Продолжаем делиться опытом по организации хранилища данных, о котором начали рассказывать в предыдущем посте. На этот раз хотим поговорить о том, как мы решали задачи по установке CDH.

Установка CDH
Запускаем сервер Cloudera Manager, добавляем его в автозагрузку и проверяем, что он перешёл в активное состояние:
systemctl start cloudera-scm-server
systemctl enable cloudera-scm-server
systemctl status cloudera-scm-server
После того, как он поднялся, переходим по ссылке «hostname:7180/», авторизуемся (admin/admin) и продолжаем установку из GUI. После авторизации автоматически начнется установка и будет произведён переход на страницу добавления хостов в кластер:

Рекомендуется добавлять все хосты, которые будут так или иначе связаны с развертываемой средой (даже если на них не будут располагаться сервисы Cloudera). Это могут быть машины с средствами непрерывной интеграции, BI или ETL средствами или инструментами Data Discovery. Включение данных машин в кластер позволит установить шлюзы сервисов кластера (Gateways), содержащие файлы с конфигурацией и расположением сервисов кластера, что упростит интеграцию со сторонними программами. Также Cloudera Manager предоставляет удобные средства мониторинга и создание мониторов ключевых метрик всех машин кластера в едином окне, что упростит локализацию проблем во время эксплуатации. Хосты добавляются с помощью кнопки “New Search” — совершается переход на страницу добавления машин в кластер, где предлагается предоставить для них данные для подключения по SSH:

После добавления хостов переходим к этапу выбора способа установки. Поскольку мы скачали парсэли, выбираем способ «Use Parcels (Recommended)», и теперь надо добавить наш репозиторий. Нажимаем на кнопку «More options», удаляем все установленные там по умолчанию репозитории и добавляем адрес репозитория с парсэлем CDH – «hostname/parcels/cdh/». После подтверждения справа от надписи «Select the version of CDH» должна отобразиться версия CDH, представленная в скаченном парсэле. Для данного способа установки на этой вкладке можно ничего не настраивать:

На следующей вкладке будет предложено установить JDK. Поскольку мы уже сделали это на этапе подготовки к установке, пропускаем данный шаг:

При переходе на следующую вкладку начинается установка компонентов кластера на указанные хосты. После окончания установки станет доступен переход к следующему шагу. Если в ходе установки будут встречаться ошибки (сталкивался с такой ситуацией при установке локальных Dev сред), то посмотреть их подробности можно с помощью команды «tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log» и по нажатию кнопки «Details» в правой части таблицы:

На следующем шаге установки вам предложат выбрать один из подготовленных наборов сервисов для установки. Сервисы и их роли в дальнейшем можно будет сконфигурировать вручную, поэтому не очень принципиально, что выбрать на данной вкладке. В нашем случае обычно устанавливался «Core with Impala». Также здесь можно указать необходимость установки Cloudera Navigator. Если вы устанавливаете Enterprise версию, то стоит установить этот полезный инструмент:

На следующей вкладки для сервисов из выбранного набора предлагается выбрать роли и хосты, на которые они будут установлены. Ниже будут приведены некоторые рекомендации по установке ролей на хосты.
Роли HDFS
NameNode — ставится в единственном экземпляре на одну из Master Nodes, желательно, самую ненагруженную, поскольку она очень важна для работы кластера и вносит весомый вклад в утилизацию ресурсов.
SecondaryNameNode — ставится в единственном экземпляре на одну из Master Nodes, желательно, не на ту же ноду, что и NameNode (для обеспечения отказоустойчивости).
Balancer — ставится в единственном экземпляре на одну из Master Nodes.
HttpFS — дополнительное API к HDFS, можно не устанавливать.
NFS Gateway — очень полезная роль, позволяет монтировать HDFS как сетевой диск. Ставится в единственном экземпляре на одну из Master Nodes.
DataNode — ставится на все Data Nodes.
Роли Hive
Gateway – конфигурационные файлы Hive. Ставится на все хосты кластера.
Hive Metastore Server – сервер метаданных, ставится в единственном экземпляре на одну из Master Nodes (например ту, где установлен PostgreSQL – он хранит там свои данные).
WebHCat – можно не устанавливать.
HiveServer2 – ставится в единственном экземпляре на ту же Master Node, что и Hive Metastore Server (требование для их совместной работы).
Роли Hue
Hue Server – GUI для HDFS, ставится в единственном экземпляре на одну из Master Nodes.
Load Balancer – балансировщик нагрузки на GUI для HDFS, ставится в единственном экземпляре на одну из Master Nodes.
Роли Impala
Impala StateStore – ставится в единственном экземпляре на одну из Master Nodes.
Impala Catalog Server – ставится в единственном экземпляре на одну из Master Nodes.
Impala Daemon – ставится на все Data Nodes (можно оставить значение по умолчанию).
Роли Cloudera Manager Services
Service Monitor, Activity Monitor, Host Monitor, Reports Manager, Event Server, Alert Publisher ставятся в единственном экземпляре на одну из Master Nodes.
Роли Oozie
Oozie Server – ставится в единственном экземпляре на одну из Master Nodes.
Роли Yarn
ResourceManager – ставится в единственном экземпляре на одну из Master Nodes.
JobHistory Server – ставится в единственном экземпляре на одну из Master Nodes.
NodeManager – ставится на все Data Nodes (можно оставить значение по умолчанию).
Роли ZooKeeper
ZooKeeper Server – для обеспечения отказоустойчивости ставится в трех экземплярах на Master Nodes.
Роли Cloudera Navigator
Navigator Audit Server – ставится в единственном экземпляре на одну из Master Nodes.
Navigator Metadata Server – ставится в единственном экземпляре на одну из Master Nodes.

Следующей после распределения ролей идет вкладка с кратким списком настроек устанавливаемых сервисов. Их изменение будет доступно после окончания установки и на данном этапе их можно оставить без изменений:

Вслед за настройками сервисов идет конфигурация баз данных для сервисов, которые в них нуждаются. Вводим полное имя хоста, на котором установлен PostgreSQL, в листбоксах «Database Type» выбираем соответствующий пункт и в остальных полях указываем данные для подключения к соответствующим базам. После того, как все данные введены, нажимаем кнопку «Test Connection» и проверяем, что базы доступны. Если это так, то в правой части таблицы напротив каждой из баз появится надпись «Successful»:

Все готово к развертыванию сервисов. Переходим на следующую вкладку и наблюдаем за этим процессом. Если мы все сделали правильно, то все шаги будут выполнены успешно. В противном случае процесс прервется на одном из шагов и по нажатию стрелки будет доступен лог ошибки:

Поздравляю – CDH развернут и практически готов к эксплуатации!

Можно переходить к установке дополнительных парсэлей.
Установка дополнительных парсэлей
В случаях, когда базового набора сервисов CHD не хватает или же требуется более свежая версия, можно установить дополнительные парсэли, расширяющие доступный список сервисов, которые можно развернуть в кластере. В ходе нашего проекта нам потребовался сервис Spark версии 2.2 для запуска разработанных задач и функционирования инструментов Data Discovery. В состав CDH он не входит, поэтому установим его отдельно. Для этого нажимаем на кнопку «Hosts» и выбираем пункт выпадающего списка «Parcels»:

Откроется вкладка с парсэлями, на которой представлен список кластеров, управляемых данным Cloudera Manager и установленных на них парсэлей. Для добавления парсэля с Spark 2.2 выбираем нужный кластер и нажимаем кнопку «Configuration» в правом верхнем углу.

Нажимаем на кнопку «+», в появившейся строке указываем адрес репозитория с парсэлем Spark 2.2 («hostname/parcels/spark/») и нажимаем кнопку «Save Changes»:

После этих манипуляций в списке парсэлей на предыдущей вкладке должен появиться новый с именем SPARK2. Изначально он появляется как доступный для скачивания, поэтому следующим шагом мы скачиваем его, нажав кнопку «Download»:

Скачанный парсэль требуется раскидать на ноды кластера, чтобы можно было устанавливать из него сервисы. Для этого нажимаем кнопку «Distribute», появившуюся в правой части строки с парсэлем SPARK2:

Последним шагом в работе с парселем является его активизация. Активируем его, нажав кнопку «Activate», появившуюся в правой части строки с парсэлем:

После подтверждения нужный нам сервис становится доступным для установки. Но тут есть нюансы. Для установки некоторых сервисов в кластер требуется произвести какие-либо дополнительные действия помимо установки парсэля. Обычно об этом написано на официальном сайте в разделе, посвященном установке и обновлению данного сервиса (вот ее пример для Spark 2 — www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html). В данном случае требуется скачать файл Spark 2 CSD (доступен на странице «Version and Packaging Information» — www.cloudera.com/documentation/spark2/latest/topics/spark2_packaging.html), установить его на хост с Cloudera Manager и перезагрузить последний. Сделаем это – скачиваем данный файл, переносим его на нужный хост и выполняем команды из инструкции:
mv SPARK2_ON_YARN-2.1.0.cloudera1.jar /opt/cloudera/csd/
chown cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar
chmod 644 /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar
systemctl restart cloudera-scm-server
Когда Cloudera Manager поднимется, все будет готово к установке Spark 2. На главном экране нажимаем стрелочку справа от имени кластера и выбираем пункт «Add Service» выпадающего меню:

В списке сервисов, доступных для установки, выбираем тот, который нам нужен:

На следующей вкладке выбираем набор зависимостей для нового сервиса. Например тот, где список шире:

Далее идет вкладка с выбором ролей и хостов, на которые они будут установлены, аналогичная той, что была во время установки CDH. Роль History Server рекомендуется ставить в единственном экземпляре на одну из Master Nodes, а Gateway на все сервера кластера:

После выбора ролей предлагается проверить и подтвердить изменения, вносимые в кластер во время установки сервиса. Здесь можно оставить все по умолчанию:

Подтверждение изменений запускает установку сервиса в кластер. Если все сделано верно, то установка будет успешно завершена:
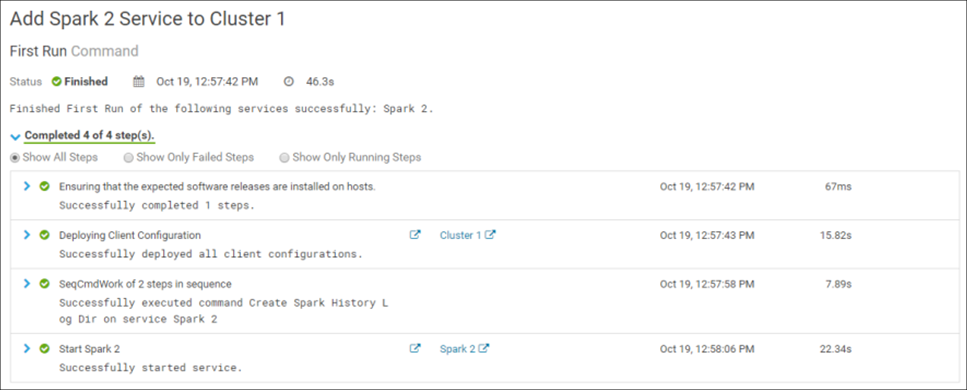
Поздравляю! Spark 2 успешно установлен в кластер:

Для завершения процесса установки требуется перезагрузить кластер. После этого все готово к работе.
На этапе установки сервиса могут возникнуть ошибки. Например, при установке на одну из сред не удавалось развернуть роль Spark 2 Gateway. В решении этой проблемы помогло копирование содержимого файла /var/lib/alternatives/spark2-conf с хоста, на который данная роль успешно установилась, в аналогичный файл проблемной машины. Для диагностики ошибок установки удобно использовать файлы логов соответствующих процессов, которые хранятся в папке /var/run/cloudera-scm-agent/process/.
На этом на сегодня всё. В следующем посте серии будет раскрыта тема администрирования кластера CDH.
