
Привет, Хабр! Сегодня я хочу рассказать вам, как можно изменить свое лицо на фото, используя довольно сложный пайплайн из нескольких генеративных нейросетей и не только. Модные недавно приложения по превращению себя в даму или дедушку работают проще, потому что нейросети медленные, да и качество, которое можно получить классическими методами компьютерного зрения, и так хорошее. Тем не менее, предложенный способ мне кажется очень перспективным. Под катом будет мало кода, зато много картинок, ссылок и личного опыта работы с GAN'ами.
Задачу можно разбить на следующие шаги:
- найти и вырезать лицо на фото
- преобразовать лицо нужным образом (превратить в женщину/чернокожего и т.п.)
- улучшить/увеличить полученное изображение
- вставить трансформированное лицо обратно в оригинальное фото
Каждый из перечисленных шагов можно реализовать отдельной нейросетью, но можно обойтись и без них. Давайте по порядку.
Детекция лица
Здесь проще всего. Можно ничего не выдумывать и просто взять dlib.get_frontal_face_detector()(пример). Dlib'овский детектор по умолчанию использует линейный классификатор, обученный на HOG-фичах.

Как мы видим, выдаваемый прямоугольник содержит не все лицо, поэтому лучше его увеличить. Оптимальные коэффициенты увеличения можно подобрать руками. В итоге у вас может получиться подобный метод и подобный результат:
def detect_single_face_dlib(img_rgb, rescale=(1.1, 1.5, 1.1, 1.3)):
fd_front_dlib = dlib.get_frontal_face_detector()
face = fd_front_dlib(img_rgb, 1)
if len(face) > 0:
face = sorted([(t.width() * t.height(), (t.left(), t.top(), t.width(), t.height()))
for t in face],
key=lambda t: t[0], reverse=True)[0][1]
else:
return None
if rescale is not None and face is not None:
if type(rescale) != tuple:
rescale = (rescale, rescale, rescale, rescale)
(x, y, w, h) = face
w = min(img_rgb.shape[1] - x, int(w / 2 + rescale[2] * w / 2))
h = min(img_rgb.shape[0] - y, int(h / 2 + rescale[3] * h / 2))
fx = max(0, int(x + w / 2 * (1 - rescale[0])))
fy = max(0, int(y + h / 2 * (1 - rescale[1])))
fw = min(img_rgb.shape[1] - fx, int(w - w / 2 * (1 - rescale[0])))
fh = min(img_rgb.shape[0] - fy, int(h - h / 2 * (1 - rescale[1])))
face = (fx, fy, fw, fh)
return face
Если же работа "старых" методов по каким-то причинам вас не устраивает, можно попробовать deep learning. Для решения задачи обнаружения лица подойдут любые Region Proposal Networks, например YOLOv2 или Faster-RCNN. Как попробуете — обязательно поделитесь тем, что у вас получилось.
Трансформация лица
Вот тут самое интересное. Как вы уже наверняка знаете, преобразовать лицо или сделать маску можно и без нейросетей, и это будет хорошо работать. Но генеративные сети — гораздо более перспективный инструмент для обработки изображений. Уже есть огромное количество моделей, типа <your prefix>GAN, которые умеют вытворять самые разные трансформации. Задача преобразования изображений из одного набора (домена) в другой называется Domain Transfer. С некоторыми архитектурами Domain Transfer сетей вы могли познакомиться в нашем недавнем обзоре GAN'ов.

Cycle-GAN
Почему именно Cycle-GAN? Да потому что она работает. Посетите сайт проекта и посмотрите, что можно делать с помощью этой модели. В качестве датасета достаточно двух наборов изображений: DomainA и DomainB. Допустим, у вас есть папки с фотографиями мужчин и женщин, белых и азиатов, яблок и персиков. Этого достаточно! Клонируете репозиторий авторов с реализацией Cycle-GAN на pytorch и приступаете к обучению.
Как это работает
На этом рисунке из оригинальной статьи достаточно полно и кратко описан принцип работы модели. По-моему, очень простое и изящное решение, которое дает хорошие результаты.

По сути, мы обучаем две функции-генератора. Одна —  — учится по входному изображению из домена
— учится по входному изображению из домена  генерировать изображение из домена
генерировать изображение из домена  . Другая —
. Другая —  — наоборот, из в . Соответствующие дискриминаторы
— наоборот, из в . Соответствующие дискриминаторы  и
и  им в этом помогают, как это свойственно GAN'ам. Обычный Advesarial Loss (или GAN Loss) выглядит следующим образом:
им в этом помогают, как это свойственно GAN'ам. Обычный Advesarial Loss (или GAN Loss) выглядит следующим образом:
![$L_{GAN}(G, D_Y, X, Y)=\mathbb{E}_{y\sim p_{data}(y)}[\log D_Y(y)]+\mathbb{E}_{x\sim p_{data}(x)}[\log (1-D_Y(G(x)))]$](https://habrastorage.org/getpro/habr/formulas/d10/d59/028/d10d590282f430fd7337fca878fd8bbb.svg)
Дополнительно авторы вводят так называемый Cycle Consistensy Loss:
![$L_{cyc}(G,F) = \mathbb{E}_{x \sim p_{data}(x)}[\left \| F(G(x))-x \right \|_1] + \mathbb{E}_{y \sim p_{data}(y)}[\left \| G(F(y))-y \right \|_1]$](https://habrastorage.org/getpro/habr/formulas/ed1/c22/bed/ed1c22bed3d34b1d37748964a6f597ff.svg)
Суть его в том, чтобы изображение из домена , пройдя через генератор , а потом через генератор , было максимально похоже на оригинал. Короче,  .
.
Таким образом, целевая функция принимает вид:

и мы решаем следующую задачу оптимизации:

Здесь  — гиперпараметр, контролирующий вес дополнительного лосса.
— гиперпараметр, контролирующий вес дополнительного лосса.
Но это еще не все. Было замечено, что генераторы очень сильно меняют цветовую гамму оригинального изображения.
Чтобы это исправить, авторы добавили дополнительный лосс — Identity Loss. Это своего рода регуляризатор, который требует от генератора identity mapping для изображений целевого домена. Т.е. если на вход генератору зебр пришла зебра — то не надо такую картинку изменять.
![$L_{identity}(G,F) = \mathbb{E}_{y \sim p_{data}(y)}[\left \| G(y)-y \right \|_1] + \mathbb{E}_{x \sim p_{data}(x)}[\left \| F(x)-x \right \|_1]$](https://habrastorage.org/getpro/habr/formulas/3ea/9bc/8bc/3ea9bc8bc2fd2bbdb5f61cfba307197f.svg)
На (мое) удивление это помогло решить проблему сохранения цветовой гаммы. Вот примеры от авторов статьи (там картины Моне пытаются преобразовать в реальные фотографии):

Архитектуры используемых сетей
Для того чтобы описать используемые архитектуры, введем некоторые условные обозначения.
c7s1-k — это сверточный слой 7х7 с последующей батч-нормализацией и ReLU, со страйдом 1, паддингом 3 и количеством фильтров k. Такие слои не уменьшают размерность нашего изображения. Пример на pytorch:
[nn.Conv2d(n_channels, inplanes, kernel_size=7, padding=3),
nn.BatchNorm2d(k, affine=True),
nn.ReLU(True)]dk — сверточный слой 3х3 со страйдом 2 и кол-вом фильтров k. Такие свертки уменьшают размерность входного изображения в 2 раза. Опять пример на pytorch:
[nn.Conv2d(inplanes, inplanes * 2, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(inplanes * 2, affine=True),
nn.ReLU(True)]Rk — residual блок с двумя свертками 3х3 с одинаковым количеством фильтров. У авторов он сконструирован так:
resnet_block = []
resnet_block += [nn.Conv2d(inplanes, planes, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(planes, affine=True),
nn.ReLU(inplace=True)]
resnet_block += [nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(planes, affine=True)]uk — 3x3 up-convolution слой с BatchNorm и ReLU — для увеличения размерности изображения. Опять пример:
[nn.ConvTranspose2d(inplanes * 4, inplanes * 2, kernel_size=3, stride=2,
padding=1, output_padding=1),
nn.BatchNorm2d(inplanes * 2, affine=True),
nn.ReLU(True)]С указанными обозначениями генератор с 9 резнет-блоками выглядит так:
c7s1-32,d64,d128,R128,R128,R128,R128,R128,R128,R128,R128,R128,u64,u32,c7s1-3
Мы делаем изначальную свертку с 32 фильтрами, потом два раза уменьшаем изображение, попутно увеличивая количество фильтров, затем идут 9 резнет-блоков, потом два раза увеличиваем изображение, уменьшая кол-во фильтров, и финальной сверткой создаем 3-канальный выход нашей нейросети.
Для дискриминатора будем ипользовать обозначение Ck — свертка 4х4 с последующими батч-норм и LeakyReLU с параметром 0.2. Архитектура дискриминатора следующая:
C64-C128-C256-C512
При этом для первого слоя C64 мы не делаем BatchNorm.
А в конце еще добавляем один нейрон с сигмоидной функцией активации, который говорит, фейк ему пришел или нет.
Еще пару слов про дискриминатор
Такой дискриминатор является так называемой fully-convolutional сетью — в нем нет полносвязных слоев, только свертки. Такие сети могут принимать на вход изображения любого размера, а количество слоев регулирует receptive field сети. Впервые такая архитектура была представлена в статье Fully Convolutional Networks for Semantic Segmentation.
В нашем случае генератор мапит входное изображение не на один скаляр, как обычно, а на 512 выходных картинок (уменьшенного размера), по которым уже делается вывод "real or fake". Это можно интерпретировать как взвешенное голосование по 512 патчам входного изображения. Размер патча (рецептивного поля) можно прикинуть пробросив обратно ко входу все активации. Но хорошие люди сделали утилиту, которая посчитает все за нас. Такие сети еще называют PatchGAN.
В нашем случае 3-слойный PatchGAN при входном изображении 256х256 имеет рецептивное поле 70х70, и это эквивалентно тому, как если бы мы вырезали несколько случайных патчей 70х70 из входа и по ним судили, реальная картинка пришла или сгенерированная. Контролируя глубину сети, мы можем контролировать размер патчей. Например, 1-слойный PatchGAN имеет рецептивное поле 16х16, и в таком случае мы смотрим на низкоуровневые фичи. 5-слойный PatchGAN будет уже смотреть почти на всю картинку целиком. Вот здесь Phillip Isola мне доходчиво объяснил всю эту магию. Почитайте, вам тоже должно стать понятней. Главное: полностью сверточные сети работают лучше обычных, и ими надо пользоваться.
Особенности обучения Cycle-GAN
Данные
Для начала мы попробовали решить задачу превращения лиц мужщин в женщин и наоборот. Благо, датасеты для этого есть. Например, CelebA, содержащий 200 тысяч фотографий лиц знаменитостей с бинарными метками Пол, Очки, Борода и пр.

Собственно, разбив этот датасет по нужному признаку мы получаем порядка 90к картинок мужщин и 110к — женщин. Это наши DomainX и DomainY.
Средний размер лиц на этих фото однако не очень большой (около 150х150), и вместо ресайза всех картинок к 256х256 мы привели их к 128х128. Также, для сохранения соотношения сторон, картинки не растягивались, а вписывались в черный квадрат 128х128. Типичный вход генераторов мог выглядеть так:

Perceptual Loss
Интуиция и опыт подсказали нам считать identity loss не в пространстве пикселей, а в пространстве фич предобученной VGG-16 сети. Именно этот трюк был впервые представлен в статье Perceptual Losses for Real-Time Style Transfer and Super-Resolution и широко используется в задачах Style Transfer. Логика здесь простая: если мы хотим делать генераторы инвариантыми к стилю изображений из целевого домена, то зачем считать ошибку на пикселях, если есть фичи, содержащие информацию о стиле. К какому эффекту это привело, вы узнаете чуть позже.
Процедура обучения
В целом модель получилась довольно громоздкой, учатся сразу 4 сети. Изображения по ним надо несколько раз прогнать туда-сюда, чтобы посчитать все лоссы, а потом и обратно распространить все градиенты. Одна эпоха обучения на CelebA (200к картинок 128х128) на GForce 1080 занимает порядка 5 часов. Так что особо не поэкспериментируешь. Скажу лишь, что наша конфигурация отличалась от авторской только заменой Identity Loss на Perceptual. PatchGAN'ы с большим или меньшим количеством слоев не зашли, оставили 3-слойный. Оптимизатор для всех сетей — Adam с параметрами betas=(0.5, 0.999). Learning rate по умолчанию 0.0002 и уменьшался каждую эпоху. BatchSize был равне 1, и во всех сетках BatchNorm был заменен (авторами) на InstanceNorm. Интересный момент — на вход дискриминатору подавался не последний выход генератора, а случайная картинка из буфера в 50 изображений. Таким образом, дискриминатору мог прийти образ, сгенерированный прошлой версией генератора. Этот трюк и многие другие, которые использовали авторы, перечислены в заметке Сумита Чинталы (автора PyTorch) How to Train a GAN? Tips and tricks to make GANs work. Рекомендую распечатать этот список и повесить возле рабочего места. У нас не дошли руки перепробовать все, что там есть, например LeakyReLU и альтернативные методы апсемплинга для генератора. Но повозились с дискриминатором и расписанием обучения пары генератор/дискриминатор. Это действительно добавляет стабильности.
Эксперименты
Сейчас пойдет больше картинок, вы наверное уже заждались.
Вообще обучение генеративных сетей несоклько отличается от других задач глубокого обучения. Здесь часто вы не увидите привычной вам картины идущего вниз лосса и растущей метрики качества. Оценить насколько хороша ваша модель можно только смотря на выходы генераторов. Типичная картина, которую мы наблюдали выглядела примерно так:

Генераторы постепенно расходятся, остальные лоссы чуть-чуть уменьшились, но тем не менее, сеть выдает приличные картинки и явно чему-то научилась. Кстати, для визуализации хода обучения модели мы использовали visdom, довольно простой в настройке и удобный инструмент от Facebook Research. Каждые несколько итераций мы смотрели на следующие 8 картинок:
- real_A — вход из домена А
- fake_B — real_A, преобразованная генератором A->B
- rec_A — реконструированная картинка, fake_B, преобразованный генератором B->A
- idty_B — real_A, преобразованный генератором B->A
- и 4 аналогичных изображения в обратную сторорну
В-среднем, хорошие результаты можно увидель уже после 5ой эпохи обучения. Смотрите, ошибка генераторов никак не уменьшается, но это не помешало сети превратить человека, похожего на Хинтона, в женщину. Ничего святого!

Иногда дела могут идти совсем плохо.
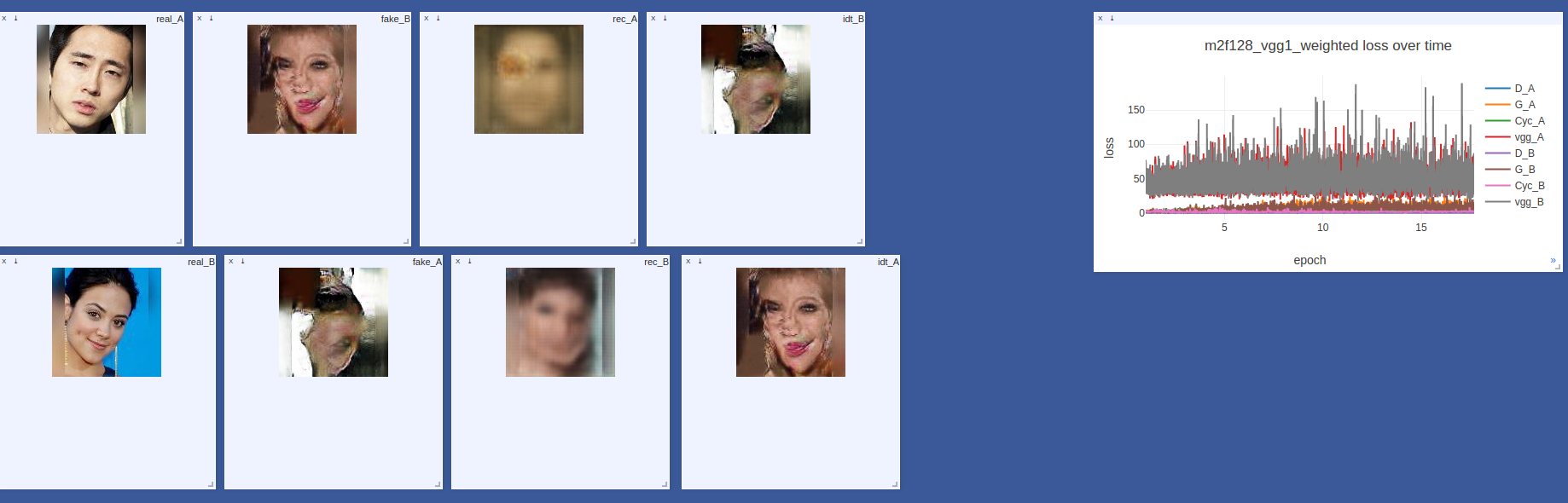
В таком случае можно нажимать Ctrl+C и звонить журналистам, рассказывать, как вы остановили искусственный интеллект.
В целом, несмотря на некоторые артефакты и низкое разрешение, Cycle-GAN на ура справился с задачей.
Смотрите сами:
Мужчины <-> Женщины

Белые <-> Азиаты


Белые <-> Черные

Вы заметили интересный эффект, который дают identity mapping и perceptual loss? Посмотрите на idty_A и idty_B. Женщина становится более женственной (больше макияжа, гладкая светлая кожа), мужщине добавляется растительность на лице, белые становятся еще белее, а черные, соттветственно — чернее. Генераторы выучивают средний стиль для всего домена, благодаря perceptual loss. Здесь прямо напрашивается создание приложения для "бьютификации" ваших фоточек. Shut up and give me your money!
Вот вам Лео:

И еще несколько знаменитостей:





Лично меня этот мужик-Джоли испугал.
А теперь, внимание, очень сложный кейс.

Увеличение разрешения
CycleGAN хорошо справился с поставленной задачей. Но получающиеся изображения имеют маленький размер и некие артефакты. Задача увеличения разрешения называется Image Superresolution. И эту задачу уже научились решать с помощью нейронных сетей. Хочу отметить две state-of-the-art модели: SR-ResNet и EDSR.
SRResNet
В статье Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network авторы предлагают архитектуру генеративной сети для задачи super-resolution (SRGAN), в основу которой положена ResNet. В дополнение к попиксельной MSE авторы добавляют Perceptual loss, используя активации предобученной VGG (видите, все так делают!) и дискриминатор, естесственно.
В генераторе используются residual блоки со свертками 3x3, 64 фильтрами, батчнормом и ParametricReLu. Для увеличения разрешения используются два SubPixel слоя.
В дискриминаторе есть 8 сверточных слоев с ядром 3х3 и увеличивающимся числом каналов с 64 до 512, активации везде — LeakyReLu, после каждого удвоения числа фич — разрешение картинки уменьшается за счет страйда в свертках. Пулинг-слоев нет, в конце — два полносвязных слоя и сигмоида для классификации. Схематично генератор и дискриминатор изображены ниже.

EDSR
Enhanced Deep Super-Resolution network это тот же SRResNet, но с тремя модификациями:
- Нет батч-нормализации. Это позволяет сократить до 40% используемой во время обучения памяти и увеличить число фильтров и слоев
- За пределами residual блоков не используется ReLu
- все resnet-блоки умножаются на коэффициент 0.1 перед их добавлением к предыдущим активациям. Это позволяет стабилизировать обучение.
Обучение
Для обучения SR-сети нужно иметь датасет изображений высокого разрешения. Определенные усилия и время пришлось потратить на то, чтобы спарсить с инстаграма несколько тысяч фотографий по хештегу #face. Но куда без этого, все мы знаем, что сбор и обработка данных это 80+% объема нашей работы.
Обучать SR-сети принято не на полных изображениях, а на патчах небольшого размера, вырезанных из них. Это позволяет генератору обучиться работать с мелкими деталями. А в рабочем режиме на вход сети можно подавать картинки любого размера, ведь это fully-convolutional сеть.
На практике EDSR, которая, якобы, должна работать лучше и быстрее ее предшественника SRResNet, не показала лучших результатов и обучалась гораздо медленнее.
В итоге для нашего пайплайна мы выбрали SRRestNet, обученную на патчах 64х64, в качестве Perceptual loss использовались 2 и 5 слои VGG-16, и дискриминатор мы вообще убрали. Ниже несколько примеров из обучающего множества.

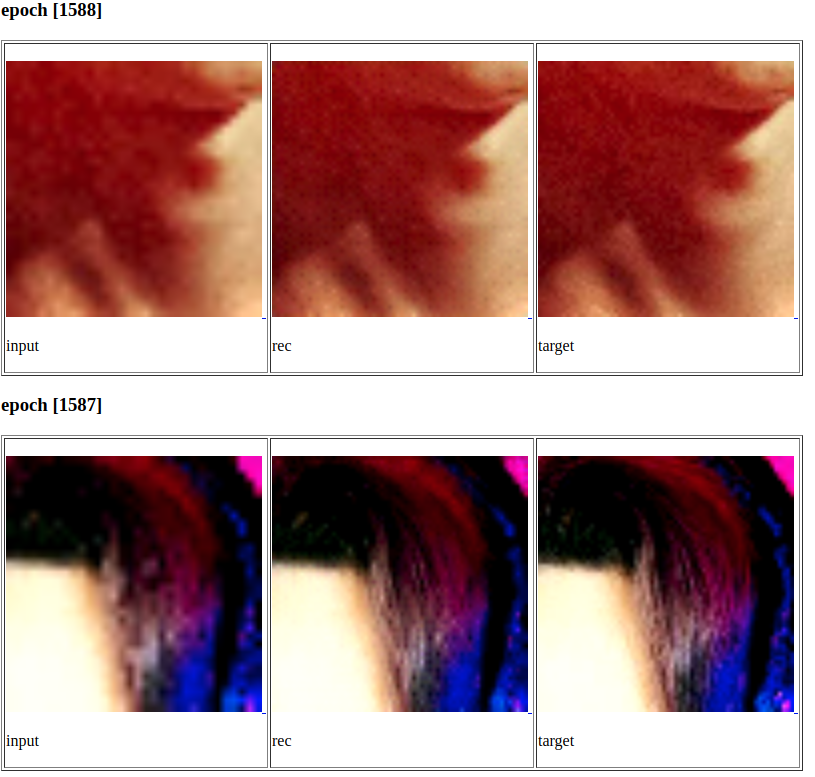
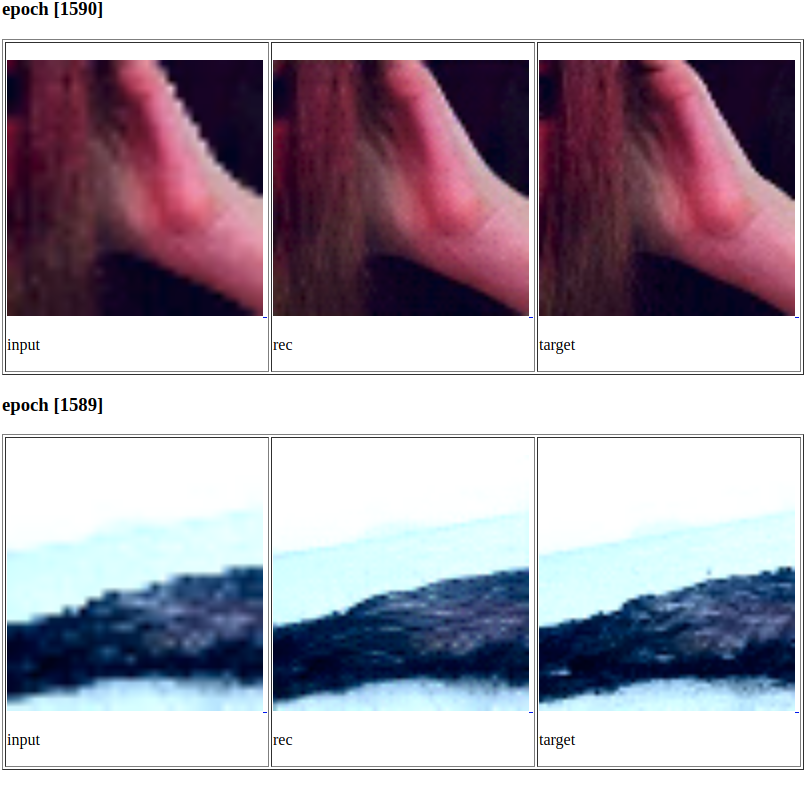
А вот так эта модель работает на наших искусственных изображениях. Не идеал, но уже неплохо.


Вставка изображения в оригинал
Даже эту задачу можно решить нейросетями. Я нашел одну интересную работу по image blending. GP-GAN: Towards Realistic High-Resolution Image Blending. Подробности рассказывать не буду, покажу лишь картинку из статьи.

Реализовать эту вещь мы не успели, отделались простым решением. Вставляем наш квадрат с трансформированным лицом обратно в оригинал, постепенно увеличивая прозрачность картинки ближе к краям. Получается примерно так:

Опять же, не идеал, но на скорую руку — ок.
Заключение
Много вещей еще можно попробовать, чтобы улучшить текущий результат. У меня целый список есть, нужно только время и побольше видеокарточек.
И вообще, очень хочется собраться на каком-нибудь хакатоне и допилить получившийся прототип до нормального веб-приложения.
А дальше уже можно думать о том, чтобы попробовать перенести ГАНы на мобильные устройства. Для этого надо пробовать разные техники по ускорению и уменьшению нейросетей: факторизация, knowledge distillation, вот это вот все. И про это у нас скоро будет отдельный пост, следите за обновлениями. До новых встреч!

