На прошлой неделе состоялся успешный эксперимент по запуску нового решения для download-сервиса. Один достаточно скромный сервер (2 x Intel Xeon E5620, 64 GB RAM) под управлением Java-приложения собственной разработки принял на себя нагрузку восьми Tomcat'ов, обслуживая более 70 тысяч HTTP-запросов в секунду общей пропускной способностью 3000 Mb/s. Таким образом, весь трафик Одноклассников, связанный с пользовательскими смайликами, обрабатывался одним сервером.
Вполне естественно, что высокие нагрузки требовали нестандартных решений. В цикле статей о разработке высоконагруженного сервера на Java я расскажу о проблемах, с которыми нам пришлось столкнуться, и о том, как мы их преодолели. Сегодня речь пойдет о кешировании изображений вне Java Heap и об использовании Shared Memory в Java.
Поскольку тянуть изображения на каждый запрос из хранилища — не вариант, а о хранении картинок на диске не может быть и речи (дисковая очередь станет узким местом сервера гораздо раньше), необходимо иметь быстрый кеш в памяти приложения.
Требования к кешу предъявлялись следующие:
Самый быстрый способ обращения к памяти вне Heap из Java – через классmemory-mapped файлов . Однако связывать кеш с реальным файлом на диске крайне не хотелось (производительность сильно пострадала бы за счет обращений к диску), поэтому в адресное пространство приложения отображается не реальный файл, а объект разделяемой памяти . В этом случае, конечно, кеш уже не будет энергонезависимым, но, главное, позволит перезапускать приложение без потери данных.
В Linux объекты Shared Memory реализованы посредством специальной файловой системы, монтируемой к
Теперь созданный объект-файл надо отобразить в адресное пространство процесса и получить адрес этого участка памяти.
Воспользуемся Java NIO API:
Самый главный недостаток этого метода заключается в том, что нельзя отображать файлы размером более 2 GB, что и описано в Javadoc к методу map: The size of the region to be mapped; must be non-negative and no greater than Integer.MAX_VALUE.
Работать с полученным участком памяти можно либо стандартными методами ByteBuffer'а, либо напрямую через Unsafe, вытащив адрес памяти с помощью Reflection:
Публично доступного метода unmap у такого MappedByteBuffer'а нет, однако есть полу-легальный способ освободить память без вызова GC:
В Oracle JDK есть класс
Такой механизм будет работать как в Linux, так и под Windows. Единственный его недостаток — отсутствие возможности выбора конкретного адреса, куда будет «замаплен» файл. Необходимость в этом может возникнуть, если в кеше присутствуют абсолютные ссылки на адреса памяти внутри этого же кеша: такие ссылки станут невалидными, если отобразить файл по другому адресу. Выхода два: либо хранить относительные ссылки в виде смещения относительно начала файла, либо прибегнуть к вызову нативного кода через JNI или JNA. Системные вызовы mmap в Linux и MapViewOfFileEx в Windows позволяют задать предпочитаемый адрес, куда «замапить» файл.
Ключевым для производительности кеша, да и download-сервера в целом, является алгоритм поиска в кеше, т.е. метод
Вся память разделяется на сегменты одинакового размера — корзины хеш-таблицы, по которым равномерно распределяются ключи. В самом простом виде
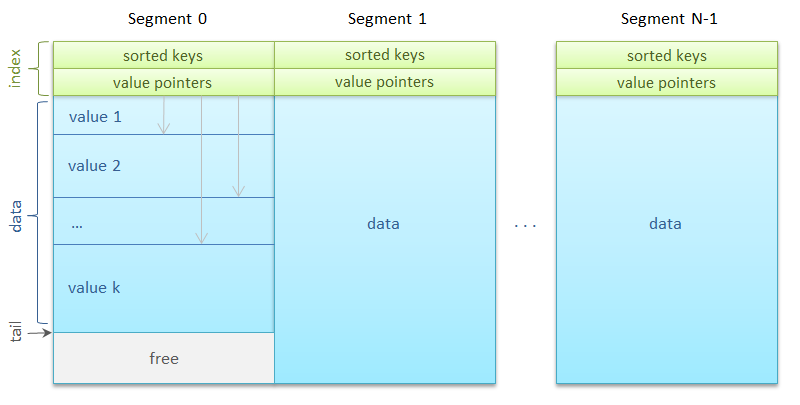
Сегментов может быть много — несколько тысяч. Каждому из них сопоставляется
Интересная деталь: использование стандартных
как реализовать ReadWriteLock при помощи Semaphore?
Итак, сегмент. Он состоит из области индекса и области данных. Индекс представляет собой упорядоченный массив из 256 ключей, сразу за которым идет такой же длины массив из 256 ссылок на значения. Ссылка задает смещение внутри сегмента на начало блока данных и длину этого блока в байтах.

Блоки данных, то есть, собственно сами изображения, выравнены по восьмибайтовой границе для оптимального копирования. Сегмент также хранит количество ключей в нем и адрес следующего блока данных для метода
Алгоритм метода get чрезвычайно быстр и прост:
Ключи неспроста записываются подряд в одной выделенной области: это способствует размещению индекса в кеше процессора, обеспечивая максимальную скорость бинарного поиска ключа.
Метод put тоже несложен:
Разумеется, помимо нашего, существует ряд других решений для кеширования данных за пределами Java Heap, как бесплатных, так и платных. Из наиболее известных –Terracota Ehcache (с in-memory off-heap хранилищем) и Apache Java Caching System. Именно с ними мы и сравнивали собственный алгоритм. Эксперименты проводились на Linux JDK 7u4 64-bit и состояли из трех сценариев:
Результаты замеров приведены в таблице. Как видно, и Ehcache, и JCS в разы уступают по производительности описанному алгоритму.

Впрочем, стоит отметить, что описанный алгоритм, будучи предназначенным для решения задачи кеширования изображений, не охватывает многих других сценариев. Например, операции
Исходные тексты алгоритма кеширования с использованием Shared Memory на github:
https://github.com/odnoklassniki/shared-memory-cache
На встрече JUG.RU в Санкт-Петербурге, которая состоится 25 июля 2012 г., apangin поделится опытом разработки высоконагруженного сервера на Java, расскажет о характерных проблемах и нетрадиционных приемах.
В следующих статьях я расскажу, как написать RPC-сервер, обрабатывающий десятки тысяч запросов в секунду, а также поведаю об альтернативном методе сериализации, в разы превосходящем стандартные механизмы Java по производительности и объему трафика. Оставайтесь с нами!
Вполне естественно, что высокие нагрузки требовали нестандартных решений. В цикле статей о разработке высоконагруженного сервера на Java я расскажу о проблемах, с которыми нам пришлось столкнуться, и о том, как мы их преодолели. Сегодня речь пойдет о кешировании изображений вне Java Heap и об использовании Shared Memory в Java.
Кеширование
Поскольку тянуть изображения на каждый запрос из хранилища — не вариант, а о хранении картинок на диске не может быть и речи (дисковая очередь станет узким местом сервера гораздо раньше), необходимо иметь быстрый кеш в памяти приложения.
Требования к кешу предъявлялись следующие:
- 64-bit keys, byte array values: идентификатор изображения — целое число типа long, а данные — картинка в формате PNG, GIF или JPG со средним размером 4 KB;
- In-process, in-memory: для максимальной скорости доступа все данные — в памяти процесса;
- RAM utilization: под кеш выделяется вся доступная оперативная память;
- Off-heap: 50 GB данных разместить в Java Heap было бы проблематично;
- LRU или FIFO: устаревшие ключи могут вытесняться более новыми;
- Concurrency: одновременное использование кеша в сотне потоков;
- Persistence: приложение может быть перезапущено с сохранением уже закешированных данных.
Самый быстрый способ обращения к памяти вне Heap из Java – через класс
sun.misc.Unsafe, т.к. его методы getLong/putLong являются JVM intrinsics, то есть, их вызовы заменяются JIT-компилятором буквально в одну машинную инструкцию. Персистентность кеша между запусками приложения достигается использованием Shared Memory
В Linux объекты Shared Memory реализованы посредством специальной файловой системы, монтируемой к
/dev/shm. Так, например, POSIX функция shm_open("name", ...) эквивалентна системному вызову open("/dev/shm/name", ...). Таким образом, в Java мы можем работать с разделяемой памятью Linux как с обычными файлами. Следующий фрагмент кода откроет объект разделяемой памяти с именем image-cache размером 1 GB. Если объекта с таким именем не существует, будет создан новый. Важно, что после завершения приложения объект останется в памяти и будет доступен при следующем запуске. RandomAccessFile f = new RandomAccessFile("/dev/shm/image-cache", "rw");
f.setLength(1024*1024*1024L);
Теперь созданный объект-файл надо отобразить в адресное пространство процесса и получить адрес этого участка памяти.
Способ 1. Легальный, но неполноценный
Воспользуемся Java NIO API:
RandomAccessFile f = ...
MappedByteBuffer buffer =
f.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, f.length());
Самый главный недостаток этого метода заключается в том, что нельзя отображать файлы размером более 2 GB, что и описано в Javadoc к методу map: The size of the region to be mapped; must be non-negative and no greater than Integer.MAX_VALUE.
Работать с полученным участком памяти можно либо стандартными методами ByteBuffer'а, либо напрямую через Unsafe, вытащив адрес памяти с помощью Reflection:
public static long getByteBufferAddress(ByteBuffer buffer) throws Exception {
Field f = Buffer.class.getDeclaredField("address");
f.setAccessible(true);
return f.getLong(buffer);
}
Публично доступного метода unmap у такого MappedByteBuffer'а нет, однако есть полу-легальный способ освободить память без вызова GC:
((sun.nio.ch.DirectBuffer) buffer).cleaner().clean();
Способ 2. Полностью на Java, но с использованием «тайных знаний»
В Oracle JDK есть класс
sun.nio.ch.FileChannelImpl с приватными методами map0 и unmap0, которые лишены ограничения в 2 GB. map0 возвращает непосредственно адрес «замапленного» участка, что для нас даже удобнее, если мы используем Unsafe. Method map0 = FileChannelImpl.class.getDeclaredMethod(
"map0", int.class, long.class, long.class);
map0.setAccessible(true);
long addr = (Long) map0.invoke(f.getChannel(), 1, 0L, f.length());
Method unmap0 = FileChannelImpl.class.getDeclaredMethod(
"unmap0", long.class, long.class);
unmap0.setAccessible(true);
unmap0.invoke(null, addr, length);
Такой механизм будет работать как в Linux, так и под Windows. Единственный его недостаток — отсутствие возможности выбора конкретного адреса, куда будет «замаплен» файл. Необходимость в этом может возникнуть, если в кеше присутствуют абсолютные ссылки на адреса памяти внутри этого же кеша: такие ссылки станут невалидными, если отобразить файл по другому адресу. Выхода два: либо хранить относительные ссылки в виде смещения относительно начала файла, либо прибегнуть к вызову нативного кода через JNI или JNA. Системные вызовы mmap в Linux и MapViewOfFileEx в Windows позволяют задать предпочитаемый адрес, куда «замапить» файл.
Алгоритм кеширования
Ключевым для производительности кеша, да и download-сервера в целом, является алгоритм поиска в кеше, т.е. метод
get. Метод put в нашем сценарии вызывается значительно реже, но тоже не должен быть слишком медленным. Хочу представить наше решение для быстрого потокобезопасного FIFO кеша в непрерывной области памяти фиксированного размера.Вся память разделяется на сегменты одинакового размера — корзины хеш-таблицы, по которым равномерно распределяются ключи. В самом простом виде
Segment s = segments[key % segments.length];
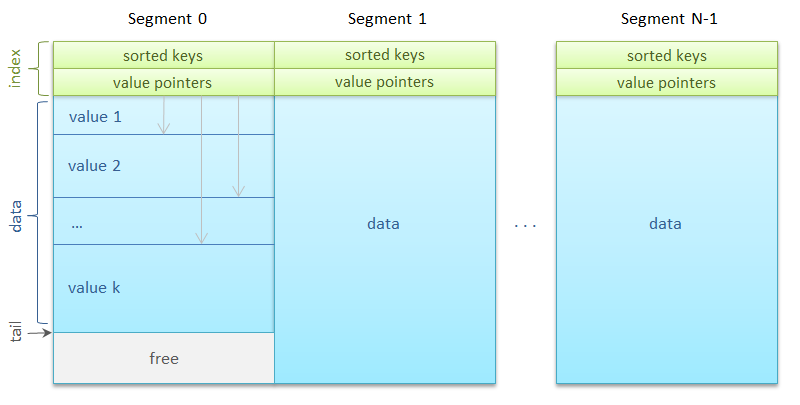
Сегментов может быть много — несколько тысяч. Каждому из них сопоставляется
ReadWriteLock. Одновременно с сегментом может работать либо неограниченное количество читателей, либо только один писатель.Интересная деталь: использование стандартных
ReentrantReadWriteLock'ов привело к потере 2 GB в Java Heap. Как оказалось, в JDK 6 существует ошибка, приводящая к чрезмерному потреблению памяти таблицами ThreadLocal в реализации ReentrantReadWriteLock. Хотя в JDK 7 ошибка уже исправлена, в нашем случае мы заменили прожорливый Lock на Semaphore. Кстати, вот вам и маленькое упражнение:как реализовать ReadWriteLock при помощи Semaphore?
Итак, сегмент. Он состоит из области индекса и области данных. Индекс представляет собой упорядоченный массив из 256 ключей, сразу за которым идет такой же длины массив из 256 ссылок на значения. Ссылка задает смещение внутри сегмента на начало блока данных и длину этого блока в байтах.

Блоки данных, то есть, собственно сами изображения, выравнены по восьмибайтовой границе для оптимального копирования. Сегмент также хранит количество ключей в нем и адрес следующего блока данных для метода
put. Новые блоки записываются друг за другом по принципу циклического буфера. Как только место в сегменте кончается, происходит запись с начала сегмента поверх более ранних данных.Алгоритм метода get чрезвычайно быстр и прост:
- по хешу ключа вычисляется сегмент, в котором будет производиться поиск;
- в области индекса бинарным поиском ищется ключ;
- если ключ найден, из массива ссылок достается смещение, по которому располагаются данные.
Ключи неспроста записываются подряд в одной выделенной области: это способствует размещению индекса в кеше процессора, обеспечивая максимальную скорость бинарного поиска ключа.
Метод put тоже несложен:
- по хешу ключа вычисляется сегмент;
- считывается адрес очередного блока данных и вычисляется адрес следующего блока путём прибавления размера записываемого объекта с учетом выравнивания;
- если сегмент заполнен, линейным поиском по массиву ссылок находятся и удаляются из индекса ключи, чьи данные будут перезаписаны очередным блоком;
- значение, представленное байтовым массивом, копируется в область данных;
- бинарным поиском находится место в индексе, куда вставляется новый ключ.
Скорость работы
Разумеется, помимо нашего, существует ряд других решений для кеширования данных за пределами Java Heap, как бесплатных, так и платных. Из наиболее известных –
- put: запись 1 млн. значений размером от 0 до 8 KB каждое;
- get: поиск по ключу 1 млн. значений;
- 90% get + 10% put: комбинирование get/put в отношении, приближенном к практическому сценарию использования кеша.
Результаты замеров приведены в таблице. Как видно, и Ehcache, и JCS в разы уступают по производительности описанному алгоритму.

Впрочем, стоит отметить, что описанный алгоритм, будучи предназначенным для решения задачи кеширования изображений, не охватывает многих других сценариев. Например, операции
remove и replace, хотя и могут быть легко реализованы, не будут освобождать память, занятую прежними значениями.Где посмотреть?
Исходные тексты алгоритма кеширования с использованием Shared Memory на github:
https://github.com/odnoklassniki/shared-memory-cache
Где послушать?
На встрече JUG.RU в Санкт-Петербурге, которая состоится 25 июля 2012 г., apangin поделится опытом разработки высоконагруженного сервера на Java, расскажет о характерных проблемах и нетрадиционных приемах.
Что дальше?
В следующих статьях я расскажу, как написать RPC-сервер, обрабатывающий десятки тысяч запросов в секунду, а также поведаю об альтернативном методе сериализации, в разы превосходящем стандартные механизмы Java по производительности и объему трафика. Оставайтесь с нами!
