
Привет, Хабр! Наверняка вы помните посты о том, как наш ABBYY Recognition Server помогал в оцифровке материалов и каталогов библиотек на Сахалине, в Латвии, Великобритании и в других странах. Мы давно не рассказывали об этом продукте, а ведь все это время он развивался. Мы обучили его новым способностям, прокачали его навыки с помощью интеллектуальных OCR-технологий последнего поколения и даже дали новое имя – ABBYY FineReader Server. Объясняем: под общим брендом FineReader мы объединили все продукты для распознавания, конвертации и редактирования документов.
Сегодня ABBYY FineReader Server помогает не только оцифровывать материалы из библиотек и архивов, но и упорядочивать хранение информации в крупных компаниях. Например, группа FESCO оцифровывает бухгалтерские счета и транспортные накладные и отправляет их в единый электронный архив, чтобы быстрее проводить транзакции, а сотрудники PwC прямо с мобильного телефона конвертируют фотографии счетов, договоров и других документов в PDF с возможностью полнотекстового поиска и отправляют их в корпоративные системы. В США юридическая фирма Kantor & Kantor использует это решение, чтобы быстрее находить значимую информацию в тысячах страниц судебных дел.
В этом посте мы расскажем о нескольких новых возможностях ABBYY FineReader Server: как они технически реализованы и для чего крупные компании пользуются ими.
По данным исследования O’Reilly «Состояние качества данных в 2020 году», большинство крупных компаний испытывают трудности при работе с корпоративной информацией. Например, 60% опрошенных отметили большое число корпоративных источников и дублирование информации в них, а 49% – отсутствие контроля над качеством входящих данных. Дубликаты – не единственная проблема. Информация устаревает, а объемные и уже не актуальные файлы замедляют поиск информации, затрудняют работу корпоративных систем, да и занимают место, что напрямую влияет на стоимость хранения данных. Это не тот балласт, который стоит переносить в новенькие DMS или ECM-системы.
На самом деле такие проблемы знакомы и каждому пользователю. Достаточно иногда взглянуть на свой рабочий стол, чтобы понять: пора навести порядок в этом зоопарке. Что уж говорить о корпоративном хранилище большой компании, где сотрудников тысячи, а документов — миллионы.

Справиться с этими проблемами – управлять потоками документов, хранить только нужные данные и в необходимом вам формате – помогают технологии интеллектуальной обработки информации. Ниже мы расскажем о нескольких возможностях, которые появились в ABBYY FineReader Server и помогут избавиться от хаоса:
- Автоматическое удаление полных дубликатов;
- Предварительная обработка документов;
- Улучшенное распознавание большинства популярных штрих-кодов, включая ISBN, PDF417, Aztec и QR;
- Единый веб-интерфейс для распознавания и конвертации файлов;
- Улучшенное сжатие цветных изображений.
Полные дубликаты: найти и остановить

В компаниях любого размера, как правило, есть электронные архивы, которые наполнялись в течение многих лет. Допустим, в вашем SharePoint’е исторически накопилось много файлов. Что там хранится и как можно быстро найти нужный документ – иногда большая тайна даже для его создателей. Но не для ABBYY FineReader Server. В нем есть режим работы Аудит, который позволяет посмотреть, какие документы размещены в хранилище и сколько их.
Сначала вы получите общую статистику по файлам: сколько изображений в графическом формате, скан-копий документов, PDF с текстовым слоем, документов MS Word. Кроме того, вы увидите и общее количество файлов в других, не текстовых форматах: видео, аудио, исполняемые файлы, системные файлы приложений и т.д. Их ABBYY FineReader Server не обрабатывает, но они существуют в архиве и это стоит учитывать. Аудит также определит, сколько всего документов стоит конвертировать, какие в хранилище есть группы дубликатов и где они лежат. Расскажем о них подробнее.
Хэш-сумма – это уникальный идентификатор файла. Он высчитывается компьютером путем математических преобразований информации, содержащейся в нем. Если файлы являются дубликатами, то хэши у них будут совпадать, даже если у файлов разные имена и расширения.
При аудите FRS считает хэш-сумму каждого файла, а затем сравнивает их между собой. Если они совпадают, значит, файлы, скорее всего, являются полными дубликатами и попадут в отчет:
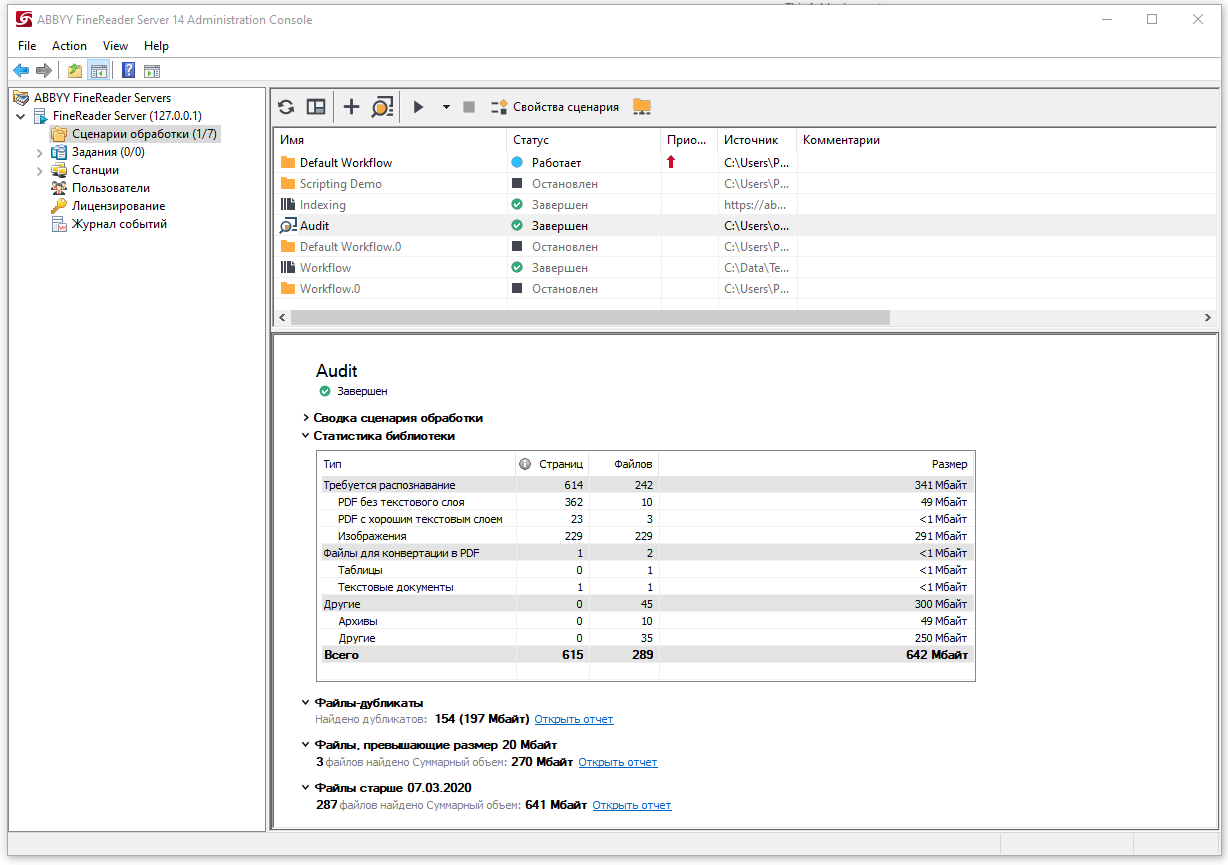
На скриншоте видна статистика: сколько картинок и сканов нужно распознать перед конвертацией, сколько текстовых документов можно перевести в PDF и сколько в хранилище файлов, которые невозможно обработать с помощью FRS. Под табличкой есть отчет по дубликатам и по файлам, чей размер больше 20 МB.
Допустим, компания решила организовать централизованный электронный архив на базе SharePoint вместо десятка разрозненных хранилищ. Для этого сначала необходимо проанализировать, какие файлы годами копились и сейчас содержатся в архивах. Вдруг там полно дубликатов и устаревших документов? А компании как раз не нужны такие копии, потому что хочется хранить меньше документов и легче искать в них нужную информацию. Проведя аудит, можно аккуратно заглянуть в черную дыру электронное хранилище и посмотреть, есть ли там дубликаты и если да, то о каких документах речь. Аудит удобно запускать как первый шаг, если у компании большое хранилище и, например, необходимо посчитать, на сколько страниц вам понадобится лицензия FRS, чтобы обработать файлы.
Второй режим работы FRS – Обработка. Если компания не хочет отправлять в новое хранилище дубликаты документов, то в программе можно поставить галочку Исключить файлы-дубликаты.

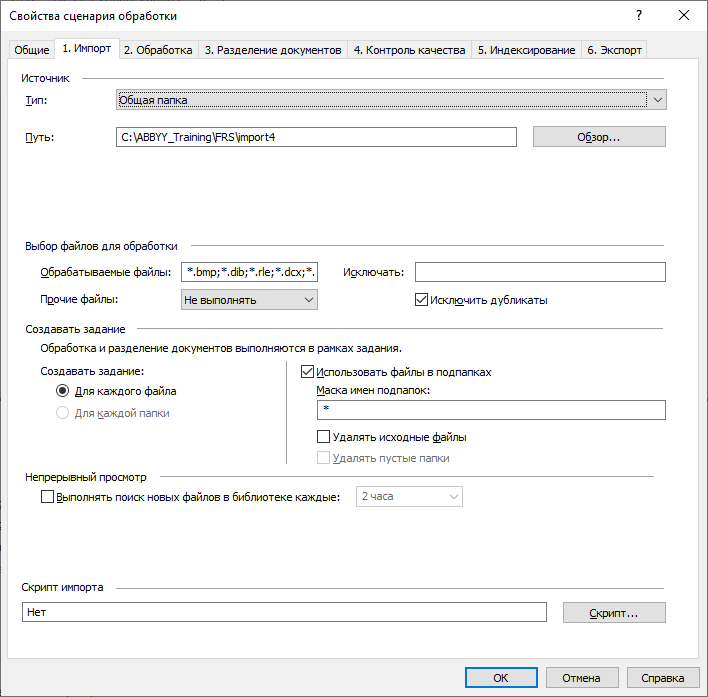
В этом случае FRS обрабатывает файлы, конвертирует, в этот же момент считает хэш-сумму каждого из них и сравнивает ее с хэшем каждого уже найденного в хранилище файла. Решение обрабатывает один файл из группы дубликатов, а остальные – пропускает. Если содержимое двух файлов полностью одинаковое, а название файлов – разное, то такие файлы тоже считаются дубликатами.
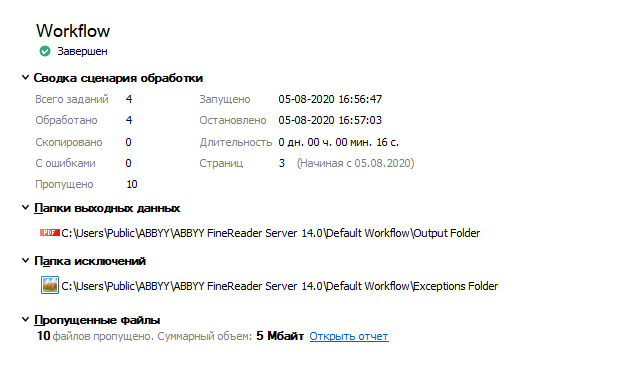
Когда обработка завершена, FRS снова выведет отчет по дубликатам. Это сделано для тех пользователей, которые не знают про аудит, не хотят его запускать или случайно пропускают этот этап. У них может появиться вопрос: «А были ли вообще в хранилище дубликаты? А какие это файлы? Много ли их?». В отчете будет показана группа дубликатов.
Как повысить качество изображения
При обработке в FRS файлы проходят несколько стадий. Например, изображения, которые нужно распознать, сначала отправляются на так называемую предобработку. На этом этапе происходит применение различных фильтров к документу, чтобы улучшить качество его распознавания. Например, если у пользователя сканы низкого качества, он может попробовать поменять набор настроек, чтобы повысить качество изображения: допустим, настроить яркость, контрастность, уровень интенсивности света и тени, повернуть, обрезать лишние границы, осветлить фон и др.
В большинстве случаев хватает профиля предобработки, который настроен в FRS по умолчанию. Это оптимальный набор фильтров, который повышает качество большого количества документов. Решение автоматически выставляет разрешение, подходящее для распознавания текста, определяет, не повернуто ли изображение, исправляет перекосы.
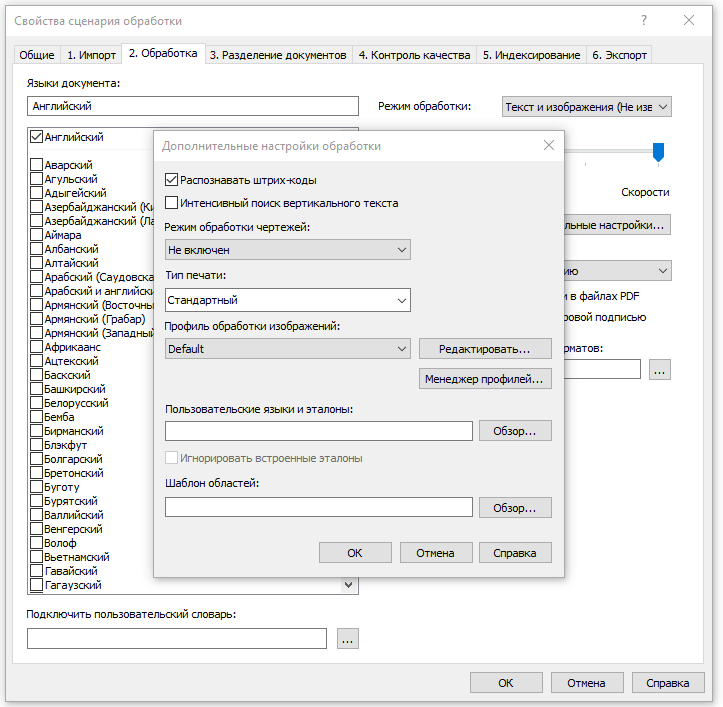
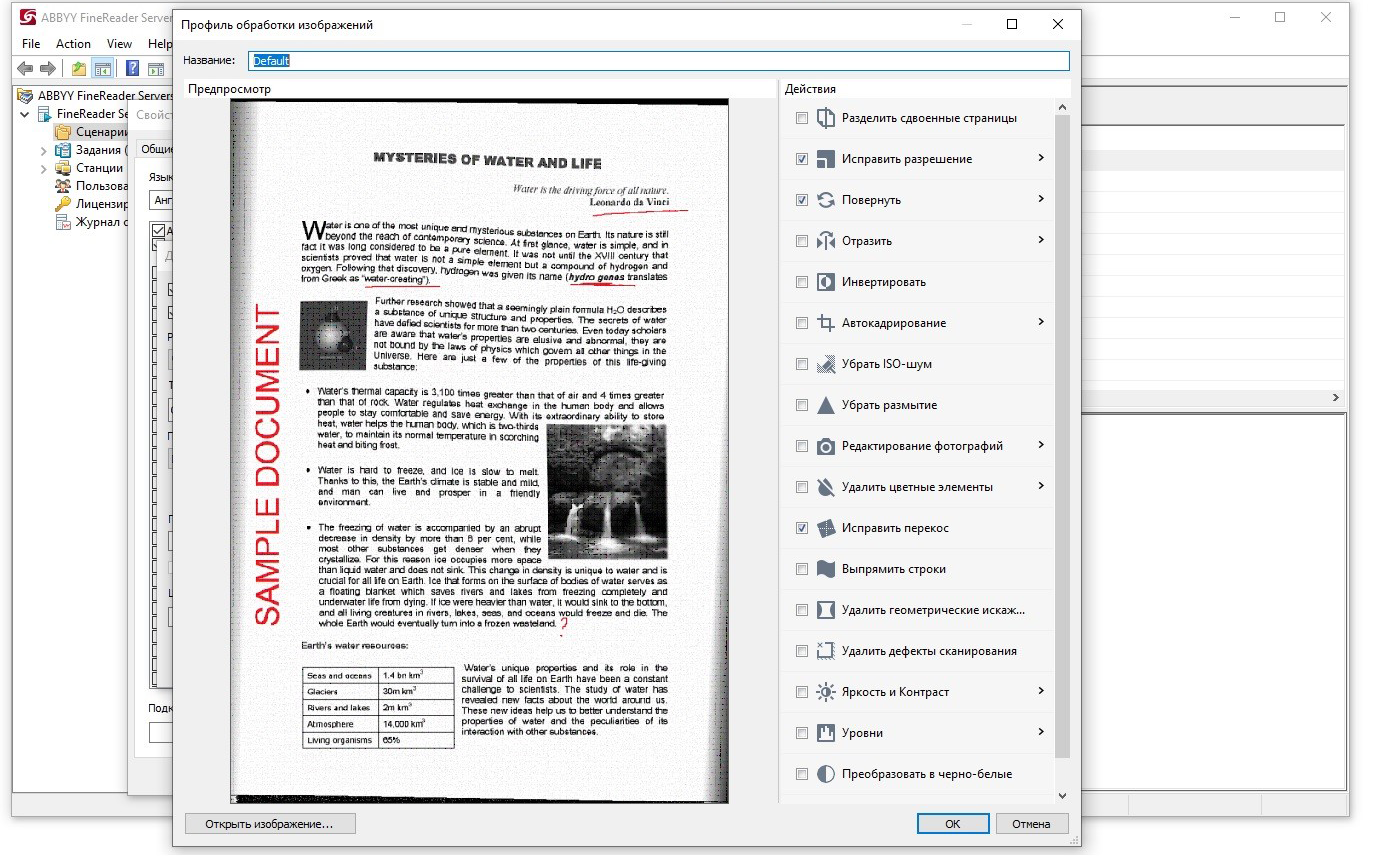
Пользователь может и сам подобрать оптимальный состав фильтров для своих документов и объединить свои группы настроек в профиль. Это удобно, чтобы каждый раз не выставлять 100500 галок. Профилей может быть сколько угодно – для обработки фото, для сканов и т.д.
Свои профили предобработки изображений настраивают пользователи и компании, у которых:
• Очень специфичные документы, например, какие-то фотографии, сделанные в темном помещении.
• Документы, на основе которых будут приниматься критически важные решения, и тут важно бороться за каждый процент качества распознавания, который можно повысить.
• Задача – распознать и конвертировать файлы для дальнейшей отправки документов в интеллектуальные системы для анализа и извлечения текстовой информации с помощью NLP-технологий – например, на платформах eDiscovery. Для них качество текста очень важно, и малейшая опечатка в слове может привести к неправильным результатам. Например, на каком-то слове не выделится сущность.
Поколдовали со штрихкодами
 По сравнению с предыдущей версией решения наши разработчики значительно улучшили распознавание ISBN, PDF-417, Aztec и QR-кодов. В некоторых категориях качество повысилось на 15%. При этом скорость обработки увеличилась на 20%.
По сравнению с предыдущей версией решения наши разработчики значительно улучшили распознавание ISBN, PDF-417, Aztec и QR-кодов. В некоторых категориях качество повысилось на 15%. При этом скорость обработки увеличилась на 20%.
Расскажем, в каких случаях компании используют такие штрихкоды и для чего их необходимо распознавать.
Первый. В логистические, транспортные и другие компании часто поступают большие файлы, в которых содержатся сразу много сканов разных документов – например, товарных накладных. И чтобы поделить этот файл на самостоятельные документы, на первой странице каждой новой накладной помещают штрихкод. В FRS есть функция разделения документов по штрихкоду. В результате на экспорте вместо одного большого комбинированного документа получается несколько аккуратно поделенных файлов.
Второй. В банках, розничных магазинах и других компаниях иногда само значение штрихкода может быть как-то использовано, допустим, в нем может быть зашифровано название файла. Например, у большой торговой сети может быть поток документов от разных поставщиков. Они используют разные штрихкоды. FRS поможет обрабатывать весь массив документов и сразу разложить счета от каждого поставщика в отдельные папки.
Кстати, в одном из европейских банков у нас был любопытный кейс. В компанию поступали бумажные письма со штрихкодами, в них были закодированы имена адресатов. Клиент хотел оцифровывать такие штрихкоды, чтобы уже по электронной почте отправлять оцифрованный документ тому адресату, которому пришло бумажное письмо.
Распознавание и конвертирование прямо в вебе
Сотрудникам крупных компаний по работе часто нужно быстро распознавать и конвертировать файлы в нужные им форматы. Например, бухгалтерия получает от контрагентов сканы товарных накладных или счета в разных графических форматах: JPEG, TIFF, PDF. Специалистам нужно конвертировать все документы в единый формат, допустим, в PDF с текстовым слоем, а затем пересылать дальше, положить в хранилище и т.д.
Раньше в FRS было две возможности для такой конвертации.
Первая: сисадмины настраивали две расшаренные папки. В одну из них конечный пользователь помещал свой документ, а через некоторое время в выходной папке появлялся документ, уже сконвертированный в нужный формат.
Вторая. Пользователь отправлял на определенный адрес письмо с вложенным документом, который нужно сконвертировать или распознать. В ответ ему в почту приходил email с результатом распознавания.
Оба этих способа существуют и сейчас. Но поскольку все движется в сторону веба, то в FRS появилась и третья возможность – конвертация и распознавание документов через веб-интерфейс. Мы постарались сделать его максимально простым и понятным.
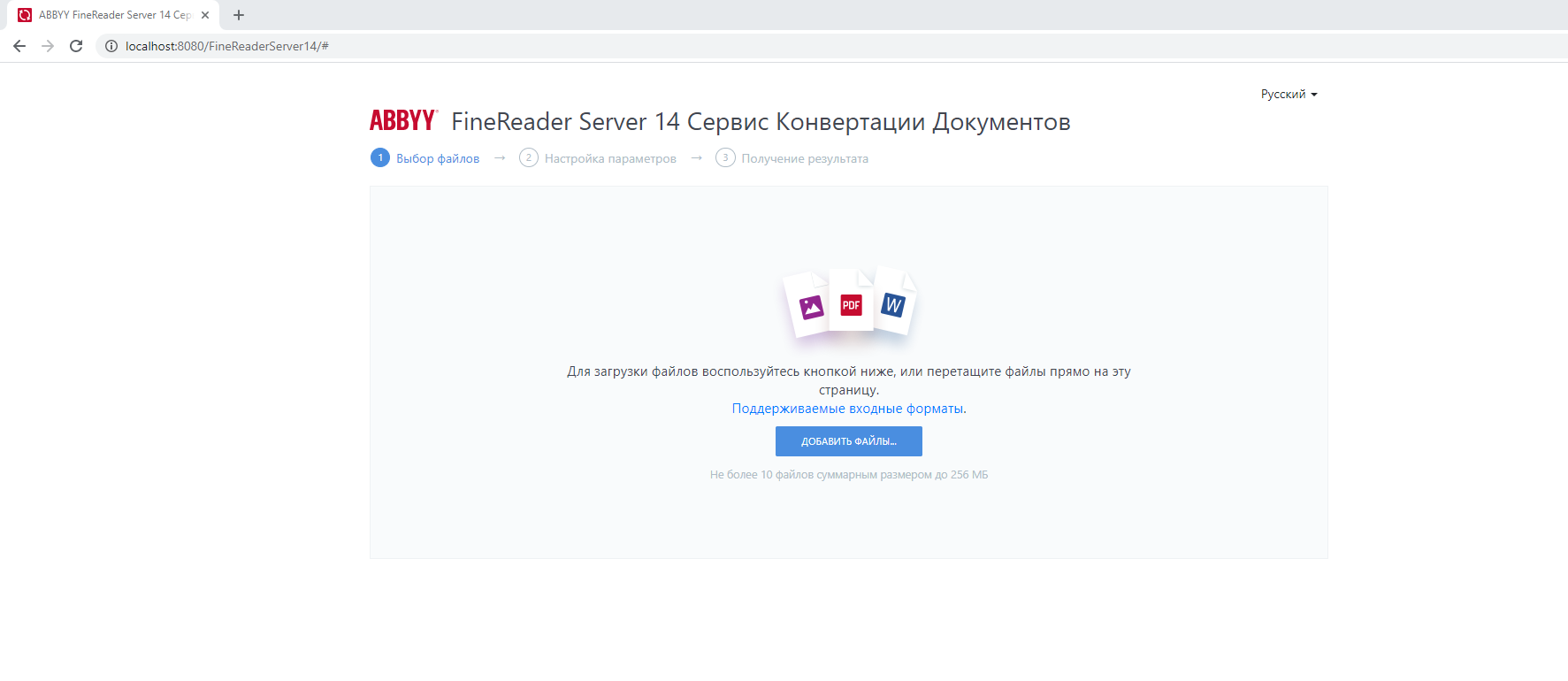
Загружаешь файл, выбираешь один или несколько форматов, в которые нужно конвертировать документ, а также выбираешь языки, которые используются в документе. Получаешь результат.
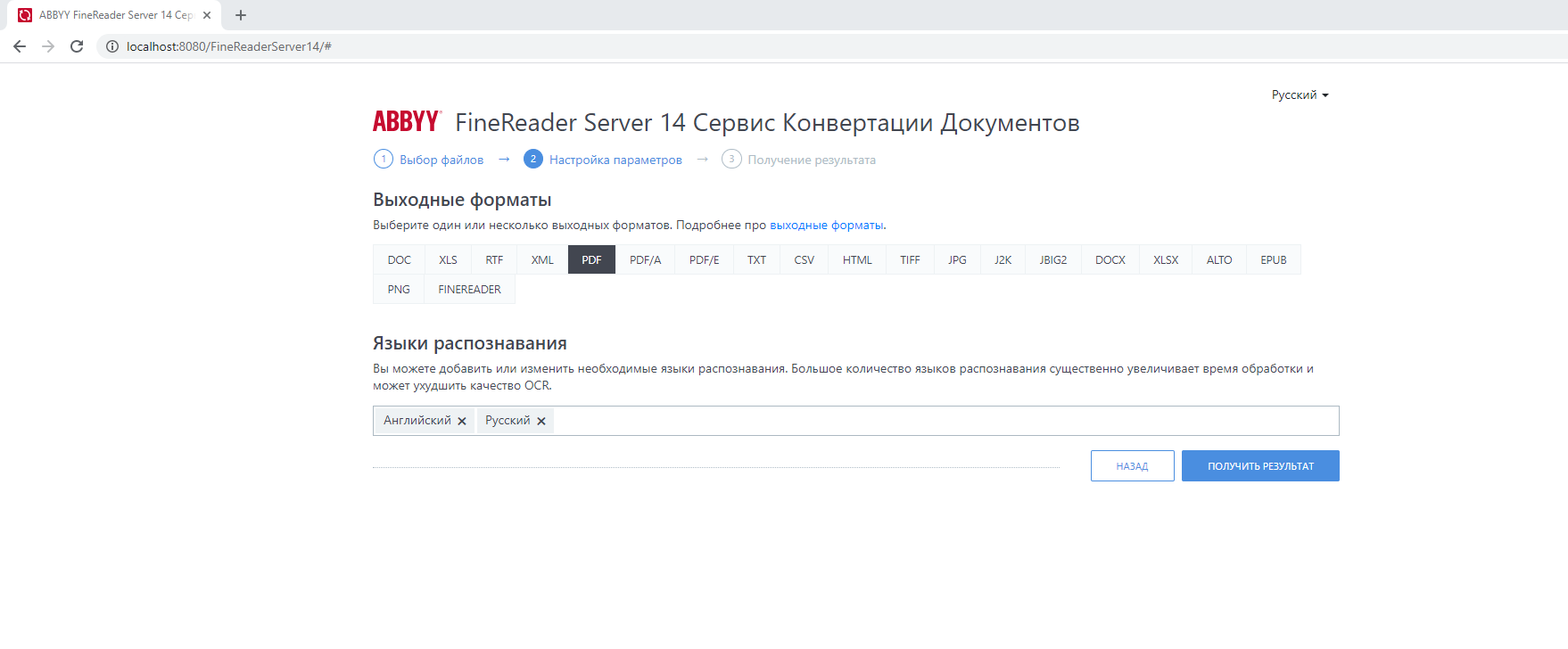
Такой сервис может пригодится в любой компании, где людям нужно массово конвертировать файлы. Причем конечным пользователям не придется тратить время на настройки. Все уже готово к работе, достаточно закинуть файл и получить результат.
Качество изображения лучше, а вес — меньше
В FRS мы усовершенствовали алгоритмы сжатия MRC, чтобы обеспечить высокое качество цветных изображений при сжатии тяжелых файлов. Во-первых, подобрали более оптимальные параметры сжатия MRC для режимов минимального размера и сбалансированного. Во-вторых, использовали нестрогий детектор определения цветности: это значит, что «почти черно-белые» изображения обрабатываются как черно-белые. Это позволяет заметно уменьшать их размер. Тестирование фичи на образцах из базы изображений ABBYY показало, что уровень сжатия файлов с цветными картинками стал лучше на 10-30%.
Подобное сжатие необходимо для конвертирования файлов в формат PDF. Чем меньше размер документа с изображением, тем быстрее он открывается на мобильном устройстве, загружается с сайта или отправляется по почте.
В качестве заключения
Эта статья рассказывает о самых интересных и необходимых на наш взгляд новых фичах ABBYY FineReader Server. Попробовать их можно уже сейчас – скачайте триал-версию продукта бесплатно. Если вам интересно узнать больше подробностей о FRS, то пишите в комментариях свои вопросы!
