
Прим. перев.: эту статью, в оригинале состоящую из двух частей, написал Kevin Yang — software engineer из компании Lyft, которая хорошо известна в Kubernetes-сообществе как минимум благодаря созданию Envoy. В новом материале автор делится интересным опытом миграции большого числа традиционных cron-задач из Linux на CronJobs в K8s. Можно в деталях узнать о том, к каким проблемам в масштабах Lyft это привело и как они были решены инженерами компании.
Мы в Lyft решили перевести серверную инфраструктуру на Kubernetes — распределенную систему оркестровки контейнеров, — чтобы воспользоваться преимуществами, которые предлагает автоматизация. Хотели получить прочную и надежную платформу, способную стать фундаментом для дальнейшего развития, а также снизить общие затраты, одновременно повысив эффективность.
Распределенные системы могут быть сложны для понимания и анализа, и в этом смысле Kubernetes — не исключение. Несмотря на его многочисленные преимущества, мы выявили несколько проблемных моментов при переходе на CronJob — встроенную в Kubernetes систему для выполнения повторяющихся задач по расписанию. В этом цикле из двух статей мы обсудим технические и эксплуатационные недостатки Kubernetes CronJob при использовании в крупном проекте и поделимся с вами опытом их преодоления.
Сначала будут описаны недостатки Kubernetes CronJobs, с которыми мы столкнулись при их использовании в Lyft. Затем (во второй части) — расскажем, как устранили эти недостатки в стеке Kubernetes, повысили удобство работы и улучшили надежность.
Сегодня в нашей multi-tenant (многопользовательской) production-среде насчитывается почти 500 cron-задач, вызываемых более 1500 раз в час.
Повторяющиеся, запланированные задачи активно используются в Lyft для различных целей. До перехода на Kubernetes они выполнялись прямо на Linux-машинах с помощью обычного cron'а Unix. Команды разработчиков отвечали за написание
В рамках более масштабных усилий по контейнеризации и миграции рабочих нагрузок на собственную платформу Kubernetes мы решили перейти на CronJob*, заменив классический Unix cron на его Kubernetes-аналог. Как и многие другие, выбор Kubernetes был сделан из-за его обширных преимуществ (по крайней мере, в теории), в том числе — для эффективного использования ресурсов.
Представьте себе cron-задачу, которая запускается раз в неделю на 15 минут. В нашей старой среде машина, выделенная под эту задачу, простаивала бы 99,85% времени. В случае же Kubernetes вычислительные ресурсы (CPU, память) используются только во время вызова. В остальное время незадействованные мощности можно использовать для запуска других CronJob'ов, или просто уменьшить (scale-down) кластер. Учитывая прошлый способ запуска cron-задач, мы многое выиграли бы от перехода на модель, в которой job'ы эфемерны.
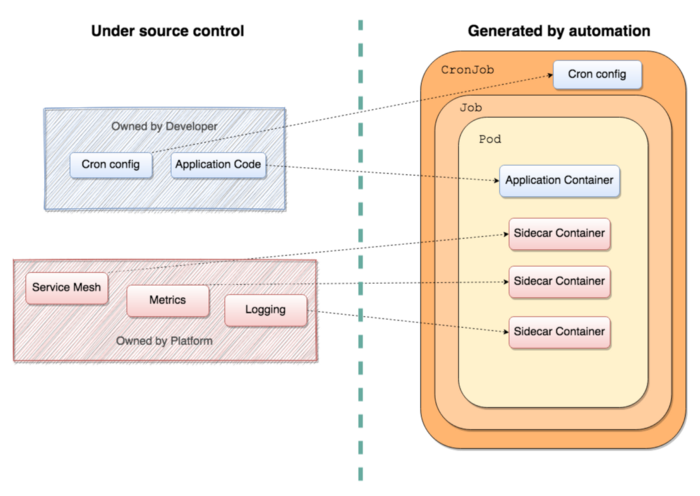
Границы зон ответственности разработчиков и платформенных инженеров в стеке Lyft
После перехода на платформу Kubernetes команды разработчиков перестали заниматься выделением и эксплуатацией собственных вычислительных экземпляров. Теперь за поддержку и эксплуатацию вычислительных ресурсов и runtime-зависимостей в стеке Kubernetes отвечает платформенная команда. Кроме того, она занимается созданием самих CronJob-объектов. Разработчикам остается только настроить расписание задач и код приложения.
Впрочем, все это хорошо выглядит на бумаге. На практике мы выявили несколько проблемных моментов при миграции от хорошо изученной среды традиционных Unix cron'ов к распределенному, эфемерному окружению CronJob'ов в Kubernetes.
* Хотя CronJob имел и по-прежнему имеет (по состоянию на Kubernetes v1.18) бета-статус, мы обнаружили, что на тот момент он вполне удовлетворял нашим потребностям и, кроме того, прекрасно вписывался в остальной инфраструктурный инструментарий Kubernetes, существовавший у нас.
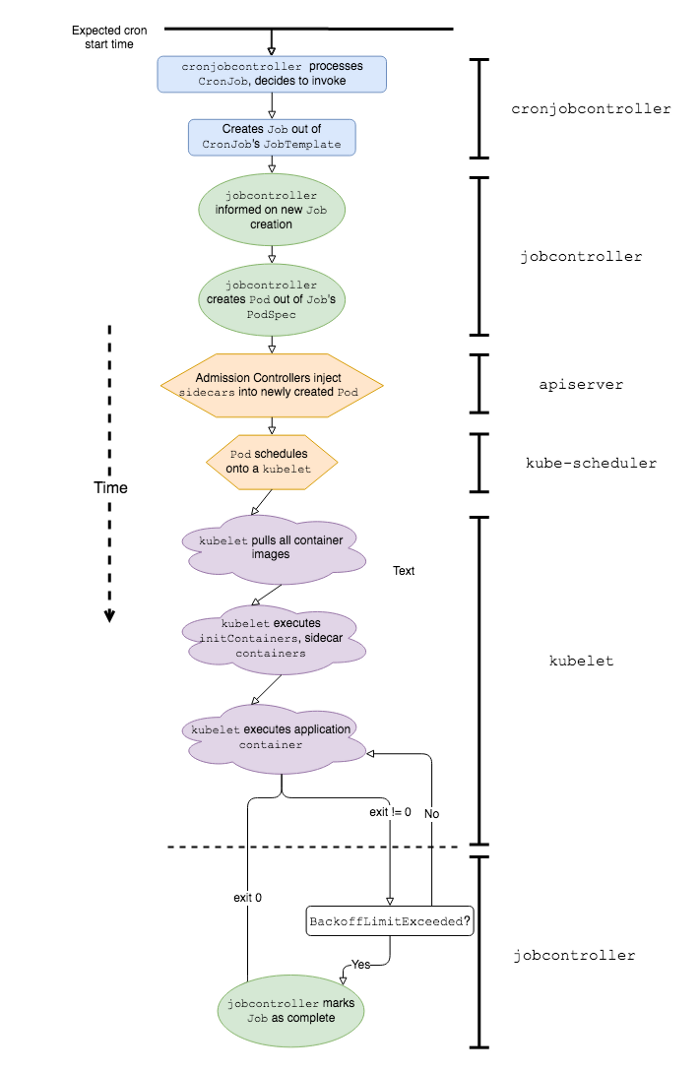
Упрощенная последовательность событий и программных компонентов K8s, участвующих в работе Kubernetes CronJob
Чтобы лучше объяснить, почему работа с CronJob'ами Kubernetes в production-среде связана с определенными трудностями, давайте сначала определим, чем же они отличаются от классических. Предполагается, что CronJob'ы работают так же, как задачи cron в Linux или Unix; однако на самом деле есть как минимум пара серьезных отличий в их поведении: скорость запуска и обработка сбоев.
Задержку запуска (start delay) мы определим как время, прошедшее с запланированного запуска cron'а до момента фактической начала работы кода приложения. Другими словами, если запуск cron'а запланирован на 00:00:00, а приложение начинает выполняться в 00:00:22, то задержка запуска этого конкретного cron'а составит 22 секунды.
В случае классических Unix cron'ов задержка запуска минимальна. Когда подходит время, указанные команды просто выполняются. Давайте подтвердим это на следующем примере:
С такой конфигурацией cron мы, скорее всего, получим следующий результат в
С другой стороны, у CronJob'ов Kubernetes могут быть значительные задержки запуска, поскольку работе приложения предшествует целый ряд событий. Вот некоторые из них:
* Эти этапы уникальны для Kubernetes-стека Lyft.
Мы обнаружили, что самый значительный вклад в задержку вносят пункты 1, 5 и 7, как только мы достигаем определенного масштаба CronJob'ов в Kubernetes-окружении.
Задержка, вызванная работой
Чтобы лучше понять, откуда берется задержка, давайте изучим исходный код встроенного
Реализация
10-секундный цикл опроса и ограничения на число обращений к API со стороны клиента приводят к значительному увеличению задержки запуска CronJob'ов.
Из-за особенностей расписания cron'ов большинство из них запускаются в начале минуты (XX:YY:00). Например,
Кроме того, если вы не выделяете вычислительную мощность с учетом пиковых нагрузок (и/или используете вычислительные экземпляры облачного сервиса), а вместо этого применяете механизм автомасштабирования кластера для динамического масштабирования узлов, то время, затрачиваемое на запуск узлов, вносит дополнительный вклад в задержку запуска pod'ов CronJob.
Как только pod CronJob'а был успешно запланирован в
Таким образом, проволочки при запуске, предшествующие выполнению нужного кода приложения, вкупе с большим количеством CronJob'ов в условиях multi-tenant-среды приводят к заметным и непредсказуемым задержкам запуска. Как мы увидим чуть позже, в реальных условиях подобная задержка может негативно сказаться на поведении CronJob'а, грозя пропуском запусков.
В общем случае рекомендуется следить за работой cron'ов. Для Unix-систем это сделать довольно просто. Unix cron'ы интерпретируют заданную команду с помощью указанной оболочки
В случае Unix cron'а
В случае CronJob'а Kubernetes, где по умолчанию определены повторные попытки при неудачах, а сама неудача может быть вызвана различными причинами (сбой Job'а или сбой контейнера), мониторинг не столь прост и однозначен.
Используя аналогичный скрипт в контейнере приложения и с Job'ами, настроенными на перезапуск при неудаче, CronJob при сбое будет пытаться выполнить задачу, генерируя в процессе метрики и логи, пока не достигнет BackoffLimit (макс. числа повторных попыток). Таким образом, разработчику, пытающемуся установить причину проблемы, придется разбирать много лишнего «мусора». Кроме того, алерт от скрипта-оболочки в ответ на первую неудачу также может оказаться обычным шумом, на котором невозможно базировать дальнейшие действия, поскольку контейнер приложения может восстановиться и успешно завершить задачу сам по себе.
Можно реализовать оповещения на уровне Job'а, а не на уровне контейнера приложения. Для этого доступны метрики API-уровня для сбоев Job'ов, такие как
Существенная задержка старта и циклы повторных запусков вносят дополнительную задержку, которая может помешать повторному выполнению CronJob'ов Kubernetes. В случае часто вызываемых CronJob'ов или тех, у которых время работы значительно превышает время простоя, эта дополнительная задержка может привести к проблемам при следующем запланированном вызове. Если для CronJob'а установлена политика

Пример хронологии (с точки зрения cronjobcontroller'а), в которой startingDeadlineSeconds превышается для конкретного почасового CronJob'а: он пропускает свой запланированный запуск и не будет вызван до следующего запланированного времени
Есть и более неприятный сценарий (с ним мы столкнулись в Lyft), из-за которого CronJob'ы могут полностью пропускать вызовы, — это когда для CronJob'а установлен
Кроме того, если
С тех пор, как мы начали переносить повторяющиеся, календарные задачи в Kubernetes, обнаружилось, что применение механизма CronJob'ов в неизменном виде приводит к возникновению неприятных моментов как с точки зрения разработчиков, так и с точки зрения платформенной команды. К сожалению, они начали сводить на нет преимущества и выгоды, ради которых мы изначально и выбрали Kubernetes CronJob. Вскоре мы поняли, что ни разработчики, ни платформенная команда не имеют в своем распоряжении необходимых инструментов для эксплуатации CronJob'ов и понимания их запутанных жизненных циклов.
Разработчики пытались эксплуатировать свои CronJob'ы и настраивать их, но в результате приходили к нам со множеством жалоб и вопросов вроде этих:
Как платформенная команда, мы были не в состоянии ответить на вопросы вроде:
Отладка сбоев CronJob — нелегкая задача. Часто требуется интуиция, чтобы понять, на каком этапе происходят сбои и где искать улики. Иногда эти улики получить довольно трудно — как, например, логи
Кроме того, иногда Kubernetes просто перестает пытаться выполнить CronJob, если тот пропустил слишком много запусков. В этом случае его приходится перезапускать вручную. В реальных условиях такое случается гораздо чаще, чем можно представить, и необходимость каждый раз исправлять проблему вручную становится довольно болезненной.
На этом я завершаю погружение в технические и эксплуатационные проблемы, с которыми мы столкнулись при использовании Kubernetes CronJob в нагруженном проекте. Во второй части пойдет речь о том, как мы устранили в нашем стеке Kubernetes, повысили удобство работы и улучшили надежность CronJob'ов.
Стало понятно, что CronJob'ы Kubernetes в неизменном виде не смогут стать простой и удобной заменой для их Unix-аналогов. Чтобы уверенно перенести все наши cron'ы в Kubernetes, нам было нужно не только устранить технические недостатки CronJob'ов, но и повысить удобство работы с ними. А именно:
1. Выслушать разработчиков, чтобы понять, ответы на какие вопросы о cron'ах волнуют их больше всего. Например: Запустился ли мой cron? (Был ли выполнен код приложения?) Прошел ли запуск успешно? Какое время заняла работа cron'а? (Как долго выполнялся код приложения?)
2. Упростить обслуживание платформы, сделав CronJob'ы более понятными, их жизненный цикл — более прозрачным, а границы платформы/приложения — более ясными.
3. Дополнить нашу платформу стандартными метриками и оповещениями, чтобы сократить объемы конфигурирования пользовательских оповещений и снизить количество дубликатов скриптов-обвязок для cron’а, которые разработчикам приходится писать и поддерживать.
4. Разработать инструментарий для простого восстановления после сбоев и тестирования новых конфигураций CronJob'ов.
5. Исправить давние технические проблемы в Kubernetes, такие как баг с TooManyMissedStarts, который требует ручного вмешательства для устранения и приводит к тому, что падение в рамках одного важного сценария сбоя (когда значение startingDeadlineSeconds не задано) происходит незаметно.
Все эти проблемы мы решили следующим образом:
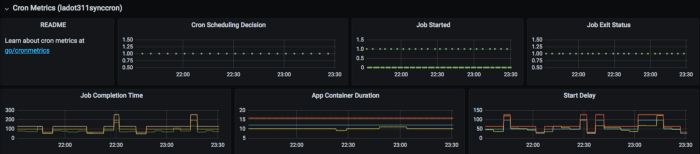
Пример панели, сгенерированной платформой для мониторинга конкретного CronJob'а
Мы дополнили стек Kubernetes следующими метриками (они определены для всех CronJob'ов в Lyft):
1.
2.
3.
4.
5.
На основе этих метрик мы создали оповещения по умолчанию. Они уведомляют разработчиков, когда:
Больше разработчикам не нужно определять собственные оповещения и метрики для cron'ов в Kubernetes — платформа предоставляет их готовые аналоги.
Мы адаптировали
Мы исправили баг с TooManyMissedStarts, так что теперь CronJob'ы не «зависают» после 100 подряд пропущенных стартов. Этот патч не только устраняет необходимость в ручном вмешательстве, но и позволяет реально отслеживать, когда время
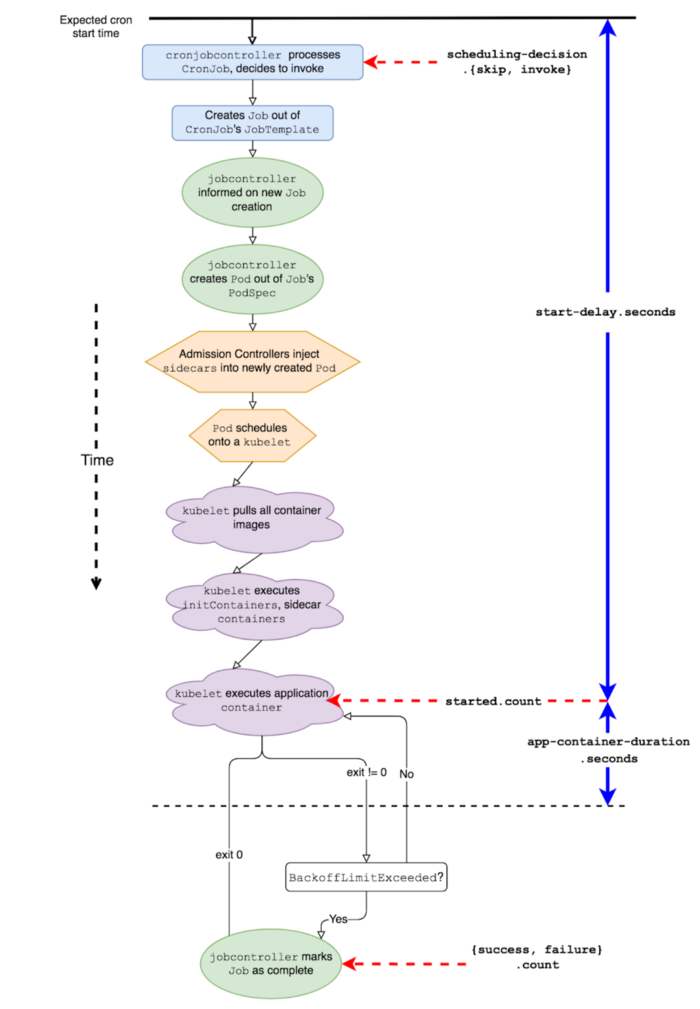
На каких стадиях жизненного цикла CronJob'ов Kubernetes мы добавили механизмы экспорта метрик
Самая хитрая часть реализации оповещений о пропущенных вызовах cron'ов — это обработка их расписаний (для их расшифровки нам очень пригодился crontab.guru). Давайте, например, рассмотрим следующее расписание:
Можно сделать так, чтобы счетчик для этого cron'а увеличивался каждый раз, когда он завершается (или использовать cron-обвязку). Тогда в системе оповещений можно прописать условное выражение вида: «Посмотри на 60 предыдущих минут и сообщи мне, если счетчик увеличится меньше чем на 12». Проблема решена, верно?
Но что, если у вас расписание следующего вида:
В этом случае придется повозиться с условием (хотя, может быть, у вашей системы есть функция оповещения только по рабочим часам?). Как бы то ни было, эти примеры иллюстрируют, что привязывание оповещений к расписаниям cron'ов имеет несколько недостатков:
Один лишь п. 2 делает генерацию оповещений по умолчанию для всех cron'ов на платформе очень сложной задачей, а п. 3 особенно актуален для распределенных платформ вроде Kubernetes CronJob, в которых задержка запуска является весомым фактором. Кроме того, есть решения, использующие «переключатели мертвеца», что опять возвращает нас к необходимости привязывать оповещение к расписанию cron'а, и/или алгоритмы обнаружения аномалий, которые требуют некоторого обучения и не работают сразу для новых CronJob'ов или изменений в их расписании.
Другой способ взглянуть на проблему заключается в том, чтобы спросить себя: что означает, что cron должен был запуститься, но этого не произошло?
В Kubernetes — если на минутку забыть о багах в
Звучит знакомо? Это именно то, чем занимается наша метрика
Это решение «отвязывает» расписание cron'а от самого оповещения, обеспечивая несколько преимуществ:
Это, в сочетании с другими временными рядами и оповещениями, упомянутыми ранее, помогает воссоздать более полную и понятную картину состояния CronJob'ов.
Из-за сложной природы жизненного цикла CronJob'ов нам было необходимо тщательно продумать конкретные точки размещения инструментария в стеке, чтобы измерять эту метрику надежно и точно. В итоге все свелось к фиксации двух моментов времени:
В этом случае
С Т2 все оказалось сложнее. Поскольку нам нужно получить значение, максимально близкое к реальному, Т2 должен совпадать с моментом, когда контейнер с приложением запустится в первый раз. Если снимать Т2 при любом запуске контейнера (включая перезапуски), то задержка запуска в этом случае включит время работы самого приложения. Поэтому мы решили присваивать еще одну
После выката нового функционала и исправления ошибок мы получили множество положительных отзывов от разработчиков. Теперь разработчики, пользующиеся нашей платформой Kubernetes CronJob:
Кроме того, у инженеров по обслуживанию платформы теперь появился новый параметр (start delay) для оценки пользовательского опыта и производительности платформы.
Наконец (пожалуй, это наша самая крупная победа), сделав CronJob'ы (и их состояния) более прозрачными и отслеживаемыми, мы сильно упростили процесс отладки для разработчиков и платформенных инженеров. Теперь они могут вести совместную отладку, используя одни и те же данные, поэтому часто бывает так, что разработчики самостоятельно находят проблему и решают ее с помощью инструментов, предоставляемых платформой.
Оркестрация распределенных, запланированных задач — непростое занятие. CronJob'ы Kubernetes — это всего лишь один из способов его организации. Хотя они далеки от идеала, CronJob'ы вполне способны работать в глобальных проектах, если, конечно, вы готовы вложить время и усилия в их усовершенствование: повысить наблюдаемость, разобраться в причинах и специфике сбоев и дополнить инструментами, упрощающими использование.
Примечание: существует открытое Kubernetes Enhancement Proposal (KEP) по устранению недостатков CronJob'ов и перевода их обновленной версии в GA.
Выражаю благодарность Rithu John, Scott Lau, Scarlett Perry, Julien Silland и Tom Wanielista за их помощь в проверке данного цикла статей.
Читайте также в нашем блоге:
Мы в Lyft решили перевести серверную инфраструктуру на Kubernetes — распределенную систему оркестровки контейнеров, — чтобы воспользоваться преимуществами, которые предлагает автоматизация. Хотели получить прочную и надежную платформу, способную стать фундаментом для дальнейшего развития, а также снизить общие затраты, одновременно повысив эффективность.
Распределенные системы могут быть сложны для понимания и анализа, и в этом смысле Kubernetes — не исключение. Несмотря на его многочисленные преимущества, мы выявили несколько проблемных моментов при переходе на CronJob — встроенную в Kubernetes систему для выполнения повторяющихся задач по расписанию. В этом цикле из двух статей мы обсудим технические и эксплуатационные недостатки Kubernetes CronJob при использовании в крупном проекте и поделимся с вами опытом их преодоления.
Сначала будут описаны недостатки Kubernetes CronJobs, с которыми мы столкнулись при их использовании в Lyft. Затем (во второй части) — расскажем, как устранили эти недостатки в стеке Kubernetes, повысили удобство работы и улучшили надежность.
Часть 1. Введение
Кому будет полезны данные статьи?
- Пользователям Kubernetes CronJob.
- Всякому, кто создает платформу на базе Kubernetes.
- Любому, что заинтересован в выполнении распределенных задач в Kubernetes по расписанию.
- Всем, кто интересуется применением Kubernetes в реальных, высоконагруженных проектах.
- Contributor'ам Kubernetes.
Что вы узнаете и чему научитесь?
- Вы получите представление о том, как отдельные компоненты Kubernetes (в частности, CronJob) работают в условиях реальных нагрузок.
- Вы ознакомитесь с уроками, которые мы извлекли из использования Kubernetes как платформы в Lyft и узнаете, как мы устранили возникшие проблемы.
Предварительные условия:
- Базовые представления о работе cron'а.
- Базовое понимание того, как работает CronJob, — в частности, взаимоотношений между контроллером CronJob, создаваемыми им Job'ами и Pod'ами, в которых все происходит. Оно позволит лучше уяснить внутреннюю механику CronJob и разобраться в сравнениях с Unix cron'ом далее в этой статье.
- Общее представление о паттерне sidecar-контейнеров и о том, для чего они нужны. Мы в Lyft используем механизм упорядочивания запуска sidecar-контейнеров с тем, чтобы runtime-зависимости вроде Envoy, statsd и т.д., упакованные в sidecar-контейнеры, запускались и приступали к работе до того, как запустился контейнер самого приложения.
История вопроса и терминология
- сronjobcontroller — это фрагмент кода в управляющем слое Kubernetes, отвечающий за CronJob'ы.
- Говорят, что cron вызывается, когда он выполняется некими системными механизмами (обычно в соответствии с расписанием).
- Lyft Engineering использует модель платформенной инфраструктуры, в рамках которой выделяются инфраструктурная команда (далее называемая «платформенной», «инженерами эксплуатации платформы», «платформенной инфраструктурой») и потребители — остальные инженеры в Lyft (далее именуемые «разработчиками», «разработчиками сервисов», «пользователями» или «потребителями»). Наши инженеры владеют, эксплуатируют и поддерживают свой код, поэтому слова с корнем «эксплуат-» повсеместно используются в этой статье.
CronJob'ы в Lyft
Сегодня в нашей multi-tenant (многопользовательской) production-среде насчитывается почти 500 cron-задач, вызываемых более 1500 раз в час.
Повторяющиеся, запланированные задачи активно используются в Lyft для различных целей. До перехода на Kubernetes они выполнялись прямо на Linux-машинах с помощью обычного cron'а Unix. Команды разработчиков отвечали за написание
crontab-определений и подготовку экземпляров, которые выполняли их с помощью пайплайнов в виде Infrastructure As Code (IaC), а за их обслуживание отвечала инфраструктурная команда.В рамках более масштабных усилий по контейнеризации и миграции рабочих нагрузок на собственную платформу Kubernetes мы решили перейти на CronJob*, заменив классический Unix cron на его Kubernetes-аналог. Как и многие другие, выбор Kubernetes был сделан из-за его обширных преимуществ (по крайней мере, в теории), в том числе — для эффективного использования ресурсов.
Представьте себе cron-задачу, которая запускается раз в неделю на 15 минут. В нашей старой среде машина, выделенная под эту задачу, простаивала бы 99,85% времени. В случае же Kubernetes вычислительные ресурсы (CPU, память) используются только во время вызова. В остальное время незадействованные мощности можно использовать для запуска других CronJob'ов, или просто уменьшить (scale-down) кластер. Учитывая прошлый способ запуска cron-задач, мы многое выиграли бы от перехода на модель, в которой job'ы эфемерны.

Границы зон ответственности разработчиков и платформенных инженеров в стеке Lyft
После перехода на платформу Kubernetes команды разработчиков перестали заниматься выделением и эксплуатацией собственных вычислительных экземпляров. Теперь за поддержку и эксплуатацию вычислительных ресурсов и runtime-зависимостей в стеке Kubernetes отвечает платформенная команда. Кроме того, она занимается созданием самих CronJob-объектов. Разработчикам остается только настроить расписание задач и код приложения.
Впрочем, все это хорошо выглядит на бумаге. На практике мы выявили несколько проблемных моментов при миграции от хорошо изученной среды традиционных Unix cron'ов к распределенному, эфемерному окружению CronJob'ов в Kubernetes.
* Хотя CronJob имел и по-прежнему имеет (по состоянию на Kubernetes v1.18) бета-статус, мы обнаружили, что на тот момент он вполне удовлетворял нашим потребностям и, кроме того, прекрасно вписывался в остальной инфраструктурный инструментарий Kubernetes, существовавший у нас.
Чем отличается Kubernetes CronJob от Unix cron'а?
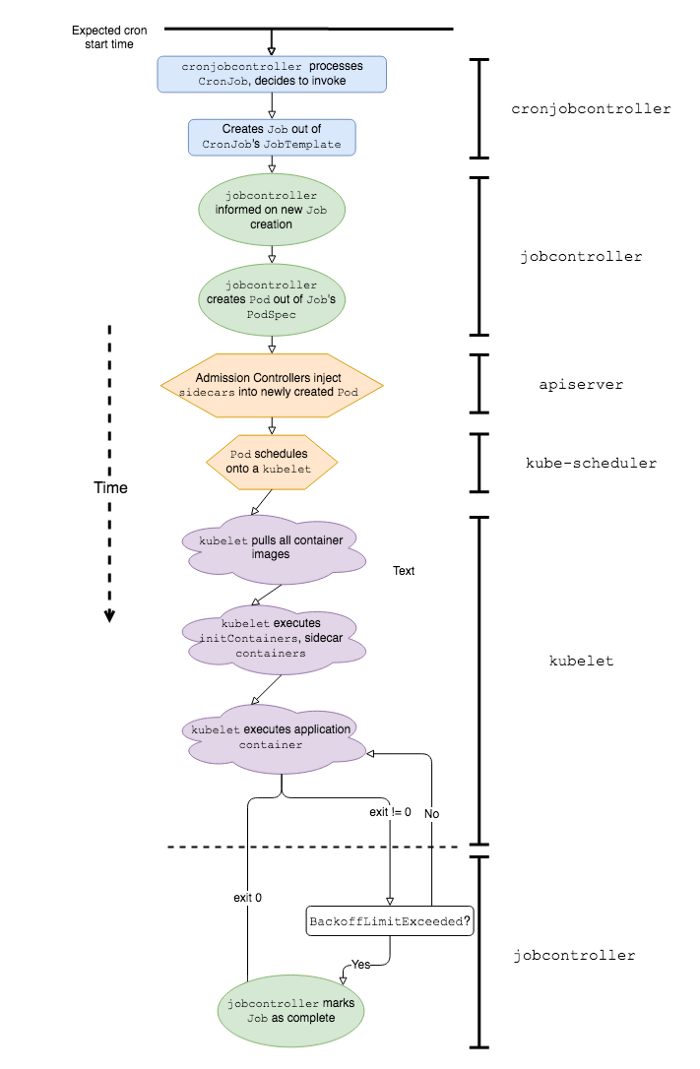
Упрощенная последовательность событий и программных компонентов K8s, участвующих в работе Kubernetes CronJob
Чтобы лучше объяснить, почему работа с CronJob'ами Kubernetes в production-среде связана с определенными трудностями, давайте сначала определим, чем же они отличаются от классических. Предполагается, что CronJob'ы работают так же, как задачи cron в Linux или Unix; однако на самом деле есть как минимум пара серьезных отличий в их поведении: скорость запуска и обработка сбоев.
Скорость запуска
Задержку запуска (start delay) мы определим как время, прошедшее с запланированного запуска cron'а до момента фактической начала работы кода приложения. Другими словами, если запуск cron'а запланирован на 00:00:00, а приложение начинает выполняться в 00:00:22, то задержка запуска этого конкретного cron'а составит 22 секунды.
В случае классических Unix cron'ов задержка запуска минимальна. Когда подходит время, указанные команды просто выполняются. Давайте подтвердим это на следующем примере:
# запускает команду date каждые сутки в полночь
0 0 * * * date >> date-cron.log
С такой конфигурацией cron мы, скорее всего, получим следующий результат в
date-cron.log:Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
С другой стороны, у CronJob'ов Kubernetes могут быть значительные задержки запуска, поскольку работе приложения предшествует целый ряд событий. Вот некоторые из них:
-
cronjobcontrollerобрабатывает и решает вызвать CronJob; -
cronjobcontrollerсоздает Job на основе спецификации задания CronJob; -
jobcontrollerзамечает новый Job и создает Pod; - Admission Controller вставляет данные sidecar-контейнера в спецификацию Pod'а*;
-
kube-schedulerпланирует Pod на kubelet; -
kubeletзапускает Pod (извлекая все образы контейнеров); -
kubeletзапускает все sidecar-контейнеры*; -
kubeletзапускает контейнер приложения*.
* Эти этапы уникальны для Kubernetes-стека Lyft.
Мы обнаружили, что самый значительный вклад в задержку вносят пункты 1, 5 и 7, как только мы достигаем определенного масштаба CronJob'ов в Kubernetes-окружении.
Задержка, вызванная работой cronjobcontroller'а
Чтобы лучше понять, откуда берется задержка, давайте изучим исходный код встроенного
cronjobcontroller'а. В Kubernetes 1.18 cronjobcontroller просто проверяет все CronJob'ы каждые 10 секунд и выполняет некоторую логику над каждым.Реализация
cronjobcontroller'а делает это синхронно, осуществляя по крайней мере один дополнительный вызов API для каждого CronJob'а. Когда число CronJob'ов превышает определенное количество, эти API-вызовы начинают страдать от ограничений на клиентской стороне.10-секундный цикл опроса и ограничения на число обращений к API со стороны клиента приводят к значительному увеличению задержки запуска CronJob'ов.
Планирование Pod'ов с cron'ами
Из-за особенностей расписания cron'ов большинство из них запускаются в начале минуты (XX:YY:00). Например,
@hourly (почасовой) cron запускается в 01:00:00, 02:00:00 и т.д. В случае multi-tenant cron-платформы со множеством cron'ов, выполняющихся каждый час, каждую четверть часа, каждые 5 минут и т.д., это приводит к возникновению узких мест («горячих точек»), когда множество cron'ов запускаются одновременно. Мы в Lyft заметили, что одним из таких мест является начало часа (XX:00:00). Эти горячие точки создают нагрузку и приводят к дополнительному ограничению частоты запросов в компонентах управляющего слоя, участвующих в выполнении CronJob'а, таких как kube-scheduler и kube-apiserver, что приводит к заметному увеличению задержки запуска.Кроме того, если вы не выделяете вычислительную мощность с учетом пиковых нагрузок (и/или используете вычислительные экземпляры облачного сервиса), а вместо этого применяете механизм автомасштабирования кластера для динамического масштабирования узлов, то время, затрачиваемое на запуск узлов, вносит дополнительный вклад в задержку запуска pod'ов CronJob.
Запуск pod'а: вспомогательные контейнеры
Как только pod CronJob'а был успешно запланирован в
kubelet, последний должен извлечь и запустить образы контейнеров всех sidecar'ов и самого приложения. Из-за специфики запуска контейнеров в Lyft (sidecar-контейнеры стартуют до контейнеров приложений), промедление при старте любого sidecar'а неминуемо отражается на результате, приводя к дополнительной задержке запуска задания.Таким образом, проволочки при запуске, предшествующие выполнению нужного кода приложения, вкупе с большим количеством CronJob'ов в условиях multi-tenant-среды приводят к заметным и непредсказуемым задержкам запуска. Как мы увидим чуть позже, в реальных условиях подобная задержка может негативно сказаться на поведении CronJob'а, грозя пропуском запусков.
Обработка сбоев контейнеров
В общем случае рекомендуется следить за работой cron'ов. Для Unix-систем это сделать довольно просто. Unix cron'ы интерпретируют заданную команду с помощью указанной оболочки
$SHELL, а после завершения работы (exit) команды (успешного или нет) этот конкретный вызов считается завершенным. Отслеживать выполнение cron'а в Unix можно с помощью простейшего скрипта вроде такого:#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
В случае Unix cron'а
stat-and-log будет выполняться ровно один раз для каждого вызова cron'а — независимо от $exitcode. Поэтому данные метрики можно использовать для организации простейших оповещений о неудачных вызовах.В случае CronJob'а Kubernetes, где по умолчанию определены повторные попытки при неудачах, а сама неудача может быть вызвана различными причинами (сбой Job'а или сбой контейнера), мониторинг не столь прост и однозначен.
Используя аналогичный скрипт в контейнере приложения и с Job'ами, настроенными на перезапуск при неудаче, CronJob при сбое будет пытаться выполнить задачу, генерируя в процессе метрики и логи, пока не достигнет BackoffLimit (макс. числа повторных попыток). Таким образом, разработчику, пытающемуся установить причину проблемы, придется разбирать много лишнего «мусора». Кроме того, алерт от скрипта-оболочки в ответ на первую неудачу также может оказаться обычным шумом, на котором невозможно базировать дальнейшие действия, поскольку контейнер приложения может восстановиться и успешно завершить задачу сам по себе.
Можно реализовать оповещения на уровне Job'а, а не на уровне контейнера приложения. Для этого доступны метрики API-уровня для сбоев Job'ов, такие как
kube_job_status_failed из kube-state-metrics. Недостаток такого подхода в том, что дежурный инженер узнает о проблеме только после того, как Job достигнет «окончательной стадии отказа» и упрется в предел BackoffLimit, что может случиться намного позже первого сбоя контейнера приложения.Причины периодических сбоев CronJob'ов
Существенная задержка старта и циклы повторных запусков вносят дополнительную задержку, которая может помешать повторному выполнению CronJob'ов Kubernetes. В случае часто вызываемых CronJob'ов или тех, у которых время работы значительно превышает время простоя, эта дополнительная задержка может привести к проблемам при следующем запланированном вызове. Если для CronJob'а установлена политика
ConcurrencyPolicy: Forbid, запрещающая параллельную работу, то задержка приводит к тому, что будущие вызовы не выполняются вовремя и откладываются.
Пример хронологии (с точки зрения cronjobcontroller'а), в которой startingDeadlineSeconds превышается для конкретного почасового CronJob'а: он пропускает свой запланированный запуск и не будет вызван до следующего запланированного времени
Есть и более неприятный сценарий (с ним мы столкнулись в Lyft), из-за которого CronJob'ы могут полностью пропускать вызовы, — это когда для CronJob'а установлен
startingDeadlineSeconds. В этом сценарии, если задержка запуска превышает startingDeadlineSeconds, CronJob полностью пропустит запуск.Кроме того, если
ConcurrencyPolicy для CronJob'а установлена в Forbid, цикл перезапусков-в-случае-сбоя предыдущего вызова также может помешать очередному вызову CronJob'а.Проблемы при эксплуатации CronJob'ов Kubernetes в реальных условиях
С тех пор, как мы начали переносить повторяющиеся, календарные задачи в Kubernetes, обнаружилось, что применение механизма CronJob'ов в неизменном виде приводит к возникновению неприятных моментов как с точки зрения разработчиков, так и с точки зрения платформенной команды. К сожалению, они начали сводить на нет преимущества и выгоды, ради которых мы изначально и выбрали Kubernetes CronJob. Вскоре мы поняли, что ни разработчики, ни платформенная команда не имеют в своем распоряжении необходимых инструментов для эксплуатации CronJob'ов и понимания их запутанных жизненных циклов.
Разработчики пытались эксплуатировать свои CronJob'ы и настраивать их, но в результате приходили к нам со множеством жалоб и вопросов вроде этих:
- Почему мой cron не работает?
- Похоже, мой cron перестал работать. Как подтвердить, что он действительно выполняется?
- Я не знал, что cron не работает, и думал, что все в порядке.
- Как мне «исправить» пропущенный cron? Я не могу просто войти по SSH и запустить команду самостоятельно.
- Вы можете сказать, почему этот cron, похоже, пропустил несколько запусков в период с X по Y?
- У нас Х (большое число) cron'ов, каждый со своими оповещениями, и обслуживать их всех становится довольно утомительно/тяжело.
- Pod, Job, sidecar — что это вообще за ерунда такая?
Как платформенная команда, мы были не в состоянии ответить на вопросы вроде:
- Как количественно оценить производительность cron-платформы Kubernetes?
- Как включение дополнительных CronJob'ов отразится на нашей Kubernetes-среде?
- Насколько отличается производительность Kubernetes CronJob'ов (выполняющихся в режиме multi-tenant) от single-tenant cron'а Unix?
- С чего начать формулирование Service-Level-Objectives (SLOs — целевых показателей доступности) для наших клиентов?
- За чем мы, как операторы платформы, следим и что делаем, чтобы решать проблемы в масштабе всей платформы быстро и с минимальным влиянием на наших потребителей?
Отладка сбоев CronJob — нелегкая задача. Часто требуется интуиция, чтобы понять, на каком этапе происходят сбои и где искать улики. Иногда эти улики получить довольно трудно — как, например, логи
cronjobcontroller'а, которые записываются, только если включен высокий уровень детализации. Кроме того, следы могут просто исчезать после определенного промежутка времени, что делает отладку похожей на игру «Прибей крота» (речь об этом — прим. перев.), — например, Kubernetes Events для CronJob'ов, Job'ов и Pod'ов, которые по умолчанию хранятся лишь в течение часа. Ни один из этих методов нельзя назвать простым в использовании, и ни один из них не масштабируется нормально с точки зрения поддержки с ростом числа CronJob'ов на платформе.Кроме того, иногда Kubernetes просто перестает пытаться выполнить CronJob, если тот пропустил слишком много запусков. В этом случае его приходится перезапускать вручную. В реальных условиях такое случается гораздо чаще, чем можно представить, и необходимость каждый раз исправлять проблему вручную становится довольно болезненной.
На этом я завершаю погружение в технические и эксплуатационные проблемы, с которыми мы столкнулись при использовании Kubernetes CronJob в нагруженном проекте. Во второй части пойдет речь о том, как мы устранили в нашем стеке Kubernetes, повысили удобство работы и улучшили надежность CronJob'ов.
Часть 2. Введение
Стало понятно, что CronJob'ы Kubernetes в неизменном виде не смогут стать простой и удобной заменой для их Unix-аналогов. Чтобы уверенно перенести все наши cron'ы в Kubernetes, нам было нужно не только устранить технические недостатки CronJob'ов, но и повысить удобство работы с ними. А именно:
1. Выслушать разработчиков, чтобы понять, ответы на какие вопросы о cron'ах волнуют их больше всего. Например: Запустился ли мой cron? (Был ли выполнен код приложения?) Прошел ли запуск успешно? Какое время заняла работа cron'а? (Как долго выполнялся код приложения?)
2. Упростить обслуживание платформы, сделав CronJob'ы более понятными, их жизненный цикл — более прозрачным, а границы платформы/приложения — более ясными.
3. Дополнить нашу платформу стандартными метриками и оповещениями, чтобы сократить объемы конфигурирования пользовательских оповещений и снизить количество дубликатов скриптов-обвязок для cron’а, которые разработчикам приходится писать и поддерживать.
4. Разработать инструментарий для простого восстановления после сбоев и тестирования новых конфигураций CronJob'ов.
5. Исправить давние технические проблемы в Kubernetes, такие как баг с TooManyMissedStarts, который требует ручного вмешательства для устранения и приводит к тому, что падение в рамках одного важного сценария сбоя (когда значение startingDeadlineSeconds не задано) происходит незаметно.
Решение
Все эти проблемы мы решили следующим образом:
- Повысили наблюдаемость (observability). Это позволило разработчикам не только проводить отладку своих CronJob'ов, но и открыло перед платформенными инженерами путь к определению целевых уровней обслуживания (Service Level Objectives, SLOs) и их контролированию.
- Разработали инструмент для упрощения вызова CronJob'ов «по запросу» в нашем стеке Kubernetes.
- Исправили давние проблемы в самом Kubernetes.
Метрики и оповещения для CronJob'ов

Пример панели, сгенерированной платформой для мониторинга конкретного CronJob'а
Мы дополнили стек Kubernetes следующими метриками (они определены для всех CronJob'ов в Lyft):
1.
started.count — этот счетчик увеличивается тогда, когда контейнер приложения впервые запускается при вызове CronJob'а. Он помогает ответить на вопрос: «Выполнялся ли код приложения?».2.
{success, failure}.count — эти счетчики увеличиваются, когда конкретный вызов CronJob'а достигает терминального состояния (то есть Job закончил свою работу и jobcontroller более не пытается его выполнить). Они отвечают на вопрос: «Прошел ли запуск успешно?».3.
scheduling-decision.{invoke, skip}.count — эти счетчики позволяют узнать о решениях, которые принимает cronjobcontroller при вызове CronJob'а. В частности, skip.count помогает ответить на вопрос: «Почему мой cron не работает?». В качестве его параметров выступают следующие метки reason:-
reason = concurrencyPolicy—cronjobcontrollerпропустил вызов CronJob'а, поскольку в ином случае это привело бы к нарушению егоConcurrencyPolicy; -
reason = missedDeadline—cronjobcontrollerотказался от вызова CronJob'а, поскольку тот пропустил окно вызова, заданное.spec.startingDeadlineSeconds; -
reason = error— это общий параметр для всех остальных ошибок, возникающих при попытке вызвать CronJob.
4.
app-container-duration.seconds — этот таймер измеряет время существования контейнера приложения. Он помогает ответить на вопрос: «Как долго выполнялся код приложения?». В этот таймер мы умышленно не включили время, требующееся на планирование pod'а, запуск sidecar-контейнеров и т.д., поскольку они входят в зону ответственности платформенной команды и включаются в задержку запуска.5.
start-delay.seconds — этот таймер измеряет задержку запуска. Эта метрика при агрегации по всей платформе позволяет инженерам, ее обслуживающим, не только оценивать, отслеживать и настраивать производительность платформы, но и выступает некой основой для определения SLO для таких параметров, как задержка запуска и максимальная частота расписания cron'ов.На основе этих метрик мы создали оповещения по умолчанию. Они уведомляют разработчиков, когда:
- Их CronJob не запустился по расписанию (
rate(scheduling-decision.skip.count) > 0); - Их CronJob завершился неудачно (
rate(failure.count) > 0).
Больше разработчикам не нужно определять собственные оповещения и метрики для cron'ов в Kubernetes — платформа предоставляет их готовые аналоги.
Запуск cron'ов при необходимости
Мы адаптировали
kubectl create job test-job --from=cronjob/<your-cronjob> под наш внутренний CLI-инструмент. Инженеры в Lyft используют его для взаимодействия со своими сервисами на Kubernetes, чтобы при необходимости вызывать CronJob'ы для:- восстановления от периодических сбоев CronJob'ов;
- воспроизведения и отладки runtime-сбоев во время, отличное от 3:00 утра (более удобное время, когда можно исследовать происходящее с CronJob'ами, Job'ами и Pod'ами в реальном времени), — вместо того, чтобы пытаться поймать проблему в процессе;
- тестирования runtime-конфигурации при разработке нового CronJob'а или миграции существующего Unix cron'а, не ожидая, когда подойдет время его вызова по расписанию.
Исправление TooManyMissedStarts
Мы исправили баг с TooManyMissedStarts, так что теперь CronJob'ы не «зависают» после 100 подряд пропущенных стартов. Этот патч не только устраняет необходимость в ручном вмешательстве, но и позволяет реально отслеживать, когда время
startingDeadlineSeconds превышено. Благодарим Vallery Lancey за проектирование и создание этого патча, Tom Wanielista — за помощь в разработке алгоритма. Мы открыли PR, чтобы внести этот патч в основную ветку Kubernetes (однако он так и не был принят, а закрыт из-за неактивности — прим. перев.).Реализация мониторинга cron'ов

На каких стадиях жизненного цикла CronJob'ов Kubernetes мы добавили механизмы экспорта метрик
Оповещения, которые не зависят от расписаний cron'ов
Самая хитрая часть реализации оповещений о пропущенных вызовах cron'ов — это обработка их расписаний (для их расшифровки нам очень пригодился crontab.guru). Давайте, например, рассмотрим следующее расписание:
# Через каждые 5 минут
*/5 * * * *
Можно сделать так, чтобы счетчик для этого cron'а увеличивался каждый раз, когда он завершается (или использовать cron-обвязку). Тогда в системе оповещений можно прописать условное выражение вида: «Посмотри на 60 предыдущих минут и сообщи мне, если счетчик увеличится меньше чем на 12». Проблема решена, верно?
Но что, если у вас расписание следующего вида:
# На нулевой минуте каждого часа с 9 до 17
# в каждый день недели с понедельника по пятницу.
# Другими словами, в рабочие часы (9-17, Пн-Пт)
0 9–17 * * 1–5
В этом случае придется повозиться с условием (хотя, может быть, у вашей системы есть функция оповещения только по рабочим часам?). Как бы то ни было, эти примеры иллюстрируют, что привязывание оповещений к расписаниям cron'ов имеет несколько недостатков:
- При смене расписания приходится вносить изменения в логику оповещения.
- Некоторые расписания cron'ов требуют для репликации довольно сложных запросов с использованием временных рядов.
- Необходим некий «период ожидания» для cron'ов, которые не начинают свою работу точно по времени, чтобы минимизировать ложные срабатывания.
Один лишь п. 2 делает генерацию оповещений по умолчанию для всех cron'ов на платформе очень сложной задачей, а п. 3 особенно актуален для распределенных платформ вроде Kubernetes CronJob, в которых задержка запуска является весомым фактором. Кроме того, есть решения, использующие «переключатели мертвеца», что опять возвращает нас к необходимости привязывать оповещение к расписанию cron'а, и/или алгоритмы обнаружения аномалий, которые требуют некоторого обучения и не работают сразу для новых CronJob'ов или изменений в их расписании.
Другой способ взглянуть на проблему заключается в том, чтобы спросить себя: что означает, что cron должен был запуститься, но этого не произошло?
В Kubernetes — если на минутку забыть о багах в
cronjobcontroller'е или возможности падения самого control plane (хотя вы должны сразу это увидеть, если правильным образом отслеживаете состояние кластера) — это означает, что cronjobcontroller оценил CronJob и решил (в соответствии с расписанием cron'а), что он должен быть вызван, но по какой-то причине намеренно решил этого не делать.Звучит знакомо? Это именно то, чем занимается наша метрика
scheduling-decision.skip.count! Теперь нам достаточно отслеживать изменение rate(scheduling-decision.skip.count), чтобы оповестить пользователя, что его CronJob должен был сработать, но этого не произошло.Это решение «отвязывает» расписание cron'а от самого оповещения, обеспечивая несколько преимуществ:
- Теперь не нужно перенастраивать оповещения при изменении расписаний.
- Отпадает необходимость в сложных временных запросах и условиях.
- Можно легко сгенерировать оповещения по умолчанию для всех CronJob'ов на платформе.
Это, в сочетании с другими временными рядами и оповещениями, упомянутыми ранее, помогает воссоздать более полную и понятную картину состояния CronJob'ов.
Реализация таймера задержки запуска
Из-за сложной природы жизненного цикла CronJob'ов нам было необходимо тщательно продумать конкретные точки размещения инструментария в стеке, чтобы измерять эту метрику надежно и точно. В итоге все свелось к фиксации двух моментов времени:
- T1: когда cron должен быть запущен (в соответствии с его расписанием).
- T2: когда код приложения фактически начнет выполняться.
В этом случае
start delay (задержка запуска) = Т2 — Т1. Чтобы зафиксировать момент Т1, мы включили код в логику вызова cron'а в самом cronjobcontroller'е. Он записывает ожидаемое время старта как .metadata.Annotation у объектов Job, которые cronjobcontroller создает при вызове CronJob'а. Теперь его можно извлечь в помощью любого API-клиента, выполнив обычный запрос GET Job.С Т2 все оказалось сложнее. Поскольку нам нужно получить значение, максимально близкое к реальному, Т2 должен совпадать с моментом, когда контейнер с приложением запустится в первый раз. Если снимать Т2 при любом запуске контейнера (включая перезапуски), то задержка запуска в этом случае включит время работы самого приложения. Поэтому мы решили присваивать еще одну
.metadata.Annotation объекту Job всякий раз, когда обнаруживали, что контейнер приложения для данного Job'а впервые получил статус Running. Тем самым, по существу, создавалась распределенная блокировка, и будущие старты контейнера приложения для данного Job'а игнорировались (сохранялся момент только первого старта).Результаты
После выката нового функционала и исправления ошибок мы получили множество положительных отзывов от разработчиков. Теперь разработчики, пользующиеся нашей платформой Kubernetes CronJob:
- больше не должны ломать голову над своими собственными инструментами мониторинга и оповещениями;
- могут быть уверены, что их CronJob'ы выполняются, т.к. наши alert'ы оповестят их, если это не так;
- могут легко восстанавливать работоспособность после сбоев и тестировать новые CronJob'ы в этой среде, используя наш инструмент вызова CronJob'ов «по запросу»;
- могут отслеживать производительность кода своего приложения (используя метрику таймера
app-container-duration.seconds).
Кроме того, у инженеров по обслуживанию платформы теперь появился новый параметр (start delay) для оценки пользовательского опыта и производительности платформы.
Наконец (пожалуй, это наша самая крупная победа), сделав CronJob'ы (и их состояния) более прозрачными и отслеживаемыми, мы сильно упростили процесс отладки для разработчиков и платформенных инженеров. Теперь они могут вести совместную отладку, используя одни и те же данные, поэтому часто бывает так, что разработчики самостоятельно находят проблему и решают ее с помощью инструментов, предоставляемых платформой.
Заключение
Оркестрация распределенных, запланированных задач — непростое занятие. CronJob'ы Kubernetes — это всего лишь один из способов его организации. Хотя они далеки от идеала, CronJob'ы вполне способны работать в глобальных проектах, если, конечно, вы готовы вложить время и усилия в их усовершенствование: повысить наблюдаемость, разобраться в причинах и специфике сбоев и дополнить инструментами, упрощающими использование.
Примечание: существует открытое Kubernetes Enhancement Proposal (KEP) по устранению недостатков CronJob'ов и перевода их обновленной версии в GA.
Выражаю благодарность Rithu John, Scott Lau, Scarlett Perry, Julien Silland и Tom Wanielista за их помощь в проверке данного цикла статей.
P.S. от переводчика
Читайте также в нашем блоге:
