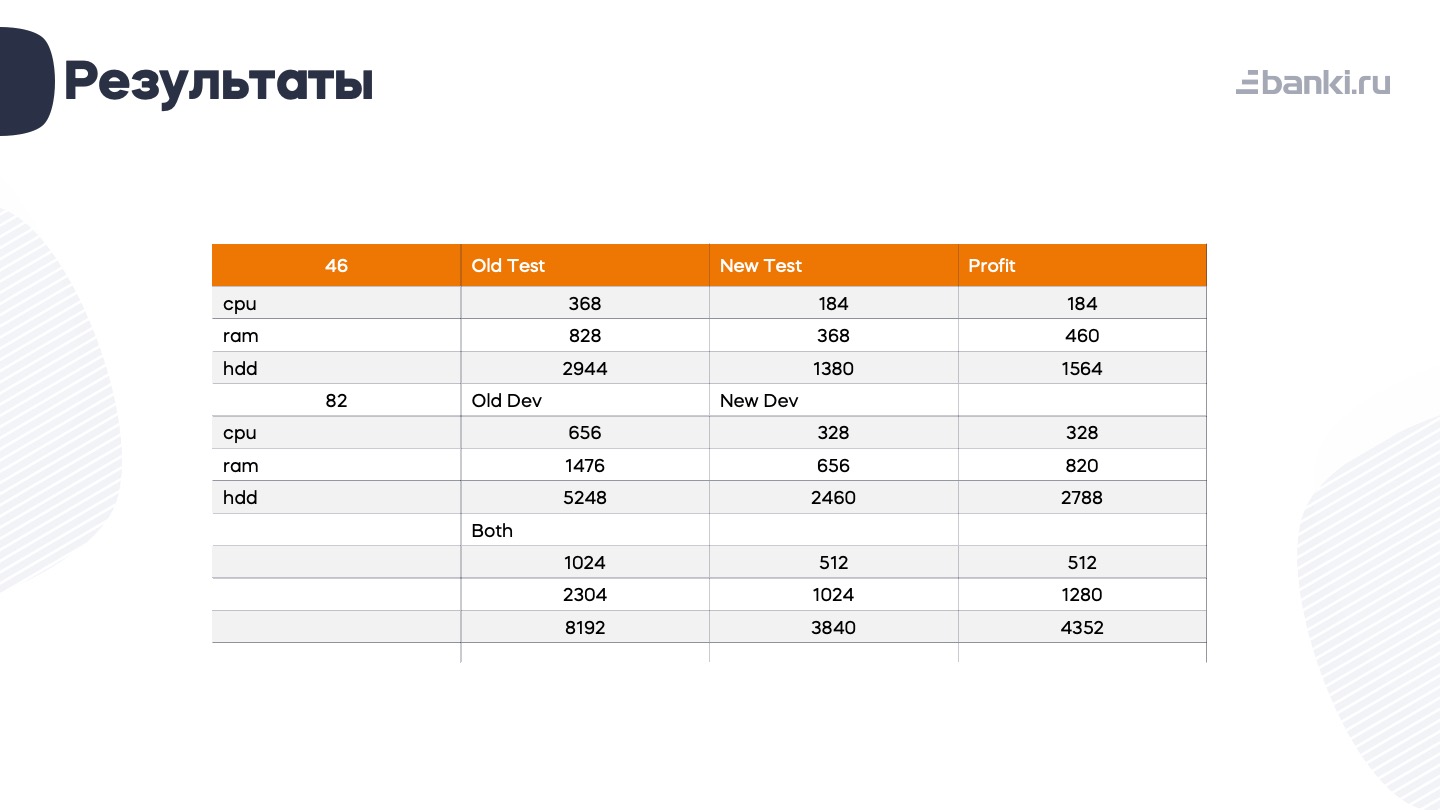
Конечно, мы очень круто на этом сэкономили. В начале 2022 года было 46 «склянок» с суммарным потреблением 368 ядер, немногим меньше ТБ оперативной памяти и 2-3 ТБ диска. 82 разработческие площадки тоже хорошо кушали.
То есть всего дев-тест кластер утилизировал 1024 ядра, больше 2 ТБ оперативной памяти и 8 ТБ дискового пространства.
В табличке ниже посчитал, сколько удалось сэкономить.
Сразу после обновления нам удалось добавить 6–8 новых тестовых площадок и резко снизить количество проблем со старыми, а также немного ускорилось тестирование.
Как мы планируем развиваться в 2024 году

Пока зафиксировали такую целевую схему: разработчик пишет код, пушит в репозиторий, триггерятся планы. Возможно, там уже будет не Bamboo, а какой-нибудь GitLab или Teamcity.
Что мы хотим там изменить относительно предыдущей схемы? Должен совсем исчезнуть слой с виртуалками – всё уедет в кубер. QA-инженерам не нужно будет самим нажимать кнопки, достаточно будет просто перевесить задачу в Jira. Воркфлоу триггерит тестинг-план, тот проверяет, что все необходимое есть, смотрит, какие сервисы нужно выложить, создает неймспейс под эту задачу и запускает деплой всех нужных сервисов. А остальное, как и раньше, берется из стейбла.
Таким образом, мы рассчитываем, что перейдем к парадигме IaaS/PaaS на базе Kubernetes, чтобы делать cloud-native-сервисы.
При этом мы сократим количество наших постоянных окружений. Всё-таки прибитые к командам «склянки» сейчас греют воздух большую часть времени.
В итоге мы планируем получить такое cloud-native решение, которое позволит максимально эффективно использовать ресурсы и нашего частного облака, и прикрутить рядом публичные.
Ну, а в финале немного статистики. Сейчас у нас 400+ сервисов, 10 миллионов строк кода и больше 30 команд. Мы выкатываем изменения в production сотни раз в неделю и не собираемся на этом останавливаться.
