В отличие от Европы и Америки в России к сайтам знакомств преобладает осторожное отношение. Однако, надежда нажать на волшебную кнопочку и найти себе любовь не гаснет в сердцах многих. И мы должны эту надежду оправдывать. Конечно, сразу найти идеально подходящую “половинку” мы не обещаем, но предложить десятки, сотни или в отдельных случаях тысячи вариантов, отвечающих именно вашим запросам, просто обязаны. Что и делаем, причем очень быстро.
Средний поиск по базе из 11 миллионов анкет, имеющих от 4 до 30 параметров каждая, занимает у нас в среднем 3.5 милисекунды. И при этом кроме поиска демон-серчер «Мамбы» выполняет следующие, в том числе не вполне традиционные задачи:
Несмотря на то, что наш поиск с самого начала разрабатывался собственными силами, время от времени возникали мысли использовать что-то уже известное, обкатанное и гарантированно эффективное. Ну, а если мы задумываемся о поиске, первым в голову приходит Sphinx. В какой-то момент мы решили проверить, может ли он дать нам серьезные преимущества, и несколько удивились полученным результатам. На тестовой базе в 2 миллиона анкет Sphinx показал средний результат в 100-120 мс в в зависимости от запроса, при этом в индекс мы (поскольку это всё-таки тест) включили только часть полей. Наш поиск на этой же базе и на таком же оборудовании тратит от 0.2 до 1.1 мс на запрос.
Как показала дальнейшая практика, половина успеха поиска заключена в создании правильного индекса. В нашем понимании правильный индекс — наиболее полно соответствующий задачам поиска и обеспечивающий наибольшую скорость обработки. После общего анализа базы индекс было решено разделить на несколько составных частей:
Но основные хитрости скрываются в структуре каждой части общего индекса, которые строятся следующим образом:
Что это означает для поиска? Например, у нас есть индекс по полям «пол» и «возраст», где пол может принимать значения «М» и «Ж», а возраст — от 18 до 21. Представим, что пользователь хочет найти девушку 20 лет (т. е. условиям удовлетворяют только по одному значению каждого поля).
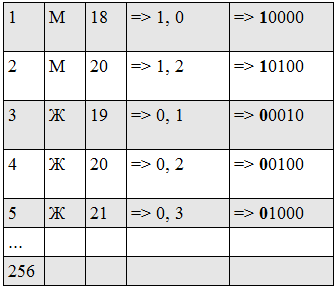
Допустим, у нас есть такие анкеты (показан 1 блок, поскольку минимально допустимый возраст 18, то 18 лет кодируется как 0000, 19 как 0010, 20 как 0100, и так далее)

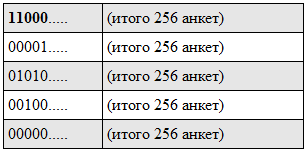
После обработки получается индекс следующего вида (жирным шрифтом выделен первый бит, до и после):
Для каких-то полей значение хранится некомпактно. Например, настоящее поле «возраст» принимает 64 значения. Можно хранить по 1 биту на возможное значение, то есть поле займёт 64 бита, но поиск будет занимать всего 1 операцию, а поиск по диапазону — 2 операции. Более традиционный вариант — хранить его как число, тогда это займёт log2(64) = 6 бит, но поиск конкретного возраста будет занимать 6 операций, а поиск по диапазону более 12 (точное значение зависит от длины записанного в виде ДНФ условия сравнения).
Сам процесс поиска происходит следующим образом:
Самое интересное — это код проверки поля. В сегменте результатов каждой анкете соответствует 1 бит, который показывает, подходит ли анкета под запрос или нет.
Обработка запроса происходит так:

После этого остается только пройти по битовому массиву с результатом и посмотреть, у каких анкет выставлены 1.
В нашем примере результатом будет 00010, то есть запросу удовлетворяет только анкета номер 4.
Демон поиска “Мамбы” вызывается со значительной части всех страниц сайта. Думаю, стоит отметить, что вместе с несколькими другими “основными” демонами он использует протокол JSON-RPC и в целом создает “единое демоническое пространство”.
Реальная статистика поиска выглядит следующим образом:
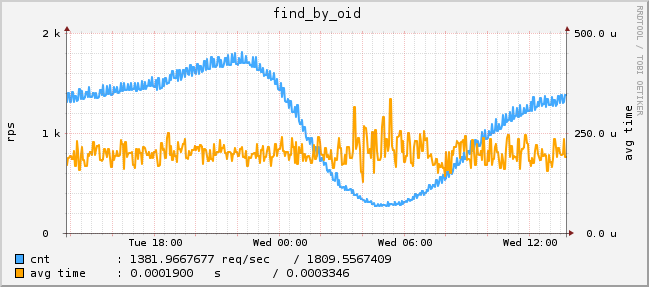
Рис. 1 Запросы на поиск по id анкеты (график с одного сервера)

Рис. 2 Запросы на поиск по параметрам (график с одного сервера)
Всего поиск работает на двух машинах, пиковая производительность одной — 20k операций поиска анкет по параметрам с полным подсчётом количества найденных анкет в секунду (это самая долгая операция, остальные работают значительно быстрее). Рабочая нагрузка — порядка 800 rps поиска + 1000 rps на получение места + 1500 rps на получение анкетных данных.
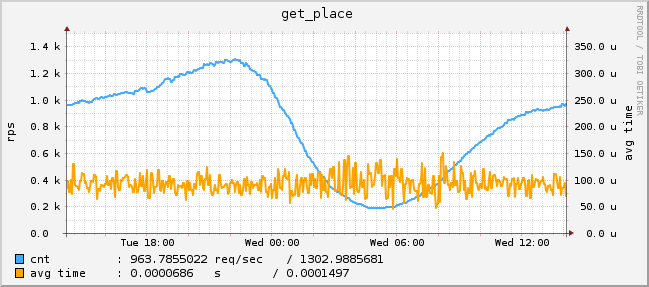
Рис. 3 Вывод места анкеты в поисковой выдаче (график с одного сервера)

Распределение полного времени ответа (т. е. с учётом сетевого взаимодействия) от всех (двух) поисковых серверов. Среднее — 2.5 мс, медиана — 1.5 мс, 5% запросов занимают более 10 мс и 1% запросов занимает более 15 мс.
Средний поиск по базе из 11 миллионов анкет, имеющих от 4 до 30 параметров каждая, занимает у нас в среднем 3.5 милисекунды. И при этом кроме поиска демон-серчер «Мамбы» выполняет следующие, в том числе не вполне традиционные задачи:
- для каждой конкретной анкеты выдает ее место в поиске (каждый пользователь, заходя в свою анкету, видит сообщение «Вы находитесь на N месте в поиске»)
- выдает конкретную анкету из списка по первичному ключу
- производит непосредственный поиск анкеты по заданным параметрам
Несмотря на то, что наш поиск с самого начала разрабатывался собственными силами, время от времени возникали мысли использовать что-то уже известное, обкатанное и гарантированно эффективное. Ну, а если мы задумываемся о поиске, первым в голову приходит Sphinx. В какой-то момент мы решили проверить, может ли он дать нам серьезные преимущества, и несколько удивились полученным результатам. На тестовой базе в 2 миллиона анкет Sphinx показал средний результат в 100-120 мс в в зависимости от запроса, при этом в индекс мы (поскольку это всё-таки тест) включили только часть полей. Наш поиск на этой же базе и на таком же оборудовании тратит от 0.2 до 1.1 мс на запрос.
Sphinx: source - mysql, индексировались только int поля через sql_attr_uint. Весь индекс в памяти.Как показала дальнейшая практика, половина успеха поиска заключена в создании правильного индекса. В нашем понимании правильный индекс — наиболее полно соответствующий задачам поиска и обеспечивающий наибольшую скорость обработки. После общего анализа базы индекс было решено разделить на несколько составных частей:
- анкеты, расположенные в Москве и области, имеющие фотографии (это наиболее часто запрашиваемый тип анкет)
- индекс ВИП-пользователей (ВИП-пользователи имеют определенные преимущества, в том числе в поисковой выдаче, поэтому обрабатываются отдельно)
- полный индекс всех типов анкет по всем полям каждой анкеты
Но основные хитрости скрываются в структуре каждой части общего индекса, которые строятся следующим образом:
- анкеты разбиваются на блоки по 256 анкет в блоке
- каждый блок кладётся в индекс: вначале 1-ый бит первого поля каждой анкеты, потом 2-ой бит от каждой анкеты, и т. д. Таким образом, данные одного бита из поля всех анкет идут подряд
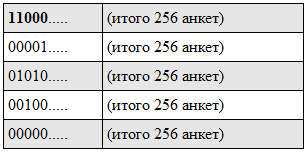
Что это означает для поиска? Например, у нас есть индекс по полям «пол» и «возраст», где пол может принимать значения «М» и «Ж», а возраст — от 18 до 21. Представим, что пользователь хочет найти девушку 20 лет (т. е. условиям удовлетворяют только по одному значению каждого поля).
Допустим, у нас есть такие анкеты (показан 1 блок, поскольку минимально допустимый возраст 18, то 18 лет кодируется как 0000, 19 как 0010, 20 как 0100, и так далее)
После обработки получается индекс следующего вида (жирным шрифтом выделен первый бит, до и после):
Для каких-то полей значение хранится некомпактно. Например, настоящее поле «возраст» принимает 64 значения. Можно хранить по 1 биту на возможное значение, то есть поле займёт 64 бита, но поиск будет занимать всего 1 операцию, а поиск по диапазону — 2 операции. Более традиционный вариант — хранить его как число, тогда это займёт log2(64) = 6 бит, но поиск конкретного возраста будет занимать 6 операций, а поиск по диапазону более 12 (точное значение зависит от длины записанного в виде ДНФ условия сравнения).
Сам процесс поиска происходит следующим образом:
- демон принимает и распарсивает запрос
- выделяется память под результаты (по биту на каждую анкету в индексе)
- выделяется сегмент памяти под скомпилированный запрос, ему ставится флаг выполнения
- в этот сегмент пишется:
- код инициализации, заголовок цикла
- для каждого поля, по которому нужно фильтровать результат, пишется код, который проверяет значение этого поля
- окончание цикла, проверка границ, подсчёт кол-ва найденного
- этот сегмент запускается на выполнение через обычный long jump
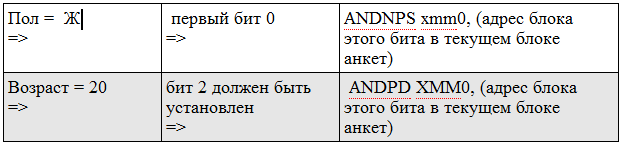
Самое интересное — это код проверки поля. В сегменте результатов каждой анкете соответствует 1 бит, который показывает, подходит ли анкета под запрос или нет.
Обработка запроса происходит так:
После этого остается только пройти по битовому массиву с результатом и посмотреть, у каких анкет выставлены 1.
В нашем примере результатом будет 00010, то есть запросу удовлетворяет только анкета номер 4.
Демон поиска “Мамбы” вызывается со значительной части всех страниц сайта. Думаю, стоит отметить, что вместе с несколькими другими “основными” демонами он использует протокол JSON-RPC и в целом создает “единое демоническое пространство”.
Реальная статистика поиска выглядит следующим образом:
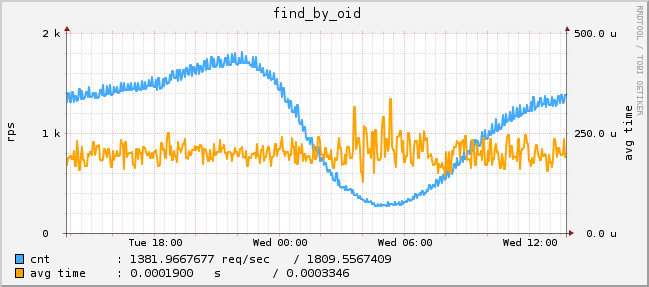
Рис. 1 Запросы на поиск по id анкеты (график с одного сервера)

Рис. 2 Запросы на поиск по параметрам (график с одного сервера)
Всего поиск работает на двух машинах, пиковая производительность одной — 20k операций поиска анкет по параметрам с полным подсчётом количества найденных анкет в секунду (это самая долгая операция, остальные работают значительно быстрее). Рабочая нагрузка — порядка 800 rps поиска + 1000 rps на получение места + 1500 rps на получение анкетных данных.

Рис. 3 Вывод места анкеты в поисковой выдаче (график с одного сервера)
Распределение полного времени ответа (т. е. с учётом сетевого взаимодействия) от всех (двух) поисковых серверов. Среднее — 2.5 мс, медиана — 1.5 мс, 5% запросов занимают более 10 мс и 1% запросов занимает более 15 мс.
