На первый взгляд, Clean Architecture – довольно простой набор рекомендаций к построению приложений. Но и я, и многие мои коллеги, сильные разработчики, осознали эту архитектуру не сразу. А в последнее время в чатах и интернете я вижу всё больше ошибочных представлений, связанных с ней. Этой статьёй я хочу помочь сообществу лучше понять Clean Architecture и избавиться от распространенных заблуждений.
Сразу хочу оговориться, заблуждения – это дело личное. Каждый в праве заблуждаться. И если это его устраивает, то я не хочу мешать. Но всегда хорошо услышать мнения других людей, а зачастую люди не знают даже мнений тех, кто стоял у истоков.
Истоки
В 2011 году Robert C. Martin, также известный как Uncle Bob, опубликовал статью Screaming Architecture, в которой говорится, что архитектура должна «кричать» о самом приложении, а не о том, какие фреймворки в нем используются. Позже вышла статья, в которой Uncle Bob даёт отпор высказывающимся против идей чистой архитектуры. А в 2012 году он опубликовал статью «The Clean Architecture», которая и является основным описанием этого подхода. Кроме этих статей я также очень рекомендую посмотреть видео выступления Дяди Боба.
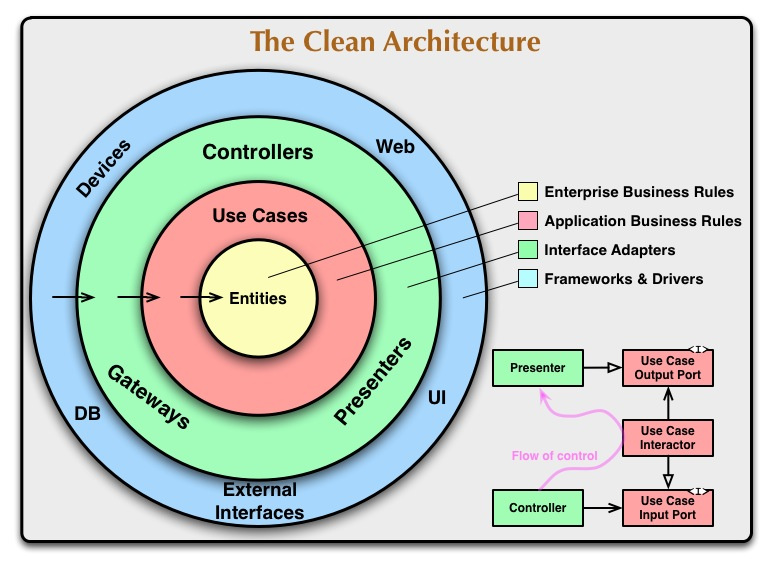
Вот оригинальная схема из статьи, которая первой всплывает в голове разработчика, когда речь заходит о Clean Architecture:
В Android-сообществе Clean стала быстро набирать популярность после статьи Architecting Android...The clean way?, написанной Fernando Cejas. Я впервые узнал про Clean Architecture именно из неё. И только потом пошёл искать оригинал. В этой статье Fernando приводит такую схему слоёв:
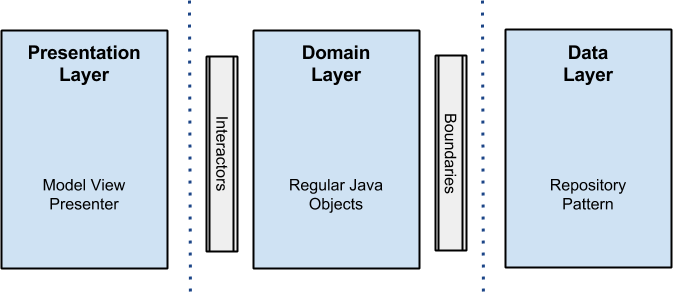
То, что на этой схеме другие слои, а в domain слое лежат ещё какие-то Interactors и Boundaries, сбивает с толку. Оригинальная картинка тоже не всем понятна. В статьях многое неоднозначно или слегка абстрактно. А видео не все смотрят (обычно из-за недостаточного знания английского). И вот, из-за недопонимания, люди начинают что-то выдумывать, усложнять, заблуждаться…
Давайте разбираться!
Сlean Architecture
Clean Architecture объединила в себе идеи нескольких других архитектурных подходов, которые сходятся в том, что архитектура должна:
- быть тестируемой;
- не зависеть от UI;
- не зависеть от БД, внешних фреймворков и библиотек.
Это достигается разделением на слои и следованием Dependency Rule (правилу зависимостей).
Dependency Rule
Dependency Rule говорит нам, что внутренние слои не должны зависеть от внешних. То есть наша бизнес-логика и логика приложения не должны зависеть от презентеров, UI, баз данных и т.п. На оригинальной схеме это правило изображено стрелками, указывающими внутрь.
В статье сказано: имена сущностей (классов, функций, переменных, чего угодно), объявленных во внешних слоях, не должны встречаться в коде внутренних слоев.
Это правило позволяет строить системы, которые будет проще поддерживать, потому что изменения во внешних слоях не затронут внутренние слои.
Слои
Uncle Bob выделяет 4 слоя:
- Entities. Бизнес-логика общая для многих приложений.
- Use Cases (Interactors). Логика приложения.
- Interface Adapters. Адаптеры между Use Cases и внешним миром. Сюда попадают Presenter’ы из MVP, а также Gateways (более популярное название репозитории).
- Frameworks. Самый внешний слой, тут лежит все остальное: UI, база данных, http-клиент, и т.п.
Подробнее, что из себя представляют эти слои, мы рассмотрим по ходу статьи. А пока остановимся на передаче данных между ними.
Переходы
Переходы между слоями осуществляются через Boundaries, то есть через два интерфейса: один для запроса и один для ответа. Их можно увидеть справа на оригинальной схеме (Input/OutputPort). Они нужны, чтобы внутренний слой не зависел от внешнего (следуя Dependency Rule), но при этом мог передать ему данные.
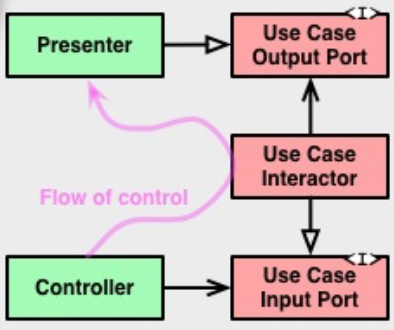
Оба интерфейса относятся к внутреннему слою (обратите внимание на их цвет на картинке).
Смотрите, Controller вызывает метод у InputPort, его реализует UseCase, а затем UseCase отдает ответ интерфейсу OutputPort, который реализует Presenter. То есть данные пересекли границу между слоями, но при этом все зависимости указывают внутрь на слой UseCase’ов.
Чтобы зависимость была направлена в сторону обратную потоку данных, применяется принцип инверсии зависимостей (буква D из аббревиатуры SOLID). То есть, вместо того чтобы UseCase напрямую зависел от Presenter’a (что нарушало бы Dependency Rule), он зависит от интерфейса в своём слое, а Presenter должен этот интерфейс реализовать.
Точно та же схема работает и в других местах, например, при обращении UseCase к Gateway/Repository. Чтобы не зависеть от репозитория, выделяется интерфейс и кладется в слой UseCases.
Что же касается данных, которые пересекают границы, то это должны быть простые структуры. Они могут передаваться как DTO или быть завернуты в HashMap, или просто быть аргументами при вызове метода. Но они обязательно должны быть в форме более удобной для внутреннего слоя (лежать во внутреннем слое).
Особенности мобильных приложений
Надо отметить, что Clean Architecture была придумана с немного иным типом приложений на уме. Большие серверные приложения для крупного бизнеса, а не мобильные клиент-серверные приложения средней сложности, которые не нуждаются в дальнейшем развитии (конечно, бывают разные приложения, но согласитесь, в большей массе они именно такие). Непонимание этого может привести к overengineering’у.
На оригинальной схеме есть слово Controllers. Оно появилось на схеме из-за frontend’a, в частности из Ruby On Rails. Там зачастую разделяют Controller, который обрабатывает запрос и отдает результат, и Presenter, который выводит этот результат на View. Многие не сразу догадываются, но в android-приложениях Controllers не нужны.
Ещё в статье Uncle Bob говорит, что слоёв не обязательно должно быть 4. Может быть любое количество, но Dependency Rule должен всегда применяться.
Глядя на схему из статьи Fernando Cejas, можно подумать, что автор воспользовался как раз этой возможностью и уменьшил количество слоев до трёх. Но это не так. Если разобраться, то в Domain Layer у него находятся как Interactors (это другое название UseCase’ов), так и Entities.
Все мы благодарны Fernando за его статьи, которые дали хороший толчок развитию Clean в Android-сообществе, но его схема также породила и заблуждение.
Заблуждение: Слои и линейность
Сравнивая оригинальную схему от Uncle Bob’a и cхему Fernando Cejas’a многие начинают путаться. Линейная схема воспринимается проще, и люди начинают неверно понимать оригинальную. А не понимая оригинальную, начинают неверно толковать и линейную. Кто-то думает, что расположение надписей в кругах имеет сакральное значение, или что надо использовать Controller, или пытаются соотнести названия слоёв на двух схемах. Смешно и грустно, но основные схемы стали основными источниками заблуждения!
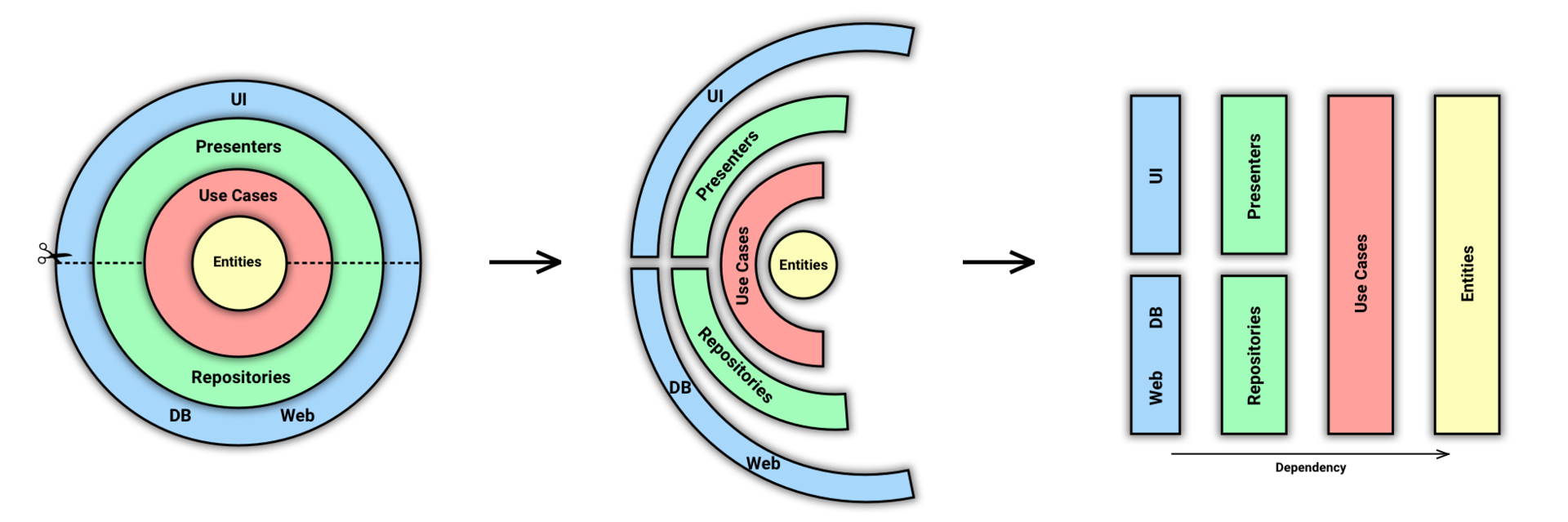
Постараемся это исправить. Для начала давайте очистим основную схему, убрав из нее лишнее для нас. И переименуем Gateways в Repositories, т.к. это более распространенное название этой сущности.
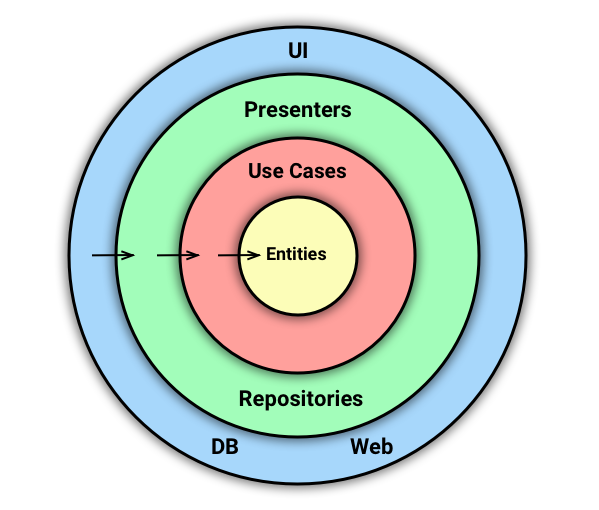
Стало немного понятнее. Теперь мы сделаем вот что: разрежем слои на части и превратим эту схему в блочную, где цвет будет по-прежнему обозначать принадлежность к слою.
Как я уже сказал выше, цвета обозначают слои. А стрелка внизу обозначает Dependency Rule.
На получившейся схеме уже проще представить себе течение данных от UI к БД или серверу и обратно. Но давайте сделаем еще один шаг к линейности, расположив слои по категориям:

Я намеренно не называю это разделение слоями, в отличие от Fernando Cejas. Потому что мы и так делим слои. Я называю это категориями или частями. Можно назвать как угодно, но повторно использовать слово «слои» не стоит.
А теперь давайте сравним то, что получилось, со схемой Fernando.
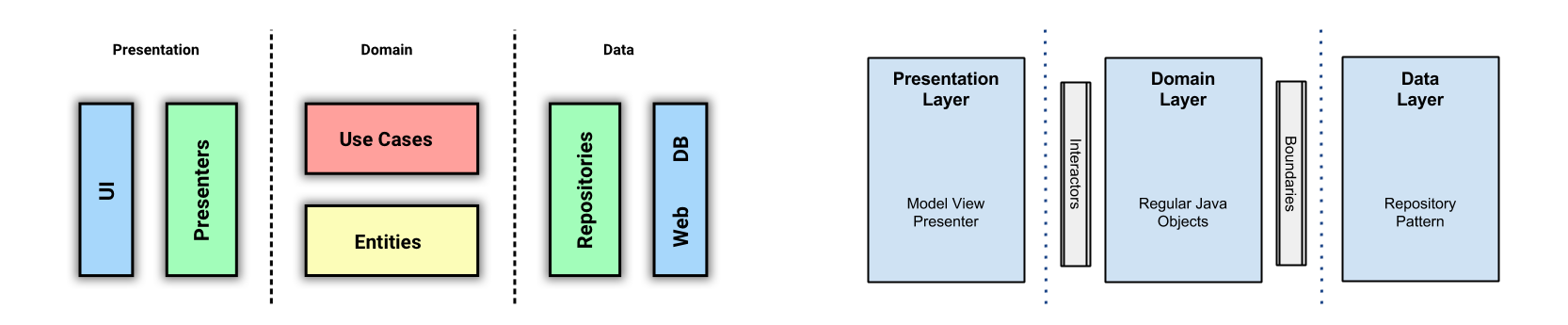
Надеюсь теперь вcё начало вставать на свои места. Выше я говорил, что, по моему мнению, у Fernando всё же 4 слоя. Думаю теперь это тоже стало понятнее. В Domain части у нас находятся и UseCases и Entities.
Такая схема воспринимается проще. Ведь обычно события и данные в наших приложениях ходят от UI к backend’у или базе данных и обратно. Давайте изобразим этот процесс:
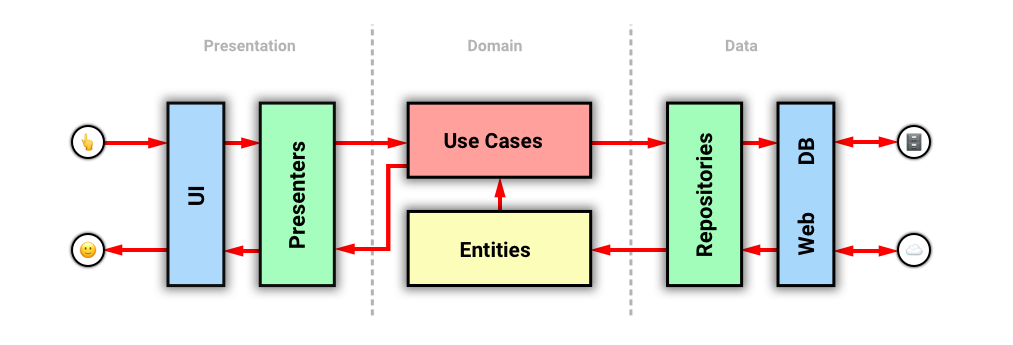
Красными стрелками показано течение данных.
Событие пользователя идет в Presenter, тот передает в Use Case. Use Case делает запрос в Repository. Repository получает данные где-то, создает Entity, передает его в UseCase. Так Use Case получает все нужные ему Entity. Затем, применив их и свою логику, получает результат, который передает обратно в Presenter. А тот, в свою очередь, отображает результат в UI.
На переходах между слоями (не категориями, а слоями, отмеченными разным цветом) используются Boundaries, описанные ранее.
Теперь, когда мы поняли, как соотносятся две схемы, давайте рассмотрим следующее заблуждение.
Заблуждение: Слои, а не сущности
Как понятно из заголовка, кто-то думает, что на схемах изображены сущности (особенно это затрагивает UseCases и Entities). Но это не так.
На схемах изображены слои, в них может находиться много сущностей. В них будут находиться интерфейсы для переходов между слоями (Boundaries), различные DTO, основные классы слоя (Interactors для слоя UseCases, например).
Не будет лишним взглянуть на схему, собранную из частей, показанных в видео выступления Uncle Bob’a. На ней изображены классы и зависимости:

Видите двойные линии? Это границы между слоями. Разделение между слоями Entities и UseCases не показаны, так как в видео основной упор делался на том, что вся логика (приложения и бизнеса) отгорожена от внешнего мира.
C Boundaries мы уже знакомы, интерфейс Gateway – это то же самое. Request/ResponseModel – просто DTO для передачи данных между слоями. По правилу зависимости они должны лежать во внутреннем слое, что мы и видим на картинке.
Про Controller мы тоже уже говорили, он нас не интересует. Его функцию у нас выполняет Presenter.
А ViewModel на картинке – это не ViewModel из MVVM и не ViewModel из Architecture Components. Это просто DTO для передачи данных View, чтобы View была тупой и просто сетила свои поля. Но это уже детали реализации и будет зависеть от выбора презентационного паттерна и личных подходов.
В слое UseCases находятся не только Interactor’ы, но также и Boundaries для работы с презентером, интерфейс для работы с репозиторием, DTO для запроса и ответа. Отсюда можно сделать вывод, что на оригинальной схеме отражены всё же слои.
Заблуждение: Entities
Entities по праву занимают первое место по непониманию.
Мало того, что почти никто (включая меня до недавнего времени) не осознает, что же это такое на самом деле, так их ещё и путают с DTO.
Однажды в чате у меня возник спор, в котором мой оппонент доказывал мне, что Entity – это объекты, полученные после парсинга JSON в data-слое, а DTO – объекты, которыми оперируют Interactor’ы…
Постараемся хорошо разобраться, чтобы таких заблуждений больше не было ни у кого.
Что же такое Entities?
Чаще всего они воспринимаются как POJO-классы, с которыми работают Interactor’ы. Но это не так. По крайней мере не совсем.
В статье Uncle Bob говорит, что Entities инкапсулируют логику бизнеса, то есть всё то, что не зависит от конкретного приложения, а будет общим для многих. Но если у вас отдельное приложение и оно не заточено под какой-то существующий бизнес, то Entities будут являться бизнес-объектами приложения, содержащими самые общие и высокоуровневые правила.
Я думаю, что именно фраза: «Entities это бизнес объекты», – запутывает больше всего. Кроме того, на приведенной выше схеме из видео Interactor получает Entity из Gateway. Это также подкрепляет ощущение, что это просто POJO объекты.
Но в статье также говорится, что Entity может быть объектом с методами или набором структур и функций. То есть упор делается на то, что важны методы, а не данные.
Это также подтверждается в разъяснении от Uncle Bob’а, которое я нашел недавно:
Uncle Bob говорит, что для него Entities содержат бизнес-правила, независимые от приложения. И они не просто объекты с данными. Entities могут содержать ссылки на объекты с данными, но основное их назначение в том, чтобы реализовать методы бизнес-логики, которые могут использоваться в различных приложениях.
А по-поводу того, что Gateways возвращают Entities на картинке, он поясняет следующее:
Реализация Gаteway получает данные из БД, и использует их, чтобы создать структуры данных, которые будут переданы в Entities, которые Gateway вернет. Реализовано это может быть композицией
class MyEntity { private MyDataStructure data;}или наследованием
class MyEntity extends MyDataStructure {...} И в конце ответа фраза, которая меня очень порадовала:
And remember, we are all pirates by nature; and the rules I'm talking about here are really more like guidelines…
(И запомните: мы все пираты по натуре, и правила, о которых я говорю тут, на самом деле, скорее рекомендации…)
Действительно, не надо слишком буквально всё воспринимать, надо искать компромиссы и не делать лишнего. Все-таки любая архитектура призвана помогать, а не мешать.
Итак, слой Entities содержит:
- Entities – функции или объекты с методами, которые реализуют логику бизнеса, общую для многих приложений (а если бизнеса нет, то самую высокоуровневую логику приложения);
- DTO, необходимые для работы и перехода между слоями.
Кроме того, когда приложение отдельное, то надо стараться находить и выделять в Entities высокоуровневую логику из слоя UseCases, где зачастую она оседает по ошибке.
Заблуждение: UseCase и/или Interactor
Многие путаются в понятиях UseCase и Interactor. Я слышал фразы типа: «Канонического определения Interactor нет». Или вопросы типа: «Мне делать это в Interactor’e или вынести в UseCase?».
Косвенное определение Interactor’a встречается в статье, которую я уже упоминал в самом начале. Оно звучит так:
«...interactor object that implements the use case by invoking business objects.»
Таким образом:
Interactor – объект, который реализует use case (сценарий использования), используя бизнес-объекты (Entities).
Что же такое Use Case или сценарий использования?
Uncle Bob в видео выступлении говорит о книге «Object-Oriented Software Engineering: A Use Case Driven Approach», которую написал Ivar Jacobson в 1992 году, и о том, как тот описывает Use Case.
Use case – это детализация, описание действия, которое может совершить пользователь системы.
Вот пример, который приводится в видео:

Это Use Case для создания заказа, причём выполняемый клерком.
Сперва перечислены входные данные, но не даётся никаких уточнений, что они из себя представляют. Тут это не важно.
Первый пункт – даже не часть Use Case’a, это его старт – клерк запускает команду для создания заказа с нужными данными.
Далее шаги:
- Система валидирует данные. Не оговаривается как.
- Система создает заказ и id заказа. Подразумевается использование БД, но это не важно пока, не уточняется. Как-то создает и всё.
- Система доставляет id заказа клерку. Не уточняется как.
Легко представить, что id возвращается не клерку, а, например, выводится на страницу сайта. То есть Use Case никак не зависит от деталей реализации.
Ivar Jacobson предложил реализовать этот Use Case в объекте, который назвал ControlObject.
Но Uncle Bob решил, что это плохая идея, так как путается с Controller из MVC и стал называть такой объект Interactor. И он говорит, что мог бы назвать его UseCase.
Это можно посмотреть примерно в этом моменте видео.
Там же он говорит, что Interactor реализует use case и имеет метод для запуска execute() и получается, что это паттерн Команда. Интересно.
Вернемся к нашим заблуждениям.
Когда кто-то говорит, что у Interactor’a нет четкого определения – он не прав. Определение есть и оно вполне четкое. Выше я привел несколько источников.
Многим нравится объединять Interactor’ы в один общий с набором методов, реализующих use case’ы.
Если вам сильно не нравятся отдельные классы, можете так делать, это ваше решение. Я лично за отдельные Interactor’ы, так как это даёт больше гибкости.
А вот давать определение: «Интерактор – это набор UseCase’ов», – вот это уже плохо. А такое определение бытует. Оно ошибочно с точки зрения оригинального толкования термина и вводит начинающих в большие заблуждения, когда в коде получается одновременно есть и UseCase классы и Interactor классы, хотя всё это одно и то же.
Я призываю не вводить друг друга в заблуждения и использовать названия Interactor и UseCase, не меняя их изначальный смысл: Interactor/UseCase – объект, реализующий use case (сценарий использования).
За примером того, чем плохо, когда одно название толкуется по-разному, далеко ходить не надо, такой пример рядом – паттерн Repository.
Доступ к данным
Для доступа к данным удобно использовать какой-либо паттерн, позволяющий скрыть процесс их получения. Uncle Bob в своей схеме использует Gateway, но сейчас куда сильнее распространен Repository.
Repository
А что из себя представляет паттерн Repository? Вот тут и возникает проблема, потому что оригинальное определение и то, как мы понимаем репозиторий сейчас (и как его описывает Fernando Cejas в своей статье), фундаментально различаются.
В оригинале Repository инкапсулирует набор сохраненных объектов в более объектно-ориентированном виде. В нем собран код, создающий запросы, который помогает минимизировать дублирование запросов.
Но в Android-сообществе куда более распространено определение Repository как объекта, предоставляющего доступ к данным с возможностью выбора источника данных в зависимости от условий.
Подробнее об этом можно прочесть в статье Hannes Dorfmann’а.
Gateway
Сначала я тоже начал использовать Repository, но воспринимая слово «репозиторий» в значении хранилища, мне не нравилось наличие там методов для работы с сервером типа login() (да, работа с сервером тоже идет через Repository, ведь в конце концов для приложения сервер – это та же база данных, только расположенная удаленно).
Я начал искать альтернативное название и узнал, что многие используют Gateway – слово более подходящее, на мой вкус. А сам паттерн Gateway по сути представляет собой разновидность фасада, где мы прячем сложное API за простыми методами. Он в оригинале тоже не предусматривает выбор источников данных, но все же ближе к тому, как используем мы.
А в обсуждениях все равно приходится использовать слово «репозиторий», всем так проще.
Доступ к Repository/Gateway только через Interactor?
Многие настаивают, что это единственный правильный способ. И они правы!
В идеале использовать Repository нужно только через Interactor.
Но я не вижу ничего страшного, чтобы в простых случаях, когда не нужно никакой логики обработки данных, вызывать Repository из Presenter’a, минуя Interactor.
Repository и презентер находятся на одном слое, Dependency Rule не запрещает нам использовать Repository напрямую. Единственное но – возможное добавления логики в Interactor в будущем. Но добавить Interactor, когда понадобится, не сложно, а иметь множество proxy-interactor’ов, просто прокидывающих вызов в репозиторий, не всегда хочется.
Повторюсь, я считаю, что в идеале надо делать запросы через Interactor, но также считаю, что в небольших проектах, где вероятность добавления логики в Interactor ничтожно мала, можно этим правилом поступиться. В качестве компромисса с собой.
Заблуждение: Обязательность маппинга между слоями
Некоторые утверждают, что маппить данные обязательно между всеми слоями. Но это может породить большое количество дублирующихся представлений одних и тех же данных.
А можно использовать DTO из слоя Entities везде во внешних слоях. Конечно, если те могут его использовать. Нарушения Dependency Rule тут нет.
Какое решение выбрать – сильно зависит от предпочтений и от проекта. В каждом варианте есть свои плюсы и минусы.
Маппинг DTO на каждом слое:
- Изменение данных в одном слое не затрагивает другой слой;
- Аннотации, нужные для какой-то библиотеки не попадут в другие слои;
- Может быть много дублирования;
- При изменении данных все равно приходится менять маппер.
Использование DTO из слоя Enitities:
- Нет дублирования кода;
- Меньше работы;
- Присутствие аннотаций, нужных для внешних библиотек на внутреннем слое;
- При изменении этого DTO, возможно придется менять код в других слоях.
Хорошее рассуждение есть вот по этой ссылке.
С выводами автора ответа я полностью согласен:
Если у вас сложное приложение с логикой бизнеса и логикой приложения, и/или разные люди работают над разными слоями, то лучше разделять данные между слоями (и маппить их). Также это стоит делать, если серверное API корявое. Но если вы работаете над проектом один, и это простое приложение, то не усложняйте лишним маппингом.
Заблуждение: маппинг в Interactor’e
Да, такое заблуждение существует. Развеять его несложно, приведя фразу из оригинальной cтатьи:
So when we pass data across a boundary, it is always in the form that is most convenient for the inner circle.
(Когда мы передаем данные между слоями, они всегда в форме более удобной для внутреннего слоя)
Поэтому в Interactor данные должны попадать уже в нужном ему виде.
Маппинг происходит в слое Interface Adapters, то есть в Presenter и Repository.
А где раскладывать объекты?
С сервера нам приходят данные в разном виде. И иногда API навязывает нам странные вещи. Например, в ответ на login() может прийти объект Profile и объект OrderState. И, конечно же, мы хотим сохранить эти объекты в разных Repository.
Так где же нам разобрать LoginResponse и разложить Profile и OrderState по нужным репозиториям, в Interactor’e или в Repository?
Многие делают это в Interactor’e. Так проще, т.к. не надо иметь зависимости между репозиториями и разрывать иногда возникающую кроссылочность.
Но я делаю это в Repository. По двум причинам:
- Если мы делаем это в Interactor’e, значит мы должны передать ему LoginResponse в каком-то виде. Но тогда, чтобы не нарушать Dependency Rule, LoginResponse должен находиться в слое Interactor’a (UseCases) или Entities. А ему там не место, ведь он им кроме как для раскладывания ни для чего больше не нужен.
- Раскладывание данных – не дело для use case. Мы же не станем писать пункт в описании действия доступного пользователю: «Получить данные, разложить данные». Скорее мы напишем просто: «Получить нужные данные»,– и всё.
Если вам удобно делать это в Interactor, то делайте, но считайте это компромиссом.
Можно ли объединить Interactor и Repository?
Некоторым нравится объединять Interactor и Repository. В основном это вызвано желанием избежать решения проблемы, описанной в пункте «Доступ к Repository/Gateway только через Interactor?».
Но в оригинале Clean Architecture эти сущности не смешиваются.
И на это пара веских причин:
- Они на разных слоях.
- Они выполняют различные функции.
А вообще, как показывает практика, в этом ничего страшного нет. Пробуйте и смотрите, особенно если у вас небольшой проект. Хотя я рекомендую разделять эти сущности.
RxJava в Clean Architecture
Уже становится сложным представить современное Android-приложение без RxJava. Поэтому не удивительно, что вторая в серии статья Fernando Cejas была про то, как он добавил RxJava в Clean Architecture.
Я не стану пересказывать статью, но хочу отметить, что, наверное, главным плюсом является возможность избавиться от интерфейсов Boundaries (как способа обеспечить выполнение Dependency Rule) в пользу общих Observable и Subscriber.
Правда есть люди, которых смущает присутствие RxJava во всех слоях, и даже в самых внутренних. Ведь это сторонняя библиотека, а убрать зависимость на всё внешнее – один из основных посылов Clean Architecture.
Но можно сказать, что RxJava негласно уже стала частью языка. Да и в Java 9 уже добавили util.concurrent.Flow, реализацию спецификации Reactive Streams, которую реализует также и RxJava2. Так что не стоит нервничать из-за RxJava, пора принять ее как часть языка и наслаждаться.
Заблуждение: Что лучше Clean Architecture или MVP?
Смешно, да? А некоторые спрашивают такое в чатах.
Быстро поясню:
- Архитектура затрагивает всё ваше приложение. И Clean – не исключение.
- А презентационные паттерны, например MVP, затрагивают лишь часть, отвечающую за отображение и взаимодействие с UI. Чтобы лучше понять эти паттерны, я рекомендую почитать статью моего коллеги dmdev.
Заблуждение: Clean Architecture в первых проектах
В последнее время архитектура приложений на слуху. Даже Google решили выпустить свои Architecture Components.
Но этот хайп заставляет молодых разработчиков пытаться затянуть какую-нибудь архитектуру в первые же свои приложения. А это чаще всего плохая идея. Так как на раннем этапе куда полезнее вникнуть в другие вещи.
Конечно, если вам все понятно и есть на это время – то супер. Но если сложно, то не надо себя мучить, делайте проще, набирайтесь опыта. А применять архитектуру начнете позже, само придет.
Лучше красивый, хорошо работающий код, чем архитектурное спагетти с соусом из недопонимания.
Фффух!
Статья получилась немаленькой. Надеюсь она будет многим полезна и поможет лучше разобраться в теме. Используйте Clean Architecture, следуйте правилам, но не забывайте, что «все мы пираты по натуре»!
