

6 июня на конференции RootConf 2017, проходившей в рамках фестиваля «Российские интернет-технологии» (РИТ++ 2017), в секции «Непрерывное развертывание и деплой» прозвучал доклад «Наш опыт с Kubernetes в небольших проектах». В нём рассказывалось об устройстве, принципах работы и основных возможностях Kubernetes, а также о нашей практике использования этой системы в небольших проектах.
По традиции мы рады представить видео с докладом (около часа, гораздо информативнее статьи) и основную выжимку в текстовом виде.
Предыстория
Современная инфраструктура (для веб-приложений) прошла длинный путь эволюции от бэкенда с СУБД на одном сервере до значительного роста используемых служб, их разнесения по виртуальным машинам/серверам, перехода на облачные решения с балансировкой нагрузки и горизонтальной масштабируемостью… и до микросервисов.
С эксплуатацией современной, микросервисной, инфраструктуры есть ряд сложностей, обусловленных самой архитектурой и количеством её компонентов. Мы выделяем следующие из них:
- сбор логов;
- сбор метрик;
- supervision (проверка состояния сервисов и их перезапуск в случае проблем);
- service discovery (автоматическое обнаружение сервисов);
- автоматизация обновления конфигураций компонентов инфраструктуры (при добавлении/удалении новых сущностей сервисов);
- масштабирование;
- CI/CD (Continuous Integration и Continuous Delivery);
- vendor lock-in (речь про зависимость от выбранного «поставщика решения»: облачного провайдера, bare metal…).
Как легко догадаться из названия доклада, система Kubernetes появилась как ответ на эти потребности.
Основы Kubernetes
Архитектура Kubernetes в целом выглядит как master (может быть не один) и множество узлов (до 5000), на каждом из которых установлены:
- Docker,
- kubelet (управляет Docker),
- kube-proxy (управляет iptables).
На master находятся:
- сервер API,
- база данных etcd,
- планировщик (решает, на каком узле запускать контейнер),
- controller-manager (отвечает за отказоустойчивость).
В дополнение ко всему этому есть управляющая утилита kubectl и конфигурации, описанные в формате YAML (декларативный DSL).

С точки зрения использования Kubernetes предлагает облако, объединяющее в себе всех этих master и узлов и позволяющее запускать «строительные блоки» инфраструктуры. К таким примитивам, в том числе, относятся:
- контейнер — образ + запускаемая в нём команда;
- под (Pod; дословно переводится как «стручок») — совокупность контейнеров (может быть и один) с общей сетью, одним IP-адресом и другими общими характеристиками (общие хранилища данных, лейблы); примечание: именно поды (а не отдельные контейнеры) позволяет запускать Kubernetes;
- лейбл и селектор (Label, Selector) — набор произвольных ключей-значений, назначаемых на поды и другие примитивы Kubernetes;
- ReplicaSet — множество подов, количество которых автоматически поддерживается (при изменении числа подов в конфигурации, при падении каких-либо подов/узлов), что делает масштабирование очень простым;
- деплой (Deployment) — ReplicaSet + история старых версий ReplicaSet + процесс обновления между версиями (используется для решения задач непрерывной интеграции — деплоя);
- сервис (Service) — DNS-имя + виртуальный IP + селектор + балансировщик нагрузки (для разбрасывания запросов по подам, подходящим под селектор);
- задача (Job) — под и логика успешности выполнения пода (используется для миграций);
- cron-задача (CronJob) — Job и расписание в формате crontab;
- том (Volume) — подключение хранилища данных (к поду, ReplicaSet или Deployment) с указанием размера, типа доступа (ReadWrite Once, ReadOnly Many, ReadWrite Many), типа хранилища (поддерживаются 19 способов реализации: железных, программных, облачных);
- StatefulSet — подобное ReplicaSet множество подов, но с жёстко определёнными названиями/хостами, чтобы эти поды могли всегда общаться между собой по ним (для ReplicaSet названия каждый раз генерируются случайным образом) и иметь отдельные тома (не один на всех, как в случае ReplicaSet);
- Ingress — служба, доступная пользователям извне и разбрасывающая все запросы на сервисы по правилам (в зависимости от имени хоста и/или URL'ов).
Примеры описания пода и ReplicaSet в формате YAML:
apiVersion: v1
kind: Pod
metadata:
name: manual-bash
spec:
containers:
- name: bash
image: ubuntu:16.04
command: bash
args: [-c, "while true; do sleep 1; date; done"]apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: backend
spec:
replicas: 3
selector:
matchLabels:
tier: backend
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: fpm
image: myregistry.local/backend:0.15.7
command: php-fpmЭти примитивы отвечают на все обозначенные выше вызовы за небольшими исключениями: в автоматизации обновлений конфигураций не решена проблема сборки Docker-образов, заказа новых серверов и установки узлов на них, а в CI/CD остаётся необходимость проведения подготовительных работ (установка CI, описание правил сборки Docker-образов, выкатывания YAML-конфигураций в Kubernetes).
Наш опыт: архитектура и CI/CD
Под небольшими проектами мы подразумеваем маленькие (до 50 узлов, до 1500 подов) и средние (до 500 узлов, до 15000 подов). Самые маленькие проекты на bare metal мы делаем тремя гипервизорами, которые выглядят так:
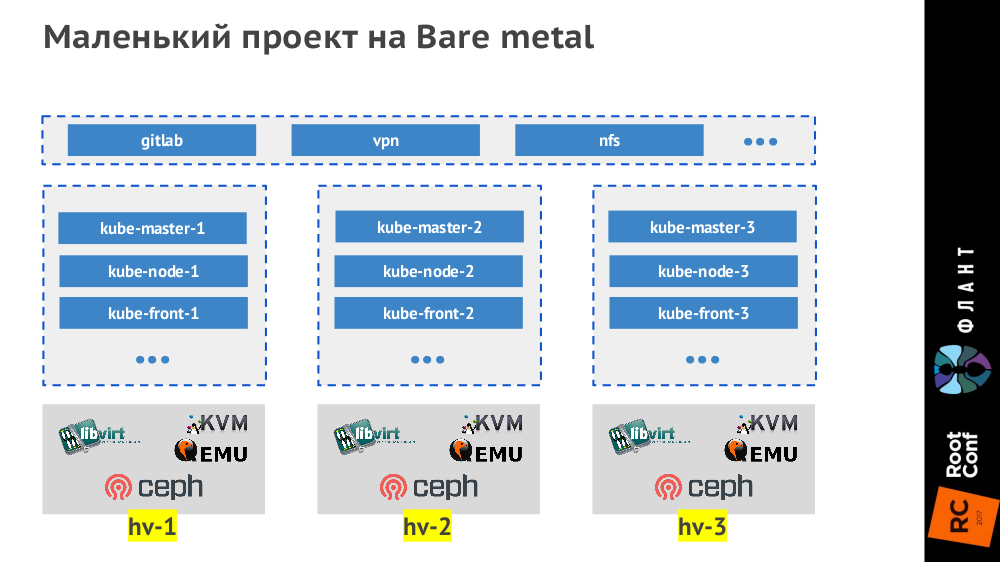
Контроллер Ingress ставится на трёх виртуальных машинах (
kube-front-X):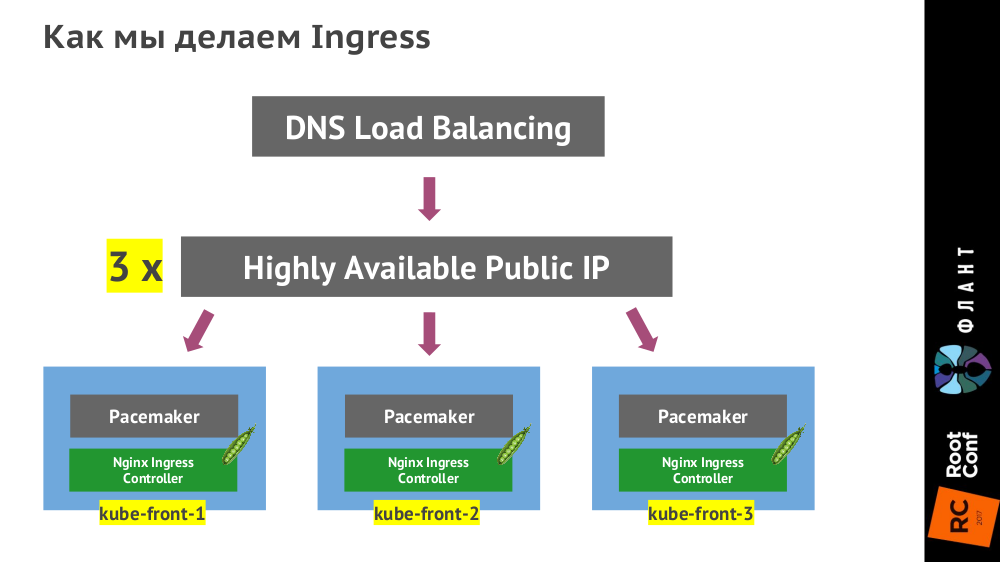
(Вместо указанного на схеме Pacemaker может быть VRRP, ucarp или другая технология — зависит от конкретного ЦОДа.)
Как выглядит цепочка Continuous Delivery:
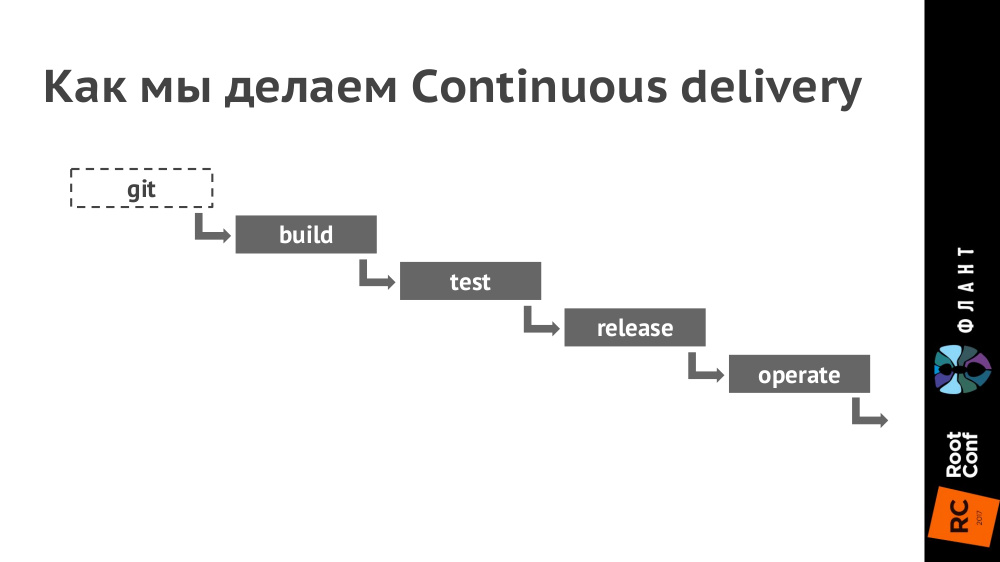
Пояснения:
- Для непрерывной интеграции используем GitLab.
Обновлено 16 августа 2019: См. также наши последующие материалы о практике использования GitLab:
- «GitLab CI для непрерывной интеграции и доставки в production»: часть 1: наш пайплайн и часть 2: преодолевая трудности;
- «Лучшие практики CI/CD с Kubernetes и GitLab (обзор и видео доклада)».
- В Kubernetes настраиваем окружения для каждого контура (production, staging, testing и т.п. — их количество зависит от конкретного проекта). При этом разные контуры могут обслуживаться разными кластерами Kubernetes (на разном железе и в разных облаках), а в GitLab настраивается деплой в них.
- В Git кладём Dockerfile (а точнее, мы используем для этого dapp) и каталог .kube с YAML-конфигурациями.
- При коммите (стадия build) создаём образ Docker, который отправляется в Docker Registry.
- Далее (стадия test) берём этот образ Docker и запускаем на нём тесты.
- При релизе (стадия release) YAML-конфигурации из директории .kube отдаём утилите kubectl, которая отправляет их в Kubernetes, после чего скачиваются Docker-образы и запускаются в инфраструктуре, развёрнутой по конфигурации из YAML. Раньше мы использовали для этого Helm, но сейчас доделываем свой инструмент dapp.
Обновлено 16 августа 2019: В настоящее время проект dapp используется в production и называется werf. - Таким образом, за последнюю стадию (operate) полностью отвечает Kubernetes.

В случае небольших проектов инфраструктура выглядит как контейнерное облако (его реализация вторична — зависит от имеющегося железа и потребностей) с настроенным хранилищем (Ceph, AWS, GCE…) и контроллером Ingress, а также (помимо этого облака) возможно наличие дополнительных виртуальных машин для запуска сервисов, которые мы не ставим внутрь Kubernetes:
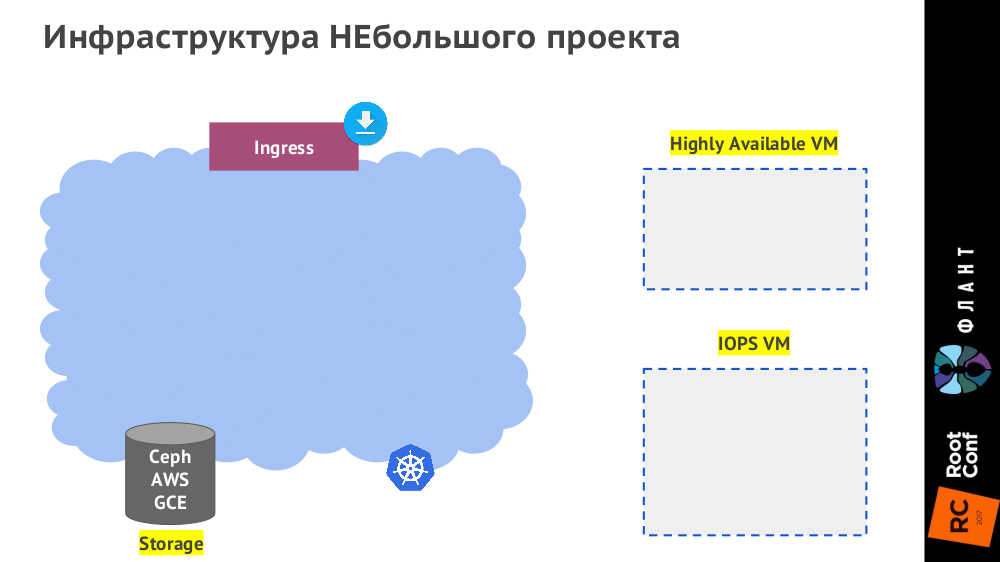
Заключение
С нашей точки зрения Kubernetes дозрел для того, чтобы его использовать в проектах любого размера. Более того, эта система даёт прекрасную возможность с самого начала сделать проект очень просто, надёжно, с отказоустойчивостью и горизонтальным масштабированием. Основной подводный камень — человеческий фактор: для небольшой команды сложно найти специалиста, который решит все нужные задачи (требует широкой технологической эрудиции), или же он будет слишком дорогим (и скоро ему станет скучно).
Видео и слайды
Видео с выступления (около часа) опубликовано в YouTube.
Презентация доклада:
Продолжение
Получив первую обратную связь по этому докладу, мы решили подготовить специальный цикл вводных статей по Kubernetes, ориентированных на разработчиков и более подробно рассказывающих об устройстве этой системы. Начнём уже в ближайшие недели — следите за обновлениями в нашем блоге!
P.S.
Читайте также в нашем блоге про CI/CD и не только:
- «werf — наш инструмент для CI/CD в Kubernetes (обзор и видео доклада)» (Дмитрий Столяров; 27 мая 2019 на DevOpsConf);
- «Базы данных и Kubernetes» (Дмитрий Столяров; 8 ноября 2018 на HighLoad++);
- «Лучшие практики CI/CD с Kubernetes и GitLab» (Дмитрий Столяров; 7 ноября 2017 на HighLoad++);
- «Наш опыт с Kubernetes в небольших проектах» (Дмитрий Столяров; 6 июня 2017 на RootConf);
- «Инфраструктура с Kubernetes как доступная услуга»;
- «Собираем Docker-образы для CI/CD быстро и удобно вместе с dapp» (Дмитрий Столяров; 8 ноября 2016 на HighLoad++);
- «Практики Continuous Delivery с Docker» (Дмитрий Столяров; 31 мая 2016 на RootConf).
