Идея моего домашнего проекта началась с простой, на первый взгляд, задачи: с потребности конвертировать файлы формата XML в формат XLS (или CSV) для последующего анализа. И я был наивен, чтобы попробовать решение «в лоб» и с помощью Excel импортировать богатый внутренний мир SAP Business Objects, описанный в иерархической структуре XML, в табличную форму, — и примерно через час мое сознание, в очередной раз выдав исключение о переполнении памяти, подключило опыт, который намекнул, что иерархические структуры заранее неизвестной глубины проще всего обрабатывать посредством рекурсии. Так появился лаконичный скрипт на Python. Потом еще один. И еще. Потом скрипты пошли в массы среди коллег по цеху. Появились фантазии и мечты, например возможность каждые пять минут забирать XML (или JSON) из кафки (Apache Kafka), трансформировать на лету и класть, например, в DWH. Вполне ожидаемо, что была масса вопросов к скриптам и просьба «быстренько поправить». И в какой-то момент, как в том классическом анекдоте про «закопанную стюардессу», я понял, что хватит… Так и появился MVP, который я хотел бы представить в этой статье.
Постановка задачи
Задачу для себя формулировал тезисно, а именно:
- Это должно быть оконное приложение, желательно кросс-платформенное, желательно в виде одного исполняемого файла. Да, «совсем не тру» (True). Не спорю, но я искал решение для пользователей разного уровня квалификации — плюс с красочной перспективой, в которой мы все будем работать под Astra Linux, к примеру.
- Мне нужен полноценный ETL «из коробки». Да, есть очень мощные аналоги (о них далее), и да, есть Cron под Linux или nnCron под Windows (интересно, он еще используется в современных версиях окошек?), но надо учитывать разную квалификацию пользователей, а также вероятность того, что в корпоративной сети возможность самостоятельно поправить планировщик задач доступна далеко не всем. Поэтому «все в одном».
- Решение прагматичной задачи с преобразованием XML/JSON в XLS/CSV. Но это задача «с бонусом»: хотелось бы, чтобы проект в дальнейшем масштабировался как под другие форматы данных, так и способы их получения и выгрузки (загрузка из файлов, выгрузка в БД через ODBC)
Вот здесь стоит оставить примечание:
я понимаю, что иду по лестнице без перил и рискую свалиться в «комбайностроение», когда я до старости буду пилить «комбайн, который может все». Но считаю, что в моем случае риск минимален, так как, во-первых, я знаю о реальных потребностях пользователей, во-вторых, отсутствие времени не позволит мне реализовывать возможности, которые когда-нибудь кому-нибудь могут потребоваться.
Поиск аналогов
Первое, что пришло мне в голову, когда я размышлял над тем, как реализовать задачу с минимальными усилиями, — это, конечно, Jupyter. Но он не подходит пользователям, у которых отсутствуют навыки написания кода на Python. Да, есть профессиональные ETL, например Apache Airflow, и да, можно заранее написать требуемые даги (DAG’s) и все это великолепие обернуть в докер и дать пользователям… Но лучше не надо, если у вас, конечно, не мощная рабочая станция с более чем 16 ГБ оперативной памяти. Мой старенький ноутбук до сих пор с содроганием вспоминает тот опыт.
Реализация
Весь код на Python. Да, использовал PySide2, Requests для получения данных. Почему не использовал стандартный пакет XML или возможности Pandas для конвертирования? Потому как наши данные могут быть невалидными — и что теперь, «работу не работать»? Потому xmltodict. Ну и, конечно, Pandas, к которому у меня особые, лирические чувства.
Установка
Весь проект вот здесь. В папке dist лежит EXE-файл, который достаточно скачать и запустить. Или, если вы, как и я, мнительны и избегаете запуска незнакомых исполняемых файлов, то нужно склонировать к себе репозиторий проекта и дать пару следующих команд:
pip install -r requirements.txt
python main.py Применение
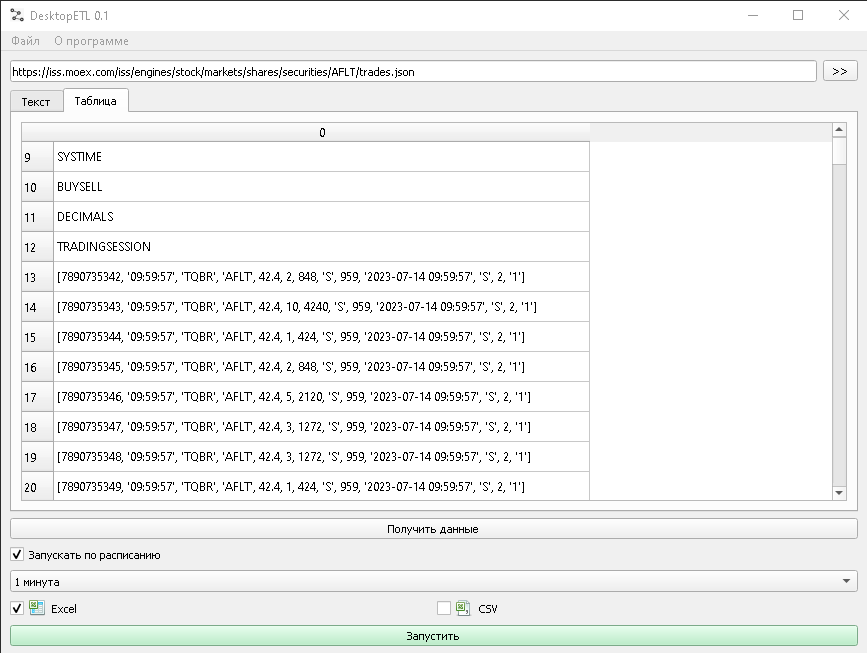
На практике попробуем получить данные сразу в табличку Excel или в CSV-файл — или сразу в оба файла одновременно. Для примера возьмем сервис горячо мною любимой Moscow_Exchange.
По этим ссылкам можно получать текущий список сделок по эмитенту, причем, указывая разное расширение в конце адреса (.xml или .json), получаем данные в формате XML или JSON соответственно.
https://iss.moex.com/iss/engines/stock/markets/shares/securities/AFLT/trades.xml
https://iss.moex.com/iss/engines/stock/markets/shares/securities/AFLT/trades.json
- Запускаем DesktopETL.
- В строке адреса указываем адрес из ссылок, приведенных выше.
- Нажимаем кнопку «Получить». Полученный ответ в виде «Как есть» отражается на закладке «Текст». Если на закладке «Таблица» отражаются данные, то мы можем производить выгрузку.
Замечание: да, на текущий момент, если в «Таблице» данных нет, то выгрузка не производится. В дальнейшем планирую добавить простой текстовый формат, в который будет возможность регулярно выгружать данные из текстовой области.

- Пункт «Запускать по расписанию». Если вам нужна регулярная выгрузка, например «Раз в минуту», то ставим галку и выбираем интересующий вас период. Обратите внимание, работа по расписанию будет осуществляться, пока работает программа! Если же речь идет о разовой выгрузке, то достаточно нажать кнопку «Запустить».
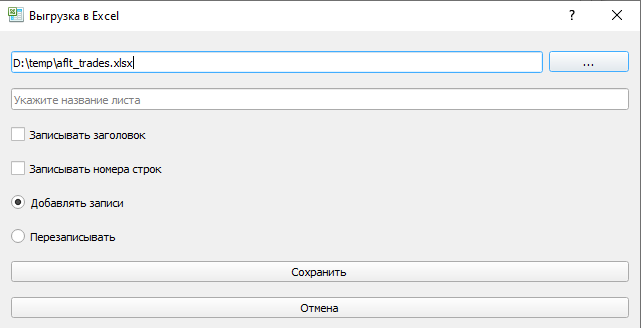
- Выгрузка в Excel. Нажимаем на кнопку с галочкой и заполняем следующую форму.

Если не указать «Имя листа», то будет использоваться «DesktopETL». Если указать «Добавлять записи», то программа сначала считает содержимое существующей таблицы нужного листа, определит последнюю строку и уже после добавит новую информацию.
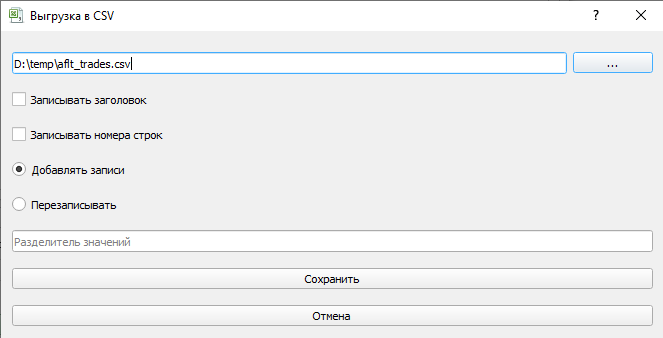
- Выгрузка в CSV. То же самое. Нажимаем на кнопку с галочкой и заполняем следующую форму.

Дальнейшее развитие
Повторюсь, в открытом доступе я публикую MVP (Minimum Viable Product, «минимально жизнеспособный продукт»). Помимо устранения выявленных багов, я бы хотел усовершенствовать часть преобразования в табличную форму, возможность фильтрации и реализовать существующие методы выгрузки в разные форматы, которые уже описаны в Pandas (это сделать проще). Не уверен, хватит ли у меня амбиций и времени замахнуться на парсинг HTML в попытке обесценить труд «веб-скраперов» и сделать Teleport Pro New Edition (старожилы поймут).
И да, мне нужна ваша помощь, чтобы собрать как пожелания, так и ошибки. Если пожеланий будет очень много, то в следующих статьях, помимо изменений, планирую публиковать голосование за наиболее востребованные возможности.
