
Некоторое время назад мы организовали оцифровку 90-томного собрания сочинений Льва Николаевича Толстого, в этом нам помогали более 3 тысяч волонтеров. Публикаций об этом краудсорсинговом проекте было много, но ни одна из них не касалась технической части – именно о ней и пойдет речь в этой статье.
Итак, перед нами стояла задача перевести в форматы электронных книг (ePub, fb2, html, mobi), а также в PDF с текстовым слоем самое полное собрание сочинений Толстого. Оно выпускалось в течение 30 лет: с 1928 по 1958 год, каждый том выходил тиражом 5 тыс. экземпляров. До выпуска электронного издания это собрание сочинений не переиздавалось и уже стало труднодоступным раритетом. В 90-томник входят: художественные произведения (1–45 тома), дневники и записные книжки (46–58 тома), письма (59–90 тома). Был ещё секретный 91-й том, который состоял целиком из указателей и поэтому доставил нашим редакторам много
Оцифровать что угодно в наше время не проблема, когда под рукой нужные технологии, а вот вычитать такие большие объемы текста и исправить все неточности распознавания – это огромная работа, которая требует либо неограниченный ресурс времени
Собрание сочинений было отсканировано Российской государственной библиотекой в 2006 году, и нам для работы достались PDF-файлы (только изображения, без текстового слоя), один том (а это от 400 до 600 страниц) – один файл. Файлы вместе занимали всего-то навсего 4 Гб.
Поскольку выверять тексты предстояло волонтерам, мы решили разделить файлы на небольшие части («пакеты») – чтобы работа не казалась людям сложной и трудозатратной, чтобы было интересно и не скучно. Нам показалось, что пакет размером 20 страниц вполне удовлетворяет этим условиям. Итак, все PDF-файлы были автоматически «разрезаны» на части при помощи ABBYY Recognition Server, из каждого тома получилось около 20 файлов – в зависимости от изначального количества страниц, формат остался по-прежнему PDF. При разделении томов никакими другими условиями, кроме количества страниц, мы не руководствовались – так, в один пакет могло попасть окончание одного произведение и начало другого.
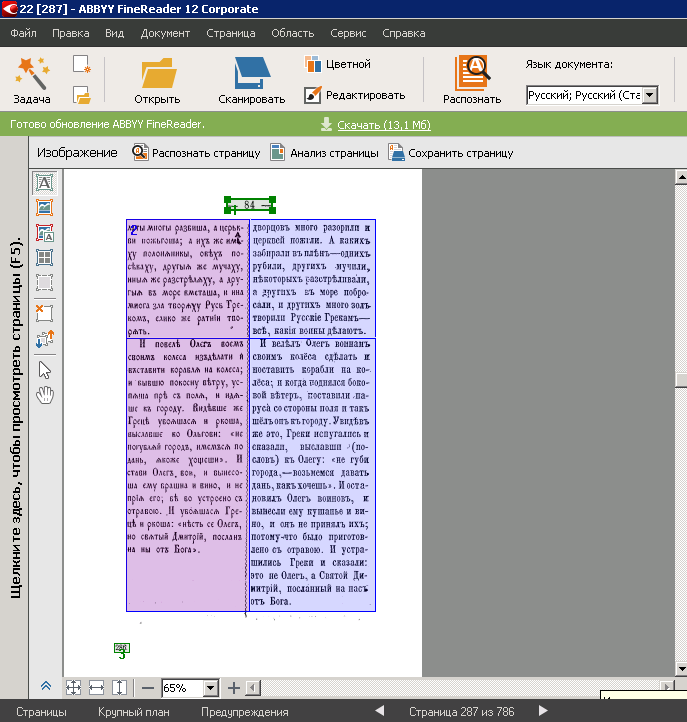
Дальше получившиеся пакеты нужно было распознать – это сделал наш сотрудник при помощи ABBYY FineReader (использовалась 11 версия). Обычно распознавание документов состоит из нескольких этапов. Сначала вы сканируете документ (или открываете в программе готовый скан, как было в нашем случае), потом программа анализирует документ и размечает области – изображения (они не распознаются, т.е. текст из них не извлекается), текст, таблицы, сноски. Дальше программа распознаёт всё, что должна распознать, потом у нас есть возможность проверить, всё ли получилось правильно (сравнить скан с результатом распознавания).
Итак, наш сотрудник «прогонял» сканы через FineReader и работал с разметкой областей (проверять правильность распознавания предстояло волонтерам). Тут и началось самое
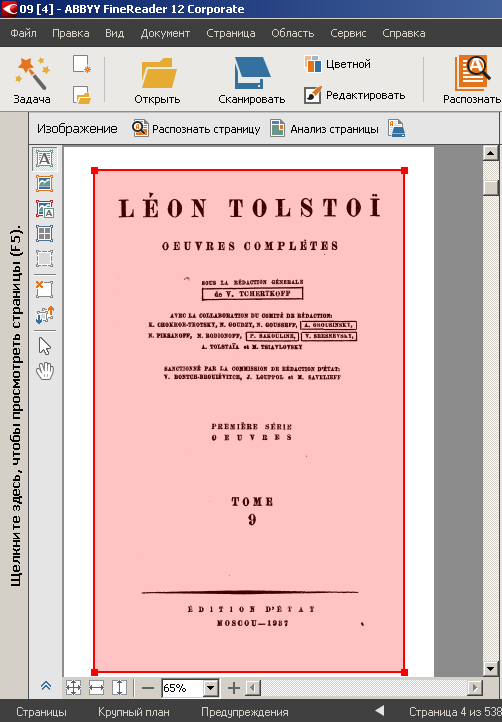
Обложка одного из томов (стандартная разметка FineReader: область «изображение» выделяется красным цветом, «текст» – зеленым, «таблица» – фиолетовым)
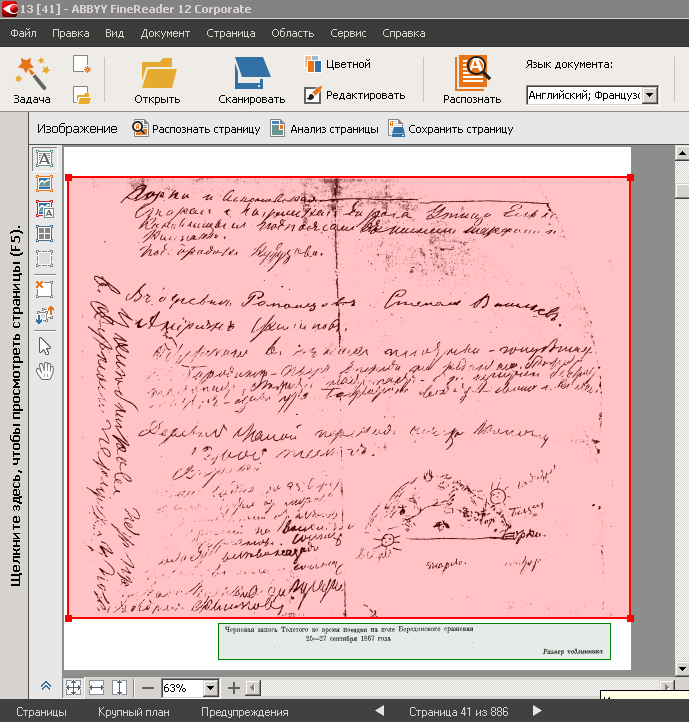
Рукописные заметки Толстого
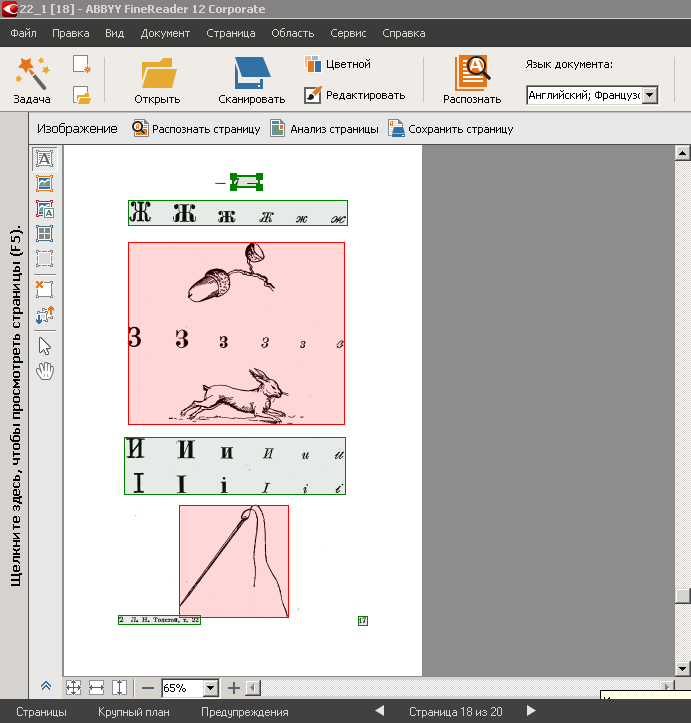
В некоторых произведениях, например, в «Азбуке», было очень много картинок и совсем мало текста – мы решили, что большая часть содержимого страниц будет оставлена изображениями. Так автоматически разметил области FineReader:
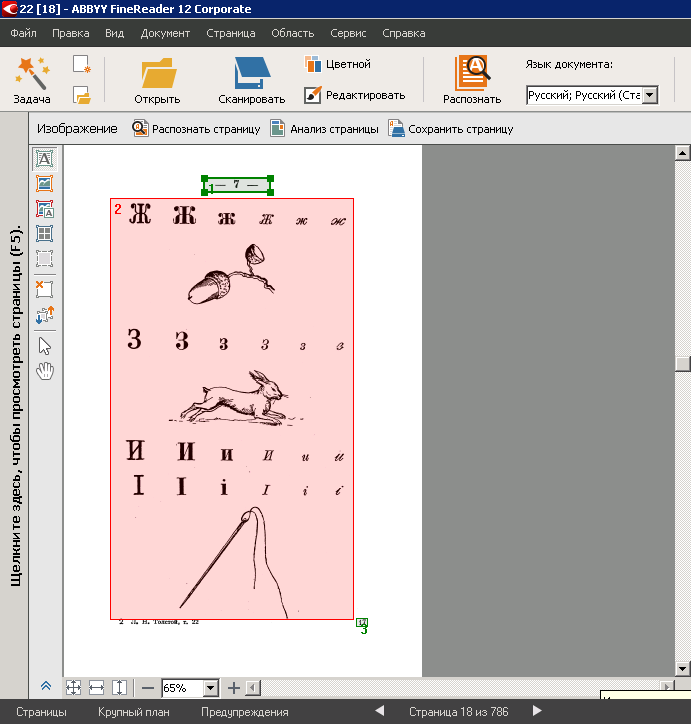
А так было удобно нам:
В выходных данных некоторых томов некоторые фамилии обведены рамками – такие места тоже помечались как изображения. Для дальнейшей работы с текстами было удобно, чтобы номера страниц были помечены областью «колонтитул». В одном из томов у Толстого приведены отрывки из «Повести временных лет» и других произведений на древнерусском языке. Этого языка FineReader не распознает, поэтому мы изначально подготовили таблицу, где такие фрагменты определены как изображения.
Размеченные таким образом и распознанные страницы сохранялись в собственном формате документа (или пакета) FineReader. Такой документ представляет папку, содержащую кучу файлов. Чтобы волонтеры могли скачать пакет одним файлом с сайта, документ архивировался в zip. Когда пакеты были готовы, их выложили на специально созданный сайт проекта, откуда волонтёры могли их скачать для проверки. Вкратце о том, как делали сам сайт, интересующиеся могут прочитать под спойлером.
Краудсорсинговая платформа
Краудсорсинговая платформа
Нужно было сделать платформу для совместной работы большого количества людей (волонтёров) в весьма сжатые сроки – на разработку самой платформы у нас было всего около месяца.
Платформу писали на Ruby в связке с СУБД MySQL, в качестве репозитория и управления разработкой использовалась система BitBucket. Составляющие платформы:
1. информационная часть (состоит из статических страниц о проекте, новости, FAQ и т.д.)
2. приложение (управляет пользователями, книгами, пакетами и процессами)
3. хранилище файлов в исходном, а также во всех промежуточных состояниях фрагментов книг.
Для надежного функционирования всего проекта в целом была использована архитектура на базе облачного хранилища Amazon с возможностью масштабирования.
По итогам проекта собралась вот такая техническая статистика:
• пиковая нагрузка – 6 запросов в секунду, в среднем 2-3
• пик – 9600 уникальных посетителей в первую неделю проекта, 3000 на третий день (20 июня)
• максимальная посещаемость 12.00-18.00, минимальная 4-6 часов утра.
Нужно было сделать платформу для совместной работы большого количества людей (волонтёров) в весьма сжатые сроки – на разработку самой платформы у нас было всего около месяца.
Платформу писали на Ruby в связке с СУБД MySQL, в качестве репозитория и управления разработкой использовалась система BitBucket. Составляющие платформы:
1. информационная часть (состоит из статических страниц о проекте, новости, FAQ и т.д.)
2. приложение (управляет пользователями, книгами, пакетами и процессами)
3. хранилище файлов в исходном, а также во всех промежуточных состояниях фрагментов книг.
Для надежного функционирования всего проекта в целом была использована архитектура на базе облачного хранилища Amazon с возможностью масштабирования.
По итогам проекта собралась вот такая техническая статистика:
• пиковая нагрузка – 6 запросов в секунду, в среднем 2-3
• пик – 9600 уникальных посетителей в первую неделю проекта, 3000 на третий день (20 июня)
• максимальная посещаемость 12.00-18.00, минимальная 4-6 часов утра.
Механика процесса выглядела так: волонтёр регистрировался на сайте www.readingtolstoy.ru, заходил в личный кабинет, где мог взять один пакет объемом 20 страниц для верификации. Пакеты выдавались пользователям по порядку их следования в томе – чтобы быстрее собирались целые тома.
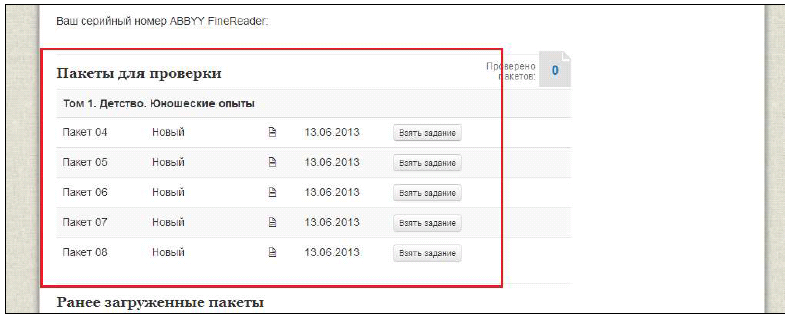
Все участники получили лицензию к ABBYY FineReader 11 Professional Edition сроком действия до конца 2013 года. В программе уже были настроены языки распознавания, которые встречаются у Толстого – старорусская орфография, английский, французский, немецкий, греческий и т.д.
Перед волонтёрами ставилось две задачи. Первая – проверить правильность разметки областей. Внимательный читатель скажет – ведь это уже было сделано на прошлом этапе. Но при распознавании правильная разметка областей – это примерно половина успеха, поэтому волонтёры тоже должны были убедиться в том, что документ размечен правильно. Вторая – проверить неточно распознанные символы, сравнить результат распознавания с оригиналом и исправить ошибки. Ошибки были двух видов: неправильно распознанные символы в тексте (там, где качество скана было плохим) и в расположении абзацев – абзацы иногда склеивались или, наоборот, разбивались там, где не надо.
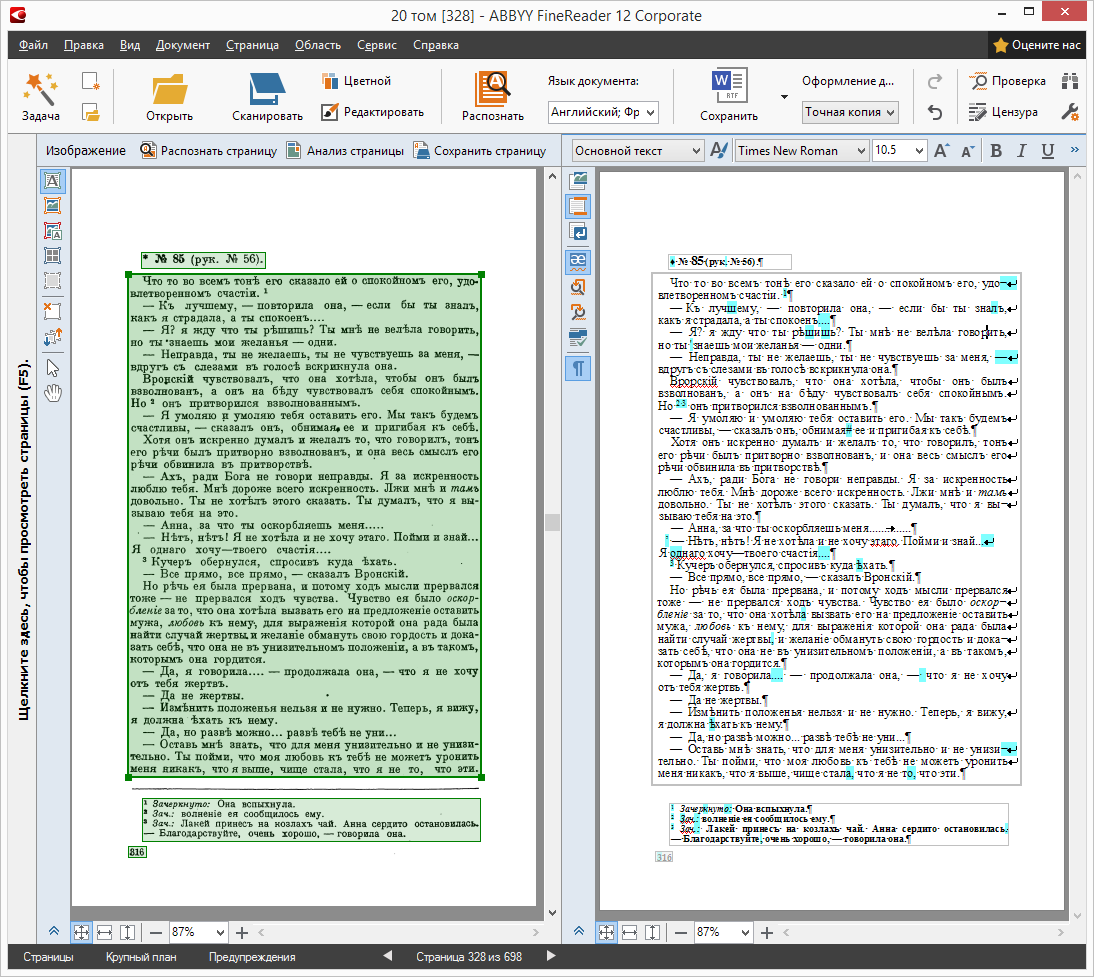
Ещё люди должны были корректировать разбивку страницы – в случае переноса слова с одной страницы на другую нужно было «склеивать» слово и оставлять его целиком на одной из страниц. В помощь волонтёрам давалась подробная инструкция.
Пакет нужно было проверить и вернуть на сайт в течение 48 часов. Как мы помним, участник скачивал заархивированный файл и в том же виде должен был его залить обратно на сайт. Если пакет не возвращался, он попадал в выдачу во второй раз. За проверенные пакеты начислялись баллы, самые активные участники получали призы – электронные книги Onyx, программы ABBYY FineReader и другие подарки. А главные герои отправились на двухдневную экскурсию в музей-усадьбу «Ясная Поляна», где могли лично пообщаться с праправнучкой писателя Фёклой Толстой и другими организаторами проекта.
По правде сказать, мы не думали, что наша инициатива получит такой активный отклик среди читателей Толстого, но регистрироваться люди начали уже во время пресс-конференции, посвященной открытию сайта проекта, а всё собрание сочинений проверили всего за две недели.

Первый этап проекта привлёк 1600 участников.
Когда мы стали проверять пакеты, качество работы оказалось неоднородным. Большинство волонтеров подошли к делу ответственно, но были и ошибки. После проверки большей части пакетов начался второй тур – проверка тех же самых пакетов так называемыми «аудиторами».
Аудиторами могли стать как участники первого тура, хорошо справившиеся с работой, так и новые волонтёры. Все претенденты должны были пройти тестирование, которое включало вопросы, связанные с верификацией текстов. Аудиторы проверяли готовые пакеты, исправляли ошибки и выставляли участникам первого тура дополнительные оценки, на которые потом обращали внимание организаторы.
После этого пакеты поступали в специальную базу на сайте. Когда были готовы все пакеты из одного тома, администратор проекта видел это, скачивал все пакеты тома с сайта и собирал обратно в единый документ (всё ещё в формате FineReader) с помощью специальной утилиты, которую написали наши разработчики. Потом наш сотрудник проверял, правильно ли собрался том, не сбита ли нумерация страниц и т.п. После этого готовый том передавался обратно администратору.
Хотя качество работы аудиторов было выше всяких похвал, мы все же хотели перестраховаться и устроили третий тур проверки текстов – на этот раз целыми томами. Из числа волонтеров мы сами выбрали 30 человек, хорошо зарекомендовавших себя на первых этапах, – они стали «редакторами», кроме того, на этом этапе к нам присоединилось небольшое количество новых волонтеров – лингвистов и профессиональных редакторов.
Редактор мог брать том только целиком, на проверку давалась одна неделя, по истечении которой человек должен был выгрузить документ обратно на сайт. Если редактор не успевал проверить том целиком, он указывал количество верифицированных страниц и загружал том на сайт. В этом туре проекта волонтеры работали так хорошо, что даже находили фактические ошибки, допущенные в бумажном издании – например, в выходных данных одного из томов были неправильно указаны инициалы одного из редакторов.
После третьего этапа проверки администратор экспортировал тома в формат MS Word и они отправлялись на проверку нашим штатным редакторам. Редакторы снова вычитывали файлы, исправления вносились как в Word-файл, так и в исходный пакет FineReader (для облегчения последующего сохранения из него в другие форматы).
По итогам проекта нам нужно было получить файлы таких типов:
1. PDF с текстовым слоем
2. Html, а также файлы форматов FB2, epub, mobi для электронных книг (на этом этапе к работе подключились наши партнеры из компании WEXLER, которые и занимались конвертацией полученных нами файлов в форматы электронных книг. Подробнее об этой работе – в статье руководителя центра разработки ПО компании WEXLER Саттара Гюльмамедова.
Ну и немного об итогах. В проекте приняли участие 3249 волонтеров из 49 стран мира. Всего по итогам работ получилось 670 книг, из которых 91 идентичны томам оригинального собрания сочинений и 579 произведений, «извлеченных» из томов. Всего это 2084 файла. Для 91-го тома была сделана только html-версия, поскольку этот указатель не будет интересен в форме электронной книги, а для 9 произведений не стали делать fb2-версию в силу некоторых ограничений формата.
Все электронные книги выложены на официальном портале, посвященном Толстому. А на сайте проекта www.readingtolstoy.ru сейчас размещена интерактивная карта, где каждый, кто скачал произведение Льва Николаевича Толстого, может отметить себя – в результате получается небезынтересная статистика по самым популярным среди пользователей произведениям и по странам и регионам с самими активными читателями.

Конечно, главная цель оцифровки собрания сочинений Толстого – предоставить доступ к наследию писателя всем читателям, но на этом польза не заканчивается. Тексты Толстого в электронном виде представляют большой интерес для исследователей-лингвистов. Об одном из таких исследований мы надеемся рассказать вам в одной из следующих статей.
