На практике нередко встречается задача не просто написать какой-то текст, а выполнить некоторые условия — например уложить максимум ключевых слов в заданную длину и/или использовать/не использовать определенные слова и словосочетания. Это бывает важно для бизнеса (при составление рекламных объявлений, в том числе, для контекстной рекламы, при SEO-оптимизации сайтов), для образовательных целей (автоматическое составление тестовых вопросов) и в ряде других случаев. Такие задачи оптимизации вызывают много головной боли, т. к. людям относительно легко сочинять тексты, но при этом не так просто написать что-то отвечающее тем или иным критериям «оптимальности». С другой стороны, компьютеры отлично справляются с задачами оптимизации в других областях, но плохо понимают естественный язык, и поэтому им трудно сочинять текст. В данной статье, рассмотрим известные подходы к решению этой задачи и немного поделимся собственным опытом.
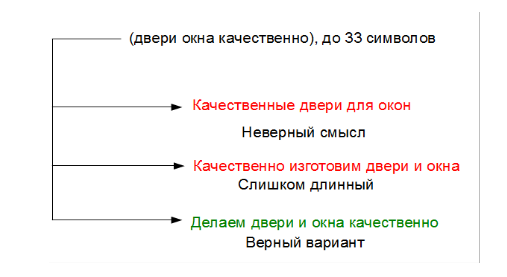
В качестве примера рассмотрим задачу написания предложения заданной длины на определенную тематику, куда должно войти определенное число ключевых слов. Скажем даны слова «двери, окна, качественно, изготовить» — надо составить предложение вроде «Качественно делаем окна и двери!».
Один из первых известных подходов для решения такой задачи — использование статистической модели языка. Модель языка — это функция распределения вероятности нахождения слов в определенной последовательности. Т.е. некая функция P(S) – которая позволяет, зная последовательность слов S, получить вероятность P встретить слова именно в этой последовательности. Чаще всего модель языка основывается на так называемых n-граммах, т. е. подсчете частоты получения словосочетаний из n слов в больших массивах текстов. Отношение числа встречаемости данного словосочетания к числу проанализированных словосочетаний дает аппроксимацию вероятности данного словосочетания. Поскольку вероятности длинных n-грамм оценить трудно (некоторые сочетания слов могут встречаться очень редко), то их вероятности тем или иным образом аппроксимируют, используя частоты более коротких последовательностей.
Применительно к нашему примеру, если у нас есть, скажем слово «Качественно», то мы можем с помощь функции P(S) оценить вероятности всех возможных словосочетаний исходных ключевых слов «Качественно окна», «Качественно двери», «Качественно изготовить». Скорее всего последнее будет иметь наибольшую вероятность. Поэтому мы добавляем слово «изготовить» к нашей строке и повторяем операцию, получая на следующем шаге «Качественно изготовить окна» и далее «Качественно изготовить окна двери».
Сразу видны минусы такого подхода. Во-первых, он использует слова только в исходных падежах и числах и поэтому мы никак не можем сказать, что нам предпочтительно использовать «изготовим» вместо «изготовить». Во-вторых, нет возможности использовать какие-либо другие слова, кроме исходных, поэтому получается неверное словосочетание «окна двери». Мы конечно можем легко разрешить использование любых слов, входящих в модель языка, например, предлогов, что сработает в данном случае. Но если ключевыми словами будет только «качественно окна двери», то предлоги не помогут и придется тщательно подбирать слова, которые модель может использовать «от себя».
Возникнут и другие сложности. Например, в описанном подходе модель языка ничего не знает о тех ключевых словах, которые она может использовать. Поэтому если сгенерируется начало «Качественно изготовить двери для», то потом неизбежно получится «Качественно изготовить двери для окна», или если использовать согласование в падежах «Качественно изготовить двери для окон», что все равно лишено смысла. Частично это можно устранить, если на каждом шаге сохранять всю историю возможностей. То есть, когда сочинилась фраза «двери для», были и другие варианты, в том числе «двери и». В отсутствие продолжения выбралось «двери для». Но если мы сохранили предыдущие варианты и достроили их тоже, то получится несколько альтернатив «двери и окна», «двери для окна», «двери под окна» и так далее. Из этих вариантов мы уже выбираем самый вероятный — «двери и окна».
Более сложный подход описан, например, в работах [1] Базируюсь на том же принципе, он, однако учитывает не просто вероятности n-грамм, но дополнительную лингвистическую информацию, определяя зависимости между словами. На основании списка ключевых слов, данный метод ищет в большом корпусе текстов употребления данных слов и генерирует на основании анализа зависимостей правила их использования. С помощью этих правил создаются тексты-кандидаты, из которых выбираются наиболее правдоподобные варианты. Помимо сложности реализации, недостатком данного способа является определенная зависимость от используемого языка, что усложняет его переносимость, а также тот факт, что на него получен патент, срок действия которого еще не истек.
Основные усилия в области текстовых генераторов были сконцентрированы в основном на добавлении все большего числа лингвистических признаков и созданных вручную правил, что привело к созданию довольно мощных систем, но ориентированных в основном на английский язык.
В последнее время снова возрос интерес к обучаемым системам генерации языка, что связано с появлением нейронных моделей языка (Neural language models). Появились архитектуры нейронных сетей, способные описывать содержание картинок, и осуществлять перевод с одного языка на другой. В предыдущих статьях мы рассматривали чат-бот на нейронных сетях и нейронный генератор описаний товаров. Интересно посмотреть, насколько нейросетевой генератор может решать данную специфическую задачу.
В качестве задачи мы выбрали проблему генерации заголовков объявлений контекстной рекламы из поисковых запросов, которая похожа на тот пример, который мы рассматривали. Взяв набор из 15 000 обучающих примеров в одной предметной области, мы применили нейронную сеть с архитектурой, описанной ранее [2], обучив ее генерировать новые заголовки. Особенностями данной архитектуры является то, что ей можно указать требуемую длину генерируемого текста и ключевые слова в качестве входных параметров. Для проверки мы сгенерировали 200 заголовков и оценили сколько из них получилось качественных:
Первые результаты оказались достаточно скромными:
Всего получилось 64% годных к использованию заголовков. Из негодных 5% превышали нужную длину, 10% содержало грамматические ошибки, а остальные меняли смысл, используя похожие, но другие слова.
После этого мы ввели в систему ряд модификаций и изменили нейросетевую архитектуру. Ключевым фактором для получения хорошего результата является возможность копирования слов из исходного текста в целевой [3]. Это существенно, так как на небольшой выборке в несколько десятков тысяч текстов (вместо миллионов предложений, как, например, в машинном переводе), система не может выучить очень много слов.
Несколько примеров:
Таким образом, годных к использованию заголовков стало 89%, при этом пропали заголовки, вообще искажающие смысл. Учитывая, что среди составленных людьми заголовков число «идеальных» достигает 68-77% в зависимости от квалификации человека, степени его усталости и.т.п., можно говорить о том, что возможности автоматической генерации составляют около 80% от возможностей человека. Это довольно неплохо, и открывает дорогу практическим применениям подобных систем, тем более, что возможности к совершенствованию еще далеко не исчерпаны.
Литература
1. Uchimoto, Kiyotaka, Hitoshi Isahara, and Satoshi Sekine. «Text generation from keywords.» Proceedings of the 19th international conference on Computational linguistics-Volume 1. Association for Computational Linguistics, 2002.
2. Tarasov D.S. (2015) Natural Language Generation, Paraphrasing and Summarization of User Reviews with Recurrent Neural Networks // Computational Linguistics and Intellectual Technologies: Proceedings of Annual International Conference “Dialogue”, Issue 14(21), V.1, pp. 571-579
3. Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. «Pointer networks.» Advances in Neural Information Processing Systems. 2015.
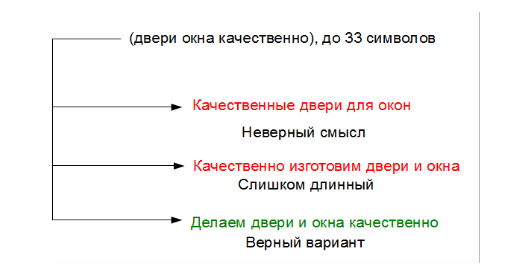
В качестве примера рассмотрим задачу написания предложения заданной длины на определенную тематику, куда должно войти определенное число ключевых слов. Скажем даны слова «двери, окна, качественно, изготовить» — надо составить предложение вроде «Качественно делаем окна и двери!».
Один из первых известных подходов для решения такой задачи — использование статистической модели языка. Модель языка — это функция распределения вероятности нахождения слов в определенной последовательности. Т.е. некая функция P(S) – которая позволяет, зная последовательность слов S, получить вероятность P встретить слова именно в этой последовательности. Чаще всего модель языка основывается на так называемых n-граммах, т. е. подсчете частоты получения словосочетаний из n слов в больших массивах текстов. Отношение числа встречаемости данного словосочетания к числу проанализированных словосочетаний дает аппроксимацию вероятности данного словосочетания. Поскольку вероятности длинных n-грамм оценить трудно (некоторые сочетания слов могут встречаться очень редко), то их вероятности тем или иным образом аппроксимируют, используя частоты более коротких последовательностей.
Применительно к нашему примеру, если у нас есть, скажем слово «Качественно», то мы можем с помощь функции P(S) оценить вероятности всех возможных словосочетаний исходных ключевых слов «Качественно окна», «Качественно двери», «Качественно изготовить». Скорее всего последнее будет иметь наибольшую вероятность. Поэтому мы добавляем слово «изготовить» к нашей строке и повторяем операцию, получая на следующем шаге «Качественно изготовить окна» и далее «Качественно изготовить окна двери».
Сразу видны минусы такого подхода. Во-первых, он использует слова только в исходных падежах и числах и поэтому мы никак не можем сказать, что нам предпочтительно использовать «изготовим» вместо «изготовить». Во-вторых, нет возможности использовать какие-либо другие слова, кроме исходных, поэтому получается неверное словосочетание «окна двери». Мы конечно можем легко разрешить использование любых слов, входящих в модель языка, например, предлогов, что сработает в данном случае. Но если ключевыми словами будет только «качественно окна двери», то предлоги не помогут и придется тщательно подбирать слова, которые модель может использовать «от себя».
Возникнут и другие сложности. Например, в описанном подходе модель языка ничего не знает о тех ключевых словах, которые она может использовать. Поэтому если сгенерируется начало «Качественно изготовить двери для», то потом неизбежно получится «Качественно изготовить двери для окна», или если использовать согласование в падежах «Качественно изготовить двери для окон», что все равно лишено смысла. Частично это можно устранить, если на каждом шаге сохранять всю историю возможностей. То есть, когда сочинилась фраза «двери для», были и другие варианты, в том числе «двери и». В отсутствие продолжения выбралось «двери для». Но если мы сохранили предыдущие варианты и достроили их тоже, то получится несколько альтернатив «двери и окна», «двери для окна», «двери под окна» и так далее. Из этих вариантов мы уже выбираем самый вероятный — «двери и окна».
Более сложный подход описан, например, в работах [1] Базируюсь на том же принципе, он, однако учитывает не просто вероятности n-грамм, но дополнительную лингвистическую информацию, определяя зависимости между словами. На основании списка ключевых слов, данный метод ищет в большом корпусе текстов употребления данных слов и генерирует на основании анализа зависимостей правила их использования. С помощью этих правил создаются тексты-кандидаты, из которых выбираются наиболее правдоподобные варианты. Помимо сложности реализации, недостатком данного способа является определенная зависимость от используемого языка, что усложняет его переносимость, а также тот факт, что на него получен патент, срок действия которого еще не истек.
Основные усилия в области текстовых генераторов были сконцентрированы в основном на добавлении все большего числа лингвистических признаков и созданных вручную правил, что привело к созданию довольно мощных систем, но ориентированных в основном на английский язык.
В последнее время снова возрос интерес к обучаемым системам генерации языка, что связано с появлением нейронных моделей языка (Neural language models). Появились архитектуры нейронных сетей, способные описывать содержание картинок, и осуществлять перевод с одного языка на другой. В предыдущих статьях мы рассматривали чат-бот на нейронных сетях и нейронный генератор описаний товаров. Интересно посмотреть, насколько нейросетевой генератор может решать данную специфическую задачу.
Наши результаты
В качестве задачи мы выбрали проблему генерации заголовков объявлений контекстной рекламы из поисковых запросов, которая похожа на тот пример, который мы рассматривали. Взяв набор из 15 000 обучающих примеров в одной предметной области, мы применили нейронную сеть с архитектурой, описанной ранее [2], обучив ее генерировать новые заголовки. Особенностями данной архитектуры является то, что ей можно указать требуемую длину генерируемого текста и ключевые слова в качестве входных параметров. Для проверки мы сгенерировали 200 заголовков и оценили сколько из них получилось качественных:
Первые результаты оказались достаточно скромными:
| Результат | Процент среди полученных заголовков |
| Идеальные заголовки | 34% |
| Хорошие заголовки | 31% |
| Плохие заголовки | 36% |
Всего получилось 64% годных к использованию заголовков. Из негодных 5% превышали нужную длину, 10% содержало грамматические ошибки, а остальные меняли смысл, используя похожие, но другие слова.
После этого мы ввели в систему ряд модификаций и изменили нейросетевую архитектуру. Ключевым фактором для получения хорошего результата является возможность копирования слов из исходного текста в целевой [3]. Это существенно, так как на небольшой выборке в несколько десятков тысяч текстов (вместо миллионов предложений, как, например, в машинном переводе), система не может выучить очень много слов.
| Результат | Процент среди полученных заголовков |
| Идеальные заголовки | 60% |
| Хорошие заголовки | 29% |
| Плохие заголовки | 11% |
Несколько примеров:
| Ключевые слова | Текст |
| оптовые поставки игрушек китая | оптовая игрушка из китая. Скидки |
| игрушка говорящая ферби отзывы | говорящая игрушка, где купить? |
| развивающие детей коврики | развивающие коврики для детей |
| куклы монстер хай обзор домик | все домики для кукол видео обзоры |
Таким образом, годных к использованию заголовков стало 89%, при этом пропали заголовки, вообще искажающие смысл. Учитывая, что среди составленных людьми заголовков число «идеальных» достигает 68-77% в зависимости от квалификации человека, степени его усталости и.т.п., можно говорить о том, что возможности автоматической генерации составляют около 80% от возможностей человека. Это довольно неплохо, и открывает дорогу практическим применениям подобных систем, тем более, что возможности к совершенствованию еще далеко не исчерпаны.
Литература
1. Uchimoto, Kiyotaka, Hitoshi Isahara, and Satoshi Sekine. «Text generation from keywords.» Proceedings of the 19th international conference on Computational linguistics-Volume 1. Association for Computational Linguistics, 2002.
2. Tarasov D.S. (2015) Natural Language Generation, Paraphrasing and Summarization of User Reviews with Recurrent Neural Networks // Computational Linguistics and Intellectual Technologies: Proceedings of Annual International Conference “Dialogue”, Issue 14(21), V.1, pp. 571-579
3. Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. «Pointer networks.» Advances in Neural Information Processing Systems. 2015.
