
У функционального программирования есть одна большая проблема — о нем очень непросто рассказывать. Попытки донести людям что-то с использованием терминов типа «зигохистоморфный препроморфизм» легко сводят неподготовленного слушателя с ума.

Марк Симан — автор популярной книги Dependency Injection in .NET, автор бесчисленных блог-постов. На DotNext 2017 Moscow Марк рассмотрел применение dependency injection в классическом объектно-ориентированном дизайне и объяснил, почему его необязательно (даже нежелательно) использовать в функциональном программировании. Следом за этим он наглядно показал, как использование приемов функционального программирования устраняет необходимость в использовании моков и стабов в модульном тестировании и позволяет полностью выбросить мусор из прямого перечисления зависимостей.
Под катом — перевод доклада и видео. Далее повествование будет от лица Марка.
Несколько лет назад я написал книгу «Внедрение зависимостей в .NET», и, так как название этого доклада гласит «От внедрения зависимостей к отказу от зависимостей», возможно, вы ждете, что я отрекусь от всего, что написал в этой книге, но этого не произойдет. Я доволен содержанием книги и думаю, что она предоставляет хорошее руководство по написанию объектно-ориентированных программ.
Внедрение зависимостей — это способ решения проблем, связанных с исходным кодом: например, снижение связности кода, разделение ответственности, улучшение тестируемости. Если вы пишете объектно-ориентированные программы, то внедрение зависимостей — хорошо изученный и проверенный путь к достижению целей, изложенных выше.
Однако примерно в то же время, когда я закончил книгу, я начал интересоваться функциональным программированием. В общем-то, это то, чем я сейчас занимаюсь большую часть времени, и поэтому меня иногда спрашивают, как я внедряю зависимости в функциональном программировании. Это как раз то, о чем и будет мой доклад.
Первая вещь, которую я хочу разъяснить, это то, что, если вы занимаетесь объектно-ориентированным программированием, то внедрение зависимостей — все еще действенный подход. Если же вы хотите решить проблемы с тестируемостью и разделяемостью в функциональном программировании, вы можете использовать одну из альтернатив, которые мы сейчас рассмотрим.

Первая — это частичное применение. Если вы уже знаете, что такое частичное применение, вы можете сейчас подумать: «Но вообще-то частичное применение очень даже функционально!» Это так, но мы будем использовать его таким образом, что оно будет не совсем функциональным. Вторая альтернатива — композиция функций.
Начнем с обзора объектно-ориентированного программирования. Рассмотрим подход внедрения зависимостей и причин того, почему оно является тем, чем является. Внедрение зависимостей, по словам Рунара Бьярнасона, это просто претенциозный способ передачи параметров, и, вероятно, в этом есть правда. В то же время, дело не только в этом, как мне кажется. Итак, является ли внедрение зависимостей просто передачей параметров или же чем-то большим?
Пример. Бронирование ресторана
Чтобы разобраться, я буду использовать один наглядный пример в течение всего доклада. Итак, мой любимый сценарий — система онлайн-бронирования в ресторане. Их существует немало, но мы можем представить, что нам нужно разработать еще одну.
Просто чтобы убедиться, что все понимают, о чем мы говорим: представьте, что вы хотите забронировать столик в ресторане. Вы находите сайт, или приложение, или что-то типа того, в нем есть форма, которую вы заполняете некоторой информацией. И да, кстати, это моя настоящая почта, раз уж она уже есть у спамеров, она должна быть и у вас. Не стесняйтесь писать.

При нажатии на кнопку «отправить» небольшой JSON будет отправлен POST-запросом на сервер. Некоторые люди называют это REST API. Итак, код, который мы рассмотрим — это код обработчика входящего POST-запроса с JSON. Чтобы убедиться, что все понятно, разделим алгоритм обработки на пять шагов.

- Проверка ввода, потому что JSON может иметь некорректную структуру.
- Если со структурой JSON все в порядке, мы можем послать запрос к базе данных, чтобы проверить, нет ли других броней на это время.
- Как только мы это узнаем, время выполнить код бизнес-логики, чтобы принять бронь или нет, в зависимости от наличия в ресторане свободных мест на это время.
- Если мы решили принять бронь, то четвертым шагом будет сохранение брони в базе данных.
- Создание HTTP-ответа.
Итак, это сценарий счастливого пути (happy path). Но не всегда все идет по плану, бывает, что где-то нужно «срезать углы». Например, если валидация провалится, нет нужды в том, чтобы проходить через все этапы, начиная с запроса к базе данных и так далее, но нам все еще нужно создать ответ. Также, если мы решим не принимать бронь, не нужно сохранять ее, но, опять же, необходимо создать HTTP-ответ.
Объектно-ориентированное программирование. Внедрение зависимостей
Начнем с рассмотрения того, как реализация выглядит в объектно-ориентированном подходе, так как нам нужно понять, почему внедрение зависимостей выглядит так, как оно выглядит.

Итак, раз мы занимаемся объектно-ориентированным программированием, начнем с написания класса ReservationsController, который наследуется от некоторого класса ApiController. Для тех, кому не все равно: это ASP.NET Web API. Но, на самом деле, нам не особо нужно понимать, как работает этот веб-фреймворк, поэтому что это не так важно. Так что это просто базовый класс.
Теперь, чтобы обработать этот входящий JSON, создадим метод Post с принимаемым аргументом типа ReservationRequestDTO. DTO — это просто небольшой объект передачи данных, C#-представление JSON-документа. Он содержит имя, адрес электронной почты и количество человек, так что это просто объект данных.
Итак, мы пытаемся понять, прав ли Рунар Бьярнасон в том, что внедрение зависимостей — это всего лишь претенциозный способ сказать «передай мне параметры». Сейчас нужно понять, как бы мы написали этот код таким образом, чтобы он делегировал часть работы некоторым сотрудничающим друг с другом объектам. Первый объект, который мы могли бы использовать, — это валидатор. Мы можем попросить валидатор проверить DTO и, если проверка провалится, отправить Bad Request. Код 400, вроде бы. Вы можете задаться вопросом, откуда у нас этот валидатор, и это то, что мы сейчас пытаемся понять. Я пройду еще немного по коду, и потом мы рассмотрим, как появляются эти объекты. Итак, это первый сотрудничающий объект.
Теперь, когда мы знаем, что DTO валиден, нам нужно преобразовать его в какой-нибудь объект предметной области. Так что я просто вызываю функцию mapper.Map. r — это просто сокращение для брони (reservation в оригинале). Я поленился, не стоит называть так переменные, это ужасно.
Если вам очень нравится предметно-ориентированное проектирование, вы могли бы внедрить то, что Эрик Эванс называет единым языком описания предметной области, в данном случае — предметной области резервирования ресторана. Представьте, вы заходите в настоящий ресторан и спрашиваете, есть ли у них столик на четверых. В некоторых ресторанах вам придется взаимодействовать с человеком, называемым метрдотелем. Так что мы введем объект maitreD, у которого мы можем спросить, может ли он принять данную бронь, и он вернет ID резервирования. Если ID равен null, мы вернем 403 Forbidden, иначе — 200 Okay. Это общая идея. Я не особый фанат использования null для контроля потока выполнения, но большое количество людей так делают, так что, думаю, это реалистичный пример.
Я говорил о пяти шагах, и некоторые шаги здесь пропущены, позже мы к этому вернемся. Сейчас важно другое: у нас есть три взаимодействующих объекта. Это валидатор, маппер и метрдотель. Так откуда же они взялись? Рунар Бьярнасон предполагает, что внедрение зависимостей — это просто претенциозный способ сказать «передавать параметры». Так могли бы мы просто взять три этих объекта и передать их в качестве аргументов в метод Post? К сожалению, это невозможно из-за того, как работают большинство современных веб-фреймворков, и этот не исключение. Когда веб-фреймворк видит POST-запрос к конечной точке /reservations, он будет рад вывалить всю информацию из HTTP-запроса и собрать все по соглашениям. Однако validator, mapper и maitreD не являются объектами времени исполнения, поэтому это не сработает.
Примечание переводчика: начиная с ASP.NET Core, зависимости уже можно передать прямо в параметры метода контроллера. Однако не все в восторге от этой возможности.
Так что следующее по предпочтительности — так же передать их как аргументы, но в конструктор класса. Так мы можем сохранить их в полях класса для последующего использования. Это называется внедрение через конструктор и это, по сути, то, как работает внедрение зависимостей.
Вы можете возразить, что это похоже на подмену понятий, потому что в данном классе контроллера мне приходится взаимодействовать с веб-фреймворком и играть по его правилам. Что, если бы у меня не было этих ограничений? Смог бы я тогда передать эти зависимости как аргументы метода?
Давайте погрузимся в код. Остановимся на объекте maitreD класса MaitreD. В этом классе определен метод TryAccept, принимающий на вход бронь и возвращающий nullable int. Давайте пройдемся по пропущенным шагам плана.
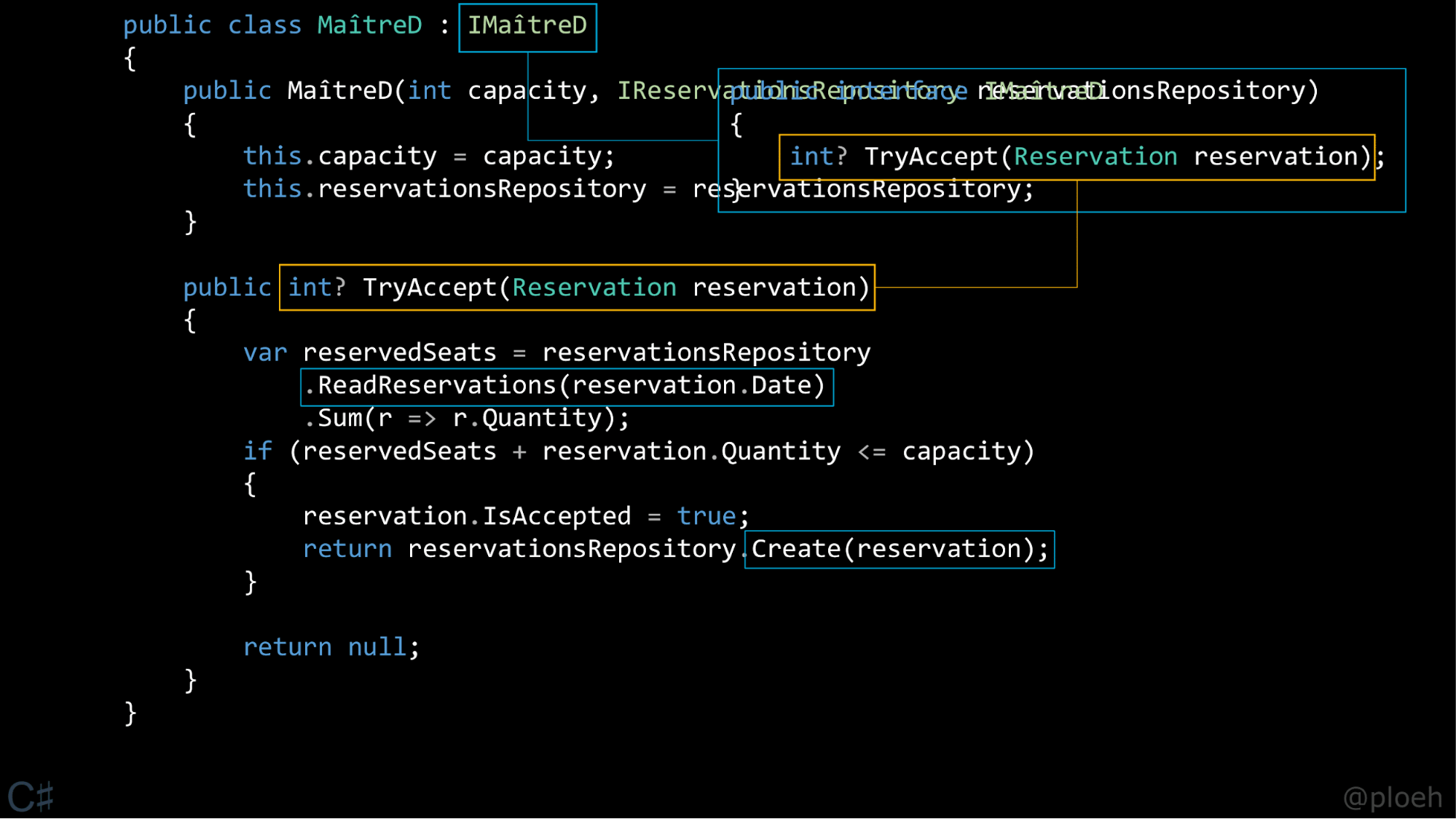
Первое, что нужно узнать, — это количество уже зарезервированных мест, поэтому мы взаимодействуем с репозиторием и просим его найти все брони на конкретную дату, и потом просто суммируем количество человек для каждого бронирования. Полученное число зарезервированных мест для определенной даты сохраняем в переменной reservedSeats. С этой информацией на руках мы можем принять бизнес-решение. Если количество уже зарезервированных мест плюс запрошенное количество меньше или равно вместимости ресторана, переменной isAccepted присваивается «истина» и вызывается метод reservationsRepository.Create, который возвращает ID строки в базе данных. Это значение будет преобразовано в nullable int. Иначе мы просто вернем null.
Здесь снова зависимости. Как минимум, это репозиторий, с которым мы взаимодействуем. И снова вы могли бы задуматься: «А не можем ли мы добавить этот репозиторий как дополнительный аргумент метода? Потому что, по словам Рунара Бьярнасона, это то, что мы можем сделать».
К сожалению, это снова не вполне рабочий вариант, потому что класс MaitreD должен реализовывать интерфейс IMaitreD, который определяет метод TryAccept с определенной сигнатурой.

И эта сигнатура не позволяет нам добавлять аргументы в метод. Так, если мы попробуем добавить репозиторий как дополнительный аргумент, программа не скомпилируется. Можно возразить, что, если мы владеем исходным кодом интерфейса, мы могли бы добавить репозиторий и в него, тогда бы все скомпилировалось. Технически это могло бы быть решением, но это привело бы нас к протечке абстракций, потому что факт, что данная реализация использует репозиторий и так далее, это детали реализации, и нам не нужно, чтобы эта переменная просачивалась.
Я думаю, эта абстракция на самом деле очень аккуратная: запрос брони приходит к нам с HTTP-запросом, и затем мы возвращаем ID брони в виде nullable int, если мы его приняли, и null в обратном случае. Абстракция хороша, и я не хочу ее портить. Так что нам снова придется воспользоваться следующим по предпочтительности вариантом и передать эти объекты, используя внедрение через конструктор. Внедрение зависимостей, как правило, так и работает повсеместно. Даже глубокие графы классов могут работать по принципу внедрения зависимостей через конструктор. Это причина, по которой мы используем внедрение зависимостей именно таким образом. Я считаю, что это хороший паттерн, потому что у нас есть абстракции, описываемые интерфейсами и реализуемые методами. Можно сказать, что все, что принадлежит абстракциям, является частью методов, конструкторы же представляют детали реализации. Это уже очень хорошее разделение ответственности, так что, я думаю, это довольно неплохой способ структурирования кода.
Итак, это был небольшой обзор внедрения зависимостей в объектно-ориентированном коде. Перед тем, как мы продолжим, я бы хотел обратить ваше внимание на пару вещей.
Первое, это то, что, как вы могли заметить, одна из зависимостей здесь — вместимость ресторана, и это просто целое число. Некоторые люди не воспринимают числа или другие примитивные типы, как зависимости, потому что они не являются объектами. Однако метод TryAccept зависит от этой информации, он не будет работать в отсутствие этой информации. Так что, я бы сказал, это вполне себе является зависимостью.
Далее, если мы взглянем на репозиторий и то, как мы с ним взаимодействуем, мы можем заметить, что в начале метода мы вызываем метод ReadReservations и секундой позже — Create. По сути, мы взаимодействуем с репозиторием только через эти два метода. Интерфейс IReservationsRepository может также содержать другие методы, но нам все равно, потому что мы не зависим от этих методов. Всё, от чего мы зависим, — это два метода и число, отражающее вместимость ресторана. Если мы попробуем декомпозировать все до объектов, которые нельзя более декомпозировать, у нас останутся три зависимости: два метода и число. Это станет важным через пять минут.
Как мне внедрять зависимости в функциональном программировании?

— Как мне внедрять зависимости в функциональном программировании?
В этом комиксе говорится о Scala, но вы можете заменить Scala на название любого другого функционального языка.
— Никак, потому что Scala — это функциональный язык.

— Хорошо, он функциональный. Как мне внедрить зависимости?
— Ну, используй свободную монаду, которая позволит тебе построить монаду из любого функтора.

— Ты только что послал меня?
— Думаю, да, Боб.
Да...
Как говорится, в каждой шутке есть доля правды. Потому что, во-первых, существует категория функциональных программистов, которые, если задать им этот вопрос, скажут использовать свободную монаду. И свободная монада действительно позволит вам построить монаду из любого функтора. Так что все это правда.
Также, если вы парень слева, этот ответ вам не особо полезен. Потому что: «Что такое свободная монада? Что такое монада? Что такое функтор?» Возможно, вам все это известно. Я не предполагаю, что вы знаете хоть что-нибудь из этого. Честно говоря, мне не особо хочется вдаваться в подробности. Все это верно, но в большинстве случаев вам все это не понадобится. В общем случае свободная монада — это действительно решение проблемы, но на практике чаще всего вам не нужно все так сильно усложнять.
Частичное применение. Попытка внедрения зависимостей в функциональном языке
Я собираюсь придерживаться значительно более простого подхода, который почти всегда работает. Если вы спросите, допустим, F#-программиста, как внедрять зависимости в F#, они скажут использовать так называемое «частичное применение». Я не предполагаю, что вы знаете, что такое частичное применение. Я расскажу вам по ходу дела, и мы посмотрим, как это соотносится с внедрением зависимостей. Возьмем код класса MaitreD, который мы видели на C#, и перепишем его на F#. Я не предполагаю, что вы хорошо знакомы с синтаксисом F#. Если знакомы, это хорошо, но я собираюсь предположить, что нет. Я объясню части кода, необходимые для понимания.

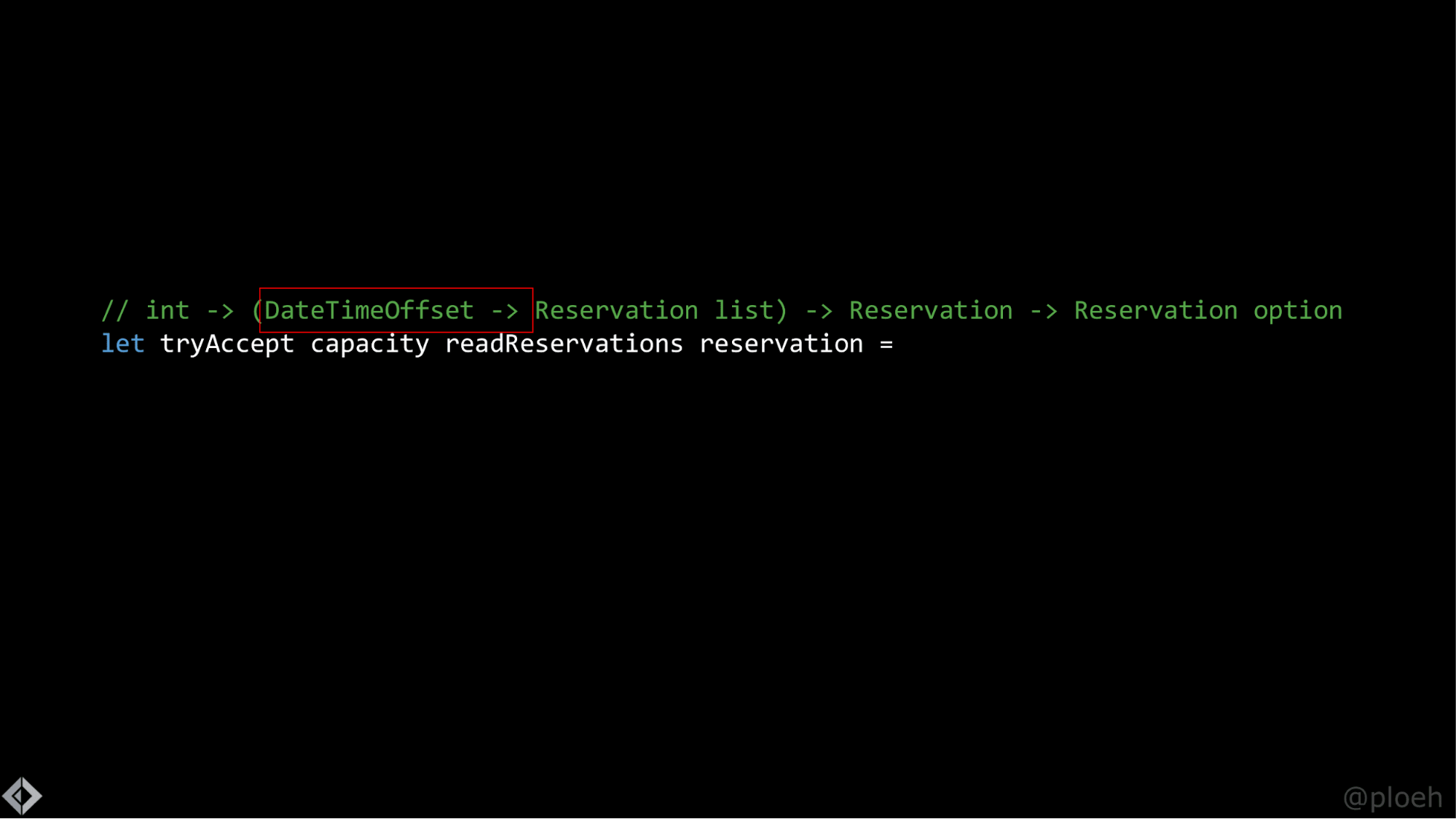
Это функция в F#, в комментарии в первых двух строках описан ее тип. Третья строка начинается с let tryAccept. tryAccept — это имя функции. Вы можете представить, что она находится в модуле MaitreD. Так что, по сути, она делает то же, что и метод TryAccept в объекте MaitreD. Далее мы видим: capacity, readReservation, createReservation и reservation — это всего лишь аргументы функции. В F# не используются скобки вокруг аргументов метода или запятые между ними. Вместо этого просто используются пробелы, и это нормально.
Итак, это функция, которая принимает четыре аргумента, и мы можем попробовать понять, что это за аргументы. Согласно комментариям, первый — это int. Следовательно, capacity — это целое число, что полностью соотносится с зависимостью capacity, которая была ранее. Это просто вместимость ресторана, целое число.
Следующий аргумент назван readReservations, в комментариях он в скобках: DateTimeOffset, стрелочка, Reservation list — это функция, которая принимает DateTimeOffset и возвращает Reservation list. Цель здесь сделать запрос к какой-нибудь базе данных, чтобы она вернула список бронирований, соотносящихся с конкретным значением типа DateTimeOffset. Мы передаем функцию как аргумент другой функции, это абсолютно нормально для функционального программирования. И если вы занимались разработкой на C# последние десять лет, вы знаете, как это делать в C#, потому что вы наверняка работали с лямбда-выражениями в Linq.
Третий аргумент называется createReservation, и это тоже функция. Она принимает на вход бронь и возвращает int. Её цель — добавить переданную бронь в базу данных и вернуть ID созданной строки.
Вы могли заметить, что две функции, которые я передал как аргументы, по сути играют ту же роль, что и репозиторий, который мы видели до этого. Мне просто не хотелось делать дополнительную работу и определять интерфейс, потому что мне нужны только эти две функции, которые я могу передать как анонимные зависимости. Так намного проще.
Четвертый аргумент — само резервирование, которое мы можем принять или нет. И последняя строка комментариев гласит «int option». По сути, это значит: «Я хочу, чтобы функция возвращала что-то, что называется int option». Это похоже на nullable int за исключением того, что option является типобезопасным, а все, что включает null в C# — нет. Null ужасен, а options — нет. Извините, это другая тема…
Итак, я хочу проделать всё те же шаги, что вы уже видели в C#-коде до этого. Первым делом нам нужно найти количество уже зарезервированных мест. Начнем с вызова функции readReservations с датой резервирования. Вы можете заметить, что справа от reservation.Date находится вертикальная черта и знак «больше». Это оператор конвейерной обработки (pipe-оператор). Если вы когда-нибудь использовали PowerShell или Bash, вы, вероятно, уже знаете о таких операторах. По сути, это значит просто «возьми значение выражения слева и используй как аргумент в выражении справа». В этом случае мы вызываем функцию readReservations с датой резервирования, она возвращает список резервирований, который потом используется как аргумент функции List.sumBy, которая просто суммирует по количеству человек в бронированиях. reservedSeats — это просто число, так же как и в C#-коде, который мы видели ранее. Это просто один из способов написания кода. Однако вы будете видеть |> в F# всякий раз, когда будете читать код на F#, а также в этом докладе.
Теперь, когда у нас есть вся нужная информация, мы можем принять решение. Мы пишем такой же блок if-then-else, как и до этого. В случае истинности условия мы вызываем функцию createReservation с резервированием, и она вернет ID строки, которая была создана в базе данных. Вероятно. Затем мы передаем это число в Some. Some значит, что это Option, которое действительно содержит значение. В последней строке else None мы просто возвращаем None, что значит, что значение отсутствует.
Теперь у нас есть функция, которая принимает четыре аргумента, и, я надеюсь, вы видите, что первые три аргумента соотносятся с зависимостями, которые у нас были в объектно-ориентированном коде. Можно подумать: «Ага, в функциональном программировании внедрение зависимостей это просто передача аргументов. Похоже, Рунар Бьярнасон все-таки был прав».
Итак, есть функция, которая принимает четыре аргумента, три зависимости как объекты времени исполнения. Как же теперь написать композицию? Если вы помните, интерфейс IMaitreD определял метод tryAccept, который принимал бронь и возвращал nullable int. Я бы хотел создать здесь подобную абстракцию, например какую-то композицию, которая принимала бы на вход бронь и возвращала бы int option. Это возможно.
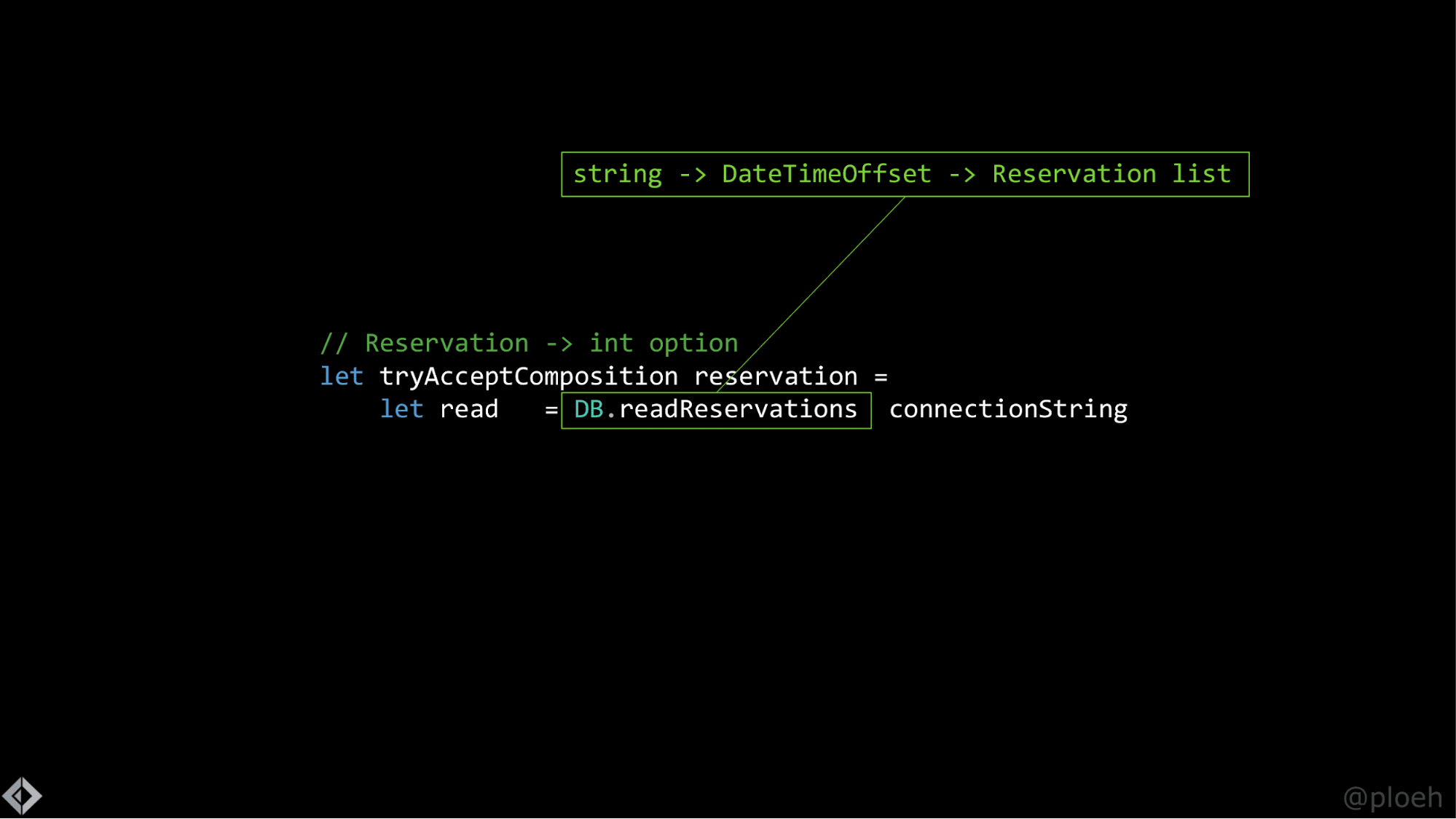
Представьте, что у нас уже есть модуль DB, который содержит код, позволяющий общаться с настоящей базой данных. Скажем, функция readReservations с типом string -> DateTimeOffset -> Reservation list. Это читается как функция с двумя аргументами, первый из которых является строкой подключения, второй — DateTimeOffset, которая возвращает список броней Reservation list. Допустим, у нас уже есть строка подключения (прочитали ее из файла конфигурации или типа того). Что будет, если мы вызовем функцию, которая принимает два аргумента, только с одним аргументом?
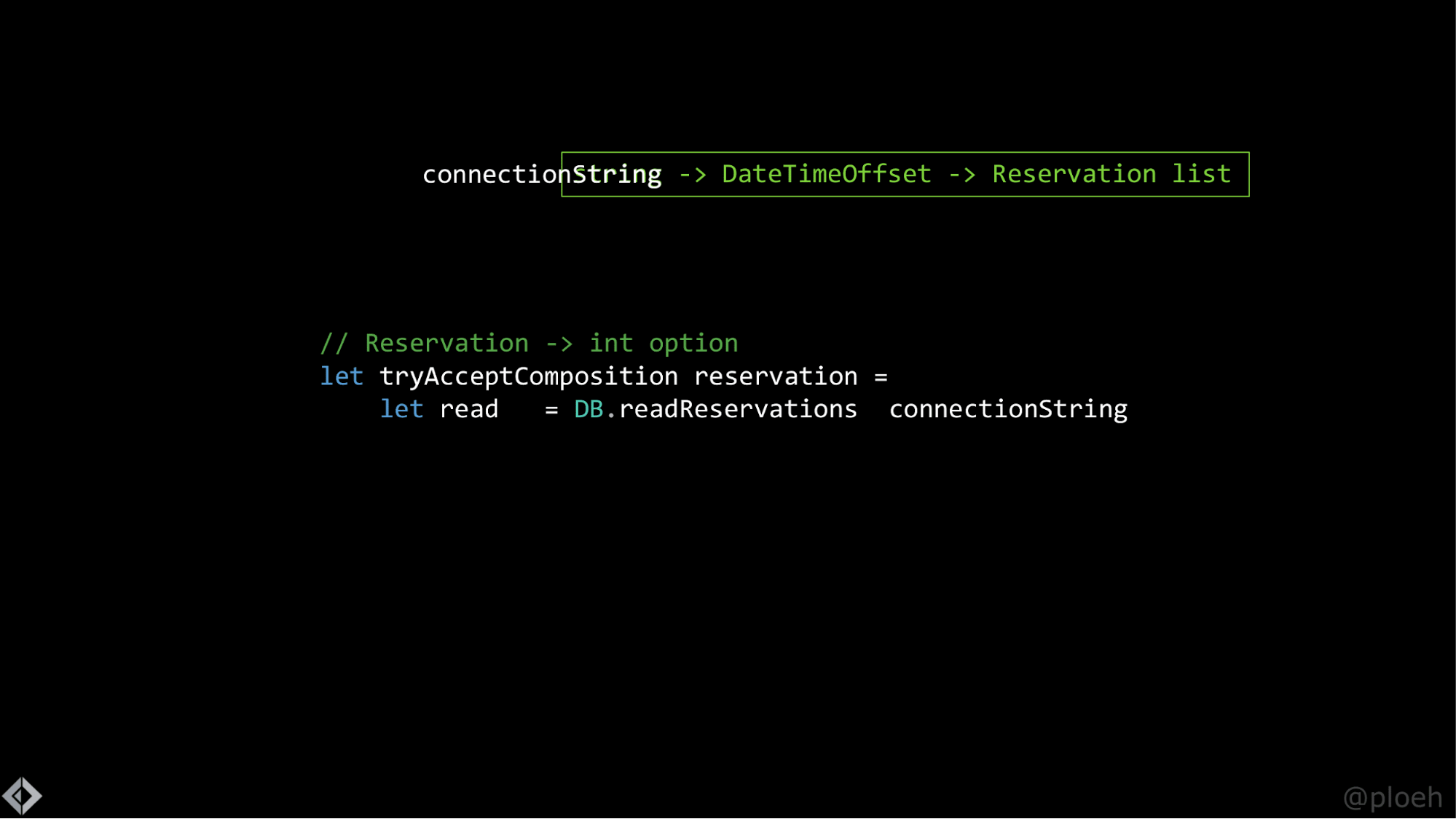
Так можно сделать, можно вызвать ее только со строкой подключения, и это сработает. Это то, что вы не сможете сделать в C#, и это называется частичным применением. Вы частично применяете функцию. Вы вызываете функцию только с частью аргументов.
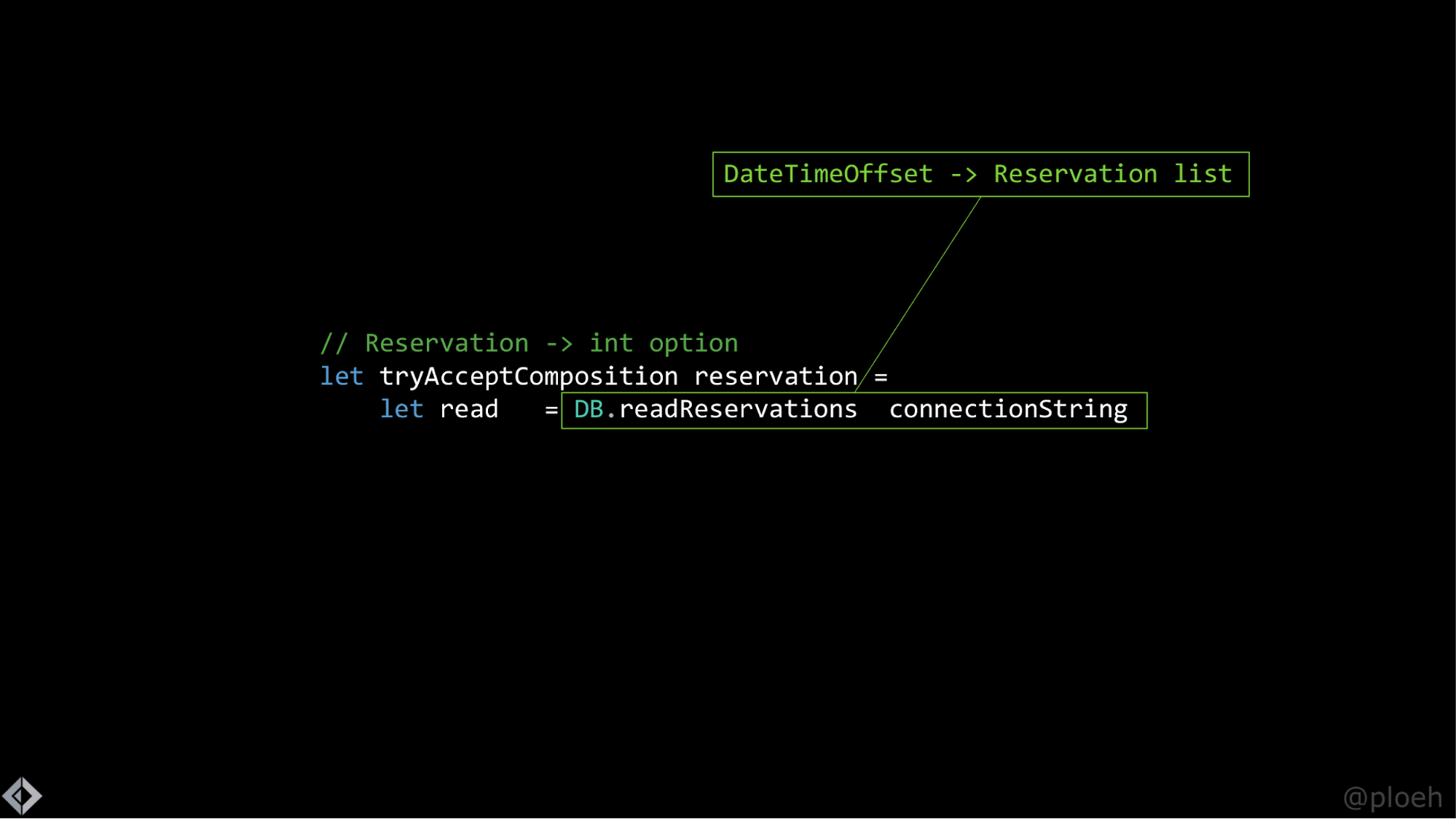
Из этого вы получите новую функцию, которая запомнила аргументы, которые вы передали, и все еще ожидает оставшиеся. Так что эта функция все еще ждет значение DateTimeOffset, и как только вы передадите ей это значение, она вспомнит строку подключения и вернет вам список бронирований. То же самое проделываем с функцией createReservation, частично применяя ее и получая функцию, которая принимает резервирование и возвращает число.
Если вы пишете на JavaScript, то частичное применение доступно с помощью вызова функции bind.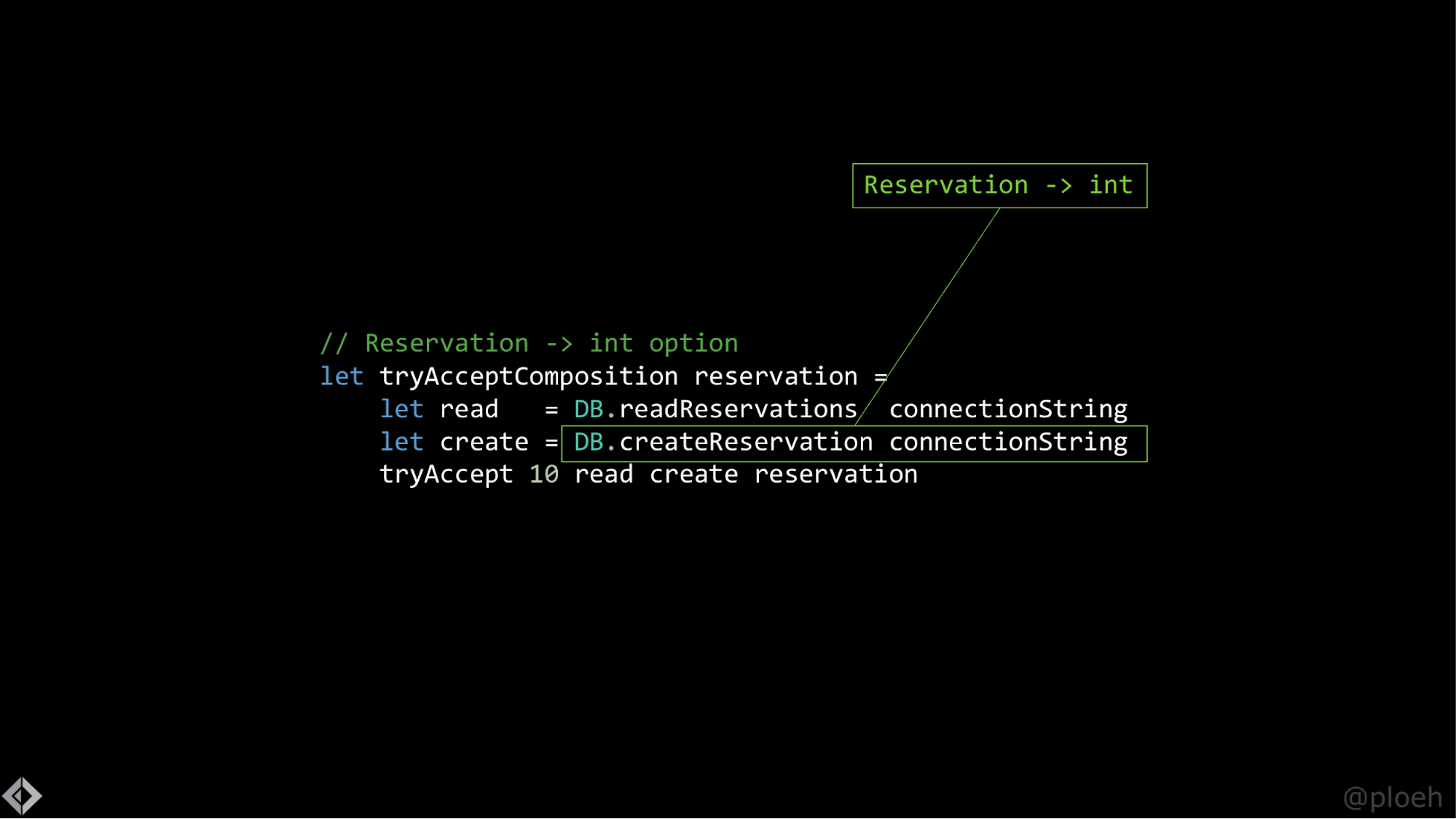
Теперь у нас есть функции read и create, и мы можем вызвать tryAccept со всеми четырьмя аргументами. Я просто захардкожу вместимость ресторана константной 10. Очень маленький, очень интимный ресторан. Такие существуют, правда. Итак, я просто напишу tryAccept 10 read create reservation. Это вызов функции. tryAccept — это функция, которая принимает четыре аргумента, и я предоставляю ей эти аргументы. Последняя строка кода просто вызовет функцию, и затем все выражение вернет значение из tryAccept.
В F# нам не нужно явное ключевое слово return, просто последнее выражение становится возвращаемым значением. Так как tryAccept возвращает int option, вся композиция также возвращает int option. Это работает в точности так, как вы ожидаете, как делает то же, что и композиция в C#, которую мы видели ранее.
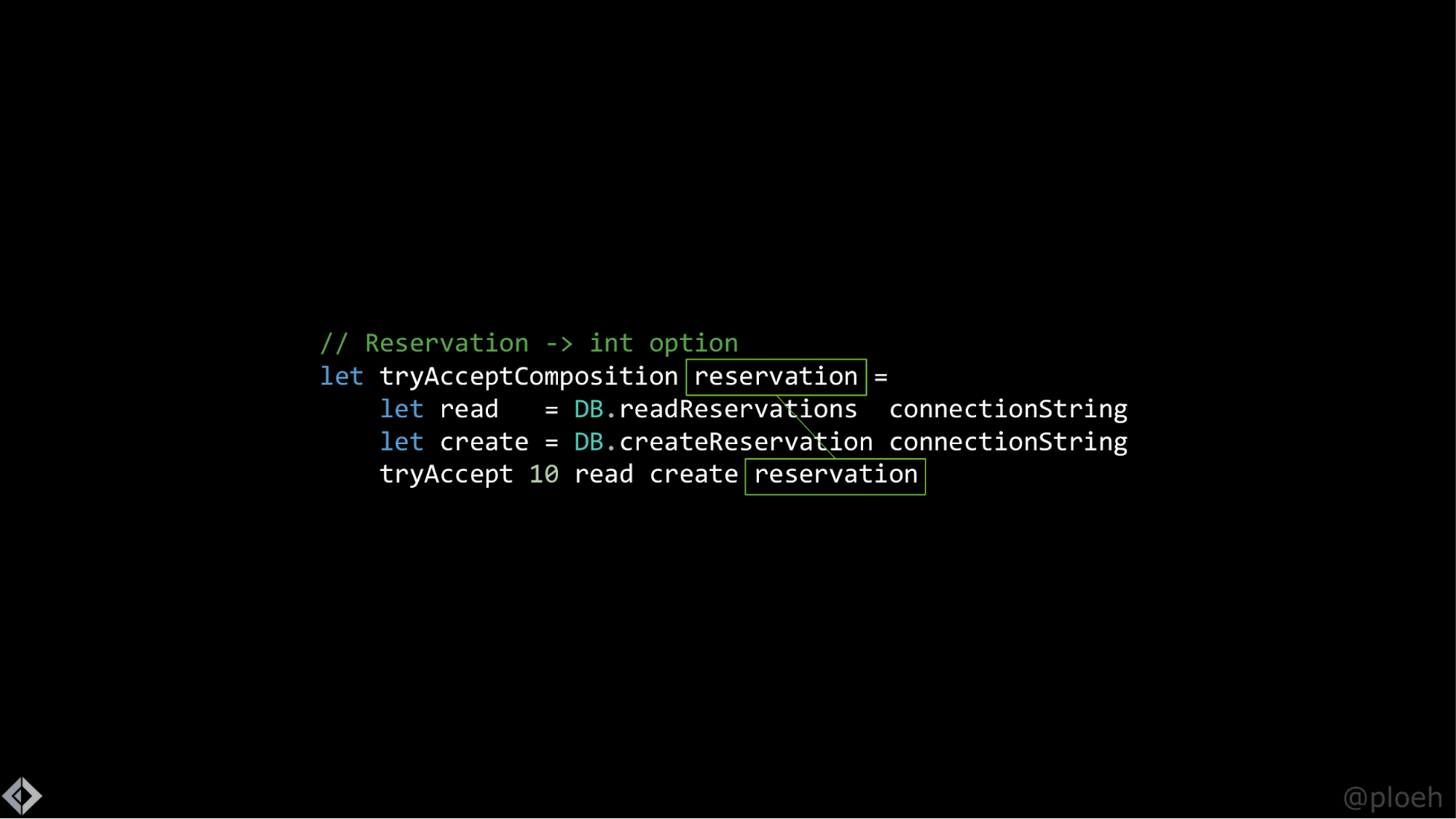
Теперь сделаем кое-что интересное. Переменная reservation стоит по обе стороны знака равно. И иногда функции F# похожи на функции в математике: если есть что-то по обеим сторонам знака равенства, мы можем попробовать убрать это. Правила слегка различаются в F# и других языках, но в данном случае мы можем произвести так называемую β-редукцию и убрать оба упоминания reservation.
Причина, по которой это интересно — это последняя строка, в которой говорится tryAccept 10 read create. В ней функция, ожидающая четыре аргумента, вызывается с тремя, так что это — частично примененная функция. Я применил все зависимости, но она все ещё ждёт переменную. Это очень похоже на то, что мы проделывали с внедрением зависимостей.
И самое интересное: если вы возьмете этот код на F#, скомпилируйте его в IL, а затем декомпилируйте в C#, чтобы понять, что этот IL представляет собой, и вы увидите что-то такое.
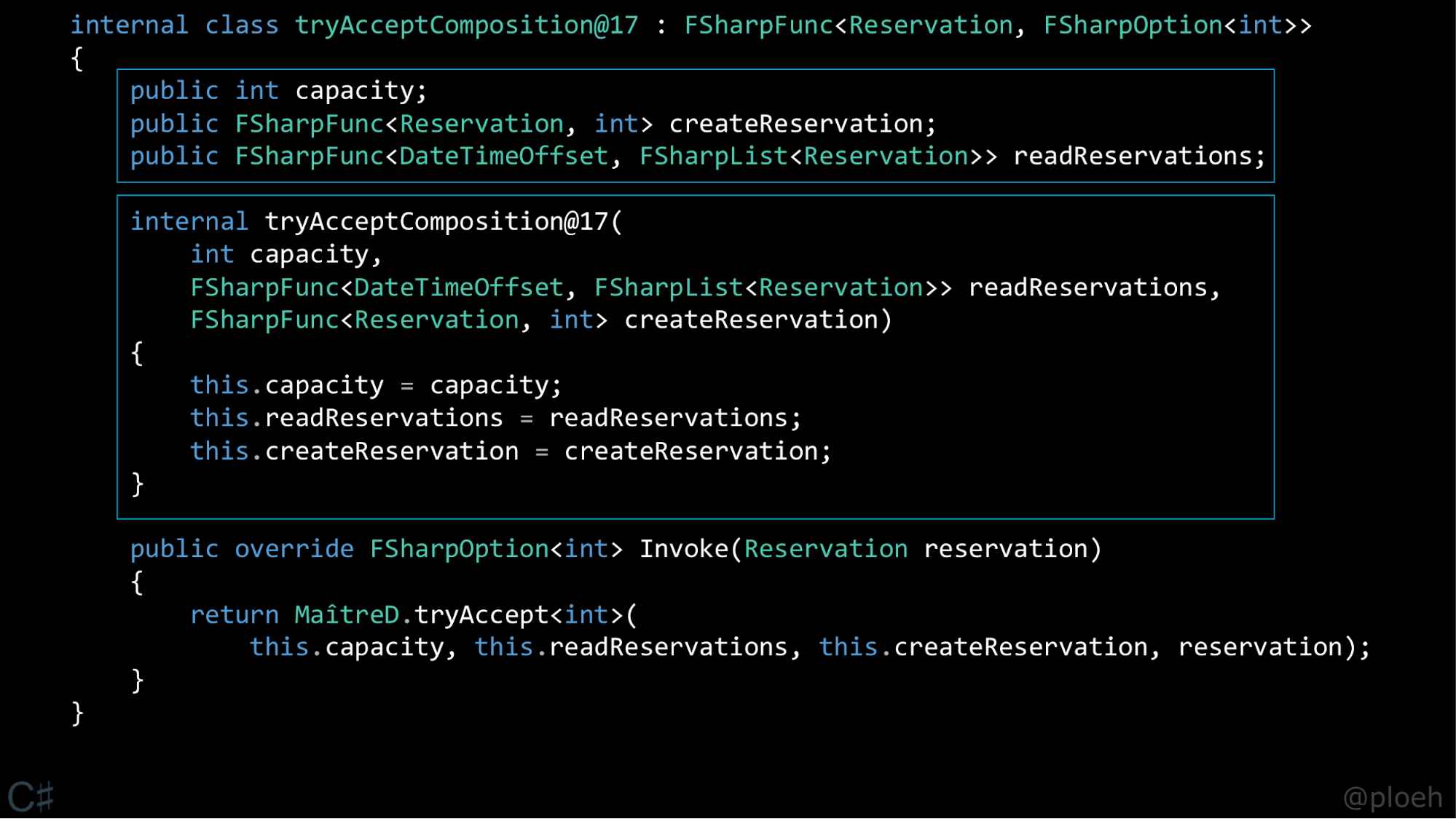
Вы получите класс со смешным названием, который мне пришлось слегка подправить, изначально он выглядел не так симпатично. Заметим кое-что еще. Во-первых, в классе имеется три поля: capacity и две функции. Также у класса есть конструктор, который принимает три аргумента и сохраняет их значения в поля класса. И, наконец, метод Invoke, который берет эти поля и переменную reservation и передает их в функцию tryAccept. Это очень похоже на то, что мы уже видели раньше, — внедрение зависимостей. Это даже не «что-то похожее» — это то же самое, это компилируется в тот же IL.
Это функционально?
Это довольно интересно. Итак, если вам было интересно только, как внедрять зависимости в F#, то вот ответ: просто используйте частичное применение. Мы знаем, что это работает, потому что мы использовали внедрение зависимостей в .NET на протяжении многих лет, это компилируется в тот же IL, так что должно работать так же хорошо. Здесь никаких отличий.
Мы могли бы остановиться на этом и сказать: «Что ж, у меня есть ответ на интересовавший меня вопрос, пойду-ка я домой». Знаете, иногда, когда я говорю о программировании на F#, люди спрашивают: «Как понять что мой код на F# функционален?» Иными словами: «Наш код функционален?» Как вообще можно понять, что код функционален? Во-первых, нужно установить, что мы имеем в виду под функциональностью.
Я расскажу про свои критерии «функциональности». Большинство людей скажут, что дело в неизменности или типа того, но мне кажется, что есть более фундаментальный способ определить «функциональность».
Чистые функции
Итак, в функциональном программировании любят чистые функции, это функции, которые обязаны подчиняться двум правилам:

Первое — при одинаковых входных значениях всегда возвращается одинаковый результат. Звучит разумно. Это интуитивно понятно, если рассматривать математические функции. Если вы складываете два числа, два плюс два всегда равно четыре. Если вы хотите развернуть строку, перевернутое «foo» — это всегда «oof». Это детерминированные функции.
Но мы довольно строги в своем определении детерминированности. Давайте рассмотрим другой пример. Представим, что у нас есть функция readReservations, которая делает запрос к базе данных по определенному отрезку времени и возвращает количество уже существующих броней. Допустим, мы вызываем readReservations для 1 декабря 2017. Если бы мы вызвали ее вчера, она вернула бы, например, 5. Интересно, что произойдет, если мы вызовем ее сегодня. Итак, мы вызвали ее снова для 1 декабря 2017 и она вернула 8. Любому, кто когда-либо занимался разработкой с применением баз данных, понятно, что произошло: кто-то добавил еще одну бронь в базу данных, ее состояние изменилось. Теперь мы получаем новый ответ, отличный от вчерашнего.
Но это все равно не считается детерминированным поведением. Зная, как работают базы данных, мы могли бы сказать, что поведение детерминировано, потому что зависит от состояния базы данных, но база данных не рассматривается как часть функции, она вне функции. Так что эта функция не считается детерминированной. Вы не можете делать запросы к базам данных внутри чистых функций, вы не можете читать содержимое файлов, вы не можете читать пользовательский ввод, потому что все это не детерминировано.
Но все становится даже хуже, потому что другое правило для чистых функций — никаких побочных эффектов. Побочный эффект — это все, что меняет наблюдаемое состояние системы. Если вы хотите добавить строку в базу данных — это побочный эффект. Если вы хотите послать сообщение — это побочный эффект. Если вы хотите поменять цвет пикселя на мониторе — это побочный эффект. Так что вы не можете сделать ничего из этого тоже.

Сами по себе чистые функции совершенно бесполезны. Вы не можете даже вызвать их, потому что они настолько ограничены. Мы знаем это. Функциональные программисты все же не архитекторы башни из слоновой кости, мы понимаем, что сами по себе чистые функции не особо полезны. Они имеют много других положительных качеств, и поэтому мы предпочитаем их, но мы понимаем, что нам также нужны «нечистые» функции. Так что же такое нечистые функции? Это обычные методы. Из C#, Java или откуда-либо еще, для нечистых функций нет правил. С ними вы можете делать все, что угодно. Пара вещей в функциональном программировании, которая относится к чистым и нечистым функциям:
- Мы хотим максимизировать количество чистого кода и снизить количество нечистого кода, потому что чистые функции имеют много положительных качеств.
- Есть правила взаимодействия чистых и нечистых функций. Если у нас есть две чистые функции, мы можем вызвать одну из другой, потому что это не изменит то, что вызывающая функция является чистой, и вторая тоже чистая. Они всё так же не будут иметь побочных эффектов и будут детерминированными. Если у вас две нечистые функции, одна из них может вызывать другую, потому что для них нет правил. Это также значит, что вы можете вызвать чистую функцию из нечистой. Однако четвертая комбинация невозможна, это не разрешено. Вы не можете вызвать нечистую функцию из чистой, потому что в обратном случае чистая функция стала бы нечистой. Она имела бы побочный эффект или была бы не детерминирована, так что это невозможно.
Это были мои критерии функциональности кода. Если код следует этим правилам, то он функционален. Если не следует, то, вероятно, он не функционален.
Самодиагностика (sanity checks)
Было бы здорово, если бы был инструмент, который мы могли бы запустить на нашем коде и который бы определил, следует ли наш код этим правилам. Такого инструмента на самом деле нет, потому что проблема F# в том, что это очень дружелюбный язык. Это очень продуктивный язык, его основной фокус в том, чтобы ваш код работал. Если вы хотите заниматься функциональным программированием, он будет счастлив предоставить такую возможность. Если вы хотите заниматься объектно-ориентированным программированием, вы можете делать это с тем же успехом. Так что он не особо озабочен правилами, скорее он просто заинтересован в том, чтобы вы были продуктивны. Очень дружелюбный язык, но не сильно жесткий.
Так что нет никакой возможности сделать такую проверку на F#, но, оказывается, есть небольшая лазейка, если вы напишете свой F#-код в достаточно функциональном стиле. Вы можете переписать свой код с Haskell на F#, потому что Haskell фактически настаивает на правиле разделения чистых и нечистых функций. Давайте посмотрим, как это выглядит.

Я также не предполагаю, что вы свободно читаете код на Haskell, так что я объясню основные моменты. Самая важная деталь функции tryAccept — это верхняя строка, которая просто объявляет тип функции. Здесь кое-что изменилось. Вместо DateTimeOffset теперь ZonedTime; список бронирований описан не как Reservation list, а как [Reservation]. Квадратные скобки в Haskell означают просто список этого типа. И вместо int option у нас теперь Maybe int, но это, по сути, то же самое. Всё остальное очень похоже на то, что было раньше.
Интересно, что эта функция является чистой. Мы знаем это потому, что все функции в Haskell по умолчанию чистые, так что если вы явно не объявите их нечистыми, по умолчанию они будут чистыми. Я позже покажу, как явно указывать, что функция является нечистой. Эта функция же является чистой, так как не указано иное. Не только эта функция, но и две функции, которые мы внедряем, тоже являются чистыми, что видно в той же строке аргументов. Так как не объявляется, что они нечистые, следовательно, они чистые.
Итак, у нас есть чистая функция, которая принимает четыре аргумента, можем ли мы всё ещё сделать композицию? Нам нужна композиция, чтобы посылать запросы и обновлять базу данных, и мы знаем, что это невозможно сделать с чистой функцией, так что композиция должна быть нечистой функцией. Это нормально, потому что входная точка программы Haskell всё равно всегда является нечистой.

Чтобы явно объявить композицию нечистой, мы должны добавить возвращаемый тип IO. Так что она возвращает не Maybe Int, a IO (Maybe Int). Эти две буквы IO показывают, что функция является нечистой.
Примечание переводчика: Эти две буквы IO показывают, что это монадический тип IO, но речь в докладе не о монадах, а о внедрении зависимостей. Подробнее матчасть монад в Haskell в статье Еще Одно Руководство по Монадам.
Мы можем попробовать проделать то же самое, что мы делали в F#: взять модуль DB, частично применить функцию readReservations со строкой соединения и получить функцию, которая принимает ZonedTime и возвращает IO [Reservation]. IO — потому что эта функция не детерминирована, когда мы вызываем ее, она может повлиять на ответ, который мы получим, поэтому она является нечистой. То же самое с createReservation: если частично применить ее со строкой соединения, мы получим функцию, которая принимает Reservation и возвращает IO Int. IO — потому что у нее есть побочный эффект: она создает строку в базе данных.
Давайте резюмируем: мы можем попробовать сделать композицию, как мы делали раньше, что нам для этого нужно? Итак, read должна быть функцией из ZonedTime в Reservation list, create — из Reservation в int. Вы могли заметить, что типы не совпадают. Вы могли бы спросить, нельзя ли как-то убрать IO, чтобы всё магическим образом заработало. Нет. В этом вся суть. Это не компилируется. Это разные типы, и на то есть причина: таким образом Haskell навязывает правило, по которому мы не можем вызывать нечистые функции из чистых. Мы не можем передать нечистую функцию в чистую и ожидать, что она сможет как-либо ее использовать, а это то, что мы пытаемся здесь сделать.
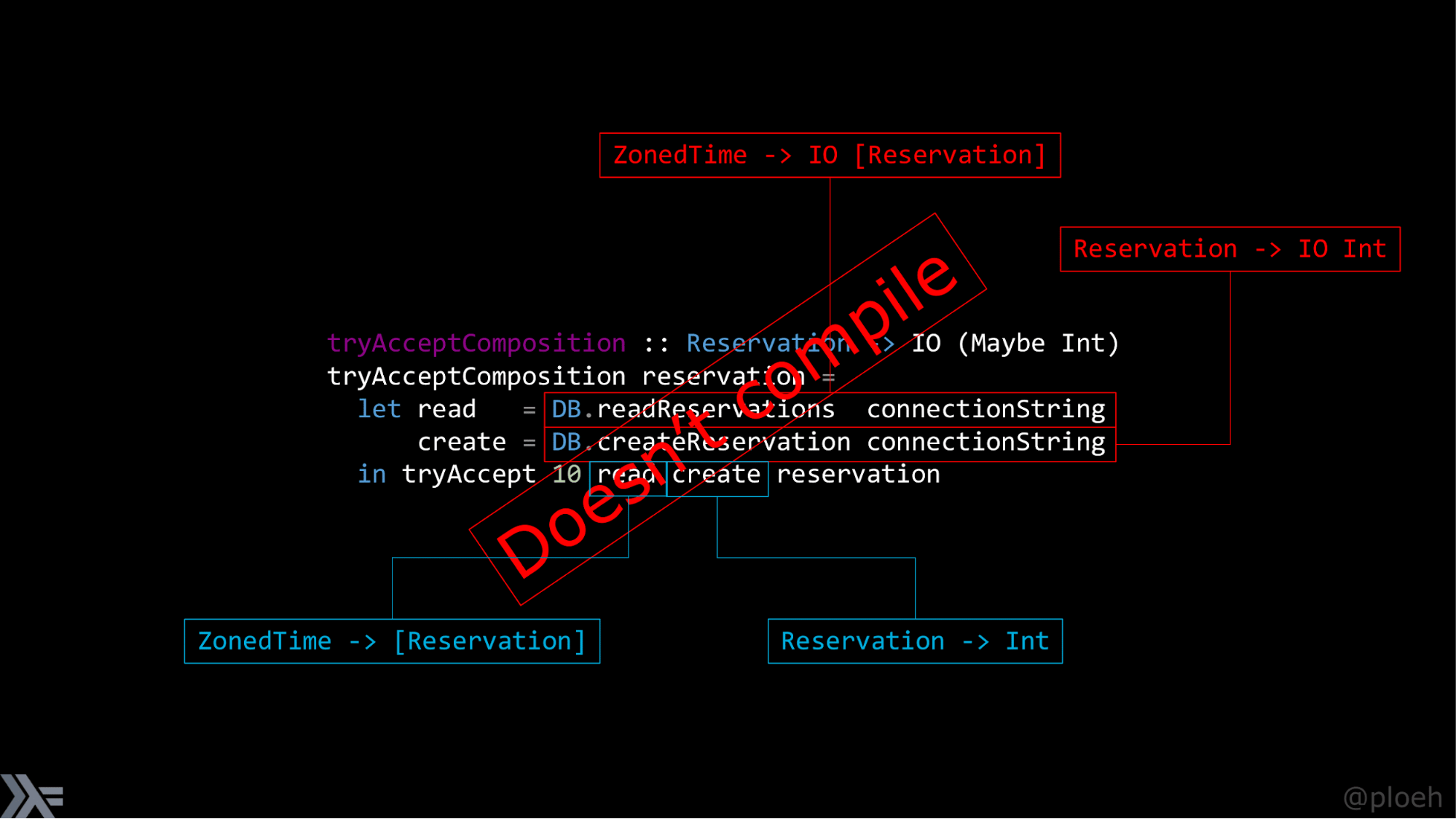
Это не функционально
Таким образом, частичное применение в F# по факту не является функциональным. Мы не можем переписать любой F#-код на Haskell, который очень строг с функциональностью. Он совершенно неумолим, что делает его таким красивым языком.

Чтобы понять, в чем проблема, давайте представим внедрение зависимостей в виде графа.
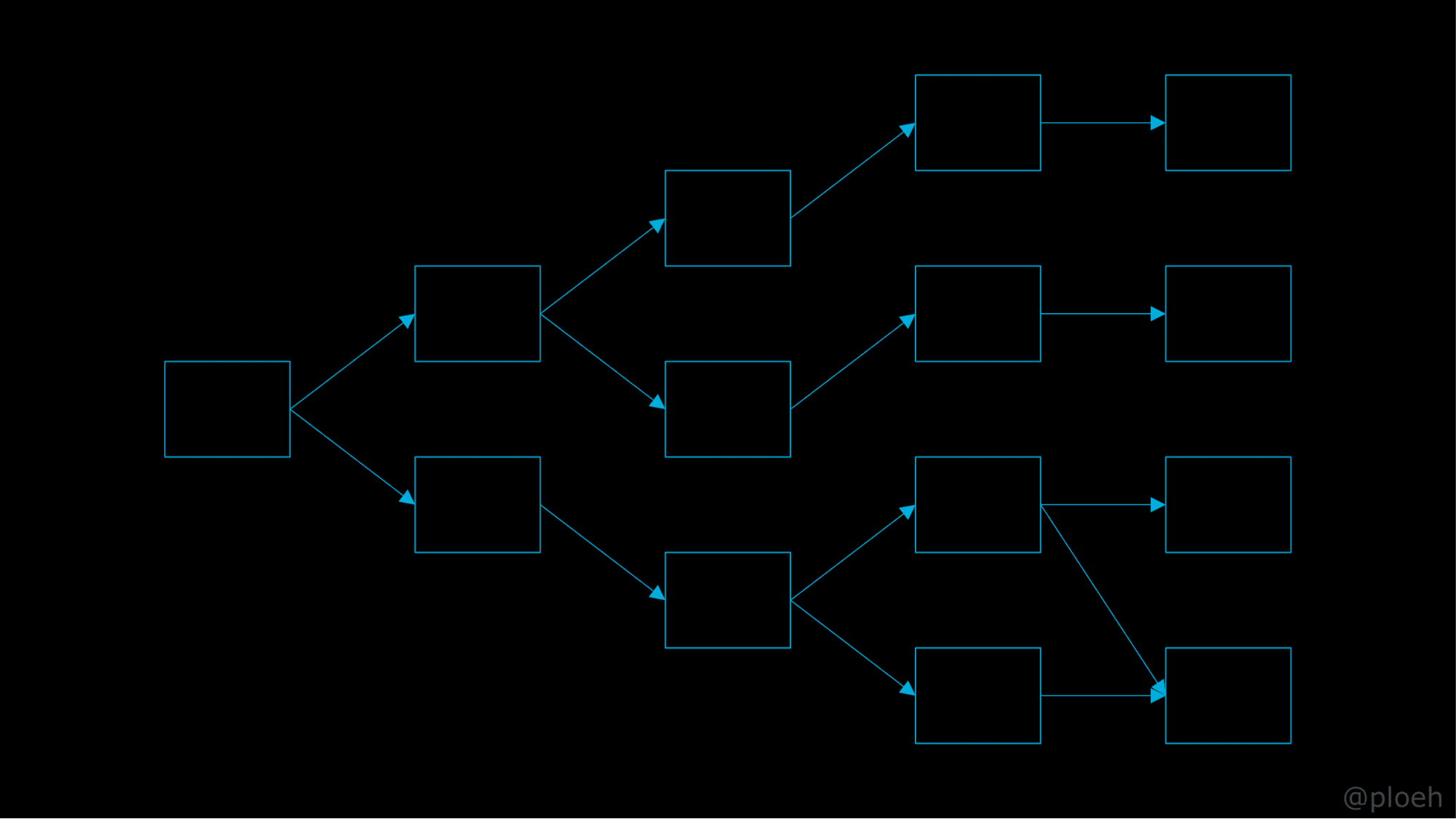
Прямоугольник слева представляет корневой объект системы: это может быть контроллер, входная точка программы и так далее. Корневой объект имеет две зависимости, у зависимостей также есть зависимости и так далее, и так далее. Листовые узлы обычно являются всеми теми вещами, которые общаются с базой данных, посылают письма и тому подобное. В общем, всё то, что является нечистым, будет происходить в листовых узлах.
Если у нас есть что-то, что имеет нечистую зависимость и хочет иметь возможность использовать ее, то единственная возможность — если это что-то само является нечистым. Это очень заразно. Если листы нечистые, весь граф становится нечистым.

Таким образом, внедрение зависимостей делает все нечистым, и это довольно интересно. Я сам не до конца понимал этого, пока не попытался переписать код на Haskell. Я проделывал трюк с частичным применением на F# как минимум год, может, немного больше, пока не задумался: «Интересно, что произойдет, если я попробую переписать это на Haskell?» И тогда я понял, что это так не работает. F# дружелюбен и продуктивен, но он не заставляет быть функциональным. Теперь мы понимаем, что это не работает, так что нам нужно придумать новый способ. Нам нужно отринуть зависимости, само понятие зависимостей.
Примечание переводчика: никогда не обращали внимания, что при появлении одного ключевого слова await в стеке вызова функций приходится добавлять Task<T> во все сигнатуры функций стека вызова? Совпадение? Не думаю!Отказ от зависимостей
Нам все еще нужно выяснить, как снизить связанности кода, тестируемость, разделить ответственности и так далее. Как нам это сделать?
Чтобы ответить на этот вопрос, давайте вернемся к основам. Одной из первых вещей, которые вы узнали, когда изучали разработку программного обеспечения, было то, что иногда у нас есть блоки кода, которые мы хотели бы иметь возможность использовать повторно. Мы можем извлекать такие блоки кода в подпроцедуры, или подпрограммы, или процедуры и методы, или функции и тому подобное. Давайте будем называть это блоком. Это повторно-используемый блок кода, который в большинстве языков работает таким образом, что он принимает входные данные и возвращает какой-либо результат. Методы в C# принимают входные аргументы и возвращают значения, вот и все.

При внедрении зависимостей также нужно взаимодействовать с этими зависимостями. Если вспомнить объект MaitreD, в первую очередь он запрашивает репозиторий и получает из него список бронирований. Мы называем это неявным вводом (indirect input). И наоборот, когда MaitreD решает принять бронь, он говорит репозиторию, что тот должен создать бронь в базе данных. Это называется неявным выводом (indirect output). Это немного всё усложняет. Когда вы занимаетесь юнит-тестированием, зависимости ввода/вывода требуют моков. Это не то чтобы невозможно, просто это делает юнит-тестирование намного сложнее, чем следует.
Давайте посмотрим, почему мы это делаем, зачем мы так всё усложняем. Начнем с непрямого ввода. Нам нужно принять решение, есть ли у нас достаточно мест, чтобы принять бронь, и только в этом случае мы хотим сохранить новую бронь в базу данных. Мы обязаны принять решение и на основе этого решения вызвать эффект. В императивных языках, таких как C#, отделить решение от побочного эффекта — не самая простая задача, поэтому мы склонны писать код определенным способом. Однако в таких языках, как F# или Haskell, это тривиально. Мы можем легко отделить точку принятия решения от эффекта, который нам нужен. Я покажу, как это делается, а после мы разберемся с другой стрелкой. Вернемся к F#-коду tryAccept.

Неявный вывод в нем есть в функции createReservation. Я хочу удалить эту функцию, я не хочу больше ее вызывать. Вы, вероятно, заметили, что эта функция возвращает int. Вот откуда берется целое число, которое возвращается самой функцией tryAccept. Нам придется немного изменить возвращаемый тип, потому что мы не можем вернуть int, если мы не вызываем createReservation. Я собираюсь удалить эту функцию и изменить тип возвращаемого значения этой общей функции на Reservation option. Теперь семантика функции такова, что если она возвращает бронь, то это признак того, что мы решили принять запрос, а если она не возвращает ничего, то мы решили отказать.

С этим изменением первая строка кода остается прежней, но в условии then мы не вызываем createReservation, потому что эта функция исчезла. Поэтому мы берем резервирование, устанавливаем поле isAccepted как true, а затем просто передаем его в Some. Теперь, если мы решаем принять бронирование, возвращается Some reservation, в противном случае — None.
Теперь у нас есть функция, которая принимает три аргумента, как бы нам составить композицию? Я стремлюсь к той же композиции, что и раньше. Я хочу, чтобы это был настоящий рефакторинг, и я не хочу менять абстракцию, я не хочу менять поведение.

Я могу вызвать новую версию tryAccept со всеми тремя аргументами. Я могу сказать tryAccept 10, потом частично примененная функция DB.readReservations со строкой подключения и третий аргумент — reservation. Это полный вызов функции, которая теперь принимает только три аргумента и возвращает Reservation option. Вы могли заметить, что я окружил этот вызов функции конструкцией match with, и это означает, что я могу делать то, что называется «сопоставлением с образцом». Если возвращаемое значение — None, я просто верну новое None, но если это Some, я могу вытащить r, резервирование внутри Some, и использовать его в качестве входного аргумента для функции DB.createReservation, частично примененной со строкой подключения, которая вернет целое число, ID, созданный в базе данных, который я просто возьму и вставлю в новый Some.
В функциональном программировании мы делаем так постоянно. Мы берем None и переводим его в None, берем Some, вызываем некоторую функцию для значения внутри Some, а затем помещаем его в новый Some. Это происходит все время. Итак, в F# мы можем переписать это просто в Option.map, а в Haskell это называется If.map, но неважно.
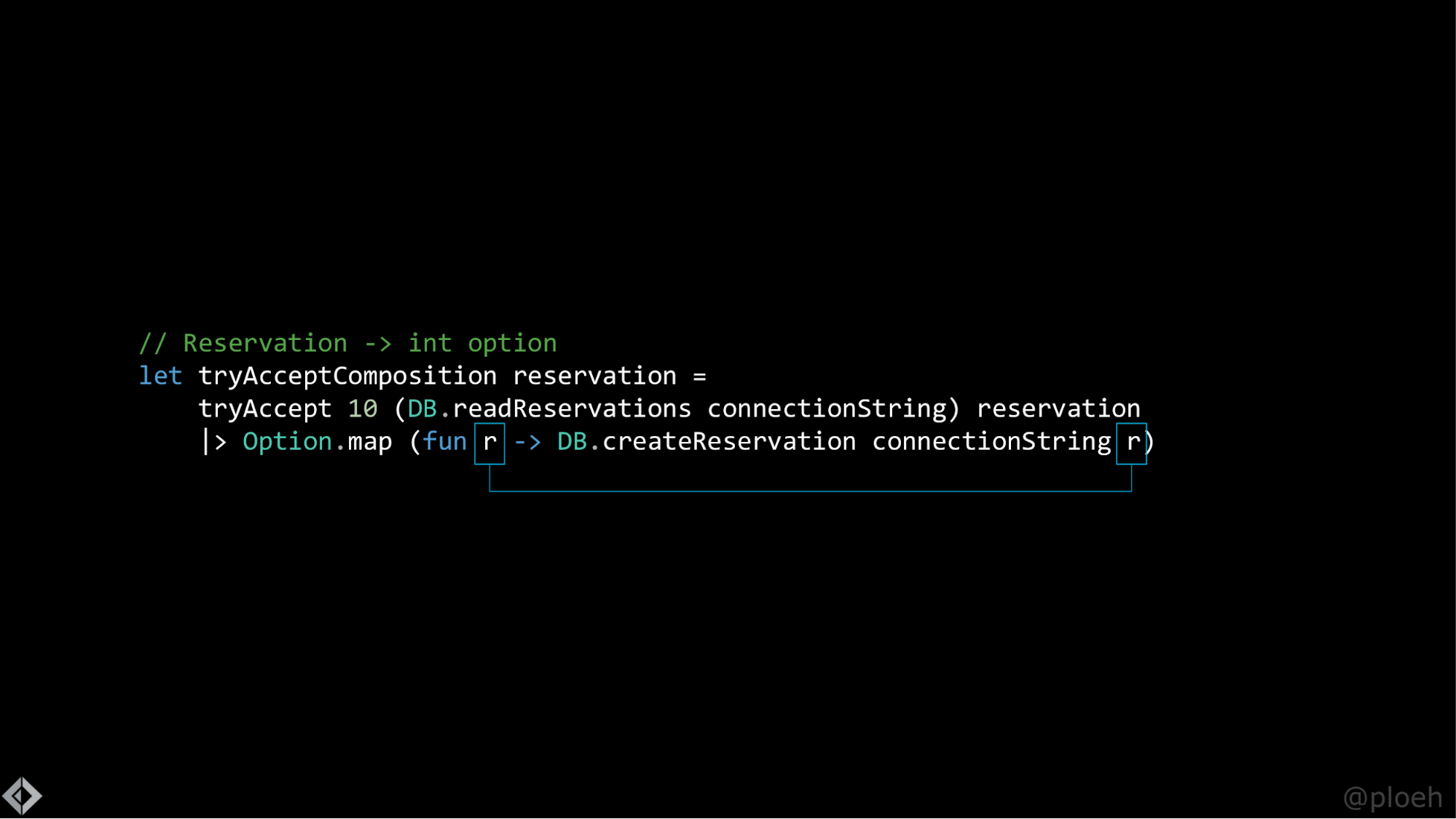
С обеих сторон лямбда-функции есть r, поэтому мы можем сделать β-редукцию и сделать немного красивее. Это не так важно. Теперь возьмем reservation и переместим его наверх и передадим его в конвейерную обработку |>.
Итак, мы избавились от побочного вывода.

Можем ли мы также избавиться от побочного ввода? MaitreD вызывает функцию для получения списка резервирований из базы данных, а затем использует этот список резервирований, чтобы делать все, что ему нужно. Зачем нам нужно, чтобы наш блок вызывал эту функцию? Почему мы не можем просто сделать это, прежде чем мы вызовем модуль, и таким образом просто превратить это в прямой ввод, что было бы намного проще. Вы заметите, что если мы сделаем это, то больше не будет стрелок между блоком и зависимостями, поэтому мы можем полностью отказаться от зависимостей.
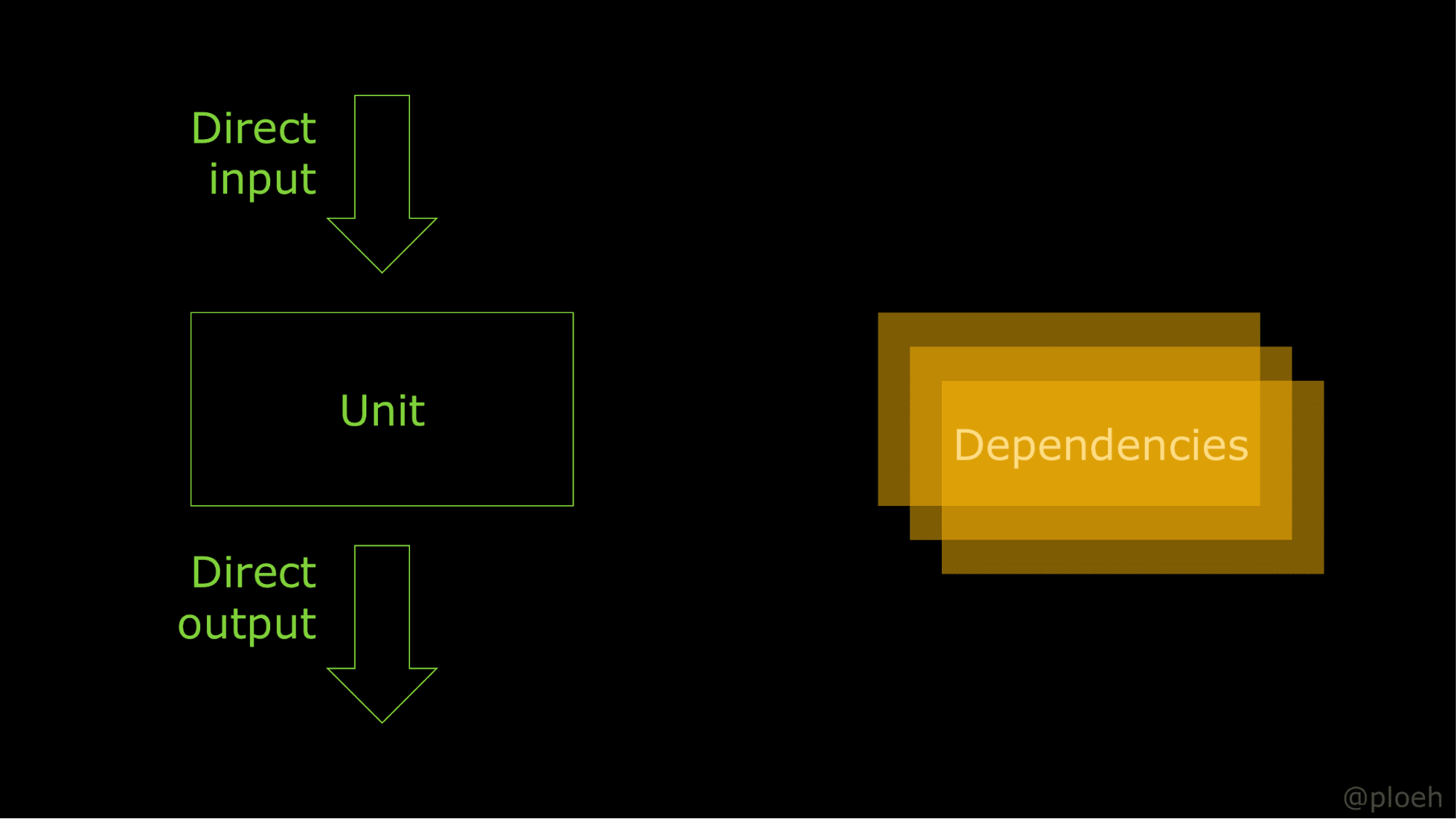
Это сделает код намного проще. Вы также заметите это, если захотите его протестировать. Это просто делает юнит-тестирование намного проще. Так как бы это выглядело? Вернемся к версии tryAccept, на которой мы остановились.
Место, где у нас есть неявный ввод, находится в функции readReservations, и главная назначение этой функции в том, что она принимает DateTimeOffset в качестве входного значения. Я не хочу, чтобы это было функцией, меня волнует только возвращаемое значение, это единственное, чего я хочу. Давайте не будем делать это функцией, мне нужно только значение. И если это просто значение, очень странно, что оно называется readReservations, поэтому мне, вероятно, следует вместо этого переименовать его в просто reservations. Это намного проще. Итак, код теперь выглядит так:
Мы по-прежнему просто суммируем резервирования по количеству, и на этом всё. Мы можем переместить пару вещей, чтобы они умещались в одну строку. Так-то лучше.
Как теперь составить композицию? Что ж, я все еще стремлюсь к рефакторингу. Я по-прежнему стремлюсь к той же абстракции, к тому же поведению.

Другой способ переписать этот код — начать с reservation.Date, передать его в функцию DB.readReservations, частично примененную со строкой подключения, которая возвращает список резервирований в качестве вывода. Мы можем передать этот список резервирований в лямбда-выражение, которое принимает reservations и вызывает tryAccept 10 reservations reservation. Это та функция tryAccept, которую мы только что видели. Она возвращает Reservation option, которое мы передаем в Option.map, как вы видели раньше.
Итак, композиция теперь делает то же самое, что и раньше. Это просто другой способ рефакторинга.
Устранение внешних зависимостей имеет не только плюсы, но и минусы. Подробнее об этом в разделе DDD-триллема доклада Владимира Хорикова «Domain-driven design: Cамое важное».
Осталась пара мелочей. Первые десять или, может быть, сто раз вы пишете лямбда-выражение, и вы думаете, что это действительно здорово, а затем начинаете очень уставать от просмотра написанных вами лямбда-выражений. Можем ли мы немного реорганизовать этот код? Можно заметить, что по обе стороны лямбда-выражения стоит reservations, так что не могли бы мы сделать β-редукцию? К сожалению, мы не можем этого сделать, потому что reservations стоит не на том месте. reservations должно быть с правого края в обоих случаях, а здесь это не так.
Есть небольшая хитрость, чтобы обойти это ограничение. Мы могли бы определить небольшую вспомогательную функцию flip, которая просто принимает функцию с двумя аргументами и возвращает новую функцию, которая делает то же самое, что и переданная функция, но ожидает аргументы в обратном порядке. Было бы хорошо, если бы мы могли это сделать. Но, к сожалению, tryAccept принимает три аргумента, мы не можем ее перевернуть, потому что flip переворачивает только те функции, которые принимают два аргумента. Но мы можем частично применить tryAccept с 10. Если мы это сделаем, то получим функцию, которая принимает два аргумента, а затем можем перевернуть ее.
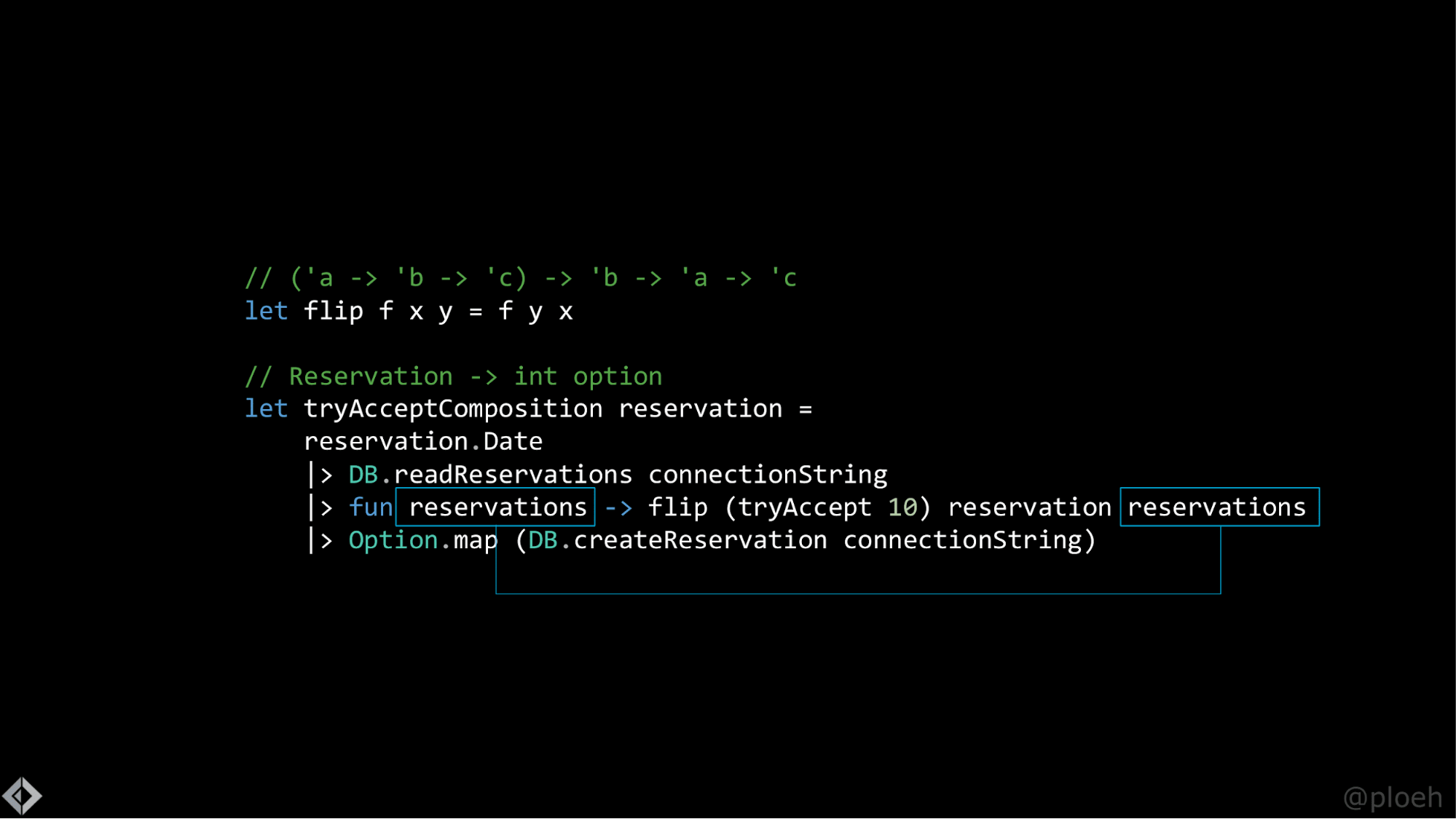
Если вы не совсем уловили, что происходит, это просто я хвастаюсь. Но это вполне нормальное явление в функциональном программировании, потому что теперь мы можем сделать β-редукцию, и тогда все станет намного красивее.

Есть причина, по которой я показываю вам этот прием: flip (tryAccept 10) reservations будет для вас чем-то вроде фиксированной точки, которую вы можете запомнить, потому что сейчас я попытаюсь проверить, действительно ли это переносимо на Haskell.
Самодиагностика 2 (Sanity check 2)
Давайте посмотрим, сможем ли мы перенести этот код на Haskell. Начнем с tryAccept. Это не было проблемой раньше, не является ею и сейчас. Эта функция по-прежнему является чистой, компилируется и всегда хороша.

Когда мы пытались портировать код раньше, где у нас были проблемы, так это в композиции. Мы не могли заставить композицию работать, потому что не могли передавать нечистые функции чистым. Давайте посмотрим, можем ли мы портировать новую версию. Композиция в итоге выглядит вот так.
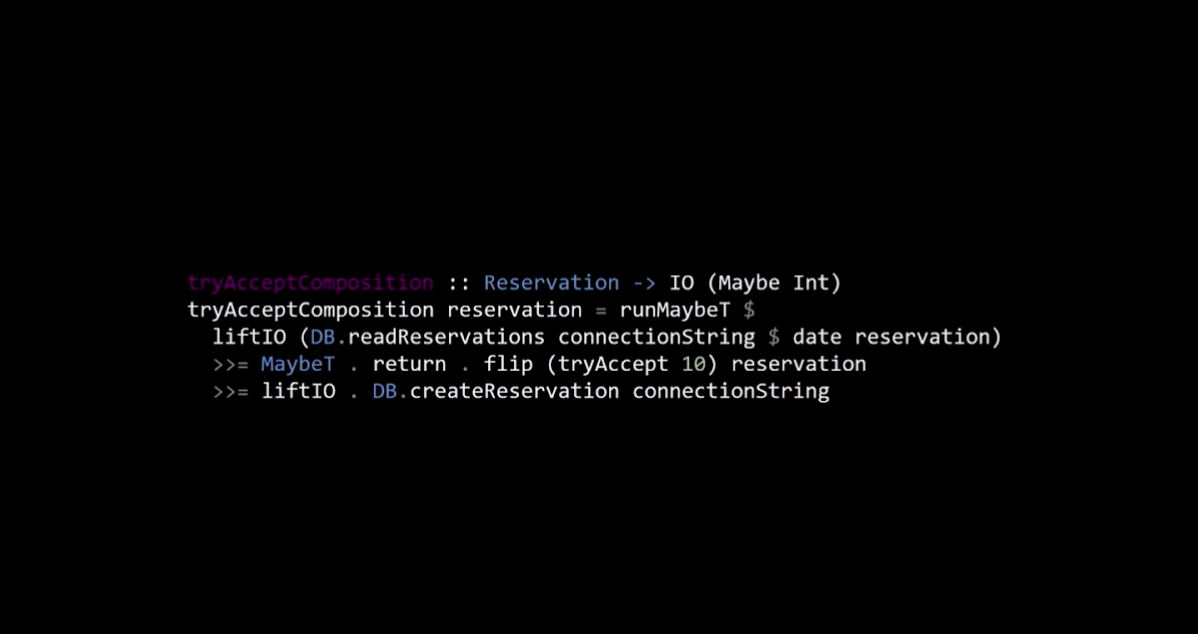
Не беспокойтесь о всех этих странно выглядящих стрелках, знаках доллара и многих других вещах. Это просто клей, которым Haskell объединяет все вместе. Но это действительно компилируется. Вы, вероятно, узнаете flip (tryAccept 10) reservation посередине. Вы также можете распознать те же шаги, которые вы видели в коде F# раньше.

Когда я пишу код на Haskell, то часто обнаруживаю, что в центре точки входа есть ядро (выделено зеленым). Можно представить, что этот код находится довольно близко к точке входа в приложение, и в середине композиции находится чистое ядро приложения. tryAccept — это чистая функция, и в основном все остальное — это просто клей, который делает возможным вызов этой чистой функции. Причина, по которой мы можем это сделать, заключается в том, что метод, который мы рассматриваем в данный момент, не является чистым, а значит, для него нет правил, поэтому он может вызывать чистые функции.
Кроме этого, мы также можем сделать некоторые нечистые шаги до и после (выделено коричневым). Поэтому, прежде чем вызывать чистую функцию, мы получаем все данные из разных нечистых источников: из переменных времени выполнения, запросов к базе данных и так далее. Как только это сделано, мы передаем все эти значения в вызов чистой функции, вызов чистой функции возвращается, а затем мы выполняем еще несколько нечистых шагов с возвращаемым значением из вызова чистой функции.
Я называю это нечистым-чистым-нечистым сэндвичем, потому что это немного похоже на сэндвич.
Я думаю, это также немного связано с шаблоном Arrange-Act-Assert, который вы, возможно, знаете из модульного тестирования. Вы как бы упорядочиваете много данных, извлекаете данные из всех видов нечистых источников, потом передаете их чистой функции, а затем делаете с ними еще несколько нечистых вещей. Это похоже на тот трехэтапный процесс, который вы проходите.
Заключение
Если вы занимаетесь объектно-ориентированным программированием, не стесняйтесь использовать внедрение зависимостей. Это проверенный в боях и хорошо описанный способ достижения слабой связанности кода, разделения проблем, тестируемости и тому подобного. Это нормально, и вы можете прочитать мою книгу, если хотите знать, как это сделать. Кстати, готовится второе издание.
Если вы занимаетесь функциональным программированием, то, как вы решаете те же проблемы, немного зависит от того, какого вида функционального программирования вы придерживаетесь. Если вы занимаетесь нестрогим функциональным программированием, как, например, с F#, вы можете использовать частичное применение тем способом, который я вам показал, и который, как оказалось, соответствует внедрению зависимостей.
Однако, как оказалось, этот способ не вполне «функциональный». Частичное применение делает все нечистым, так что на самом деле это не самый лучший способ. Так что вместо этого, если вы действительно хотите писать по-настоящему функциональный код, вы можете использовать композицию функций, этот нечистый-чистый-нечистый сэндвич.
Именно так я сейчас пишу большую часть своего кода F#, а также, очевидно, на Haskell. Если вы хотите узнать об этом больше, вы можете зайти на http://blog.ploeh.dk, там есть статья, которая называется «From dependency injection to dependency rejection». Эта вводная статья, которая содержит ссылки на еще несколько статей. Также, если вы хотите посмотреть исходный код, он находится в репозитории Github. На этом все.
Похоже, вам интересны .NET и функциональщина, и для вас F# — это не тональность «фа-диез». Тогда не пропустите новый DotNext (пройдет онлайн с 20 по 23 апреля): там Вагиф Абилов расскажет, как он на F# вообще фронтенд делал, а в числе других спикеров будет Скотт Влашин, известный своим сайтом «F# for fun and profit». Ну и, как всегда, будет много другого про .NET: программа скоро будет готова полностью, раздел с докладами на сайте постоянно обновляется.
