
Несколько месяцев назад у нас появилась необходимость разработать CSI-драйвер для Kubernetes, который в первую очередь использовался бы для хранения дисков виртуальных машин в Deckhouse Virtualization, но также мог бы использоваться и со стандартными контейнерами в Kubernetes. У оборудования наших заказчиков, как правило, есть определенная специфика — чаще всего это классическая SAN (Storage Area Network) с внешним хранилищем и общим shared LUN, который выделяется на несколько узлов. На одном LUN одновременно работает несколько виртуальных машин или контейнеров.
Помимо всего прочего, от драйвера нам требовалась поддержка различных CoW-фичей, таких как снапшоты, thin provisioning и возможность выполнять live-миграцию виртуальных машин в Kubernetes. Из существующих решений можно было бы отметить некоторые свободные проекты, однако ни один из них не реализует все желаемые фичи. Кроме того, у них есть явные проблемы с масштабированием.
Дальше мы будем много говорить о виртуализации, поэтому рекомендую прочитать наш недавний перевод статьи «Эволюция технологий виртуализации сети в Linux», которую написала техническая команда ByteDance — разработчики технологии VDUSE.
В поиске подходящего бэкенда
Кластерные файловые системы вроде GFS2 и OCFS2 не подошли ввиду того, что максимальный размер кластера в них ограничен 32 узлами. Кроме того, для их настройки необходим распределенный менеджер блокировок (DLM), который зависит от Corosync. С архитектурной точки зрения это довольно старые и сложные технологии, не совсем укладывающиеся в концепцию Kubernetes.
Использование POSIX-совместимой файловой системы, с одной стороны, могло бы всё упростить, с другой — добавило бы еще один уровень абстракции, в итоге ухудшив производительность. А так как на рынке не было подходящих свободных решений, мы решили продолжить поиски.
Основной альтернативой кластерным файловым системам является обычный LVM, который умеет работать в кластерном режиме, а с новым менеджером блокировок (sanlock) настраивается относительно просто и поддерживает кластеры размером до 2000 узлов. Однако единственный на данный момент найденный нами CSI-драйвер для Kubernetes, который умел бы работать с кластерным LVM, оказался неофициальным проектом Google и поддерживается всего одним человеком.
Чувствуется, что автор отвел душу при его разработке: заимплементил и снапшоты, и фенсинг, и дисковый RPC, который позволяет компонентам драйвера общаться, отправляя команды прямо через специальный раздел на дисковом устройстве.
Кстати, если вы захотите более глубоко разобраться с кластерным LVM, рекомендую вам отличную статью по теме.
Еще одна проблема заключается в том, что снапшоты в LVM очень сильно влияют на производительность ввода-вывода. Это можно видеть по результатам нашего бенчмарка (по ссылке можно изучить и исходную табличку):
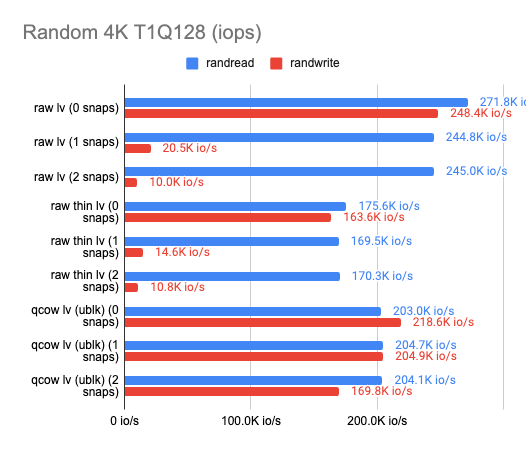

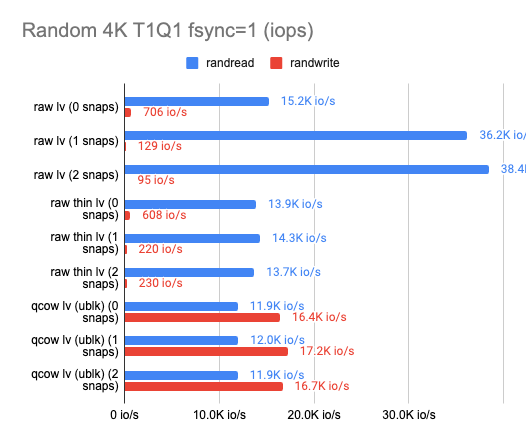
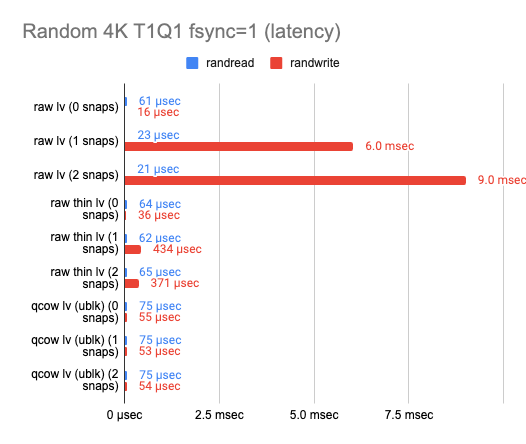
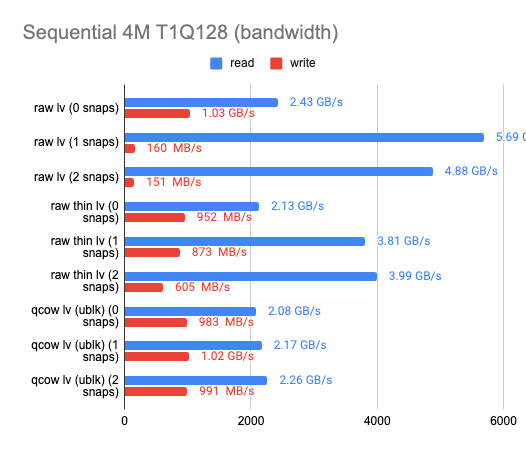
Здесь мы сравнили три технологии для реализации снапшотов:
классический LVM;
LVM Thin (расширение LVM, позволяющее использовать Copy-on-write);
QCOW2 (формат образов виртуальных машин, используемый в QEMU).
Для бенчмарков использовались те же тесты, которые мы упоминали в одной из предыдущих статей — там мы сравнивали производительность LINSTOR, Ceph, Mayastor и Vitastor в Kubernetes.
На графиках мы можем увидеть, как растет latency и как деградирует производительность при создании снапшотов, если мы используем ту или иную технологию. При этом обычный файловый QCOW2 с внешними снапшотами в тех же тестах показывает стабильно неизменяемую производительность. Отсюда делаем вывод, что на самом деле QCOW2 не так уж и плох для реализации снапшотов, особенно в тех случаях, когда бэкенд не поддерживает механизм Copy-on-write.
Отдельно можно отметить, что в некоторых тестах LVM показывает более высокую скорость чтения при создании снапшотов, чем без них. С чем связан этот феномен, я не знаю, но есть предположение, что если обращение идёт к неразмеченным экстентам, LVM с ходу возвращает нули, не производя непосредственно операции чтения с диска.
Мы ориентировались в первую очередь на показатели записи, и потому решили остановиться на классическом LVM для разделения физического LUN на виртуальные тома и файловом формате QCOW2 для реализации механизма снапшотов и thin provisioned-томов.
Используем файловый формат без файловой системы
Но ведь QCOW2 — это файловый формат. Существует ли возможность использовать его без файловой системы? Оказывается, существует. Изучая решения различных вендоров, мы наткнулись на один любопытный документ. В нем довольно подробно расписан механизм реализации thin provisioning в oVirt.
На самом деле авторы этого документа тоже используют LVM и просто записывают QCOW2 поверх блочного устройства, а затем настраивают дополнительный handler в libvirt, чтобы следить за размером виртуального тома и заблаговременно увеличивать LV, находящийся под ним.
То есть LVM используется для нарезания томов, а QCOW2 — для thin provisioning. При этом снапшоты — это всегда отдельный том c QCOW2, ссылающийся на предыдущий том с помощью механизма chaining.
Нам этот подход показался довольно интересным: он сочетает в себе универсальность и производительность, а кроме того, технически его можно применить не только для SAN, но и для стандартных локальных дисков на узлах.
Звучит вполне реализуемо, но, как всегда, есть нюанс. В отличие от Kubernetes, основная сущность, с которой работает oVirt, — это виртуальная машина. И вполне логично, что для управления всем жизненным циклом виртуальной машины, а также всех сопутствующих систем (сеть, хранилище) он максимально задействует возможности libvirt. Libvirt же, запускаясь как системный демон, имеет полный доступ как к виртуальной машине, так и к дисковой подсистеме.
Таким образом, через libvirt oVirt выполняет все операции для подготовки и выполнения виртуальной машины: настраивает сеть и хранилище, запускает саму ВМ — и все это работает как единый инструмент. Kubernetes же в первую очередь работает с контейнерами, для управления которыми определяет целый стек слабосвязанных (by-design) интерфейсов: CRI, CSI и CNI. Каждый интерфейс выполняет свою, четко определенную функцию: например, CSI отвечает за хранилище, CNI — за сеть, CRI — за рантайм и подготовку песочницы для запуска процессов в контейнере. Поэтому в Kubernetes (а точнее, в расширении KubeVirt) libvirt используется исключительно как средство запуска виртуальных машин и работает в виде отдельного процесса внутри контейнера, а от функций управления сетью и хранилищем он избавлен, полностью полагаясь в этом на CNI и CSI.
Именно поэтому в случае с Kubernetes при разработке CSI-драйвера нужно учитывать тот факт, что основным консьюмером у нас является ядро, которое может запустить в песочнице любой процесс — а не только libvirt. То есть применение CSI-драйвера не должно ограничиваться рамками виртуальных машин, вместо этого драйвер должен предоставлять системе сырое блочное устройство и обеспечивать возможность его использования стандартными средствами хостовой ОС, например:
Создать и примонтировать устройство как файловую систему (вариант по умолчанию). Обычно это выглядит как блочное устройство, поверх которого создается файловая система. Эта файловая система отдается контейнеру как директория, в которую он может «складывать свои файлики».
Пробросить блочное устройство в контейнер «как есть». Дело в том, что виртуальным машинам файловая система как таковая не нужна, им нужен виртуальный диск в виде файла или отдельного блочного устройства. Поэтому Kubernetes научили прокидывать в контейнер блочные устройства «как есть» — и с ними виртуальная машина может работать напрямую, без прослойки в виде файловой системы.
Но как же нам «подключить» QCOW2-файл, чтобы получить его представление в виде сырого блочного устройства в хостовой системе? На данный момент одним из самых простых и известных способов получить доступ к содержимому QCOW2 без запуска виртуальной машины является qemu-nbd. Но стоит копнуть чуть глубже, и тут же выяснится, что qemu-nbd имеет серьезные ограничения и не предназначен для использования на постоянной основе для чего-то бóльшего, чем единичные задачи или отладка (например, вытащить какой-нибудь файл из образа): например, мы не сможем создавать и удалять снапшоты или изменять размер блочного устройства на лету.
Есть и более продвинутое решение — qemu-storage-daemon. Он представляет собой отдельный демон с отделенной от QEMU функциональностью, который отвечает исключительно за подсистему хранения. С ним можно общаться через unix-сокет с помощью QMP-протокола и динамически выполнять различные команды вроде «открыть файл», «закрыть файл», «создать снапшот», «экспортировать устройство» и т. п.
Кстати, в комьюнити KubeVirt уже представлена попытка написать CSI-драйвер с использованием qemu-storage-daemon. Однако этот проект ориентирован на предоставление COW поверх обычной файловой системы, а мы делаем упор на поддержку SAN и кластерный режим.
Однако это далеко не единственный вариант. Например, в шестой версии ядра Linux появилась система ublk (io_uring based userspace block device driver). С помощью ubdsrv к ней можно подключить QCOW2-файл: он будет представлен в ядре в виде сырого блочного устройства, а количество прослоек, через которые он работает, будет минимальным.
Забегая вперед скажу, что нам удалось протестировать ublk и сравнить ее с другими методами подключения. И смею вас заверить — на сегодняшний день это один из самых продуктивных методов. К сожалению, он по-прежнему достаточно экспериментальный и на момент публикации статьи у него еще нет поддержки со стороны qemu-storage-daemon.
Разбираемся с экспортами в qemu-storage-daemon
qemu-storage-daemon поддерживает следующие методы для экспорта виртуального устройства в систему: NBD, FUSE, vhost-user и VDUSE.
И если NBD уже достаточно известен, то наличие FUSE в этом списке может несколько сбить с толку, ведь его основная задача — выступать в качестве интерфейса файловой системы пространства пользователя, а не блочных устройств. Однако в Linux существует возможность монтирования некоторых файловых систем не только в директорию, но и в обычные файлы, что позволяет получить некий импровизированный аналог виртуализированного блочного устройства. Правда, это не совсем наш вариант, так как в конечном итоге мы ожидаем получить честное блочное устройство, на которое Kubernetes сможет выставить специальные разрешения для использования в cgroups для нашего контейнера, и пробросить его в контейнер.
Vhost-user тоже довольно специфический протокол, который позволяет реализовать прямой канал коммуникации между виртуальной машиной и системой хранения (в том случае, если это два раздельных процесса). Таким образом, виртуальной машине не нужен отдельный контроллер для трансляции системных вызовов VirtIO, вместо этого подобные вызовы могут передаваться напрямую в хранилище. Со стороны хоста такой экспорт выглядит как обычный unix-сокет, и он просто передается QEMU-процессу, в котором исполняется виртуальная машина. Ввиду отсутствия каких-либо прослоек vhost-user должен быть наиболее продуктивным протоколом для подключения хранилища к виртуальным машинам.
Однако на данный момент KubeVirt не поддерживает vhost-user для подсистемы хранения, а мы всё же очень хотим сделать универсальное решение, которое работало бы как с виртуальными машинами, так и с контейнерами. Поэтому мы решили, что не будем полностью завязываться на vhost-user, а просто добавим возможность его использования — с прицелом на то, что в будущем в KubeVirt всё же появится соответствующий интерфейс.
И на данный момент мы решили построить свое решение на основе последнего, недавно добавленного в qemu-storage-daemon протокола VDUSE, который, по сути, является интерфейсом к шине vDPA в ядре Linux.
Если вы не знакомы с этими технологиями виртуализации, снова порекомендую ознакомиться с нашим переводом статьи «Эволюция технологий виртуализации сети в Linux».
Что такое vDPA
В ядре Linux существует технология vDPA (VirtIO Data Path Acceleration), которая позволяет драйверам устройств предоставлять полностью совместимый с VirtIO интерфейс (vhost). Благодаря этому виртуальная машина может напрямую взаимодействовать с физическими устройствами, без необходимости создания дополнительного control plane для трансляции системных вызовов.
На практике у шины vDPA есть бэкенд и фронтенд. В качестве бэкенда может выступать драйвер устройства или VDUSE (vDPA Device in Userspace). По сути, это еще один модуль ядра Linux, который позволяет полностью вынести бэкенд vDPA в пространство пользователя. Для взаимодействия VDUSE создает символьное устройство (character device) в директории /dev/vduse/device, с которым может общаться SDS или SDN, работающая в пространстве пользователя. qemu-storage-daemon — единственная известная мне на данный момент имплементация этого интерфейса для хранилища. Начиная с версии 7.1.0, QSD научился экспортировать QCOW2-файл в VDUSE и таким образом предоставлять его в шине vDPA как готовое к подключению устройство.
Для фронтенда есть два варианта, которые так же реализованы в виде модулей ядра:
vhost-vdpa — используется для виртуальных машин. С точки зрения операционной системы экспортированное устройство выглядит как еще одно символьное устройство (например,
/dev/vhost-vdpa-0), которое можно передать процессу QEMU или другому приложению, способному работать с протоколом vhost.virtio-vdpa — используется для контейнеров. Выглядит как обычный
/dev/vda, который работает прямо на bare metal.
")
Таким образом, базовая имплементация нашего CSI-драйвера должна экспортировать цепочку QCOW2-файлов в виде блочных устройств VirtIO. Каждое такое устройство будет проброшено в контейнер и сможет использоваться для запуска как виртуальных машин, так и обычных контейнеров.
Протестировав скорость работы VDUSE, мы обнаружили, что эта технология не особо уступает той же ublk, а в некоторых случаях даже обходит ее (таблица с результатами):

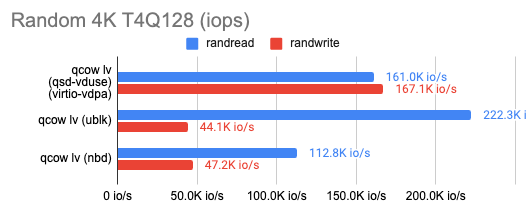

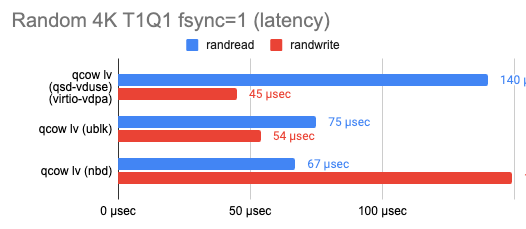

Реализуем ReadWriteMany для QCOW2
Казалось, что все уже шло к своему логическому завершению, однако возник еще один интересный момент касательно реализации конкурентного доступа к данным. Напомню, что со стороны драйвера мы должны предоставлять блочное устройство или файловую систему вне зависимости от того, кто будет его использовать — виртуальная машина или контейнер.
При этом виртуальные машины могут мигрировать между хостами (соответственно, нам необходима поддержка ReadWriteMany со стороны драйвера). В итоге встал резонный вопрос: как реализовать ReadWriteMany для QCOW2, если сам QEMU это решение не поддерживает? При live-миграции виртуальной машины в момент переключения QEMU просто сбрасывает все кэши, и виртуальная машина начинает работать с новым QCOW2.
Это казалось серьезной проблемой, потому что в концепции Kubernetes дисковая подсистема и рабочая нагрузка непременно должны быть четко отделены друг от друга: первая предоставляет нам блочное устройство, а вторая его использует. То есть со стороны CSI-драйвера мы не смогли бы привязаться к событию «окончание live-миграции», чтобы сбросить кэши, потому что драйвер «ничего не знает» и о виртуальной машине, и о любом другом процессе, использующем устройство внутри контейнера.
Но спустя некоторое время решение все-таки было найдено: если установить параметр cache.direct в true, это повлечет за собой инвалидацию page-кэшей на узле и позволит обойти описанное выше ограничение.
Таким образом, когда от драйвера требуется присоединение только к одному узлу, этот параметр использует значение по умолчанию false, что позволяет достичь наилучшей производительности. Однако, если появляется необходимость сделать еще один аттачмент, мы переводим этот параметр в true. Конечно, это ухудшает производительность дисковой подсистемы в момент миграции, но зато позволяет избежать проблем, связанных с инвалидацией кэшей.
Важно понимать, что это не полноценный ReadWriteMany и при одновременной записи с обоих хостов мы рискуем повредить структуру QCOW2-файла. Однако такого решения уже достаточно, чтобы гарантировать беспроблемную live-миграцию виртуальных машин в Kubernetes.
Что в итоге
Вот так, используя кластерный LVM и файловый QCOW2-формат, мы можем получить всю функциональность thin provisioning, почти не потеряв в производительности. Это позволяет реализовать быстрый и, главное, универсальный драйвер для подключения и эффективного использования любой SAN-подобной системы хранения данных в Kubernetes.
Со стеком технологий мы определились и уже приступили к разработке драйвера.
P. S.
Читайте также в нашем блоге:
