Comments 42
Мое почтение за прекрасную работу и рассказ.
В top 100 на Kaggle с точки зрения ML очень серьезные люди, а он даже не в сотне, он в 30-ке.
На предыдущем соревновании по image segmentation мы финишировали примерно одинаково (я 10, он 12), поэтому я предполагаю, что в это соревнование с точки зрения DL мы вошли примерно на одном уровне по знаниям, но судя по тому, что он делал все возможные submission каждый день я думаю, что он изначально нацеливался на победу, в то время как мне больше интересны знания, то есть он рассматривал эту задачу значительно более серьезно.
На этой задаче вполне можно работать в одиночку если хватает domain knowledge и опыта работы с изображениями, что Евгений Некрасов, Дмитрий Цыбулевский и другие участники в топе и продемонстрировали.
У нас ушло много времени, как на инженерные нюансы, так и на то, чтобы разобраться с тем, как работа со спутниковыми снимками отличается от обычных задач сегментации.
Если не тратить на это время все можно делать гораздо быстрее, что, будем надеяться, я смогу продемонстрировать на какой-нибудь другой задаче сегментации.
Суммируя — я думаю, что работал он сам, без поддержки. И тот факт, что он держится на первом месте на задаче про тюленей только укрепляет меня в этой мысли.
Далее по тексту я буду называть Data Scientist’ов кодовым словом «саентолог»Тут я капитально подвис :)
Среди саентологов Кремниевой Долины, в которой я в данный момент обитаю, успехи на Kaggle котируются примерно рядом с никак
А в чем причина? Вроде бы кагли — довольно авторитетный портал, не?
Под этот вопрос можной целый пост написать, но если в двух словах, все, как обычно, сводится к эффекту Даннинга — Крюгера
Про Kaggle слышали все, а вот число тех, кто пробовал работать хоть над одной задачей, в районе одной десятой от одного процента от общего числа. И, наверно, многие бы хотели попробовать, но не смотря на то, что порог вхождения в Kaggle по знаниям достаточно низкий, требования по затрачиваемому времени и по железу многих отпугивают.
Опять же среди коллектива есть мнение, что читать выжимку решения победителей и сделать такое же решение самому — это одно и то же, хотя, эти две вещи даже и не в одной вселенной.
Плюс у всех мозги промыты стандартной пропагандой Долины, что твоя единственная цель в жизни: "bring value to the company", поэтому подсознательно все вне этого имеет сильно меньшую ценность. Что в общем тоже имеет под собой основу, от прототипа модели до production путь достаточно долгий.
В общем среди тех, кто пробовал работать хоть над одной задачей Kaggle котируется — их просто очень мало. Есть надежда, что после того, как Google купил Kaggle у него поднимется статус и больше людей закатают рукава и начнут что-то пробовать, тем более, что в последнее время идут очень интересные задачи.
Есть исключения, вроде компаний H2O или DataRobot, но в их бизнес модель каглеры замечательно вписываются, поэтому они народ из top 100 и нанимают и для них кагловые ачивки засчитываются.
У тебя очень сильные посты про компьютерное зрание. Жаль посты плюсовать уже не могу, поставлю в карму.
Ты сейчас работаешь над какой-нибудь задачей на Kaggle по этой тематике?
Плюс у всех мозги промыты стандартной пропагандой Долины, что твоя единственная цель в жизни: "bring value to the company", поэтому подсознательно все вне этого имеет сильно меньшую ценность.
Мне казалось, что наоборот в Долине все постоянно тусуются по всяким митапам, хакатонам и прочим компетишенам и больше тратыт время на околопрофессиональные хобби. Но видать глобализация последних пары лет что-то изменила)
Ты сейчас работаешь над какой-нибудь задачей на Kaggle по этой тематике?
Меня морские львы заинтересовали, но пока дело дальше изучения датасета не двинулось. Странный формат разметки и большая фора у тех, кто учавствовал в рыбках/спутника пока несколько отпугивают от глубокого погружения в задачу.
Там аэрофотоснимки лежбищ, а разметка лежит в виде: weak instance segmentation (разноцветными точками отмечены отдельные особи) + для каждой картинки есть число особей каждого типа. Картинки, естественно, лошадиного размера (т.ч. все трюки с тайлингом туда пойдут без изменений). Думаю, что решение ternaus довольно легко можно адаптировать под эту задачу (лоадер данных переписать, вместо crossentropy взять total variation, etc.) и получить неплохой baseline практически из коробки.
Ну а судя по тому, что топ-1 в спутниках и львах совпадает, то похоже так оно и есть)
есть методика в соревновательном машинном обучении, которая объясняет как выбирать правильный random seed при разбиении на фолды так, чтобы у ваших моделей была выше способность к предсказаниям на тех данных, что ваша модель еще не видела.
Не подскажите ссылки на методику или попутные примеры/материалы? Спасибо.
Если почитать форум после окончания каждого соревнования, то участники делятся идеями и трюками, которые они пробовали и там обычно очень много креатива.
Конкретно c выбором random seed вот такой трюк, дает он мало, но когда борешься за пятый знак после запятой, что часто встречается на Kaggle, то вполне себе работает.
Пусть есть данные, пусть есть задача бинарной классификации и пусть у нас положительных исходов в 100 раз больше, чем отрицательных. Путь мы хотим разбить данные на 5 folds. Делаем рандомно. Делаем крос валидацию, смотрим на mean предсказаний и std.
std большое. Что получилось? Единичек мало и получилось что в каких-то фолдах их сильно меньше, чем в других.
Собственно для решения этой проблемы и придумали stratified Kfold, то есть чтобы при разбиении распределение по классам в разных фолдах стало одинаковым.
Проверяем, std предсказаний с разных фолдов стало меньше.
Можно усугубить? Можно.
Идея в том, что если в данных хватает outliers, то их может неравномерно раскидать по фолдам. Но мы не знаем какие именно ряды — это аутлаеры, да даже если бы и знали, просто дропать их сомнительное решение.
И вот тут появляется трюк:
Мы берем простую, быстро тренируемую модель, и в цикле делаем разбивку на startified folds с различными random_seeds, на каждой разбивке тренируем модель, смотрим на std, и выбираем тот random_seed, где std небольшой.
Но, повторюсь, трюки вроде этого это там же где и технология stacking, то есть чисто под соревнования, да и то, далеко не под все. На работе так делать не надо.
Я проходил курс по ML от Стэнфорда на Coursera, но тут явно я многого не знаю.
Спасибо!
Хорошой вопрос. Есть замечательная книжка Deep Learning. Под эту задачу, наверно, можно обчитаться статьями которые говорят про image segmentation.
Но самое быстрое, это, наверно, просто взять какую-то задачу, и если нет ничего подходящего под рукой, то задача про морских львов, которую обсуждали выше, хорошо подойдет. Там и литература будет читаться, и код писаться и прийдут все необходимые данные под ту задачу, а часть из них можно будет перенести и на другие.
Хотя если есть какие-то конкретные вопросы — я готов попытаться указать где почитать.
Лучше в слаке Open Data Science
Причем там можно даже и не в личку писать, хотя и так, конечно, можно, а сразу в каналы:
deep_learning, ml_beginners, kaggle_crackers, и т.д. Народу много, ответят по делу и быстро.
Каждая Fully Convolutional Network грешит тем, что предсказания уменьшают точность при удалении от центра, что обычно решается обрезанием предсказания по краям и / или перехлестом предсказаний.
Из-за чего они возникают? из-за zero padding'а на слоях в самой сети?
Как выбирается нахлест тайлов на которые бьётся вся картинка и padding вокруг тайла при подаче на вход сети, исходя из receptive field самой сети?
Т.е. надо взять тайл изначально большего размера, добив его по краям k/2 pixels от большого изображения, на краях(там где кончается большое изображение) используем отражение.
Так вот насколько я понимаю k это как раз и есть receptive field пикселя с выходного feature map (который имеет меньший spartial размер чем входной тайл) или как высчитать k?
Потом от конечной feature map вырезаем только середину.
Как раз вопрос про предикш, опять же нахлест был k пикселей? как потом объединялись результаты с соседних тайлов, просто усреднением в области пересечения?
Когда мы добиваем нулями по краям края плывут. Тут можно говорить про то, что они меняют распределение. (Где-то мне попадалось Andrew Karpathy на эту тему переживал)
Интуитивно, если использовать свертки 3x3 — то каждый раз, один краевой пиксель портится => 16 сверток => 16 пикселей пролетает. Этой логикой мы и руководствовались. При напсиании поста на kaggle хотелось добавить структуры к повествованию, так что мы сделали то, до чего руки не доходили раньше — мы замерили это все и получилось вот так:

То есть да, 16 пикселей по краям — беда.
Была идея применить reflection padding, вместо ZeroPadding, тем более, что он есть в Tensorflow, но опять же руки не дошли.
На тему пикселей и receptive field => нам попадались статья, где как раз исследовалось, как точность убывает к краям. Там было много красивых слов, но по факту они просто замерили для какой-то архитектуры сети на каких-то данных, построили графики и этого хватило на статью.
Списывать падение точности предсказания к краям только на zeropadding будет не правильно. Банально число путей добраться из любого пикселя на входе в любой пиксель на выходе как раз и будет функцией от того, как далеко этот выходной пиксель на выходе. Под это дело можно придумать много математики и написать что эта функция ни что иное как гауссиана, или еще что-нибудь.
Но на практике достаточно прогнать сеть, посмотреть как точность на train убывает к краям и эти края перехлестывать или обрезать. Или и то и другое. Теории, лучше чем подсчитать число padded pixels на всем пути нет.
Как усреднять перехлест — я бы делал через геометрическое среднее, на практике, обычно, хоть и не всегда, это работает лучше, чем арифметическое. Хотя тут можно много чего накрутить.
Я пробовал reflective padding чтобы предсказывать на краях картинки, на всех классах с мелкими деталями это только ухудшало финальный скор, и визуально было много false positives.
Я изначально имел ввиду что то такое:
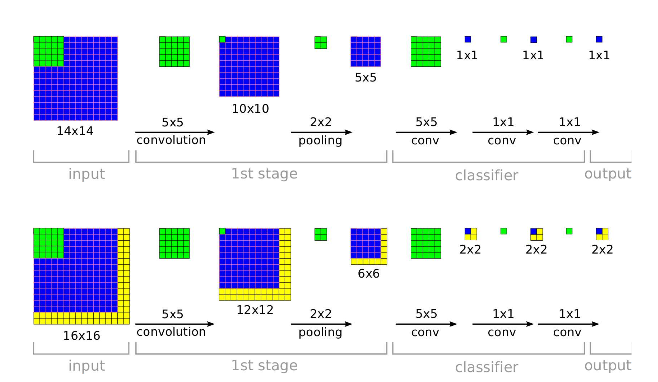
Т.е. в зависимости от архитектуры сети можно добить тайл по краям так, чтобы в конце мы получили feature map у которого мы отбросим рамку в 1 пиксель вокруг, а внутреннюю часть возмём, таким образом я предполагаю можно избавится от дефектов.
Судя по пейперу U-net используется unpadded convolutions, но не написано по какому принципу они кропают центральную часть feature map'а.
Тут вот судя по коду на это вообще забили.
В вашем случае k = 16, т.к. 16 сверток 3x3, каждая из которых съедает по пикселю, как было описано выше.
В итоге это избавляет от артефактов на краях тайла.
В U-net судя по пейперу идёт кроп перед каждым пулингом и не описано по какому принципу.
Я пробовал делать так, как описано в оригинальной статье, где они начинают с 512x512 и добавляют crop2d после каждого конволюционного блока и на выходе получают 388x388.
В чем логика выбора размера кропа я не разбилася, но кропают они там очень агрессивно.
И, так делать не надо. Работает плохо. Все более поздние работы, которые основаны на этой архитектуре поступают по другому. Более адекватный и менее ресурсоемкий вариант — забить, как Марко и сделал по ссылке, которую вы указали. А предсказывать с перехлестом, который позволяют вычислительные ресурсы.
Наверное можно, размазать наш crop2d на 16 пикселей на весь encoding block (16 crop2d, которые кропают по одному пикселю), но было лень. Хотя в следующий раз я, возможно, озадачусь. Это позволит слегка уменьшить число вычислений.
Хотя вычислять все-таки можно. Например, на картинке которую вы указали используется 5x5 conv, то есть 2 пикселя по краям после этой свертки убиваются и их можно кропнуть.
При написании этого поста, мне было лень рисовать нашу сеть, но при подготове текста на Kaggle cepera_ang все-таки ее изобразил. То, что мы по фaкту использовали, выглядит так:

Можно было делать valid. Про размазывание crop2d с кропом в один пиксель после конволюций c same — это я спросоня написал :)
Но valid неудобно именно по соображениям, что написал Костя — надо думать про размеры, что замедляет скорость итераций.
Очень хотелось проверить, что будет на краях, если вместо same использовать reflection padding и как это скажется на краевых эффектах, но руки не дошли.
Kaggle: Британские спутниковые снимки. Как мы взяли третье место