Comments 100
Двадцать… восемь… миллионов… рублей… Никогда не интересовался ценами, но это пи… ц как много)) Не думал, что солидная производительность обходится дата центрам так дорого.
А сколько стоит стойка на последнем фото? Да еще если добить ее полностью…
Да ничего не обходится насктолько дорого ДЦ, которые деньги считают. EMC — большие, кормиться надо хорошо и вкусно…
В реалиях — вон, у нас в Nutanix (а мы EMC выносим очень много где сейчас, особенно в США) — 200.000$k GPL за коробку с 1TB RAM, 80 ядер 2.8Ghz E5, 8x 10G интерфейсов, 6.4TB SSD Flash, 16TB SATA.
Как коллеги из «крока» написали — " На практике возможны различные варианты скидок".
Коробка в 2U, тянет до 400+ VDI (или серверных виртуалок), около 70.000 IOPS на чтение и 40.000 на запись.
Еще раз — 2U, ничего кроме нее (и коммутатора сетевого типа Arista Networks) не нужно. Масштабируется почти безлимитно.
Нужны ли такие, по миллиону долларов СХД как EMC Flash array? Изредка — да, для OLTP баз гигантских например, или невиртуализируемых / не X86 нагрузок. Но это событие намного реже случается, чем хотелось бы EMC. :)
И в облака активно все уходят (приватные и публичные), и базы проектировать правильно начинают (шардинг / NoSQL / параллельная обработка и тд).
В реалиях — вон, у нас в Nutanix (а мы EMC выносим очень много где сейчас, особенно в США) — 200.000$k GPL за коробку с 1TB RAM, 80 ядер 2.8Ghz E5, 8x 10G интерфейсов, 6.4TB SSD Flash, 16TB SATA.
Как коллеги из «крока» написали — " На практике возможны различные варианты скидок".
Коробка в 2U, тянет до 400+ VDI (или серверных виртуалок), около 70.000 IOPS на чтение и 40.000 на запись.
Еще раз — 2U, ничего кроме нее (и коммутатора сетевого типа Arista Networks) не нужно. Масштабируется почти безлимитно.
Нужны ли такие, по миллиону долларов СХД как EMC Flash array? Изредка — да, для OLTP баз гигантских например, или невиртуализируемых / не X86 нагрузок. Но это событие намного реже случается, чем хотелось бы EMC. :)
И в облака активно все уходят (приватные и публичные), и базы проектировать правильно начинают (шардинг / NoSQL / параллельная обработка и тд).
Nutanix — это уже коробка с виртуализацией, которую сложно использовать в гетерогенной облачной среде, где необходимо использовать несколько гипервизоров: KVM, VMWare, Xen. Например, для нашего «облака» эта коробка по результатам тестов просто не подошла. И если ваша задача не виртуализуется — забудьте про Nutanix. В общем, решение интересное, имеет право на жизнь, но пока очень нишевое с моей точки зрения. Плюс очень важно учитывать, что один брик EMC на практике поддерживает раз в 10 больше виртуальных машин, чем два описанных юнита — часто это важно в разрезе стоимости лицензий и решения других узких мест.
«которую сложно использовать в гетерогенной облачной среде» — достаточно удивительно такое слышать.
Если нужен Xen — да, мы его не поддерживаем (он в принципе активно умирает и имеет множество технических / архитектурных проблем)
Срос на Xen есть только в РФ, к тому-же буквально только пару клиентов спрашивали.
ESXi + HyperV + KVM — да, поддерживаем.
Мало того, у нас уже готово мультикластерное управление — можно управлять всеми кластерами Nutanix из одного места (да хоть сотни).
Откровенно говоря — это как раз самое что ни на есть гетерогенное решение, к тому-же реально уникальное.
Если задача не виртуализируется — да, множество раз писал — мы в эту область (пока) не лезем.
С этой стороны и EMC и Netapp — прекрасные решения. Мало того, никто не мешает на Nutanix монтировать «чужие» NAS по NFS / iSCSI.
Огромное количество задач, особенно новые / современные проекты, виртуализируются прекрасно.
Если нужен Xen — да, мы его не поддерживаем (он в принципе активно умирает и имеет множество технических / архитектурных проблем)
Срос на Xen есть только в РФ, к тому-же буквально только пару клиентов спрашивали.
ESXi + HyperV + KVM — да, поддерживаем.
Мало того, у нас уже готово мультикластерное управление — можно управлять всеми кластерами Nutanix из одного места (да хоть сотни).
Откровенно говоря — это как раз самое что ни на есть гетерогенное решение, к тому-же реально уникальное.
Если задача не виртуализируется — да, множество раз писал — мы в эту область (пока) не лезем.
С этой стороны и EMC и Netapp — прекрасные решения. Мало того, никто не мешает на Nutanix монтировать «чужие» NAS по NFS / iSCSI.
Огромное количество задач, особенно новые / современные проекты, виртуализируются прекрасно.
Хотел добавить запоздалый комментарий на тему «да это что, я пару лет назад админил blade-сервер за 400К евро».
Потом решил сравнить. 400 000 евро = 28 055 484.2 российских рубля ©Google. Невероятно прицельное попадание. :)
Потом решил сравнить. 400 000 евро = 28 055 484.2 российских рубля ©Google. Невероятно прицельное попадание. :)
Мне не совсем понятно чем обусловлена такая стоимость? Можете рассказать подробнее? (я в этом мало что понимаю, просто интересно откуда такая цена :))
На самом деле, во многих случаях цена заметно ниже — я уже говорил, есть ряд специальный скидочных программ от вендора. Однако если говорить в целом — железо такого класса используются для тех случаев, когда нужно убрать конкретное узкое место. То есть производители постарались максимально улучшить характеристики производительности, что, естественно, сказалось на цене.
Железка для специальных задач вроде высоконагруженных VDI сред и СУБД, куда раньше ставили Hi-End или топовый Mid-Range, которые стоят еще больших денег при меньшем эффекте.
Железка для специальных задач вроде высоконагруженных VDI сред и СУБД, куда раньше ставили Hi-End или топовый Mid-Range, которые стоят еще больших денег при меньшем эффекте.
ЭЭЭЭ, 28 лямов? Диски эти по 3000$ (за MLC диск), а остальное за что? Что в этой СХД такого «золотого»?
Денег стоят не столько сами диски, сколько тот факт, что если их поместить в другую систему классом ниже, такой производительности для пиковых нагрузок и надёжности добиться просто не удастся.
Каждую плату для СХД нужно разработать и протестировать, а потом протестировать их на вместе совместимость. Кроме того, СХД — это не только железо, но и софт. На его разработку и тестирование (а тестирование очень серьезное, ведь речь идет о критичных данных) тратится очень много денег и усилий.
Более того, в эту цену включена поддержка и замена запчастей в течение 3 лет.
Каждую плату для СХД нужно разработать и протестировать, а потом протестировать их на вместе совместимость. Кроме того, СХД — это не только железо, но и софт. На его разработку и тестирование (а тестирование очень серьезное, ведь речь идет о критичных данных) тратится очень много денег и усилий.
Более того, в эту цену включена поддержка и замена запчастей в течение 3 лет.
Увеличить производительность с 10% до 70% — стоит $Х
Увеличить её же с 80% до 95% стоит $XXX
Я так полагаю, создатели системы не просто набили в свою СХД SSD-дисков.
Но вот описания того, что именно там дорабатывали и не хватает.
Увеличить её же с 80% до 95% стоит $XXX
Я так полагаю, создатели системы не просто набили в свою СХД SSD-дисков.
Но вот описания того, что именно там дорабатывали и не хватает.
В дата центрах используют SSD с SLC или с MLC ячейками?
Используются и SLC, и MLC. Конкретно в XtremIO сейчас доступны только MLC модули. SLC даёт несколько большую производительность и ресурс перезаписи при значительно меньшем объёме на кристалл — их имеет смысл использовать только в очень «экзотических» задачах со сверхинтенсивной нагрузкой на запись.
Технология MLC же позволяет многослойную запись, что несколько снижает производительность, но даёт двойной и даже иногда более выигрыш в объёме. Однако, чипы выполненные по этой технологии, способны пережить меньше операций записи.
Последние годы MLC всё ближе к SLC по сроку службы, плюс благодаря правильной работе контроллеров есть возможность делать некоторые tradeoff в сторону производительности поближе к SLC. Поэтому в общем случае используются именно MLC как более экономически оправданные, а в частных, особо тяжелых случаях (в России — единичных) используются SLC чипы.
Технология MLC же позволяет многослойную запись, что несколько снижает производительность, но даёт двойной и даже иногда более выигрыш в объёме. Однако, чипы выполненные по этой технологии, способны пережить меньше операций записи.
Последние годы MLC всё ближе к SLC по сроку службы, плюс благодаря правильной работе контроллеров есть возможность делать некоторые tradeoff в сторону производительности поближе к SLC. Поэтому в общем случае используются именно MLC как более экономически оправданные, а в частных, особо тяжелых случаях (в России — единичных) используются SLC чипы.
Спасибо. А есть какой-то опыт по выработке таких накопителей? Сколько уже в read-only?
Просто смотрю на консьюмерские sata ssd — техпроцесс MLC чипов всё тоеньше и тоньше, а число перезаписей всё меньше и меньше.
Просто смотрю на консьюмерские sata ssd — техпроцесс MLC чипов всё тоеньше и тоньше, а число перезаписей всё меньше и меньше.
Смотрите на EMLC диски типа Intel
www.intel.com/content/www/us/en/solid-state-drives/solid-state-drives-dc-s3700-series.html?wapkw=s3700
Про платы и прочее — конечно это все сочинения на вольную тему, диски в мире делает всего пара компаний и в основном все вендоры используют одни и те-же
Мы используем как-раз S3700
2 million hours Mean Time Between Failures (MTBF)
www.intel.com/content/www/us/en/solid-state-drives/solid-state-drives-dc-s3700-series.html?wapkw=s3700
Про платы и прочее — конечно это все сочинения на вольную тему, диски в мире делает всего пара компаний и в основном все вендоры используют одни и те-же
Мы используем как-раз S3700
2 million hours Mean Time Between Failures (MTBF)
EMC Data Domain DD2500 — 5 лям, для EMC это обычная стоимость, а вот стоимость поддержки вас приятно удивит… 2x — 3x стоимости железки.
Ребята, на тест-драйве проведите синтетическое тестирование на подобие habrahabr.ru/company/advanserv/blog/207014/
Хоть будут примерные цифры для сравнения с другими СХД.
Хоть будут примерные цифры для сравнения с другими СХД.
А если при втыкании/вытыкании «на горячую», чо-нить сгорит производитель заменит? Я бы сцыканул с коробкой за 28 лямов играться.
Если в спецификации заявленна горячая замена то вопросов не будет.
Если у такого оборудования что-то сгорит (при штатном использовании), то неплохая идея — заменить… производителя! :) Поэтому, производитель, по-идее, должен не только заменить бегом, но ещё и дико извиняться и предлагать всякие неожиданные бонусы! Это чтобы всё тихо и мирно замять, не вызывая очень болезненного ажиотажа вокруг этого печального факта.
Было бы интересно тестирование какой-то «обычной задачи». Чтобы народ мог повторить. Стандартного теста от базы данных.
Вношу предложение: проведите тест в fio по методу amarao
А рассказ или видео после вашего тест-двайва тут, случайно, не появится?
+1
У нас вся диагностика производительности IOPS сделана как раз на FIO (в Nutanix встроенная диагностика / тестирование системы, чтобы клиенты могли после запуска убедиться что все в норме работает).
На каждом ноде запускается автоматически виртуальная машинка линуксовая (она открыта, можно смотреть все параметры) и через FIO начинает генериться нагрузка.
IOMeter устарел и зачастую покажет погоду на луне, особенно если специально подтюнить ;)
У нас вся диагностика производительности IOPS сделана как раз на FIO (в Nutanix встроенная диагностика / тестирование системы, чтобы клиенты могли после запуска убедиться что все в норме работает).
На каждом ноде запускается автоматически виртуальная машинка линуксовая (она открыта, можно смотреть все параметры) и через FIO начинает генериться нагрузка.
IOMeter устарел и зачастую покажет погоду на луне, особенно если специально подтюнить ;)
Расскажите про диагностику / тестирование у Nutanix, а то у нас было демо-образец, инженеры с ним 2 недели играли и сейчас статью по нему готовят, а до меня он не успел дойти :((
В Advanserv? Гхм, я наверное что-то пропустил, вроде бы не знал что вы тестировали.
Хотя я отслеживаю в основном только очень крупных клиентов сам. Если есть любые вопросы — пишите смело прямо, всегда рад помочь.
Через дистрибьюторов наверное?
Если по каким-то причинам тестирование вдруг прошло неуспешно — тоже готов напрямую подключиться (или прислать качественного инженера из OCS или Netwell — наших дистрибьюторов), в 99% это просто ошибка в процедуре тестирования (классические примеры — см. дальше).
Тестирование достаточно просто. У нас встроенная самодиагностика и тестирование, работает — дается команда из CLI, которая создает на всех нодах кластера виртуальные машины под Linux (Centos) и там запускается FIO.
Вообще, сталкивался неоднократно раз, когда без понимания архитектуры, тестирование проводится некорректно.
Простой пример (коллеги себя узнают, пальцем тыкать не буду) — у нас четко описано что запуск кластера под KVM возможен только на 10G интерфейсах.
Что делают коллеги? 3 дня запускают через 1G. Оставив 10G нескоммутированными вообще.
И предъявляют нам претензии («вы обещали запуск за 10 минут»).
Далее, в версии 3.5 ПО — можно одновременно выдергивать один узел (любой). Буквально через несколько минут — уже другой.
В версии 4 мы это кардинально улучшили (можно терять целиком блок или два одновременно узла), но «тестировщики» вытащили сразу два нода (кластер остановился), тут-же вернули все обратно дистрибьютору с фразой «фигня полная».
При том что будет если выдергнуть два контроллера сразу например у vblock или XtremeIO — скромно умолчано :)
…
При желании — у нас есть инструкции и готовые виртуалки для IOMeter тоже.
Вообще, тестировать распределенные системы — надо понимать что и как делаете, стандартные средства (включая обычную конфигурацию IOMeter) не имеют никакого смысла и покажут что-то абсолютно «левое».
Хотя я отслеживаю в основном только очень крупных клиентов сам. Если есть любые вопросы — пишите смело прямо, всегда рад помочь.
Через дистрибьюторов наверное?
Если по каким-то причинам тестирование вдруг прошло неуспешно — тоже готов напрямую подключиться (или прислать качественного инженера из OCS или Netwell — наших дистрибьюторов), в 99% это просто ошибка в процедуре тестирования (классические примеры — см. дальше).
Тестирование достаточно просто. У нас встроенная самодиагностика и тестирование, работает — дается команда из CLI, которая создает на всех нодах кластера виртуальные машины под Linux (Centos) и там запускается FIO.
Вообще, сталкивался неоднократно раз, когда без понимания архитектуры, тестирование проводится некорректно.
Простой пример (коллеги себя узнают, пальцем тыкать не буду) — у нас четко описано что запуск кластера под KVM возможен только на 10G интерфейсах.
Что делают коллеги? 3 дня запускают через 1G. Оставив 10G нескоммутированными вообще.
И предъявляют нам претензии («вы обещали запуск за 10 минут»).
Далее, в версии 3.5 ПО — можно одновременно выдергивать один узел (любой). Буквально через несколько минут — уже другой.
В версии 4 мы это кардинально улучшили (можно терять целиком блок или два одновременно узла), но «тестировщики» вытащили сразу два нода (кластер остановился), тут-же вернули все обратно дистрибьютору с фразой «фигня полная».
При том что будет если выдергнуть два контроллера сразу например у vblock или XtremeIO — скромно умолчано :)
…
При желании — у нас есть инструкции и готовые виртуалки для IOMeter тоже.
Вообще, тестировать распределенные системы — надо понимать что и как делаете, стандартные средства (включая обычную конфигурацию IOMeter) не имеют никакого смысла и покажут что-то абсолютно «левое».
Почти 4$ за iops для ssd хранилки? Неужели она действительно так хороша, чтобы отдавать такие деньги?
Вот, например, www.storageperformance.org/benchmark_results_files/SPC-1/Huawei/A00119_Huawei_Dorado5100/a00119_Huawei_Dorado5100_SPC-1_full-disclosure-report.pdf
Dorado 5100. Тестированное количество Iops 600000. Стоимость 0.81$ за iops. Общая стоимость получилась всего в 500 000 долларов. Отклик не превышает 1мс.
Dorado 5100. Тестированное количество Iops 600000. Стоимость 0.81$ за iops. Общая стоимость получилась всего в 500 000 долларов. Отклик не превышает 1мс.
У неё нет дедупликации «на лету» — только для VDI разница может быть в несколько десятков раз. Ну и тесты надо делать одинаковые, на одном стенде, иначе разница в результатах IOPS может быть очень большой.
Конечно, есть много нюансов.
По поводу дедупликации, да, ее нет. Но мне интересно, какие есть нюансы при этом? Есть ли реальная потребность в дедупликации именно на лету? В VDI особенно критично к чтению, чем к записи.
Хотелось бы прочитать хотя бы одно обоснование покупки такого специфического оборудования.
По поводу дедупликации, да, ее нет. Но мне интересно, какие есть нюансы при этом? Есть ли реальная потребность в дедупликации именно на лету? В VDI особенно критично к чтению, чем к записи.
Хотелось бы прочитать хотя бы одно обоснование покупки такого специфического оборудования.
Дедупликация нужна при «неправильной» конфигурации VDI, когда вместо золотого образа и связанных клонов, пользователям выдаются персональные ВМ.
К примеру, у VMware в документации использование персональных пулов почти не покрыто, по-умолчанию считается, что у заказчика linked-clone.
К примеру, у VMware в документации использование персональных пулов почти не покрыто, по-умолчанию считается, что у заказчика linked-clone.
В чем основное преимущество покупки устройства с дедуплекацией именно на лету? Для VDI по-моему это вообще не нужно.
Странный вопрос, наверное, в более эффективном использовании пространства и кешировании.
Когда вы развернули новое приложение на пуле виртуалок, на диск записалась всего одна копия и горячие блоки улетели в кеш в единственном экземпляре.
Когда вы развернули новое приложение на пуле виртуалок, на диск записалась всего одна копия и горячие блоки улетели в кеш в единственном экземпляре.
Ну так стандартный кэш чтения не по хэшам разве производит кеширование? Дедупликация в моем понимании помогает только более эффективно складывать записанные блоки. Если цель только экономия пространства, то для этого можно проводить дедупликацию по расписанию, за одно и ресурсы ЦПУ сэкономит в горячий период.
Пыльновато у вас в стойке что-то:)
Без пластиковых заглушек схд напоминает поделку дядюшки Ляо. ЕМС очень спешило выкатить ее на рынок?
EMC в своем стиле ;))))
Накручивать цены в 100 раз и выдавать старье за новое.
www.youtube.com/watch?v=B-RBDtKgQTo
Вот пожалуйста, более миллиона IOPS :) Больше тоже тестили (2 с лишним), на ютюб не выкладывали.
По поводу дисков — использутся даже в EMC (удивительно что коллеги из крока это не указали), не MLC а EMLC
MLC stands for Multi-Level Cell, and is used to describe a type of flash memory that can store more than 1-bit per cell. This is the popular choice for consumer-grade solid state storage.
eMLC stands for Enterprise MLC, an improved version of the Multi-Level Cell flash memory.
Накручивать цены в 100 раз и выдавать старье за новое.
www.youtube.com/watch?v=B-RBDtKgQTo
Вот пожалуйста, более миллиона IOPS :) Больше тоже тестили (2 с лишним), на ютюб не выкладывали.
По поводу дисков — использутся даже в EMC (удивительно что коллеги из крока это не указали), не MLC а EMLC
MLC stands for Multi-Level Cell, and is used to describe a type of flash memory that can store more than 1-bit per cell. This is the popular choice for consumer-grade solid state storage.
eMLC stands for Enterprise MLC, an improved version of the Multi-Level Cell flash memory.
Если кому интересно — EMC сейчас очень сильно нас (Nutanix) боится, причем официально молчат.
Но что забавно — внутренние battlecards утекают от них — где они (достаточно смешно впрочем) описывают как своим сейлзам с нами бороться ;)

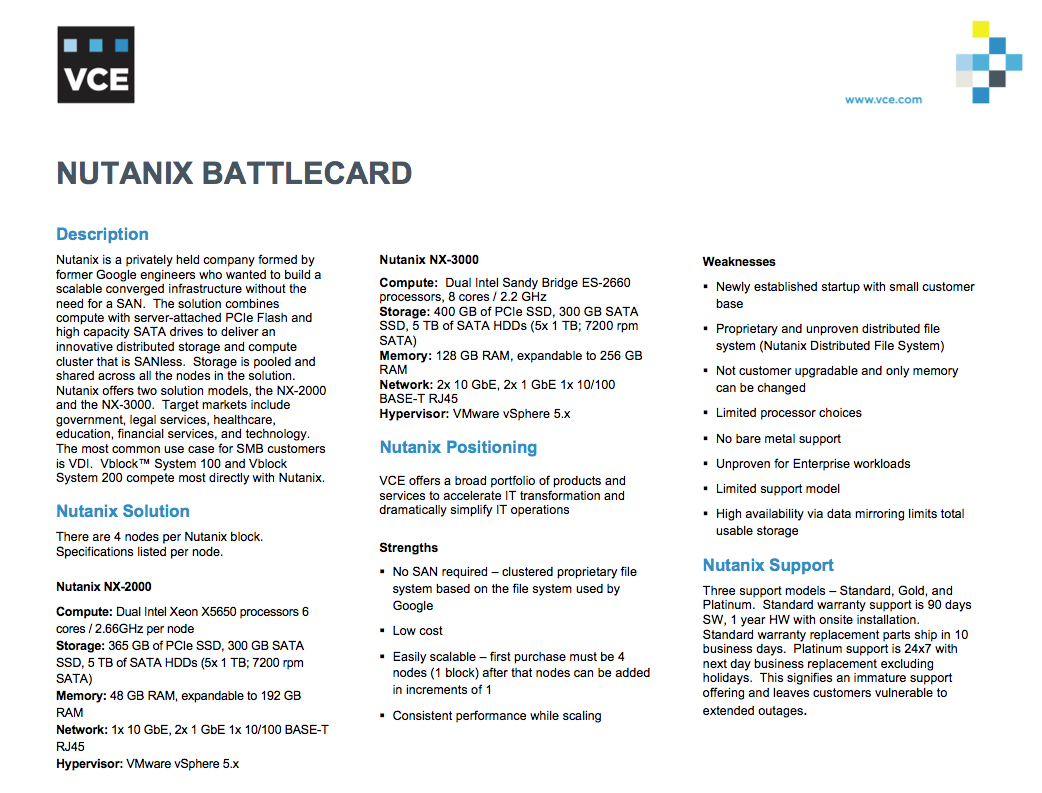
Но что забавно — внутренние battlecards утекают от них — где они (достаточно смешно впрочем) описывают как своим сейлзам с нами бороться ;)


В сущности, бедняг даже жаль. Cейчас будет передел рынка, а из всех «проблем» Nutanix смогли из пальца только достаточно смешные аргументы достать. Железо кстати старое в battlecard, у нас уже E5-28Ghz Ivy Bridge, про энтерпрайз нагрузки — тоже весьма забавно (у нас основной клиент — правительство США и крупные энтерпрайзы), NDFS базируется на ext4+cassandra (это бедняжки назвали propietary), и тд.
Надо отдать должное — EMC признает что мы очень сильны в правительственном секторе ;)
Надо отдать должное — EMC признает что мы очень сильны в правительственном секторе ;)
Да, чтобы не было вопросов — никто у них не утаскивал «карты», это в интернете уже засветилось. Учитывая что в EMC тысячи сотрудников (десятки тысяч?), всех надо кормить… В общем похоже не уследить ;)
Так сколько будет стоить ваше решение, аналогичное этому EMC?
У нас все предельно понятно и прозрачно.
1) Мы не СХД, а гибридное решение (сервера + «СХД») в одном блоке. Вся коммутация — только через множественные 10G соединения (на блок — 8 портов по 10 гигабит). Принцип работы — NoSQL для метаданных, «разманные» данные (рейд не применяется), обмен данными аналогично (очень упрощая) torrent.
2) Один блок (4 нода) выдает в среднем 70.000 IOPS на чтение и 40.000 IOPS на запись.
Масштабирование абсолютно линейное.
Блок несет в себе до 2TB RAM, 80 ядер 2.8Ghz E5 v2 (Ivy Bridge), до 6.4TB SSD и 16TB SATA диски.
Цена блока (GPL) — около 200$k.
Дальше можете спокойно подсчитать. За 1m$ мы получим 5 блоков, которые дадут 350000 IOPS на чтение и 200000 на запись.
При этом сразу же вы будете иметь 400 ядер по 2.8Ghz, до 10TB RAM, 40x10G интерфейсов, 32TB SSD и 80TB SATA
Это — очень много, и тянет спокойно 2000 VDI например. По стойкоместу — всего 6U, по питанию — всего 7.5kW (реально даже меньше).
Такие вот дела.
1) Мы не СХД, а гибридное решение (сервера + «СХД») в одном блоке. Вся коммутация — только через множественные 10G соединения (на блок — 8 портов по 10 гигабит). Принцип работы — NoSQL для метаданных, «разманные» данные (рейд не применяется), обмен данными аналогично (очень упрощая) torrent.
2) Один блок (4 нода) выдает в среднем 70.000 IOPS на чтение и 40.000 IOPS на запись.
Масштабирование абсолютно линейное.
Блок несет в себе до 2TB RAM, 80 ядер 2.8Ghz E5 v2 (Ivy Bridge), до 6.4TB SSD и 16TB SATA диски.
Цена блока (GPL) — около 200$k.
Дальше можете спокойно подсчитать. За 1m$ мы получим 5 блоков, которые дадут 350000 IOPS на чтение и 200000 на запись.
При этом сразу же вы будете иметь 400 ядер по 2.8Ghz, до 10TB RAM, 40x10G интерфейсов, 32TB SSD и 80TB SATA
Это — очень много, и тянет спокойно 2000 VDI например. По стойкоместу — всего 6U, по питанию — всего 7.5kW (реально даже меньше).
Такие вот дела.
Слышу о ваших решениях впервые. И то что вы написали как-то выглядит неуверенно. По крайней мере понятности и прозрачности я лично не заметил
На рынок РФ выходить начали несколько месяцев назад, без шума и пыли. Единственный «шум» за все время — это пожалуй я здесь развел, по определенным причинам (взаимоотношения с «Крок»).
А так — в США мы сейчас один из самых известных вендоров «СХД», с пачкой наград (включая — единственные за всю историю трижды подряд золотые медалисты VMworld)
Клиентура — компаниии топ-уровня, включая правительство и военных США. Можете на сайте посмотреть.
Даже Корейцы (например Hyundai / Kia) уже на нас переходят.
В Китае нас уже признали лучшим решением для построения инфраструктур нового поколения
www.nutanix.com/2013/09/12/nutanix-wins-china-computerworld-award/
www.nutanix.com/2013/11/14/nutanix-wins-chinas-hpc-annual-big-data-infrastructure-award/
И тд.
Это — «неуверенно»? :)) Зря наверное Netapp и EMC против нас баттл-карты рисуют.
А так — в США мы сейчас один из самых известных вендоров «СХД», с пачкой наград (включая — единственные за всю историю трижды подряд золотые медалисты VMworld)
Клиентура — компаниии топ-уровня, включая правительство и военных США. Можете на сайте посмотреть.
Даже Корейцы (например Hyundai / Kia) уже на нас переходят.
В Китае нас уже признали лучшим решением для построения инфраструктур нового поколения
www.nutanix.com/2013/09/12/nutanix-wins-china-computerworld-award/
www.nutanix.com/2013/11/14/nutanix-wins-chinas-hpc-annual-big-data-infrastructure-award/
И тд.
Это — «неуверенно»? :)) Зря наверное Netapp и EMC против нас баттл-карты рисуют.
Я вообще не нашел Nutanix в волшебном квадрате за 2013 год. Заговор?
По поводу лучшего решения в Китае, было бы неплохо на оригинальные заключения, а не рекламу со своего же сайта. Да и по поводу наград, еще над понять за что их дают.
Huawei OceanStor UDS тоже предлагает хранение на основе нод. Это не аналог? Я еще почитаю про вас, но мне больше кажется это все пыль в глаза.
По поводу лучшего решения в Китае, было бы неплохо на оригинальные заключения, а не рекламу со своего же сайта. Да и по поводу наград, еще над понять за что их дают.
Huawei OceanStor UDS тоже предлагает хранение на основе нод. Это не аналог? Я еще почитаю про вас, но мне больше кажется это все пыль в глаза.
Гартнер — это прекрасно, но вообще-то если кто-то думает что туда попадают бесплатно и абсолютно прозрачно… — Мир большого бизнеса разочарует… :)
У нас есть другие направления, куда надо тратить деньги, нежели чем продавать железки по миллиону долларов и пускать потом на окучивание клиентов.
Впрочем, насколько я помню, в этом году над этим поработают. Гартнеру уже деваться не особо есть куда… (это мое личное мнение, не компании).
…
Почитайте, потом обсудим конструктивно. Нет, мы не пыль в глаза :)
…
Оригинальные ссылки — гугл я так понимаю не устраивает? Не проблема, поможем.
stor-age.zdnet.com.cn/stor-age/2013/1114/2995593.shtml
…
Нет, OceanStor UDS — совсем «не то». Хотя тоже очень хорошее решение.
Еще раз — мы не СХД.
Мы заменяем как сервера X86, так и СХД, делая ненужной практически всю аппаратную инфраструктуру (включая FC SAN).
У нас есть другие направления, куда надо тратить деньги, нежели чем продавать железки по миллиону долларов и пускать потом на окучивание клиентов.
Впрочем, насколько я помню, в этом году над этим поработают. Гартнеру уже деваться не особо есть куда… (это мое личное мнение, не компании).
…
Почитайте, потом обсудим конструктивно. Нет, мы не пыль в глаза :)
…
Оригинальные ссылки — гугл я так понимаю не устраивает? Не проблема, поможем.
stor-age.zdnet.com.cn/stor-age/2013/1114/2995593.shtml
…
Нет, OceanStor UDS — совсем «не то». Хотя тоже очень хорошее решение.
Еще раз — мы не СХД.
Мы заменяем как сервера X86, так и СХД, делая ненужной практически всю аппаратную инфраструктуру (включая FC SAN).
Тогда, на сколько я понял, наиболее подходит Huawei FusionCube. У вас на сайте как-то предельно мало техническое информации.
И все же чем лучше это решение, а не раздельно сервера, раздельно СХД я так и не понял. Ну может быть кроме простоты развертывания и экономии места. Про миллион Iops тоже плохо понятно. Это общая производительной всей системы? Кто производит демонстрацию тестирования скриншотами с панели управления? Производительность дисков одной ВМ будет ограничена производительностью одного хоста?
В общем, не убедительно, если честно.
По поводу цен. Вы написали 200k$
Можно прикинуть, СХД S5600T и 204 15k дисков с корзинами обойдется примерно в 150k$. И сервера еще тыщ на 50$. За то наиболее понятная логика работы и понятная масштабируемость. По iops это составит 90к на чтение. По ценами могут быть неточности, я навырывал из тех цен, которые мне показывали поставщики. И дальше тоже все логично — нужна скорость дисков, ставь больше или апгрейд контроллера. Хочешь ЦПУ, меняй его. raid 2.0 и ssd cache, на сколько я там понял тоже смогут использовать ssd диски по полной для оптимизации IO. Так что сомнений лично у меня больше.
Если рассматривать как независимая VDI структура, тем более простая в обслуживании, может быть ваше решение будет подходить. Но говорить, что EMC и конкуренты всякую шнягу толкают, а вы делаете что-то невероятно революционное, я бы не стал.
И все же чем лучше это решение, а не раздельно сервера, раздельно СХД я так и не понял. Ну может быть кроме простоты развертывания и экономии места. Про миллион Iops тоже плохо понятно. Это общая производительной всей системы? Кто производит демонстрацию тестирования скриншотами с панели управления? Производительность дисков одной ВМ будет ограничена производительностью одного хоста?
В общем, не убедительно, если честно.
По поводу цен. Вы написали 200k$
Можно прикинуть, СХД S5600T и 204 15k дисков с корзинами обойдется примерно в 150k$. И сервера еще тыщ на 50$. За то наиболее понятная логика работы и понятная масштабируемость. По iops это составит 90к на чтение. По ценами могут быть неточности, я навырывал из тех цен, которые мне показывали поставщики. И дальше тоже все логично — нужна скорость дисков, ставь больше или апгрейд контроллера. Хочешь ЦПУ, меняй его. raid 2.0 и ssd cache, на сколько я там понял тоже смогут использовать ssd диски по полной для оптимизации IO. Так что сомнений лично у меня больше.
Если рассматривать как независимая VDI структура, тем более простая в обслуживании, может быть ваше решение будет подходить. Но говорить, что EMC и конкуренты всякую шнягу толкают, а вы делаете что-то невероятно революционное, я бы не стал.
Чем лучше — если коротко:
1) локализированный ввод-вывод, что дает максимум производительности дисков и SSD (мы не упираемся в скорости централизованных контроллеров и интерфейсов ввода-вывода)
2) до 90% скоращения места в датацентрах
3) в среднем два раза выигрыш по электричеству
4) не используются RAID как таковые, но технологии разработанные людьми из google (те кто делал googlefs — основатели компании) — «размазывание» данных.
5) масштабируемость абсолютно линейна (хоть 100 нодов), в отличии от СХД и серверов
6) кардинальные сокращения на инженеров (инженеры по СХД не нужны, ибо как таковой СХД нет — нет Lun, нет Raid, нет FC SAN, и тд)
7) чем больше нодов в кластере, тем выше надежность хранения и скорость восстановления
8) в новом ПО — из 3-х блоков может один целиком (4 нода) вылететь — и ничего не умрет (я с нетерпением жду тестов как вы будете вынимать оба контроллера на хуавее)
Продолжать можно долго. И да, зачастую конкуренты толкают «шнягу». Но не всегда, есть случаи когда традиционные, устаревающие архитектуры имеют применение.
Ну а рассказывать как надо правильно делать — это гуглу и амазону можете, которые вообще в принципе СХД не используют. Да и facebook ушел с нетапа очень давно (собственно в т.ч. за счет фейсбука нетап и поднялся)
Реально, просьба — если хочется понять по настоящему — изучите материалы.
Я уже приводил ссылку, Nutanix Bible очень хорошим началом для этого будет.
stevenpoitras.com/the-nutanix-bible/
1) локализированный ввод-вывод, что дает максимум производительности дисков и SSD (мы не упираемся в скорости централизованных контроллеров и интерфейсов ввода-вывода)
2) до 90% скоращения места в датацентрах
3) в среднем два раза выигрыш по электричеству
4) не используются RAID как таковые, но технологии разработанные людьми из google (те кто делал googlefs — основатели компании) — «размазывание» данных.
5) масштабируемость абсолютно линейна (хоть 100 нодов), в отличии от СХД и серверов
6) кардинальные сокращения на инженеров (инженеры по СХД не нужны, ибо как таковой СХД нет — нет Lun, нет Raid, нет FC SAN, и тд)
7) чем больше нодов в кластере, тем выше надежность хранения и скорость восстановления
8) в новом ПО — из 3-х блоков может один целиком (4 нода) вылететь — и ничего не умрет (я с нетерпением жду тестов как вы будете вынимать оба контроллера на хуавее)
Продолжать можно долго. И да, зачастую конкуренты толкают «шнягу». Но не всегда, есть случаи когда традиционные, устаревающие архитектуры имеют применение.
Ну а рассказывать как надо правильно делать — это гуглу и амазону можете, которые вообще в принципе СХД не используют. Да и facebook ушел с нетапа очень давно (собственно в т.ч. за счет фейсбука нетап и поднялся)
Реально, просьба — если хочется понять по настоящему — изучите материалы.
Я уже приводил ссылку, Nutanix Bible очень хорошим началом для этого будет.
stevenpoitras.com/the-nutanix-bible/
Вот только не надо сюда ФБ да гугл приплетать. В ВК тоже не используются СХД. Все дело в специфике хранения и обработки.
Они, кстати, и ваше решение никогда не будут использовать. Казалось бы, почему?
По вашим ответам:
1) Когда блоки находятся на разных устройствах, доступ к ним получается достаточно долгим, по скорости доступа это может быть медленнее, чем тот же FC. Но это еще вопрос, надо смотреть.
2) Все условно. Чудес компоновки вы не создаете. Все-таки чем же хуже Huawei FusionCube? По рекламным материалам очень похоже на ваше решение.
3) Для России пока(!) не очень актуально.
4) Не преимущество. То что вы создаете отказоустойчивость своими решениями, не говорит о том, что это лучше само по себе.
5) Все условно и требует тестирования. Могу предположить, что однажды все упрется в интерконнект. Но опять же, надо еще внимательно изучать, чудес не бывает. Бесконечной идеальной масштабируемости тоже.
6) А сколько инженеров по СХД в найме крупной компании? Что они делают, если СХД корректно настроена? По опыту работы в интеграторе, обычно крупные компании используют платную поддержку. То же самое будет и с ваши решением.
Они, кстати, и ваше решение никогда не будут использовать. Казалось бы, почему?
По вашим ответам:
1) Когда блоки находятся на разных устройствах, доступ к ним получается достаточно долгим, по скорости доступа это может быть медленнее, чем тот же FC. Но это еще вопрос, надо смотреть.
2) Все условно. Чудес компоновки вы не создаете. Все-таки чем же хуже Huawei FusionCube? По рекламным материалам очень похоже на ваше решение.
3) Для России пока(!) не очень актуально.
4) Не преимущество. То что вы создаете отказоустойчивость своими решениями, не говорит о том, что это лучше само по себе.
5) Все условно и требует тестирования. Могу предположить, что однажды все упрется в интерконнект. Но опять же, надо еще внимательно изучать, чудес не бывает. Бесконечной идеальной масштабируемости тоже.
6) А сколько инженеров по СХД в найме крупной компании? Что они делают, если СХД корректно настроена? По опыту работы в интеграторе, обычно крупные компании используют платную поддержку. То же самое будет и с ваши решением.
О, уже лучше, пошла конкретика.
Насчет приплетать — «надо вася, надо» (без обид, просто из фильма)
Технологии рейд уже просто не предназначены для реально больших объемов данных. Почитайте например хотя-бы
www.storagenewsletter.com/rubriques/market-reportsresearch/why-raid-dead-for-big-storage-cleversafe/
1) Nutanix настолько умен, что подтаскивает все блоки виртуальной машины локально (на тот нод где виртуалка запущена). Копии остаются размазанными по кластеру естественно.
По скорости доступа даже если это доступ по сети — медленнее FC не будет.
Коммутаторы сетевые Arista Networks (24x 10G порта Wire Rate, 350нс скорость коммутации, прайс всего 12000$) — быстрее большинства FC свитчей.
Ну и обращение будет сразу к пачке «контроллеров» в кластере, которым надо отдать нужные блоки. Это — очень быстро.
2) Huawei FusionCube, так-же как Dell VRTX, как Cisco Flexpod и прочие — это всего лишь сервера + СХД, упакованные в общий корпус, аналог стойки. Просто маркетинговая уловка.
Мы отличаемся принципиально, у нас изначально вся «СХД» размазана по всем нодам кластера логически и аппаратно.
Подсчитайте плз размер решения скажем на 400 VDI (это понятные попугаи для всех). У нас — 2U + сетевые коммутаторы (еще два U на стойку). Все. Больше ничего не нужно.
3) Не рассказывайте мне пожалуйста про неактуальность электричества.
Особенно для Мск, где ДЦ многие уже просто воют от того что с электричеством проблемы.
Да и «цены повышаются и постоянно растут».
Почти все крупные клиенты с которыми говорил — стоимость электричества ежемесячная — очень печалит.
Неакутально это разве что для SMB, но мы туда и не ориентированы.
4) Почитайте пожалуйста ссылку выше, тогда возможно поймете о чем я говорю.
Это — реально кардинальное преимущество. В случае вылета полки традиционной СХД (скажем на 24 диска), ребилд будет идти до недели. У нас чем больше кластер — тем быстрее ребилд, на 20 нодах вылетевший диск — ребилд 10 минут.
Как в свое время все смеялись над виртуализацией («железные сервера — наше все!»), теперь приходит время умирать RAID. Точнее, останется (как и bare-bone решения), но узкоспециализированно.
5) Верно! Берут и тестируют ;) На слово мне верить точно не надо.
Есть интерес — и вы берите.
«Могу предположить, что однажды все упрется в интерконнект.» — 80 гигабит на 4 нода мало?
Не вопрос, воткнем 40 гигабит (80 на каждый нод будет). 40G сетевые карты уже есть.
Не забывайте — нет центральной точки обмена, все ноды друг с другом по принципу «торрента» работают. Суммарно мы на порядок (именно порядок) быстрее традиционной FC 8G будем по интерконнекту.
16G FC (который безумно дорогой нынче) мы тоже выносим на ура (простая математика).
6) У нас конвергентное решение — поддержка сразу на все. Железо, софт, «СХД», сервера, и даже гипервизор. У нас наибольшее количество VCDX-специалистов в мире после самой vmware. Клиентам очень нравится система «единого окна», в отличии от VCE и прочих Flexpod, где постоянные хождения по кругу между вендорами.
Фактически, по опыту — даже очень крупные проекты, инфраструктурных инженеров остается нужно буквально пару человек вообще на все.
Пример конкретный — мы делали очень большой VDI проект для американской армии, они в итоге с 15 человек инженеров сократили до 4-х.
p.s. приложил кусочек case study из армии США:

весь кейс (он кстати сильно устарел, сейчас там намного интереснее все — но уже NDA)
www.dropbox.com/s/4sh3rd7b2k9350w/Nutanix_US_Army_Case_Study.pdf
Насчет приплетать — «надо вася, надо» (без обид, просто из фильма)
Технологии рейд уже просто не предназначены для реально больших объемов данных. Почитайте например хотя-бы
www.storagenewsletter.com/rubriques/market-reportsresearch/why-raid-dead-for-big-storage-cleversafe/
1) Nutanix настолько умен, что подтаскивает все блоки виртуальной машины локально (на тот нод где виртуалка запущена). Копии остаются размазанными по кластеру естественно.
По скорости доступа даже если это доступ по сети — медленнее FC не будет.
Коммутаторы сетевые Arista Networks (24x 10G порта Wire Rate, 350нс скорость коммутации, прайс всего 12000$) — быстрее большинства FC свитчей.
Ну и обращение будет сразу к пачке «контроллеров» в кластере, которым надо отдать нужные блоки. Это — очень быстро.
2) Huawei FusionCube, так-же как Dell VRTX, как Cisco Flexpod и прочие — это всего лишь сервера + СХД, упакованные в общий корпус, аналог стойки. Просто маркетинговая уловка.
Мы отличаемся принципиально, у нас изначально вся «СХД» размазана по всем нодам кластера логически и аппаратно.
Подсчитайте плз размер решения скажем на 400 VDI (это понятные попугаи для всех). У нас — 2U + сетевые коммутаторы (еще два U на стойку). Все. Больше ничего не нужно.
3) Не рассказывайте мне пожалуйста про неактуальность электричества.
Особенно для Мск, где ДЦ многие уже просто воют от того что с электричеством проблемы.
Да и «цены повышаются и постоянно растут».
Почти все крупные клиенты с которыми говорил — стоимость электричества ежемесячная — очень печалит.
Неакутально это разве что для SMB, но мы туда и не ориентированы.
4) Почитайте пожалуйста ссылку выше, тогда возможно поймете о чем я говорю.
Это — реально кардинальное преимущество. В случае вылета полки традиционной СХД (скажем на 24 диска), ребилд будет идти до недели. У нас чем больше кластер — тем быстрее ребилд, на 20 нодах вылетевший диск — ребилд 10 минут.
Как в свое время все смеялись над виртуализацией («железные сервера — наше все!»), теперь приходит время умирать RAID. Точнее, останется (как и bare-bone решения), но узкоспециализированно.
5) Верно! Берут и тестируют ;) На слово мне верить точно не надо.
Есть интерес — и вы берите.
«Могу предположить, что однажды все упрется в интерконнект.» — 80 гигабит на 4 нода мало?
Не вопрос, воткнем 40 гигабит (80 на каждый нод будет). 40G сетевые карты уже есть.
Не забывайте — нет центральной точки обмена, все ноды друг с другом по принципу «торрента» работают. Суммарно мы на порядок (именно порядок) быстрее традиционной FC 8G будем по интерконнекту.
16G FC (который безумно дорогой нынче) мы тоже выносим на ура (простая математика).
6) У нас конвергентное решение — поддержка сразу на все. Железо, софт, «СХД», сервера, и даже гипервизор. У нас наибольшее количество VCDX-специалистов в мире после самой vmware. Клиентам очень нравится система «единого окна», в отличии от VCE и прочих Flexpod, где постоянные хождения по кругу между вендорами.
Фактически, по опыту — даже очень крупные проекты, инфраструктурных инженеров остается нужно буквально пару человек вообще на все.
Пример конкретный — мы делали очень большой VDI проект для американской армии, они в итоге с 15 человек инженеров сократили до 4-х.
p.s. приложил кусочек case study из армии США:

весь кейс (он кстати сильно устарел, сейчас там намного интереснее все — но уже NDA)
www.dropbox.com/s/4sh3rd7b2k9350w/Nutanix_US_Army_Case_Study.pdf
Ладно, убедили. Покупаю. Заворачивайте)
Посмотрим, конечно, что будет дальше.
На 400 VDI могу предложить VMware VSA. Но я не знаю на сколько там производительности хватит, но это первое что приходит в голову. Но опять же, 400 VDI это никак не крупный бизнес, на который вы вроде как метите, что толку его обсуждать?
Электричество в дата-центрах, безусловно, имеет вес. Да вот только не вижу что-то что кто-то реально начинает покупать зеленые устройства для экономии электроэнергии. Когда-то это будет актуально, но не сейчас.
FusionCube вроде как ставит себя как именно масштабируемая система без единого СХД, используется распределенное хранение по нодам.
Ребилд, если рассматривать Huawei, будет короче, там для этого есть техологии типа raid 2.0. По крайней мере заявлено исправление косяков стандартных рейдов и более оптимальное хранение данных.
И про армию. Эти все сравнения умиляют у всех вендоров. Если у них до этого было что-то, что внедряли 10 лет назад, то само собой оно устарело по всем параметрам. Точные данные проекта ни кто не расскажет, например.
Посмотрим, конечно, что будет дальше.
На 400 VDI могу предложить VMware VSA. Но я не знаю на сколько там производительности хватит, но это первое что приходит в голову. Но опять же, 400 VDI это никак не крупный бизнес, на который вы вроде как метите, что толку его обсуждать?
Электричество в дата-центрах, безусловно, имеет вес. Да вот только не вижу что-то что кто-то реально начинает покупать зеленые устройства для экономии электроэнергии. Когда-то это будет актуально, но не сейчас.
FusionCube вроде как ставит себя как именно масштабируемая система без единого СХД, используется распределенное хранение по нодам.
Ребилд, если рассматривать Huawei, будет короче, там для этого есть техологии типа raid 2.0. По крайней мере заявлено исправление косяков стандартных рейдов и более оптимальное хранение данных.
И про армию. Эти все сравнения умиляют у всех вендоров. Если у них до этого было что-то, что внедряли 10 лет назад, то само собой оно устарело по всем параметрам. Точные данные проекта ни кто не расскажет, например.
VDI это просто попугаи в которых удобно мерять. Можете 40000 VDI :)
Просто умножаете на нужное количество блоков нутаникс.
Очевидно, мы не только и не столько для VDI.
В РФ сейчас проекты просчитываем на 20000.
VSA — поверьте, все плохо. Это чистый SMB, да еще и внутри как раз сделано все по старинке — фактически, сетевой RAID. Любой профессионал по Vmware ( включая работников компании) сразу скажет — VSAN на большие объемы никак не претендует.
«FusionCube вроде как ставит себя как именно масштабируемая система без единого СХД, используется распределенное хранение по нодам. „
И да и нет ;) Там реально есть некоторые начальные шаги в нашем направлении, но много ограничений (например посмотрите максимальные параметры), да и распределенная ФС построена криво, особенно работа с метаданными.
У нас кстати метаданные (я уже говорил) — на жестко доработанной Cassandra, чистый NoSQL внутри системы крутится. Кассандра масштабируется на тысячи нодов (например Инстаграм на ней сидит), многие ключевые разработчики кассандры сейчас у нас работают.
Ближе были кстати ScaleIO — но их выкупила EMC. И что-то мне подсказывает, на рынок выводить торопиться не будут или по космическим ценам выведут ;)
Опять-же, мы где-то на два года впереди от ScaleIO по разработке.
“И про армию. Эти все сравнения умиляют у всех вендоров. „
Cогласен, чего уж там. Люди реально требуют кейсов, мы их даем. Тут уже как про волков — с волками жить, по волчьи выть ;) И в “магический квадрант» придется войти.
Замечу, что в очень многих правительственных контрактах — «выносим» именно EMC / Netapp.
Согласитесь, для «неизвестного стартапа» — дела неплохи весьма? Как технически, так и с клиентами.
На самом деле компания первый год работала только с правительственными службами, и не было за всю историю (пока как минимум ;) ) ни одной потери данных ни у одного клиента. Иначе уже EMC и прочие бегали с большими флагами и тыкали в нас палкой.
Никто не говорит что никогда не произойдет (все в этом мире бывает), но архитектура на самом деле очень интересная и чрезвычайно отказоустойчиво.
Опять-же — на слово мне верить не надо, мы с удовольствием даем клиентам на тесты.
Больше тестов и трезвых мнений — проще работать на рынке.
p.s. Вот кстати брошюра на русском:
www.dropbox.com/s/smpuvy1yxb6du4z/Datasheet_Nov2013_ru-RU.pdf
Просто умножаете на нужное количество блоков нутаникс.
Очевидно, мы не только и не столько для VDI.
В РФ сейчас проекты просчитываем на 20000.
VSA — поверьте, все плохо. Это чистый SMB, да еще и внутри как раз сделано все по старинке — фактически, сетевой RAID. Любой профессионал по Vmware ( включая работников компании) сразу скажет — VSAN на большие объемы никак не претендует.
«FusionCube вроде как ставит себя как именно масштабируемая система без единого СХД, используется распределенное хранение по нодам. „
И да и нет ;) Там реально есть некоторые начальные шаги в нашем направлении, но много ограничений (например посмотрите максимальные параметры), да и распределенная ФС построена криво, особенно работа с метаданными.
У нас кстати метаданные (я уже говорил) — на жестко доработанной Cassandra, чистый NoSQL внутри системы крутится. Кассандра масштабируется на тысячи нодов (например Инстаграм на ней сидит), многие ключевые разработчики кассандры сейчас у нас работают.
Ближе были кстати ScaleIO — но их выкупила EMC. И что-то мне подсказывает, на рынок выводить торопиться не будут или по космическим ценам выведут ;)
Опять-же, мы где-то на два года впереди от ScaleIO по разработке.
“И про армию. Эти все сравнения умиляют у всех вендоров. „
Cогласен, чего уж там. Люди реально требуют кейсов, мы их даем. Тут уже как про волков — с волками жить, по волчьи выть ;) И в “магический квадрант» придется войти.
Замечу, что в очень многих правительственных контрактах — «выносим» именно EMC / Netapp.
Согласитесь, для «неизвестного стартапа» — дела неплохи весьма? Как технически, так и с клиентами.
На самом деле компания первый год работала только с правительственными службами, и не было за всю историю (пока как минимум ;) ) ни одной потери данных ни у одного клиента. Иначе уже EMC и прочие бегали с большими флагами и тыкали в нас палкой.
Никто не говорит что никогда не произойдет (все в этом мире бывает), но архитектура на самом деле очень интересная и чрезвычайно отказоустойчиво.
Опять-же — на слово мне верить не надо, мы с удовольствием даем клиентам на тесты.
Больше тестов и трезвых мнений — проще работать на рынке.
p.s. Вот кстати брошюра на русском:
www.dropbox.com/s/smpuvy1yxb6du4z/Datasheet_Nov2013_ru-RU.pdf
По поводу 40кiops я уже приводил пример. На том же Huawei можно вполне себе бюджетно вписаться. При том что решение будет более гибкое, чем VDI.
В целом я соглашусь, что в некоторых случаях ваше решение может быть безусловно интересным. Но все же кардинально неправильно его сравнивать с тем же XtremIO. Ваше решение нацелено именно на конвергентное решение VDI и сравнивать эти решения было бы не совсем правильно.
Проект интересный. Возможно, если задача только VDI из коробки, то будет интересно. Но это очень узкий рынок.
В целом я соглашусь, что в некоторых случаях ваше решение может быть безусловно интересным. Но все же кардинально неправильно его сравнивать с тем же XtremIO. Ваше решение нацелено именно на конвергентное решение VDI и сравнивать эти решения было бы не совсем правильно.
Проект интересный. Возможно, если задача только VDI из коробки, то будет интересно. Но это очень узкий рынок.
Еще раз, коротко.
Мы НЕ нацелены только на VDI. VDI это просто пример который удобен для измерения в попугаях.
Почти все что виртуализируется — на нас прекрасно работает. Включая крупные базы данных на терабайты.
Не надо ни себя, ни других обманывать — VDI это лишь только небольшая область наших проектов.
Посмотрите-таки брошюру, если не хочется сайт изучать и кейсы наши.
www.dropbox.com/s/smpuvy1yxb6du4z/Datasheet_Nov2013_ru-RU.pdf
Мы НЕ нацелены только на VDI. VDI это просто пример который удобен для измерения в попугаях.
Почти все что виртуализируется — на нас прекрасно работает. Включая крупные базы данных на терабайты.
Не надо ни себя, ни других обманывать — VDI это лишь только небольшая область наших проектов.
Посмотрите-таки брошюру, если не хочется сайт изучать и кейсы наши.
www.dropbox.com/s/smpuvy1yxb6du4z/Datasheet_Nov2013_ru-RU.pdf
Совсем забыл (с ребенком заигрался ;) )
FusionCube — это чисто линукс, Oracle / RH насколько я помню.
У нас — ESXi, HyperV, KVM / Openstack — официально поддерживаемые. Со всеми вытекающими…
FusionCube — это чисто линукс, Oracle / RH насколько я помню.
У нас — ESXi, HyperV, KVM / Openstack — официально поддерживаемые. Со всеми вытекающими…
Кстати.
Нас оказывается гартнер к серверам отнес ;)
Nutanix Named «Cool Vendor» by Analyst Firm Gartner
«Cool Vendor» Report Recognizes the Most Innovative, Impactful Vendors in the Server Market
finance.yahoo.com/news/nutanix-named-cool-vendor-analyst-130000137.html
В общем-то — логично, СХД как отдельная вещь себя изживает.
Нас оказывается гартнер к серверам отнес ;)
Nutanix Named «Cool Vendor» by Analyst Firm Gartner
«Cool Vendor» Report Recognizes the Most Innovative, Impactful Vendors in the Server Market
finance.yahoo.com/news/nutanix-named-cool-vendor-analyst-130000137.html
В общем-то — логично, СХД как отдельная вещь себя изживает.
Хотелось бы реально увидеть как нам показывали на презентации:
1. отказ 6 дисков из брика
2. 100 000 IOPS на random write блоками по 4К
3. 150 000 IOPS на random read/write блоками по 4К
4. 200 000 IOPS на random read блоками по 4К
Кстати для интересующихся есть документы на xtremio.com, как это все работает. По первым прикидкам очень интересно. Фишка не только в сквозной дедупликации, но и как она сделана на весь объем, и как работает при этом запись.
Если уважаемый автор сможет провести тесты про которые я выше написал и они подтвердятся, это будет супер!
VCE это не XtremIO.
К нам тоже приходил Nutanix хотел через нас продаваться… Нет слов. Аж 3 раза приходил, по нашим прикидкам было нам не выгодно его продавать. Мне стало интересно, чем интересен Nutanix, на официальном сайте, как то совсем мало по технологии, начал читать зарубежные блоги… интересно почитать ПОЧЕМУ продается Nutinix, потому что продается за себестоимость, по крайней мере, год назад такое писали, компания не вышла не прибыльность, пока только проедает венчурные деньги. Да и слушок такой не хороший, что создавалась, чтобы продаться подороже той же EMC, но последней она не понравилась, вот и комплекс теперь похоже.
Может за год, который прошел с моего последнего интереса к ней, что-то и поменялось.
Да и открытых тестов мягко сказать, маловато, только EGS Labs кажется, по ним не особо то фантастичная скорость. То же клонирование, от того же Netapp 3200 серии на обычных дисках отстает хорошо. С флешем даже не сравнить.
Ну и из той же презентации, якобы Vmware использовало на VMworld 2013 XtremIO в какой конфигурации, и они в полном восторге, да и пользователи vLab тоже, деталей не помню, думаю не трудно будет найти, тем более публичное мероприятие. Наверно будь Nutanix так хорош, наверно бы его взяли, тем более он тоже какие то там медали от Vmware получал.
Да и не в одном VDI смысл жизни, подключите ка Nutanix к серверу с Виндой или линуксом с базой Oracle терабайт на 5 по FC?
1. отказ 6 дисков из брика
2. 100 000 IOPS на random write блоками по 4К
3. 150 000 IOPS на random read/write блоками по 4К
4. 200 000 IOPS на random read блоками по 4К
Кстати для интересующихся есть документы на xtremio.com, как это все работает. По первым прикидкам очень интересно. Фишка не только в сквозной дедупликации, но и как она сделана на весь объем, и как работает при этом запись.
Если уважаемый автор сможет провести тесты про которые я выше написал и они подтвердятся, это будет супер!
VCE это не XtremIO.
К нам тоже приходил Nutanix хотел через нас продаваться… Нет слов. Аж 3 раза приходил, по нашим прикидкам было нам не выгодно его продавать. Мне стало интересно, чем интересен Nutanix, на официальном сайте, как то совсем мало по технологии, начал читать зарубежные блоги… интересно почитать ПОЧЕМУ продается Nutinix, потому что продается за себестоимость, по крайней мере, год назад такое писали, компания не вышла не прибыльность, пока только проедает венчурные деньги. Да и слушок такой не хороший, что создавалась, чтобы продаться подороже той же EMC, но последней она не понравилась, вот и комплекс теперь похоже.
Может за год, который прошел с моего последнего интереса к ней, что-то и поменялось.
Да и открытых тестов мягко сказать, маловато, только EGS Labs кажется, по ним не особо то фантастичная скорость. То же клонирование, от того же Netapp 3200 серии на обычных дисках отстает хорошо. С флешем даже не сравнить.
Ну и из той же презентации, якобы Vmware использовало на VMworld 2013 XtremIO в какой конфигурации, и они в полном восторге, да и пользователи vLab тоже, деталей не помню, думаю не трудно будет найти, тем более публичное мероприятие. Наверно будь Nutanix так хорош, наверно бы его взяли, тем более он тоже какие то там медали от Vmware получал.
Да и не в одном VDI смысл жизни, подключите ка Nutanix к серверу с Виндой или линуксом с базой Oracle терабайт на 5 по FC?
«но последней она не понравилась, вот и комплекс теперь похоже.» со стороны, как говорится, виднее :)
новости-то смотрите? компания только что полчила оценку более миллиарда долларов. Продаваться может и будет, но учитывая что основная «крыша» это ГолдманСаш, а все еще только начинается — это будут совсем другие деньги и время. Уж больно Goldman любит деньги (взаимною любовью).
" Vmware использовало на VMworld 2013 XtremIO в какой конфигураци" — именно поэтому Nutanix взял золотую медаль VMworld 2013? :D Точнее, берет три года подряд? ;)
finance.yahoo.com/news/nutanix-wins-best-vmworld-2013-160000882.html
«Nutanix Wins Best of VMworld 2013 Gold Award for Private Cloud Computing»
«подключите ка Nutanix к серверу с Виндой или линуксом с базой Oracle терабайт на 5 по FC?»
Как я понимаю, нет понимания нашей архитектуры? «Диск» у нас спокойно между нодами растягивается. Если в нодах по 1.6TB ставить (3461 модель например) — то на 2U блок будет уже 6.4TB SSD.
У нас есть 6120 ноды уже — чисто для расширения «СХД» — один блок 1U — 20TB места (+800G флеш).
Ну и зачем нам FC? Если внутри блока у нас доступно 80 гигабит для обмена? :)
Насчет приходили, аж три раза — не назовете все-же компанию? У меня есть пара очень веселых историй на рынке РФ с интеграторами (когда внутренние отделы по СХД делали все что можно лишь бы тестирование «не прошло»), но в общем-то есть и много хороших кейсов.
А вообще — дабы не устраивать здесь свалку, давайте не будем споры разводить. Если есть конструктивная критика или вопросы — можно на емейл или я все-же скоро статью на хабре опубликую (и там можно будет оторваться по полной).
новости-то смотрите? компания только что полчила оценку более миллиарда долларов. Продаваться может и будет, но учитывая что основная «крыша» это ГолдманСаш, а все еще только начинается — это будут совсем другие деньги и время. Уж больно Goldman любит деньги (взаимною любовью).
" Vmware использовало на VMworld 2013 XtremIO в какой конфигураци" — именно поэтому Nutanix взял золотую медаль VMworld 2013? :D Точнее, берет три года подряд? ;)
finance.yahoo.com/news/nutanix-wins-best-vmworld-2013-160000882.html
«Nutanix Wins Best of VMworld 2013 Gold Award for Private Cloud Computing»
«подключите ка Nutanix к серверу с Виндой или линуксом с базой Oracle терабайт на 5 по FC?»
Как я понимаю, нет понимания нашей архитектуры? «Диск» у нас спокойно между нодами растягивается. Если в нодах по 1.6TB ставить (3461 модель например) — то на 2U блок будет уже 6.4TB SSD.
У нас есть 6120 ноды уже — чисто для расширения «СХД» — один блок 1U — 20TB места (+800G флеш).
Ну и зачем нам FC? Если внутри блока у нас доступно 80 гигабит для обмена? :)
Насчет приходили, аж три раза — не назовете все-же компанию? У меня есть пара очень веселых историй на рынке РФ с интеграторами (когда внутренние отделы по СХД делали все что можно лишь бы тестирование «не прошло»), но в общем-то есть и много хороших кейсов.
А вообще — дабы не устраивать здесь свалку, давайте не будем споры разводить. Если есть конструктивная критика или вопросы — можно на емейл или я все-же скоро статью на хабре опубликую (и там можно будет оторваться по полной).
«но последней она не понравилась, вот и комплекс теперь похоже.» со стороны, как говорится, виднее :)
Пишу, то что читал на блоге, но ни для кого не секрет, что 99% стартапов продается, чтобы продаться подороже.
новости-то смотрите? компания только что полчила оценку более миллиарда долларов. Продаваться может и будет, но учитывая что основная «крыша» это ГолдманСаш, а все еще только начинается — это будут совсем другие деньги и время
Оценка это не стоимость, у нокии лицензии было на 100500 долларов, а продалась за копейки. А это не тот Goldman, из-за которого весь этот кризис и начался, или я его с другим путаю?
Кстати почему пропала статься про Nutanix на en.wikipedia, год назад еще была, сам читал, или есть что скрывать?
Пришлось обратиться к интересному блогу о Нетапп, в нем один из комментаторов, который пробовал Nutanix, писал, что по отчету за 2012 года, было продано 150 систем!!!
Это в принципе коррелирует с тем, что я читал на вики и других блогах. Не важно, сколько в тебя влили, важно, сколько ты даешь прибыли. Есть результаты продаж систем за 2013 год?
" Vmware использовало на VMworld 2013 XtremIO в какой конфигураци" — именно поэтому Nutanix взял золотую медаль VMworld 2013? :D
Да хоть платиновая, было бы написано, что там под сотню тысяч VM развернуто и работало на VMworld на Nutanix, это интересно, а медали там вроде бы не только одной компании давались? Я за этим не слежу, как и за олимпиадой.
Как я понимаю, нет понимания нашей архитектуры? «Диск» у нас спокойно между нодами растягивается. Если в нодах по 1.6TB ставить (3461 модель например) — то на 2U блок будет уже 6.4TB SSD.
Я интересовался этой архитектурой год назад, тогда же к ней и пропал интерес, ничего личного, для нас это НЕ ВЫГОДНО продавать.
Ну и зачем нам FC? Если внутри блока у нас доступно 80 гигабит для обмена? :)
У наших клиентов все на FC, и их это устраивает.
Насчет приходили, аж три раза — не назовете все-же компанию?
Я не с РФ. Повторюсь, политика бизнеса такая, если даже у тебя внутри корпуса сидят 100 эйнштейнов, но ты не продаешься, ты даром не нужен. Цена на самом деле, не сильное большое значение, при должном умении, при хорошем проекте, любой вендор прогибается под такую цену, которую ты просишь.
«А это не тот Goldman, из-за которого весь этот кризис и начался, или я его с другим путаю?» — тот, тот. Я-же говорю — деньги любят. Фейсбук на IPO выводили тоже.
Исходя из оценки дают инвестиции. Nutanix только что закрыл раунд, 100 миллионов долларов. Деньги в дело идут — например по количеству VCDX в команде мы уже на первом месте в мире после самой VMware.
И ПО гипер-активно разработка, выходящая вот-вот (месяц) версия 4 например выдерживает отказ блока целиком (если их больше 3) со всеми 4-я нодами. Это, чтобы было понятно — как взять и выдергнуть 4 контроллера одновременно из EMC, и чтобы при этом еще и продолжало все работать. ExtremeIO пока только два контроллера умеет, да?
" что по отчету за 2012 года, было продано 150 систем!!!" — неверно, но в общем-то не важно. Во-первых надо смотреть _кому_ продано было (военные и правительство США), во-вторых — реально рабочее универсальное ПО появилось как раз к концу 2012 года.
После этого темпы роста — коллосальные. Оно и понятно почему, нам не надо вкладываться в «железо» — мы написали свою ОС и очень быстро ее развиваем. Железо пусть делает Intel, они это умеют ;)
В отличии от безумных затрат на R&D железа у EMC — у нас оно практически ноль. Интел процессоры, шасси — супермикро, память / диски / флеш — все на одних заводах.
«медали там вроде бы не только одной компании давались?» — в каждой категории — одной. Nutanix фактически назван лучшим решением для построения частных облаков.
Мало того, Nutanix — единственная за всю историю компания, которая берет золотые медали три года подряд.
«100 эйнштейнов, но ты не продаешься, ты даром не нужен.» — конечно. Если не в РФ, тогда в общем-то скорее шанс упустили, в EU только за этот квартал на десятки миллионов $ продажи насколько я знаю. NHS в UK например тоже уже на Nutanix переходит.
«У наших клиентов все на FC, и их это устраивает. » ну, тут спорить не вижу смысла. Устраивает ровно до того момента пока не поймут что можно быстрее, лучше и дешевле. Мы как раз по тем «кого FC устраивает» специализируемся — выносим EMC из правительственных органов, военных, спецслужб и крупных энтерпрайзов.
в США уже продает на CDW. Если есть понимание рынка США — то если что-то начал активно пихать CDW, это очень сильно меняет расклад.
«для нас это НЕ ВЫГОДНО продавать.» — не зная экономики, не отвечу. скорее не выгодно именно потому что вы сейчас можете на клиентах зарабатывать больше, продавая множество разных технологий. Обычно, это все работает до того момента пока не пришли более шустрые мелкие интеграторы и не рассказали что можно по другому.
Исходя из оценки дают инвестиции. Nutanix только что закрыл раунд, 100 миллионов долларов. Деньги в дело идут — например по количеству VCDX в команде мы уже на первом месте в мире после самой VMware.
И ПО гипер-активно разработка, выходящая вот-вот (месяц) версия 4 например выдерживает отказ блока целиком (если их больше 3) со всеми 4-я нодами. Это, чтобы было понятно — как взять и выдергнуть 4 контроллера одновременно из EMC, и чтобы при этом еще и продолжало все работать. ExtremeIO пока только два контроллера умеет, да?
" что по отчету за 2012 года, было продано 150 систем!!!" — неверно, но в общем-то не важно. Во-первых надо смотреть _кому_ продано было (военные и правительство США), во-вторых — реально рабочее универсальное ПО появилось как раз к концу 2012 года.
После этого темпы роста — коллосальные. Оно и понятно почему, нам не надо вкладываться в «железо» — мы написали свою ОС и очень быстро ее развиваем. Железо пусть делает Intel, они это умеют ;)
В отличии от безумных затрат на R&D железа у EMC — у нас оно практически ноль. Интел процессоры, шасси — супермикро, память / диски / флеш — все на одних заводах.
«медали там вроде бы не только одной компании давались?» — в каждой категории — одной. Nutanix фактически назван лучшим решением для построения частных облаков.
Мало того, Nutanix — единственная за всю историю компания, которая берет золотые медали три года подряд.
«100 эйнштейнов, но ты не продаешься, ты даром не нужен.» — конечно. Если не в РФ, тогда в общем-то скорее шанс упустили, в EU только за этот квартал на десятки миллионов $ продажи насколько я знаю. NHS в UK например тоже уже на Nutanix переходит.
«У наших клиентов все на FC, и их это устраивает. » ну, тут спорить не вижу смысла. Устраивает ровно до того момента пока не поймут что можно быстрее, лучше и дешевле. Мы как раз по тем «кого FC устраивает» специализируемся — выносим EMC из правительственных органов, военных, спецслужб и крупных энтерпрайзов.
в США уже продает на CDW. Если есть понимание рынка США — то если что-то начал активно пихать CDW, это очень сильно меняет расклад.
«для нас это НЕ ВЫГОДНО продавать.» — не зная экономики, не отвечу. скорее не выгодно именно потому что вы сейчас можете на клиентах зарабатывать больше, продавая множество разных технологий. Обычно, это все работает до того момента пока не пришли более шустрые мелкие интеграторы и не рассказали что можно по другому.
тот, тот. Я-же говорю — деньги любят. Фейсбук на IPO выводили тоже.И где теперь этот IPO от фейсбука от первоначально заявленного? Не очень хорошая реклама, долги Goldman покрыли из госсредств, т.е. тоже самое госрегулирование, очень мало имеющего отношения к бизнесу.
И ПО гипер-активно разработка, выходящая вот-вот (месяц) версия 4 например выдерживает отказ блока целиком (если их больше 3) со всеми 4-я нодами. Это, чтобы было понятно — как взять и выдергнуть 4 контроллера одновременно из EMC, и чтобы при этом еще и продолжало все работать. ExtremeIO пока только два контроллера умеет, да?
По презентации полный отказ одного брика, но не суть. XtremIO (Extreme это сетевая компания) продается 6 месяцев и успешно, а Nutanix с 2010 года, а уж разработка еще раньше шла. Что-то не очень то активно.
" что по отчету за 2012 года, было продано 150 систем!!!" — неверно, но в общем-то не важно.
Это очень важно, еще раз повторюсь есть цифры продаж за 2013 год, без цифр это голимый маркетинг, мой финдиректор пошлет сразу и далеко.
В отличии от безумных затрат на R&D железа у EMC
Вы не поверите, но EMC XtremIO купила, т.е. нет затрат R&D, и сразу начали продаваться! Да и в самих EMC, все те же Intel процессоры да eMLC диски. И в Netapp и многих других.
Обычно, это все работает до того момента пока не пришли более шустрые мелкие интеграторы и не рассказали что можно по другому
Флаг им в руки, обычно до первой продажи «чего-нибудь которое супер фантастично и решает все ваши задачи», тогда приходим опять мы, выкидываем это «чудо» и ставим нормальные решения, которые можно реально потестить.
Вот уважаемый автор с Крока, не боится потестить XtremIO, подозреваю, что EMC тоже не боится опозориться, вот покажите чего стоят ваши ярды зелени, отдайте любому вашему партнеру или сами, на суд инженеров Хабра, если ваши результаты будут совпадать с вашими словами, я первый скажу ЧТО NUTANIX НАШЕ ВСЁ!!!
«И где теперь этот IPO от фейсбука от первоначально заявленного? » — шутите? или решили «грамотность» финансовую показать?
Ссылка
Акции очень сильно выросли после начала IPO, да. На facebook многие заработали колоссальные деньги.
«EMC XtremIO купила, т.е. нет затрат R&D» — там далеко не все так как вы рассказываете ;)
Затраты есть, и очень большие. Отсюда и цену выкатили фантастическую.
«отдайте любому вашему партнеру или сами, на суд инженеров Хабра» — да бог-ты мой, какие проблемы ;)
OCS Distribution поговорите например. Они тестили ;) И подписались на дистрибьюцию в РФ.
А так — тут есть даже один известный автор блога по Netapp (Роман), он про Nutanix тоже завел. Оно понятно, что на двух стульях ему тяжело сидеть (netapp-таки кормилец), но пишет вполне неплохо. Мало того — мы с ним много виртуально переругивались в переписке ;)) Так что вполне честное и независимое мнение.
И да — он имеет доступ к железу и тестировал его.
blog.in-a-nutshell.ru/
Ссылка
Акции очень сильно выросли после начала IPO, да. На facebook многие заработали колоссальные деньги.
«EMC XtremIO купила, т.е. нет затрат R&D» — там далеко не все так как вы рассказываете ;)
Затраты есть, и очень большие. Отсюда и цену выкатили фантастическую.
«отдайте любому вашему партнеру или сами, на суд инженеров Хабра» — да бог-ты мой, какие проблемы ;)
OCS Distribution поговорите например. Они тестили ;) И подписались на дистрибьюцию в РФ.
А так — тут есть даже один известный автор блога по Netapp (Роман), он про Nutanix тоже завел. Оно понятно, что на двух стульях ему тяжело сидеть (netapp-таки кормилец), но пишет вполне неплохо. Мало того — мы с ним много виртуально переругивались в переписке ;)) Так что вполне честное и независимое мнение.
И да — он имеет доступ к железу и тестировал его.
blog.in-a-nutshell.ru/
шутите? или решили «грамотность» финансовую показать?
И? Роста за последние полгода только, а год до этого тяжелые потуги вернуться на прежний уровень 2012 года.
На IPO выходят, чтобы подняться в цене а не упасть. Первоначально заявленные 38 баксов за акцию и мгновенный рост до 45 и такое же падение до 31 бакса, показывают, что явна была переоценка стоимости, и инвесторам это очень не понравилось, что и показывает стоимость за год от 2012 до середины 2013. Почему дальше стали расти надо смотреть, может прикупили кого, может еще что.
Но оценка Morgan Stanley, которая выводила IPO Facebook на рынок, явно была завышенной.
Думаю надо дождаться результатов года работы Nutanix после оценки Goldman, тогда и будет видно чего стоят эти деньги.
И подписались на дистрибьюцию в РФ.
Ждем инженеров OCS и лично Романа, с аналогичной статьей по оценке производительности.
«Первоначально заявленные 38 баксов за акцию и мгновенный рост до 45 и такое же падение до 31 бакса, показывают, что явна была переоценка стоимости» — пардон, это что-то показывает лишь паникерам да псевдо-экспертам.
Реальная стоимость акций сейчас практически в два раза выше чем была на IPO, что совершенно четко показывает ложность вашего заявления «и где они сейчас».
Остальные рассуждения — попытки как-то оправдать свою ошибку ;). Бывает. На самом деле многие реально думают что акции Facebook обвалены до сих пор…
Те-же кто мозгами работает и информацией — мой друг на акциях facebook заработал несколько миллионов долларов как минимум. Мало того — считает что выход на IPO был по заниженной оценке. Я скорее ему поверю, как очень успешному инвестору.
…
Насчет тестирования — совершенно согласен, все кто хотят — берут и тестируют. На слово точно никому нельзя верить в этом мире ;)
Реальная стоимость акций сейчас практически в два раза выше чем была на IPO, что совершенно четко показывает ложность вашего заявления «и где они сейчас».
Остальные рассуждения — попытки как-то оправдать свою ошибку ;). Бывает. На самом деле многие реально думают что акции Facebook обвалены до сих пор…
Те-же кто мозгами работает и информацией — мой друг на акциях facebook заработал несколько миллионов долларов как минимум. Мало того — считает что выход на IPO был по заниженной оценке. Я скорее ему поверю, как очень успешному инвестору.
…
Насчет тестирования — совершенно согласен, все кто хотят — берут и тестируют. На слово точно никому нельзя верить в этом мире ;)
На IPO выходят, чтобы подняться в цене а не упасть.Вы это всеръёз? Нет, действительно? Я понимаю, что вы не экономист, но есть же некоторый предел в уровне бреда, который можно тут нести.
Выход на IPO — это способ заработать для компании денег. Не больше и не меньше. Если акции после выхода на IPO сильно растут — то это плохо. Если они в первый день вырастуют в несколько раз — то это просто жутчайшая некомпетентность. Также некомпетентностью является вывод по цене, по которой весь пакет не удаётся продать: мало того, что после этого приходится все планы перекраивать, так ещё и ущерб по репутации наносится.
Первоначально заявленные 38 баксов за акцию и мгновенный рост до 45 и такое же падение до 31 бакса, показывают, что явна была переоценка стоимости, и инвесторам это очень не понравилось, что и показывает стоимость за год от 2012 до середины 2013.Неа. Это показывает что вывод на IPO был фантастически успешен: все акции были проданы и за них было взято почти всё, что за них можно было взять. Я вообще очень мало более грамотных примеров могу вспомнить. А то, что на этом IPO «инвестроры» (то есть спекулянты) навариться «от души» (как планировали) не смогли — так это другая история.
«то же клонирование, от того же Netapp 3200 серии на обычных дисках отстает хорошо. С флешем даже не сравнить.»
Кто-то что-то путает мне сдается.
У нас клонирование все внутри — в линкованные клоны превращается. Так-же как есть технология shadow clone — когда на каждом ноде автоматически появляются линкованные клоны для акселерации работы виртуалок склонированных.
врочем, встречаются не очень грамотные инженеры по СХД, которые не знают ограничений ESXi по клонированию — VAAI аккселерация работает только в случае если клонируемый диск не имеет снапшотов и виртуальная машина выключена. Иначе клонирование идет средствами гипервизора, и производительность будет очень невысокая.
говорить про «только VDI» — очень смешно, у нас множество проектов по полной виртуализации сверхкрупных энтерпрайзов (сервера включая БД, bigdata и тд).
Да, я кажется начинаю понимать о ком речь идет — пару «тестеров» таких я знаю ;)
Кто-то что-то путает мне сдается.
У нас клонирование все внутри — в линкованные клоны превращается. Так-же как есть технология shadow clone — когда на каждом ноде автоматически появляются линкованные клоны для акселерации работы виртуалок склонированных.
врочем, встречаются не очень грамотные инженеры по СХД, которые не знают ограничений ESXi по клонированию — VAAI аккселерация работает только в случае если клонируемый диск не имеет снапшотов и виртуальная машина выключена. Иначе клонирование идет средствами гипервизора, и производительность будет очень невысокая.
говорить про «только VDI» — очень смешно, у нас множество проектов по полной виртуализации сверхкрупных энтерпрайзов (сервера включая БД, bigdata и тд).
Да, я кажется начинаю понимать о ком речь идет — пару «тестеров» таких я знаю ;)
У нас клонирование все внутри — в линкованные клоны превращается.
У Нетапа тоже все внутри, без всякого использования Vmware, сравнил с первым что пришло на память, на youtube есть какой ролик про клонирование нескольких тыс или десятков тысяч VM, поищите мне просто лень.
А вы почитайте каким образом идет клонирование в XtremIO вы сильно удивитесь, насколько это ушло вперед от всех других. Поэтому и прошу уважаемого автора хорошо потестить XtremIO, т.к. самим в демо его брать дороговато :)
Пожалуйста виртуализируйте мне базу нашего клиента на Oracle под AIX, который на Power 770 крутиться, который сам иногда не справляется.
Далеко не все задачи можно виртуализировать, а вот хорошая СХД нужна всем.
Да, я кажется начинаю понимать о ком речь идет — пару «тестеров» таких я знаю ;)
Можете не напрягаться, мы даже его не тестили.
Результаты продаж за 2013 год есть, чтобы хотябы можно было говорить, что он взлетел?
Я же писал выше — мы не претендуем заменить _все_. OLTP базы и нестандартные архитектуры — пока не наш рынок (хотя в общем-то надо будет — выйдем без больших проблем).
При этом Oracle на нас гоняет весьма много клиентов, да и SAP мы на финальных стадиях сертификации (не зря в нас вложился SAP Ventures)
www.sapventures.com/2014/02/12/nutanix-accelerates-transformation-of-enterprise-datacenters-with-historic-101-million-funding-round-sap-ventures-co-leads-round/
«клонирование нескольких тыс или десятков тысяч VM»
Мы точно так-же сделаем это за считанные секунды. Как сделано в XtremIO — не удивлюсь ;). Так уж сложилось, что много разработчиков переходит к нам — в тч из EMC, VMware, Netapp и т.д. (причины очевидны — лучше условия, интереснее работа и все стартапы в США дают акции).
Ничего особенного там нет. Вы лучше изучите как оно у нас сделано — вот точно удивитесь. Почитайте кстати Nutanix Bible — много интересного.
stevenpoitras.com/the-nutanix-bible/
При этом Oracle на нас гоняет весьма много клиентов, да и SAP мы на финальных стадиях сертификации (не зря в нас вложился SAP Ventures)
www.sapventures.com/2014/02/12/nutanix-accelerates-transformation-of-enterprise-datacenters-with-historic-101-million-funding-round-sap-ventures-co-leads-round/
«клонирование нескольких тыс или десятков тысяч VM»
Мы точно так-же сделаем это за считанные секунды. Как сделано в XtremIO — не удивлюсь ;). Так уж сложилось, что много разработчиков переходит к нам — в тч из EMC, VMware, Netapp и т.д. (причины очевидны — лучше условия, интереснее работа и все стартапы в США дают акции).
Ничего особенного там нет. Вы лучше изучите как оно у нас сделано — вот точно удивитесь. Почитайте кстати Nutanix Bible — много интересного.
stevenpoitras.com/the-nutanix-bible/
Для понимания — технически, мы можем «отдаваться» наружу как generic СХД.
Дизайн системы позволяет, мало того в версии 4 в этом смысле сильно улучшено все, да еще и с 3.5.2 мы свою реализацию SMB3 сделали (что резко подняло производительность HyperV на нас).
Но официально мы это не делаем и пока не собираемся. Это уже бизнес-логика.
Дизайн системы позволяет, мало того в версии 4 в этом смысле сильно улучшено все, да еще и с 3.5.2 мы свою реализацию SMB3 сделали (что резко подняло производительность HyperV на нас).
Но официально мы это не делаем и пока не собираемся. Это уже бизнес-логика.
Случайно наткнулся на интересный видеообзор:
www.youtube.com/watch?v=Qf8Oh62reiI
www.youtube.com/watch?v=Qf8Oh62reiI
Пропустил про результаты продаж…
«Nutanix has exceeded $100 million in lifetime sales and acquired 13 customers who have purchased more than $1 million of products within two years of launching its award-winning Virtual Computing Platform, cementing its status as the fastest-growing infrastructure company of the decade. Due to an aggressive global expansion strategy, international sales now account for 33 percent of the business and the company has shipped product to more than 30 countries in the last six months.»
«Nutanix has exceeded $100 million in lifetime sales and acquired 13 customers who have purchased more than $1 million of products within two years of launching its award-winning Virtual Computing Platform, cementing its status as the fastest-growing infrastructure company of the decade. Due to an aggressive global expansion strategy, international sales now account for 33 percent of the business and the company has shipped product to more than 30 countries in the last six months.»
Собственно, мы (это уже официально признано) — самая быстрорастущая технологическая IT компания за последние 10 лет.
О чем SAP Ventures и пишет.
О чем SAP Ventures и пишет.
Цифры ни о чем. 100 млн. в ценах Nutanix или отпускных для клиента? на 1 млн продано 13 клиентам или каждому из них? и это за 2 года?
Если интересуют конкретика — это с нашими финансистами общаться. Я — тех.дир по Восточной Европе, и вне области своей компетенции могу оперировать только тем что свободно в интернете есть.
Повторюсь, если нас начал продавать CDW / CDW-G — это означает что с финансовыми показателями у нас все прекраснейшим образом обстоит.
И поверьте, я вас не уговариваю заняться нашей продажей ;). Опыт показывает что зачастую надо с клиентами напрямую работать с точки зрения информационной поддержки, а затем уже они приходят к интеграторам и требуют то что хотят сами, а не то что им «впаривают».
Повторюсь, если нас начал продавать CDW / CDW-G — это означает что с финансовыми показателями у нас все прекраснейшим образом обстоит.
И поверьте, я вас не уговариваю заняться нашей продажей ;). Опыт показывает что зачастую надо с клиентами напрямую работать с точки зрения информационной поддержки, а затем уже они приходят к интеграторам и требуют то что хотят сами, а не то что им «впаривают».
Опыт показывает что зачастую надо с клиентами напрямую работать с точки зрения информационной поддержки, а затем уже они приходят к интеграторам и требуют то что хотят сами, а не то что им «впаривают».
acquired 13 customers who have purchased more than $1 million of products
Поэтому продавцы даже не утруждаются отвечать на запросы от SMB?
Если вам где-то не ответили на запрос по поводу Nutanix — дайте пожалуйста знать. Скажем, как очевидно по переписке — очень много продавцов реально не очень заинтересованы в технологиях подобным Нутаниксу — заработки падают (как минимум, как они считают). Продавать «по старинке» очевидно (в первом приближении) выгоднее.
Но вообще мы на SMB официально не ориентированы (как минимум пока), это несколько другой рынок. Хотя запрета конечно никто не поставит.
Технически, у нас вот-вот будет «очень мелкая» железка на 10-20 виртуальных машин с достаточно смешной ценой.
Но вообще мы на SMB официально не ориентированы (как минимум пока), это несколько другой рынок. Хотя запрета конечно никто не поставит.
Технически, у нас вот-вот будет «очень мелкая» железка на 10-20 виртуальных машин с достаточно смешной ценой.
Уже не вспомню где именно оставлял запрос, возможно, что через форму на сайте спросил «сколько стоит».
Но спасибо за честный ответ про позиционирование. $90k за младшую систему выходит сильно дороже традиционного решения на 100-150 пользователей даже на железе от Tier 1, а если брать SM/Intel/Quanta от местных сборщиков, то становится совсем грустно.
Но спасибо за честный ответ про позиционирование. $90k за младшую систему выходит сильно дороже традиционного решения на 100-150 пользователей даже на железе от Tier 1, а если брать SM/Intel/Quanta от местных сборщиков, то становится совсем грустно.
У нас есть 1050 серия до 200 пользователей, GPL 100$k.
Для госов и учебных учреждений даем (как и во всем мире) совсем хорошие цены.
Ничего грустно не становится, уж пардон ;)
Как я понимаю, на сайт сходить так и появилось желания? Там же все есть.
Cкоро будет мельче железка за совсем смешные деньги (на 10-20 пользователей), я уже выше упоминал.
Но да, на SMB не ориентировны особо.
Для госов и учебных учреждений даем (как и во всем мире) совсем хорошие цены.
Ничего грустно не становится, уж пардон ;)
Как я понимаю, на сайт сходить так и появилось желания? Там же все есть.
Cкоро будет мельче железка за совсем смешные деньги (на 10-20 пользователей), я уже выше упоминал.
Но да, на SMB не ориентировны особо.
На фоне отдельных вариантов воплощения дедупликации (да что там далеко ходить, даже вот — habrahabr.ru/company/hostkey/blog/179151/ ) хочется спросить, как с надежностью и производительностью у рассматриваемого в посте решения?
Установка ИБП выше оборудования это моветон.
Немного оффтоп, но, так как это последний пост в блоге компании, то поздравляю оную с получением статуса сертифицированного поставщика облачных услуг Red Hat!
Спасибо! Вот тут немного деталей об этом — habrahabr.ru/company/croc/blog/215021/
Sign up to leave a comment.
Приглашаю на тест-драйв коробки за 28 миллионов рублей – СХД EMC XtremIO