Этой статьей мы открываем серию материалов, посвященных азам разработки WinRT-приложений на HTML/JS для Windows 8. Мы последовательно пройдем путь от стартового практически пустого шаблона к полноценному приложению с серверной частью и живыми плитками.
Первая часть посвящена созданию простой версии приложения, читающего внешние данные через RSS-каналы на базе стандартного шаблона. В результате должен получиться работающий прототип приложения, способный показывать новости из нескольких RSS-потоков и отображать их на трех типах страниц: хаб (первая страница), группа и детали.
Откройте Visual Studio 2012, выберите создание нового проекта (File -> New -> Project…). Далее в шаблонах выберите проект на JavaScript -> Windows Store. Укажите, что будете использовать шаблон Grid App.

Укажите любое название проекта, например, Reader App.
Изучите структуру проекта:
Также по умолчанию к проекту подключена библиотека WinJS, содержащая наборы стилей для темной и светлой тем и вспомогательных функций и объектов на JavaScript.
Попробуйте запустить приложение, нажав F5, зеленую стрелочку или выбрав Debug -> Start Debugging.

Изучите работу приложения:
Вернитесь в Visual Studio и остановите отладку (Shift+F5, красный квадратик или выберите в меню Debug -> Stop Debugging).
Откройте файл js\data.js. В нем объявлено несколько важных функций и объектов, которые мы также будет использовать.
Первым делом необходимо избавиться от строчек кода, генерирующих примеры данных. Для этого удалите следующие строчки:
Если вы запустите приложение, оно продолжит работать, только в нем будут отсутствовать какие-либо данные. Остановите отладку и вернитесь к файлу data.js. Давайте вкратце пройдемся по его структуре, чтобы были понятны дальнейшие действия:
Создается список, который будет использоваться для связки данных с отображением. В него мы будем заносить те блоки информации, которые хотим вывести на экран.
На основании списка создается группированная коллекция, при создании которой с помощью специальных функций указывается, как элементы коллекции разделять на отдельные группы.
Через функцию define в библиотеке WinJS (Namespace) прописывается глобальный объект Data, который будет доступен из других частей программы для работы с нашими данными. Внутри объекта прописываются ссылки на группированную коллекцию, список групп внутри нее и ряд функций, описанных в файле data.js и используемых для работы с коллекцией и извлечения данных.
Оставшиеся 4 функции (getItemReference, getItemsFromGroup, resolveGroupReference и resolveItemReference) используются для сравнения объектов, извлечения подмножеств элементов, принадлежащих одной группе, определения группы по ключу и элемента по набору уникальных идентификаторов.
Теперь самое время приступить к добавлению наших собственных данных. В качестве источников мы будет использовать внешние RSS-потоки.
Вернитесь к началу файла и после строчки «use strict» опишите блоги, информацию из которых вы будете выводить:
Для описания каждого блога (группы контента) мы указываем:
Чтобы превратить ссылки в данные на компьютере, информацию по ним необходимо загрузить. Для этого после строчки var list = new WinJS.Binding.List(); добавьте новую функцию getBlogPosts, которая как раз будет заниматься загрузкой:
В данной функции мы в цикле проходимся по всем блогам, для каждой ссылки через функцию WinJS.xhr создаем асинхронную Promise-обертку вокруг XMLHttpRequest-запроса и после получения результата (then) передаем полученный ответ на обработку в функцию processRSSFeed, которую мы опишем ниже.
Для обработки потока добавьте нижу еще одну функцию — processRSSFeed:
В данной функции мы пользуемся тем фактом, что на входе имеем XML-файл с известной структурой (RSS 2.0), по которому можно перемещаться используя DOM-модель, в частности, функцию querySelector, используя которую, можно вытаскивать из полученного документа необходимые данные.
Полученное текстовое значение последней даты обновления мы преобразуем в нужный формат, используя функции глобализации, доступные через API WinRT.
В конце мы передаем документ на дальнейшую обработку в функцию getItemsFromRSSFeed, которая выделяет отдельные посты и заносит их в коллекцию posts.
Добавьте ниже следующую функцию:
В данной функции мы проходимся в цикле по всем постам в полученном потоке, выбирая из XML-описания нужные поля (заголовок, дату публикации, контент и т.п.), после чего собираем нужную информацию в один объект (postItem), который добавляем в список постов.
Обратите внимание на форматирование дат и привязку каждого поста к соответствующей группе. Также заметьте, что для повышения безопасности полученное содержимое поста мы приводим к статическому виду с помощью функции toStaticHTML.
Добавьте ниже следующую строчку, чтобы запустить считывание блогов:
Запустите приложение на отладку:

Как видите, оно уже использует наши новые данные, однако, есть несколько «проблемных» зон, которые необходимо поправить:
Этими задачами мы займемся в следующих статьях.
Первая часть посвящена созданию простой версии приложения, читающего внешние данные через RSS-каналы на базе стандартного шаблона. В результате должен получиться работающий прототип приложения, способный показывать новости из нескольких RSS-потоков и отображать их на трех типах страниц: хаб (первая страница), группа и детали.
Создание приложения из шаблона
Откройте Visual Studio 2012, выберите создание нового проекта (File -> New -> Project…). Далее в шаблонах выберите проект на JavaScript -> Windows Store. Укажите, что будете использовать шаблон Grid App.
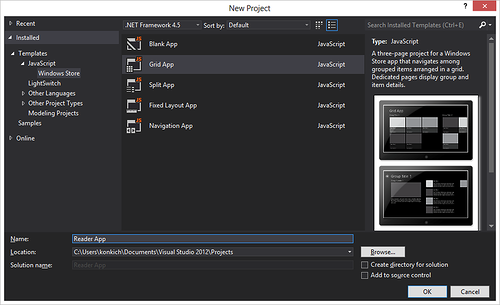
Укажите любое название проекта, например, Reader App.
Изучите структуру проекта:
- package.appxmanifest — манифест приложения, описывающий ключевые настройки, используемые возможности, название приложения, плитки и другие параметры;
- default.html — формальная стартовая страница приложения;
- pages\groupedItems — папка с html-, js- и css-файлами для страницы представления групп контента (подгружается в стартовую страницу);
- pages\groupDetail — папка с html-, js- и css-файлами для страницы отображения группы новостей (записей в rss-потоке), соответствующих одному потоку;
- pages\itemDetail — папка с html-, js- и css-файлами для страницы отображения каждой из новостей отдельно;
- js\data.js — js-файл, описывающий работу с данными (содержит зашитые внутрь демонстрационные данные);
- js\default.js — описывает события, необходимые для инициализации приложения;
- js\navigator.js — описывает логику переходов между страницами и необходимые для этого события и объекты;
- images\logo.png — изображение, используемое для квадратной плитки;
- images\smalllogo.png — изображение, используемое при перечислении приложения в операционной системе, например, при поиске или выборе приложений для поиска или общего доступа;
- images\splashscreen.png — загрузочное изображение, показываемое при открытии приложения;
- images\storelogo.png — изображение, используемое в интерфейсе магазина приложений (Windows Store).
Также по умолчанию к проекту подключена библиотека WinJS, содержащая наборы стилей для темной и светлой тем и вспомогательных функций и объектов на JavaScript.
Попробуйте запустить приложение, нажав F5, зеленую стрелочку или выбрав Debug -> Start Debugging.

Изучите работу приложения:
- Попробуйте нажать на отдельную серую плитку или на заголовок группы.
- Попробуйте нажать на кнопку назад во внутренних страницах.
- Попробуйте перевести приложение в Snapped-режим.
Вернитесь в Visual Studio и остановите отладку (Shift+F5, красный квадратик или выберите в меню Debug -> Stop Debugging).
Замена источников данных
Откройте файл js\data.js. В нем объявлено несколько важных функций и объектов, которые мы также будет использовать.
Первым делом необходимо избавиться от строчек кода, генерирующих примеры данных. Для этого удалите следующие строчки:
- Вставка данных в список:
// You can add data from asynchronous sources whenever it becomes available. generateSampleData().forEach(function (item) { list.push(item); });
- Генерация примеров данных:
// Returns an array of sample data that can be added to the application's // data list. function generateSampleData() { var itemContent = "<p>Curabitur class … "; var itemDescription = "Item Description: Pellente…"; var groupDescription = "Group Description: Lorem …"; … return sampleItems; }
Если вы запустите приложение, оно продолжит работать, только в нем будут отсутствовать какие-либо данные. Остановите отладку и вернитесь к файлу data.js. Давайте вкратце пройдемся по его структуре, чтобы были понятны дальнейшие действия:
var list = new WinJS.Binding.List();Создается список, который будет использоваться для связки данных с отображением. В него мы будем заносить те блоки информации, которые хотим вывести на экран.
var groupedItems = list.createGrouped(
function groupKeySelector(item) { return item.group.key; },
function groupDataSelector(item) { return item.group; }
);На основании списка создается группированная коллекция, при создании которой с помощью специальных функций указывается, как элементы коллекции разделять на отдельные группы.
WinJS.Namespace.define("Data", {
items: groupedItems,
groups: groupedItems.groups,
getItemReference: getItemReference,
getItemsFromGroup: getItemsFromGroup,
resolveGroupReference: resolveGroupReference,
resolveItemReference: resolveItemReference
});Через функцию define в библиотеке WinJS (Namespace) прописывается глобальный объект Data, который будет доступен из других частей программы для работы с нашими данными. Внутри объекта прописываются ссылки на группированную коллекцию, список групп внутри нее и ряд функций, описанных в файле data.js и используемых для работы с коллекцией и извлечения данных.
Оставшиеся 4 функции (getItemReference, getItemsFromGroup, resolveGroupReference и resolveItemReference) используются для сравнения объектов, извлечения подмножеств элементов, принадлежащих одной группе, определения группы по ключу и элемента по набору уникальных идентификаторов.
Теперь самое время приступить к добавлению наших собственных данных. В качестве источников мы будет использовать внешние RSS-потоки.
Важно: в рамках данной статьи в целях упрощения кода для получения данных мы будет использовать только RSS-потоки, однако, добавление поддержки Atom-потоков не должно составить труда, так как они имеют схожую структуру и ключевая разница будет в адресации искомых полей данных.
Вернитесь к началу файла и после строчки «use strict» опишите блоги, информацию из которых вы будете выводить:
var blogs = [
{
key: "ABlogging",
url: "http://blogs.windows.com/windows/b/bloggingwindows/rss.aspx",
title: 'Blogging Windows', rsstitle: 'tbd', updated: 'tbd',
dataPromise: null
},
{
key: "BExperience",
url: 'http://blogs.windows.com/windows/b/windowsexperience/rss.aspx',
title: 'Windows Experience', rsstitle: 'tbd', updated: 'tbd',
dataPromise: null
},
{
key: "CExtreme",
url: 'http://blogs.windows.com/windows/b/extremewindows/rss.aspx',
title: 'Extreme Windows', rsstitle: 'tbd', updated: 'tbd',
dataPromise: null
}];
Для описания каждого блога (группы контента) мы указываем:
- ключ — key (так как сортировка групп будет по ключу, мы также добавили в начале группы латинские буквы для явного задания сортировки — в реальном проекте это можно сделать более элегантным способом),
- ссылку на RSS-поток — url,
- название потока — title,
- несколько заглушек:
- реальное название блога — rsstitle,
- дата обновления (updated),
- указатель на dataPromise — «обещание» загрузить этот поток и его обработать.
Чтобы превратить ссылки в данные на компьютере, информацию по ним необходимо загрузить. Для этого после строчки var list = new WinJS.Binding.List(); добавьте новую функцию getBlogPosts, которая как раз будет заниматься загрузкой:
function getBlogPosts(postsList) {
blogs.forEach(function (feed) {
// Создание Promise
feed.dataPromise = WinJS.xhr( { url: feed.url } ).then(
function (response) {
if (response) {
var syndicationXML = response.responseXML || (new DOMParser()).parseFromString(response.responseText, "text/xml");
processRSSFeed(syndicationXML, feed, postsList);
}
}
);
});
return postsList;
}
В данной функции мы в цикле проходимся по всем блогам, для каждой ссылки через функцию WinJS.xhr создаем асинхронную Promise-обертку вокруг XMLHttpRequest-запроса и после получения результата (then) передаем полученный ответ на обработку в функцию processRSSFeed, которую мы опишем ниже.
Замечание: для используемых нами блогов нет необходимости в дополнительной проверке, что мы получили ответ в виде XML (наличие responseXML), однако, в общем случае это неверно: некоторые блоги из-за неверных настроек сервера/движка отдают RSS-поток как текстовое содержимое, которое необходимо дополнительно обрабатывать, если мы хотим работать с ним как с XML-файлом.
Для обработки потока добавьте нижу еще одну функцию — processRSSFeed:
function processRSSFeed(articleSyndication, feed, postsList) {
// Название блога
feed.rsstitle = articleSyndication.querySelector("rss > channel > title").textContent;
// Используем дату публикации последнего поста как дату обновления
var published = articleSyndication.querySelector("rss > channel > item > pubDate").textContent;
// Преобразуем дату в удобрый формат
var date = new Date(published);
var dateFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter(
"day month.abbreviated year.full");
var blogDate = dateFmt.format(date);
feed.updated = "Обновление: " + blogDate;
// Обработка постов
getItemsFromRSSFeed(articleSyndication, feed, postsList);
}
В данной функции мы пользуемся тем фактом, что на входе имеем XML-файл с известной структурой (RSS 2.0), по которому можно перемещаться используя DOM-модель, в частности, функцию querySelector, используя которую, можно вытаскивать из полученного документа необходимые данные.
Полученное текстовое значение последней даты обновления мы преобразуем в нужный формат, используя функции глобализации, доступные через API WinRT.
В конце мы передаем документ на дальнейшую обработку в функцию getItemsFromRSSFeed, которая выделяет отдельные посты и заносит их в коллекцию posts.
Добавьте ниже следующую функцию:
function getItemsFromRSSFeed(articleSyndication, feed, postsList) {
var posts = articleSyndication.querySelectorAll("item");
// Цикл по каждому посту в потоке
var length = posts.length;
for (var postIndex = 0; postIndex < length; postIndex++) {
var post = posts[postIndex];
// форматирование даты
var postPublished = post.querySelector("pubDate").textContent;
var postDate = new Date(postPublished);
var monthFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("month.abbreviated");
var dayFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("day");
var yearFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("year.full");
var timeFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("shorttime");
var postContent = toStaticHTML(post.querySelector("description").textContent);
var postItem = {
index: postIndex,
group: feed,
// заголовок поста
title: post.querySelector("title").textContent,
// дата и отдельные компоненты
postDate: postDate,
month: monthFmt.format(postDate).toUpperCase(),
day: dayFmt.format(postDate),
year: yearFmt.format(postDate),
time: timeFmt.format(postDate),
// содержимое поста
content: postContent,
// ссылка на пост
link: post.querySelector("link").textContent
};
postsList.push(postItem);
}
}
В данной функции мы проходимся в цикле по всем постам в полученном потоке, выбирая из XML-описания нужные поля (заголовок, дату публикации, контент и т.п.), после чего собираем нужную информацию в один объект (postItem), который добавляем в список постов.
Обратите внимание на форматирование дат и привязку каждого поста к соответствующей группе. Также заметьте, что для повышения безопасности полученное содержимое поста мы приводим к статическому виду с помощью функции toStaticHTML.
Замечание: в общем случае работы с RSS-потоками из неконтролируемых источников нужно внимательно контролировать (и исследовать) получаемые данные. На практике часть данных по искомым полям может отсутствовать, поэтому прежде, чем извлекать текстовое содержимое (textContent) необходимо убеждаться, что предыдущая операция вернула не null-значение. В некоторых случаях полное содержимое поста может скрываться за элементами encoded или full-text или и вовсе отсутствовать. Также известны случаи, когда сервер отдает дату в неправильном формате, в результате чего стандартный парсер выдает исключение.
Добавьте ниже следующую строчку, чтобы запустить считывание блогов:
list = getBlogPosts(list);Запустите приложение на отладку:
Как видите, оно уже использует наши новые данные, однако, есть несколько «проблемных» зон, которые необходимо поправить:
- нет картинок,
- в отдельных строчках выводится странное «undefined»,
- на главной странице выводится сразу весь список из потока, а хочется его ограничить несколькими записями.
Этими задачами мы займемся в следующих статьях.
