
Проблема stateful-приложений в Kubernetes
Конфигурация, запуск и дальнейшее масштабирование приложений и служб осуществляются просто, если речь идёт о случаях, классифицируемых как stateless, т.е. без сохранения данных. Такие сервисы удобно запускать в Kubernetes, пользуясь его стандартными API, потому что всё происходит «из коробки»: по стандартным конфигурациям, без привлечения какой-либо специфики и магии.
Проще говоря, для запуска в кластере из контейнеров ещё пяти копий бэкенда на PHP/Ruby/Python требуется лишь 5 раз поднять новый сервер и скопировать исходники. Поскольку и исходники, и init-скрипт лежат в образе, масштабирование stateless-приложения становится совсем элементарным. Как хорошо известно любителям контейнеров и микросервисной архитектуры, сложности начинаются для приложений категории stateful, т.е. с сохранением данных, таких как базы данных и кэши (MySQL, PostgreSQL, Redis, ElasticSearch, Cassandra…). Это касается как софта, самостоятельно реализующего кворумный кластер (например, Percona XtraDB и Cassandra), так и софта, требующего отдельных управляющих утилит (такого, как Redis, MySQL, PostgreSQL…).
Сложности возникают по той причине, что исходников и запуска сервиса становится не достаточно — нужно выполнить еще некоторые действия. Как минимум — скопировать данные и/или присоединиться к кластеру. А если точнее, то эти сервисы требуют понимания, как их правильно масштабировать, обновлять и переконфигурировать без потери данных и их временной недоступности. Учёт этих потребностей и называется «эксплуатационными знаниями» (operational knowledge).
Операторы CoreOS
Для того, чтобы «запрограммировать» эксплуатационные знания, в конце прошлого года проект CoreOS представил «новый класс программного обеспечения» для платформы Kubernetes — Операторы (Operators, от англ. «operation», т.е. «эксплуатация»).
Операторы, используя и расширяя базовые возможности Kubernetes (в т.ч. StatefulSets, о разнице с которыми см. ниже), позволяют DevOps-специалистам добавить эксплуатационные знания в код приложений.
Цель Оператора — предоставить пользователю API, который позволяет управлять множеством сущностей stateful-приложения в кластере Kubernetes, не задумываясь о том, что у него под капотом (какие данные и что с ними делать, какие команды необходимо ещё выполнить для поддержания кластера). Фактически Оператор призван максимально упростить работу с приложением в рамках кластера, автоматизируя выполнение эксплуатационных задач, которые раньше приходилось решать вручную.
Как работают Операторы
ReplicaSets в Kubernetes позволяют указывать желаемое количество запущенных подов, а контроллеры следят за тем, чтобы их количество сохранялось (создавая и удаляя поды). Аналогично работает Оператор, который добавляет к стандартному ресурсу и контроллеру Kubernetes набор эксплуатационных знаний, позволяющих выполнять дополнительные действия для поддержания нужного количества сущностей приложения.
Чем это отличается от StatefulSets, предназначенных для приложений, требующих от кластера предоставить им такие stateful-ресурсы, как хранилище данных или статичные IP? Для таких приложений Операторы могут использовать StatefulSets (вместо ReplicaSets) в качестве основы, предлагая дополнительную автоматизацию: выполнять необходимые действия в случае падений, делать бэкапы, обновлять конфигурацию и т.п.
Итак, как же всё это работает? Оператор представляет собой демон-управлятор, который:
- подписывается на событийное API в Kubernetes;
- получает из него данные о системе (о своих ReplicaSets, Pods, Services и т.п.);
- получает данные о Third Party Resources (см. примеры ниже);
- реагирует на появление/изменение Third Party Resources (например, на изменение размера, изменение версии и так далее);
- реагирует на изменение состояние системы (о своих ReplicaSets, Pods, Services и т.п.);
- самое главное:
- обращается к Kubernetes API, чтобы создавать всё необходимое (опять же, свои ReplicaSets, Pods, Services…),
- выполняет некоторую магию (можно, для упрощения, думать, что Оператор заходит в сами поды и вызывает команды, например, для вступления в кластер или для апгрейда формата данных при обновлении версии).
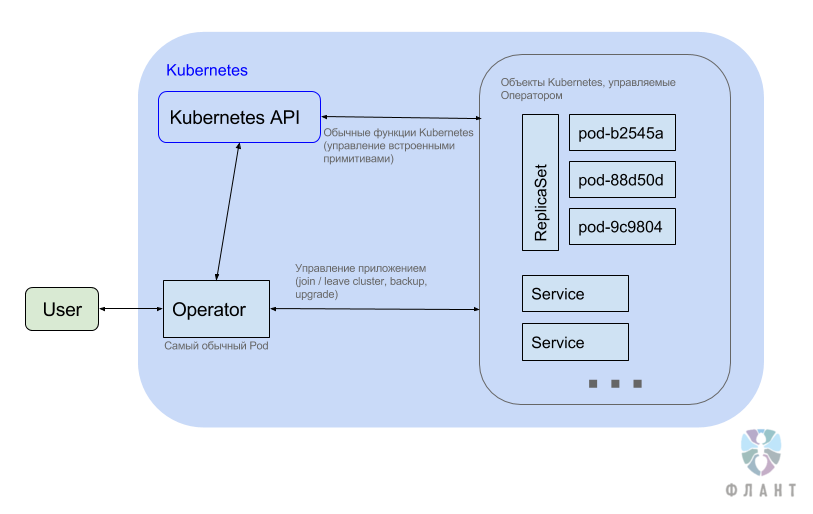
По факту, как видно из картинки, в Kubernetes просто добавляется отдельное приложение (обычный Deployment с ReplicaSet), которое и называется Оператором. Оно живёт в обычном поде (обычно одном-единственном) и, как правило, отвечает только за свой Namespace. Это приложение-оператор реализует свой API — правда, не напрямую, а через Third Party Resources в Kubernetes.
Таким образом, после того, как мы создали в Namespace Оператора, мы можем добавлять в него Third Party Resources.
Пример для etcd (подробности см. ниже):
apiVersion: etcd.coreos.com/v1beta1
kind: Cluster
metadata:
name: example-etcd-cluster
spec:
size: 3
version: 3.1.0
Пример для Elasticsearch:
apiVersion: enterprises.upmc.com/v1
kind: ElasticsearchCluster
metadata:
name: example-es-cluster
spec:
client-node-replicas: 3
master-node-replicas: 2
data-node-replicas: 3
zones:
- us-east-1c
- us-east-1d
- us-east-1e
data-volume-size: 10Gi
java-options: "-Xms1024m -Xmx1024m"
snapshot:
scheduler-enabled: true
bucket-name: elasticsnapshots99
cron-schedule: "@every 2m"
storage:
type: gp2
storage-class-provisioner: kubernetes.io/aws-ebs
Требования, предъявляемые к Операторам
В CoreOS сформулировали основные паттерны, полученные инженерами во время работы над Операторами. Несмотря на то, что все Операторы индивидуальны (создаются под конкретное приложение со своими особенностями и потребностями), их создание должно опираться на своеобразный каркас, предъявляющий следующие требования:
- Установка должна производиться через единственный Deployment: kubectl create -f SOME_OPERATOR_URL/deployment.yaml — и не требовать дополнительных действий.
- При установке Оператора в Kubernetes должен создаваться новый сторонний тип (ThirdPartyResource). Для запуска экземпляров приложений (экземпляров кластеров) и дальнейшего управления ими (обновление версий, изменение размера и др.) пользователь будет использовать этот тип.
- При любой возможности необходимо использовать встроенные в Kubernetes примитивы, такие как Services и ReplicaSets, чтобы задействовать хорошо проверенный и понятный код.
- Необходима обратная совместимость Операторов и поддержка старых версий ресурсов, созданных пользователем.
- При удалении Оператора само приложение должно продолжить функционировать без изменений.
- У пользователей должна быть возможность определять желаемую версию приложения и выполнять оркестровку обновлений версии приложения. Отсутствие обновлений ПО — частый источник проблем эксплуатации и безопасности, поэтому Операторы должны помогать пользователям в этом вопросе.
- Операторы должны тестироваться инструментом типа Chaos Monkey, выявляющим потенциальные сбои в подах, конфигурациях и сети.
etcd Operator
Пример реализации Оператора — etcd Operator, подготовленный ко дню анонса этой концепции. Кластерная конфигурация etcd может быть сложной из-за необходимости поддержания кворума, потребности в переконфигурации членства в кластере, создания бэкапов и т.п. Например, масштабирование кластера etcd вручную означает необходимость создания DNS-имени для нового члена кластера, запуск новой сущности etcd, оповещения кластера о новом члене (etcdctl member add). В случае с Оператором пользователю достаточно будет изменить размер кластера — всё остальное произойдёт автоматически.
И поскольку etcd создали тоже в CoreOS, вполне логичным было увидеть появление его Оператора первым. Как он работает? Логика Оператора etcd определяется тремя составляющими:
- Наблюдение (Observe). Оператор следит за состоянием кластера по Kubernetes API.
- Анализ (Analyze). Находит отличия текущего статуса от желаемого (определённого пользовательской конфигурацией).
- Действие (Act). Устраняет обнаруженные различия с помощью API сервиса etcd и/или Kubernetes.
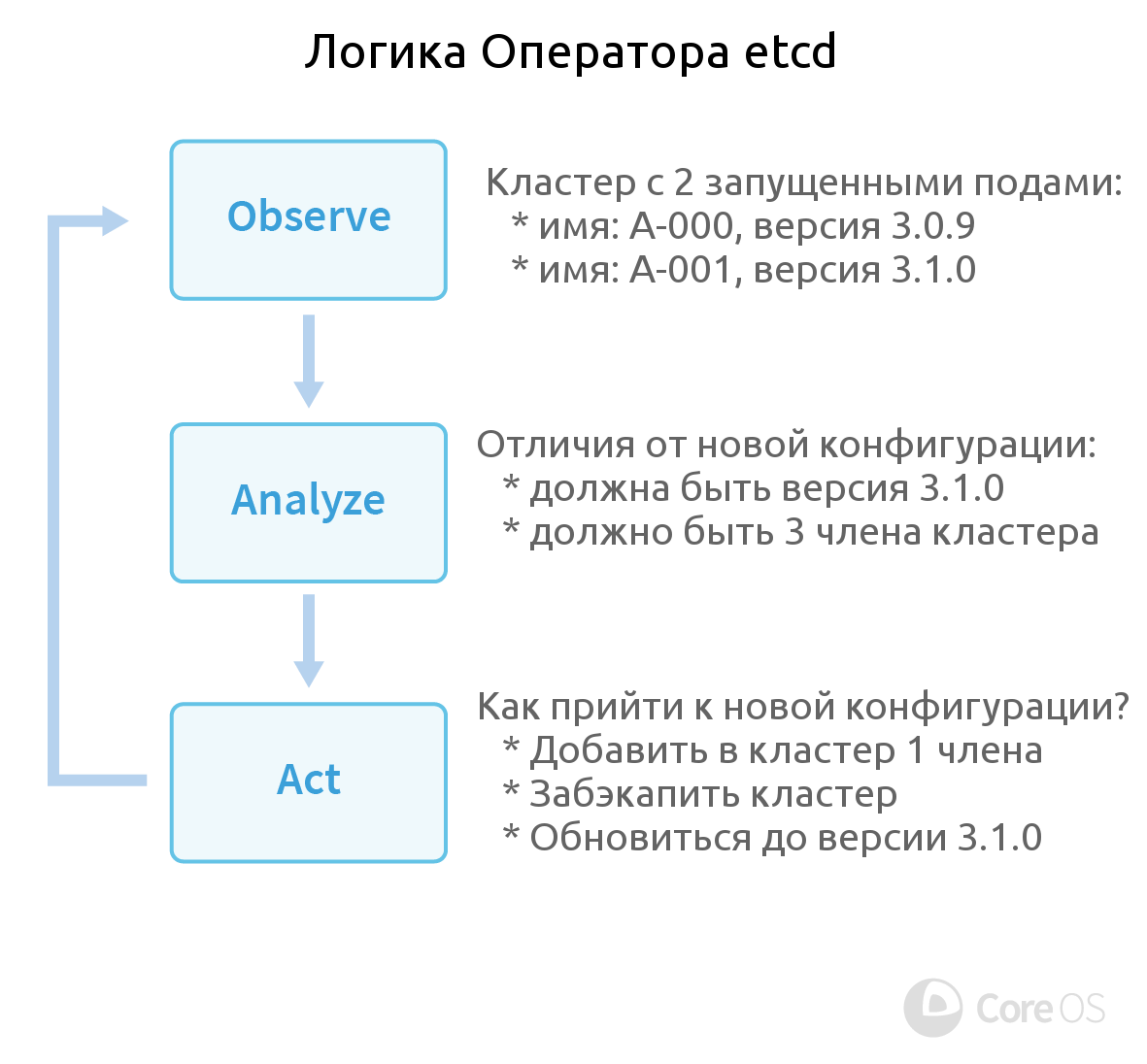
Для реализации этой логики в Операторе подготовлены функции Create/Destroy (создание и удаление членов кластера etcd) и Resize (изменение количества членов кластера). Проверка корректности её работоспособности проверялась с помощью утилиты, созданной по подобию Chaos Monkey от Netflix, т.е. убивающей поды etcd случайным образом.
Для полноценной эксплуатации etcd в Операторе предусмотрены дополнительные возможности: Backup (автоматическое и незаметное для пользователей создание резервных копий — в конфиге достаточно определить, как часто их делать и какое количество хранить, — и последующее восстановление данных из них) и Upgrade (обновление инсталляций etcd без простоя).
Как выглядит работа с Оператором?
$ kubectl create -f https://coreos.com/operators/etcd/latest/deployment.yaml
$ kubectl create -f https://coreos.com/operators/etcd/latest/example-etcd-cluster.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
etcd-cluster-0000 1/1 Running 0 23s
etcd-cluster-0001 1/1 Running 0 16s
etcd-cluster-0002 1/1 Running 0 8s
etcd-cluster-backup-tool-rhygq 1/1 Running 0 18s
Текущий статус etcd Operator — бета-версия, требующая для работы Kubernetes 1.5.3+ и etcd 3.0+. Исходный код и документация (включая инструкцию по применению) доступны на GitHub.
Создан и другой пример реализации от CoreOS — Prometheus Operator, но он пока находится в альфа-версии (не все запланированные функции реализованы).
Статус и перспективы
С момента анонса Операторов Kubernetes прошло 5 месяцев. В официальном репозитории CoreOS по-прежнему доступны лишь две реализации (для etcd и Prometheus). Обе ещё не достигли своих стабильных версий, но коммиты в них наблюдаются ежедневно.
Разработчики ожидают «будущее, в котором пользователи устанавливают Postgres Operators, Cassandra Operators или Redis Operators в своих кластерах Kubernetes и работают с масштабируемыми сущностями этих приложений так же легко, как сегодня это происходит с деплоем реплик stateless-приложений для веба». Первые Операторы от сторонних разработчиков действительно начали появляться:
- Elasticsearch Operator от UPMC Enterprises;
- PostgreSQL Operator от Crunchy Data (анонсирован в конце марта 2017 .);
- Rook Operator от авторов распределённой системы хранения данных на базе Ceph (Rook находится в альфа-статусе);
- Openstack Operators от SAP CCloud.
На крупнейшей европейской конференции по свободному программному обеспечению FOSDEM, что проходила в феврале 2017 года в Брюсселе, Josh Wood из CoreOS анонсировал Операторов в докладе (по ссылке доступно видео!), что должно способствовать росту популярности этой концепции в более широком Open Source-сообществе.
P.S. Спасибо за интерес к статье! Подписывайтесь на наш хаб, чтобы не пропустить новые материалы и рецепты по DevOps и системному администрированию GNU/Linux — мы будем публиковать их регулярно!
