Отдел микросервисов Netflix обратился ко мне за помощью с загадочной проблемой. Они заявили, что у них на сервере файловая система ZFS потребляет 30% CPU. Я рассказывал об этом на конференции Kernel Recipes 2017 — да, это старая история… но её стоит рассказать ещё раз.
Постановка задачи
Этот микросервис предназначен для сбора метрик. Недавно ребята обновились на новый образ ОС (BaseAMI) — и после этого заявили, что ZFS начала потреблять более 30% ресурса CPU. Первым делом я подумал, что они ошиблись: я лично разрабатывал системные компоненты ZFS в компании Sun Microsystems — и файловая система ну никак не могла настолько загружать процессор.
Однако в своей карьере я неоднократно сталкивался с неожиданными проблемами производительности. Поэтому решил всё-таки лично проверить их инстансы. Хотелось разобраться, какой процесс на самом деле нагружает CPU.
Мониторинг
Для начала я запустил инструмент облачного мониторинга Atlas, чтобы посмотреть показатели CPU в целом, включая разбивку процессорного времени в процентах на работу системы ('sys') и пользовательскую нагрузку ('usr').
К своему удивлению я обнаружил, что 38% процессорного времени действительно приходится на
sys. Это очень необычно для облачных рабочих нагрузок Netflix — и вроде бы подтверждает заявление парней, что ZFS съедает CPU… но как такое возможно? Наверняка тут ошибка — и процессор нагружает некий другой процесс в ядре, а не ZFS.Дальнейшие действия
Для более глубокого анализа я обычно подключаюсь к инстансам по SSH, так можно запустить
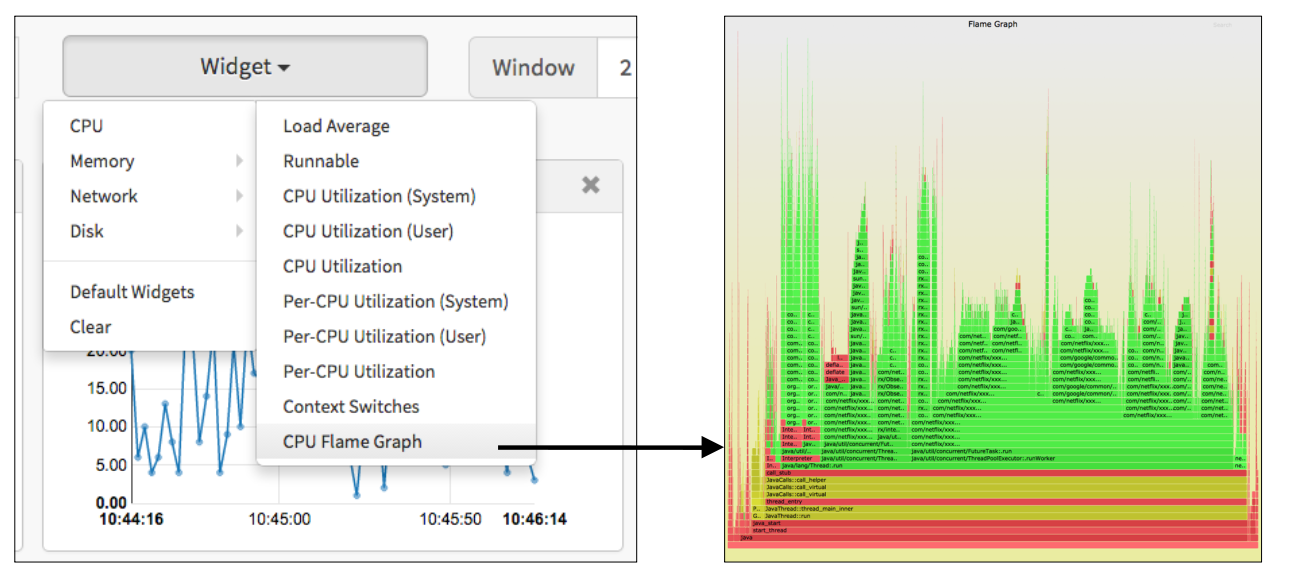
mpstat(1) и ещё раз посмотреть разбивку usr/sys, а также perf(1) для первоначального профилирования и проверки, какие конкретно пути кода нагружают ядра CPU. Однако у Netflix есть очень удобные инструменты для построения flame-графики прямо из облачного UI (раньше это был Vector, теперь FlameCommander). Так что я сразу перешёл к делу. Для наглядности на КДПВ показан пользовательский интерфейс Vector и типичный flame-график для облачной нагрузки.Обратите внимание, что в этом образце преобладает Java (показана зелёным). Вот увеличенный фрагмент:
Flame-график
Посмотрим график нагрузки на CPU одного из проблемных инстансов:

Сразу бросаются в глаза системные процессы. Это две оранжевые башни слева и справа. Жёлтый — это C++, а красный — прочий код пользовательского уровня.
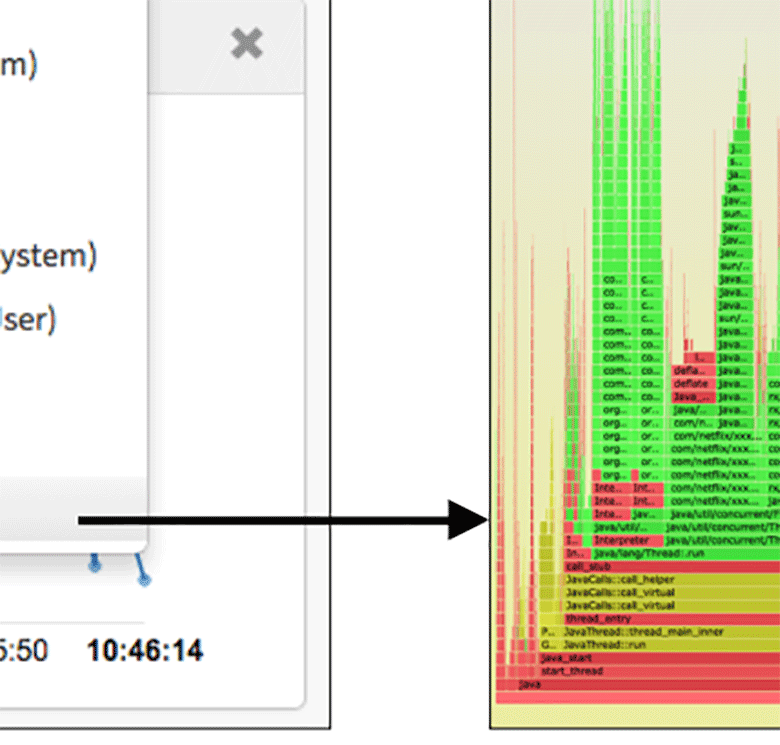
Итак, посмотрим поближе на левую башню с нагрузкой от ядра:

Да это же поток
arc_reclaim_thread! С этим кодом я колупался ещё в Sun. Так что здесь действительно ZFS, они правы!Adapative Replacement Cache (ARC) в ZFS — это основной кэш памяти для файловой системы. Поток
arc_reclaim_thread выполняет операцию arc_adjust() для удаления памяти из кэша, чтобы тот не слишком разрастался и чтобы освободить память для приложений. Процесс выполняется по расписанию или по вызову, в условиях нехватки памяти. Вообще-то я помню, что поток arc_reclaim_thread действительно может нагружать CPU в определённых условиях: если в файловой системе используется крошечный размер записи (например, 512 байт), что создаёт миллионы маленьких буферов. Но это по сути некорректная конфигурация ZFS. Размер записи по умолчанию составляет 128 КБ, и ни при каких условиях не следует указывать размер меньше 8 КБ.Правая башня нагрузки от ядра показывает
spl_kmem_cache_reap_now(), ещё одну функцию освобождения памяти ZFS. Предполагаю, что она связана с левой башней (например, борьба за одни и те же блокировки).Но главный вопрос: почему вообще используется ZFS?
Конфигурация
Насколько я знаю, до сих пор ZFS использовалась только однажды: инновационную файловую систему поставили для контейнеров в новом инфраструктурном проекте. Это навело меня на мысль: если они быстро меняют контейнеры, то есть вероятность, что так же быстро меняются файловые системы ZFS, а это может означать, что многие старые страницы нужно вычищать из кэша. Теперь всё понятно.
Я выложил ребятам свою теорию, уверенный, что нахожусь на правильном пути. Но они ответили: «Мы не используем контейнеры». Хорошо, тогда как вы используете ZFS? Я не ожидал такого ответа:
— Мы не используем ZFS.
Что!? Конечно используете. Я же вижу поток
arc_reclaim_thread на flame-графике. Он не запускается просто так! Он может появиться на CPU только по одной причине: когда нужно удалить страницы памяти из кэша ARC. Если вы не используете ZFS, то в ARC не будет никаких страниц, поэтому нечего очищать, и этот процесс просто не запустится.Но они были уверены, что вообще не используют ZFS. В таком случае график невозможно логично объяснить. Я должен был выяснить, каким образом всё-таки запускается ZFS, и показать им это.
cd и ls
Для ответов на все вопросы достаточно команд
cd и ls(1). Первая обращается к файловой системе, а вторая показывает, что там находится. Имена файлов во многом объяснят, почему запускается эта файловая система.Сначала посмотрим, где смонтированы системы ZFS:
df -h
mount
zfs listНо результат нулевой! В данный момент не смонтировано ни одной файловой системы ZFS. Я попробовал другой инстанс — то же самое. Что за ерунда?
А, ну да, контейнеры же могли создать раньше, а затем уничтожить. Поэтому сейчас не осталось тех файловых систем. Как же доказать, что использовалась ZFS?
arcstats
Точно, мне помогут
arcstats! Счётчики работают на уровне ядра и отслеживают статистику ZFS, включая попадания и промахи кэша ARC. Посмотрим на них:# cat /proc/spl/kstat/zfs/arcstats name type data hits 4 0 misses 4 0 demand_data_hits 4 0 demand_data_misses 4 0 demand_metadata_hits 4 0 demand_metadata_misses 4 0 prefetch_data_hits 4 0 prefetch_data_misses 4 0 prefetch_metadata_hits 4 0 prefetch_metadata_misses 4 0 mru_hits 4 0 mru_ghost_hits 4 0 mfu_hits 4 0 mfu_ghost_hits 4 0 deleted 4 0 mutex_miss 4 0 evict_skip 4 0 evict_not_enough 4 0 evict_l2_cached 4 0 evict_l2_eligible 4 0 [...]
Невероятно! Все счётчики по нулям! ZFS действительно не использовалась, вообще ни разу! Но в то же время она съедала более 30% вычислительных ресурсов! Как???
Клиент, который впервые заметил проблему, оказался прав. ZFS прямо-таки пожирала процессор, причём без всякой причины.
Как файловая система, которая вообще не используется, может потреблять 38% CPU? Я такого никогда не видел… Загадка.
8. Анализ кода
Я внимательнее посмотрел график, а именно задействованные пути кода. И обратил внимание, что они ведут к
get_random_bytes() и extract_entropy(). Это что-то новенькое, я такого не писал. Посмотрев исходный код и историю изменений, всё стало понятно.В кэше ARC хранятся списки буферов для различных типов памяти. В какой-то момент для оптимизации производительности в код добавили функцию
multilist, которая разделяла списки ARC по разным CPU, чтобы убрать конфликты блокировок на многопроцессорных системах. Вроде хорошее дело — это должно повысить производительность. Но что происходит, когда вы очищаете кэш? Вам нужно выбрать один из этих списков. Какой именно? Можно брать их по очереди, но разработчик решил, что лучше выбрать наугад.Криптографически безопасный рандом.
Самое интересное заключалось в том, что ZFS даже не использовалась. ARC замечал низкий уровень системной памяти, соответствующим образом пытался изменить размер списка, фиксировал, что список нулевого размера — значит, ничего не нужно делать. Но это происходило после случайного выбора списка нулевого размера с помощью генератора случайных чисел, который сильно нагружал CPU.
В 2017 году я зафиксировал проблему в тикете #6531. Полагаю, что первым делом они внесли изменения в код
arc_reclaim_thread, чтобы процесс не занимался выбором списка, когда ZFS не используется, а завершал работу. С тех пор код ARC изменяли многократно, и я больше не слышал об этой проблеме.
