 Когда вы выросли настолько, что появились узлы в разных городах, возникает задача распределения нагрузки между ними. Задачи такой балансировки могут быть разными, но цель, как правило, одна: сделать так, чтобы было хорошо. У меня дошли руки рассказать о том, как это делают обычно, и как это сделано в ivi.ru.
Когда вы выросли настолько, что появились узлы в разных городах, возникает задача распределения нагрузки между ними. Задачи такой балансировки могут быть разными, но цель, как правило, одна: сделать так, чтобы было хорошо. У меня дошли руки рассказать о том, как это делают обычно, и как это сделано в ivi.ru.В предыдущей статье я рассказал, что CDN у нас свой, при этом тщательно избегал подробностей. Пришла пора поделиться. Рассказ будет в стиле поиска решения, каким он мог бы быть.
В поисках идеи
Какие могут быть критерии для гео-балансировки? Мне приходит в голову вот такой список:
1) уменьшение задержек при загрузке контента
2) размазывание нагрузки на серверы
3) размазывание нагрузки на каналы
Окей, раз на первом месте уменьшение задержек, то надо отправлять пользователя на ближайший узел. Как этого можно добиться? Ну, у нас тут завалялась Geo-IP база, которую мы используем для региональной привязки рекламы. Может, её к делу приспособить? Можно, к примеру, написать распасовщик, который будет стоять в нашем центральном ЦОДе, определять регион пришедшего на него пользователя и отвечать тому редиректом на ближайший узел. Работать будет? Будет, но хреново! Почему?
Ну, во-первых, пользователь уже пришёл в Москву только для того, чтобы узнать, что ему в Москву не надо. А затем ему надо сделать второй заход уже на местный узел за требуемым файлом с фильмом. А если фильм нарезан чанками (chunk, это такие маленькие маленькие файлы с маленькими кусочками фильма)? Тогда будет по два запроса на каждый чанк. Ой-ой-ой! Можно, конечно, попробовать это всё оптимизировать и написать на клиенте код, который будет ходить в Москву только один раз за фильм, но это уже утяжелит этот самый код. А потом его придётся дублировать на всех типах поддерживаемых устройств. Избыточный код — это плохо, поэтому — отказать!
Довольно много CDN, которые я наблюдал (не могу сказать, что тестировал), пользуются балансировкой редиректами. Думаю, дополнительной причиной, почему они это делают, является биллинг. Ведь они — коммерческие люди, им нужно обслужить тех и только тех, кто им заплатил. А такая проверка на балансировщике занимает дополнительное время. Я уверен, что именно такой подход и привёл к упомянутому мной прошлый раз результату — сайты с CDN грузятся медленнее. А мы этот способ полностью и с самого начала проигнорировали.
А если по имени?
Как мы можем сделать геобалансировку так, чтобы не надо было бегать лишний раз в Москву? Но позвольте! Мы и так по-любому ходим в Москву — чтобы разрезолвить доменное имя! А что, если ответ сервера будет учитывать местонахождение пользователя? Да запросто! Как это можно сделать? Можно, конечно, вручную: создать несколько представлений (view) и для разных пользователей возвращать разные IP-адреса для одного и того же доменного имени (сделаем для этого специально выделенный FQDN). Вариант? А то! Только поддерживать придётся вручную. Можно и автоматизировать — для bind, к примеру, есть модуль для работы с тем же MaxMind. Думаю, есть и другие варианты.
К моему огромному изумлению, балансировка при помощи DNS сейчас является самым распространённым способом. Не только небольшие фирмы используют этот метод для своих нужды, но и крупные уважаемые производители предлагают комплексные аппаратные решения, основанные на этом методе. Так, например, работает F5 Big IP. Опять же, говорят, что так работает Netflix. Откуда изумление? Проследите мысленно цепочку прохождения запроса к DNS от пользователя.
Куда пакет попадает с пользовательского ПК? Как правило — на провайдерский DNS-сервер. И в этом случае, если предположить, что этот сервер находится близко к пользователю, то пользователь попадёт на ближайший к нему узел. Но в значимом проценте случаев (даже простая выборка у нас по офису даёт заметный результат) это будет либо вселенское зло — Google DNS, либо Яндекс.DNS, либо ещё какой-либо DNS.
Чем это плохо? Давайте смотреть дальше: когда такой запрос попадёт на ваш уполномоченный DNS, чей будет source IP? Сервера! Никак не клиента! Соответственно, балансирующий DNS будет по факту балансировать не пользователя, а сервер. Учитывая, что пользователь может использовать сервер не в своём регионе, то и выбор узла на основе этой информации будет неоптимальным. А дальше — хуже. Такой гуглоднс закэширует у себя ответ нашего балансирующего сервера, и будет возвращать его всем клиентам, уже без учёта региона (в нём-то не настроены view). Т.е. фиаско. Кстати, сами производители такого оборудования, при личной встрече мне вполне подтвердили наличие этих фундаментальных проблем с DNS-балансировкой.
Сказать по правде, мы этот метод применяли на заре строительства нашего CDN. Ведь опыта с собственными узлами у нас не было. Системные интеграторы сразу пытались продать под такую задачу по много вагонов оборудования за сумму с большим количеством нулей. А решение на основе DNS в принципе понятно, и работоспособно. Из нашего опыта эксплуатации и выплыли все эти отрицательные стороны. К тому же, вывод узла на профилактику чертовски сложен: приходится ждать, пока протухнут кэши на всех устройствах по пути к пользователю (кстати, оказывается, огромное количество домашних роутеров напрочь игнорирует TTL в DNS-записях и хранят кэш до пропадания питания). А уж что будет, если узел вдруг аварийно отключится — так вообще страшно подумать! И ещё одна вещь: очень непросто понять, с которого узла абонент обслуживается, когда у него проблема. Ведь это зависит от нескольких факторов: и в каком регионе он находится, и какой DNS он использует. В общем, очень много неоднозначностей.
Пинг или не пинг?
И вот тут наступает «во-вторых» (на случай если кто-то удивляется, зачем я начал во-первых): в интернете географически близкие элементы могут оказаться очень далеки с точки зрения прохождения трафика (помните с прошлого раза «из Москвы в Москву — через Амстердам»?). Т.е. geo-IP базы недостаточно для принятия решения о направлении пользователя на какой-либо конкретный узел. Необходимо дополнительно учитывать связность между провайдером, к которому подключен узел CDN, и пользователем. По-моему, здесь же, на хабре, мне попадалась статья, в которой упоминалось ручное ведение базы данных по связности между провайдерами. Оно, конечно, может и работать значимую часть времени, но разумность в таком решение явно отсутствует. Каналы между провайдерами могут падать, могут забиваться, могут отключаться из-за разрыва отношений. Поэтому отслеживание качества от узла до пользователя должно быть автоматизировано.
Как мы можем оценить качество канала до пользователя? Пропинговкой, конечно! И пинговать пользователя мы будем со всех наших узлов — ведь нам надо выбрать лучший вариант. Полученные результаты мы где-нибудь сохраним для следующего раза — ведь если ждать, пока все узлы пользователя пропингуют, он просто не дождётся кино. Так что первый раз пользователь всегда будет обслуживаться с центрального узла. А если с Чукотки до Москвы плохие каналы — ну, значит, второго раза не будет. Кстати, пользователи не всегда пингуются — новые домашние роутеры и всяческие Windows 7 по умолчанию не отвечают на эхо-запросы. Так что такие тоже будут всегда обслуживаться из Москвы. Чтобы замаскировать эти проблемы, давайте усложним наш алгоритм вычисления лучшего узла аггрегированием пользователей по подсетям. Затем запатентуем его и поедем в Сколково — больше нигде такая система не нужна в виду своей тяжести и неэффективности.
И как ни странно, «промышленные» решения используют именно такой способ определения карты связности — пропинговку конкретных пользователей. Начисто игнорируя и то, что оконечные устройства не отвечают на ICMP пинги, и многие провайдеры (особенно на западе) вырезают весь ICMP под корень (я и сам люблю его хорошо зафильтровать). И все эти промышленные решения заполняют интернет бессмысленными пингами, фактически вынуждая провайдеров фильтровать ICMP. Не наш выбор!
В этой точке мне стало очень грустно. Ведь те методы гео-балансировки, которые я нашёл в интернете, были не очень подходящи под наши цели и задачи. А они в тот момент уже могли быть сформулированы в виде:
1. Абонент должен сначала обращаться к ближайшему узлу, и только если там нет нужного контента, тогда — к следующему, покрупнее
2. Решение должно быть независимым от настроек у конкретного пользователя
3. Решение должно учитывать текущую связность от пользователя до узла CDN
4. Решение должно предоставлять техническим сотрудникам ivi возможность понять, на каком узле пользователь обслуживается
Просветление
И тут мне на глаза попалось слово anycast. Я его не знал. Оно чем-то напоминало известные мне unicast, broadcast и любимый multicast. Я полез гуглить и скоро стало понятно, что это наш выбор.
Если кратко описывать anycast, то это будет так: «Хак, нарушение принципа уникальности IP-адреса в интернете». За счёт того, что одна и та же подсеть анонсируется из разных мест интернета, с учетом взаимодействия автономных систем, а если разные наши узлы контактируют с одной и той же автономкой провайдера — за счет метрики IGP или её эквивалента, выбираться будет ближайший узел. Смотрите, как собранная система (номера автономок указаны для примера, хотя и не без уважения к коллегам) выглядит на самом деле:
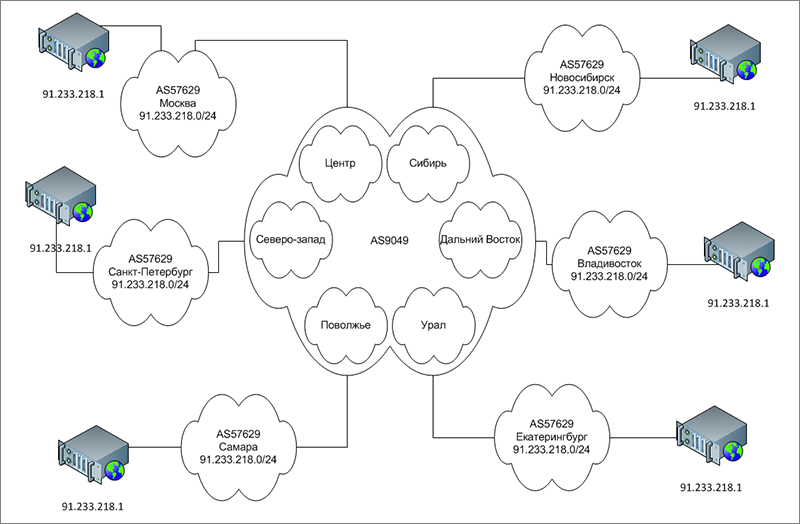
И как она же выглядит с точки зрения маршрутизации BGP. Как будто бы нет никаких неуникальных IP-адресов, а есть несколько каналов связи в разных городах:

И дальше пусть сеть провайдера выбирает, как ей лучше поступить. Поскольку не все операторы связи являются врагами собственной сети, можно быть уверенным в том, что пользователь будет попадать на ближайший узел CDN.
Конечно, BGP в текущей инкарнации не содержит информации о загруженности каналов. Зато такой информацией обладают сетевые инженеры провайдера. И если они отправляют свой трафик в тот или иной канал, значит, у них есть причина это сделать. Из-за специфики anycast, наш трафик придёт с той стороны, куда они отправили пакеты.
Итоговая схема выглядит так:
1. Пользователь обращается на выделенный для контента FQDN
2. Это имя резолвится в адрес из anycast'ового диапазона
3. Пользователь попадает на ближайший (с точки зрения сети) узел CDN
4. Если такой контент на узле есть, то пользователь его получает с узла (т.е. один запрос!!!)
5. Если такого контента на узле нет, то пользователь получает HTTP-redirect в Москву
Исходя из того, что локализация контента на узле высока (односерверные узлы — не в счёт), бОльшая часть запросов пользователей будет обслужена с ближайшего узла, т.е. с минимальными задержками. И хотя пользователю это неважно (зато очень важно для провайдеров) — через немагистральные каналы связи.
Anycast и его ограничения очень хорошо описаны в RFC4786. И это было первое и пока что последнее RFC, которое я дочитал до конца. Основное ограничение — это возможность перестроения маршрутов. Ведь если пакеты из середины TCP-сессии вдруг пойдут на другой узел, то оттуда в ответ прилетит RST. И чем длительнее TCP-сессия, тем выше вероятность этого. Для просмотра фильма это весьма критично. Как мы это обошли? По нескольким направлениям:
1. Часть контента доступна в виде чанков. Соответственно, время TCP-сессии незначительно
2. Если плеер не смог скачать кусочек фильма из-за разрыва сессии, то плеер не показывает ошибку, а делает ещё одну попытку. С учетом большого буфера (10-15 секунд) пользователь вообще ничего не замечает.
Другое (и временами, крайне неприятное ограничение) заключается в том, что оператор CDN на основе anycast не имеет непосредственного управления над тем, с какого именно узла пользователь обслуживается. В большинстве случаев, это для нас хорошо (пусть оператор сам решает, где у него каналы толще). Но иногда нужно подтолкнуть в другом направлении. И самое приятное, что это возможно!
Балансируем!
Есть несколько способов добиться нужного распределения запросов между узлами:
1. Написать сетевикам — долго, мучительно искать контакты (RIPE DB все как-то не хотят вести), напрягает их и приходится долго рассказывать про anycast. Но в ряде случаев — единственный способ
2. Добавить препендов (prepend, это когда мы «визуально удлиняем маршрут в BGP») в анонсы. Тяжёлая артиллерия. Применяется только на прямых стыках и никогда — на точках обмена трафиком (IX)
3. Управляющие community, моё любимое. У всех приличных провайдеров они есть (да, обратное верно: у кого нет — тот неприличный). Работает примерно как препенд, но гранулярнее, добавляет препенд не всем клиентам через стык, а только в конкретные направления, вплоть до закрытия анонсов.
Естественно, со всей этой системой чёрных ящиков работать было бы невозможно, но есть такая приятная вещь, как Looking Glass (LG, переводить не буду, т.к. все переводы плохие). LG позволяет заглянуть в роутинговую таблицу провайдера, не имея доступа к его оборудованию. У всех приличных операторов есть такая штука (мы не оператор, но у нас тоже есть). И такая мелочь позволяет избегать обращений к сетевикам операторов связи в очень большом количестве случаев. Я так и свои ошибки ловил, и чужие.
За всю нашу трёхлетнюю эксплуатацию CDN с балансировкой на основе anycast всплыл только один тяжелый случай: сеть на всю страну с централизованным роут-рефлектором (route-reflector, RR) в Москве. Фактически такая архитектура делает для провайдера бесполезными распределённые стыки: ведь RR будет выбирать лучшим ближайший к нему маршрут. И его же будет анонсировать всем. Впрочем, эта сеть по совокупности недостатков такой архитектуры уже перестраивается.
Аварии и на нашем оборудовании, и на чужом оборудовании, показали очень хорошую устойчивость CDN: как только один узел выбывает из строя, клиенты с него разбегаются на другие. И не все на один, что тоже весьма полезно. Никакого вмешательства человеческого разума для этого не требуется. Вывод узла на профилактические работы тоже прост: мы прекращаем анонсы нашего anycast-префикса, и пользователи быстро переключаются на другие узлы.
Пожалуй, дам ещё один совет (впрочем, и это тоже описано в упомянутом RFC): если вы строите узел распределённой сети на основе anycast, обязательно обзаведитесь на этом узле если не FullView (в те Cisco, которые у нас стоят в регионах, 500 килопрефиксов не влезает), то маршрутом по умолчанию — обязательно! Случаи несимметричной маршрутизации в интернете встречаются сплошь и рядом, а мы совсем не хотим оставлять пользователя перед чёрным экраном из-за чёрной дыры в маршрутизации.
Так, кажется я ещё в требованиях упоминал про возможность определения «прилипания» пользователя к узлу. Это тоже реализовано. :) Для того, чтобы провайдер мог определить, на какой узел шлёт (или может слать пользователей), анонсы со всех наших узлов помечены маркировочным community. А их значения — описаны в нашей IRR-записи в RIPE DB. Соответственно, если вы приняли префикс с меткой 57629:101, знайте, что вы ходите в Москву.
Есть и другой способ, которым мы пользуемся: попинговать IP-адрес под вопросом с источника в anycast-сети. Если пакет вернулся (мы получили ответ на свой пинг), значит клиент обслуживается с данного узла. В теории, это означает, что надо перебрать все узлы, но на практике мы достаточно точно можем предсказать, где абонент обслуживается. А если пользователь не пингуется вообще (я же сам про это и написал выше, да?)? Не проблема! Как правило, в этой же подсети есть роутер, который пингуется. А нам этого вполне достаточно.
Что ж, на узел мы пришли. Но ведь никто же не думает, что у нас на одном узле только один сервер? А раз так, то надо как-то распределить запросы между ними. Но эта тема — для другой статьи, если конечно это вам интересно.
