Comments 23
А как уточняющие сети могут уточнять положение суставов, если у них нет всей картинки? Если, например, картинки со спортсменами будут иметь разрешение UltraHD, то кусочек 220х220 в районе сустава особо полезной информации не предоставит. Или модель не рассчитана на такие данные? / Или я что-то не так понял?
Приведу простой пример.
Изначально есть большая картинка, на которой есть маленький человечек. Он на столько маленький, что, упихнув всю картинку в 220x220, становится еле видно его ноги и руки. Нейронная сеть на первом этапе находит их, но очень примерно. Далее же, мы уже откинем здоровенную часть исходной картинки, так как будем смотреть на кусочки вокруг предсказанных координат. Поскольку исходная картинка была большой, то на новых кусочках, упиханных в 220x220, будет отчетливее видны детали человечка. Поэтому следующий слой нейронной сети сможет сделать более точные предсказания.
Вот так это работает. Стало понятнее? Если нет, то спрашивайте.
Изначально есть большая картинка, на которой есть маленький человечек. Он на столько маленький, что, упихнув всю картинку в 220x220, становится еле видно его ноги и руки. Нейронная сеть на первом этапе находит их, но очень примерно. Далее же, мы уже откинем здоровенную часть исходной картинки, так как будем смотреть на кусочки вокруг предсказанных координат. Поскольку исходная картинка была большой, то на новых кусочках, упиханных в 220x220, будет отчетливее видны детали человечка. Поэтому следующий слой нейронной сети сможет сделать более точные предсказания.
Вот так это работает. Стало понятнее? Если нет, то спрашивайте.
Нейронка специально этому обучалась, поэтому она может распознавать по частям тела, перекрытые объекты, объекты которые не в фас — иначе чудес не будет.
Для примера здесь процесс ручной аннотации — машина наполовину перекрыта трейлером. В нейронку при обучении попадает сама эта картинка и маска(уже с полным контуром машины).
Для примера здесь процесс ручной аннотации — машина наполовину перекрыта трейлером. В нейронку при обучении попадает сама эта картинка и маска(уже с полным контуром машины).
Возьмем сложные картинки и пропустим через github.com/psycharo/cpm
Как видно, если картинка человека неполная, то нейронная сеть рисует суставы в том месте, где они должны были быть — получается полная фигня, естественно)






Как видно, если картинка человека неполная, то нейронная сеть рисует суставы в том месте, где они должны были быть — получается полная фигня, естественно)






Еще один кирпич в стену цифрового концлагеря.
Это дистанционный Бертильонаж.
Это дистанционный Бертильонаж.
Да, с такой штукой можно устроить идеальную массовую слежку. Вышел из метро — камера распознала лицо, а другая камера посмотрела как ты уходишь вдаль, ну, еще и походку записала.
И все, теперь нам подойдет домофонное качество видео, чтобы определить тебя за километр по походке — с распознаванием лиц такое не сработает, а тут прям идеально)
И все, теперь нам подойдет домофонное качество видео, чтобы определить тебя за километр по походке — с распознаванием лиц такое не сработает, а тут прям идеально)
а не будет ли точнее решена задача, если каким-нить «edge detection»-ом отделить «тело» от фона, а потом с помощью «ridig + nonrigid image registration» совместить изображение с наиболее подходящим из уже размеченных в заранее заготовленной базе?
Не могу знать наверняка. Однако решение, которое ищет позы в базе данных, кажется более ограниченным.
Можно погуглить, возможно кто-то ровно такое и делал.
Можно погуглить, возможно кто-то ровно такое и делал.
1) Сети куда эффективней сегментируют сцену на человек/не человек, чем edge detector’ы на традиционном зрении.
2) Параметризовать человека, а потом пытаться вписать параметрическую модель в сцену, минимизируя какую-нибудь ошибку репроекции — это так раньше делали, но trainable подходы, основаные на сетках работают лучше. Посмотрите на видосики того, как работает DensePose, «классикой» вряд ли получится такое качество получить.

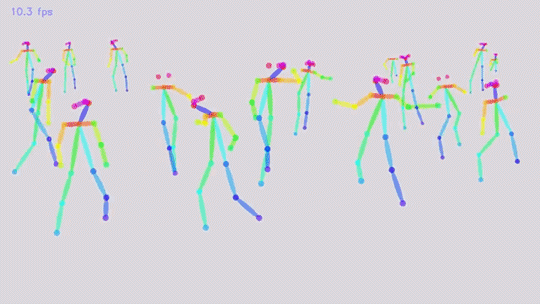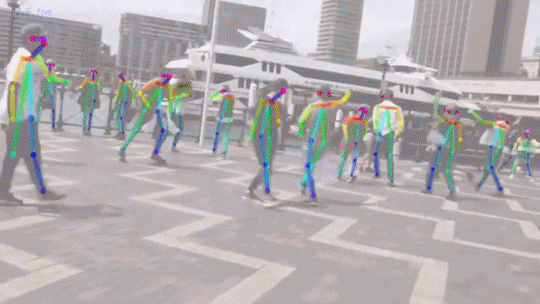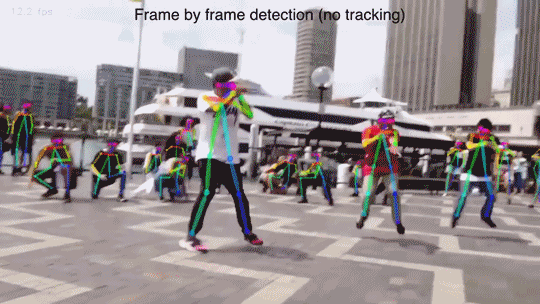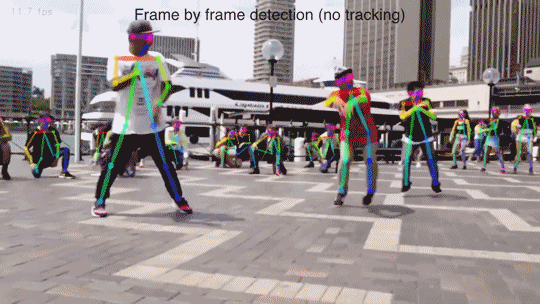
Прелесть нейронки — она за один проход найдет все объекты, и за константное время. Все что нужно — аннотированный датасет и обучить сеть.
Теперь проще нанять тыщу индусов, которые будут аннотировать картинки, чем писать алгоритмы:)
Теперь проще нанять тыщу индусов, которые будут аннотировать картинки, чем писать алгоритмы:)
в том и дело, что во время работы нейросети на результат мы получаем прелесть, а во время подготовки примеров и самого процесса обучения прелестями даже не пахнет )
Это не проблема — уволить сто программистов и нанять 10 тысяч людей, которое будут тупо смотреть на картинку и нажимать три кнопки. Потом и их заменят на нейронку) Корпорации уже держат такие отделы. Получается быстрее и результат — бриллиант.
Плюс, здесь мы решаем одну задачу — pose estimation, а с алгоритмами придется решить сто адовых задач, прежде чем мы дойдем хотя бы до выяснения позы. А у нас получается, что это как бы из коробки — мы сеть заставляем распознавать позы людей обучая на фото людей и инфе о позе — вот она и распознает сходу и людей, и позы.
Плюс, здесь мы решаем одну задачу — pose estimation, а с алгоритмами придется решить сто адовых задач, прежде чем мы дойдем хотя бы до выяснения позы. А у нас получается, что это как бы из коробки — мы сеть заставляем распознавать позы людей обучая на фото людей и инфе о позе — вот она и распознает сходу и людей, и позы.
А датчик расстояния ( как в кинекте) дает что то алгоритму или он не подходит?
Датчики глубины нужны для работы с облаком точек(Point cloud) это немного другая задача, здесь говорится о распознавании частей тела в координатах xy.
Т.е. в кинект его от балды прикрутили?
Нет, как я выше сказал это другая задача. Поясню, в случае когда мы захватываем изображение или видео поток с камеры мы имеем двумерное изображение в координатах xy и его мы обрабатываем как изображение соответственно на выходе мы тоже получим плоские координаты, это как раз тот случай что описывается в статье. Если стоит задача получить положение частей тела в пространстве (xyz), то нужно получить глубину и существует несколько способов это сделать например «склеивание» двух изображений на разном фокусном расстоянии, использование инфракрасных датчиков(как в кинекте или intel realseance), но в любом случае нужно трехмерное представление объекта. При любом выбранном способе мы получаем облако точек и условно говоря нейросеть уже в этом случае нужно обучать по объемным датасетам, а не по изображениям. Датчик расстояния для способа описанного в статье ни к чему в общем.
Sign up to leave a comment.
Детектирование частей тела с помощью глубоких нейронных сетей