
Типовое условие при реализации CI/CD в Kubernetes: приложение должно уметь перед полной остановкой не принимать новые клиентские запросы, а самое главное — успешно завершать уже существующие.

Соблюдение такого условия позволяет достичь нулевого простоя во время деплоя. Однако, даже при использовании очень популярных связок (вроде NGINX и PHP-FPM) можно столкнуться со сложностями, которые приведут к всплеску ошибок при каждом деплое…
Подробно о жизненном цикле pod’а мы уже публиковали эту статью. В контексте рассматриваемой темы нас интересует следующее: в тот момент, когда pod переходит в состояние Terminating, на него перестают отправляться новые запросы (pod удаляется из списка endpoints для сервиса). Таким образом, для избежания простоя во время деплоя, с нашей стороны достаточно решить проблему корректной остановки приложения.
Также следует помнить, что grace period по умолчанию равен 30 секундам: после этого pod будет терминирован и приложение должно успеть обработать все запросы до этого периода. Примечание: хотя любой запрос, который выполняется более 5-10 секунд, уже является проблемным, и graceful shutdown ему уже не поможет…
Чтобы лучше понять, что происходит, когда pod завершает свою работу, достаточно изучить следующую схему:
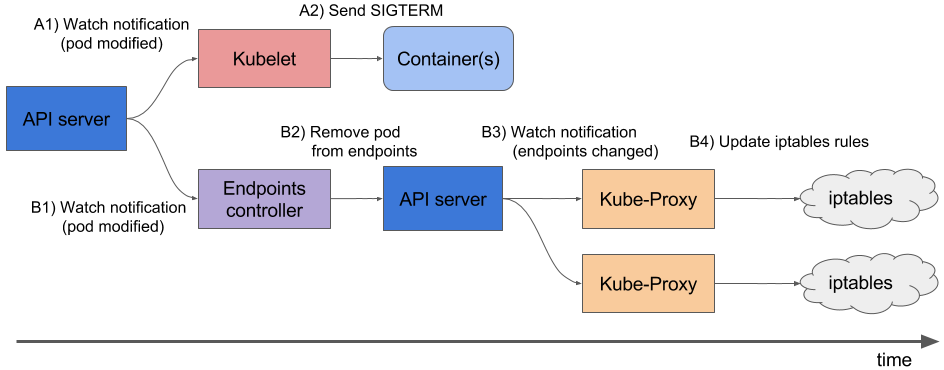
А1, B1 — Получение изменений о состоянии пода
A2 — Отправление SIGTERM
B2 — Удаление pod’а из endpoints
B3 — Получение изменений (изменился список endpoints)
B4 — Обновление правил iptables
Обратите внимание: удаление endpoint pod’а и посылка SIGTERM происходит не последовательно, а параллельно. А из-за того, что Ingress получает обновленный список Endpoints не сразу, в pod будут отправляться новые запросы от клиентов, что вызовет 500 ошибки во время терминации pod’а (более подробный материал по этому вопросу мы переводили). Решать эту проблему нужно следующими способами:
Начнем с NGINX, так как с ним все более-менее очевидно. Погрузившись в теорию, мы узнаем, что у NGINX есть один мастер-процесс и несколько «воркеров» — это дочерние процессы, которые и обрабатывают клиентские запросы. Предусмотрена удобная возможность: с помощью команды
Дальше всё просто: требуется добавить в preStop-хук команду, которая будет посылать сигнал о graceful shutdown. Это можно сделать в Deployment, в блоке контейнера:
Теперь в момент завершения работы pod’а в логах контейнера NGINX мы увидим следующее:
И это будет означать то, что нам нужно: NGINX ожидает завершения выполнения запросов, после чего убивает процесс. Впрочем, ниже ещё будет рассмотрена распространенная проблема, из-за которой даже при наличии команды
А на данном этапе с NGINX закончили: как минимум по логам можно понять, что всё работает так, как надо.
Как обстоят дела с PHP-FPM? Как он обрабатывает graceful shutdown? Давайте разбираться.
В случае с PHP-FPM информации немного меньше. Если ориентироваться на официальный мануал по PHP-FPM, то в нём будет рассказано, что принимаются следующие POSIX-сигналы:
Остальные сигналы в данной задаче не требуются, поэтому их разбор опустим. Для корректного завершения процесса понадобится написать следующий preStop-хук:
На первый взгляд, это всё, что требуется для выполнения graceful shutdown в обоих контейнерах. Тем не менее, задача сложнее, чем кажется. Далее разобраны два случая, в которых graceful shutdown не работал и вызывал кратковременную недоступность проекта во время деплоя.
В первую очередь полезно помнить: помимо выполнения команды
Мы можем наблюдать такую проблему, например, по ответам на нужном нам Ingress’e:

Показатели статус-кодов в момент деплоя
В данном случае мы получаем как раз 503 код ошибки от самого Ingress: он не может обратиться к контейнеру NGINX, так как тот уже недоступен. Если посмотреть в логи контейнера с NGINX, в них — следующее:
После изменения стоп-сигнала контейнер начинает останавливаться корректно: это подтверждается тем, что больше не наблюдается 503 ошибка.
Если вы встретились с похожей проблемой, есть смысл разобраться, какой стоп-сигнал используется в контейнере и как именно выглядит preStop-хук. Вполне возможно, что причина кроется как раз в этом.
Проблема с PHP-FPM описывается тривиально: он не дожидается завершения дочерних процессов, терминирует их, из-за чего возникают 502-е ошибки во время деплоя и других операций. На bugs.php.net с 2005 года есть несколько сообщений об ошибках (например, здесь и здесь), в которых описывается данная проблема. А вот в логах вы, вероятнее всего, ничего не увидите: PHP-FPM объявит о завершении своего процесса без каких-либо ошибок или сторонних уведомлений.
Стоит уточнить, что сама проблема может в меньшей или большей степени зависеть от самого приложения и не проявляться, например, в мониторинге. Если вы все же столкнетесь с ней, то на ум сначала приходит простой workaround: добавить preStop-хук со
Получается, что
Однако, из-за указания 30-секундного
Обратимся к стороне, отвечающей за непосредственное исполнение приложения. В нашем случае это PHP-FPM, который по умолчанию не следит за выполнением своих child-процессов: мастер-процесс терминируется сразу же. Изменить это поведение можно с помощью директивы
С этим знанием вернёмся к нашей последней проблеме. Как уже упоминалось, Kubernetes не является монолитной платформой: на взаимодействие между разными её компонентами требуется некоторое время. Это особенно актуально, когда мы рассматриваем работу Ingress’ов и других смежных компонентов, поскольку из-за такой задержки в момент деплоя легко получить всплеск 500-х ошибок. Например, ошибка может возникать на этапе отправки запроса к upstream’у, но сам «временной лаг» взаимодействия между компонентами довольно короткий — меньше секунды.
Поэтому, в совокупности с уже упомянутой директивой
В таком случае мы компенсируем задержку командой
Вообще говоря, описанное поведение и соответствующий workaround касаются не только PHP-FPM. Схожая ситуация может так или иначе возникать при использовании других ЯП/фреймворков. Если не получается другими способами исправить graceful shutdown — например, переписать код так, чтобы приложение корректно обрабатывало сигналы завершения, — можно применить описанный способ. Пусть он не самый красивый, но работает.
Нагрузочное тестирование — один из способов проверки, как работает контейнер, поскольку эта процедура приближает к реальным боевым условиям, когда на сайт заходят пользователи. Для тестирования приведённых выше рекомендаций можно воспользоваться Яндекс.Танком: он отлично покрывает все наши потребности. Далее приведены советы и рекомендации по проведению тестирования с наглядным — благодаря графикам Grafana и самого Яндекс.Танка — примером из нашего опыта.
Самое главное здесь — проверять изменения поэтапно. После добавления нового исправления запускайте тестирование и смотрите, изменились ли результаты по сравнению с прошлым запуском. В противном случае будет сложно выявить неэффективные решения, а в перспективе можно и вовсе только навредить (например, увеличить время деплоя).
Другой нюанс — смотрите логи контейнера во время его терминации. Фиксируется ли там информация о graceful shutdown? Есть ли в логах ошибки при обращении к другим ресурсам (например, к соседнему контейнеру PHP-FPM)? Ошибки самого приложения (как в описанном выше случае с NGINX)? Надеюсь, что вводная информация из этой статьи поможет лучше разобраться, что же происходит с контейнером во время его терминирования.
Итак, первый запуск тестирования происходил без

На информационной панели Яндекс.Танка виден всплеск 502 ошибок, который произошел в момент деплоя и продолжался в среднем до 5 секунд. Предположительно это обрывались существующие запросы к старому pod’у, когда он терминировался. После этого появились 503 ошибки, что стало результатом остановленного контейнера NGINX, который также оборвал соединения из-за бэкенда (из-за чего к нему не смог подключиться Ingress).
Посмотрим, как

Во время деплоя 500-х ошибок больше нет! Деплой проходит успешно, graceful shutdown работает.
Однако стоит вспомнить момент с Ingress-контейнерами, небольшой процент ошибок в которых мы можем получать из-за временного лага. Чтобы их избежать, остается добавить конструкцию со
Для корректного завершения процесса мы ожидаем от приложения следующего поведения:
Однако не все приложения умеют так работать. Одним из решений проблемы в реалиях Kubernetes является:
Пример с NGINX позволяет понять, что даже то приложение, которое изначально должно корректно отрабатывает сигналы к завершению, может этого не делать, поэтому критично проверять наличие 500 ошибок во время деплоя приложения. Также это позволяет смотреть на проблему шире и не концентрироваться на отдельном pod’е или контейнере, а смотреть на всю инфраструктуру в целом.
В качестве инструмента для тестирования можно использовать Яндекс.Танк совместно с любой системой мониторинга (в нашем случае для теста брались данные из Grafana с бэкендом в виде Prometheus). Проблемы с graceful shutdown хорошо видны при больших нагрузках, которую может генерировать benchmark, а мониторинг помогает детальнее разобрать ситуацию во время или после теста.
Отвечая на обратную связь по статье: стоит оговориться, что проблемы и пути их решения здесь описываются применительно к NGINX Ingress. Для других случаев есть иные решения, которые, возможно, мы рассмотрим в следующих материалах цикла.
Другое из цикла K8s tips & tricks:
Соблюдение такого условия позволяет достичь нулевого простоя во время деплоя. Однако, даже при использовании очень популярных связок (вроде NGINX и PHP-FPM) можно столкнуться со сложностями, которые приведут к всплеску ошибок при каждом деплое…
Теория. Как живёт pod
Подробно о жизненном цикле pod’а мы уже публиковали эту статью. В контексте рассматриваемой темы нас интересует следующее: в тот момент, когда pod переходит в состояние Terminating, на него перестают отправляться новые запросы (pod удаляется из списка endpoints для сервиса). Таким образом, для избежания простоя во время деплоя, с нашей стороны достаточно решить проблему корректной остановки приложения.
Также следует помнить, что grace period по умолчанию равен 30 секундам: после этого pod будет терминирован и приложение должно успеть обработать все запросы до этого периода. Примечание: хотя любой запрос, который выполняется более 5-10 секунд, уже является проблемным, и graceful shutdown ему уже не поможет…
Чтобы лучше понять, что происходит, когда pod завершает свою работу, достаточно изучить следующую схему:
А1, B1 — Получение изменений о состоянии пода
A2 — Отправление SIGTERM
B2 — Удаление pod’а из endpoints
B3 — Получение изменений (изменился список endpoints)
B4 — Обновление правил iptables
Обратите внимание: удаление endpoint pod’а и посылка SIGTERM происходит не последовательно, а параллельно. А из-за того, что Ingress получает обновленный список Endpoints не сразу, в pod будут отправляться новые запросы от клиентов, что вызовет 500 ошибки во время терминации pod’а (более подробный материал по этому вопросу мы переводили). Решать эту проблему нужно следующими способами:
- Отправлять в заголовках ответа Connection: close (если это касается HTTP-приложения).
- Если нет возможности вносить изменения в код, то далее в статье описано решение, которое позволит обработать запросы до конца graceful period.
Теория. Как NGINX и PHP-FPM завершают свои процессы
NGINX
Начнем с NGINX, так как с ним все более-менее очевидно. Погрузившись в теорию, мы узнаем, что у NGINX есть один мастер-процесс и несколько «воркеров» — это дочерние процессы, которые и обрабатывают клиентские запросы. Предусмотрена удобная возможность: с помощью команды
nginx -s <SIGNAL> завершать процессы либо в режиме fast shutdown, либо в graceful shutdown. Очевидно, что нас интересует именно последний вариант.Дальше всё просто: требуется добавить в preStop-хук команду, которая будет посылать сигнал о graceful shutdown. Это можно сделать в Deployment, в блоке контейнера:
lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quitТеперь в момент завершения работы pod’а в логах контейнера NGINX мы увидим следующее:
2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting downИ это будет означать то, что нам нужно: NGINX ожидает завершения выполнения запросов, после чего убивает процесс. Впрочем, ниже ещё будет рассмотрена распространенная проблема, из-за которой даже при наличии команды
nginx -s quit процесс завершается некорректно. А на данном этапе с NGINX закончили: как минимум по логам можно понять, что всё работает так, как надо.
Как обстоят дела с PHP-FPM? Как он обрабатывает graceful shutdown? Давайте разбираться.
PHP-FPM
В случае с PHP-FPM информации немного меньше. Если ориентироваться на официальный мануал по PHP-FPM, то в нём будет рассказано, что принимаются следующие POSIX-сигналы:
-
SIGINT,SIGTERM— fast shutdown; -
SIGQUIT— graceful shutdown (то, что нам нужно).
Остальные сигналы в данной задаче не требуются, поэтому их разбор опустим. Для корректного завершения процесса понадобится написать следующий preStop-хук:
lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"На первый взгляд, это всё, что требуется для выполнения graceful shutdown в обоих контейнерах. Тем не менее, задача сложнее, чем кажется. Далее разобраны два случая, в которых graceful shutdown не работал и вызывал кратковременную недоступность проекта во время деплоя.
Практика. Возможные проблемы с graceful shutdown
NGINX
В первую очередь полезно помнить: помимо выполнения команды
nginx -s quit есть ещё один этап, на который стоит обратить внимание. Мы сталкивались с проблемой, когда NGINX вместо сигнала SIGQUIT всё равно отправлял SIGTERM, из-за чего запросы не завершались корректно. Похожие случаи можно найти, например, здесь. К сожалению, конкретную причину такого поведения нам установить не удалось: было подозрение на версии NGINX, но оно не подтвердилось. Симптоматика же заключалась в том, что в логах контейнера NGINX наблюдались сообщения «open socket #10 left in connection 5», после чего pod останавливался. Мы можем наблюдать такую проблему, например, по ответам на нужном нам Ingress’e:
Показатели статус-кодов в момент деплоя
В данном случае мы получаем как раз 503 код ошибки от самого Ingress: он не может обратиться к контейнеру NGINX, так как тот уже недоступен. Если посмотреть в логи контейнера с NGINX, в них — следующее:
[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13После изменения стоп-сигнала контейнер начинает останавливаться корректно: это подтверждается тем, что больше не наблюдается 503 ошибка.
Если вы встретились с похожей проблемой, есть смысл разобраться, какой стоп-сигнал используется в контейнере и как именно выглядит preStop-хук. Вполне возможно, что причина кроется как раз в этом.
PHP-FPM… и не только
Проблема с PHP-FPM описывается тривиально: он не дожидается завершения дочерних процессов, терминирует их, из-за чего возникают 502-е ошибки во время деплоя и других операций. На bugs.php.net с 2005 года есть несколько сообщений об ошибках (например, здесь и здесь), в которых описывается данная проблема. А вот в логах вы, вероятнее всего, ничего не увидите: PHP-FPM объявит о завершении своего процесса без каких-либо ошибок или сторонних уведомлений.
Стоит уточнить, что сама проблема может в меньшей или большей степени зависеть от самого приложения и не проявляться, например, в мониторинге. Если вы все же столкнетесь с ней, то на ум сначала приходит простой workaround: добавить preStop-хук со
sleep(30). Он позволит завершить все запросы, которые были до этого (а новые мы не принимаем, так как pod уже в состоянии Terminating), а по истечении 30 секунд сам pod завершится сигналом SIGTERM.Получается, что
lifecycle для контейнера будет выглядеть следующим образом: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"Однако, из-за указания 30-секундного
sleep мы сильно увеличим время деплоя, так как каждый pod будет терминироваться минимум 30 секунд, что плохо. Что с этим можно сделать?Обратимся к стороне, отвечающей за непосредственное исполнение приложения. В нашем случае это PHP-FPM, который по умолчанию не следит за выполнением своих child-процессов: мастер-процесс терминируется сразу же. Изменить это поведение можно с помощью директивы
process_control_timeout, которая указывает временные лимиты для ожидания сигналов от мастера дочерними процессами. Если установить значение в 20 секунд, тем самым покроется большинство запросов, выполняемых в контейнере, и после их завершения мастер-процесс будет остановлен. С этим знанием вернёмся к нашей последней проблеме. Как уже упоминалось, Kubernetes не является монолитной платформой: на взаимодействие между разными её компонентами требуется некоторое время. Это особенно актуально, когда мы рассматриваем работу Ingress’ов и других смежных компонентов, поскольку из-за такой задержки в момент деплоя легко получить всплеск 500-х ошибок. Например, ошибка может возникать на этапе отправки запроса к upstream’у, но сам «временной лаг» взаимодействия между компонентами довольно короткий — меньше секунды.
Поэтому, в совокупности с уже упомянутой директивой
process_control_timeout можно использовать следующую конструкцию для lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]В таком случае мы компенсируем задержку командой
sleep и сильно не увеличиваем время деплоя: ведь заметна разница между 30 секундами и одной?.. По сути «основную работу» на себя берёт именно process_control_timeout, а lifecycle используется лишь в качестве «подстраховки» на случай лага. Вообще говоря, описанное поведение и соответствующий workaround касаются не только PHP-FPM. Схожая ситуация может так или иначе возникать при использовании других ЯП/фреймворков. Если не получается другими способами исправить graceful shutdown — например, переписать код так, чтобы приложение корректно обрабатывало сигналы завершения, — можно применить описанный способ. Пусть он не самый красивый, но работает.
Практика. Нагрузочное тестирование для проверки работы pod’а
Нагрузочное тестирование — один из способов проверки, как работает контейнер, поскольку эта процедура приближает к реальным боевым условиям, когда на сайт заходят пользователи. Для тестирования приведённых выше рекомендаций можно воспользоваться Яндекс.Танком: он отлично покрывает все наши потребности. Далее приведены советы и рекомендации по проведению тестирования с наглядным — благодаря графикам Grafana и самого Яндекс.Танка — примером из нашего опыта.
Самое главное здесь — проверять изменения поэтапно. После добавления нового исправления запускайте тестирование и смотрите, изменились ли результаты по сравнению с прошлым запуском. В противном случае будет сложно выявить неэффективные решения, а в перспективе можно и вовсе только навредить (например, увеличить время деплоя).
Другой нюанс — смотрите логи контейнера во время его терминации. Фиксируется ли там информация о graceful shutdown? Есть ли в логах ошибки при обращении к другим ресурсам (например, к соседнему контейнеру PHP-FPM)? Ошибки самого приложения (как в описанном выше случае с NGINX)? Надеюсь, что вводная информация из этой статьи поможет лучше разобраться, что же происходит с контейнером во время его терминирования.
Итак, первый запуск тестирования происходил без
lifecycle и без дополнительных директив для сервера приложений (process_control_timeout в PHP-FPM). Целью этого теста было выявление приблизительного количества ошибок (и есть ли они вообще). Также из дополнительной информации следует знать, что среднее время деплоя каждого пода составляло около 5-10 секунд до состояния полной готовности. Результаты таковы:На информационной панели Яндекс.Танка виден всплеск 502 ошибок, который произошел в момент деплоя и продолжался в среднем до 5 секунд. Предположительно это обрывались существующие запросы к старому pod’у, когда он терминировался. После этого появились 503 ошибки, что стало результатом остановленного контейнера NGINX, который также оборвал соединения из-за бэкенда (из-за чего к нему не смог подключиться Ingress).
Посмотрим, как
process_control_timeout в PHP-FPM поможет нам дожидаться завершения child-процессов, т.е. исправить такие ошибки. Повторный деплой уже с использованием этой директивы:Во время деплоя 500-х ошибок больше нет! Деплой проходит успешно, graceful shutdown работает.
Однако стоит вспомнить момент с Ingress-контейнерами, небольшой процент ошибок в которых мы можем получать из-за временного лага. Чтобы их избежать, остается добавить конструкцию со
sleep и повторить деплой. Впрочем, в нашем конкретном случае изменений не было видно (ошибок снова нет).Заключение
Для корректного завершения процесса мы ожидаем от приложения следующего поведения:
- Ожидать несколько секунд, после чего перестать принимать новые соединения.
- Дождаться завершения всех запросов и закрыть все keepalive-подключения, которые запросы не выполняют.
- Завершить свой процесс.
Однако не все приложения умеют так работать. Одним из решений проблемы в реалиях Kubernetes является:
- добавление хука pre-stop, который будет ожидать несколько секунд;
- изучение конфигурационного файла нашего бэкенда на предмет соответствующих параметров.
Пример с NGINX позволяет понять, что даже то приложение, которое изначально должно корректно отрабатывает сигналы к завершению, может этого не делать, поэтому критично проверять наличие 500 ошибок во время деплоя приложения. Также это позволяет смотреть на проблему шире и не концентрироваться на отдельном pod’е или контейнере, а смотреть на всю инфраструктуру в целом.
В качестве инструмента для тестирования можно использовать Яндекс.Танк совместно с любой системой мониторинга (в нашем случае для теста брались данные из Grafana с бэкендом в виде Prometheus). Проблемы с graceful shutdown хорошо видны при больших нагрузках, которую может генерировать benchmark, а мониторинг помогает детальнее разобрать ситуацию во время или после теста.
Отвечая на обратную связь по статье: стоит оговориться, что проблемы и пути их решения здесь описываются применительно к NGINX Ingress. Для других случаев есть иные решения, которые, возможно, мы рассмотрим в следующих материалах цикла.
P.S.
Другое из цикла K8s tips & tricks:
