
Сага о том, как Java-разработчики должны тестировать свои приложения. Часть 1
Перед вами вторая часть Саги от Николая xpinjection Алименкова о том, как Java-разработчики должны тестировать свои приложения, речь в которой пойдет о TDD, BDD, тестировании FTP, UI, web-UI, JMS и баз данных.
Итак, шёл второй час…

Test Driven Development (TDD) или не TDD
Основное преимущество TDD для Java-разработчиков (помимо больших размышлений над своим дизайном и более полного покрытия тестами в виде приятного дополнения) — это разработка большей части кода посредством генерации.
Рассмотрим это на примере.
У меня есть ShoppingCart, в который можно добавлять какие-то item-ы. И я хочу посчитать Total по ShoppingCart по общей цене. Я называю тест соответственно:
public class ShoppingCardTest {
private ShoppingCard card = new ShoppingCard ();
@Test
public void anyNumberOfItemsMayBeAddedToShoppingCard () {
card.add (new Item ("iPad", 200), 1);
card.add (new Item ("iPhone 6", 600), 1);
assertEquals (2, card.get Items () .size () );
}Какой же должен быть API? Тут замечательно помогает излюбленный метод разработчиков «copy-paste»:
@Test
public void anyNumberOfItemsMayBeAddedToShoppingCard () {
card.add (new Item ("iPad", 200), 1);
card.add (new Item ("iPhone 6", 600), 1);
}У меня будет 2 элемента: один из них iPad, другой — iPhone 6S.
Как было бы удобно мне получить этот Total? Его можно получить числом, но, возможно, число — не самая хорошая штука. Число можно было бы сделать мультивалютным или добавить внутрь форматирование. Поэтому я это сделаю по-другому:
Total total = card.getTotal ();А что же в Total должно храниться? Точно в нем должна быть цена. Я убеждаюсь, что это цены:

Double cost у меня есть, один item. И мне нужно сделать Assert.
Total total = card.getTotal ();
assertEquals (800, total.getSum (), 0.0000001);Надо помнить, что double нельзя непосредственно сравнивать между собой — только с дельтой.
Как видите, появляется много разных идей. Кто-то говорит: «назовем getSum», — кто-то еще что-то — нам надо выбрать. Это и есть генерация API.
После генерации этой штуки все просто. Во-первых, вы приходите выше и у вас горит красненьким. Вы создаете класс.
Вот появился класс:
public class Total {
}Я никогда не пишу руками public class и т.п., поэтому так разрабатывать гораздо быстрее. Теперь мне нужно сделать метод (он у меня горит красненьким). Todo-шка сразу сгенерировалась:
public Total getTotal () {
return null; //todo<lumii> implement me
}И здесь еще getSum. Я подозреваю, что это будет property, поэтому я создаю property:
public class Total {
public double getSum () {
return sum;
}
}Мне пока не надо знать, как формируется Total. Но я уже могу этот тест запустить:

В результате — наш любимый старый добрый NPE.
Мы получили неработающий тест — это очень важный момент. Если бы мы сразу получили работающий, я бы однозначно сказал, что что-то где-то не так.
Мы идем туда и видим, что все логично: метод getTotal у нас возвращает null. Вместо него мы возвращаем new Total:
public Total getTotal () {
return new Total ();
}
}Давайте запустим и посмотрим, может сработает уже.

Смотрите: мы хотели, чтобы вернулось 800, а не вернулось ничего. Соответственно, давайте попробуем прокалькулировать через for: пробежимся по item-ам и вычислим сумму:
public Total getTotal() {
for (Item item : items) {
sum += item.getCost();
}
}
И надо local variable создать.
double sum;
for (Item item : items) {
sum = item.getCost();
}
Создавая переменную, мы потеряли плюсик в сумме. Я не буду его ставить. Обнулим переменную, все это сгенерим сейчас. Создадим конструктор.
Запускаем тест. Вместо 800 получаем 600. Вот здесь мы видим, что плюса не хватает — можем исправить. И не задумывайтесь, работает оно или не работает: у вас теперь есть тест, который несет ответственность за это вместо вас. Когда заработает, он вам скажет, что пора остановиться в своих попытках что-то сделать. Это экономия нервов и времени.
Теперь у меня есть рабочая функциональность, но написано как-то коряво. Можно переделать.
Кроме того, мы не все тесты написали. У меня есть еще куча идей. Например, есть идея для следующего теста: если item повторяется в корзине, его стоимость учитывается в Total несколько раз. Или же если item предоставляется бесплатно, он не влияет на Total. Может быть, мне ничего для этого писать не придется (может быть моя логика уже покрыла это все), но я сделаю такие тестовые данные, чтобы потом тот, кто придет туда, не встретился с проблемами.

У нас нет времени, чтобы пройти через изначальное создание ShoppingCart. Когда он создавался, был очень важный момент: если в качестве первой реализации для него использовать, например, set, то вы просто не будете поддерживать количество item-ов. Вы добавляете новый, потом перетираете его и так далее. Там всегда один. И первоначально, когда вы только один уникальный item создавали, все кажется очень правильно: если item добавить, то он там. Вы добавили iPhone и iPad — и они оба там. Все круто. Но вы выбрали Set в качестве хранилища. А потом вы говорите, что есть же еще сценарий, когда я взял два iPad. Тогда ваш тест перестает работать — но покажет это только тот тест. Если же у вас такого сценария нет (нет его в бизнес-логике), не пишите такой тест, и тогда все будут понимать, что вы не знаете, как ведет себя система, если добавить два одинаковых item-а (вы ее не дизайнили на то, чтобы она поддерживала два одинаковых item-а).
На пути к какому-то API TDD позволяет вам попробовать, как он работает. Написали тест — посмотрели. Убедились, что все так, как вы хотели, и оставили этот тестик. Он теперь является описанием того, как это работает на самом деле.
Самое главное, на чем я хотел сосредоточиться в этой теме: TDD — это стиль работы, подход к самой разработке, а не только тестам. Он упрощает вашу разработку, позволяет меньше кода писать руками и получать более надежный код с более простым дизайном. Поэтому если вы хотите ускорится, попробуйте TDD. Но TDD не отменяет того, что у вас должны быть навыки хорошего дизайна. Потому что если вы будете генерировать первое, что в голову придет, а не то, что удобнее, никакой TDD вам не поможет. Магии нет. Но и сложности в этом никакой нет.
FTP
С тестированием FTP все мега-просто. Я бы рекомендовал, чтобы работать с FTP, использовать нормальный Java API и мокать (и тут мы возвращаемся просто к бизнес-логике).
Работа с настоящим FTP связана с множеством препятствий. И одно из них заключается в том, что вы надеетесь на внешнюю сеть и на всё, что связано с внешней сетью. Делать это не имеет ни малейшего смысла. Это очень важный принцип, который будет распространяться и на другие более высокоуровневые места, где мы используем моки. Как только вы мокируете какую-то внешнюю систему (это может быть внешний сервис, FTP в данном случае), вам необходимо написать еще 1 тестик. Он будет более интеграционным. И проверить, что этот ваш API хоть один файлик туда доставляет (чтобы не получилось описанной выше ситуации: когда всю систему подняли и она большим количеством юнит-тестов — в нашей прошлой системе было порядка 7 тыс. юнит-тестов только на уровне Java — говорит, что все круто, но не работает, т.к. ни один файлик не может туда добраться из-за неправильно прописанной конфигурации FTP). Такое случается. Поэтому вам нужен один интеграционный тестик на внешнюю систему. Если у вас его нет, убедиться в том, что вся система целиком заведется, физически невозможно.
Web-UI, mobile-UI, desktop UI, Swing
Я бы сказал, что мне повезло. Когда-то давным-давно я натолкнулся на Selenium. Он тогда был в бета-версии, но мне понравилась сама концепция, что можно реально запускать команды в браузере не с помощью внешнего инструмента, которому тыкать что-то через операционную систему, а напрямую. Это было реально круто. Поэтому еще с тех времен я проникся и по сей день остаюсь большим фаном Selenium.
Я был очень рад, что в какой-то момент Selenium слился с API WebDriver, а потом началась глобализация применения WebDriver повсеместно. И сейчас если вы тестируете Web-UI, практически все инструменты пытаются работать с браузером посредством WebDriver, т.к. WebDriver уже вот-вот окончательно станет стандартом W3C. Как только он станет стандартом W3C уже официально, все производители хороших браузеров (браузер — это достаточно соревновательная среда и все пытаются выделиться; если ты не поддерживаешь какой-то из стандартов W3C, то автоматически отстаешь от других) будут заботиться о том, чтобы WebDriver правильно, корректно и быстро выполнял команды в их браузере. На текущий момент этим занимается команда разработки самого Selenium-WebDriver, но не для всех браузеров. Например, Firefox уже сделан внутренний модуль под названием Marionette, который является реализацией API управления Firefox, поэтому всё достаточно красиво и аккуратненько. С Internet Explorer всё не так радостно, потому что его разработчики не делают для этого того, что должны. Тем не менее планы такие есть. И они в ближайшее время осуществятся, но понятно, только для последних версий браузера (Edge). Для других браузеров Internet Explorer (7-8-9) этого не будет — он по-прежнему будет работать через дополнительный прокси.
Чем это удобно? Тем, что WebDriver API очень простой. Команды примитивные — только те, которые вы можете формировать у себя с клавиатуры и мышки. Вы можете на что-то кликнуть или ввести какой-то текст. Все. Сложность в использовании WebDriver — это найти на странице того, по кому надо кликнуть или куда ввести. И для этого используются локаторы. Почему очень здорово, что этим могут заниматься разработчики? Когда это пишут тестировщики, у них есть проблема, что они не создают само приложение. И в итоге если приложение сделано хреново, и локаторы нельзя написать хорошо, то и тесты точно так же будут сделаны. Если вы разработчик и понимаете, что здесь можете сделать более удобную верстку, добавить айдишник в каком-то контейнере, чтобы за него можно было зацепиться в тестах, это здорово. Это значит, что ваши тесты будут гораздо более надежными.
К WebDriver существуют инструменты, которые обязан знать любой java-разработчик. Это инструменты, которые позволяют быстро начать использовать Selenium WebDriver.
Самый банальный пример — plug-in к Firefox, который называется Selenium IDE. Предположим, вы решаете задачу: у вас есть некая легаси-система и вам необходимо сделать рефакторинг для легаси-системы, чтобы поменять какой-то внутренний код. Как же убедиться, что легаси-система в этом сценарий продолжит вести себя так же, как было раньше? Понятно, что хотелось бы иметь тесты, но их нет. Но есть возможность написать сценарий достаточно быстро: включаем в режим записи, идем, например, на Яндекс, ищем jeeconf. Можно тут взять и сказать — assert title:
(здесь и далее вы увидите несколько «кривых» скриношотов, к сожалению, не все ужалось выразить в Java-коде)

Нашел 44 тыс. ответов. Кликнем на ссылку, перейдем на программу и проверим, например, что существуют оба дня.
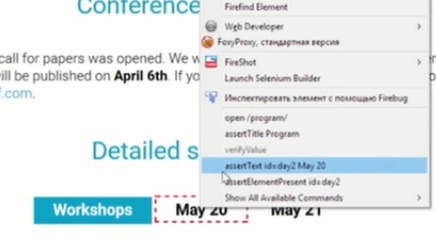
Идем в записанный тест, и что мы видим? Что у нас здесь записалось много всего интересного:
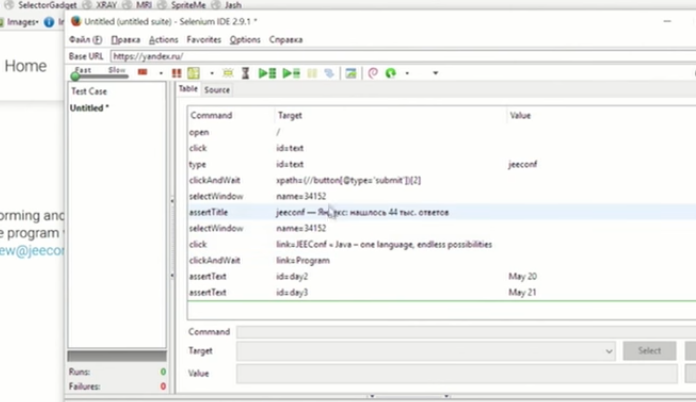
У нас записался клик, type текста, ожидание загрузки страницы и прочее.
Из Selenium IDE мы можем это запускать. А самый большой бонус в том, что вы можете поменять формат и сказать: «Я бы хотел это видеть в Java-коде с WebDriver», — и таким образом вы получаете ваши Java-команды:
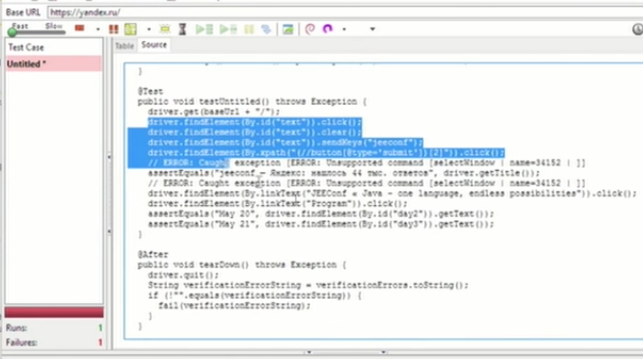
Далее вы можете уже перенести это в свой Java-код.
Это не очень хорошо, потому что здесь код достаточно грязный. И любой Java-разработчик, который один раз перенесет, поймет, что не очень качественно получается.
Есть другие плагины, например, Selenium Builder, который позволяет делать уже более хороший код. Но даже если вы не хотите переносить это как код, а хотите остаться в рамках того, что есть, вы можете просто использовать этот плагин, чтобы тестировать приложения. Даже просто для автоматизации ряда сценариев, с которыми вы связаны в своем приложении (если у вас веб-приложение).
Теперь вернемся к тому, что вы еще можете делать с Web-UI.
У Web-UI есть 2 части:
- непосредственно сам UI
- и логика, которая находится на стороне сервера (контроллера, если вы используете MVC-модель — в Java-мире это парадигма, которая используется повсеместно).
Если вы используете Spring MVC или иной MVC-фреймворк, хотелось бы максимально протестировать парадигму, чтобы не допустить там ошибок.
Mobile UI точно также тестируется с помощью Appium-а, который является «надмножеством» Selenium и позволяет делать все то же самое, только для мобильных приложений.
С desktop UI, к сожалению, все не так красочно. Вы сильно зависите от того, для какой платформы пишите десктопный UI. Однако есть новость буквально двухнедельной давности: Microsoft заявил поддержку WebDriver для тестирования UI, написанного под Windows. Т.е. этот же API будет поддерживаться для нахождения локаторов элементов для десктопа. Это вполне логично: все, что есть у тестировщика, — это клавиатура и мышка (сенсорный экран — в случае мобильного). Соответственно, не важно, какой UI мы тестируем. Юзер все равно пользуется мышкой и клавиатурой. Т.е. если он находит какой-то элемент, он либо кликает туда, либо вводит туда текст. Больше он с ним ничего сделать не может (перетягивание и прочее — все частные случаи этого). Именно поэтому понятие WebDriver очень хорошо: у вас есть один глобальный API и возможность подставлять разные его реализации под разные приложения, которые вы хотите тестировать. Если надо браузер — вы управляете браузером, если надо десктоп — вы управляете десктопом. Вы находите по локаторам определенные элементы и кликаете в них, вводите текст — делаете все, что вам нужно.
С тестированием Swing-а все очень хорошо. Т.к. Swing не генерит нативные элементы, а рендерит их самостоятельно, он знает, как это делается. Существует большое количество инструментов, которые позволяют сравнительно легко поднять компонент или все приложение и доступиться к нужному элементу. Мы писали одно Swing-приложение, которое полностью было написано по TDD и при этом полностью было покрыто тестами на сам свинговый UI. Подобные примеры вы можете найти в книжечке “Growing Object-Oriented Software, Guided by Tests” с примерами на Java. Там показывается, как сделать достаточно сложное приложение со сложной бизнес-логикой полностью с UI, написанным на Swing именно по TDD, и каким образом писать юнит-тесты, которые будут хорошо проверять, что отобразилось на UI и как оно отобразилось. Я вам настоятельно рекомендую почитать.
Еще один инструмент — Applitools. Он должен быть вам интересен, если вы сильно заинтересованы в тестировании веб-UI. Он предназначен для визуального тестирования. Разработчики Applitools создали свою очень мощную библиотеку, которая умеет хорошо анализировать изображение. И логика его работы основана на следующем: вы пишите некий навигационный сценарий, который проходит сквозь ваше приложение. И после каждого шага вашего сценария Applitools делает полный скриншот (т.е. он при необходимости скролит браузер). Набор скриншотов после первого прогона он предлагает использовать в качестве baseline (того, от чего будем отталкиваться).
Прошел день, вы сделали какие-то изменения в UI. Инструмент позволяет прогнать сценарий еще раз и сравнить с baseline. Это все можно сделать и самому (прошел — снял скриншоты). Но тут весь фокус в аналитике, которую делает упомянутая библиотечка. А делает она очень много всего. К примеру, она умеет различать, когда у вас вся картинка съехала на 1 пиксель (браузер отрендерил так пиксель). Для человеческого глаза это не видно, но если бы вы сравнивали скриншоты, у вас были бы проблемы. Или если инструмент нашел на всех ваших страничках, например, в Header-е или Footer-е какое-то маленькое отличие (например, у вас поехал текст или картинка заехала на текст), он его красиво подсвечивает и позволяет заапрувить после исправления на всех местах. Т.е. вы можете запросить все уникальные ошибки (иначе все 200 скринов отмечаются как инвалидные). Инструмент этот коммерческий, но стоит недорого. У него есть бесплатный триал, с помощью которого можно делать, если не ошибаюсь, до 50 скринов в день.
Подобный инструментарий — большой прорыв в тестировании UI-приложений, т.к. он тестирует не только текст или содержимое элементов на странице, а финальный UI. Если у вас есть приложение, которое обязано открываться в Internet Explorer (в трех версиях), в Firefox (в двух последних версиях), в Chrome, Safari, а также на iPad, iPhone с разными разрешениями экрана, протестировать его по-другому просто невозможно. Это надо иметь гигантскую команду тестировщиков, которые будут еще и экспертами в дизайне, чтобы понимать, что вообще должно происходить.
Последнее, что я хотел вам показать — MVC (на примере Spring MVC, но у всех остальных все ровно то же самое). В Spring MVC это все очень круто сделано. У вас есть понятие standalone setup, где я могу поднять просто мок MVC и зарегистрировать туда один свой контроллер:
private MockMvc mvc;
@Before
public void setUp () throws Exception {
mvc = standaloneSetup (new AuthLabsCallbackController
(jobResultListener)
.setUseSuffixPatternMatch (false)
.setUseTrailingSlashPatternMatch (false) .build ();
}Я здесь запускаюсь со специальным runner-ом, который понимает spring-овый контекст:
@RunWith(UnitilsJUnit4TestClassRunner.class)
В данном случае я говорю: «ок, вот у меня один контроллер, который я зарегистрировал». Сообщаю, какие суффиксы / префиксы использовать:
public void setUp () throws Exception {
mvc = standaloneSetup (new AuthLabsCallbackController
(jobResultListener)
.setUseSuffixPatternMatch (false)
.setUseTrailingSlashPatternMatch (false) .build ();И делаю build этого MockMVC.
Теперь с помощью MockMVC я могу делать такие штуки: могу проверять, что был успешный ответ, когда я сделал perform вот такой-то post с таким-то параметром:
assertSuccessResponse (mvc.perform (post ("/callback/123")
.param ("status", "SUCCESS")
.param ("rank_date", "2013-07-24")));Что входит в assertSuccessResponse?
private void assertSuccessResponse (ResultActions results) throws *******
results.andExpect (status() .isOk())
.andExpect (content() .contentType ("text/plain;charset= "utf-8");
.andExpect (content() .string ("OK"));Предположим, это был бы у меня rest-контроллер, который возвращал бы наружу JSON. Я бы мог, не запуская всего приложения, протестировать, что он возвращает JSON в правильном формате, что используются правильные application context, статус-коды и т.п.
Чего я не могу сделать в этом setup? Я не могу проверить, что у меня работают все дополнительные штуки, которые я наконфигурил в Spring (валидаторы, редиректы на JSP, на template и прочее), т.к. я пока поднял только свой контроллер. И для этого есть возможность поднять контекст и сделать тоже MockMVC, но с реальным веб-контекстом. Я могу поднять все контроллеры там и дергать их точно так же. Поэтому мне не надо даже тестировать это через браузер, чтобы убедиться, что я всегда отдаю все правильно. Эта задача становится все более и более актуальна, поскольку становится все меньше и меньше full stack девелоперов. Теперь в большинстве сложных проектов разработка разделена на back-end и front-end, потому что и там, и там по миллиону технологий и нельзя изучить оба миллиона, по крайней мере достаточно глубоко. Поэтому очень здорово, когда вы тестируете контакты между вами, т.е. тестируете, что у вас на контроллерах все хорошо.
Behaviour Driven Development (BDD)
BDD — это тоже стиль разработки, в котором вы отталкиваетесь от поведения системы. Когда я показывал TDD, я тоже отталкивался от поведения системы (писал, что хочу протестировать, что система будет обладать таким поведением).
Многие ошибочно полагают, что следование BDD подразумевает обязательное использование какого-то инструмента, вроде cucumber JVM и других, которые позволяют (благодаря дополнительному оверхеду) сделать из этого супер-красивые тесты на человеческом языке. И не дай бог они этот BDD начинают применять на уровне юнит-тестов. В итоге получаются супер-красивые юнит-тесты, каждый из которых пишется очень долго, упорно и кропотливо, но на эти отчеты никто не смотрит: на человеческом языке они никому не нужны. Девелоперу вполне достаточно кода.
BDD был задуман, чтобы объединить бизнес-людей с девелоперами. И это нужно только там, где вы тестируете некую грань вашего приложения, например, функциональные тесты.
API, которые тестируют, тоже могут быть написаны с помощью подхода BDD. И они нужны бизнесу, чтобы, читая отчет, он понимал, что именно мы покрываем, какие именно сценарии присутствуют в системе, чтобы в идеале дать бизнесу возможность в любой момент времени прийти и на обычном английском языке (или с помощью dictionary какого-то, в который вы уже забили достаточное количество операций) дать возможность написать свой тест.
Казалось бы, зачем бизнесу эту нужно? Бизнес придумал какой-то сценарий и хочет проверить, сработает ли он в текущей версии приложения. Что он вернет? Что произойдет? И он может запустить тест и увидеть, причем с помощью достаточно удобного API. Вот, что важно.
Поэтому ответ на вопрос «использовать или не использовать BDD» зависит от того, насколько у вас бизнес вовлечен в разработку. Если бизнес только выдает спецификацию, вам не нужен BDD. Он вам никак не поможет, лишь утяжелит разработку. Если бизнес хочет постоянно смотреть, что происходит, как развивается система, присутствует на всех планированиях, на демо, бизнесу можно предложить использовать BDD.
JMS
Большинство нормальных JMS-провайдеров позволяют работать в embedded-моде. Поэтому если вы очень хотите тестировать ваше приложение, которое интегрируется с ActiveMQ или с другим каким-то MQ, который написан на Java и позволяет работать в embedded mode, поднимайте его в embedded mode и работайте. Если вам не хочется работать в embedded mode, но при этом тестирование работы с JMS вам по-прежнему необходимо, все равно есть 2 выхода.
- первый вариант — вы наверняка имеете интеграцию с посылкой / получением сообщений посредством некого фреймворка. Например, вы используете Spring и сделали какой-то интерфейс MessageSender (или какой-то специальный Sender, который посылает ваши бизнес-сообщения). Плюс к этому у вас есть набор бинов, которые помечены как слушатели неких очередей. Вы можете исключить JMS из этой цепочки и дергать их напрямую, генерируя им то, что они должны получать. Это не очень хороший способ.
- Второй выход — использовать Mock JMS. И есть довольно много реализаций Mock JMS. JMS — это API, соответственно нет никакой проблемы сделать реализацию, которая работает целиком в памяти и просто говорит «прислали message» в такую-то очередь. Мы не сможем протестировать транзакционную модель, что у нас есть распределенная транзакция между базой и JMS. Поэтому взгляните на мой доклад c Jpoint 2015 (https://www.youtube.com/watch?v=ExjPxDxkmFo) по поводу того, что может быть вообще не JMS? Есть миллион разных вариантов, что можно использовать вместо JMS более легковесное. Возможно, они вашу задачу решат гораздо лучше.
База данных
На текущий момент у меня тут ответ один. В том или ином виде ситуация все равно сводится к DbUnit-у.
Для успешного тестирования баз данных вам нужны 2 вещи:
- некий механизм, с помощью которого вы сможете вставлять data set в базы данных;
- инкрементальный апдейт базы данных.
Для инкрементального апдейта базы данных существует много инструментов, я перечислю несколько. На прошлом проекте мы использовали DbMaintainer, на текущем проекте используем Liquibase. Еще один достойный внимания инструмент — Flyway.
Для чего это нужно? Чтобы существенно сэкономить время, необходимое на создание пустой базы данных. Потому что если с прошлого прогона ничего не изменилось, нет смысла создавать схему с нуля. Можно просто начинать работать на этой же схеме. Плюс хотелось бы иметь кросс-базность, чтобы можно было использовать разные базы данных. Мы, например, локально поднимаем все тесты в H2 — замечательная in-memory база данных, которая позволяет вам пользоваться урезанным синтаксисом других БД, что очень удобно. Вы говорите: «У меня Oracle, ничего специфического (типа деревьев) я не использую, поэтому будет хорошо работать на H2». И оно работает на H2. Если у вас используются какие-то специфические вещи, вы не сможете работать на in-memory БД, но тогда вы можете сделать RAM-диск для вашей БД и работать не менее быстро (вы поднимаете нормальный MySQL или Oracle, определяете директорию для хранения БД и эта директория будет в RAM-е, ведь тесты, которые вы пишите, не нуждаются в гигабайтах — мы сейчас не говорим про нагрузочные тесты).
Как выглядит тест?
Первый тест на то, что кто-то вставляет какие-то данные:
@Test
@ExpectedDataSet (“HibernateElectionDaoTest-candidateRegistered”)
public void candidateMayBeRegistered() {
Candidate candidate = new Candidate (“Alex”, “Usachev”);
candidate.setExperience (20);
Candidate registered = dao.register (candidate);
assertNotNull (registered);
assertNotNull (registered.getId());
}Тут у меня есть dao. Взял его из реального Spring контекста.
@Transactional
public class HibernateElectionDaoTest extends AbstractDbTest {
@SpringBean (“electionDao”)
private ElectionDao dao;Тест у меня Transactional (это значит, что каждый тест будет запускаться собственной транзакцией). Я ожидаю на выходе такой набор данных (открываем его):
<!DOCTYPE dataset SYSTEM “../../../../../db-schema/database.dtd”>
<dataset>
<CANDIDATE NAME = “Alex” SURNAME = “Usachev” EXPERIENCE = “20”/>
</dataset>Т.к. у меня автоматически по базе данных генерится DTD, я могу видеть все таблички — очень удобно забивать данные в XML-формате.

Теперь я говорю dao.register, после чего проверяю, что у зарегистрированного появился ID, а все остальное за меня проверяет ExpectedDataSet.
Когда я это делаю, мне не важно, что в базе данных: я вставляю какого-то уникального кандидата, и мне все равно, какой этот кандидат.
Теперь предположим, что нам надо вставить какой-то data set. В данном случае я проверяю, что «candidate is chosen from experienced only». У меня есть метод dao.findTheBestCandidate и действует правило, что кандидатом может стать только тот, у кого есть experience.
@Test
@DataSet (“HibernateElectionDaoTest-candidates.xml”)
public void candidateIsChosenFromExperienceOnly() {
Candidate theBestCandidate = dao.findTheBestCandidate();
assertEquals (1, (long) theBestCandidate.getId());
}
}Чтобы реализовать эту логику, я проверяю, что experience не ноль.
Далее — какой мне нужно data set? У меня есть «Алекс Усачев» — у него experience 20 лет и «Николай Алименков» — у него experience нет.
<!DOCTYPE dataset SYSTEM “../../../../../db-schema/database.dtd”>
<dataset>
<CANDIDATE ID = “1” NAME = “Alex” SURNAME = “Usachev” EXPERIENCE = “20”/>
<CANDIDATE ID = “2” NAME = “Mikalai” SURNAME = “Alimenkou” EXPERIENCE = «[null]”/>
</dataset>Что делает DBUnit? Сначала просто выполняет truncate таблички и вставляет 2 записи.
Когда я тестирую логику, которая работает только с табличкой кандидатов, мне не важно, что прописано в других табличках. Я работаю только с теми табличками, которые присутствуют в моем тесте. Поэтому это все хорошо и быстро работает. Я могу легко переключаться между in-memory и не in-memory базой данных. Кроме того, я могу посмотреть все SQL-запросы, экспериментировать с реализациями и делать еще много всего интересного.
В реальности встретиться с Николаем в Москве можно будет на JPoint 2017 (7-8 апреля 2017 года в Москве). В этот раз он представит доклад «Сделаем Hibernate снова быстрым». Зато в дискуссионной зоне на конференции никто не сможет остановить вас от обсуждения тестирования!
И как всегда, на JPoint есть целая куча крутых докладов практически обо всем из мира Java — обзор планируемых докладов представлен на сайте мероприятия.
А если вы из Украины и вам до JPoint не доехать, берите билеты на JEEConf.
