
Привет! Меня зовут Александр Голиков, я работаю в компании Bercut. Наша компания разрабатывает и развивает IT-решения для операторов цифровых услуг и мобильных сервисов. Коротко говоря, мы помогаем цифровизации бизнеса. В компании я занимаюсь виртуализацией, СХД, мониторингом, разработкой и интеграцией продуктов Bercut c операционными системами. Для агрегации данных и анализа мы используем Prometheus.
В этой статье рассмотрю одну из конфигураций Prometheus в отказоустойчивом режиме, познакомлю вас с Karma alert dashboard и продемонстрирую написание алертов. Напишу несколько простых включений Go Template и рассмотрю ситуацию, где такие включения противопоказаны. Продемонстрирую, как на основе меток можно сделать исключения из общих правил, и обучу Prometheus самостоятельно чинить поломки.
Начнем
В этой публикации я не касаюсь этапа начальной конфигурации Prometheus. Новичкам рекомендую как минимум ознакомиться с Getting Started разделом на сайте Prometheus.io, а также скачать и немного пощелкать Grafana.
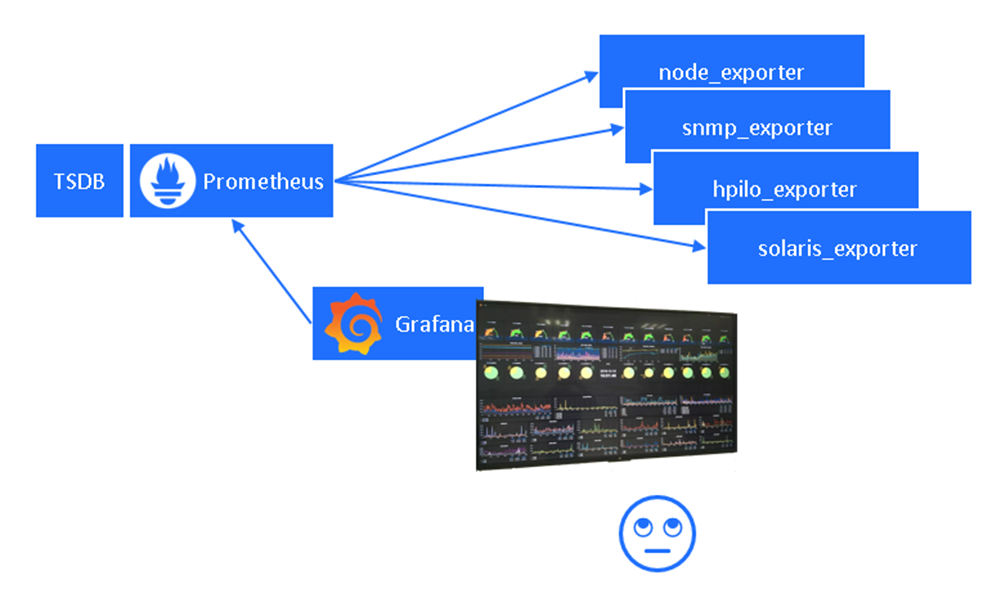
Итак, у нас уже есть первый дашборд с какими-то метриками. Все выглядит красиво, но слишком много деталей, глаза разбегаются. Хочется убрать с экрана избыточную информацию и возвращаться к большому дашборду только для аналитики и диагностики, а не смотреть на него постоянно.

Сегодня мы будем говорить о компонентах, выделенных на схеме зеленым.
В конфигурацию Prometheus можно добавить правила алертов по имеющимся метрикам(alert_rules). Поговорим о том, как их лучше организовать, чтобы было удобней с ними работать.
AlertManager занимается маршрутизацией алертов. Для разных команд свой набор алертов и способы доставки (E-mail, MS Teams, Zulip, Telegram, Karma и другие). Одной из команд у нас будут фиксики, т.е. инструменты для автоматической починки.
Karma – это единый дашборд для алертов, о нем позже будет подробней. Если все хорошо – на нем нарисована кружечка кофе.
Добавив эти компоненты, мы разгрузим нашего дежурного инженера от нервной проверки всех дашбордов в Grafana и оставим ему только удобные каналы информирования без избыточной информации.
Кластерная конфигурация
Отказоустойчивость – очень важное свойство правильно настроенного мониторинга.

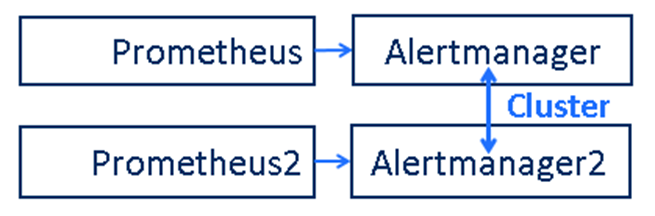
В предложенной инсталляции компоненты представлены в удвоенном количестве, каждый экземпляр работает на своем узле для обеспечения отказоустойчивости.
Для простоты диагностики если что-то работает не так каждый Prometheus отсылает свои алерты только в отдельный Alertmanager, но вы можете также настроить и перекрестные связи.
Т.к. все собираемые метрики и алерты в обоих Prometheus идентичны, то в случае каких-то проблем, алерты всплывут на каждом из них, и каждый передаст их в свой Alertmanager. Чтобы получателям не приходило двойных нотификаций об алертах, Alertmanager объединены в кластер. Кластер Alertmanager делает дедублекацию алертов, поэтому пользователи получают их один раз.
В случае отказа любого компонента в любой из двух цепочек у нас все равно остается в работе вторая цепочка, и это гарантирует доставку алертов даже если наш мониторинг будет не совсем здоровым.
Дублирование происходит и на уровне Karma. Если один из узлов Karma откажет, пользователь может переключиться на резервный узел (либо просто настроить virtual IP, чтобы автоматизировать процесс).
Дашборд алертов Karma

Так выглядит дашборд алертов Karma (так он выглядит вживую). Чем он удобен?
Удобные фильтры по меткам. Достаточно щелкнуть по какой-то метке из алерта и на экране останутся только алерты, содержащие данную метку с указанным значением. Фильтры легко редактировать, можно быстро исправить правило на противоположное, например, замена “=” на “!=” в фильтре отобразит только алерты с меткой НЕ РАВНОЙ данному значению. В фильтрах можно пользоваться регулярными выражениями. Например, фильтр instance=~10.10.* отобразит алерты только от узлов с IP адресами, начинающимися с 10.10, а фильтр instance!~10.10.* - наоборот, с начинающихся не с 10.10.
В аннотацию к алертам можно прицепить специальную метку со ссылкой на страницу Wiki или видеоролик с подсказкой, как правильно чинить данный алерт (alertReferance).
Karma подскажет, как давно загорелся конкретный алерт. Karma умеет следить за большим количеством разных Alertmanager, в том числе состоящих в разных кластерах, и показывает от какого именно AlertManager пришел какой alert. Карму можно легко подключить и к Prometheus-Operator в Kubernetes.
Karma умеет делать acknowledge (silence) на алерты, чтобы они не беспокоили, если по ним уже кто-то начал работать. В то же время легко посмотреть и алерты, на которых сейчас установлен silence (мало ли что-то забыли отработать), для этого просто нужно убрать фильтр @state=active.
Конечно, картинка не передает полностью все возможности, поэтому разработчики Karma создали специальный демо-сайт с множеством алертов, переходите и пощелкайте. Заинтересовались? Тогда добро пожаловать на публичный репозиторий на github (prymitive / karma), где собрана вся документация, исходники и бинарники.
Зачем нужен DeadMan алерт?
При настройке Karma рекомендую всегда выставлять в конфигурации Prometheus дополнительный синтетический алерт, называемый DeadMan.

Данный алерт должен быть всегда активен. На картинке слева я обозначил этот алерт цветной головой зомби. Алерт DeadMan есть, а в Karma мы видим только кружечку кофе - все хорошо. Karma в своем конфиге явно настроена на опознавание этого DeadMan и специально его игнорирует (но это настраивается, если вы хотите, можно его и отображать).
А что произойдет, если на одном из узлов Prometheus закончится место на диске?
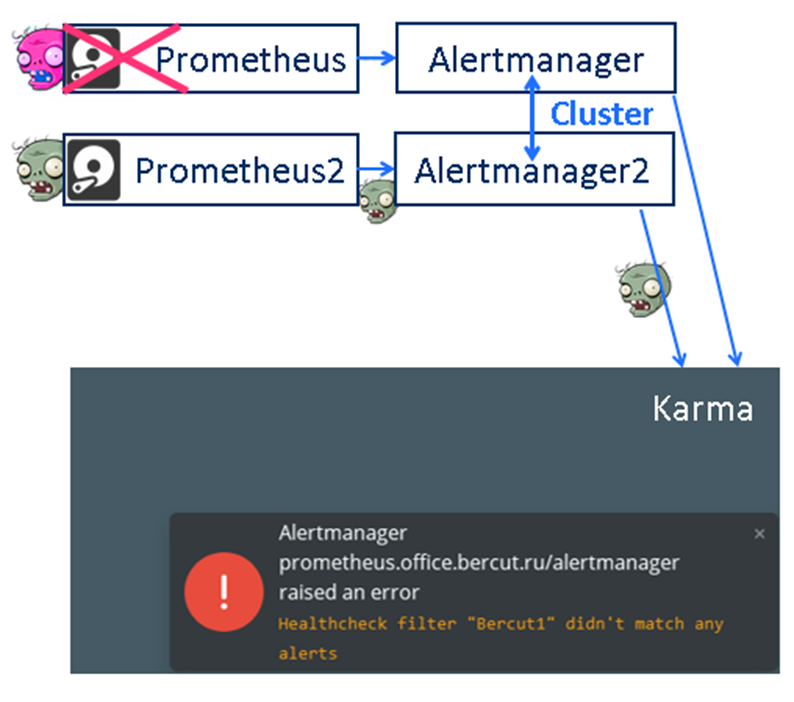
Место закончится и первый Prometheus перестанет записывать синтетический алерт DeadMan в свою TSDB, перестанет передавать его в свой AlertManager, а тот в свою очередь перестанет передавать его в Karma. И Karma среагирует, в нижнем правом углу у нас появится тревожное сообщение об этом, чтобы мы увидели, что наш мониторинг захромал. В то же время вторая цепочка Prometheus по-прежнему жива, посылает DeadMan и другие алерты, наш мониторинг работает.
Как настроить Deadman алерт?
В файле prometheus.yml объявляем внешний файл правил DeadMansSwitch.yml:
...
rule_files:
- 'DeadMansSwitch.yml'
...Во внешнем файле правил DeadMansSwitch.yml записываем примерно такой синтетический алерт с выражением vector(1):
groups:
- name: 'DeadMansSwitch'
rules:
- alert: DeadMansSwitch
expr: vector(1)
labels:
prom: 'Bercut1' # уникальный тэг для каждого узла
annotations:
title: 'DeadMansSwitch Alert'
description: 'This alert should be always ON to check that alert pipeline is working'В файле конфигурации AlertManager (alertmanager.yml ) необходимо указать явно, что этот алерт предназначен ТОЛЬКО для karma, чтобы не получать о нем E-Mail:
routes:
- receiver: 'karma'
match:
alertname: 'DeadMansSwitch'
continue: false #ignore all other routesAlertManager в кластере. Запуск
Чтобы запустить AlertManager в кластерном режиме достаточно добавить к параметрам запуска всего две опции.
В опции --cluster.listen-address укажем, на каком интерфейсе и порту нужно ждать подключений от других узлов.
В опции --cluster.peer указывается узел/порт к которому надо подключаться. Опция --cluster.peer может быть указана несколько раз, если ваш кластер больше чем на два узла.

Alertmanager в кластере. Синхронизация
В нашем кластере есть несколько процессов и у них разные конфигурации (отмечено желтым на картинке):

Необходимо сделать так, чтобы конфигурации совпадали и не разъезжались.
Сделать это можно либо через git pull, если вы храните свои настройки по принципу Infrastructure-as-Code, либо просто написать простой скриптик для rsync:
rsync --recursive --relative --links --delete --checksum --group --owner --perms \
-e "ssh -i ${ssh_key}" \
--exclude=${promdir}/etc/DeadMansSwitch.yml \
${file_list} \
${promuser}@${remote_host}:/В скрипте заводится исключение для DeadManSwitch.yml, чтобы алерт DeadMan был с уникальными параметрами для каждого экземпляра Prometheus.
Написание Alerts
Группировка правил
В основном файле конфигурации prometheus.yml можно указывать ссылки на внешние правила конфигурации:

Мы уже рассмотрели один из файлов конфигурации – DeadManSwitch.yml.
В других – тематически разложенные алерты.
Все сайты довольно сильно отличаются по типу серверного оборудования, системам хранения данных, наличию или отсутствию слежения за источниками бесперебойного питания. Разные операционные системы, разные системы виртуализации, разные шасси для лезвий, разные СУБД, брокеры и т.д.
Удобно при новой инсталляции мониторинга иметь багаж готовых алертов. Вам достаточно закомментировать ненужные, чтобы быстро запуститься.
Полезные метки алертов
Рассмотрим ситуацию. К нам приходит программист и говорит:

Мы открываем почту и видим сообщение от мониторинга:

Мы пробуем подключиться к этому адресу и, конечно же, у нас ничего не получается:

И вместо того, чтобы сразу включиться в работу и начать чинить, мы начинаем лишний раз заниматься поиском дополнительной информации о неисправном узле.
Что это за адрес? Зачем он? Может, в заявке на создание стенда что-то сохранилось?
Мы теряем драгоценное время. Гораздо удобнее было бы увидеть более насыщенный информацией алерт:

Тогда бы мы смогли устранить проблему существенно раньше. Из алерта понятно, что это сервер-лезвие, работающее в шасси plat198c7000 с iLO 10.10.11.10.
Как добиться такого в конфигурации Prometheus?
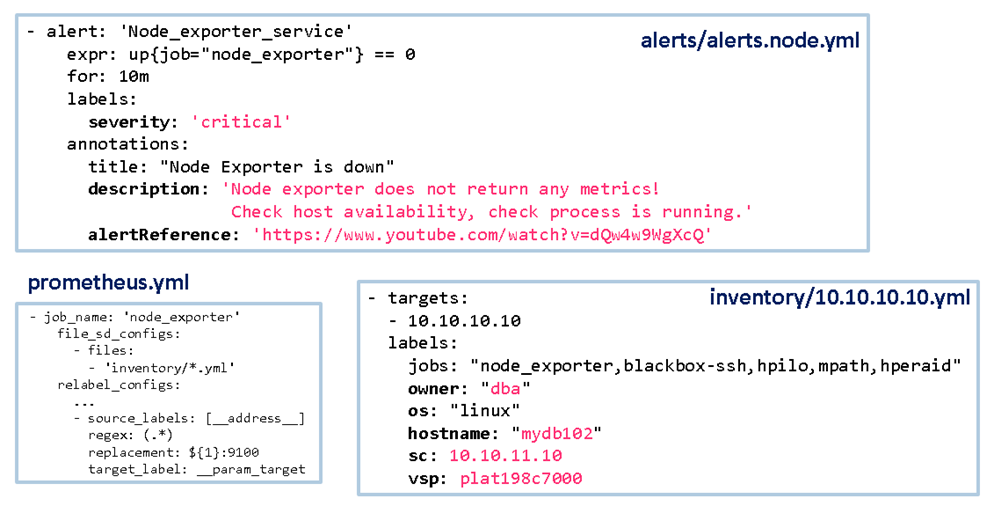
В Prometheus.yml указываем, где искать inventory для job. За тремя точками (…) у меня тут скрыта логика, которая поднимает хост из inventory только если в его теге jobs найдется имя node_exporter, перечисленное через запятую:
- job_name: 'node_exporter'
scrape_interval: 90s
scrape_timeout: 50s
file_sd_configs:
- files:
- 'inventory/*.yml'
relabel_configs:
- source_labels: [jobs] #check 'node_exporter' in label 'jobs', drop if not
regex: '(.*,|^)node_exporter(,.*|$)'
action: keep
- regex: '^jobs$' #drop unused label 'jobs'
action: labeldrop
- source_labels: [__address__] #add port if it is absent in target
regex: (.*)
replacement: ${1}:9100
target_label: __param_target
- source_labels: [__param_target] #copy '__param_target' to 'instance'
target_label: instance
- source_labels: [__param_target] #copy '__param_target' to '__address__'
target_label: __address__В inventory/10.10.10.10.yml указываем адрес узла, а также связанную с ним информацию – какие jobs Prometheus проверяет на нем, кто его использует, какая там ОС, имя хоста, адрес системного контроллера и имя шасси (если это шасси с лезвиями).
Наконец, часть меток добавляется в правиле алерта alerts/alerts.node.yml, тут это метка severity(важность) и alertReference (ссылка на инструкцию по устранению алерта).
Проверка алертов. Синтаксис
Вместе с бинарным файлом Prometheus разработчики на GitHub предлагают в комплекте утилиту promtool.
Её применение достаточно широко, начнем с проверки синтаксиса конфигурации. Например, это можно сделать так:
bin/promtool check config etc/prometheus.yml
echo -e "Check result code is $?"Примеры найденных ошибок. Необъявленная функция:
Checking alerts/alerts.node.yml
FAILED:
alerts/alerts.node.yml: group "Node exporter alerts", rule 1, "Node_exporter_service": annotation "description": template: __alert_Node_exporter_service:1: function "blababala" not definedИли потеряли кавычку:
Checking /opt/prometheus/etc/alerts/alerts.node.yml
FAILED:
alerts/alerts.node.yml: yaml: line 11: did not find expected key Проще всего находить ошибки после того, как вы написали один алерт, так что, если вы пишете много алертов за раз, имеет смысл между ними запускать синтактическую проверку.
Однако синтаксические проверки часто недостаточны, особенно если вы широко используете Go Template.
Проверка алертов. Вживую
Такие проверки уместны, если вы единственный пользователь Prometheus или у вас там мало хостов – лишний алерт не запустит панику среди дежурных инженеров. А возможно просто у вас есть тестовый Prometheus для отладки. Как проверить, что наш алерт сработает?
Исправляем значение алерта на противоположное, например в expr вместо “=” пишем “!=”, тогда алерт сработает без необходимости что-то ломать.
В Prometheus при срабатывании алерта появляется встроенная метрика ALERTS. Прямо в веб-интерфейсе Prometheus можно убедиться, что она появилась и в ней есть все нужные метки:

Выполнение запроса к метрике ALERTS в CLI:
bin/promtool query instant "http://localhost:9090/prometheus" \
"ALERTS{hostname='mydb102',alertname='Node_exporter_service',severity='critical'}"Выполнение запроса к Prometheus через API:
curl 'http://localhost:9090/prometheus/api/v1/alerts' | jqПроверка алертов. Unit-Test
Проверки вживую не всегда удобны, можно воспользоваться Unit-Test, встроенный в promtool.
Для этого необходимо написать дополнительный манифест unit-test.yml. Документацию по синтаксису можно подсмотреть тут.
rule_files:
- alerts/alerts.node.yml
evaluation_interval: 1m
tests:
- interval: 1m
input_series:
- series: 'up{hostname="mydb102",instance="10.10.10.10:9100",ip="10.10.10.10",
job="node_exporter", os="linux",owner="dba",sc="10.10.11.10",severity="critical",
vsp="plat198c7000"}'
values: '0 0 0 0 0 0 0 0 0 0 0 0 0 0 0'
alert_rule_test:
- eval_time: 10m
alertname: 'Node_exporter_service'
exp_alerts:
- exp_labels:
severity: 'critical'
instance: "10.10.10.10:9100"
job: "node_exporter"
ip: "10.10.10.10"
hostname: "mydb102"
os: "linux"
owner: "dba"
sc: "10.10.11.10"
vsp: "plat198c7000"
exp_annotations:
title: "Node Exporter is down"
description: "Node exporter does not return any metrics!
Check host availability, check process is running."
alertReference: "https://www.youtube.com/watch?v=dQw4w9WgXcQ"Внутри этого манифеста мы указываем, какой файл с правилами алертов мы будем тестировать, а также какие синтетические метрики для теста у нас есть на входе (input_series), указываем в этих метриках все необходимые метки.
Затем в блоке alert_rule_test необходимо указать, через какой интервал мы будем смотреть возникшие алерты.
Опционально можно расписать какие именно алерты мы ожидаем увидеть.
Для запуска проверки unit-test набираем:
bin/promtool test rules unit-test.ymlЕсли все хорошо, получим такой ответ:
Unit Testing: unit-test.yml
SUCCESSПример выше скорее искусственный и неинтересный, но если мы добавим немного Go Template, то увидим, что их дебажить с unit-test очень удобно.
Алерты с Go template, if, eq, query
Рассмотрим ситуацию, когда мы мониторим состояние жестких дисков внутри сервера, которые иногда ломаются.
В нашем Prometheus есть две метрики:
hpe_raid_message{hostname="mydb102", ip="10.10.10.10", job="hperaid", owner="dba", sc="10.10.11.10", vsp="plat198c7000", message="RAID WARNING - Component Failure: Array A logicaldrive 1 (1.64 TB, RAID 1+0, OK) Array B logicaldrive 2 (3.27 TB, RAID 5, OK) physicaldrive 1I:3:3 (port 1I:box 3:bay 3, SAS HDD, 900 GB, Predictive Failure)"} 1
hpe_raid_status{hostname=" mydb102", ip="10.10.10.10", job="hperaid", owner="dba", sc="10.10.11.10", vsp="plat198c7000"} 1Метрика hpe_raid_status основная, она равна 0, если с дисками все хорошо, и не равна нулю, если что-то сломалось.
Но нам хочется получить больше информации в нашем алерте - не просто что что-то сломалось, а что конкретно сломалось, вот так:
hperaid on 10.10.10.10 has problems
hperaid check on host 10.10.10.10 mydb102 has returned Warning status (1).
RAID WARNING - Component Failure: Array A logicaldrive 1 (1.64 TB, RAID 1+0, OK) Array B logicaldrive 2 (3.27 TB, RAID 5, OK) physicaldrive 1I:3:3 (port 1I:box 3:bay 3, SAS HDD, 900 GB, Predictive Failure)Информация о том, что именно сломалось, должна браться из значения метки message метрики hpe_raid_message.
Как это сделать? Немного YAML:
- alert: 'hperaid_result'
expr: hpe_raid_status{} != 0
for: 10m
labels:
severity: warning
annotations:
title: 'hperaid on {{ .Labels.ip }} has problems'
description: "hperaid check on host {{ .Labels.ip }} {{ .Labels.hostname }} has returned
{{ if eq (.Value | humanize) \"0\" }} OK
{{ else if eq (.Value | humanize) \"1\" }} Warning
{{ else if eq (.Value | humanize) \"2\" }} Critical
{{ else if eq (.Value | humanize) \"3\" }} Unknown
{{ end }} status
({{ .Value | printf \"%.0f\" }}).
{{ with printf \"hpe_raid_message{ip='%s',job='%s'}\"
.Labels.ip .Labels.job | query }}
{{ . | first | label \"message\" }}
{{end}}"Тематические разделения (места, выделенные одним цветом, связаны между собой):

При срабатывании алерта Prometheus вернет структуру, в которой будет доступен словарь Labels (в нем будет перечислены все метки, сопровождающие метрику) и вещественное число Value – значение метрики.
К ним можно обращаться из Go Template включений.
На то, что началось Go Template включение, мы указываем двойными фигурными скобками (и ими же заканчиваем).
В Go Template можно использовать условные конструкции if, else, а также пользоваться встроенными функциями. Скажем, в примере есть функция humanize, которая преобразует float-число в строку для дальнейшего строкового сравнения через eq (можно сравнивать и без преобразования в строку, ниже будет другой пример). Есть и другие полезные функции, например query, которая может сделать PromQL запрос в TSDB, чтобы вытащить оттуда новый набор метрик (что позволит отбросить лишнее и оставить только текст в метке message).
Алерты с Go template, if, eq, query: UnitTest
А вот теперь unit test будет очень даже показателен и не скучен.
Снова составляем манифест для проверки с исходными данными. Не будем тратить время на то, чтобы описать в нем же все алерты, которые хотим получить:
…
input_series:
- series: 'hpe_raid_message{hostname="mydb102", ip="10.10.10.10", job="hperaid", owner="dba", sc="10.10.11.10", vsp="plat198c7000",message="RAID WARNING - Component Failure: Array A logicaldrive 1 (1.64 TB, RAID 1+0, OK) Array B logicaldrive 2 (3.27 TB, RAID 5, OK) physicaldrive 1I:3:3 (port 1I:box 3:bay 3, SAS HDD, 900 GB, Predictive Failure)"}'
values: '1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1'
- series: 'hpe_raid_status{hostname=" mydb102", ip="10.10.10.10", job="hperaid", owner="dba", sc="10.10.11.10", vsp="plat198c7000"}'
values: '1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1'
alert_rule_test:
- eval_time: 11m
alertname: hperaid_result'
…Сразу же запускаем проверку:
bin/promtool test rules unit-test.ymlТ.к. мы не расписали алерты, которые мы хотим получить, имеем статус FAILED, но зато можно сразу прочитать желаемый текст генерируемой аннотации:
Unit Testing: unit-test.yml
FAILED:
alertname: hperaid_result, time: 11m,
exp:[
0:
Labels:{alertname="hperaid_result"}
Annotations:{}
],
got:[
0:
Labels:{alertname="hperaid_result", hostname=" mydb102", ip="10.10.10.10", job="hperaid", owner="dba", sc="10.10.11.10", severity="warning", vsp="plat198c7000"}
Annotations:{description="hperaid check on host 10.10.10.10 mydb102 has returned Warning status (1). RAID WARNING - Component Failure: Array A logicaldrive 1 (1.64 TB, RAID 1+0, OK) Array B logicaldrive 2 (3.27 TB, RAID 5, OK) physicaldrive 1I:3:3 (port 1I:box 3:bay 3, SAS HDD, 900 GB, Predictive Failure) ", title="hperaid on 10.10.10.10 has problems"}А вот как могла бы выглядеть ошибка, допущенная в GoTemplate:
alerts/alerts.node.testrule.yml: group "Testing alerts", rule 3, "hperaid_result": annotation "description": template: __alert_hperaid_result:1: unexpected "}" in operandВ unit-test ее легко отловить и исправить перед запуском в прод.
Алерты с Go template, динамические метки
Рассмотрим следующую ситуацию. У нас есть набор метрик, которые начинаются на hpilo_ и заканчиваются на _status
hpilo_battery_status 0
hpilo_bios_hardware_status 1
hpilo_fan_status 0
hpilo_memory_status 2
hpilo_power_supply_status 0
hpilo_processor_status 0
hpilo_running_status 0
hpilo_storage_controller_health_status 0
hpilo_storage_enclosure_health_status 0
hpilo_storage_ld_health_status 0
hpilo_storage_pd_health_status 0Значение метки может быть от 0 до 3. Мы бы хотели сделать так, чтобы метка severity выставлялась автоматически согласно значению метрики по правилу:
0 – ok
1 – warning
2 – critical
3 – warning
Также нам не хочется писать отдельное правило алерта для каждой из метрик, хочется сделать одно универсальное правило алерта.
Как это сделать с помощью Go Template и PromQL?
- alert: 'HWstatus'
expr: '{job="hpilo", __name__=~"hpilo_.*status"} > 0'
for: 0s
labels:
severity: "{{ if or ( eq ($value) 1.0 ) ( eq ($value) 3.0 }}warning
{{ else }}critical{{ end }}"
metric: '{{ .Labels.__name__ }}'
annotations:
...Метка severity теперь полностью формируется из Go Template. И да, обратите внимание на альтернативный способ сравнения числа float с целым (без преобразования в строку). Нужно дописать .0 рядом со сравниваемым числом (1.0 и 3.0), чтобы Go понял, что сравниваем переменные одного типа float.
Если мы сделаем unit-test, то увидим, что хотя правило только одно, алерта возникает два и severity у них разный:
0:
Labels:{alertname="HWstatus", metric="hpilo_bios_hardware_status", severity="warning"}
1:
Labels:{alertname="HWstatus", metric="hpilo_memory_status", severity="critical"}Теперь обсудим случаи, когда динамические метки противопоказаны.
Алерты с Go template, где нельзя динамические метки?
У нас есть некая метрика space_used_on_disk_percent. Мы ленивы и хотим сделать одно универсальное правило для алерта, чтобы severity был warning при значении метрики от 80 до 90 и превращался в critical, если значение метрики больше 90.
Вовка сделал бы так:

Но нет. Так нельзя. Давайте разбираться.
Рассмотрим случай, когда наша метрика меняется вверх-вниз вот так:
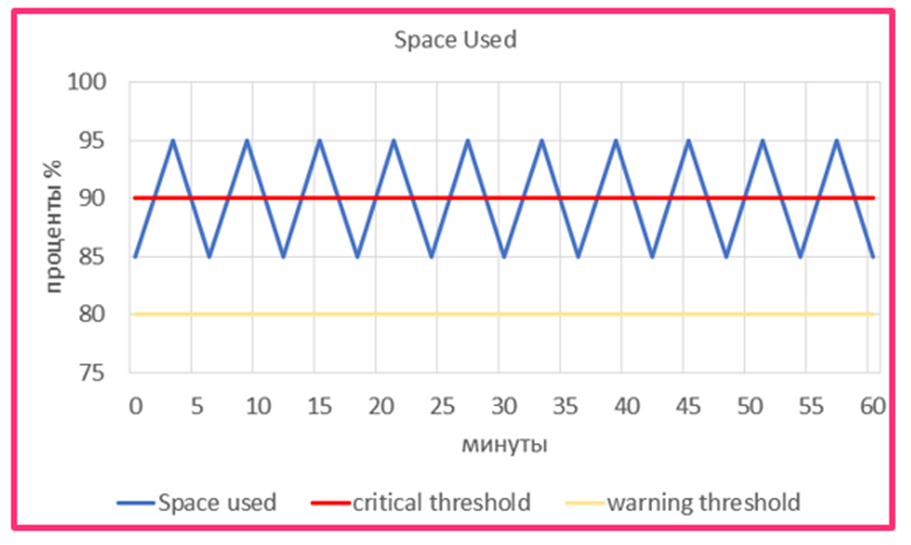
Вполне реальная картина. Одна программа пишет лог в файл, затем делается ротация и старый лог удаляется.
Что будет происходить с точки зрения алертинга в Prometheus?
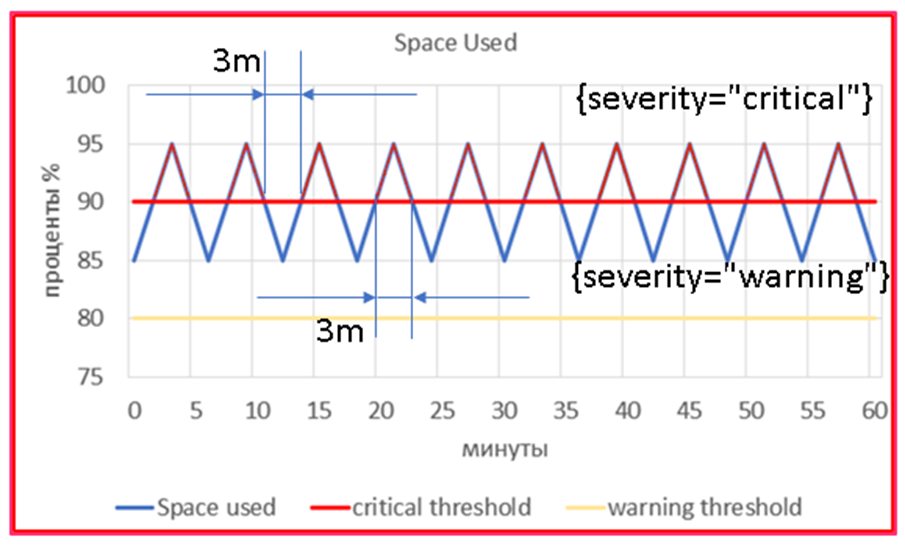
В глазах Prometheus у нас будет две независимые метрики, с отличающимся тегом severity, но обе будут появляться всего на 3 минуты (по очереди), а потом исчезать, не дождавшись нужного времени, указанного в for: 10m (10 минут).
Поэтому так делать нельзя. Проблема есть, а алерта НЕТ! Нет даже warning:

Динамические метки выгодно применять на алертах с нулевым for, либо на метриках, которые не дадут вам в своих значениях нарисованной выше “пилы”.
Что же делать с метрикой space_used_on_disk_percent? Как правильно реализовать алертинг по ней?
Классически, через два алерта в alerts/alerts.node.yml:
- alert: 'DiskSpace'
expr: space_used_on_disk_percent > 80
for: 10m
labels:
severity: "warning"
...
- alert: 'DiskSpace'
expr: space_used_on_disk_percent > 90
for: 10m
labels:
severity: "critical"
...А чтобы не получать два письма (и о warning, и о critical), добавим inhibit_rule в конфиг AlertManager (alertmanager.yml):
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance' ]Это правило будет автоматически включать silence на алерт warning, если уже есть такой же алерт с severity critical.
Алерты с Go template, добавленные теги
Переходим к следующей ситуации. У нас есть несколько похожих метрик, которые говорят о том, работает ли сейчас приложение:
Mib_LBR_Status{instance="10.10.10.31", job="MIB"} 1
Mib_SMSC_Status{instance="10.10.10.32", job="MIB"} 1
Mib_USSDC_Status{instance="10.10.10.33", job="MIB"} 0
Mib_MNP_WII_SCPwii_Status{instance="10.10.10.34", job="MIB"} 1Все метрики начинаются на слово Mib_ и заканчиваются на _Status, между этими словами спрятано название приложения.
Метка job равна “MIB”, 1 – приложение работает, 0 – приложение не работает.
Как лучше написать алерты?
Можно про каждое приложение сочинить отдельные правила, рискуя наделать ошибок и опечаток:

Можно сделать один ленивый алерт от Вовки, выкинув подробности:
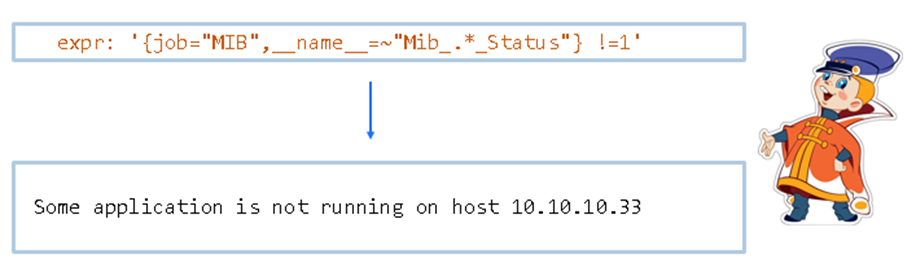
Но можно воспользоваться силой PromQL и сделать дополнительную метку Application вот так:
- alert: 'Application is not running'
#expr: '{job="MIB",__name__=~"Mib_.*_Status"} !=1'
expr: 'label_replace(
{job="MIB",__name__=~"Mib_.*_Status"},
"Application",
"$1", "__name__",
"Mib_(.*)_Status"
)
!= 1'
for: 0s
labels:
severity: 'warning'
annotations:
title: '{{ .Labels.Application }} is not running'
description: 'Metric Mib_{{ .Labels.Application }}_Status on host {{ .Labels.instance }} shows that
{{ .Labels.Application }} is not running'Тогда мы получим подробный алерт с информацией о приложении:

Сложные пороги срабатывания, *_over_time
Иногда бывает, что нам нужно работать с какой-то метрикой, которая очень дорого собирается и мы не можем позволить ее собирать каждую минуту. Собираем ее раз в 15 минут (900 секунд). Если мы попробуем отобразить в веб-интерфейсе Prometheus эту метрику, мы увидим вот такую картину:

Да, поиграв настройками в Grafana, мы можем сконфигурировать ее игнорировать null и соединять только те точки, данные которых есть, но алерт так построить не получится.
В такой ситуации нам поможет любая функция из набора *_over_time, например max_over_time.
В нашем примере для корректного срабатывания алерта нужно использовать выражение такого вида:
expr: max_over_time(hard_to_get_metric[900s]) > 5000Сложные пороги срабатывания, offset
Иногда нам нужно следить за какой-то бизнес-метрикой, которая сильно зависит от активности абонентов. Ночью абоненты спят, метрика падает, днем она снова растет. Нам нужно, чтобы мы могли заметить тот момент, когда метрика будет отличаться от целевого значения больше, чем на 10 процентов.
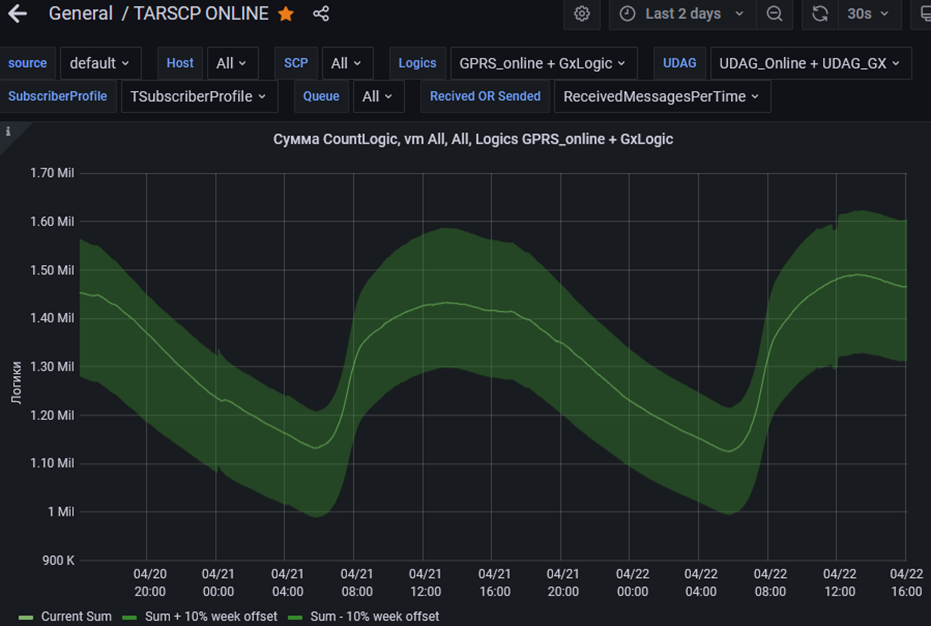
В этом случае мы можем снова привлечь PromQL и воспользоваться offset для того, чтобы сравнить значение метрики с ней самой же неделю назад:
expr: 'abs(
100 * (
Mib_SCP_ONLINE_CountLogic_counter
-
(Mib_SCP_ONLINE_CountLogic_counter{} offset 1w)
)
/
(Mib_SCP_ONLINE_CountLogic_counter{} offset 1w)
)
> 10'Надо сделать оговорку, что эту идею нужно совершенствовать: например, если неделю назад произошла авария, будет падать алерт при ее неповторении.
Следует ориентироваться на средние значения последних трех недель, которые можно заранее записать в соответствующие дополнительные метрики через rules. Я этот момент специально убрал для упрощения.
Иммунитет от алертов (тэг noAlarmOn)
В инфраструктуре бывают такие объекты, которые имеют право легитимно вести себя не так, как другие. Что делать, если мы не хотим получать об этом алерты?

При добавлении узла в inventory предлагаю ему присвоить новую метку noAlarmOn, в которой через запятую перечислять все события, для которых будет срабатывать иммунитет:
- targets:
- 10.10.10.10
labels:
jobs: "node_exporter,blackbox-ssh,hpilo,mpath,hperaid"
owner: "dba"
hostname: "mydb102"
sc: 10.10.11.10
vsp: plat198c7000
noAlarmOn: "bond,space"Изменения потребуются и в правилах алертов, например, алерт о неправильно работающем резервировании сетевых интерфейсов в Linux (bonding) будет выглядеть так:
- alert: "Bond degraded"
expr: (node_bonding_active{ noAlarmOn!~"(.*,|^)bond(,.*|$)" } - node_bonding_slaves) != 0
for: 1m
labels:
severity: 'warning'
annotations:
title: "Bonding status"
description: 'Bond {{ $labels.master }} is degraded.'Добавился фильтр по метке, которая не должна содержать слово bond: noAlarmOn!~"(.*,|^)bond(,.*|$)".
Фиксики (event handlers)
Можно сделать так, чтобы наша система мониторинга сама предпринимала попытки починить некоторые поломки.
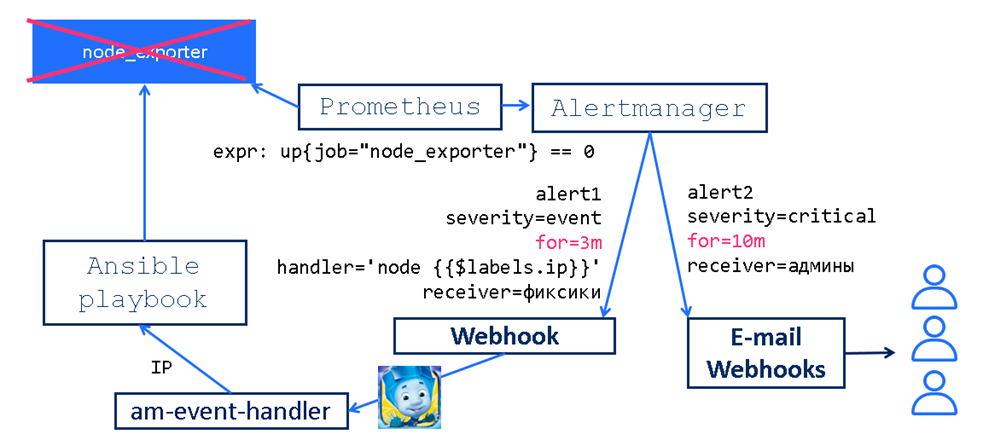
Мы заранее написали два правила по метрике up{job=”node_exporter”} ,чтобы первое срабатывало через 3 минуты с меткой severity=event (+ доп. метка handler с IP), а второе - через 10 минут с меткой critical.
В AlertManager мы заранее сделали правило, что алерты с severity=event мы передаем только для webhook an-event-handler.
Как это работает?
Предположим, что на нашем наблюдаемом узле разработчик решил включить firewall. И, конечно, не прорезал порт 9100 для агента node_exporter. Все сломалось.
Через три минуты возникнет алерт c severity=event и AlertManager отдаст его an-event-handler, который посмотрит в аннотацию “node IP” и поймет, что ему нужно запустить Ansible playbook по установке node_exporter на узел с этим IP. Именно этот playbook в конце увидит, что теперь включен firewall и необходимо прорезать в нем дополнительную дырку 9100/tcp. Таким образом наш алерт починится.
Но если ситуация более сложная и ansible не сможет, например, подключиться к узлу, то через шесть с половиной минут загорится второй алерт с severity=critical, по которому уже и отработают админы.
Заключение
Prometheus - продвинутая система мониторинга. На каждый жизненный вызов в ней можно что-то придумать. Надеюсь, эта моя публикация будет вам полезна. Оставляю ссылки на источники, где можно подробнее изучить вопрос.
Ссылки
Наборы готовых алертов awesome-prometheus-alerts, даже если у вас уже все, казалось бы, мониторится. Возможно там найдется что-то важное, о чем вы забыли.
О unit testing в Prometheus.
Solaris exporter (к теме не относится, но это тоже моя работа, вдруг в вашем зоопарке есть Solaris?).
HP iLO exporter (мой вариант exporter для HPE iLO, существенно переработанный).
Инструмент по экcпорту/импорту дашбордов в Grafana Grafana-Import-Export (вам это тоже понадобится, когда вы будете делать синхронизацию дашбордов в разных экземплярах Grafana).
