

Мы продолжаем публиковать самые интересные доклады RAIF, ежегодного форума по искусственному интеллекту, организованному «Инфосистемы Джет». Сегодня хотим поделиться рассказом доктора физико-математических наук, профессора департамента информатики НИУ ВШЭ Бориса Асеновича Новикова.
Мифы о больших данных и цифровая культура
Слово big в нашем случае относится больше к мифам, чем к данным, поэтому я расскажу, в основном, о первых, но в контексте вторых. Поскольку я уже несколько десятилетий делаю вид, что работаю в научном сообществе, я начну с определения, чтобы это выглядело, как точное знание.

Мифы – неотъемлемая часть культуры общества, они существовали всегда и продолжают появляться в современном мире. Привожу примеры:

Более старшая часть аудитории должна помнить шум вокруг 2000-го года, который на самом деле является одним из 400 относительно честных способов извлечения денег из заказчика, не более того. Конечно, катастрофы тогда не случилось.
Возникает масса мифов вокруг software engineering – здесь есть много разных точек зрения, и на этой теме я концентрироваться сейчас не буду.
К этому докладу меня подтолкнула инициатива сверху: в том университете, где я работал, появилась необходимость обучить цифровой грамотности поголовно всех, от детского сада до аспирантуры. Никто не знал, что это такое, и я опрометчиво признался руководству, что я примерно понимаю, как это делать… и попался. Нужно было учить разные специальности по одной программе:

Основной мой вклад в дело заключался в том, что я переименовал этот курс из «Цифровой грамотности» в «Цифровую культуру».
На одной из международных конференций я услышал такое высказывание: для того, чтобы привлечь внимание аудитории, нужно добавить в доклад хоть какой-то намек на сексуальность, так вот: несколько лет назад в прессе (в частности, в российской) широко обсуждался случай, как американской школьнице стали присылать рекламу для беременных (на этом сексуальный контекст истории исчерпывается ), потом семья обратилась с иском, но в итоге иск пришлось отозвать… Потому что девушка действительно оказалась беременной. История понаделала много шума, мол, эти аналитики знают о нас больше, чем мы сами (это уж вряд ли)! Все это очень опасно, и надо усиливать защиту. Так родились мифы:
- Большие данные крайне опасны
- Они знают о нас больше, чем мы сами
- Необходимы дополнительные меры по безопасности
Поймите меня правильно: безопасность важна, но давайте посмотрим, как оценивать этот случай профессионально.

Какой вывод можно сделать? Анализ ИНОГДА может давать правильные результаты, и мы можем также сказать, что иногда мы ничего не знаем.
Мои друзья и коллеги обращают внимание на то, что случайная рассылка тоже иногда дает правильные результаты, и мы ничего не можем сказать о качестве рассылки, если не оценим какие-нибудь количественные показатели. Прежде всего, необходимо оценивать полноту и точность.
Следующие виды мифов я позаимствовал из зарубежного контекста. Например, на одной из топовых конференций по обработке данных SIGMOD 2019 проходила панельная дискуссия (или, как говорят у нас, «круглый стол») на тему «Responsible Data Science». Там обсуждались примеры того, каким образом случается безответственное применение средств анализа данных, машинного обучения и т.п. В качестве одного из примеров привели историю с определением пола человека по фотографии глаз. Люди работали над этим несколько лет, достигли точности аж 80%, пока один скептик не выяснил, что на самом деле они определяют наличие или отсутствие косметики.
Это курьез, но вот дальше пример, в котором опасность уже абсолютно реальная: речь идет о применении методов машинного обучения для выявления преступников по фотографиям. Как выяснилось, в самом принципе работы этой обучающейся системы есть проблемы с политкорректностью: во-первых, они давали ложноположительные ответы с разной частотой в зависимости от расы, а во-вторых, как оказалось потом, на самом деле они определяли наличие или отсутствие улыбки на фотографии, не более того. Однако были попытки применения этой системы, и офицерам, которые должны были использовать результаты, в случае несогласия полагалось писать письменное объяснение, почему именно они не согласны с результатами, которые выдает система. Вот это уже пример того, каким образом мифы могут стать опасными для общества.
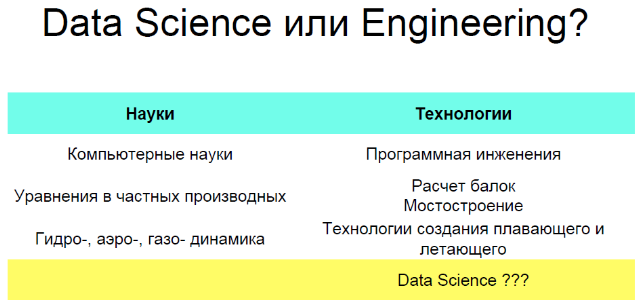
Почему-то мы говорим Data Science, хотя речь идет о промышленных применениях. Во всех остальных областях – Computer Science, но… Software Engineering. Уравнения математической физики и какое-нибудь мостостроение, или что-то еще? Коллеги, ученым нельзя верить! Хотелось бы думать, что Data Science относится к разделу «Науки», и к сожалению, формулировка Data Engineering уже занята другим понятием.
Я возвращаюсь к истории с проектом курса для всего университета независимо от подготовленности и специальности. Картинка с правой стороны (лебедь, рак и щука) показывает, каким образом работала команда, собранная из представителей всех факультетов университета.

Тем не менее, мы попытались сделать что-то разумное. Идея состояла в том, чтобы показать простые вещи, которые каждый исследователь может делать сам независимо от той области, в которой он работает. При этом чтобы он мог понять, в какой момент (это самое важное!) нужно обратиться к профессионалам по обработке данных. Я пытался избежать таких рецептов для начинающих (но из этого мало что получилось), типа «Сделайте сложение популярным, но не практическим руководством».
Итак, мифы неизбежны, и мы должны понимать, что с ними все-таки придется иметь дело. Мифы являются источником многих ошибок, неудач и проблем, а иногда могут быть даже опасны – необдуманное применение мифических «знаний» может иметь негативные последствия.
Кроме того, что мы развиваем технологии, надо заниматься просвещением общества, и это забота постоянная, которая никогда не будет решена полностью, потому что человечество в общем развивается не так быстро, как технологии. Обучить людей намного труднее, чем искусственный интеллект – один из источников мифов. Нам надо научиться работать и жить с этим так, чтобы избежать больших опасностей.
