
Миграция базы данных 1С с MS SQL на PostgreSQL – по-прежнему насущная тема, особенно в контексте импортозамещения. На наших вебинарах и в беседах с клиентами мы получаем много вопросов по нюансам миграции. Решили собрать основные рекомендации в одну статью.
1. С чего начать подготовку к миграции?
Первая задача – это тюнинг параметров потребляемой памяти в Postgres.
Postgres активно взаимодействует с ОС и если не находит в своем кеше требуемой страницы, то обращается к кешу операционной системы. Поэтому параметр shared_buffers выставляется от 25 до 50% от общего объема памяти. Shared_buffers не должен равняться общему объему памяти, выделенному на сервер (~= ¼ от общего объема памяти, но не более 50%).
Параметр work_mem отвечает за объем памяти для операций сортировки и хеш-таблицы. Этот параметр индивидуален для каждой сессии, поэтому его не надо сильно увеличивать. Тестируйте свое решение в диапазоне от 32 до 128 Мб.
Если запросу не хватает текущего объема, work_mem обратится к временным таблицам, и здесь включится в игру следующий параметр – temp_buffers. Он отвечает за количество буферов для временных таблиц. По дефолту его значение составляет 8 Мб. Здесь тоже советуем его изменить и поставить от 128 до 256 Мб, в зависимости от конфигурации.

В современных ОС используется страничный способ организации виртуальной памяти. По умолчанию размер страницы составляет 4 Кб. Чем больше у вас памяти, тем больше накладных расходов потребуется на обработку ее объема.
Каждая страница памяти сопоставлена с таблицей в адресном пространстве, которое преобразует виртуальную адресацию в физическую. C увеличением размера страницы, мы сокращаем ее. Соответственно, если таблица умещается в буфер ассоциативной памяти, то ускорение и увеличение производительности нагруженных систем с точки зрения памяти будет ощутимо. ОС трансформирует физическую трансляцию в виртуальную и кеш – в TLB.

Параметр Huge pages позволяет заметно сократить потребление общей памяти Postgres, его фоновых процессов и повысить производительность. По умолчанию параметр составляет 4 Кб, как размер страницы в ОС. Для процессов с большими объемами мы рекомендуем выставить его значение не менее 2 Мб. Но жесткой рекомендации нет: надо тестировать в своей системе.
Настроив эти параметры, запускаем Postgres и вычисляем, сколько памяти мы готовы ему отдать.
Как проверить поддержку huge_pages в Postgres:
[root@pg01 ~]# sudo su - postgres
[postgres@pg01 ~]$
[postgres@pg01 ~]$ psql
psql (14.1)
Введите "help", чтобы получить справку.
postgres=# show huge_pages;
huge_pages
------------
try
(1 строка)Как вычислить необходимый размер памяти:
[root@pg01 ~]# head -1 /var/lib/pgsql/14/data/postmaster.pid
1854
[root@pg01 ~]# grep ^VmPeak /proc/1854/status
VmPeak: 17480728 kB
[root@pg01 ~]# echo $((17480728 / 2048 + 1))
8536
[root@pg01 ~]# echo 'vm.nr_hugepages = 8536' >> /etc/sysctl.d/00-postgresql.conf
[root@pg01 ~]# sysctl -p --system2. Что нужно учесть при настройке ОС?
PostgreSQL, как и большинство приложений, зависит от параметров операционной системы. Для СУБД это особенно критично: производительность может ощутимо снизиться при некорректной настройке параметров.
Ключевыми являются следующие настройки:
1.
vm.swappines:
sysctl -w vm.swappines=2 Так регулируется процент памяти, при котором система начинает использовать swap-файл – область на диске, которая может быть использована системой как очень медленная оперативная память.
2.
vm.overcommit_memory / vm.overcommit_ratio
sysctl -w vm.overcommit_memory=2 Убираем перевыделение памяти по умолчанию: в значении vm.overcommit_memory=0 происходит эвристический анализ для определения выделяемой процессу памяти. Это дополнительная трата ресурсов, а острая нехватка памяти и большая конкуренция запустит процесс OOM Killer, при этом вы получите сообщения: “Out of Memory: Killed process 12345 (postgres)”.
Избежать этого поможет контроль перевыделения. Рекомендуем установить значение vm.overcommit_memory=2. Имейте в виду, что после установки этого параметра большую роль начнет играть значение vm.overcommit_ratio (число будет определять процент памяти, доступный для перевыделения, например, 50 для 4 Гб = 6 Гб) и наличие SWAP-файла. Для vm.overcommit_ratio универсальных значений нет: его обычно вычисляют исходя из доступной памяти и объема SWAP: overcommit_ratio < (RAM - swap) / RAM * 100.
3. Как повысить производительность PostgreSQL?
1С не делит данные на “горячие” и “холодные” (архивные) и все содержит в одной базе. Со временем объем данных увеличивается до многомиллионных значений. И небольшое изменение в процентном соотношении с общим объемом данных приводит к тому, что воркеры “не заходят” в эти таблицы и не пересчитывают статистику. А иметь правильную статистику очень важно, так как она используется оптимизатором при построении запроса.
Для ускорения и улучшения производительности стоит настроить процесс автовакуума.
Параметр autovacuum_max_workers отвечает за количество воркеров. Его можно определить по простой формуле: общее кол-во ядер делите пополам (~ кол-во vCPU / 2). Можно варьировать, но формула рабочая.
Само по себе увеличение количества воркеров не даст нам кратное увеличение производительности, поскольку на поведение воркеров влияют еще такие характеристики, как Autovacuum_vacuum_scale_factor и autovacuum_analyze_scale_factor. Они отвечают за пороги, при которых автовакуум будет заходить в таблицы/индексы, очищать и пересчитывать статистику.
Значения по умолчанию для scale_factor равны 0,2 (20%). Чем больше объем данных, тем больше влияют эти 10–20% на то, как будут заходить воркеры в таблицы и индексы: в многомиллиардных таблицах небольшие изменения будут незаметны для воркеров автовакуума. Поэтому рекомендуем уменьшить значения, выставленные по умолчанию, например:
5% – для autovacuum_vacuum_scale_factor;
10% – для autovacuum_analyze_scale_factor.
Таким образом мы повлияем на два важных фактора: у нас будет происходить очистка, и воркеры будут знать, что произошли изменения данных и надо обновить статистику.
Но важно помнить, что все же эти настройки индивидуальны.
Autovacuum_vacuum_cost_limit следит за суммарным порогом стоимости всех воркеров автовакуума. Если увеличиваете количество воркеров автовакуума, увеличивайте значение autovacuum_vacuum_cost_limit примерно во столько же раз.
4. Реально ли сделать перенос, если мало опыта в 1С?
Существует два способа миграции стандартными средствами 1С. У каждого есть свои плюсы и минусы.
Миграция при помощи планов обмена. Этот способ дает возможность гибкой настройки, например: отфильтровывать данные, которые вы не хотите переносить, или переключаться на новую СУБД постепенно. Однако это трудозатратно, вы не сможете обойтись без квалифицированного программиста 1С.
Выгрузка-загрузка дампа базы в .dt-файл.
Более простой метод миграции:
- вам не потребуется разработчик 1С;
- но нужна пауза в работе на время переноса базы

Соответственно, если опыта мало, мы рекомендуем второй способ. Ниже разберем его подробнее.
5. Можно ли сотрудникам продолжать работу во время миграции?
Во время выгрузки база должна быть открыта в монопольном режиме. Работа пользователей или фоновые задания будут мешать процессу и завершат выгрузку дампа ошибкой. При многопоточной загрузке дампа в Postgres конфликт блокировок также даст ошибку загрузки. Подробно об этом можно прочитать здесь.
НО! Эти ограничения можно обойти при помощи штатной консольной утилиты ibcmd, которая создана для автономного управления сервером. Утилита существует как для Windows, так и для Linux, работает с СУБД напрямую, что значительно ускоряет процесс выгрузки и загрузки дампов. Дамп можно выгружать даже при работающих пользователях. Поэтому утилиту также используют для создания тестовых копий базы или для какой-нибудь отладки.
При использовании утилиты для миграции лучше отключать базу от сервера приложений, чтобы сохранить консистентность данных. Утилита устанавливается в папку \bin вместе c сервером 1С:Предприятие.
Подробные инструкции для ibcmd мы повторять не будем, их можно прочитать в этом руководстве.
6. Расскажите про миграцию БД по шагам
В нашем случае мы говорим про версию 1С:Предприятие 8.3.18.1334. Это важный момент, поскольку следующие версии имеют другой синтаксис.
Для начала вам понадобятся:
Установленный сервер 1С:Предприятие 8.3.18.1334. Службу сервера запускать не нужно, нам нужна только утилита. Чем ближе к утилите вы расположите СУБД, тем быстрее будет происходить выгрузка и загрузка.
Учетная запись к базе на сервере MS SQL.
Учетная запись к серверу Postgres c правами SuperUser.
Шаг 1. Отключаем базу от сервера приложения, чтобы исключить изменения в базе во время выгрузки дампа.
Для этого удаляем регистрацию базы на кластере 1С. Важно: удаляем только запись на кластере, саму базу оставляем на месте.
Альтернативным решением можно запретить на стороне СУБД подключение к базе пользователя, под которым сервер приложения цепляется к базе.
Шаг 2. Переходим непосредственно к выгрузке базы в dt.
Запускаем ibcmd в режиме infobase и указываем:
тип СУБД – в нашем случае это MS SQL;
сетевое имя сервера и IP-адрес;
имя базы на SQL;
логин и пароль на SQL;
команду для выгрузки dump;
путь, куда будет выгружаться база.
Все вместе:
Ibcmd.exe infobase --dbms=MSSQLServer --db-Server=ИмяСервераSQL --db-name=ИмяБазыНаSQL --db-user=ПользовательSQL --db-pwd=ПарольSQL dump \\ПапкаДляВыгрузки\ИмяФайла.dt

Шаг 3. Теперь загружаем.
Создаем базу на сервере Postgres и загружаем в нее дамп. Запускаем ibcmd в режиме infobase create. Указываем:
тип СУБД – теперь это PostgreSQL;
сетевое имя сервера;
имя базы – как она будет называться на сервере;
логин, пароль;
команду create-database, которая создает СУБД, если ее нет;
команду restore – указывает на файл дампа, который надо развернуть.
Ibcmd infobase create --dbms=PostgreSQL --db-server=ИмяСервераPostgres --db-name=ИмяБазыНаPostgres --db-user=ПользовательPostgres --db-pwd=ПарольPostgres --create-database --restore=\\ПапкаДляВыгрузки\ИмяФайла.dt

Шаг 4. По окончании загрузки регистрируем на кластере 1С развернутую базу.
Базу можно зарегистрировать под старым именем, чтобы не переписывать список клиентов.
Теперь можно считать нашу базу смигрированной.
7. А можно этот процесс упаковать в скрипт?
Поскольку утилита ibcmd является консольной, все шаги выгрузки и загрузки дампа можно собрать в один скрипт. Ниже на скриншоте вы видите работу такого скрипта для загрузки базы 30 Гб.

Если вы используете для управления сервером 1С Remote admin server, то шаги с удалением и регистрацией базы на кластере можно также упаковать в скрипт.
8. Как сравнить производительность MS SQL и PostgreSQL после миграции?
На слайде ниже показана конфигурация нашего стенда: RDP, кластер 1С из двух нод и сервер СУБД. Сервер MS SQL и PostgreSQL имеют одинаковые характеристики.

Для сравнения использовали два теста.
1. Синтетический многопоточный тест производительности Fragster. Он создает множество фоновых сеансов и выполняет с их помощью операции с различными объектами базы.
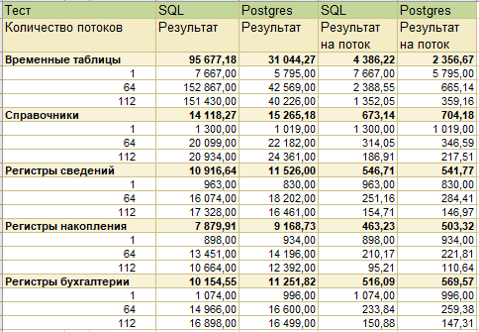
Как видно из результатов, PostgreSQL проигрывает в работе с временными таблицами, однако показывает лучшую производительность при работе с объектами, что суммарно дает одинаковую производительность с MS SQL.
2. Тест по методике APDEX – симулирует работу пользователей 1С:Бухгалтерия типовой конфигурации. Здесь мы запускали одновременно 70 клиентов в тестовой базе, и каждый клиент проводил 500 операций, выбираемых из списка рандомно.

9. Какие инструменты администрирования в PostgreSQL аналогичны инструментам MS SQL?
Резервное копирование. Аналогом встроенного средства MS SQL в Postgres является pg_basebackup + WAL archiving или pg_probackup. Централизованные решения РК, например, Commvault или Veeam B&R, поддерживают как MS SQL, так и Postgres. Из OpenSource решений используется Bareos.
Репликация. В Postgres также есть встроенные средства. Для управления отказоустойчивостью можно использовать Patroni. Он позволит управлять кластером, добавлять новые реплики, производить автоматические контролируемые и аварийные переключения.
Мониторинг. Здесь ничего не меняется: для алертинга и сбора также продолжаем использовать Zabbix, Nagios, Prometheus, VictoriaMetrics.
Анализ. Используются встроенные средства, такие как log_statements и System View, и дополнительно можно использовать расширение pg_profile.

10. А как обстоят дела с HA? Раньше мы использовали MS SQL AlwaysOn
В PostgreSQL есть встроенная поддержка потоковой репликации. Архитектура этого процесса схожа с реализацией в MS SQL. В обеих СУБД репликация использует журналы транзакций, которые накатываются отдельными фоновыми процессами. В случае с Postgres для этого используются WAL sender, отправляющий изменения на реплику, и процесс WAL receiver, получающий данные.
Ключевым отличием от технологии AlwaysON в MS SQL является встроенная поддержка виртуального адреса (VIP) – listener в терминологии MS SQL AlwaysON. Она дает возможность “бегать” за главной репликой и тем самым позволяет клиентским приложениям быть подключенными к одному IP-адресу. В MS SQL это реализовано благодаря тесной интеграции со встроенной в Windows Server реализацией Failover Clustering (WSFC) – ставится как отдельный feature. Именно WSFC управляет сетевым стеком в данном случае и отвечает за переключение реплики с одного узла кластера на другой.
В случае Postgres VIP реализуется сторонними инструментами и решениями, например, pacemaker. Он, как и в случае с WSFC в Windows Server, управляет VIP и контролирует его по некоторым базовым метрикам.
Кроме того, упомянутый ранее Patroni также облегчает управление отказоустойчивым решением.
11. Как изменятся механизмы бэкапа и репликации после переезда с MS SQL на PostgreSQL?
Особенности резервного копирования и восстановления для PostgreSQL продиктованы его архитектурой. Что важно понимать?
Есть несколько вариантов реализации РК:
дамп базы;
бэкап кластера (в терминологии MS SQL - бэкап инстанса).
Дамп не позволяет восстановиться к конкретному времени, поэтому для бизнес-систем, с точки зрения RTO/RPO, не применим.
Встроенные средства Postgres позволяют создавать полный бэкап и бэкап WAL. Таким образом, восстановиться можно на заданную точку (Point-in-time-Recovery – PITR). Дифференциальные копии отсутствуют.
В Postgres выполняется бэкап всей директории с данными. Нет возможности указать конкретную базу для бэкапа. Это же касается и папки с WAL-файлами: она одна на весь кластер/инстанс. Таким образом, процедура и восстановление выполняется для всей инсталляции целиком.
12. Стоит разносить WAL и файлы базы на отдельные дисковые группы, если они на SSD?
Все зависит от многих факторов, например:
это локальные диски на сервере или выделенная СХД, на которой запущены другие ресурсоемкие процессы;
какая нагрузка ожидается в части Read/Write? Возможно, речь идет о постоянном чтении, при котором использование WAL минимально, и будет нелогичным выделение отдельного дискового пула для WAL.
Мы поделились ответами лишь на самые основные вопросы, возникающие при подготовке к переносу 1С на PostgreSQL. Если у вас есть другие вопросы или проблемы, обращайтесь! Расскажем-покажем, чем сможем – поможем. Удачи!
