Технологии искусственного интеллекта (ИИ) и машинного обучения (МО) уже начинают трансформировать бизнес практически во всех направлениях. Лидерами в этой трансформации являются сферы здравоохранения, финансовых услуг и автомобильной промышленности. Однако примеры удачного применения ИИ, повышающего ценность, появляются в самых разных областях — от розничной торговли до энергетики, от коммунальных услуг до промышленного производства, причем это касается и любых промежуточных сфер.
Искусственный интеллект, машинное обучение и глубокое обучение
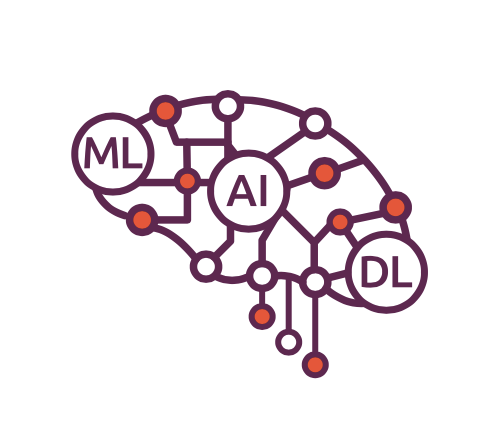
Термины "искусственный интеллект", "машинное обучение" и "глубокое обучение" часто используют как взаимозаменяемые, но они имеют разные значения. Искусственный интеллект — это собирательное понятие о машинах, которые могут имитировать человеческий интеллект и поведение. Машинное обучение — это процесс, применяемый для реализации искусственного интеллекта. Этот процесс включает в себя разработку алгоритмов, которые могут обучаться на основе предоставляемых данных и со временем повышают свою точность и эффективность. Глубокое обучение — это раздел машинного обучения, который пытается имитировать работу мозга. При глубоком обучении используются слои искусственных нейронных сетей, которые создают логическую структуру по аналогии с работой человеческого мозга.
Потенциал ИИ для бизнеса растет с каждым днем, особенно на фоне расширения возможностей технологии от прогнозирования и анализа до принятия по-настоящему независимых решений, открывающих невиданный ранее уровень анализа и понимания, знаний и инноваций. Пионеры в этой области уже ощутили огромные выгоды программ ИИ, которые повышают финансовую эффективность, безопасность, снижают отток клиентов, раскрывают факты мошенничества, повышают посещаемость веб-сайтов, вовлекают людей, помогают удержать сотрудников, внедряют робототехнику, и многое другое. По оценкам компании Gartner к 2022 году технология искусственного интеллекта принесет бизнесу около 3,9 трлн долларов. Мы стремительно приближаемся к тому моменту, когда компании, которые не инвестируют в ИИ, рискуют отстать от конкурентов.
В этом документе мы рассмотрим три фундаментальных этапа для запуска успешной и жизнеспособной программы искусственного интеллекта. На каждом этапе нужно ответить на ключевые вопросы:
1. Создание бизнес-модели для ИИ

Иногда этот этап называют "мысленно начать с конца". На этом этапе нужно ответить на три ключевых вопроса: какую проблему вы пытаетесь решить? Есть ли у вас реалистичные ожидания? Есть ли у вас необходимые данные?
2. Оценка вашей готовности к ИИ
Определив бизнес-модель, необходимо понять, готовы ли вы к внедрению ИИ. Здесь важно ответить на следующие вопросы: Есть ли наработки для быстрого выявления пробелов в готовности? Какие ключевые факторы следует учитывать? Есть ли скрытые пробелы в готовности? Каких распространенных типичных ошибок следует избегать? Как удостовериться, что у вашего бизнеса есть необходимая инфраструктура и опыт для успешного внедрения?
3. Создание вашей персональной программы ИИ

Ответы на эти вопросы дадут исходные данные для разработки вашей программы искусственного интеллекта. В условиях ограниченного времени и бюджета бизнес-модель и выявленные пробелы в готовности к ИИ помогают сосредоточиться и установить приоритеты работы. Важнейшие вопросы: Как вы собираетесь внедрять ИИ? Вы определили пробелы и верный порядок, в котором их нужно закрыть? Какие пробелы можно игнорировать и как долго? У вас есть планы по быстрому достижению ценности на начальном этапе? Что еще нужно сделать для эффективного планирования и управления программой ИИ?
Действуя согласно этапам, описанным в этом документе, вы сможете составить план для внедрения ИИ в вашу организацию. Эта проверенная методология создана в ходе ряда семинаров, тренингов и проектов по внедрению компанией Canonical и нашими партнерами. Она включает в себя лучшие практики и руководства по внедрению, и позволяет создать структурированную программу, с помощью которой ваша организация сможет реализовать свои амбиции в области искусственного интеллекта быстрым, надежным и экономически обоснованным путем.
Создание бизнес-модели для ИИ

ИИ быстро набирает популярность, но организациям не следует внедрять у себя ИИ, только чтобы оставаться в тренде. Крайне важно иметь четкий набор целей и придерживаться их на протяжении всего проекта. Прежде чем погрузиться в ИИ, разработайте технико-экономическое обоснование вашего проекта ИИ. Потенциал ИИ увлекает, и эти технологии можно применить в самых разных областях вашей компании. Однако с точки зрения экономической целесообразности и сроков не все проекты подходят для ИИ.
Далее приведены ключевые вопросы, на которые необходимо дать ответы, рассматривая ваши первые проекты ИИ для бизнеса.
Есть ли у вас реалистичные ожидания?
Технологии искусственного интеллекта и машинного обучения могут обеспечить колоссальную экономию затрат и рост доходов, но доход на инвестиции не всегда заметен сразу. ИИ — это ресурсоемкая технология, особенно с точки зрения вычислительных мощностей и хранения данных. Даже несмотря на то, что мощности аппаратного обеспечения постоянно растут, а цены снижаются, первоначальные затраты на внедрение ИИ будут относительно высоки, если ваши задачи предполагают большие массивы данных и длительные серии экспериментов по глубокому обучению. В такой модели рентабельность инвестиций достигается только в долгосрочной перспективе по мере совершенствования и доработки вашего решения, что ставит вас и вашу программу в потенциально неудобное положение.
Потребности в ресурсах, требования к качеству и объему данных —это лишь часть всех неизвестных. Есть еще неизвестные, которые описаны в разделе, посвященном готовности к ИИ. Лучше всего начать с проверки концепции, чтобы раскрыть все текущие неизвестные. Это поможет вам понять условия для внедрения — скорость разработки, области риска, слабые стороны, сложности, связанные с конвейером данных и применимые модели машинного обучения. Полученные знания помогут вам сформировать реалистичные ожидания. Вы узнаете, какие пробелы необходимо закрыть, и это поможет вам сократить время окупаемости инвестиций за счет более четких действий. Далее в этой статье мы рассмотрим, как может выглядеть такая проверка концепции в форме дизайн-спринта.
Может возникнуть соблазн сразу перейти к пилотному проекту. Но сначала нужно определить критерии успеха. Они помогут сформировать ожидания от программы. Соблюдение принципа "мысленно начать с конца", т.е. с критериев, которые будут использоваться для оценки эффективности программы, будет давать результаты на протяжении всего проекта. Сначала это поможет проектной группе и ключевым заинтересованным сторонам (спонсорам проекта) согласовать результаты проекта. В ходе реализации проекта критерии успеха помогут оценить результаты на основных этапах проекта. Критерии успеха должны включать в себя измеримое увеличение ценности проекта для бизнеса, открывая путь для будущих инвестиций в ИИ. Очень важно сформировать эти критерии до запуска пилотного проекта, до того, как группа по реализации увлечется захватывающими, новыми игрушками.
Какую проблему вы пытаетесь решить?

Какую бы бизнес-задачу вы ни пытались решить, убедитесь, что у вас есть стратегия, четко определяющая, почему и для кого вы реализуете проект. Исходя из нашего опыта, обычно решают несколько задач параллельно. Можно выделить три категории проблем: коммерческие, тактические и стратегические.
Коммерческая категория — это коммерческий стимул для решения проблемы с помощью ИИ. Эта область должна быть основным мотиватором для использования ИИ. Она должна гарантировать, что программа имеет прочный фундамент для продолжения инвестиций. Вариантов применения ИИ множество, и вы, скорее всего, имеете в виду конкретные бизнес-приложения. Примеры грамотного использования ИИ можно найти в большинстве секторов — финансовых услугах, розничной торговле, здравоохранении, производстве, робототехнике, энергетике, коммунальном хозяйстве, образовании и органах госуправления. Коммерческий стимул может иметь отраслевой или общий характер для всех секторов, и затрагивать, например, функциональную область. Среди межотраслевых вариантов применения можно отметить информационные системы, безопасность, управление персоналом, маркетинг и продажи, контроль качества и работу с клиентами.
Тактическая категория ориентирована на умение организации выполнять коммерческие задачи. Она касается блокирования и решения вопросов, связанных с успехом проекта. Стандартные вопросы в этой категории: С чего начать? Какие навыки необходимы? Какая инфраструктура нужна? Какие проблемы с данными необходимо решить? Есть ли у нас необходимые данные? Есть ли сторонние данные, которые были бы полезны? Какие модели можно взять в качестве отправных точек? Какие модели можно использовать повторно? Более подробно эта область рассматривается в следующем разделе, посвященном готовности к ИИ.
Если вы не можете ответить на некоторые из этих вопросов, в качестве примера критериев успеха программы попробуйте использовать следующее: определите и обучите 4 человек, которые будут ядром команды ИИ и которые смогут ответить на эти вопросы.
Отвечая на эти вопросы и определяя приоритетность решаемых проблем, используйте принцип "от пика к пику" — решите проблему, связанную с достижением непосредственно видимого пика, прежде чем переходить к следующему пику. Это поможет вам сохранять гибкость при принятии решений. Каждый путь к пику обычно начинается с простого примера "hello world", использующего существующие данные и решения, а затем группа повторяет цикл до тех пор, пока коммерческая проблема не будет решена.
Стратегическая категория относится к структурированию программы ИИ таким образом, который ведет к эффективному циклу успешной разработки модели ИИ и ее интеграции в существующие системы. Стратегия, как правило, включает в себя ряд коммерческих и тактических решений, которые тщательно спланированы и организованы в порядке приоритета, чтобы дополнять друг на друга. Вы можете использовать широко признанную стратегию "ползти, идти, бежать":
Ползти — обеспечить одно преимущество для одного бизнес-приложения, с участием небольшой группы экспертов для устранения рисков и неизвестных.
Идти — обеспечить несколько преимуществ за счет применения знаний в двух бизнес-приложениях с участием той же группы экспертов.
Бежать — определить и обеспечить преимущества в масштабах всего бизнеса, включая получение прибыли и снижение затрат, за счет применения лучших практик в ИИ во всех соответствующих областях с участием группы в расширенном составе.
В разделе программы ИИ ниже представлена полезная модель для построения такой серии проектов.
Есть ли у вас необходимые данные?
Для всех типов машинного обучения требуются данные. Ваши данные станут основой для обучения ваших моделей. Они научатся распознавать паттерны в данных и определять отношения между этими паттернами и результатами, которые вы ищете. Какие данные у вас есть? Нужно ли получать данные из других источников для обучения ваших моделей?
Примеры данных и сценариев использования, когда ваш бизнес может извлечь выгоду:
Продажи и маркетинг — приоритизация лидов, прогнозирование пожизненной ценности, анализ эмоциональной окраски, анализ и прогнозирование поведения, анализ активности клиентов, предотвращение потерь, генерация контента, системы рекомендаций по увеличению активности и доли в кошельке клиента, прогнозирование спроса
Управление персоналом и продуктивность команды — поиск, привлечение и наем идеальных кандидатов, анализ лучших исполнителей и оценка риска ухода, чрезмерные командировочные расходы, выявление сотрудников, повышающих продуктивность команды, управление рисками проекта
Безопасность, отказы и мошенничество — производство и диагностическое обслуживание, предотвращение опасностей и угроз, выявление возникающих угроз, предотвращение мошенничества, общий анализ и прогнозирование отказов, обнаружение и предотвращение отказов
Образование и активность клиентов — индивидуальные учебные планы, автоматизированное и интеллектуальное обслуживание клиентов, уникальное взаимодействие с пользователем на основе истории и группового анализа
Робототехника — машинное зрение и движение, адаптивное мышление, распределенные робототехнические системы и датчики, контроллеры с развитой логикой для автономных подводных аппаратов.
Как бы ни были широки и разнообразны варианты использования машинного обучения, у них есть общие черты — потребность в данных, типы машинного обучения, типы используемых алгоритмов. Важно понимать, какие требования алгоритмы машинного обучения будут предъявлять к вашим данным, в частности, к их полноте и качеству. Исходя из этих требований станет ясно, нужно ли доработать конвейер данных до начала обучения модели.
С точки зрения типов машинного обучения, обычно применяют два типа алгоритмов — контролируемые и неконтролируемые. Также набирает полярность третий тип — обучение с подкреплением.
Контролируемое обучение — имея набор данных, включающий входные переменные и результат, модель может изучить взаимосвязь между входными данными и результатом. На основе таких данных модель может делать классификацию, например, "да" или "нет", или генерировать непрерывные данные, например, прогнозы цен.
Неконтролируемое обучение — мы можем подходить к проблемам, практически не имея представления о результате. Структуру можно получить из данных, по которым результаты группируются и демонстрируют влияние переменных. В качестве примера можно привести анализ нуклеотидной последовательности гена для определения роли гена в развитии рака.
Обучение с подкреплением — модель формируется, обучаясь самостоятельно, методом проб и ошибок. Таким образом достигается баланс между исследованием нового и использованием текущих знаний. Модели могут обучаться с помощью внешних взаимодействий и со временем совершенствоваться. Обучение с подкреплением широко используется в играх, робототехнике и промышленной автоматизации для создания эффективных адаптивных систем управления, механизмов агрегирования текстов и диалоговых агентов, подбора оптимальной тактики лечения в здравоохранении и для онлайн-торговли акциями.
Оценка вашей готовности к ИИ
Для большинства людей машинное обучение является относительно новой отраслью, поэтому навыки, процессы, инструменты, методики и инфраструктура, необходимые для реализации успешной программы ИИ, могут быть незнакомы вашей организации. Обычно организации, которые только начинают работать с ИИ, внедряют и масштабируют программу силами небольшой группы мотивированных людей, как только будет создана бизнес-модель. Это поможет начать процесс обнаружения и уменьшить количество неизвестных.
В этом разделе мы рассмотрим ключевые вопросы готовности к ИИ. Они помогут определить возможные пробелы.
У вас есть собственные специалисты в области искусственного интеллекта?
Для реализации программ ИИ нужны люди, обладающие специализированными знаниями и навыками для создания технологии, которая будет стимулировать автоматизацию, экспериментирование и повышать ценность бизнеса.
Вот простой список специалистов, которые вам понадобятся для начала работы:
Инженеры по обработке данных обеспечивают качество и пригодность ваших данных, а также интегрируют в вашу инфраструктуру ИИ.
Специалисты по обработке и анализу данных и инженеры по машинному обучению анализируют данные, ищут закономерности, разрабатывают модели ИИ, алгоритмы и нейронные сети, которые будут потреблять ваши данные, и извлекать полезную информацию.
DevOps инженеры осуществляют развертывание и управление вашими ИИ-решениями в производственной среде.
Для более продвинутых вариантов ИИ требуются дополнительные специалисты, например: инженеры по инфраструктуре, специалисты по информационно-техническому обслуживанию, специалисты по платформам, специалисты по прикладным областям и, конечно же, менеджеры.
Прежде чем приступать к внедрению ИИ, убедитесь, что команда укомплектована, и у нее нет серьезных пробелов. В опросе Gartner за 2018 год ИТ-директора в качестве главной болевой точки отмечали нехватку собственных специалистов в области ИИ, обладающих необходимыми знаниями. Поэтому не удивляйтесь, если обнаружите пробелы в вашей команде. Хотя в некоторых случаях может быть целесообразно обучить существующих сотрудников выполнять эти функции, часто более практично привлекать внешних экспертов, особенно для первых проектов ИИ. Привлечение внешних экспертов для обучения вашей команды в процессе совместной работы над одним проектом может оказаться лучшей стратегией для запуска вашей программы.
У вас есть аппаратная инфраструктура?

Планирование производительности, от рабочих станций до вычислительных кластеров — это важный элемент любой инициативы в области ИИ. Рабочие станции являются важным компонентом в процессе обнаружения и разработки, и порой, для обучения ваших моделей достаточно только этого. В зависимости от количества экспериментов и объема данных специалист по обработке и анализу данных или инженер по машинному обучению могут выполнять большую часть своей работы локально. В основном эта работа включает в себя обнаружение данных, их анализ, создание прототипов или разработку моделей.
Машинное обучение и, в частности, глубокое обучение предъявляют повышенные требования к вычислительной инфраструктуре. В реальности нужно провести тщательный анализ имеющейся инфраструктуры, чтобы обеспечить необходимый уровень пропускной способности для обоих типов обучения. Основные факторы, которые следует учитывать при планировании объема работ:
Какой объем данных необходимо обрабатывать?
Каковы требования к взаимодействию с базой данных (операции ввода-вывода, пропускная способность сети)?
Сколько моделей нужно обучить?
Насколько сложны модели (слои, вычисления)?
Каковы требования к точности моделей?
Каковы ваши требования к пропускной способности FLOPS?
Будете ли вы использовать стратегии непрерывного обучения?
К счастью, вы можете запустить инициативы по ИИ без детального планирования аппаратных мощностей и инфраструктуры, если готовы перенести часть данных или весь их объем в общедоступные облачные среды. Это снижает барьер для входа на начальном этапе. У общедоступной облачной среды есть и другие преимущества, в частности, гибкая инфраструктура. То есть вы можете использовать только то, что вам нужно и когда вам это нужно, включая графический процессор. С помощью общедоступных облачных сред вы сможете закрыть вопрос планирования производительности, поскольку сервис будет информировать вас о закупках оборудования. Но все же необходимо проработать вопрос объемов данных, чтобы лучше понять, какими будут затраты на облачные сервисы.
Если вы не можете использовать общедоступные облачные среды или считаете, что их стоимость слишком высока, вам придется рассчитать уровень производительности — это довольно трудоемкая задача. Ответив на поставленные выше вопросы, вы сможете удостовериться, что ваше оборудование не создает узкое место в инфраструктуре, которое искусственно ограничивает конвейер обучения. При планировании инфраструктуры часто приходится делать выбор — выделить аппаратную инфраструктуру для ИИ или разделить ее между несколькими типами рабочих нагрузок. Выделенное оборудование для ИИ имеет смысл для обучения в устоявшемся состоянии, когда 100% оборудования используется постоянно. Общее оборудование можно использовать для нескольких типов рабочих нагрузок и смягчать колебания нагрузки и потребностей, сводя к минимуму простой оборудования.
Какой бы вариант вы не выбрали — общедоступное облако, частное облако, общее или выделенное оборудование, вам в любом случае понадобится программное обеспечение для управления инфраструктурой. Объединив Kubernetes и Kubeflow, вы получите мощное решение с открытым исходным кодом для управления аппаратной и программной инфраструктурой. Эта тема будет обсуждаться более подробно в следующем разделе.
У вас есть вас современная программная инфраструктура, которая использует имеющееся оборудование?
Преимущества надежного кластера Kubernetes не ограничиваются ИИ. Миграция других рабочих нагрузок (особенно корпоративных производственных) на Kubernetes позволяет значительно сэкономить, ускорив трансформацию ваших бизнес-приложений.
Вы можете использовать собственное оборудование или оборудование из облачной среды, но машинное обучение в любом масштабе требует эффективного использования базового оборудования. Аппаратные ускорители, к примеру, графические процессоры, стоят дорого и пользователи должны использовать их максимально эффективно. Вам понадобится программное обеспечение, которое эффективно использует доступные аппаратные средства. Кроме того, требуется портативное решение, которое обеспечит вам гибкость при обучении моделей локальными средствами или в облаке, позволяя использовать гибридные и мультиоблачные инфраструктуры. Именно поэтому Kubernetes небезосновательно признан подходящим решением для автоматизации инфраструктуры ИИ. Платформа Kubernetes может эффективно использовать доступные физические ресурсы, разделяя их между пользователями, и одинаково хорошо работает в разных типах инфраструктуры: частной или общедоступной, на bare-metal машине, VMware, OpenStack, AWS, GCP, Azure и т. д.
Kubernetes изначально разработана компанией Google и представляет собой платформу с открытым исходным кодом для управления контейнеризованными рабочими нагрузками, которая автоматизирует развертывание, масштабирование и управление контейнерными приложениями. С помощью Kubernetes пользователи могут развертывать сложные рабочие нагрузки простым и воспроизводимым способом. Помимо поддержки приложений и рабочих нагрузок, Kubernetes отлично справляется с управлением контейнерными задачами, которые доказали свою эффективность в машинном обучении моделей и экспериментах. Kubernetes также обеспечивает надежный фундамент для большинства технологий, используемых в инженерии данных, как показано на диаграмме ассоциации Cloud Native Compute Foundation CNCF). Именно по этим причинам Kubernetes является предпочтительным решением для автоматизации инфраструктуры ИИ.
Если ваша организация планирует развертывание в нескольких облачных средах или гибридное развертывание, предлагается решение Kubernetes для Ubuntu, которое называется Charmed Distribution of Kubernetes (CDK) от Canonical. Оно работает с самыми разными вариантами частной и общедоступной инфраструктуры, а также с самыми разными процессорными архитектурами. CDK — базируется на Kubernetes. Исходный код и двоичные файлы, публикуемые Kubernetes, используются в CDK, таким образом пользователи могут использовать преимущества всех инноваций и не зависеть от конкретного производителя. Помимо того, что CDK базируется на проекте Kubernetes, разработчики платформы внимательно следят за Kubernetes и часто выпускают обновления в течение недели после последнего выпуска базы, чтобы пользователям были доступны все новейшие решения.
Для разработчиков, которые хотят начать работу локально, на ноутбуке или рабочей станции, создано простое решение на одном ядре kubernetes под названием Microk8s, которое устанавливается за считанные секунды с помощью одной команды. Для корпоративных развертываний, в которых участвует целая команда разработчиков, подойдет Charmed Kubernetes.
Сама по себе Kubernetes обеспечивает надежную платформу для контейнерных приложений и задач. Но вам нужно приложение или платформа ИИ, которые можно развернуть на Kubernetes, чтобы обеспечить по настоящему комплексные решения для машинного обучения. Для этого идеально подходит Kubeflow, о которой рассказывается в следующем разделе.
Вы используете современный программный стек, в котором реализованы инновационные решения машинного обучения?
Мир ИИ быстро развивается. В этой сфере постоянно появляются инновации, например, повышающие производительность или демократизирующие ИИ, которые позволяют новичкам создавать мощные решения. Важно разбираться в этих инновациях и использовать те из них, которые наиболее близки вашей команде и проблемной области. Но одного только понимания недостаточно. Как ваша организация может воспользоваться новейшим программным обеспечением и достичь высокого уровня производительности? Как организация может обеспечить безопасное развертывание новых версий программных платформ без ущерба для конвейеров разработки и эксплуатации? Как вы можете использовать несколько версий компонентов в своем наборе технологий?
Некоторые организации используют собственный набор технологий для своих программ ИИ, которые создают и поддерживают специалисты организации. Если один из ключевых специалистов, который управляет такой уникальной и хрупкой технологией уходит из организации, это может поставить бизнес в довольно трудное положение. Переход к развертыванию стандартизированных решений снижает этот риск.
Также при масштабировании возникает несколько логистических проблем: как использовать все оборудование почти на 100% загрузки? Как сравнить эксперименты в масштабе? Как применять и повторно использовать передовые практики в создании и обучении моделей? Есть ли способ сделать так, чтобы все инженеры соблюдали единый рабочий процесс, от обучения до производства (как корпоративные стандарты)?
В этом помогают программные среды и платформы. Для ИИ, в частности, эти задачи решает Kubeflow. Kubeflow — это стандартизированное решение для машинного обучения с нативной поддержкой Kubernetes, которое поставляется с готовыми стеками технологий машинного обучения, и позволяют добавлять свои собственные решения. Kubeflow позволяет легко развертывать ваши фреймворки машинного обучения, библиотеки и инструменты на вашем оборудовании. Среды популярных компонентов отмечают Tensorflow, TFX, JupyterHub, PyTorch, XGBoost, Pachyderm и Seldon, но их гораздо больше. Кроме того, вы можете расширить возможности Kubeflow, добавив свои собственные компоненты. Kubeflow регулярно обновляется, и вы сможете постоянно пользоваться самыми новыми решениям, повышая скорость работы вашей команды по ИИ.
Определение и выполнение рабочего процесса в Kubeflow вызывает интерес у большинства пользователей. Kubeflow помогает применять передовые практики и стандартизировать рабочие процессы машинного обучения с помощью фреймворка с конвейерами. Вы сможете оптимизировать процесс построения, обучения, оценки и развертывания моделей машинного обучения. Вы можете определять этапы рабочего процесса, в том числе обнаружение смещения данных, процессы соответствия и параметры производительности. Конвейеры позволяют определять многократно используемые рабочие процессы, которые помогут продвигать ваши модели от разработки до производства по заранее определенным и важным для вашей организации этапам.
В многооблачном мире ИИ, где организации, практикующие ИИ, используют несколько сред, довольно быстро формируются требования к портативности. Мы считаем, что каждая среда, будь то ноутбук, рабочая станция или вычислительный кластер, имеет свои отличия и должна иметь возможность получать воспроизводимый стек технологий машинного обучения. Под воспроизводимостью подразумевается, что технологический стек машинного обучения может быть развернут в любой среде. Это значит, что разработку и обучение также можно выполнять в любой среде. Без платформ Kubeflow и Kubernetes с хорошей поддержкой, вам придется тратить очень много времени на подключение компонентов вашей экосистемы ИИ и их управление. Более того, для переноса моделей ИИ между средами может потребоваться значительная перестройка архитектуры, затрудняющая переход от разработки к тестированию и производству.
Вам известны распространенные ошибки?

Искусственный интеллект, и машинное обучение в частности, имеют много подводных камней, которых хотелось бы избежать. Рассмотрим некоторые из них. Хотя обсуждение каждой ошибки и поиск решений не входит в задачи данного материала, читатели должны понимать, что из коллективных знаний можно извлечь много полезной информации. Очень полезно опираться на опыт людей, которые уже прошли этот путь и могут помочь вам быстро и легко преодолеть конкретное препятствие.
Типовые ошибки можно классифицировать следующим образом:
Ошибки в данных – источники данных, качество данных, недостающие данные, утечка данных, разделение данных, смещение выборки, конфиденциальность данных и целевое использование
Ошибки в модели – выделение признаков, неверно рассчитанные признаки, выбор алгоритма, объекты с неизвестными свойствами, неспособность исследовать новые методы
Ошибки в оценке – статистические ошибки, корреляция и причинный анализ, пренебрежение отклоняющимися значениями, критерии оценки, чрезмерное обучение
Операционные ошибки – неэффективные KPI, незавершенное тестирование, колебания качества данных, колебания смещения данных
Ошибки в проекте – время на оценку, объем и выбор минимально жизнеспособного продукта (MVP), разнообразный состав команды (систематическая ошибка, вносимая человеком), технические недоработки продуктов собственной разработки
Ошибки в бизнесе – формирование доверия к ИИ, затраты на развертывание и ROI, проверки концепции и пилотные проекты, недостаточное изучение вариантов использования и роста, обнаружение и определение проблем
Этические и систематические ошибки – систематические ошибки в больших наборах данных, в развитии модели, навыки этического мышления, встроенные ценности и допущения
Узнать о них — это первый шаг к тому, чтобы их избежать. Эти сведения должны быть в контрольной карте выполнения проекта и учитываться при управлении проектом. Давайте рассмотрим некоторые типичные ошибки более подробно.
#1 - Какие бывают типичные ошибки с данными?
Качество данных, включая недостающие данные, является одной из наиболее распространенных типичных ошибок в области данных, которые необходимо устранить, прежде чем использовать машинное обучение. Обнаружить пробелы в качестве и содержании позволяет первоначальное исследование данных. Оно же помогает определить масштаб проблемы, стоящей перед командой. Могут потребоваться значительные усилия, чтобы привести данные в соответствие требованиям машинного обучения. В противном случае вы на себе испытаете принцип "мусор на входе — мусор на выходе".
В дополнение к традиционным методам контроля качества данных, которые обычно основываются на пользовательском опыте и процессах с ручным управлением, мы можем использовать машинное обучение и передовые методы, чтобы преодолеть эти проблемы и представить большую ценность для пользователей. Машинное обучение использует вычислительные, а не человеческие ресурсы, чтобы преодолеть ограничения в производительности и получить желаемую точность при установленных ранее бизнес-правилах. Машинное обучение и проверки качества данных на основе правил постоянно контролируют качество, полноту и формат данных. Оценка данных по этим критериям позволяет автоматически исключать ошибки путем предупреждения владельцев данных и конечных пользователей о проблемах.
#2 - Мы можем выявлять, отслеживать и объяснять смещения данных в обученных моделях?
Полностью устранить смещение данных в моделях, которые обучаются и используются для принятия решений очень трудно, а может даже невозможно. Работая с большими массивами данных, вы можете даже не осознавать, что данные слегка смещены по полу, расе, возрасту или иному анализируемому признаку. Если ИИ работает в производственной среде и постоянно делает прогнозы, важно понимать, что модель может не соответствовать реальности. В ходе обучения данные могли немного отличаться от тех, с которыми модель сталкивается в производственной среде. В зависимости от задач модели, проблема может быть не так страшна. Для примера возьмем модели, которые ищут выгодных клиентов или лучших кандидатов для найма. Это очень разные с этической точки зрения сценарии. Ваша команда по ИИ должна понимать серьезность проблем, которые они решают с помощью своих моделей ИИ, и задавать нормативные вопросы, то есть осознавать смещение в данных.
Есть несколько способов, которые помогут контролировать или смягчить влияние этих типичных ошибок. Во-первых, важно подумать о том, как технологии внедряют определенные значения и допущения, которые приводят к смещению данных, и как эти смещения приводят к проблемам с этической стороны. Большинство таких этических проблем не имеют одного правильного ответа, поэтому важно, чтобы команда обучалась фундаментальным навыкам этического мышления и понимала, что ко всему, что проектирует команда ИИ, всегда будут нормативные вопросы. Во-вторых, оцените сами алгоритмы и убедитесь, что их код не приводит к к смещению. В-третьих, найдите способы раскрытия процесса принятия решений — какая модель за них отвечает, какие обучающие данные, какие входные данные. Наконец, найдите способы, с помощью которых ИИ сам по себе может помочь снизить риск смещения данных или алгоритмов.
Создание вашей персональной программы ИИ

Как и в большинстве инженерных разработок, для руководства и управления программой ИИ существует общий набор макро этапов. Полезно определить критерии успеха для каждого этапа и использовать их в качестве ворот для следующего этапа. Так можно гарантировать, что команда сосредоточена на текущей задаче и продолжает оправдывать основные ожидания заинтересованных сторон. Для успеха проекта решающее значение имеют налаженное взаимодействие и четкое понимание критериев прогресса — это характерно для всех гибких методик ведения проектов.
Макро этапы
Выделают следующие макро этапы:
Исследование – начните с широкого, но поверхностного анализа, выделяя самые важные моменты.
Оценка – используйте качественное осмысление для обнаружения артефактов.
Проектирование – в первую очередь найдите решения для областей с наибольшим риском, а затем приступайте к хорошо изученным областям.
Внедрение – прорабатывайте эксплуатационные сценарии согласно плану.
Эксплуатация – обеспечьте подготовку специалистов по надежности и эксплуатации.
Каждый этап может длиться недели или месяцы. Если вы ответили на вопросы в предыдущих разделах, посвященных бизнес-модели и готовности к ИИ, то вы уже приступили к этапам исследования и оценки. На этапах оценки и проектирования должен появиться план по устранению пробелов.
Макро этапы выполняются каскадно, т.е. прежде чем перейти к следующему этапу, нужно полностью завершить предыдущий. Это хорошо работает для небольших проектов — потребуется меньше нескольких человеко-месяцев работы. Для крупных проектов следует придерживаться итеративной, гибкой методологии работы, в которой акцент ставиться на ранней обратной связи и снижении рисков.
Нужно в первую очередь понять полную картину и перейти от идеи к развертыванию в среде эксплуатации, особенно для тех, кто только начинает, и для тех, кто застрял. Именно по этой причине мы рекомендуем провести недельный дизайн-спринт по ИИ, который подробно описан в следующем разделе. Дизайн-спринт даст вам четкое представление о возможностях, и поможет сформировать ожидания по срокам, функционалу и качеству.
Дизайн-спринт по ИИ
В ходе недельного дизайн-спринта вся ваша команда познакомится с современными технологиями и методологиями искусственного интеллекта. Решит реальную бизнес-задачу и добьется ощутимых результатов. Это послужит проверкой концепции ваших решений в области искусственного интеллекта.
Главные результаты этой недели – базовая архитектура для итерационной разработки решений, которая включает в себя непрерывно работающий конвейер интеграции, а также высокоуровневая стратегия, адаптированная к вашей схеме трансформации в ИИ. Обратите внимание, что для проведения такой недели требуется соответствующая аппаратная и программная инфраструктура, на которой можно развернуть стек технологий искусственного интеллекта. Физическая инфраструктура может быть локальной или находится в общедоступном облаке. Также необходим доступ к данным, которые будут использоваться для обучения модели. На этой физической инфраструктуре должен быть создан кластер Kubernetes, имеющий необходимое оборудование для обучения моделей в желаемые сроки.
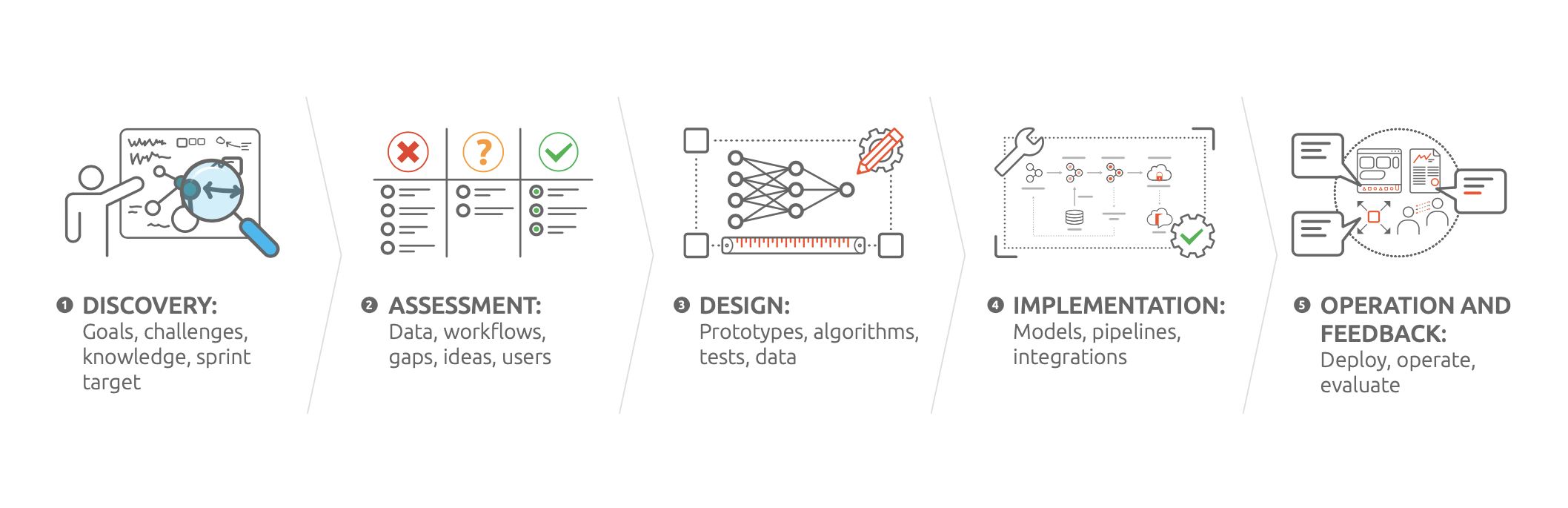
Здесь мы более подробно рассмотрим жизненный цикл первого дизайн-спринта. Конкретные шаги на каждом этапе могут быть скорректированы в соответствии с вашими конкретными потребностями:
День первый. Исследование. После установочной встречи (обсуждается ниже) соберите команду по ИИ для конструктивного разговора, в ходе которого будет разработан план на неделю. Начните с долгосрочной цели, наметьте задачу, попросите экспертов в предметной области поделиться своими знаниями и выберите цель для спринта (цель спринта) — это должна быть амбициозная, но решаемая задача, с которой можно справиться в течение этой недели. Намеченная задача должна учитывать бизнес-требования, ожидаемые результаты, источники данных, сценарии развертывания, потенциальные возможности и риски.

Второй день. Оценка. Эксперты в предметной области должны предоставить первую обратную связь по данным на этапе исследования. Они будут отчитываться о полученных данных и давать рекомендации по решению. Также они обсудят создание стратегической дорожной карты проекта на основе вашей бизнес-модели. На этом этапе необходимо обозначить любые изменения в вашей инфраструктуре.
Третий день. Проектирование. Создание нескольких прототипов решений для достижения цели спринта и определение наиболее подходящего варианта. Инженеры по обработке данных должны подготовить данные. Специалисты по обработке и анализу данных должны обсудить и выбрать соответствующие функции и алгоритмы машинного обучения. Инженеры по машинному обучению должны спроектировать, создать и провести предварительные испытания вашего прототипа нейронной сети. Если позволит время, можно начать итерационный процесс проектирования и обнаружения данных и модели нейросети.
Четвертый день. Внедрение. Завершение процесса проектирования и переход к обучению и тестированию вашей модели ИИ, пока она не достигнет желаемого порога точности. Создание конвейера, обеспечивающего подходящую среду для тестирования модели и получения обратной связи от других участников. Эксперты в предметной области должны давать рекомендации по оценке прогнозов машинного обучения и применению обнаруженных идей на практике.
Пятый день. Эксплуатация и обратная связь. Этот этап может включать разработку пользовательского интерфейса, создание технической документации и обмен практическими знаниями между группами разработки и эксплуатации, чтобы гарантировать, что они могут работать с решением. Важно обсудить варианты развертывания в среде эксплуатации – например, "темный запуск" или интеграция с прототипом бизнес-приложения. На этом этапе необходимо получить обратную связь о базовой архитектуре и модели от ключевых участников проекта.
Для успешной реализации пятидневной, пяти-ступенчатой программы, нужно еще несколько дополнительных "дней":

1. Нулевой день — установочный. На этом этапе собирается необходимая предварительная информация, данные, определяются участники и системы для Первого дня. Также он включает в себя предварительное исследование и оценку с небольшой группой экспертов в предметной области, которые могут определить основные артефакты этой фазы. Эти артефакты служат входными данными для команды в Первый день
2. Шестой день — подведение итогов. По сути это продолжение Пятого дня. Цель шестого дня — проанализировать уроки, полученные в течение недели спринта, и программу искусственного интеллекта. Примерные вопросы: Что мы изучили во время спринта по проектированию ИИ? Как это повлияет на предварительный план, который был создан для программы в ее более широком варианте? Что рекомендуется сделать, и что представить спонсорам проекта? Что сработало хорошо? Что не сработало? Эти уроки служат вводными данными для программы ИИ и способствуют созданию эффективного цикла разработки.
Пора начинать
В этом документе изложена простая, но эффективная стратегия, которая направит вашу инициативу ИИ в нужное русло. Есть три основных шага для начала работы с ИИ. Вот они:
Создание бизнес-модели ИИ.
Оценка вашей готовности к ИИ.
Создание вашей программы ИИ.
Если вы прочли этот документ, прежде чем приступить к работе с ИИ, то разработка бизнес-модели и оценка готовности к ИИ могут стать частью вашей программы ИИ. На каждом вышеописанном шаге есть ключевые вопросы, на которые необходимо ответить, и ожидаемые результаты, определяющие успешность выполнения. Пришло время начать. Вы можете использовать этот чеклист, чтобы направлять усилия:
План
Разработайте основные положения программы, включающие в себя:
- Область применения программы
- Критерии успеха программы
- Бюджет программы
- Сроки спринта и пилотного проекта
Организация:
Создайте небольшую группу для решения следующих задач перед началом:
- Структура планирования и анализа
- Методика управления проектами
- Средства отчетности и ее периодичность
- Назначение других встреч в интересах проекта для вашей организации.
- Предварительное исследование и оценка (готовность к ИИ)
- Оценка экспертных знаний специалистов в области ИИ
- Аппаратная и программная инфраструктура
- Определение имеющихся ресурсов ИИ, оценка потенциальных ошибок
- Оценка необходимости привлечения сторонних экспертов
Выполнение:
Задействуйте основную команду, ключевых участников и достигайте результатов:
- Запланируйте установочную встречу
- Запланируйте дизайн-спринт
- Оцените результаты дизайн-спринта
- Сделайте отчет о результатах и дальнейших действиях
- Запланируйте пилотный проект, чтобы продолжать движение
Приступайте! Иногда это самый трудный шаг. Для начала определите, потребуется ли помощь извне. И если вам нужна помощь, дальше можно не искать.
ИИ С Canonical
Если дизайн-спринт по ИИ кажется вам пугающе сложным или есть пробелы в кадровом составе, которые хотелось бы быстро закрыть, обратитесь к Canonical. Canonical позаботится о подготовке инфраструктуры, а наши партнеры предложат знания специалистов по обработке и анализу данных, а также инженеров по обработке данных, чтобы вы могли начать ваш проект ИИ. Мы поможем пройти пятидневный/пятиступенчатый дизайн-спринт по ИИ с вашим специалистами по аналитике и инфраструктуре. По завершении нашего сотрудничества у вас будет шаблон продуктивных рабочих станций для разработчиков, инфраструктура машинного обучения (в облаке или локально) и приложения ИИ, предоставляющие ежедневные аналитические данные, основанные на ваших данных.
Опыт и требования к инструментарию могут стать не очевидными, но серьезными препятствиями для входа новичков в ИИ. Смена платформы, наем и обучение специалистов — это потенциально длительные и затратные процессы, которые могут увеличивать время окупаемости и негативно повлиять на производительность. Организациям, которые решили пойти по пути "сделай сам", может быть трудно выйти за рамки устоявшейся системы, даже если ее слабые точки хорошо известны.
С помощью нашей структурированной программы мы можем найти подход к любой ситуации и предложить инфраструктуру и возможности именно под ваш бизнес. Опираясь на накопленный передовой опыт мы можем устранить все догадки и ненужные эксперименты в процессе внедрения вашего решения ИИ и быстро привести его к окупаемости, не опустошая ваш бюджет.
Canonical предлагает полный технологический стек для ИИ, начиная с операционной системы (ОС). Ubuntu — это стандартная ОС для Kubernetes, которую используют ведущие компании по всему миру в своих проектах в области ИИ, включая Google, Amazon и IBM. Мы предоставляем дистрибутив Kubernetes на Ubuntu с новейшими контейнерными технологиями на современных ядрах. Именно поэтому так много компаний полагаются на Ubuntu в своих проектов ИИ.

Если вы предпочитаете сосредоточиться на своих основных бизнес-задачах, Canonical предлагает комплексную услугу внешнего управления вашего кластера и инфраструктуры.
Сделайте первый шаг
Теперь вы знаете основы успешной программы ИИ, и все, что вам остается, это сделать решительный шаг и начать свой собственный путь к ИИ. Чем раньше вы начнете, тем скорее ваш бизнес увидит первые плоды.
Сделать первые шаги в ИИ увереннее вам поможет собственный опыт, приобретенный в ходе недельного дизайн-спринта вместе с Canonical и ее партнерами. Вместе с экспертами-консультантами вы изучите варианты применения, выполните первоначальный анализ затрат и рентабельности инвестиций, а также разработаете дорожную карту внедрения ИИ. При этом вы получите практический опыт и реальные выгоды для бизнеса. Чтобы заказать дизайн-спринт, посетите сайт ubuntu.com/ai/consulting.
Дополнительные материалы:
Для более детального изучения области искусственного интеллекта и машинного обучения, включая глубокое погружение в основные концепции, инструменты и примеры использования, ознакомьтесь с некоторыми из вебинаров:
• AI, ML, & Ubuntu: Все, что вам необходимо знать
• Начало работы с DevOps: лучшие практики CICD
• Создание и развертывание вашей первой AI/ML модели на Ubuntu
Присоединяйтесь к Telegram каналу UBUNTU Community, чтобы быть в курсе последних новостей!
