
Проектирование API контрактов — одна из непростых задач в работе системного аналитика. Нужно не только корректно спроектировать API, но и оформить требования на разработку. Это важно для понимания задачи разработчиками и её реализации в соответствии с требованиями.
Меня зовут Ирина Тикинева, я системный аналитик в Magnit Tech на внутреннем проекте по интеграции с ГИС Зерно — государственной информационной системой прослеживаемости зерна и продуктов переработки зерна. Наш продукт предназначен для автоматизации работы операторов с документами маркировки Зерна. Разработку продукта мы начали недавно с нуля новой командой, скоро планируем релизить MVP.
У нас в команде два системных аналитика с разным бэкграундом и изначально разными подходами к оформлению требований, в том числе к API. Вначале каждый из нас писал требования по-своему, с разным уровнем проработки и детализации. Но быстро стало понятно, что так дальше не пойдет: это приводило к разночтению требований разработчиками и тормозило реализацию. Поэтому мы в команде решили унифицировать формат описания требований к API.
Сначала мы пробовали документировать API в Swagger в формате OpenAPI. Но одного YAML было недостаточно для бэкенда. Параллельно описывали сценарии обработки запросов и маппинг параметров API в конфлюенсе. Разработчики по нашим требованиям писали код и средствами FastAPI генерировали API-документацию обратно в Swagger из кода. Такой формат дублирования оказался для нас не особо удобным. Поэтому мы решили сделать шаблон требований к API для бэкенда в конфлюенсе, который бы включал в себя все нужные нам пункты, и отказаться от первичного описания в Swagger.
В статье расскажу, к какому формату описания в итоге мы пришли, и покажу заполнение шаблона на конкретных примерах. Думаю, статья будет полезна как начинающим, так и опытным системным аналитикам, а также всем тем, кто проектирует API-контракты.
Проектируем REST API
Допустим, мы разрабатываем сервис Meowgram — приложение для котиков, в котором котики публикуют посты с фотографиями.
В этом примере ограничимся следующими сценариями использования:
Просмотр котиком всех своих постов с учетом:
фильтрации по дате создания и изменения поста,
поиска по тексту поста,
сортировки по дате изменения.
Публикация котиком нового поста. Пост состоит из:
изображения до 30 мб,
текста длиной до 256 символов.
У нас уже есть реляционная БД с таблицами post и cat.

Осталось описать требования к REST API, чтобы подружить бэкенд и фронтенд и котики могли публиковать посты и просматривать их.
Будем проектировать REST API.
Описание ресурса
В обоих задачах мы работаем с одним и тем же ресурсом, постом.

Ресурс можно выделить и описать в отдельной вкладке.
Также отдельно можно вынести описать общие пункты, которые относятся ко всем методам. Например, заголовки, коды ошибок. В нашем случае это заголовок авторизации.
Перейдем к описанию методов. Требования к каждому методу для ресурса описываем на отдельной странице.
Получение постов котика
1 шаг. Описываем конечную точку и метод

Указываем:
описание метода,
полный URL,
кому разрешено вызывать метод (бывает полезно прописать, если есть требования по ограничению прав).
В нашем случае список своих постов могут посмотреть только авторизованные котики.
В данном случае логичнее было бы назвать конечную точку /my/posts. Она показывает, что возвращаемые данные относятся к текущему аутентифицированному пользователю. Бэкенд определяет пользователя с помощью механизмов аутентификации: например, токенов, передаваемых в заголовке
Authorization. Но для примера я специально выбрала /cats/{catId}/posts, чтобы показать описание path-параметров.
2 шаг. Описываем заголовки и параметры запроса

Конечная точка содержит path-параметр {catId}. Указываем:
тип параметра и ограничения,
соответствующую таблицу.поле в БД, где содержится ИД котика.

Прописываем query-параметры:
Помимо параметров для фильтрации не забываем указать параметры для пагинации, сортировки и полнотекстового поиска.
Для каждого параметра указываем тип, ограничения (возможные значения, значения по умолчанию и формат) и соответствующую таблицу.поле в БД.
Прикладываем пример запроса в curl
curl -X GET "<https://meowgram.ru/api/v1/cats/1/posts?page=1&pageSize=20&query=счастливый&sortingKey=dateCreated&sortingValue=asc>" \\
-H "Authorization: Bearer ACCESS_TOKEN"Пагинация для GET в query-параметрах позволяет гибко управлять объёмом передаваемых данных и экономить ресурсы. Есть несколько вариантов реализации пагинации:
Пагинация с номером страницы и размером страницы — вариант, который мы использовали.
Пагинация с ограничением и смещением — используются параметры:
limit(максимальное количество возвращаемых элементов) иoffset(смещение, указывающее, с какой записи начинать вывод). Например: /items?limit=20&offset=40Пагинация по ключу — используется идентификатор (обычно это уникальный ключ или временная метка) последнего элемента на предыдущей странице для загрузки следующего набора результатов. Например: /items?startAfter=12345&limit=20
3 шаг. Описываем сценарии обработки запроса

В сценариях обработки важно учесть валидацию запроса, проверку авторизации, продумать различные варианты обработки бизнесовых ошибок.
Если API публичное или у него много потребителей, можно добавить ограничение на количество запросов (rate limit). И предусмотреть ответ 429 при превышении.
Бывает полезно логировать запросы и ответы для последующего мониторинга и отладки. Требования к логированию полезно указать в сценарии.
В дополнение к описанию сценария можно приложить ссылку на диаграмму последовательности.
4 шаг. Описываем параметры ответа

HTTP/1.1 200 OK
Content-Type: application/json
{
"posts": [
{
"postId": 123,
"text": "Это первый пост котика.",
"imageUrl": "<https://example.com/images/cat1.jpg>",
"dateCreated": "2023-12-01T10:00",
"dateUpdated": "2023-12-01T12:00"
},
{
"postId": 124,
"text": "Это второй пост котика.",
"imageUrl": "<https://example.com/images/cat2.jpg>",
"dateCreated": "2023-12-01T11:00",
"dateUpdated": "2023-12-01T13:00"
}
],
"cat_id": 42,
"totalCount": 2
}

HTTP/1.1 401 Unauthorized
Content-Type: application/json
{
"error": "Signature has expired",
"messageOutput": "Требуется аутентификация. Пожалуйста, проверьте ваши учетные данные."
}
Прописываем параметры для успешного и неуспешных ответов:
Для каждого параметра аналогично указываем тип, ограничения (возможные значения, значения по умолчанию и формат) и соответствующую таблицу.поле в БД.
Мы используем “/” для отображения вложенности массивов или объектов. Например, в нашей таблице postId относится к массиву post.
Для ошибочных ответов мы передаем параметр “messageOutput” с сообщением для вывода пользователю.
Добавляем примеры успешного и неуспешного ответов.
5️⃣ 5 шаг. Описание кодов ответа и сообщений для вывода в интерфейс

В отдельной таблице прописываем возможные ответы на запрос с описаниями.
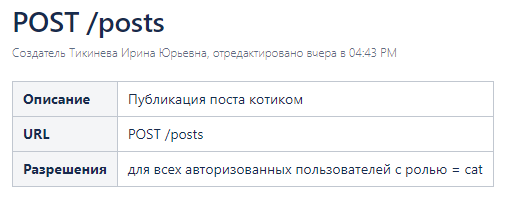
Публикация нового поста котика
По аналогии опишем метод POST для создания нового поста котиком.
1 шаг. Описываем конечную точку и метод
2 шаг. Описываем заголовок и параметры запроса
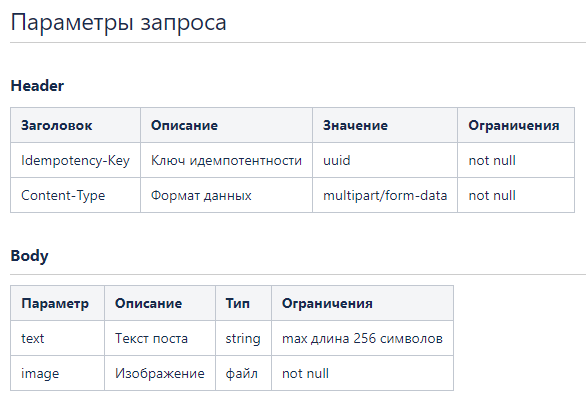
Описываем заголовки:
Так как это POST-запрос, то в избежании дублирования поста, добавляем в заголовок ключ идемпотентности. Например, при повторном запросе в случае обрыва соединения.
Для загрузки изображения используем бинарный формат данных (Content-type: multipart/form-data).
Описываем параметры тела запроса: тип и ограничения.
Прикладываем пример запроса.
curl -X POST '<https://meowgram.ru/api/v1/posts>' \\
-H 'Idempotency-Key: UUID' \\
-H "Authorization: Bearer ACCESS_TOKEN"\\
-F 'text=Текст поста котика, не более 256 символов.' \\
-F 'image=@/path/to/cat/image.jpg'
3 шаг. Описываем сценарии обработки запроса
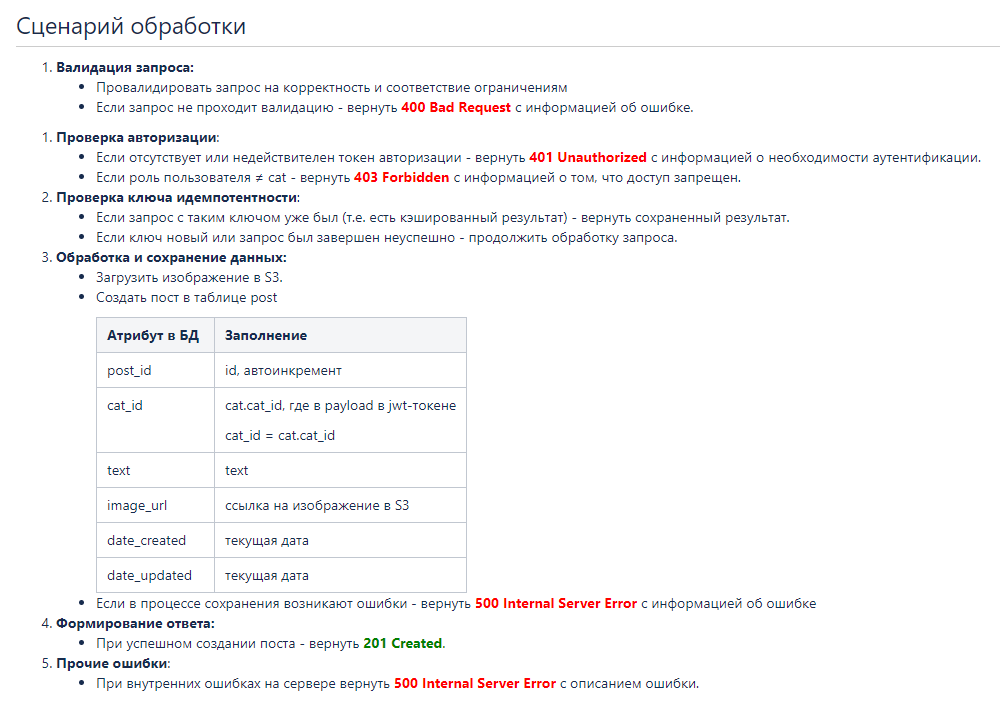
Помимо стандартных сценариев полезно будет описать логику проверки ключа идемпотентности.
А также логику создания и обновления объекта в БД, загрузки изображения в хранилище.
4 шаг. Описываем параметры ответа

HTTP/1.1 201 Created
Content-Type: application/json
{
"post_id": 123456,
"text": "Здесь текст поста котика",
"image_url": "<https://example.com/path/to/uploaded/image.jpg>",
"date_created": "2023-12-02T12:34",
"date_updated": "2023-12-02T12:34"
}

HTTP/1.1 400 Bad Request
Content-Type: application/json
{
"error": "Invalid request",
"messageOutput": "Некорректный формат запроса"
}
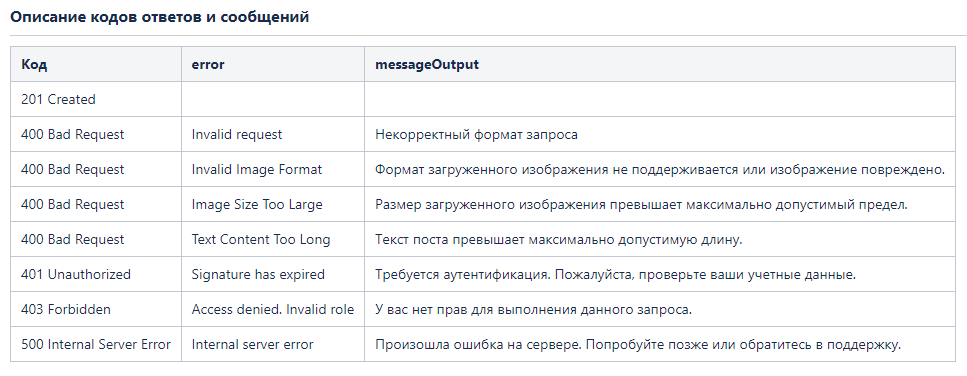
Валидацию формата изображения и длины поста желательно делать не только на фронте. На бэкенде желательно проверять критичные ограничения.
И, в принципе, всё :) Требования к методам получения постов и создания постов для котиков готовы.
В данных примерах я опустила заполнение блоков с историей изменений и согласованиями, которые имеются в нашем рабочем шаблоне. Мне больше хотелось акцентировать внимание на содержании требований плюс показать полезные фишки.
Требования к фронтенду с описаниями экранных форм и вызовами API мы оформляем отдельным артефактом.
Итоги
Внедрение шаблона требований к API позволил нам:
Уменьшить время на разработку требований: все необходимые для описания разделы и подсказки под рукой.
Повысить качество и полноту требований.
Уменьшить скорость разработки: разработчики теперь быстрее понимают задачу.
Значительно уменьшить количество багов на выходе.
Важно собирать обратную связь от коллег по команде. Это поможет сделать документацию максимально полезной и понятной.
Структура и процесс документации может изменяться в процессе разработки. Это нормальный процесс.
Напоследок хочу поделиться литературой по проектированию и документированию REST API:
Я веду тг-канал «Системный суетолог» про системный анализ, где разбираю разные темы и кейсы, связанные с системным анализом. Присоединяйтесь!
