Любой измерительный прибор, будь то аналоговый или цифровой, показывает результат с определенной погрешностью и шумом. Погрешность GPS сенсора определяется погрешностью самого датчика и такими факторами как: ландшафт, скорость движения, количество и положение спутников.
В нашем приложении мы предоставляем пользователю возможность детально просмотреть маршруты его поездок. И если отображать сырые, не отфильтрованные данные, то получится, что маршрут проходит не по дороге, а через здания или по воде, некоторые точки маршрута сильно удалены от соседних или даже отсутствуют куски маршрута.
Думаю, ни для кого не секрет, что на рынке есть решения, которые предоставляют сервис Map matching. Он выполняет обработку координат и в результате выдает координаты, привязанные к дороге. Однако, ни один сервис не будет понимать специфику ваших данных, а результат обработки сырых данных может быть не самым лучшим. В связи с этим нами было разработано решение, которое позволило максимально отфильтровать и наложить на дороги данные с датчиков.
Входные данные
На момент начала разработки OBD-донгл передавал на сервер телематические данные в виде точек, у каждой из которых были следующие параметры:
- Координаты, полученные с GPS сенсора;
- Скорость, полученная от автомобиля;
- Обороты двигателя, полученные от автомобиля;
- Время конкретной точки.
Точки передавались по следующему алгоритму – раз в 3 секунды или каждые 20 метров. Отметим, что алгоритм передачи не идеальный, но в рамках конкретной проблемы мы решили его не менять, т.к. очевидно, что если передавать точки по более совершенному алгоритму, то результат работы только улучшится. Также донгл собирал такие данные как: heading (вектор движения) и dilution of precision (грубо говоря, точность GPS), однако на сервер эти данные не передавались.
Алгоритм
Алгоритм, который мы применяли, можно разделить на две части:
- Фильтрация данных;
- Map matching;
- Частичная обработка.
Фильтрация
Никто не знает специфику ваших данных лучше, чем вы сами. Мы решили воспользоваться нашими знаниями и сделать фильтрацию данных на стороне собственного сервиса. Давайте рассмотрим простой пример маршрута:

На графике отображены скорость машины, полученная донглом от автомобиля, и скорость, подсчитанная из GPS. Как видно, на графике есть много выбросов — как в большую, так и в меньшую стороны. Сразу на ум приходят стандартные алгоритмы фильтрации: фильтр Калмана, alpha-beta filter. За них мы и взялись в первую очередь. Однако, подобные фильтры показали себя не с лучшей стороны. На то было несколько причин: низкая частота и абсолютная разнородность данных (сложно подобрать единый модифицированный алгоритм с подходящей погрешностью), наличие трансформаций входящих данных было неприемлемо. Куда лучше в ходе тестирования себя показал очень простой линейный фильтр скорости. Суть алгоритма очень проста: для всех соседних точек вычисляем скорость по GPS и сравниваем с скоростью, полученной от автомобиля, и если отличия выше, чем допустимая погрешность, то выкидываем одну из точек.
Вот псевдокод:
`for i in range(1, len(data)):
velocity_gps = calc_dist(data[i - 1].lat, data[i - 1].lon, data[i].lat, data[i].lon) / (data[i] - data[i - 1])
velocity_vehicle = (data[i - 1].speed + data[i].speed) / 2
relative_error = abs(velocity_gps - velocity_vehicle) / (velocity_vehicle)
if relative_error > 1.5:
data.remove(data[i])`В результате фильтрации, получаем данные без выбросов, при этом, точки по-прежнему не ложатся на дорогу. Однако перед процедурой Map matching стоит еще проредить наши данные, т.к. нет смысла передавать 10 точек, лежащих на одной прямой, когда для определения прямой достаточно двух точек. Тем не менее не надо усердствовать с фильтрацией, ибо сервис Map matching может посчитать наши данные шумом. Для удаления лишних точек мы пользовались алгоритмом Ramer-Douglas-Peucker, а точнее его немного модифицированной версией.

Для упорядоченной по времени пачки точек вычисляем расстояние для всех точек до дуги, соединяющей первую и последнюю точки пачки. Если расстояние от каждой точки меньше некоторого значения E, то возвращаем только начальную и конечную точки пачки. Иначе делим пачку на две, деление происходит в точке максимально удаленной от дуги, и затем повторяем процедуру.
Map matching
Ввиду того, что карты для наших мобильных приложений и порталов предоставлены сервисом Mapbox, было решено пользоваться их сервисом Map matching. Но мы сразу столкнулись с ограничением — 100 точек в запросе. Даже с учетом фильтрации и уменьшения числа точек алгоритмом RDP среднее число на наших маршрутах получается — 250 точек. Соответственно, нам нужно обрабатывать батчами (batch), плюс ко всему внахлест, т.к. в некоторых случаях при простом батчинге будут происходить ошибки обработки. Алгоритм батчинга следующий:
- N — число точек для обработки внахлест;
- Нарезаем роут на батчи размером не более 100-N;

- Затем обрабатываем первый батч;
- Берем последние N точек обработанных данных и второй батч;
- Продолжаем до последнего батча;
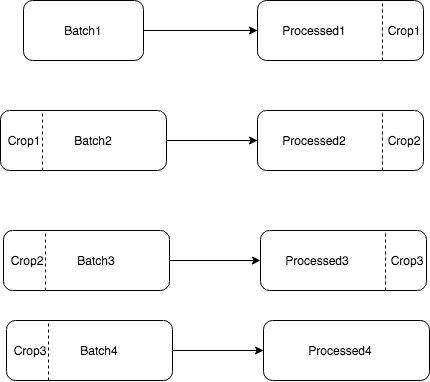
- Конечный результат состоит из Processed1, Processed2, Processed3, Processed4.

Следующей проблемой, с которой мы столкнулись, было определение точности данных. API Mapbox требует указывать точность передаваемых данных, несмотря на то, что в документе этот параметр указан как опциональный. И если его не передавать, он будет выставляться из дефолтного значения. Параметр, отвечающий за точность — gps_precision. Вот что говорится о нем в документации:
An integer in meters indicating the assumed precision of the used tracking device. Use higher numbers (5-10) for noisy traces and lower numbers (1-3) for clean traces. The default value is 4.
Однако, эти данные мы не передавали с донгла на момент разработки сервиса. Ввиду редкой частоты данных, использовать алгоритмы определения уровня шума оказалось невозможным. Таким образом, мы произвели обработку некоторого количества маршрутов и попробовали найти наиболее подходящие параметры. Но как произвести выбор лучшего параметра для 1000 маршрутов? Вручную делать это нецелесообразно. Оказалось, что этот процесс можно автоматизировать из-за специфики результатов с неудачно выбранным параметром. Если выбрать слишком низкое значение параметра — могут пропасть куски маршрута, а если завысить параметр, то появятся лишние петли.

Для выявления подобных случаев хорошо подходит алгоритм DTW. В результате обработки 1000 маршрутов и сравнения результатов работы с помощью алгоритма DTW, стало ясно, что лучшие результаты получаются с значениями precision 3, 6, 10 (в разных случаях).
В итоге, в отсутствии данных с GPS о точности, мы запустили обработку параллельно с тремя различными gps_precision (3,6,10), а затем выбрали лучший из них. Также было запланировано добавление отправки с донгла параметра dilution, что позволило сильно улучшить качество работы сервиса.
Частичная обработка
Конечные точки маршрутов часто бывают в местах, где дорога на карте не обозначена (парковки, пути между домами и т.д.). Алгоритмы Map matching в таких ситуациях работают не очень хорошо, и хотелось бы максимально точно указывать, где пользователь оставил свое авто. Для решения этой проблемы мы стали производить цикл обработки не всего маршрута, а только внутренних точек: отбрасываем начало и конец маршрута, затем к обработанным данным добавляем начало и конец оригинального маршрута. Начало и конец определяем следующим образом: берем 5% маршрута либо часть до того, как скорость авто станет больше 10км/ч.
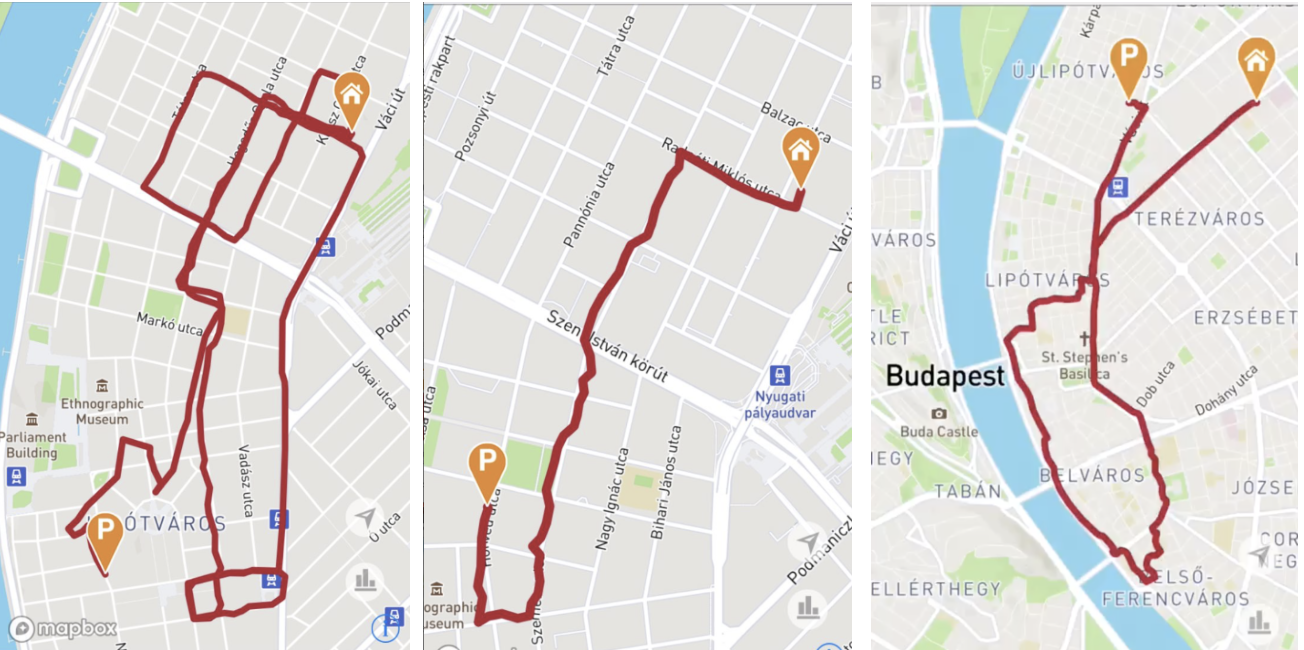
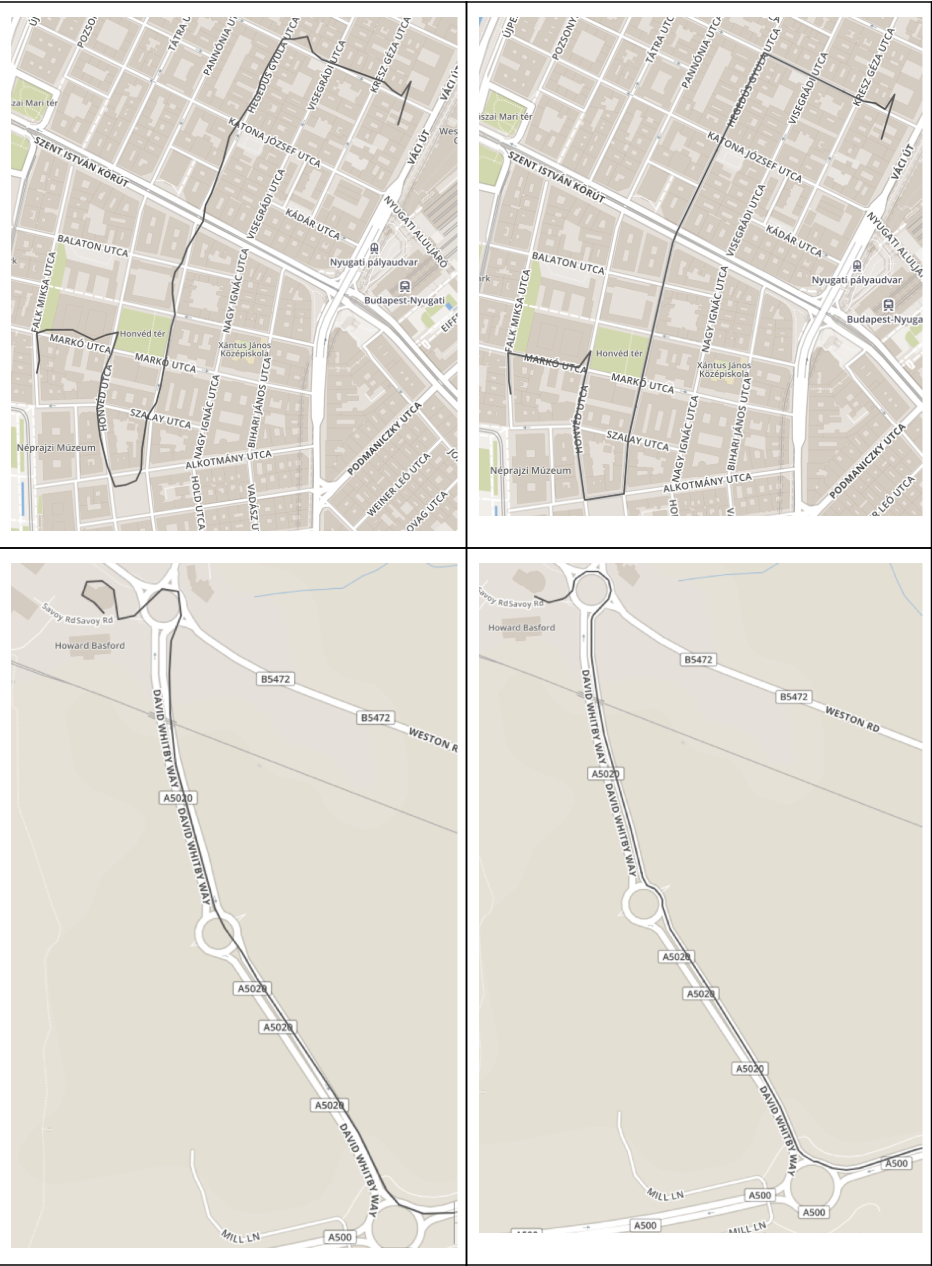
Конечный результат
В конце хотелось бы продемонстрировать результат процессинга маршрутов. В результате маршруты проходят почти везде по дорогам, сильные шумы исчезли, пропущенные куски маршрутов были восстановлены (езда по кольцу или мосту).

Автор: Кирилл Кульченков, kulchenkov32, Senior Software Developer, Bright Box.
