Ежегодно в России проходит крупнейшая конференция по компьютерной лингвистике «Диалог», на которой специалисты обсуждают методы компьютерного анализа русского языка, оценивают уровень компьютерного языкознания и определяют направления его развития. Каждый год в рамках «Диалога» организуются соревнования систем автоматической обработки русского языка — Dialogue Evaluation. В этом посте мы расскажем о том, как устроено соревнование Dialogue Evaluation, и более подробно о том, как проходит одна из его составляющих — RUSSE и что ждет его участников в этом году. Поехали.
Всего за последние семь лет состоялось 13 состязаний Dialogue Evaluation на самые разные темы: от соревнования морфологических анализаторов до кампании по оценке качества систем машинного перевода. Все они похожи на международные соревнования систем анализа текстов SemEval, но с фокусом на особенности обработки текстов на русском языке — богатую морфологию или более свободный, чем в английском языке, порядок слов. Задания на Dialogue Evaluation по структуре подобны задачам на Kaggle в области анализа данных, SemEval — в области компьютерной лингвистики, TREC — в области информационного поиска и ILSVRC — в области распознавания образов.
Перед участниками соревнования ставится задача, которую нужно решить в оговоренные сроки (как правило, за несколько недель). На SemEval и Dialogue Evaluation соревнования проходят в два этапа. Вначале участники получают описание задачи и обучающую выборку, которую можно использовать для разработки методов решения задачи и оценки качества полученных методов. Например, в дорожке 2015 года были пары семантически близких слов, которые участники могли использовать для разработки моделей векторных представлений слов. Организаторы обговаривают список внешних ресурсов, которые можно или нельзя использовать. На втором этапе участники получают тестовую выборку. Они должны применить к ней модели, разработанные на первом этапе. В отличие от обучающей выборки тестовая не содержит никакой разметки. Разметка тестовой выборки на этом этапе доступна только организаторам, что гарантирует честность соревнования. В результате участники отправляют свои решения на тестовой выборке организаторам, которые оценивают результаты и публикуют ранг участников.
Как правило, после окончания соревнований тестовые выборки выкладывают в публичный доступ. Их могут использовать в дальнейших исследованиях. Если соревнование проводится в рамках научной конференции, участники могут опубликовать доклады об участии в трудах конференции.
RUSSE — cоревнования по оценке методов вычислительной лексической семантики для русского языка
RUSSE (Russian Semantic Evaluation) — серия мероприятий по систематической оценке методов вычислительной лексической семантики русского языка. Первое соревнование RUSSE состоялось в 2015 году во время конференции «Диалог» и было посвящено сравнению методов, как определять семантическую близость слов (semantic similarity). Для оценки качества дистрибутивных моделей семантики впервые были созданы наборы данных на русском языке, аналогичные широко распространенным датасетам на английском — таким, как WordSim353. Более десяти команд оценивали качество таких моделей векторных представлений слов для русского языка, как word2vec и GloVe.
Второе соревнование RUSSE состоится в этом году. Оно будет сфокусировано на оценке векторных представлений значений слов (word sense embeddings) и других моделей для извлечения значений и разрешения лексической многозначности (word sense induction & disambiguation).
RUSSE 2018: извлечение значений слов из текстов и разрешение лексической многозначности
Многие слова языка имеют несколько значений. Однако простые модели векторных представлений слов, такие как word2vec, не учитывают этого и смешивают разные значения слова в одном векторе. Эту проблему призвана решить задача извлечения значений слов из текстов и автоматического обнаружения значений неоднозначного слова в корпусе текстов. В рамках соревнований SemEval исследовали методы по автоматическому извлечению значений слов и разрешению лексической многозначности для западноевропейских языков — английского, французского и немецкого. При этом систематическая оценка таких методов для славянских языков не проводилась. Соревнование 2018 года привлечет внимание исследователей к проблеме автоматического разрешения лексической многозначности и выявит эффективные подходы к решению этой задачи на примере русского языка.
Одна из основных трудностей при обработке русского и других славянских языков заключается в отсутствии или ограниченной доступности высококачественных лексических ресурсов, таких как WordNet для английского языка. Мы полагаем, что результаты RUSSE будут полезны для автоматической обработки не только славянских языков, но и других языков с ограниченными лексико-семантическими ресурсами.
Описание задачи
Участникам RUSSE 2018 предлагается решить задачу кластеризации коротких текстов. В частности, на этапе тестирования участники получают набор неоднозначных слов, например, слово «замок», и совокупность текстовых фрагментов (контекстов), в которых упоминаются целевые неоднозначные слова. Например, «замок владимира мономаха в любече» или «передвижение засова ключом в замке». Участники должны кластеризовать полученные контексты так, чтобы каждый кластер соответствовал отдельному значению слова. Число значений и, соответственно, число кластеров заранее неизвестно. В данном примере нужно сгруппировать контексты в два кластера, соответствующие двум значениям слова «замок»: «устройство, препятствующее доступу куда-либо» и «сооружение».
Для соревнования организаторы подготовили три набора данных из разных источников. Для каждого такого набора нужно заполнить столбец «идентификатор предсказанного значения» и загрузить файл с ответами, используя платформу CodaLab. CodaLab дает участнику возможность сразу увидеть свои результаты, вычисленные на части тестового набора данных.
Задача, поставленная на данном соревновании, близка к задаче, сформулированной для английского языка на соревнованиях SemEval-2007 и SemEval-2010. Отметим, что в задачах этого типа участникам не предоставляется эталонный перечень значений слова — т.н. инвентарь значений. Поэтому для разметки контекстов участник может использовать произвольные идентификаторы, например, замок#1 или замок (устройство).
Основные этапы соревнования
C 15 декабря по 15 января участники могут загрузить результаты решения задачи на платформу CodaLab. Всего предлагается разметить три набора данных, оформленных в виде отдельных задач на CodaLab:
В соревновании предлагаются три набора данных для построения моделей на основе различных корпусов и инвентарей значений слов, описанные в таблице ниже:
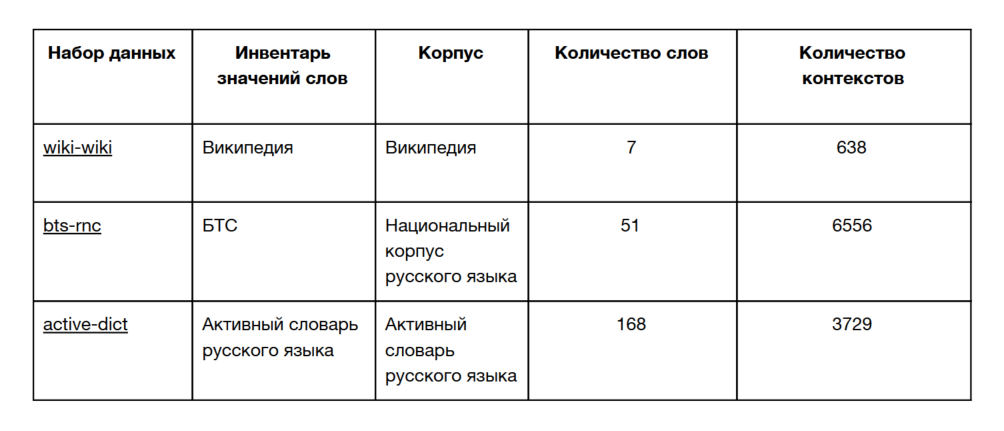
Первый набор данных (wiki-wiki) использует в качестве значений слов разделение, предложенное в Википедии; контексты взяты из статей Википедии. Набор данных bts-rnc в качестве инвентаря значений слов использует Большой толковый словарь русского языка под редакцией С. А. Кузнецова (БТС); контексты взяты из Национального корпуса русского языка (НКРЯ). Наконец, active-dict использует значения слов из Активного словаря русского языка под редакцией Ю. Д. Апресяна; контексты взяты также из Активного словаря русского языка — это примеры и иллюстрации из словарных статей.
Для обучения и разработки систем участникам предоставляются шесть наборов данных (три основных и три дополнительных), использующие различные инвентари значений слов. Все обучающие наборы данных перечислены в таблице:
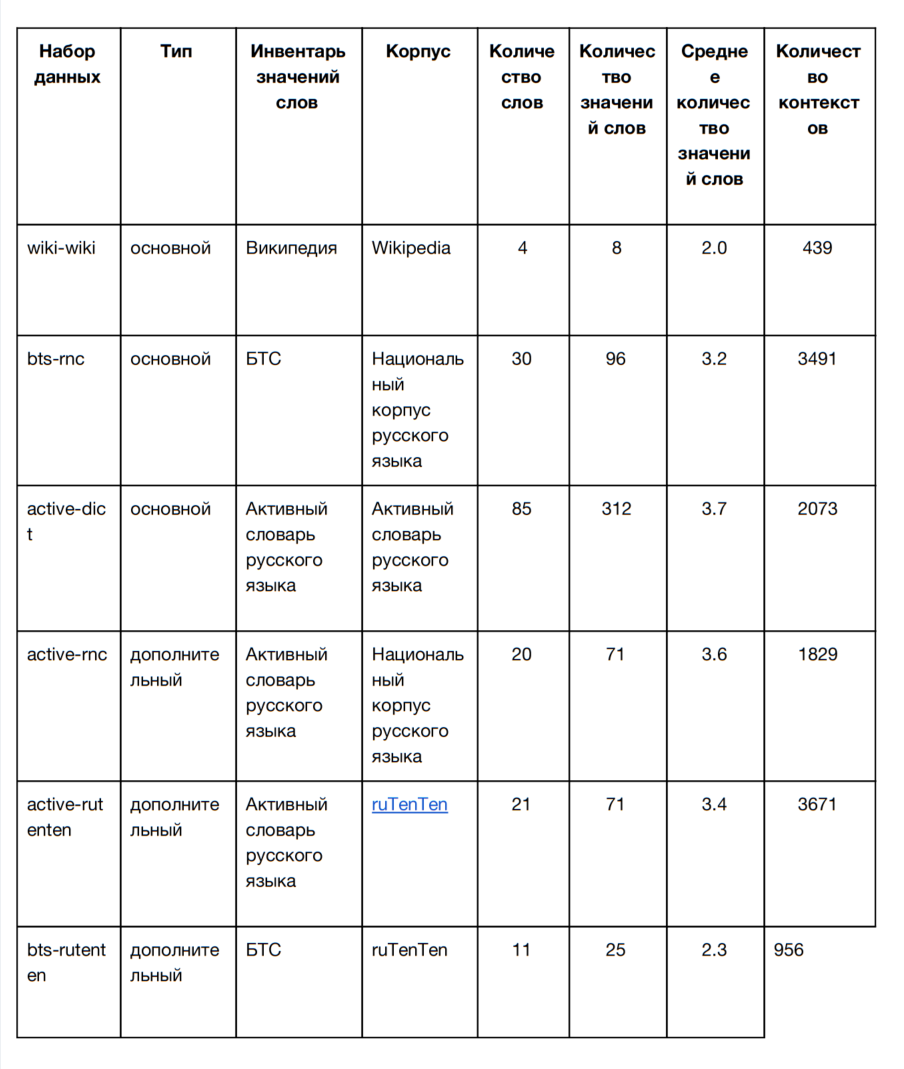
Тестовые наборы данных (wiki-wiki, bts-rnc, active-dict) устроены так же, как и обучающие. Но в них не заполнено поле со значением целевого слова — ‘идентификатор предсказанного значения’. Это поле заполняют участники. Их ответы будут сопоставлены с эталонными. Участвующие системы сравниваются на основе меры качества. Обучающие и тестовые наборы данных размечены по одному и тому же принципу, но целевые неоднозначные слова в них различаются.
Мера качества
Как и в других аналогичных соревнованиях, например, SemEval-2010, в нашем соревновании качество системы оценивается путем сопоставления ее ответов с золотым стандартом. Золотой стандарт — это множество предложений, в котором люди определяют значения целевых неоднозначных слов. Целевому слову в каждом предложении вручную приписан тот или иной идентификатор из заданного инвентаря значений слов. После того как система каждого участника укажет идентификатор предсказанного значения целевого слова в каждом предложении тестовой выборки, мы сравним группировку предложений по значениям слова от системы участника с золотым стандартом. Для сравнения мы будем использовать скорректированный коэффициент Рэнда. Такое сравнение можно считать сравнением двух кластеризаций.
Соревновательные дорожки
Соревнование включает в себя две дорожки:
Наш подход к оценке систем предполагает, что в соревновании может участвовать практически любая модель разрешения лексической многозначности: как подходы на основе машинного обучения без учителя (распределенные векторные представления, графовые методы), так и подходы на основе лексических ресурсов, таких как WordNet.
Эталонные системы
Чтобы сделать задачу более понятной, мы публикуем несколько готовых решений, с которыми можно сравнить свои результаты. Для дорожки без использования лингвистических ресурсов (knowledge-free) мы рекомендуем обратить внимание на системы разрешения лексической многозначности без учителя, например, AdaGram. Для дорожки с использованием лингвистических ресурсов (knowledge-rich) мы рекомендуем использовать векторные представления значений слов, построенные с использованием существующих лексико-семантических ресурсов, например РуТез и RuWordNet. Это можно сделать при помощи таких методов, как AutoExtend.
Рекомендации участникам
Обучающие наборы данных уже опубликованы. За отправную точку вы можете взять наши модели, опубликованные в репозитории на GitHub (там есть подробное руководство), и доработать и улучшить их. Пожалуйста, следуйте инструкциям, но не бойтесь задавать вопросы — организаторы будут рады помочь!
Обсуждение и публикация результатов
Участникам предлагается написать статью о своей системе и подать ее на
международную конференцию по компьютерной лингвистике «Диалог 2018». Труды этой конференции индексируются Scopus. В рамках специальной секции этой конференции будут обсуждаться результаты соревнования.
Организаторы
Организаторы соревнования будут рады ответить на ваши вопросы в группе в Google и на Facebook. Более подробная информация представлена на странице соревнования.
Спонсоры и партнеры

Dialogue Evaluation — соревнования по оценке качества методов анализа текстов на русском языке
Всего за последние семь лет состоялось 13 состязаний Dialogue Evaluation на самые разные темы: от соревнования морфологических анализаторов до кампании по оценке качества систем машинного перевода. Все они похожи на международные соревнования систем анализа текстов SemEval, но с фокусом на особенности обработки текстов на русском языке — богатую морфологию или более свободный, чем в английском языке, порядок слов. Задания на Dialogue Evaluation по структуре подобны задачам на Kaggle в области анализа данных, SemEval — в области компьютерной лингвистики, TREC — в области информационного поиска и ILSVRC — в области распознавания образов.
Перед участниками соревнования ставится задача, которую нужно решить в оговоренные сроки (как правило, за несколько недель). На SemEval и Dialogue Evaluation соревнования проходят в два этапа. Вначале участники получают описание задачи и обучающую выборку, которую можно использовать для разработки методов решения задачи и оценки качества полученных методов. Например, в дорожке 2015 года были пары семантически близких слов, которые участники могли использовать для разработки моделей векторных представлений слов. Организаторы обговаривают список внешних ресурсов, которые можно или нельзя использовать. На втором этапе участники получают тестовую выборку. Они должны применить к ней модели, разработанные на первом этапе. В отличие от обучающей выборки тестовая не содержит никакой разметки. Разметка тестовой выборки на этом этапе доступна только организаторам, что гарантирует честность соревнования. В результате участники отправляют свои решения на тестовой выборке организаторам, которые оценивают результаты и публикуют ранг участников.
Как правило, после окончания соревнований тестовые выборки выкладывают в публичный доступ. Их могут использовать в дальнейших исследованиях. Если соревнование проводится в рамках научной конференции, участники могут опубликовать доклады об участии в трудах конференции.
RUSSE — cоревнования по оценке методов вычислительной лексической семантики для русского языка
RUSSE (Russian Semantic Evaluation) — серия мероприятий по систематической оценке методов вычислительной лексической семантики русского языка. Первое соревнование RUSSE состоялось в 2015 году во время конференции «Диалог» и было посвящено сравнению методов, как определять семантическую близость слов (semantic similarity). Для оценки качества дистрибутивных моделей семантики впервые были созданы наборы данных на русском языке, аналогичные широко распространенным датасетам на английском — таким, как WordSim353. Более десяти команд оценивали качество таких моделей векторных представлений слов для русского языка, как word2vec и GloVe.
Второе соревнование RUSSE состоится в этом году. Оно будет сфокусировано на оценке векторных представлений значений слов (word sense embeddings) и других моделей для извлечения значений и разрешения лексической многозначности (word sense induction & disambiguation).
RUSSE 2018: извлечение значений слов из текстов и разрешение лексической многозначности
Многие слова языка имеют несколько значений. Однако простые модели векторных представлений слов, такие как word2vec, не учитывают этого и смешивают разные значения слова в одном векторе. Эту проблему призвана решить задача извлечения значений слов из текстов и автоматического обнаружения значений неоднозначного слова в корпусе текстов. В рамках соревнований SemEval исследовали методы по автоматическому извлечению значений слов и разрешению лексической многозначности для западноевропейских языков — английского, французского и немецкого. При этом систематическая оценка таких методов для славянских языков не проводилась. Соревнование 2018 года привлечет внимание исследователей к проблеме автоматического разрешения лексической многозначности и выявит эффективные подходы к решению этой задачи на примере русского языка.
Одна из основных трудностей при обработке русского и других славянских языков заключается в отсутствии или ограниченной доступности высококачественных лексических ресурсов, таких как WordNet для английского языка. Мы полагаем, что результаты RUSSE будут полезны для автоматической обработки не только славянских языков, но и других языков с ограниченными лексико-семантическими ресурсами.
Описание задачи
Участникам RUSSE 2018 предлагается решить задачу кластеризации коротких текстов. В частности, на этапе тестирования участники получают набор неоднозначных слов, например, слово «замок», и совокупность текстовых фрагментов (контекстов), в которых упоминаются целевые неоднозначные слова. Например, «замок владимира мономаха в любече» или «передвижение засова ключом в замке». Участники должны кластеризовать полученные контексты так, чтобы каждый кластер соответствовал отдельному значению слова. Число значений и, соответственно, число кластеров заранее неизвестно. В данном примере нужно сгруппировать контексты в два кластера, соответствующие двум значениям слова «замок»: «устройство, препятствующее доступу куда-либо» и «сооружение».
Для соревнования организаторы подготовили три набора данных из разных источников. Для каждого такого набора нужно заполнить столбец «идентификатор предсказанного значения» и загрузить файл с ответами, используя платформу CodaLab. CodaLab дает участнику возможность сразу увидеть свои результаты, вычисленные на части тестового набора данных.
Задача, поставленная на данном соревновании, близка к задаче, сформулированной для английского языка на соревнованиях SemEval-2007 и SemEval-2010. Отметим, что в задачах этого типа участникам не предоставляется эталонный перечень значений слова — т.н. инвентарь значений. Поэтому для разметки контекстов участник может использовать произвольные идентификаторы, например, замок#1 или замок (устройство).
Основные этапы соревнования
- 1 ноября 2017 г. — публикация обучающего набора данных
- 15 декабря 2017 г. — выпуск тестового набора данных
- 1 февраля 2018 г. — завершение приема результатов для оценки
- 15 февраля 2018 г. — объявление результатов соревнования
C 15 декабря по 15 января участники могут загрузить результаты решения задачи на платформу CodaLab. Всего предлагается разметить три набора данных, оформленных в виде отдельных задач на CodaLab:
- на основе Википедии,
- на основе иллюстраций и примеров из толкового словаря,
- на основе текстов из интернета
Наборы данных
В соревновании предлагаются три набора данных для построения моделей на основе различных корпусов и инвентарей значений слов, описанные в таблице ниже:

Первый набор данных (wiki-wiki) использует в качестве значений слов разделение, предложенное в Википедии; контексты взяты из статей Википедии. Набор данных bts-rnc в качестве инвентаря значений слов использует Большой толковый словарь русского языка под редакцией С. А. Кузнецова (БТС); контексты взяты из Национального корпуса русского языка (НКРЯ). Наконец, active-dict использует значения слов из Активного словаря русского языка под редакцией Ю. Д. Апресяна; контексты взяты также из Активного словаря русского языка — это примеры и иллюстрации из словарных статей.
Для обучения и разработки систем участникам предоставляются шесть наборов данных (три основных и три дополнительных), использующие различные инвентари значений слов. Все обучающие наборы данных перечислены в таблице:
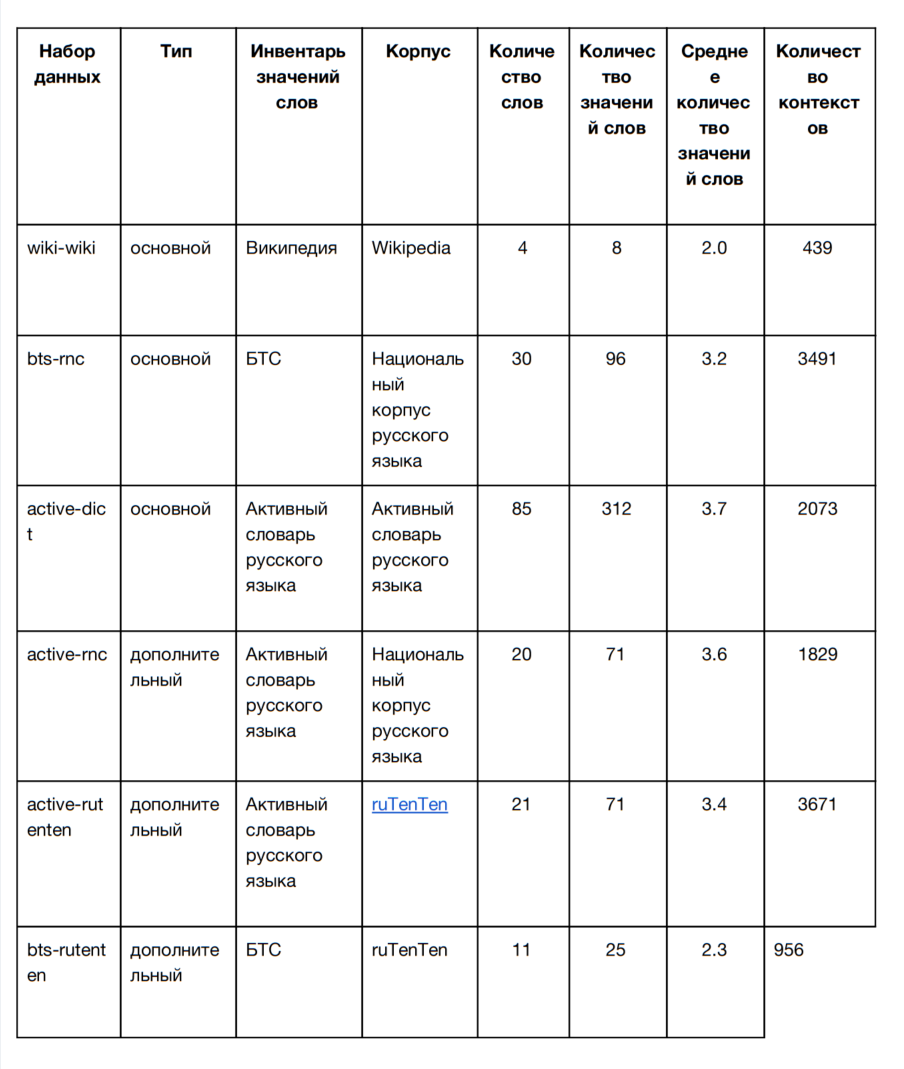
Тестовые наборы данных (wiki-wiki, bts-rnc, active-dict) устроены так же, как и обучающие. Но в них не заполнено поле со значением целевого слова — ‘идентификатор предсказанного значения’. Это поле заполняют участники. Их ответы будут сопоставлены с эталонными. Участвующие системы сравниваются на основе меры качества. Обучающие и тестовые наборы данных размечены по одному и тому же принципу, но целевые неоднозначные слова в них различаются.
Мера качества
Как и в других аналогичных соревнованиях, например, SemEval-2010, в нашем соревновании качество системы оценивается путем сопоставления ее ответов с золотым стандартом. Золотой стандарт — это множество предложений, в котором люди определяют значения целевых неоднозначных слов. Целевому слову в каждом предложении вручную приписан тот или иной идентификатор из заданного инвентаря значений слов. После того как система каждого участника укажет идентификатор предсказанного значения целевого слова в каждом предложении тестовой выборки, мы сравним группировку предложений по значениям слова от системы участника с золотым стандартом. Для сравнения мы будем использовать скорректированный коэффициент Рэнда. Такое сравнение можно считать сравнением двух кластеризаций.
Соревновательные дорожки
Соревнование включает в себя две дорожки:
- В дорожке без использования лингвистических ресурсов (knowledge-free track) участники должны кластеризовать контексты в соответствии с разными значениями и присвоить каждому значению какой-то идентификатор, используя только корпус текстов.
- В дорожке с использованием лингвистических ресурсов (knowledge-rich track) участники могут использовать любые дополнительные ресурсы, например, словари, чтобы выявить значения целевых слов.
Наш подход к оценке систем предполагает, что в соревновании может участвовать практически любая модель разрешения лексической многозначности: как подходы на основе машинного обучения без учителя (распределенные векторные представления, графовые методы), так и подходы на основе лексических ресурсов, таких как WordNet.
Эталонные системы
Чтобы сделать задачу более понятной, мы публикуем несколько готовых решений, с которыми можно сравнить свои результаты. Для дорожки без использования лингвистических ресурсов (knowledge-free) мы рекомендуем обратить внимание на системы разрешения лексической многозначности без учителя, например, AdaGram. Для дорожки с использованием лингвистических ресурсов (knowledge-rich) мы рекомендуем использовать векторные представления значений слов, построенные с использованием существующих лексико-семантических ресурсов, например РуТез и RuWordNet. Это можно сделать при помощи таких методов, как AutoExtend.
Рекомендации участникам
Обучающие наборы данных уже опубликованы. За отправную точку вы можете взять наши модели, опубликованные в репозитории на GitHub (там есть подробное руководство), и доработать и улучшить их. Пожалуйста, следуйте инструкциям, но не бойтесь задавать вопросы — организаторы будут рады помочь!
Обсуждение и публикация результатов
Участникам предлагается написать статью о своей системе и подать ее на
международную конференцию по компьютерной лингвистике «Диалог 2018». Труды этой конференции индексируются Scopus. В рамках специальной секции этой конференции будут обсуждаться результаты соревнования.
Организаторы
- Александр Панченко, Гамбургский университет
- Константин Лопухин, Scrapinghub Inc.
- Анастасия Лопухина, Лаборатория нейролингвистики НИУ ВШЭ и ИРЯ РАН
- Дмитрий Усталов, Университет Мангейма и ИММ УрО РАН
- Николай Арефьев, МГУ и Исследовательский центр Samsung
- Наталья Лукашевич, МГУ
- Алексей Леонтьев, ABBYY
Контакты
Организаторы соревнования будут рады ответить на ваши вопросы в группе в Google и на Facebook. Более подробная информация представлена на странице соревнования.
