Comments 21
"шага преобразования бизнес-ключей в суррогатные " ну как бэ это и PowerBI умеет, и имхо кто-угодно
Добрый день! Да, мы не сомневаемся, что многие наши требования в каких-то системах реализованы. Нам просто требовалось сделать нечто достаточно точно соответствующее совокупности наших требований. Мы не претендуем на революционность идей :-)
И ещё уточню, возможно, этот момент в тексте не был правильно понят. Допустим у вас есть ИНН людей, по которому вам нужно фильтровать отчёт. Вам нужно сделать отчёт по большому списку людей, идентифицируемых их ИНН, условно: "1234, 5678, 9101". Допустим в справочнике налогоплательщиков у этих людей есть ID: 1, 2, 3 соответственно. Вы берёте прям эту строку и подставляете в соответствующее поле фильтра. Все известные нам BI-системы сделают такой предикат запроса: WHERE TAXPAYER_INN in ('1234', '5678', '9101'), и это не очень хорошо для базы, потому что в базах могут быть индексы по сурогатным ключам, партиционирование, да и просто сравнивать числа быстрее, чем строки. Магрепорт сделает по-другому: он запросит справочник (который может лежать вообще в отдельной базе справочников и обращения к которому могут быть очень быстрыми), получит список IDшников и сформирует такой предикат: WHERE TAXPAYER_ID in (1, 2, 3). Может не слишком уж крутая оптимизация, но по опыту всё-таки увеличивает производительность и экономит ресурсы базы. Мелочь, как говорится, а приятно :-) И это не гипотетическая ситуация - у нас много лет пользователи запрашивают данные по бизнес-ключам (по огромному списку бизнес-ключей) и до внедрения Магрепорта нам всегда было неприятно, что они так делают, а сейчас - пожалуйста, милости просим :-)
Это не мелочь, это важная и давно известная фича.И в PowerBI и в TIBCO spotfire к примеру - они прекрасно умеют в фильтре показать дескрипшен, а данные отфильтровать по ID.
Вы немного путаете. Так умеют действительно многие. То есть если у вас фильтр так устроен, что вам там что-то показывают, то такой фильтр действительно, как правило, показывает человеку описательное имя, а в запрос подставляет ключ. Я говорю о другом типе фильтров - крайне популярном у нас - когда вам ничего не показывают, а просто вы текстом можете вставить список каких-то ключей. Разыменование бизнес-ключей в суррогатные в фильтре такого типа я нигде не встречал. Возможно где-то есть, но нам этого не хватало и мы это сделали. Не великое достижение, но для нас полезная особенность.
ну ясно, это другое, но ставлю деньги что напримкер Tibco сможет это сделать с помощью простого скрипта на встроенном питоне
Ну вот, а мы без всякого скрипта, просто из коробки :-)
я так понял по прочтении - что вы целиком свой велосипед наваяли
Да, в том и суть :-) И пытаемся сделать такой велосипед, на котором нам самим было бы ездить в удовольствие. И пока получается :-) Например, я же реально сам администрирую боевой инстанс системы, сам запускаю какие-то отчёты, которые мне нужны по всякой статистике и т.п., и реально сам кайфую от того, насколько всё удобно сделано. Кое-что мне или другим нашим коллегам бывает не нравится, и это в планах на изменение и доработку. Вся соль в том, что мы делаем BI-систему под свой опыт построения хранилища и решения реальных задач пользователей, а не наоборот - подстраиваемся под концепт какой-то существующей системы. Вопрос, конечно, насколько наш опыт релевантен опыту других компаний. Тут, конечно, предсказать не берусь. Но думаю, что по крайней мере для очень больших компаний он более-менее актуален. Конечно, очень хотелось бы, чтобы были какие-то хотя бы тестовые внедрения и тогда было бы более-менее понятно, как с этим обстоят дела.
Кто у вас занимается миграцией старой и созданием новой отчётности?
С точки зрения разработки продукт наверное интересный, а вот с точки зрения пользователя - я, например, как аналитик старался избегать работодателей, использующих собственные решения или ноунейм импортозамещение, потому что усилия, потраченные на освоение этих вещей, при поиске следующей работы окажутся выкинутыми впустую.
Важный момент! Спасибо, действительно это интересный вопрос. Постараюсь осветить. Миграцией занимаемся в частности мы же, созданием новой отчётности занимаются разные подразделения. Пользователю действительно иногда приходится переходить с инструмента на инструмент, причём даже внутри одной компании, не говоря уже о смене места работы. И, конечно, это далеко не всегда вызывает бурю радостных эмоций - мы с этим встречались и мы это понимаем. Но у нас эволюция систем отчётности выглядела так, что массовый пользователь не был избалован какими-то очень удобными инструментами - была иностранная опенсорсная система отчётности, которую мы допиливали напильником, которая была крайне скудной по возможностям и неудобной и с которой пользователь просто бегом перебежал в Магрепорт, при том что мы палками их не перегоняли :-) Если говорить о возможности покупки системы на рынке, то отвлекаясь от финансовой составляющей, всё равно должен констатировать, что это не обязательно будет лучше для пользователя - мы преследовали цель сделать в том числе интуитивно понятную и простую в использовании систему. Показателен тот факт, что за 2,5 года эксплуатации тысячами пользователей мы только сейчас впервые организовываем корпоративные курсы по системе, и то потому что она стала обрастать новым более сложным функционалом. За эти 2,5 года по пальцам одной руки я могу пересчитать письма от пользователей с вопросом, как работать с Магрепортом, и во всех этих случаях пользователи удовлетворялись ответом "там всё интуитивно понятно". Это я не к тому, какая у нас замечательная система, а к тому, что мы обслуживаем огромную Компанию и нашим приоритетом является сделать так, чтобы всё работало надёжно и по возможности просто - где простота, там, как правило, и надёжность и эффективность. Конечно, при переходе в другую Компанию пользователи столкнутся с другими инструментами и, возможно, испытают от этого некоторые трудности. Но то же самое будет и при использовании любой покупной системы - их на рынке по крайней мере десятки и вероятность попасть на ту, которую ты использовал до этого, мала. В частности поэтому этот вопрос не является для нас приоритетным.
Решение получилось масштабируемое. Интересно, сталкивались ли вы с проблемой ограничений на число строк в excel ? Допустим, используя pivot table, пользователю надо проанализировать данные, выполняя drilldown до уровня документа и его позиции. А это означает, что такие детальные данные уже должны быть в excel-файле - ведь excel-файл не выполняет подключение к БД. Это Java backend app “набивает” файл данными из субд, и затем «отдаёт» его пользователю вместе с pivot table над ними.
Если пользователь с полномочиями на большой регион выберет ещё и большой период времени для анализа, то при ваших розничных объемах максимальный миллион строк на листе в книге excel будет легко достигнут.
О, да! Вы смотрите в корень :-) Это действительно серьёзная проблема - в Эксель не помещается более 1 млн строк и у нас действительно пользователи очень легко этот лимит превышают в своих выгрузках, соответственно отчёт падает по превышению лимита, который у нас составляет как раз 1 млн строк, чтобы можно было отдать пользователю файл. Нашим ответом на эту проблему стало создание механизма работы со сводной внутри самого Магрепорта - наш внутренний OLAP-движок. Он пока не вошёл в релиз свободно распространяемой версии. Пользователь теперь может "крутить" свои сводные прямо в веб-интерфейсе, что гораздо удобнее, потому что иметь дело с такими "жирными" эксель-файлами - то ещё удовольствие: он и ресурсы ПК прилично ест (а у рядовых сотрудников не очень мощные ПК), и по почте его никому не пошлёшь. Правда, лимит мы ещё не подняли, но скоро сделаем это. И в заключение маленькая ремарка: когда я изучал остроту проблемы с лимитом в 1 млн строк, я выяснил, что 99% отчётов не превышают 700 тыс строк в объёме. Правда, это можно объяснить тем, что пользователи знают про лимит и вместо того, чтобы, например, сразу посмотреть все интересующие их товарные категории, смотрят сначала одну, потом другую, что, конечно, неудобно. Для нас эта проблема - некий вызов, на который мы хотим дать достойный ответ и разработать механизм, позволяющий пользователю работать с по-настоящему большими объемами данных, постепенно фильтруя их и детализируя (то есть сделать реально качественный drill down). Мы работаем над этим.
Для преодоления 1M-limit вы не рассматривали выгрузку в MS Access с последующим подключением к файлу Access из Excel?
Рассматривали примерно такой вариант: хотели выгружать в MS Analysis Services и предоставлять пользователю файл со сводной, настроенной на куб в нём. У этого варианта оказался ряд очень неприятных технических проблем:
1) Для создания такого файла понадобится использование какого-то екселевского API и соответственно машина с Windows, а нам очень не хотелось бы так усложнять архитектуру и вообще слишком сильно завязываться на технологии Microsoft.
2) Для работы такого файла понадобится у всех пользователей унифицировано настроить подключение к MS Analysis Services. Кроме того, что это само по себе не очень приятно зависеть от какого-то стороннего установленного и правильно настроенного ПО, так встают ещё и вопросы аутентификации и управления правами доступа на этом MS Analysis Services.
Поэтому мы решили в это не ввязываться, считая, что гораздо перспективнее сделать свой хороший OLAP и встроенные сводные таблицы, чем мы сейчас и занимаемся :-)
Развернул на Focal Fossa
Вопрос:
Почему выбран режим экспорта отчета в формате .xlsm(Macro-Enabled файл Excel Workbook)?
В рамках технологического суверенитета, открывал отчет в onlyoffice-desktopeditors(r7-office) и LibreOffice Calc. Макросы не окрыляют.
Запуск H2 Database server таким методом мне больше нравится.(server modes; databases)
[Unit]
Description=H2 Database server
[Service]
Type=simple
User=h2
ExecStart=/usr/bin/java -cp /usr/share/java/h2/h2.jar org.h2.tools.Server -baseDir /var/lib/h2 -tcp -web -ifNotExists -tcpPassword h2
ExecStop=/usr/bin/java -cp /usr/share/java/h2/h2.jar org.h2.tools.Server -tcpShutdown tcp://localhost -tcpPassword h2
[Install]
WantedBy=multi-user.targetСкрины тестирования:
01- запуск и выгрузка отчета
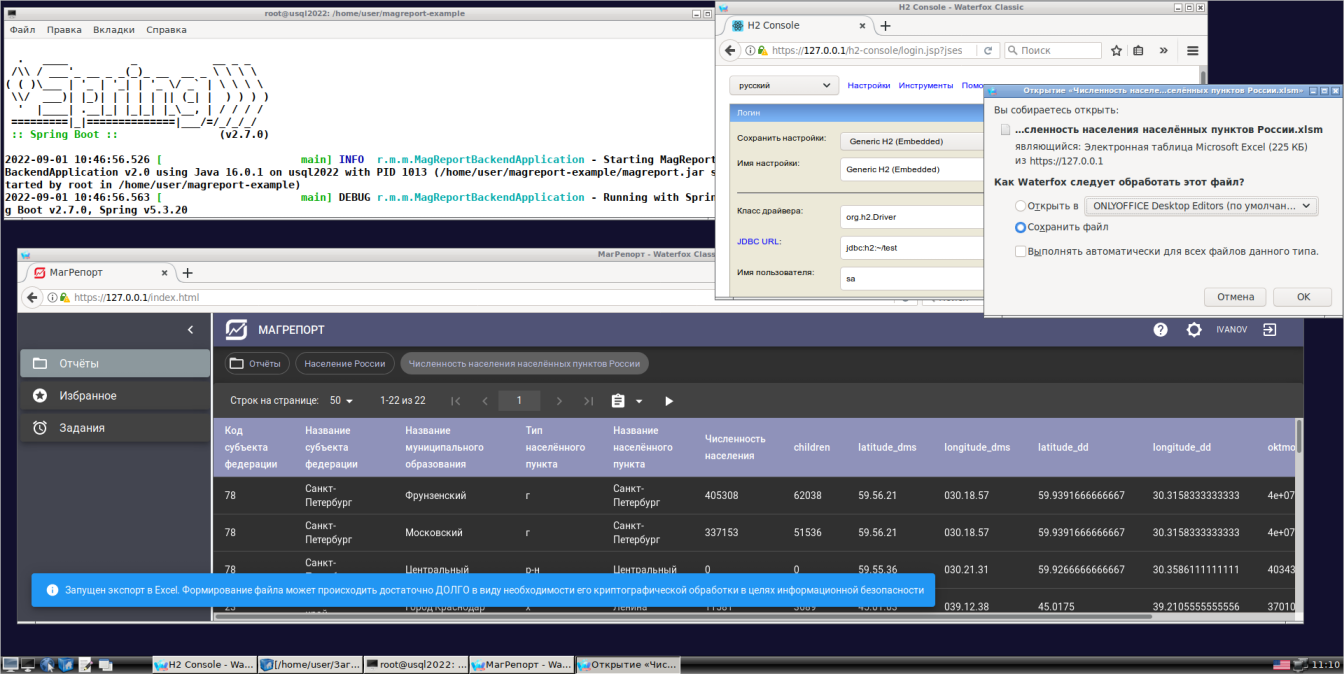
02- тест отчета

Огромное спасибо, что протестировали и даже приложили скрины!
Почему .xlsm:
Исходный сценарий работы, на котором у нас завязаны почти все отчёты выглядит так: пользователь выгружает в Excel, в котором автоматически создаётся сводная через макрос и далее работает с ней. Именно для автоматического создания сводной по любому отчёту нужен макрос. У нас в системе предусмотрена возможность добавлять кастомизированный шаблон Excel под тот или иной отчёт, но есть "Стандартный шаблон" в котором предусмотрено создание сводной по всем выгруженным полям, какие бы они ни были - для этого нужен макрос. На момент создания первых версий Магрепорта вопрос полного ухода от Excel не стоял (честно говоря, в таком виде он и сейчас не стоит). В контексте современного понимания вопроса технологического суверенитета можно рассматривать другие форматы экспорта - мы готовы их добавить, если появится соответствующая необходимость (причем готовы рассматривать в том числе запросы внешних пользователей - мы готовы рассматривать issue в нашем публичном репозитории).
Про внутреннюю БД (репозиторий) и H2:
Мы специально сделали репозиторий на H2 в режиме embedded, чтобы максимально просто была устроена архитектура приложения, развёртывание и администрирование системы. Мы предусмотрели возможность размещения репозитория на внешней БД (в том числе H2 в режиме отдельного сервера) и думали, что довольно скоро на неё перейдём. Но оказалось, что в том режиме, в котором это нужно Магрепорту H2 прекрасно справляется. Единственно, отчёт по статистике запуска отчётов стал отрабатывать чуть медленнее по мере накопления статистики. Ну и мы не стали ещё сохранять некоторые статистические вещи, которые можно было бы сохранять в базе (логи запросов пользователей), чтобы база совсем уж не распухала. Но всегда есть возможность перехода на другую БД - у нас для этого предусмотрен экспорт-импорт репозитория в текстовый формат. Но с embedded H2 работать очень удобно, поэтому мы лично пока остаёмся на ней.
Ещё раз спасибо, что запустили Магрепорт и приложили скрины!
Да не за что. Было интересно потестировать(ldap, domain и mail-server не настраивал) Все завелось сразу и без ошибок. На установку потратил 20 мин.
скачать и распаковать magreport-3.6.0-with-example.zip
sudo apt install openjdk-16-jre
sudo update-alternatives --config java # все расписывать не буду
sudo chmod +x run.sh && sudo ./run.shH2 Database Engine реактивная - пользовательские функции и триггеры работают очень быстро: du -h example-db.mv.db 16M - отчеты формируются за 2-3 сек. Вижу, что предусмотрели подключение к внешним БД.
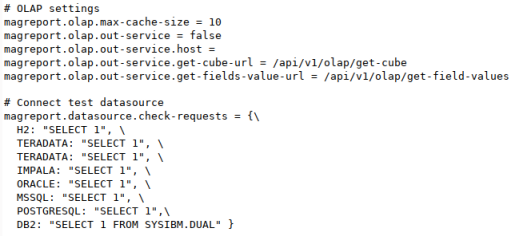
Моя контора уходит от классической on-premise схемы MS: Analysis Services(SSAS) с Reporting Services(SSRS)
Года 3 использую в тесте JasperReports Server CE и Pentaho BI Server CE
А сколько по времени у вас заняла разработка?
Сколько трудоресурсов ушло на это (в людях)?
Можно хотя бы примерно, чтобы понять масштабы :)
Понятно, что система постоянно дорабатывается, но хочется понять - создание до какого-то реального рабочего продукта
Разработку мы начали в ноябре 2019 года. Начали вдвоём, потом спустя пару месяцев работали втроём, ещё через некоторое время вчетвером. В апреле 2020 года у нас была первая промышленно внедрённая версия. Примерно летом 2020 года мы решили полностью переработать продукт и в апреле 2021 года мы выпустили новый существенно переработанный релиз (предыдущую версию в течение этого времени мы дорабатывали по мере необходимости внести критические исправления или доработки). С середины 2020 года и по настоящее время команда непосредственно разработчиков составляет 5 человек (есть ещё ребята, которые занимаются эксплуатацией продукта - их я здесь не учитываю): 2 бэкенд-разработчика, 3 фронтенд-разработчика.
Импортозамещение BI своими руками