Сразу оговорюсь, что данный текст — это не сухая выжимка основных идей с красивыми графиками и обилием технических терминов (такой текст называется научной статьей и я его обязательно напишу, но потом, когда нам заплатят призовые $20000, а то, не дай бог, начнутся разговоры про лицензию, авторские права и прочее.) (UPD: https://arxiv.org/abs/1706.06169). К моему сожалению, пока устаканиваются все детали, мы не можем поделиться кодом, который написали под эту задачу, так как хотим получить деньги. Как всё утрясётся — обязательно займемся этим вопросом. (UPD: https://github.com/ternaus/kaggle_dstl_submission)
Так вот, данный текст — это скорее байки по мотивам, в которых, с одной стороны, всё — правда, а с другой, обилие лирических отступлений и прочей отсебятины не позволяет рассматривать его как что-то наукоемкое, а скорее просто как полезное и увлекательное чтиво, цель которого показать, как может происходить процесс работы над задачами в дисциплине соревновательного машинного обучения. Кроме того, в тексте достаточно много лексикона, который специфичен для Kaggle и что-то я буду по ходу объяснять, а что-то оставлю так, например, вопрос про гусей раскрыт не будет.
Несколько недель назад на Kaggle закончилось очередное соревнование по компьютерному зрению. Несмотря на все наши старания, в команде с Сергеем Мушинским мы таки умудрились финишировать третьими (изначальный маршальский план был остаться в топ-50), что сделало нас причастными к распилу призового фонда, который выделило Британское министерство обороны. Тройка победителей делит $100k: первое место получил малазиец Kyle ($50k), второе — команда Романа Соловьева и Артура Кузина ($30k), а третье — мы, то есть я и Сергей Мушинcкий ($20k). Как side effect я попал в топ-100 в глобальном рейтинге, что никого, конечно, не волнует, но является приятным дополнением к резюме.
Далее по тексту я буду называть Data Scientist’ов кодовым словом «саентолог», что, с одной стороны, подчеркивает глубокую связь Data Scienсe с фундаментальной наукой, а с другой, является стандартным неологизмом в slack’e Open Data Science, который далее я буду называть просто — «чатик».
Среди саентологов Кремниевой Долины, в которой я в данный момент обитаю, успехи на Kaggle котируются примерно рядом с никак, и рассчитывать на получение призовых денег — довольно смелый ход, поэтому единственно верной мотивацией для участия в соревнованиях являются знания, которые приобретаются в процессе. Кому очень интересно, несколько месяцев назад, когда я писал похожий текст, но про другую задачу, все вступление я посвятил вопросу мотивации в разрезе соревновательного машинного обучения, где русским по белому расписал, как и почему имеет смысл инвестировать какой-то кусок свободного времени в это занятие.
Надо отметить, что соревнований много, а свободного времени мало, плюс жизнь за пределами монитора и клавиатуры таки существует, поэтому достаточно остро стоит процесс его планирования.
Каждое соревнование на Kaggle, как правило, идет порядка трех месяцев, и одновременно проходят сразу несколько. Организаторы стараются сдвигать их по времени, так что у меня достаточно хорошо показала себя методика, когда соревнования сортируются в порядке наступления дедлайнов и ты работаешь над той задачей, которая заканчивается следующей.
Из плюсов то, что ближе к концу форум насыщен плодотворными дискуссиями, что, в свою очередь, сильно уменьшает время на проверку того, что работает, а что нет, а из минусов, что пары недель по вечерам после работы может не хватить на то, чтобы предложить что-то достойное, и с таким подходом в топ-10 уйти крайне сложно, во всяком случае, у меня получилось только один раз.
Но, так как нам не шашечки, а ехать, такой подход позволил нахвататься машинного обучения до уровня, которого было достаточно, чтобы найти адекватно оплачиваемую позицию Sr. Data Scientist, на которой машинное обучение много используется по работе.
Все это замечательно, но есть нюанс. Классическое машинное обучение — это прекрасно, но нейронные сети — это гораздо более увлекательно, и тот факт, что днем на работе я прикручиваю машинное обучение в production, а по вечерам читаю всякие умные книжки и статьи про Deep Learning, мне кажется неудовлетворительным. Да и вообще, я хочу в DeepMind, но есть гипотеза, что если я сейчас туда подам, никто на мое резюме смотреть не будет, ибо все мои статьи по теоретической физике, а не по машинному обучению, но, что более фундаментально, у меня банально может не хватить знаний, чтобы правильно ответить на вопросы на интервью.
Всю эту лирику я развожу для того, чтобы раскрыть простую мысль: рубить соревнования по Deep Learning, если я хочу найти интересную работу с этим самым Deep Learning — очень надо и это чуть не самый эффективный вариант научиться работать с нейронными сетями в короткие сроки.
Прошлым летом я сунулся на ImageNet и сразу стало понятно, что и инфраструктура у меня не подготовлена, вечно вылезают какие-то мелочи, про которые авторы статей умышленно или случайно умалчивают, но про которые надо знать, да и особенности различных framework’ов я знаю не так хорошо, как мне бы хотелось.
Всю осень на Kaggle шли какие-то неинтересные задачи, причем в каждом втором — data leak, так что вместо машинного обучения публика занималась эксплуатацией кривизны рук организаторов, но с началом зимы карта мне пошла. В последние пару месяцев тысячи опытных Kaggler'ов сидят и удивленно хлопают глазами от того факта, что с декабря стартовало 6 соревнований по Deep Learning с общим призовым фондом $1,475,000. На стаканьи xgboost’ов, как обычно, уже не выехать, надо тратить деньги на GPU / cloud, выходить из зоны комфорта, разминать мозги и начинать работать с нейронными сетями.
Первым среди этих шести соревнований как раз и шла та задача, про которую я дальше буду рассказывать.
Постановка задачи
Данные были предоставлены исследовательской лабораторией при министерстве обороны Великобритании и составляли 450 спутниковых снимков нигерийских джунглей общей площадью 450
 . То, что это Нигерия, мы узнали уже после окончания. Организаторы достаточно хорошо анонимизировали данные, так что для нас это были просто картинки, без привязки к местности. Я не думаю, что целью соревнования было получить код, который можно вставлять в production и смело начинать наводить ракеты на африканские деревушки. Скорее это было что-то из серии «отправим задачу, возьмем попкорн и будем смотреть, что у этих саентологов получится», то есть обыкновенное Proof Of Concept. Результаты их порадовали настолько, что они запилили свою собственную копию Kaggle.
. То, что это Нигерия, мы узнали уже после окончания. Организаторы достаточно хорошо анонимизировали данные, так что для нас это были просто картинки, без привязки к местности. Я не думаю, что целью соревнования было получить код, который можно вставлять в production и смело начинать наводить ракеты на африканские деревушки. Скорее это было что-то из серии «отправим задачу, возьмем попкорн и будем смотреть, что у этих саентологов получится», то есть обыкновенное Proof Of Concept. Результаты их порадовали настолько, что они запилили свою собственную копию Kaggle.В отличие от классических проблем на сегментацию изображений, в этой задаче каждая из картинок доступна в большом числе спектральных каналов. Причем эти каналы имеют различное разрешение и могут иметь сдвиги по времени и в пространстве.

На выходе же нужно попиксельно предсказать классовую принадлежность. Стоит отметить, что классы не взаимоисключающие, то есть один и тот же пиксель может принадлежать и машине, и дороге, по которой эта машина едет, и дереву, которое над этой машиной и дорогой нависает.
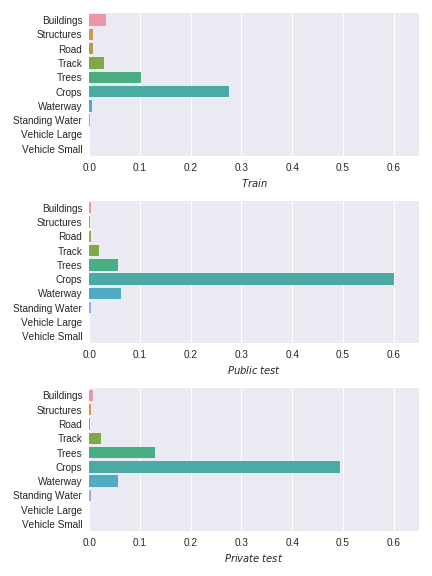
Всего надо было предсказать принадлежность к 10 классам, которые распределены крайне неравномерно, да и еще эти распределения отличаются в train и test, плюс многих классов мало, а машинок так и вообще меньше, чем мало.
Как упоминалось выше, все данные разделены на 26 картинок train set (для них доступны маски), и 425 картинок test set, для которых маски и надо было предсказать. Test set, в свою очередь, тоже был поделен на две части в лучших традициях Kaggle:
- 19% — Public test
- 81% — Private test
Все три месяца, пока шло соревнование, была известна оценка точности модели на Public, а когда соревнование закончилось, итоговый результат подсчитывается по Private части.
Метрика
Точность вычислялась как средний Jaccard Index по всем классам, то есть поля вносили такой же вклад, как и машинки, при том, что судя по train пикселей с полями в 60 тысяч раз больше.


Вот так все это выглядит навскидку, то есть задача достаточно прямолинейная, особенно учитывая то, что над похожей задачей, правда не про спутниковые снимки, а про ультразвуковые сканы, и не для дорог и домов, а для нахождения нервов, я уже работал. Но в целом, с технической стороны это image segmentation как он есть.
Нюансы
Для любого соревнования, да и вообще задачи машинного обучения, самый важный первый шаг -написать pipeline, который берет сырые данные, чистит, кэширует, что-то тренирует, осуществляет валидацию и подготавливает сабмит. И обычно, за что, часто справедливо, хают Kaggle, данные более-менее чистые и все с технической стороны достаточно прямолинейно и основные проблемы возникают на этапах feature engineering и тренировки моделей, но тут британские военные добавили британской экзотики.
Проблема первая
Я смотрю на то, что нам отмаркировали организаторы и не понимаю, что с этим делать. Для тренировки нейронной сети мне на выход нужна матрица
(height, width, num_channels), а как ее получить, нет ни малейшего понимания.Выглядит все это как-то вот так:
'MULTIPOLYGON (((0.005311 -0.009044999999999999, 0.00531 -0.009035, 0.00531 -0.009024000000000001, 0.005318 -0.009018999999999999, 0.005327 -0.009016, 0.005341 -0.009016, 0.005356 -0.009017000000000001, 0.005372 -0.009023, 0.005375 -0.009031000000000001, 0.005375 -0.009044999999999999, 0.005311 -0.009044999999999999)), ...Какие-то полигоны, и много нецелых цифр. Лезем на форум и, как обычно, есть добрая душа, которая поделилась кодом, который осуществляет искомое преобразование.
Проблема вторая
Правильная валидация — это 90% успеха. На ImageNet такой вопрос не стоит — там организаторы выбирают подвыборку, которая хорошо представляет полное распределение и предоставляют ее участникам. Да и вообще, там картинок столько, что практически любая подвыборка будет работать замечательно. На Kaggle все обычно по-другому. Прецеденты, когда данные хорошо сбалансированы, и локальная валидация соответствует тому, что мы видим на лидерборде, существуют, но это скорее исключение, чем правило. Забегая вперед, скажу, что проблему с валидацией наших результатов мы, также как и, возможно, и все остальные, так и не решили. У Романа Соловьева (его команда закончила на втором месте) была какая-то система, с крос валидацией, но к ней я отношусь с определенной долей скепсиса.
Идея в том, что картинок мало, и они соответствуют достаточно разным областям. То есть Train, Public и Private — это три разных распределения, сильно скореллированных, но, тем не менее, различных, в чем можно убедиться на картинке выше.
Проблема третья
Бог с ней с валидацией, чтобы добраться до первого сабмита, ее можно отключить. Беру стандартную рабочую лошадку задач сегментации Unet, пишу всю инфраструктуру с формированием батчей на лету, аугментацией преобразованиями группы D4, тренирую сеть предсказывая все 10 классов за раз, что-то даже куда-то сходится.
Натренировал. Круто. Дальше-то что? Следующая проблема — это, как, собственно, сделать само предсказание. Сеть тренировалась на рандомных кропах размером 112x112 из картинок размером 3600x3600 и на этом этапе надо было создавать инфраструктуру, которая будет резать большую картинку на маленькие, предсказывать, правильно обрабатывать краевые эффекты, а потом собирать все обратно. Это муторный, но прямолинейный кусок, хотя, как выяснилось позже, на нем я тоже накосячил.

Проблема четвертая
Круто. Я уже чую, что почти добрался до сабмита, и для каждой большой картинки я могу создать маску. Но этого мало. Kaggle принимает предсказание в форме полигонов, а перегнать маски в полигоны с ходу — задача нетривиальная. Лезу на форум. Там есть какой-то код. Я его прикручиваю. Собираю сабмит — размер 4Gb. Загружаю на сайт, загрузка длится дольше чем долго, что-то начинает считаться, и сабмит не проходит. Лезу на форум, а там уже есть ветка, в которой интеллигентно, но без мата, обсуждают именно эту проблему. Какое-то из предложенных решений прикручиваю к сабмиту, теперь файл только 2Gb, что все равно много, но уже лучше — загружаю, и в этот раз загрузка длится в два раза быстрее, чем очень долго, что-то начинает крутиться, и на экране появляется вот такое емкое сообщение.

И вот за всеми движениями уже прошел месяц, а я так и не сделал первый сабмит. Стоит заметить, что параллельно со всем этим процессом я начал искать работу, ориентированную на Deep Learning, для того чтобы усугублять свои знания в данной области в рамках оплачиваемой работы, а не по вечерам, убивая свое свободное время. Напыщенные индусы, которые меня интервьюировали не раз, говорили что-то типа: «Kaggle для детей, там чистые данные, да и код толком писать не надо, не то, что тут у нас в Рогах и Копытах». И во многом они правы, но в разрезе этой задачи про спутниковые снимки по голове стукнуть таких персонажей, конечно, хотелось.
Так вот, страдаю я. Ни черта не получается и непонятно, куда копать. Я сильно грешил на сеть, мол она у меня косячит, и поэтому ошибка в битых полигонах оттого, что предсказывает она плохо, полигоны в сабмите сильно фрагментированы, что приводит к большому размеру сабмита, плюс полигоны имеют какой-то неправильный формат, что и приводит к ошибкам. И весь месяц со всем этим я безуспешно прокувыркался. Надо отметить, что похожий успех имел не я один, но и большинство участников, что привело к тому, что многие не захотели мучаться со всем этим оверхедом и свалили на более прямолинейные, но от того не менее мутные параллельные соревнования по классификации рыбок и рака легких. За месяц до окончания на Leadeboard было порядка 200 человек, причем только 50 из них были выше sample submission.
Итак, что мы хотим? Получить много знаний в задаче по сегментации спутниковых снимков. Но что мы имеем? Да ни черта мы не имеем, кучу кода с какими-то сетями, которые непонятно как работают, если вообще работают.
Оставалось 30 дней, и чтобы в этот промежуток времени что-то склеилось, было необходимо сделать ход конем, что и было успешно осуществлено. В чатике (Slack канал Open Data Science) есть комната kaggle_crackers, в которой, в теории, происходит интеллигентное обсуждение текущих и прошлых задач по машинному обучению. Собственно, там я и начал активно задавать вопросы по этой задаче, в режиме «вот выдается ошибка, кто сталкивался?». Один из участников чата, а именно простой брутальный парень Костя Лопухин (финишировал пятым в составе крайне сильного DL квартета ), пока я блеял и спотыкался, прорубился через документацию по OpenCV и shapely, и написал правильный и быстрый код для перегона из маски в полигоны, который позволял сделать сабмиты адекватного размера, и это стало поворотным моментом для всего соревнования, я бы даже сказал, эпохальным. Собственно, с этого все и началось. Этой функцией пользовалось 90% участников, да и вообще, если бы не Костя, сидели бы британские военные и матерились на саентологов, а не запиливали свой Kaggle.
Я прикрутил функцию, сделал сабмит, получил 0 и последнее место на Leaderboard. Связано это было с очередным финтом от организаторов: оказывается, существовали какие-то мутные коэффициенты, которые применялись для анонимизации, и их надо было учесть, а после того, как я их учел, выяснилось, что сети у меня очень даже адекватные и выдают результат в топ-10%. Вопрос с ошибками при сабмите решился раздутием полигонов, потому что, оказывается, код Kaggle не любит полигоны с сильно острыми углами, и, если я не вру, это решение предложил Александр Мовчан.
Слово за слово, обсуждение этой задачи в профильном канале начало привлекать тех, кому эта задача показалось интересной, особенно когда стало понятно, что вся нездоровая инженерия, которой все занимаются на работе за деньги, но никто не хочет заниматься в свободное время и за бесплатно, преодолима.
Второе эпохальное событие случилось, когда Артур Кузин (закончил вторым в команде с Романом Соловьевым) решил показать, что аналитики в Avito не пальцем деланы, и что сейчас он покажет свой высокий класс саентологу из долины, и зафигачил kernel на Kaggle, который выдает решение end2end, то есть чистит данные, тренирует модель и делает предсказание, что привлекло еще пару сотен человек поучаствовать в решении этой проблемы.
Под это дело создали отдельный канал, Артур пригласил в чатик Романа Соловьева, который на Kaggle известен как легендарный ZFTurbo, а в России как скромный научный сотрудник в одном из конструкторских бюро. Также к чатику присоединился Алексей Носков. Видимо, его пригласили после того, как в составе команды он занял второе место в закончившемся в январе соревновании Outbrain Click Prediction. Мой будущий напарник Сергей Мушинский также решил, что хватит пинать балду в сибирских снегах и взялся за код и чтение литературы. Отдельно хочется отметить Андрея Стромнова, который хоть в соревновании и не участвовал, но так как сильно разбирался в предметной области, много консультировал нас на тему специфики работы со спутниковыми снимками.
Коллектив подтянулся, с инженерией мы разобрались, оставалось три недели, и что мы имели?
Абсолютно непонятно, как локально валидироваться. Стандартный способ — взять 5 картинок в holdout set и использовать их для валидации — меня сильно настораживал, ибо приводил к тому, что у нас train, validation, Public и Private — это четыре различных распределения, да и урезать и без того маленький train очень не хотелось.
Саша Мовчан предложил другой способ — от каждой картинки откусить кусок и validation кропать из него. В теории это было лучше, ибо гарантировало, что train и validation из одного распределения. Но это, конечно, тоже не решение, потому что test все равно достаточно сильно отличался, хотя эту гипотезу мы, безусловно, проверили.
В конце концов, каждый придумал что-то свое. Роман не жалел компьютерных ресурсов и делал 5 fold, Костя и Алексей выделяли несколько картинок для валидации, кто-то просто верил Public лидерборду, мотивируясь тем, что там 80 картинок, да и вообще, на задаче сегментации тяжело оверфитить.
Мы с Сергеем использовали рабоче-крестьянское решение и вообще не использовали валидацию. Тренировали, пока train loss не выходил на плато. После этого делались предсказания на весь test, бок о бок — маска и картинка.

И все это просматривалось глазами. С одной стороны, можно было словить очевидные недостатки в коде, например, у меня сеть любила добавить домов ровным слоем по краям картинки, что я решил тем же приемом, что использовался в оригинальной статье про Unet, а именно сделать padding отражением ближайшей области исходной картинки.
Или на картинке выше:
- Пруды напредсказывало в домах и посреди дорог.
- Непонятные куски асфальтовых дорог тут и там. Можно отфильтровать на стадии постпроцессинга по минимальной площади полигонов.
- Разрывы в предсказаниях асфальтовых дорог — можно попытаться исправить через морфологические преобразования.
Также это позволяло понять, на чем мы горим, на False Positive или False Negative и подкорректировать пороги бинаризации. После того, как визуально нам казалось, что стало лучше, отправлялось предсказание на Leaderboard. С одной стороны, такой подход — это нарушение правил, типа, смотреть на test — низкий стиль, но с другой — это жизнь, и занимались мы этим от безысходности. На работе же все время от времени делают manual review, ибо машинное обучение без Human In the Loop — это криминал.
Подытоживая про валидацию — из того, что я видел, наш подход самый надежный.
Следующий вопрос, на который мы всем коллективом пытались получить ответ — как ловить машинки и грузовики. Их целых два класса, то есть 20% итогового результата заложено в них. С машинками основные проблемы были в том, что их мало, каждая из них — это несколько пикселей на асфальте, да и размечены они по-индусски — где-то машина не размечена, где-то вместо машины отмечен мусорный бак, различные бэнды в одном и том же снимке могут быть сделаны с промежутком в несколько секунд, так что если машина движется, вы можете запросто получить на одном и том же снимке машину в различных местах.

Вот это один и тот же грузовик.
Другие команды использовали решения различной степени эффективности, но наша команда решила, опять же, поступить по-простому: мы на машинки забили, отдавая себе отчет, что на этом мы точно теряем. Возможно сейчас, когда я сильно улучшил свои навыки и знания в задачах локализации, я бы поступил по-другому, но на тот момент, видится мне, это было самое правильное решение.
Еще один нюанс, которым обладало данное соревнование — это формат сабмита и метрика, которые позволяли делать предсказания по отдельным классам и проверять, чему это соответствует на Leaderboard. С одной стороны, это позволяло участникам уйти в silent mode, а с другой, иметь более точную оценку предсказаний. Классы настолько разные, что при предсказании их всех за раз очень сложно оценивать прогресс. Из этих соображений все стали делать предсказания поклассово, что привело к появлению сводной таблички, которая выглядела примерно вот так:
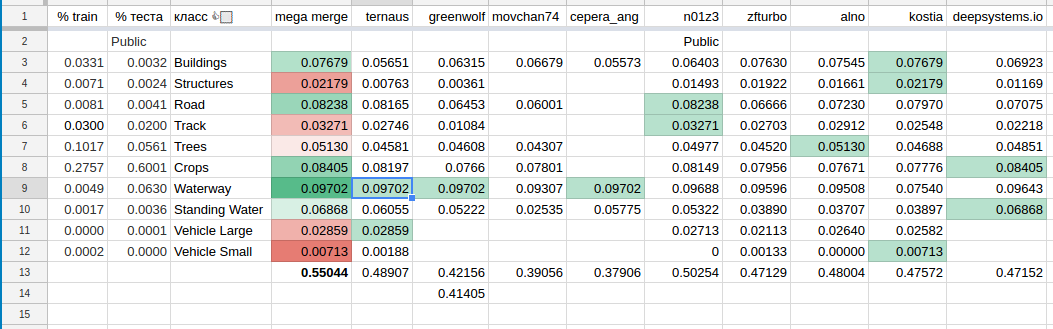
В свою очередь, это привело к формированию команд среди тех, кто верил, что это позволит сильно улучшить результат. Сначала Артур с Романом сбились в команду, после них Алексей, Костя и ребята с deepsystems.io. А потом и мы с Сергеем образовали команду, причем у нас получилось достаточно удобно из-за сильно различных часовых зон (Ангарск — Сан Франциско), этакая посменная работа.
Стандартный технический вопрос: какую сеть использовать? Каждая статья утверждает, что уж они то, State of The Art, при этом если и не врут, то этот State Of The Art был на других данных, и их опыт не обязательно переносится. Для оценки того, что из литературы можно использовать, а что нет, нужна адекватная валидация, а у нас, как отмечалось выше, ее не было. Все статьи, которые мы обсуждали, оперируют какими-то чистыми большими данными, а вот такого нигерийского паскудства, с которым работали мы, что-то нигде не встречалось.
И, конечно, у того, кто разбирается в задачах сегментации, может возникнуть законный вопрос: «А вы пробовали использовать прием X из статьи Y, ну например CRF для постпроцессинга?» или «А вы пробовали архитектуру сети Z, скажем, вариацию DenseNet для сегментации?». Скорее всего, ответ — да, мы перелопатили кубометры литературы, и многие идеи воплощали в коде и проверяли, но не в том режиме, что каждый пробовал все, скорее так: кто-то пробовал — у него не зашло, он поделился с остальными, и те уже на это время не теряли.
В отличие от стандартной задачи сегментации, где на RGB картинках надо попиксельно отличать золушек от чебурашек, у нас было много каналов на вход в различных диапазонах и это надо было как-то учитывать. Простой вариант — склеить все в один большой бутерброд и на этом тренировать, (Роман так и поступил), или же сделать хитрую сеть с различными входами, как поступил Артур? Довериться сети или же помочь ей дедовскими методами, а именно, делать сегментацию через индексы? Что делать с RGB? Спутник RGB не производит. Получается, что M band в низком разрешении смешивается с P band, который в высоком, добавляется щепотка табаку и получается RGB. Что и было показано в первом кернеле Владимира Осина.
Наша команда сделала так: быструю и медленную воду мы нашли через индексы на основе второго кернела от Владимира Осина.
А для остальных классов мы собрали RGB, P, M и приклеили 4 дополнительных индекса Enhanced vegetation index (EVI), Normalized difference water index (NDWI), Canopy Chlorophyl Content Index (CCCI), Soil-Adjusted Vegetation Index (SAVI). Все эти индексы не добавляют никакой новой информации, так что сеть и так бы разобралась, но, памятуя о том, как добавление квадратичных взаимодействий между признаками помогло градиентному бустингу в задаче Allstate, при том, что этот бустинг должен высокоуровневые взаимодействия находить сам, мы их добавили.
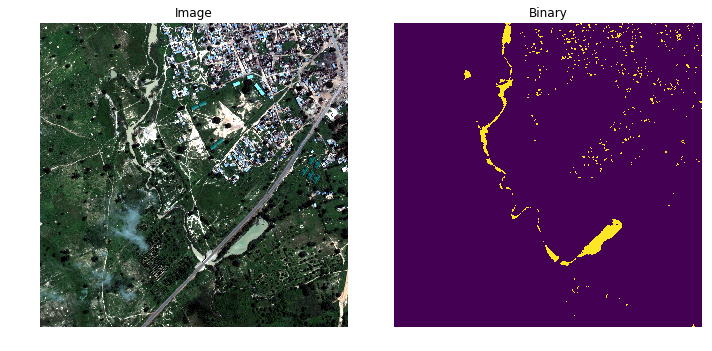
Как видно, на этой картинке вода через индексы находится очень неплохо, поэтому похожие техники и использовались с тех пор, как начали делать мультиспектральные спутниковые снимки.
После этого все это подавалось на вход подкрученной Unet. Unet — это что-то вот такое:
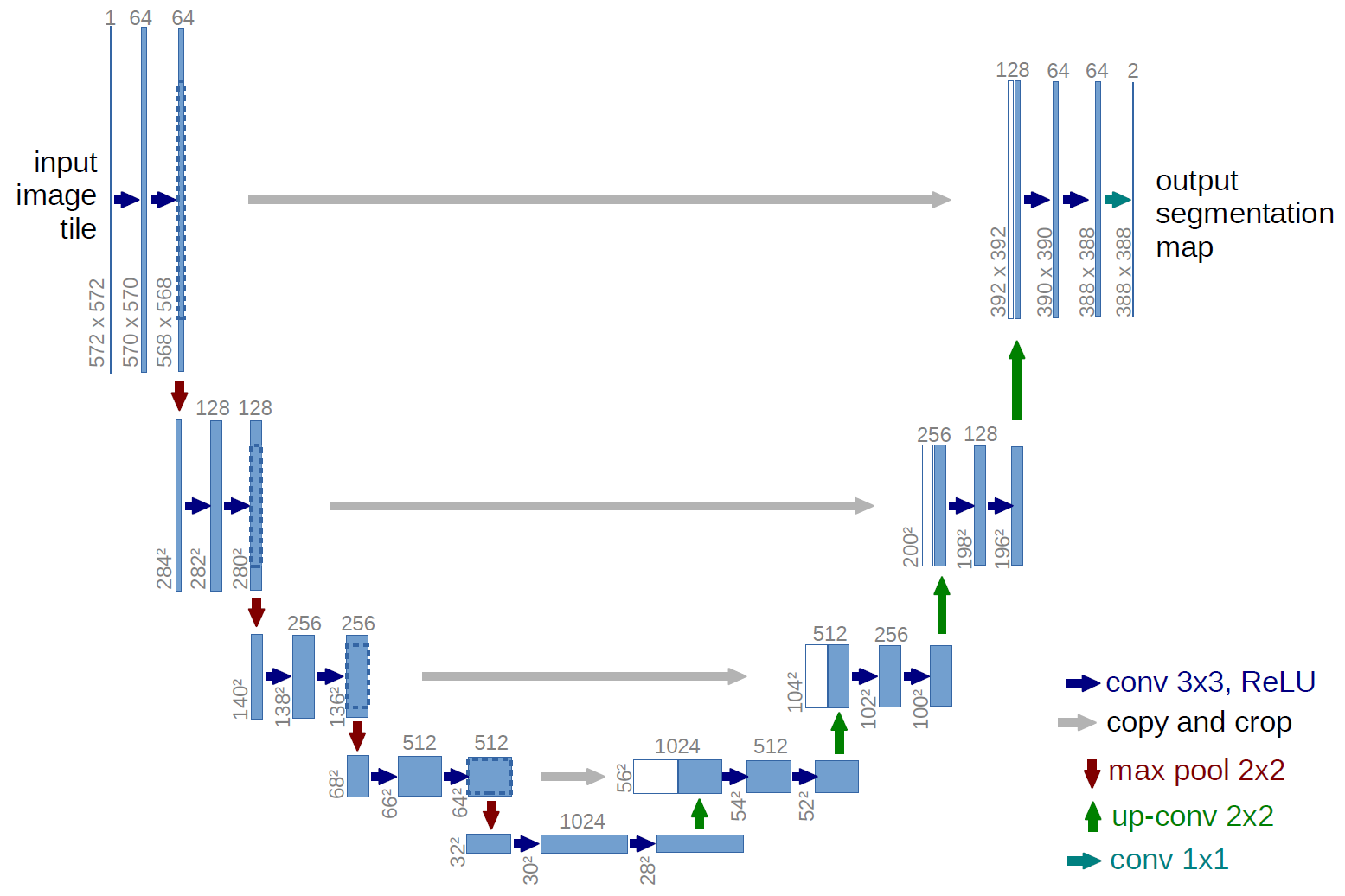
(картинка из оригинальной статьи, у нас было чуть по-другому (мы добавили BatchNormalization, заменили Relu на Elu, по-другому делали cropping и изменили число фильтров), но концептуально Unet он и в Африке Unet, хотя тут накрутить можно много. Вот интересный пример, сеть Тирамису, на которую у нас были большие надежды, но что-то она как-то не зашла ни у кого, кроме Алексея Носкова.)
У нас сложилось нестойкое впечатление, что поскольку картинки в Train сильно разные, то в данной задаче большой батч важнее чем большой receptive field, так что мы использовали батч в 128 картинок размером 112x112 и 16 каналами каждая. То есть на вход сети мы подавали матрицу (128, 112, 112, 16).
Сергей на своей GPU проверял с батчем в 96 картинок, зашло нормально, так что, возможно, имело смысл использовать (96, 128, 128, 16), что в общем похоже, но чуть лучше.
Скажу больше, разные классы требовали различного receptive field и разного числа каналов, скажем, поля скорее всего можно было предсказывать на одном M band, разрешения 1.24 m/pixel хватало за глаза. Можно даже уменьшать. И так как этих полей много, то и большой batch size не требовался.
Данных мало, поэтому при тренировке к каждой картинке из батча применялось рандомное преобразование из группы D4 (группа симметрий квадрата). Другие команды дополнительно использовали повороты на небольшие углы, но у меня руки не дошли, и без этого то, что работало, работало более-менее, а для машинок этого было маловато в любом случае.
В качестве Optimizer мы использовали Nadam и тренировали каждую сеть 50 эпох по 400 updates с learning rate = 1e-3, а потом еще 50 с learning rate = 1e-4
В качестве функции потерь мы использовали вот такое выражение:

Похожая функция потерь хорошо себя показала в другой задаче сегментации. Интуиция за нашим выбором была вот такая: c одной стороны, нам нужна вероятность принадлежности к каждому классу, поэтому хорошо себя покажет binary_crossentropy, а с другой, наша метрика это jaccard, значит хорошо бы добавить его аппроксимацию в loss function. Как бонус, такая комбинация упрощала жизнь на стадии выбора threshold при перегоне из вероятности принадлежности пикселя к маске к двоичному значению. При этой loss function становится не очень важно, что вы используете: 0.3, 0.5 или 0.7. Вернее, разница есть, но она меньше, чем могла бы быть при использовании голой binary_crossentropy.
Каждая Fully Convolutional Network грешит тем, что предсказания уменьшают точность при удалении от центра, что обычно решается обрезанием предсказания по краям и / или перехлестом предсказаний. Мы делали и то, и другое. У каждой предсказанной маски по краям обрезались по 16 пикселей. Плюс мы использовали test time augmentation, вот в таком режиме, что отчасти уменьшало краевые эффекты:
К примеру, исходная картинка размером (3348, 3396) добиваться через ZeroPadding до (3392, 3472)
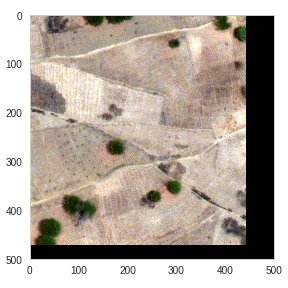
Оставлять края в таком ZeroPadding режиме нельзя, когда я так делал, эта острая грань сетью воспринималась как стена дома, и получались дома, размазанные ровным слоем по всему периметру. Это достаточно легко решается. Как я уже упоминал, в оригинальной статье по Unet это решалось добавлением отражения от исходной картинки в эту область, и мы поступили точно так же.

Эта картинка режется на пересекающиеся куски 112x112, с 16 пиксельным перехлестом. Собирается в один большой батч (а он реально большой: одна картинка 3600x3600 ~ 1800 патчей 112x112), предсказывается, разбирается обратно в большую картинку.

Но можно усугубить. Если отразить/повернуть исходную большую картинку, сделать предсказание, а потом вернуть к исходной ориентации, то выяснится, что нарезка происходила немного по-другому. И если повторить это несколько раз для различных ориентаций и усреднить (в данном случае мы использовали геометрическое среднее), то с одной стороны частично будет закрыт вопрос с краевыми эффектами, а с другой, test time augmentation, который мы провели, уменьшает variance предсказания, что железобетонно добавляет чуть-чуть к точности.
К точности добавляет, но и на предсказания начинает уходить значительно больше времени. Что-то вроде пяти часов на весь test. Другое дело, что это можно распараллелить, но на тот момент дома в компьютере стоял только один Titan, так что test time augmentation под такие задачи, наверно, имеет смысл использовать ближе к финалу. Ну очень уж накладно.
Сделали предсказания. Все? Конечно нет. Остается post processing. Например, можно попытаться убрать все предсказания домов из быстрой воды, которой мы верим больше, чем домам, а всю медленную воду из домов, которым мы верим больше, чем этой медленной воде.
После этого применяется Костина функция, мы пробиваемся через ошибки сабмита, все становится хорошо и приятно, и мы добираем еще немного очков на LeaderBoard.
Если суммировать кусок нашего решения про нейронные сети в двух словах, то может получиться что-то вроде того, что получилось у Артура, когда он на той неделе делал доклад на ML-тренировке в Яндексе:
В последние несколько дней, когда все уже эмоционально вымотались, а кто-то еще и физически (ближе к концу я пару часов за ночь вставал по будильнику перезапустить тренировку сети, предсказаний или еще чего-нибудь), хотелось если не хлеба, то зрелищ, и под это дело Сергей выложил на форум скрипт Артура, в котором поправил баги + добавил пару улучшений, а Михаил Каменщиков пожертвовал готовые натренированные веса для сети для этого скрипта. И этот скрипт выдавал 0.42 на Public Leaderboard, то есть на тот момент что-то в районе 30 места из 420. Халява — это сладкое слово, так что народ начал массово этот скрипт запускать, вызывая стоны гнева на форуме, правда, как выяснилось позже, на Private Leaderboard все было сильно хуже, и весь этот коллектив халявщиков улетел мест на 100 вниз.
Под это дело Михаил моментально разродился вот таким мемом.

Это я к тому, что все вымотаны. Те, кто в топ-10, гадают, останутся ли они там (мечтая о Kaggle’овой ачивке gold medal, которая является необходимым условием для другой ачивки Kaggle Master/GrandMaster), а те кто в топ-3, в похожих мыслях, но уже про деньги.
На финише, на Public Leaderboard в top 10:
- 0.5858 - Kyle — альфа-гусь из Малайзии
- 0.5569 — Квартет из Кости Лопухина, Алексея Носкова, Рената Баширова, Руслана Байкулова
- 0.5484 — Роман Соловьев, Артур Кузин
- 0.5413 — Дмитрий Цыбулевский
- 0.5413 — Октет deepsense.io
- 0.5345 - ironbar — неизвестный нам испанец
- 0.5338 — Kohei — неизвестный нам японец
- 0.5287 — Я и Сергей Мушинский
- 0.5222 — Daniel FG — какой-то неизвестный гусь
- 0.51725 — Евгений Некрасов
Итак, в Москве — ночь на 7 марта, в топ-10 на Public Leaderboard половина команд — из нашего дружного чатика. Все ждут трех часов ночи, объявления результатов. Тут надо отметить, что вся эта месячная движуха вокруг спутниковых снимков подогрела к ней интерес не только участников, но и большого числа болельщиков, которые сами не пробовали окунуться в пучину водоема всей этой инженерной мути, в которую мы не только окунулись, но и благополучно переплыли, поддерживая друг друга от того, чтобы не утонуть. Мне чуть проще — у меня другой часовой пояс, так что я на работе прикручивал очередную модель в production, параллельно наблюдая и участвуя в дискуссиях.
Седьмое марта, 3 часа ночи по Москве, окончание соревнований, все вдохнули, смотрят на сайт — а выдыхать не хочется. Всем хочется развязки, какой бы она ни была, а она не наступает. Зато, вместо этого, приходит от админа вежливое:
I wanted to remind you that per Dstl's request, we will withhold the private leaderboard until March 14th in order to synchronize with their press release.
Чатик бурил, стонал и матерился, эмоции лились через край.
Через неделю, вышел пресс релиз, с мощным названием: «Dstl’s Kaggle competition has been a great success» британских военных о том, как они все впечатлены, и рассказали, сколько денег они за это возможно попилили (2,500k), сколько заплатили Kagge (350k за хостинг соревнования, 100k на призы), и что они активно и тщательно анализируют решения победителей.
И чуть позже этих победителей таки объявили. В первой десятке только альфа-гусь Kyle остался без изменений, остальных чуть перемешало, что и не удивительно, учитывая, что Public test и Private test так сильно различались. Артур с Романом поднялись с третьего места на второе, мы с Серегой с восьмого на третье, квартет потерял 3 места и ушел на пятое, Дмитрий Цыбулевский тоже потерял пару мест, зато Евгений Некрасов поднялся на целых три.
Ниже по рейтингу народ метало гораздо сильнее, +- 100 мест влегкую. Например, движения 129 => 19 (это хорошо карта легла), или 20 => 133 (это плохо). Такие движения — классический пример того, что получается когда Train, Public / Private — это различные распределения, и тут помогут либо удача, либо правильный механизм cross validation: под этим я понимаю не то, что пишут в книжках вроде «разделите на 5 statified fold и все нормально», а про то, что на пару порядков замысловатее. Например, есть методика в соревновательном машинном обучении, которая объясняет как выбирать правильный random seed при разбиении на фолды так, чтобы у ваших моделей была выше способность к предсказаниям на тех данных, что ваша модель еще не видела.
Но тем не менее, вся эта движуха — это все равно странно. Да, коллектив оверфитил Public LB в надежде на то, что точность модели на Private будет такая же. И по идее, так и надо было делать. Вот просто потому, что в train — 25 картинок, а в Public — 19% от 425, то есть 80. А 80 — это гораздо больше, чем любой hold out, что вы можете откусить от train. Вера в то, что точность на 80 картинках Public будет похожа на 397 картинок в Private если не железобетонная, но вполне себе логичная.
А вот что получилось на самом деле. После окончания соревнования админы признались, что по факту было размечено только 57 изображений. Есть гипотеза, что изначально у британских военных было 450 картинок, они наняли индусов размечать данные, и кто-то на форуме даже публиковал ссылку на объявление об этой работе. Те успели разметить только 57 картинок. Но так как соревнование надо начинать, то сделали ход конем — 25 картинок в Train, 6 в Public, 26 в Private и 397 для шуму. То есть предсказания на этих 397 картинках мы делали, но они не учитывались. Такой фокус делают достаточно часто, чтобы предотвратить ручную разметку, но обычно об этом объявляют до начала соревнований, а не после. И чатик снова бурлил, стонал и матерился.
Закругляясь, скажу, что лично мне хотелось нахвататься знаний про применение нейронных сетей для сегментации изображений. Тут и статьи по DL, и туториалы по OpenCV, все это воплощено в коде, плюс была написана инфраструктура, которая может быть использована под любую другую задачу сегментации.
У меня появился доступ к коллективу очень умных людей, которые могут и хотят рубить злые проблемы в машинном обучении. Последние два года, после регистрации на Kaggle, я пытался сагитировать одногруппников в аспирантуре, коллег на работе, даже стал соучредителем meetup group San Francisco Kagglers, но все безуспешно. И тут карта легла. И это очень-очень важно.
За третье место меня подняло в Kaggle рейтинге аж до 67 места из 55000, что, будем надеяться, чуть поможет с поиском Deep Learning ориентированной работы, да и деньги, которые мы, кстати, пока так и не получили, являются приятным бонусом.
Что не получилось: работу, напрямую связянную с DL, я пока так и не нашел, хотя я в процессе с парой компаний. Но быть в процессе и получить оффер — это совсем не одно и то же. Два параллельных соревнования про рыбок (приз 150k) и про рак легких (приз миллион долларов) прошли мимо меня, то есть ни знаний, ни денег с этих задач я тоже не получил. Но это все мелочи, на фоне того, что я разобрался с задачами сегментации всего чего можно как классическими методами, так и через Deep Learning.
Что получили британские военные: они получили Proof Of Concept, что делать разметку по спутниковым снимкам можно, и что соревнования — это дешевый вариант поиметь алгоритмы за маленькие деньги, плюc немного PR.
Как я уже упоминал, они даже запилили свою версию Kaggle, и даже запустили там пару соревнований, и одно из них про идентификацию машинок на спутниковых снимках. Правда, так как на уровне Британского правительства Граждане России считаются людьми второго сорта, на приз претендовать мы не можем, китайцы, правда, тоже.
Насколько предложенные нами решения далеки от production?
В том виде, в котором они есть сейчас, в production пускать, наверно, не стоит, хотя если добавить данных, нанять специалистов по DL, дотренировать, докрутить эвристик, то можно получить более чем достойные результаты. Но вот прямо сейчас Британские ракеты по нашим предсказаниям наводить, наверно, не стоит, так что Нигерия может спать спокойно.
Наш блог пост на Kaggle (за него вроде обещают дать футболку с надписью Kaggle). Он по английски, в нем меньше динамики, но чуть больше технических деталей — ссылка.
Для тех, кто, таки добрался до этой части текста и ему все еще мало, вот ссылка на видео с выступления Артура в Yandex про свое решение этой задачи плюс его пост на хабре.
В дополнение видео от Романа (у него профессиональная деформация интересные визуализации делать.)
Ну и напоследок хочется сказать отдельное спасибо всем тем, с кем мы долго и упорно обсуждали эту задачу, что и позволило добраться до топа. Отмечаются в лучшую сторону: Сергей Мушинский, Артур Кузин, Константин Лопухин, Андрей Стромнов, Роман Соловьев, Александр Мовчан, Артем Янков, Евгений Нижбицкий, Владимир Осин, Алексей Носков, Алексей Романов, Михаил Каменщиков, Расим Ахунзянов, Глеб Филатов, Егор Панфилов.
Отдельное спасибо Насте bauchgefuehl за редактирование.
