

Как уже говорилось в статье Радар технологий, Lamoda активно двигается в направлении микросервисной архитектуры. Большинство наших сервисов упаковываются с помощью Helm и деплоятся в Kubernetes. Данный подход полностью удовлетворяет наши потребности в 99% случаев. Остается 1%, когда стандартного функционала Kubernetes недостаточно, например, когда нужно настроить бэкап или обновление сервиса по определенному событию. Для решения данной задачи мы используем паттерн оператор. В данном цикле статей я — Григорий Михалкин, разработчик команды R&D в Lamoda — расскажу об уроках, которые я вынес из моего опыта разработки K8s операторов c помощью Operator Framework.
Что такое оператор?
Один из способов расширить функционал Kubernetes — создание собственных контроллеров. Главные абстракции в Kubernetes — объекты и контроллеры. Объекты описывают желаемое состояние кластера. Например, Pod описывает, какие контейнеры необходимо запустить и параметры запуска, а объект ReplicaSet говорит, какое количество реплик данного Pod'а нужно запустить. Контроллеры управляют состоянием кластера, основываясь на описании объектов, применительно к вышеописанному случаю, ReplicationController будет поддерживать то количество реплик Pod'ов, которое указано в ReplicaSet. С помощью новых контроллеров можно реализовать дополнительную логику вроде отправки нотификаций по событиям, восстановления после сбоя или управления third party ресурсами.
Оператор — это kubernetes приложение, которое включает в себя один или несколько контроллеров, обслуживающих third party ресурс. Концепцию придумала команда CoreOS в 2016, и в последнее время популярность операторов стремительно растет. Попытаться найти нужный оператор можно в списке на kubedex, (тут перечислено уже более 100 общедоступных операторов), а также на OperatorHub. Для разработки оператора сейчас есть 3 популярных инструмента: Kubebuilder, Operator SDK и Metacontroller. В Lamoda мы используем Operator SDK, поэтому дальше речь пойдет о нем.
Operator SDK
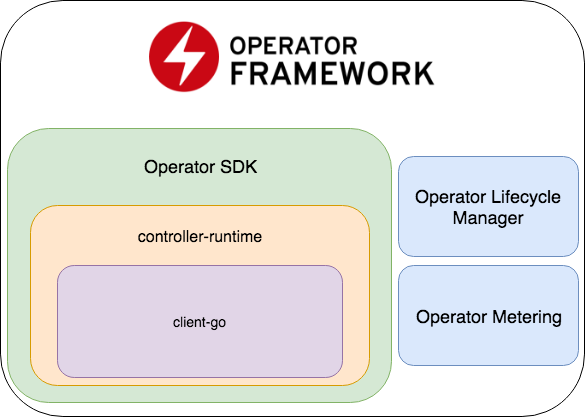
Operator SDK является частью Operator Framework, который включает в себя ещё две важные части: Operator Lifecycle Manager и Operator Metering.
- Operator SDK представляет из себя обертку над controller-runtime, популярной библиотекой для разработки контроллеров (которая, в свою очередь, является оберткой над client-go), кодогенератор + фреймворк для написания E2E тестов.
- Operator Lifecycle Manager — фреймворк для управления уже работающими операторами; разрешает ситуации, когда оператор переходит в режим зомби или выкатывается новая версия.
- Operator Metering — как очевидно из названия, он собирает данные о работе оператора, а также может генерировать репорты на их основе.
Создание нового проекта
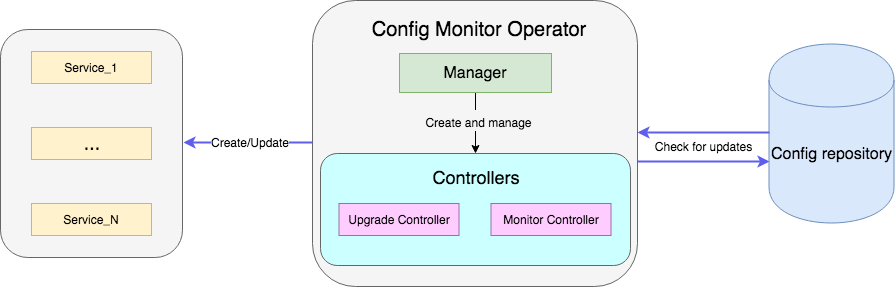
В качестве примера будет служить оператор, который следит за файлом с конфигами в репозитории и при их обновлении перезапускает deployment сервиса с новыми конфигами. Полный код примера доступен здесь.
Создадим проект с новым оператором:
operator-sdk new config-monitorКодогенератор создаст код для оператора, работающего в выделенном namespace. Данный подход предпочтительнее, чем давать доступ ко всему кластеру, так как в случае ошибок проблемы будут изолированы в рамках одного неймспейса. Сгенерировать cluster-wide оператор можно добавив к команде --cluster-scoped. Внутри созданного проекта будут находиться следующие директории:
- cmd — содержит
main package, в котором инициализируется и запускаетсяManager; - deploy — содержит декларации оператора, CRD и объектов, необходимых для настройки RBAC оператора;
- pkg — тут будет находиться наш основной код для новых объектов и контроллеров.
В cmd находится всего один файл cmd/manager/main.go.
// Become the leader before proceeding
err = leader.Become(ctx, "config-monitor-lock")
if err != nil {
log.Error(err, "")
os.Exit(1)
}
// Create a new Cmd to provide shared dependencies and start components
mgr, err := manager.New(cfg, manager.Options{
Namespace: namespace,
MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort),
})
...
// Setup Scheme for all resources
if err := apis.AddToScheme(mgr.GetScheme()); err != nil {
log.Error(err, "")
os.Exit(1)
}
// Setup all Controllers
if err := controller.AddToManager(mgr); err != nil {
log.Error(err, "")
os.Exit(1)
}
...
// Start the Cmd
if err := mgr.Start(signals.SetupSignalHandler()); err != nil {
log.Error(err, "Manager exited non-zero")
os.Exit(1)
} В первой строчке: err = leader.Become(ctx, "config-monitor-lock") — происходит выбор лидера. В большинстве сценариев нужен только один активный экземпляр оператора на namespace/cluster. По умолчанию Operator SDK использует стратегию Leader for life — первый запущенный экземпляр оператора будет оставаться лидером, пока не будет удален из кластера.
После того, как данный инстанс оператора был назначен лидером, инициализируется новый Manager — mgr, err := manager.New(...). В его обязанности входят:
err := apis.AddToScheme(mgr.GetScheme())— регистрация схем новых ресурсов;err := controller.AddToManager(mgr)— регистрация контроллеров;err := mgr.Start(signals.SetupSignalHandler())— запуск и управление контроллерами.
На данный момент у нас нет ни новых ресурсов, ни контроллеров для регистрации. Добавить новый ресурс можно с помощью команды:
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredServiceДанная команда добавит определение схемы ресурса MonitoredService в директорию pkg/apis, а также yaml c определением CRD в deploy/crds. Из всех сгенерированных файлов вручную стоит изменять только определение схемы в monitoredservice_types.go. Тип MonitoredServiceSpec определяет желаемое состояние ресурса: то, что пользователь указывает в yaml с определением ресурса. В контексте нашего оператора поле Size определяет желаемое количество реплик, ConfigRepo указывает, откуда можно подтянуть актуальные конфиги. MonitoredServiceStatus определяет наблюдаемое состояние ресурса, например, в нем хранятся названия Pod'ов, принадлежащих данному ресурсу и акутальный spec Pod'ов.
После редактирования схемы нужно выполнить команду:
operator-sdk generate k8sОна обновит определение CRD в deploy/crds.
Теперь создадим основную часть нашего оператора, контроллер:
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=MonitorВ директории pkg/controller появится файл monitor_controller.go, в который добавим нужную нам логику.
Разработка контроллера
Контроллер — основной рабочий юнит оператора. В нашем случае есть два контроллера:
- Monitor сontroller отслеживает изменение конфигов сервиса;
- Upgrade controller обновляет сервис и поддерживает его в желаемом состоянии.
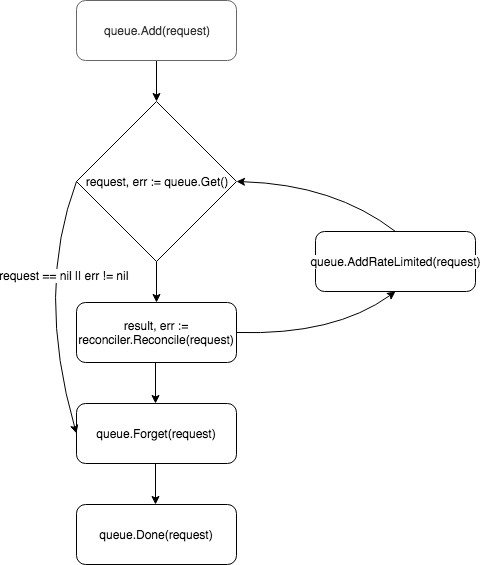
В своей основе контроллер — это control loop, он следит за очередью с событиями, на которые подписан, и обрабатывает их:
Новый контроллер создается и регистрируется менеджером в методе add:
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r})С помощью метода Watch подписываем его на события по поводу создания нового ресурса или обновления Spec существующего ресурса MonitoredService:
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate)Тип события можно настроить с помощью параметров src и predicates. src принимает объекты типа Source.
Informer— периодически опрашиваетapiserverо событиях, удовлетворяющих фильтру, если такое событие есть, кладет его в очередь конттроллера. Вcontroller-runtimeэто обертка надSharedIndexInformerизclient-go.Kind— также обертка надSharedIndexInformer, но, в отличии отInformer, самостоятельно создает инстанс информера на основании переданных параметров (схема отслеживаемого ресурса).Channel— принимаетchan event.GenericEventкак параметр, приходящие по нему события помещает в очередь котроллера.
Рredicates ожидает объекты, удовлетворяющие интерфейсу Predicate. По сути, это дополнительный фильтр на события, например, при фильтрации UpdateEvent можно посмотреть, какие именно изменения были сделаны в spec ресурса.
Когда событие приходит, его принимает EventHandler — второй аргумент метода Watch — который оборачивает событие в формат запроса, который ожидает Reconciler:
EnqueueRequestForObject— создает запрос с именем и неймспейсом объекта, который был причиной события;EnqueueRequestForOwner— создает запрос с данными родителя объекта. Это нужно, например, если подконтрольный ресурсуPodбыл удален, и нужно запустить его замену;EnqueueRequestsFromMapFunc— принимает как параметрmapфункцию, которая получает на вход событие (обернутое вMapObject) и возвращает список запросов. Пример, когда нужен данный handler — есть таймер, по каждому тику которого нужно вытянуть новые конфиги для всех доступных сервисов.
Запросы кладутся в очередь контроллера, и один из воркеров (по умолчанию контроллер имеет одного) вытаскивает событие из очереди и передает его Reconciler'у.
Reconciler реализует всего один метод — Reconcile, который содержит основную логику обработки событий:
func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) {
reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name)
reqLogger.Info("Checking updates in repo for MonitoredService")
// fetch the Monitor instance
instance := &servicesv1alpha1.MonitoredService{}
err := r.client.Get(context.Background(), request.NamespacedName, instance)
if err != nil {
if errors.IsNotFound(err) {
// Request object not found, could have been deleted after reconcile request.
// Owned objects are automatically garbage collected. For additional cleanup logic use finalizers.
// Return and don't requeue
return reconcile.Result{}, nil
}
// Error reading the object - requeue the request.
return reconcile.Result{}, err
}
// check if service's config was updated
// if it was, send event to upgrade controller
if podSpec, ok := r.isServiceConfigUpdated(instance); ok {
// Update instance Spec
instance.Status.PodSpec = *podSpec
instance.Status.ConfigChanged = true
err = r.client.Status().Update(context.Background(), instance)
if err != nil {
reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name)
return reconcile.Result{}, err
}
r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance}
}
return reconcile.Result{}, nil
}Метод принимает объект Request с полем NamespacedName, по которому из кэша можно вытащить ресурс: r.client.Get(context.TODO(), request.NamespacedName, instance). В примере делается запрос к файлу с конфигурацией сервиса, на который ссылается поле ConfigRepo в spec'е ресурса. Если конфиг обновился, то создается новое событие типа GenericEvent и отправляется в канал, который слушает Upgrade контроллер.
После обработки запроса Reconcile возвращает объект типа Result и error. Если в Result поле Requeue: true или error != nil, контроллер вернет запрос обратно в очередь с помощью метода queue.AddRateLimited. Запрос будет возвращен в очередь с задержкой, которая определяется RateLimiter'ом. По умолчанию используется ItemExponentialFailureRateLimiter, который увеличивает время задержки экспоненциально с ростом числа "возвратов" запроса. Если поле Requeue не установлено, и во время обработки запроса не возникла ошибка, контроллер вызовет метод Queue.Forget, который удалит запрос из кэша RateLimiter'а (тем самым обнуляя количество возвратов). В конце обработки запроса контроллер удаляет его из очереди, с помощью метода Queue.Done.
Запуск оператора
Выше были описаны составные части оператора, и остался один вопрос: как его запустить. Для начала нужно убедиться, что установлены все необходимые ресурсы (для локального тестирования рекомендую настроить minikube):
# Setup Service Account
kubectl create -f deploy/service_account.yaml
# Setup RBAC
kubectl create -f deploy/role.yaml
kubectl create -f deploy/role_binding.yaml
# Setup the CRD
kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml
# Setup custom resource
kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yamlПосле того как предварительные требования были выполнены, есть два простых способа запустить оператор для тестирования. Самый простой — запустить его вне кластера с помощью команды:
operator-sdk up local --namespace=defaultВторой способ — задеплоить оператор в кластере. Сначала нужно собрать Docker image с оператором:
operator-sdk build config-monitor-operator:latestВ файле deploy/operator.yaml заменить REPLACE_IMAGE на config-monitor-operator:latest:
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yamlСоздать Deployment с оператором:
kubectl create -f deploy/operator.yamlТеперь в списке Pod'ов на кластере должен появиться Pod с тестовым сервисом, а во втором случае — еще один с оператором.
Вместо заключения или Best practices
Ключевыe проблемы разработки операторов на данный момент — это слабая задокументированность инструментария и отсутствие устоявшихся best practices. Когда новый разработчик приступает к разработке оператора, ему практически негде подсмотреть примеры реализации того или иного требования, поэтому ошибки неизбежны. Ниже несколько уроков, которые мы выучили на собственных ошибках:
- Если есть два связанных приложения, стоит избегать желания объединить их единственным оператором. В ином случае нарушается принцип loose coupling сервисов.
- Нужно помнить о separation of concerns: не стоит пытаться реализовать всю логику в одном контроллере. Например, стоит разнести функции мониторинга конфигов и создания/обновления ресурса.
- В методе
Reconcileстоит избегать блокирующих вызовов. Например, можно подтянуть конфиги из внешнего источника, но если операция более продолжительная, создайте для этого горутину, а запрос отправьте обратно в очередь, указав в ответеRequeue: true.
В комментариях было бы интересно услышать о вашем опыте разработки операторов. А в следующей части поговорим о тестировании оператора.
