
Представьте: у вас пара сотен микросервисов, и вдруг всё ломается. А может даже не всё, а, скажем, только одна страница. Если вы хорошо знакомы с системой, то по мониторингу и логам быстро обнаружите проблему и пойдете её решать. Но иногда систему вы видите впервые, и на поиск бага могут уйти часы, или даже дни.
Всем привет, меня зовут Саша Казанцев, я — тимлид команды “Clickme” в hh.ru. В этой статье расскажу о том, как мы внедряли трейсинг.
Как было раньше
Мы храним логи просто файлами на дисках. Искать по ним не всегда просто и не очень быстро. Наши коллеги написали систему, которая позволяет искать логи по request_id. Так мы можем достать логи запроса по всем микросервисам одним запросом. Вроде бы удобно и быстро, но есть проблема.
Во-первых, сначала нам нужно где-то взять этот request_id — в логах или у пользователя. Во-вторых, эта система не умеет строить дерево запросов, поэтому мы не знаем, какой микросервис кого вызывал, и понять что происходит в целом - сложно.
Так мы пришли к пониманию, что нам нужен трейсинг.
Трейсинг, в общем случае — это список вызовов, представленных в виде дерева. Там можно увидеть коды ошибок, время, которое занял запрос, и на каком сервере он выполнялся. Кроме того, некоторые системы умеют дополнять его метриками, логами и даже строить граф зависимости микросервисов. Стали изучать, сколько будет стоить разработать свою систему или взять готовую. Посчитали, что взять готовую будет сильно дешевле, на этом варианте и остановились.

OpenTracing
Мы начинали внедрение OpenTracing в конце двадцатого года. Тогда во всех докладах и статьях OpenTracing подавался как стандарт отрасли.
Написали свой прототип, показали коллегам. И тут один из разработчиков заметил, что OpenTracing — deprecated. Зашли на сайт, смотрим, а там действительно огромный красный баннер ссылка на OpenTelemetry.

OpenTelemetry
OpenTelemetry тогда ещё была в beta. Но выбирая между сырой технологией и устаревшей, мы решили остановиться на первой.
В этой итерации мы взяли клиент OpenTelemetry и внедрили его в наше java-приложение. В качестве бэкенда мы взяли openzipkin. Тогда он был достаточно популярен и написан на java, и мы смогли бы доработать его в случае необходимости.
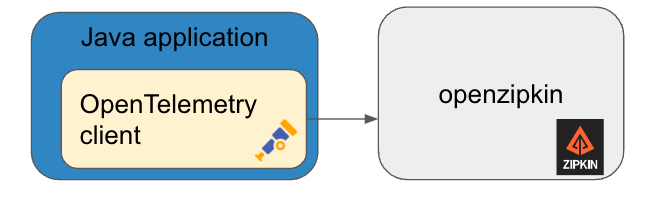
Мы внедрили клиент OpenTelemetry в первые три микросервиса, запустили, и оно заработало!
Стали собираться трейсы и строиться первые деревья. Мы были несказанно счастливы, потому что у нас появилась очень классная картинка вызовов с таймингами, кодами ответов и так далее. Но появились и первые проблемы. Например, микросервисы иногда стали вылетать с ошибкой “out of memory”. Начали разбираться в чем дело, и оказалось, что OkHttp client выжирает весь heap.


Мы пытались его настроить, ограничить буферы, подтюнить, но в тот момент ничего не вышло. Тогда мы стали искать новое решение.
Меняем okhttp на grpc и распространяем ̶з̶а̶р̶а̶з̶у̶
На следующей итерации мы попробовали разные клиенты, и в итоге взяли на основе GRPC. У него не было проблем с памятью, как у OkHttp, и он обеспечивал достаточную производительность под высокими нагрузками.
Кроме того, мы начали масштабировать backend-часть, добавили агент и поставили коллекторы перед zipkin. Агент и collector мы связывали по протоколу OTLP, он позволяет использовать встроенную балансировку.
С взаимодействием OpenTelemetry <-> zipkin вышло не все так просто, поскольку zipkin не поддерживает протокол OTLP, а collector OpenTelemetry не умеет делать балансировку по другим протоколам.
Мы пытались научить коллектор балансировать по другим протоколам, или как добавить внешний балансировщик, но в итоге взяли самый простой вариант — один collector OpenTelemetry пишет в конкретный инстанс zipkin. Таким образом обеспечивалась достаточная простота и надежности на данный момент достаточно.

Еще растем
Мы продолжали развивать нашу систему, добавлять новые микросервисы, нагрузка постепенно росла. Параллельно мы общались с коллегами из других компаний и интересовались, как они используют трейсинг.
Стало понятно, что zipkin перестает быть трендом, а на его место пришел jaeger. Мы заменили zipkin безболезненно, jaeger прекрасно вписался в нашу инфраструктуру и работал без всяких проблем.

Продолжили добавлять новые микросервисы, нагрузка росла, и тут нас начинает отказывать Cassandra. Мы пытались её масштабировать, добавить инстансов, ресурсов. Но, увы, она всё равно не справилась. Для телеметрии нужно огромное количество индексов, а cassandra явно под такое не приспособлена.
Мы обратились к разработчикам OpenTelemetry, чтобы они помогли настроить кассандру, или предложили другое решение. Они порекомендовали использовать ElasticSearch. С ним всё заработало без проблем, и он потребляет гораздо меньше ресурсов, чем Cassandra.
Добавили еше jaeger UI для просмотра трейсов. И получили такую итоговую схему:

Ресурсы
Мы стали оценивать, во сколько нам обходится поддержание всей инфраструктуры телеметрии. Оказалось, что на одно ядро полезной нагрузки приходится почти одно ядро на поддержание системы телеметрии. Кроме cpu еще оперативная память и довольно много диска — до 500 гб на один сервис, а у нас их почти две сотни.
Дорого. Нужно каким-то образом снижать затраты.
Первое что попалось — сэмплирование. Оно позволяет отбросить часть ненужных трейсов и сохранять только те, что нам нужны. Мы хотели создать систему, которая в первую очередь позволяла бы анализировать ошибки. Поэтому нам нужно было сохранять только трейсы с “плохими” запросами. Есть два основных подхода к сэмплированию: head-сэмплинг и tail-сэмплинг.
head-сэмплинг может принимать решения о сохранении только в самом начале запроса, когда он приходит в первый сервис. Затем первый сервис пробрасывает решение о сохранении всем остальным сервисам дальше по стеку, а они уже ничего не отправляют, просто отбрасывают эти трейсы. Нам это решение не подходит, потому что первый сервис не может знать, будут ошибки в запросе или нет.
Поэтому мы стали смотреть в сторону tail-сэмплинга. В этом варианте система собирает все трейсы запроса и уже потом принимает решение, нужно сохранять trace или нет. Сначала попытались настроить tail-семплинг на jaeger коллекторе, но на нем можно настроить tail-семплинг, только если вся цепочка сбора от агента до коллектора джагеровская. А нам хотелось сделать vendor-free систему. В итоге мы настроили tail-сэмлинг на OpenTelemetry коллекторе. С семплингом потребление ресурсов стало в разы меньше.
Снова стреляет клиент
Когда мы раскатили OpenTelemetry на бóльшее количество микросервисов, оказалось, что на некоторых из них появились проблемы с производительностью. На этот раз были сложности не с хипом, a с direct-буфером. У GRPC под капотом есть библиотека netty и в определенных условиях она полностью забивала direct-буфер. Приложение просто переставало нормально функционировать.
Мы снова начали искать решения и, как ни странно, снова вернулись к OkHttp client. На этот раз нам удалось настроить буферы и переделать отправку трейсов батчами. Приложение заработало стабильно, и никаких проблем ни по памяти, ни по cpu больше не возникает. Кроме того, side-эффектом было то, что OpenTelemetry агенты стали потреблять гораздо меньше cpu.
Примеры конфигов
opentelemetry-agent
receivers:
otlp:
protocols:
grpc:
endpoint: :1234
processors:
batch:
exporters:
logging:
loglevel: warn
loadbalancing:
protocol:
otlp:
timeout: 1s
insecure: true
resolver:
static:
hostnames:
[ host1, host2]
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [logging, loadbalancing]
opentelemetry-collector
extensions:
pprof:
endpoint: 127.0.0.1:1236
receivers:
otlp:
protocols:
grpc:
endpoint: :1234
processors:
tail_sampling:
decision_wait: 5s
num_traces: 10000
expected_new_traces_per_sec: 10000
policies:
[
{
name: error_policy,
type: numeric_attribute,
-- сохраняем только трейсы, в которых есть 500-ка в ответах сервисов
numeric_attribute: { key: "http.status_code", min_value: 500, max_value: 599 }
}
]
exporters:
logging:
logLevel: warn
jaeger:
endpoint: 127.0.0.1:1235
insecure: true
service:
extensions: [pprof]
pipelines:
traces:
receivers: [otlp]
processors: [tail_sampling]
exporters: [logging, jaeger]
jaeger-collector
collector.grpc-server.host-port={{ port.grpc_receiver }}
collector.http-server.host-port={{ port.http_receiver }}
collector.queue-size=250000
admin.http.host-port=:{{ port.prometheus }}
es.use-aliases=true
es.use-ilm=true
es.create-index-templates=false
log-level=info
es.server-urls=elastic1, elastic2
Небольшое заключение
Мы собрали много граблей пока строили свою систему. Может быть наша история убережет вас от части из них.
Наша телеметрия уже приносит пользу в поисках ошибок. А в планах еще добавить автоматическое определение причин ошибок и возможно однажды добавим сбор продуктовых метрик на основе opentelemetry.
пример полного трейса

пример спана(кусочка трейса)

Где вам хочется работать
Мы запускаем ежегодное исследование узнаваемости брендов IT-компаний на российском рынке. Каждый год изучаем, какие айтишки у нас знают лучше, и в каких хочется работать большинству специалистов.
Пройдите этот опрос и расскажите о своих впечатлениях от сегодняшнего IT в РФ.
Ваши ответы помогут нам составить наиболее объективную картину, которой мы по традиции поделимся со всеми.
