
Василий Сошников (Mail.Ru)
Сегодня я вам расскажу о том, как создавать nginx-модули и, что самое главное, попытаюсь ответить, зачем это надо делать. Это надо далеко не всегда, но есть определенный круг задач, который можно решить на стороне nginx.

Вот краткий наш план. Первое – я введу в курс дела, расскажу об архитектуре nginx. Второе – я попытаюсь сразу ответить на некоторые часто задаваемые вопросы, потому что очень часто ко мне подходят люди, работающие в Mail.ru, и задают одни и те же вопросы, и я решил их просто в небольшой FAQ вывести. Прямо сразу, чтобы было лучшее понимание, что будет дальше.
Самая интересная часть – это анатомия. Я расскажу о том, как создавать nginx-модули, какие есть типы, немножечко расскажу о подводных камнях, но без всех тонкостей, потому что, сами понимаете, nginx – это очень сложная технология, там 1000 нюансов, 1000 тонкостей. И попробую ответить на вопросы: «Зачем их создавать?, «Зачем мы их создаем в Mail.ru?» и «Зачем я их создавал, работая не в Mail.ru?».
Также вчера вечером я решил написать примеры, буквально шаблоны nginx-модулей, которые вы можете просто взять и воспользоваться. В конце я дам ссылочку. Потому что мне мои товарищи сказали, что без этого моя презентация неполная.
Начнем с части «Введение» и часто задаваемых вопросов.
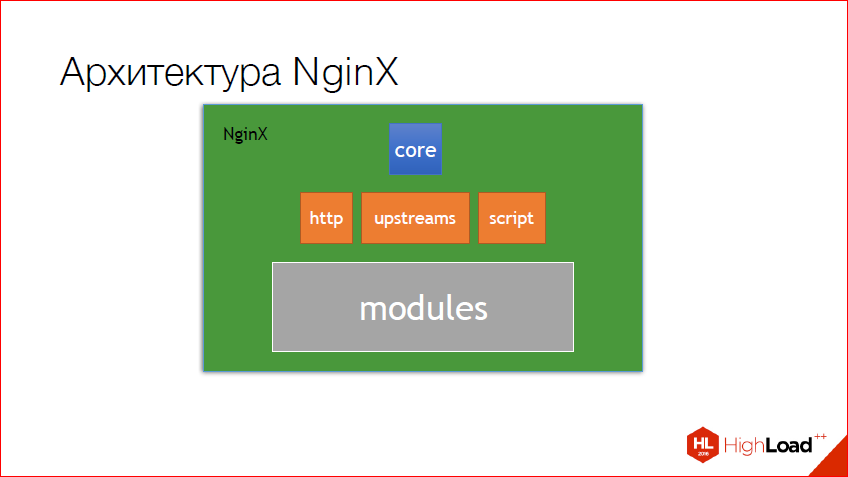
Первое – архитектура nginx. У меня он все время ассоциируется с матрешкой. На самом деле так оно и есть. Есть некое core, в котором находится вся базовая API, из которой можно слепить все, что хочешь. В данном случае был слеплен http, из http были слеплены upstreams и также скриптовый движок. И мэйловский движок, который работает с мэйлом, тоже сделан на базе core. Модули, которые уже пишутся для http, сделаны на http core. Т.е. сами понимаете, это такая матрешка, есть база – это core, есть слои ниже, ниже. И причем, чем ниже слой, тем, как правило, больше всяких модулей. Сами понимаете, для http полно есть модулей, и все они базируются как раз на http core, ну и возможностях nginx.

И вот один из самых часто задаваемых вопросов – это о модели памяти nginx. Nginx использует pool. Это надо помнить всегда. И надо брать правильный pool. Очень многие люди делают частую ошибку и стараются прибить свои буфера к connection’у, а connection в режиме keep-alive может жить очень долго. Сами понимаете, что такие буфера будут скапливаться до тех пор, пока жив connection, и nginx может просто утечь. Поэтому надо всегда выбирать правильный pool. Если мы хотим просто сохранить какой-то буфер на время жизни request’а, логичней прибить его к request’у, а не к connection’у.
Также надо помнить, что эти pool’ы периодически чистятся и у них есть свои life-time’ы. Они, в принципе, все достаточно логичны, connection живет в рамках connection’а, request – в рамках request’а, config всегда жив и периодически домерживается. Там также есть много других контекстов, но о них чуть дальше.
Также старайтесь использовать внутри nginx всегда nginx’овские локаторы. Ссылочка на API, находится наверху. Почему надо использовать именно их? а) они быстрее; б) их проще дебажить, если вы используете Valgrind для nginx. Правда, в жизни не дебажил буферы nginx’а. Не приходилось, потому что pool, если все правильно сделать и все рассчитать, работает отлично.
Но бывает такая ситуация, например, у меня совсем недавно была, когда мне пришлось использовать стандартный маллок, аллок, реаллок. Почему? Потому что в nginx нет реаллока. Это большая проблема. Если у вас есть какая-то библиотека, которая использует реаллок, то вы просто не можете подменить эти функции аллокации в библиотеке. Вот, пример хороший – яджил. В принципе, я придумал, как это сделать, если кто-то знаком с паскаль-строками, можно просто на 4 байтика больше выделять и прибивать еще размер в этот кусок памяти. И использовать для реаллокации обычный nginx’овский аллок.
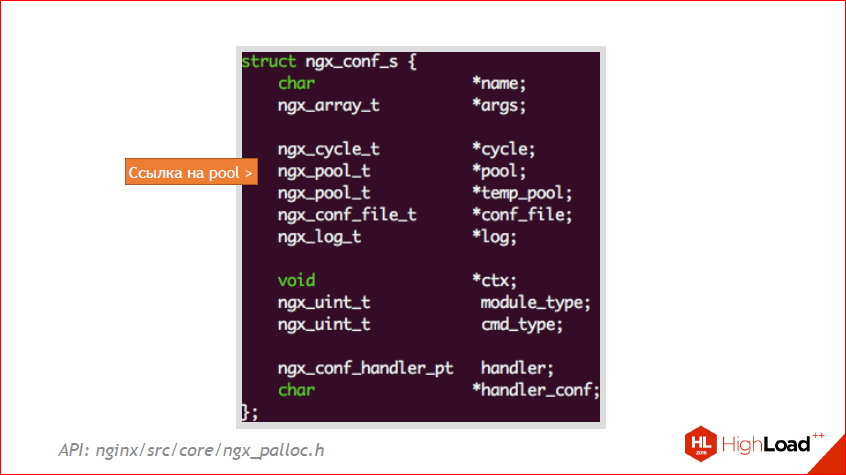
А это пример, это nginx_conf_s. Это его внутренняя структура. Здесь можно увидеть как раз эту ссылочку на pool. В данном случае, если вы будете выделять что-то в рамках конфига, у вас будет жить до тех пор, пока жив конфиг. А в nginx конфиг живет всегда, пока вы ручками его не очистите. Но там есть разные конфиги, об этом тоже чуть дальше. Так что надо помнить, надо всегда посмотреть на структуру, которую вы хотите прибить, и приблизительно понять, где она живет. И через какое-то время у вас все это будет на автомате, но вначале надо за этим очень четко следить.

А теперь очень коротко о том, что есть в nginx, и как его структура в репозитории устроена. На верху API, а внизу – что там есть. Первое – в nginx очень много структур данных, и старайтесь использовать именно их, потому что: а) они уже знают о nginx pool’ах; б) это максимально нативный способ его использовать с nginx-типами данных, потому что в nginx почти все типы данных, это либо typedef системных типов, либо свои собственные структуры.
Также в nginx core можно найти ОS с API, естественно завернутый в фасад. Это может пригодиться, если вы будете писать уже не свой http-модуль на nginx, а, скажем, какой-то свой TCP-модуль, такое тоже возможно. Потому что http сделан на основе core и его можно расширять, при желании, как угодно. Также там можно найти state-машину, которая отвечает за полинг файлового дескриптора, и много других полезных функций, как логирование, работа со скриптами и с конфигами.

А теперь самое интересное и самое наболевшее, а точнее, самое неизвестное. Это то, как устроены nginx-модули, какие типы бывают. Поскольку я ограничен во времени, я решил рассказать только о трех основных. И то о самом, наверное, интересном – это об апстримах. Вкратце, потому что действительно это тема для отдельного доклада.

Поэтому сегодня мы рассмотрим только 3 основных модуля – это Handlers, Filters и Proxies. Proxies вкратце. На самом деле там много других есть типов модулей, как я и сказал, потому что http, по сути, тоже модуль, на основе core. Но в такие нюансы мы заходить не будем, потому что это очень долго и, опять же, это тема для отдельного доклада.

Все в nginx подчинено одному паттерну. Это паттерн Chain of responsibility. Другими словами, ваш реквест от пользователя проходит через модуль http, модуль http запускает какую-то последовательность – chain модулей. И если они все отработали хорошо, то пользователь получит хороший ответ, если нет, то получится ошибка. Ближайшая аналогия – эта строчка кода:

Я подумал, это будет идеальная аналогия, надеюсь, я прав. Всем понятна эта строчка? Это, по сути, баш. Мы грепаем что-то, достаем первую строку по делиметру; делаем сорт и подсчет слов. Принцип работы nginx-модуля очень схож с этим. Т.е. если пайп сломается, у вас отлетит весь этот chain, и в баше вы получите ошибку. Также там есть сигналы и т.д. У nginx все то же самое есть, поэтому ко всем nginx-модулям надо относиться именно так.
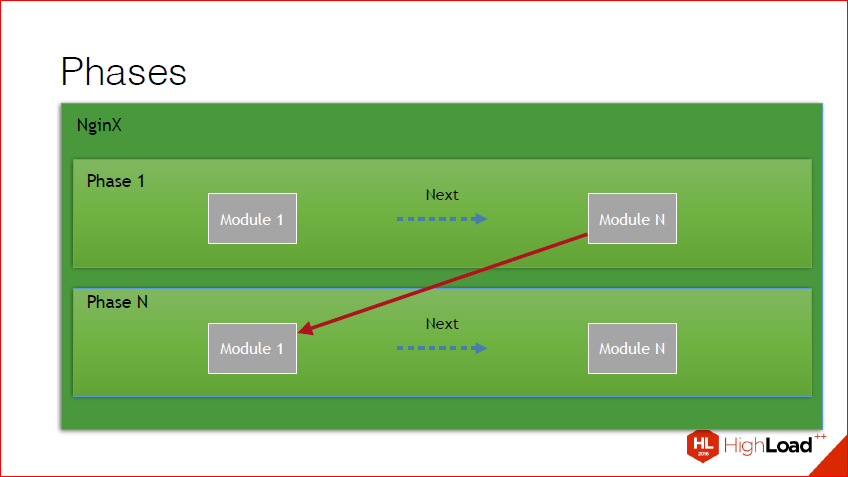
Также, если копнуть чуть глубже, можно обнаружить, что помимо того, что это chain, этот chain разбит еще на фазы. В nginx есть очень много фаз, каждая фаза вызывается в определенный момент времени при определенных условиях, проходятся все хэндлеры внутри фазы, после чего идет переключение уже с результатом выполнения той фазы на другую фазу. В принципе, этот рисунок это иллюстрирует. У нас есть некий набор модулей в фазе, проходим, получаем результат, идем на следующую фазу.
И вот те фазы, которые сейчас в nginx_http доступны:
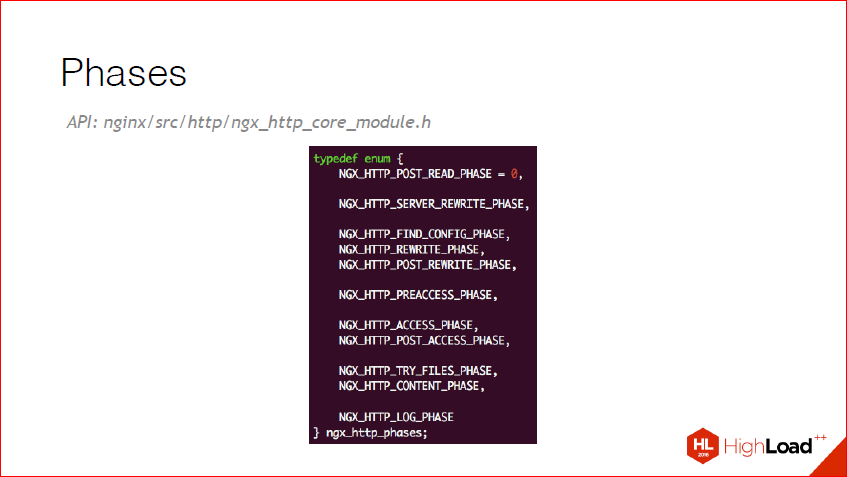
Они самоговорящие, я думаю, вопросов тут не возникает. Т.е. server_rewrite, поиск конфига, rewrite обычный, content_phase.

А теперь приступим непосредственно к тому, как разрабатываются модули. Именно к тем вещам, которые обязательно надо сделать для каждого модуля.

Первое – любой модуль в nginx начинается с конфига. В nginx есть определенный способ именования таких структур для вашего модуля и для любых других модулей и даже для внутренних nginx. Это использовать такое соглашение по именованию, т.е. ngx_http показывает, что мы сейчас для http чего-то делаем. Дальше имя вашего модуля – это может быть что угодно. И соответственно, один из типов конфига – main, server, loc – и _conf.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Все помнят nginx_config? Этот как раз оттуда идет. Есть main – это самый глобальный скоуп, есть сервер, бета-сервер, и есть location. Location if – это тоже считайте location, только специфический. На самом деле эти конфиги и эти структуры могут мержится на разных этапах, т.е. вам ничто не мешает сделать эту структуру, чтобы она присутствовала и в main, и в сервере, и в location и в location if, ничего. Все, что надо – это написать одну функцию и задать бит-маску определенную. Об этом чуть позже.
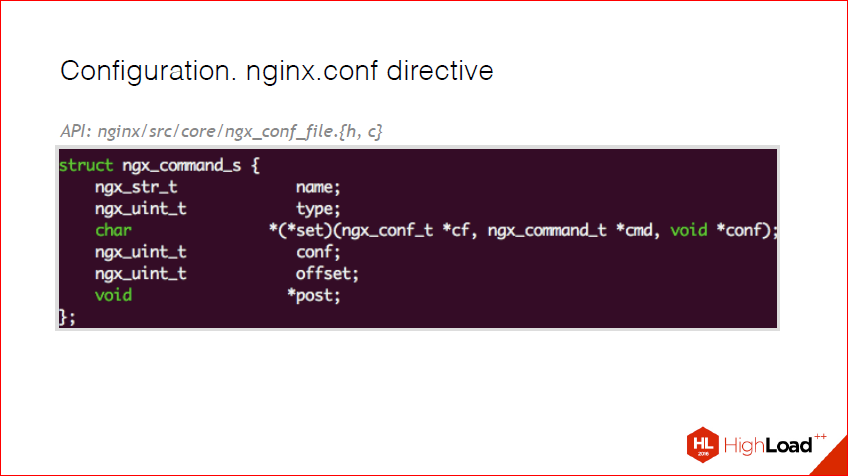
Директивы. В nginx-конфиге присутствуют директивы. И, соответственно, когда вы разрабатываете свой модуль, вы должны понимать, что вы должны дать какую-то ручку администраторам и пользователям. В nginx для этого есть специальная структура – это ngx_command_s. Я все ссылочки на API размещаю здесь, так что вы потом можете просто посмотреть, там ничего сложного нет. И здесь, по сути, все, что присутствует – это имя. Имя – это то, как в nginx config будет представлена ваша директива. Это тип, и он и есть та маска, чем является эта директива. Т.е. присутствует она в location, в main conf, server conf. Callback существует, чтобы распарсить значение этой переменной. Есть большой набор уже готовых callback’ов. К примеру, если мы используем ngx_string, и нам нужно просто строчку сохранить, то мы не должны реализовывать этот callback, а взять уже готовый от nginx. И дальше несколько системных полей, о них я расскажу на следующем слайде.
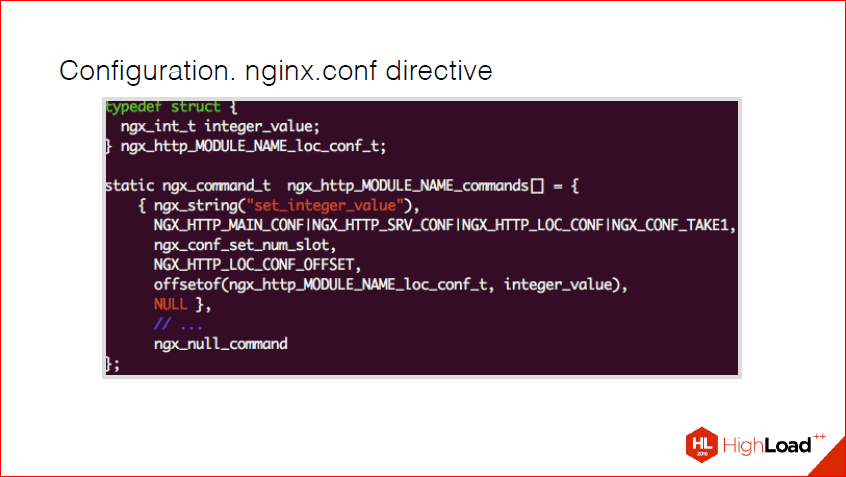
Допустим, мы создаем некий модуль под названием MODULE_NAME. Вот, у нас появляется некая переменная, обычный integer, и мы хотим перебросить этот integer в config. Все, что нам надо – это объявить такую структурку в этом массиве. Если бы у нас было много разных переменных, у нас было бы много элементов этого массива. И вот, как я и говорил, эта маска, здесь в данном случае, вот этот битмап говорит, что принимается один аргумент. Здесь о том, что эта директива может присутствовать в location кофиге, сервер конфиге, и в main конфиге. Если бы я еще захотел в location if иметь, мне бы пришлось добавить еще один кусок этой маски.
Соответственно, это nginx-функция, она существует для парсинга интов обычных. Это специально для экономии времени, чтобы каждый раз эту функцию не делать. offsetof просто говорит о том, где располагается это поле в нашей структуре, это старый добрый C-шный хак. Я на нем заострять внимание не буду, потому что, по сути, в данном контексте его надо принять как данное. Т.е. смысловой нагрузки дополнительной он не несет.
И заканчивается такой массив обычным ngx_null_command – маркер о том, что массив кончился. Потому что в nginx почти все, что вы объявляете внутри своего модуля – это статик, и оно экстернится где-то там, потому что в nginx сейчас есть два способа, как разрабатывать модули – это либо скомпилировать вместе с nginx, либо load модуль, но об этом чуть позже. В данном случае надо помнить, что у вас пока все будет статик, и то, что нужен конечный маркер, потому что он идет по этому массиву до конца, до этого маркера.
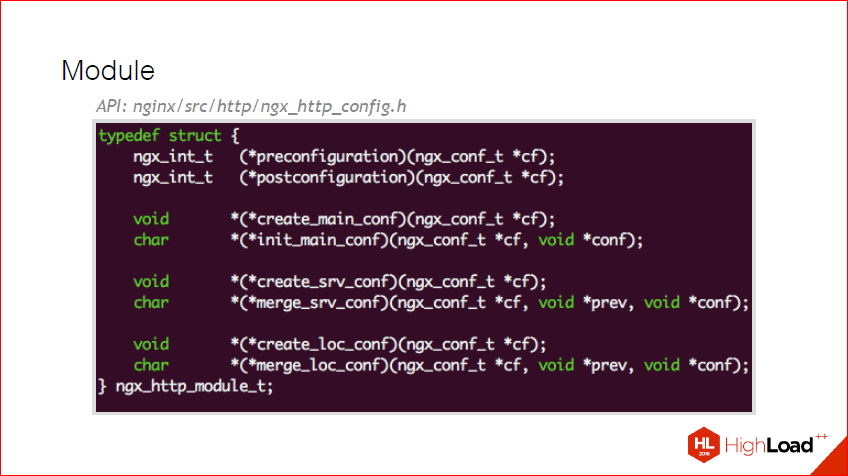
Вот, мы создали какие-то директивы, хорошо у нас все это работает, но теперь нам надо сделать install внутри nginx, создание конфига и его merge. Для этого существует такая структурка как ngx_http_module_t. Она тоже достаточно простая, тут есть несколько этапов инсталляции, это preconfiguration, это до того, как происходит какая-либо конфигурация postconfiguration, а также несколько других функций, о них на следующем слайде поподробней.

Мы, допустим, хотим, чтобы то, что мы объявили ранее, наша директива мерджилась на локэйшне правильно. Все, что для этого надо сделать – это в ту структуру забить два наших callback’а, которые мы сами объявили внутри нашего модуля, и используя ngx_palloc преаллоцировать наш конфиг. И сделать его мердж. В nginx, если это примитивный тип, который понимает nginx, уже есть большой набор функций, чтобы мерджить любые переменные. Если это ваш собственный какой-нибудь тип, скажем, у вас какая-то очень хитрая строчка, которую нужно пропарсить, скажем xml, и вы хотите его в отдельной структуре писать, то вам надо будет функцию и мерджа, и сета такой переменной описать самим и передать ее в callback. И на этапе мерджа конфига в этой функции можно сделать какие-нибудь дополнительные проверки и сказать, что произошла ошибка такая-то. Здесь также можно чего-нибудь залогировать и еще дополнительно сделать.

Все, у нас мерджится конфиг, мы получили директивы. Теперь самое интересное – как нам сказать nginx, что появился наш модуль? Для этого существует ngx_module_t – это специальный тип. И, опять же, объявляется статикой внутри нашего объектника, т.е. обычной переменной. Описываешь, передаешь контекст, эти команды, которые мы сформировали, и также можно дополнительные callback’и для более гибкого управления. Т.е. допустим, если мы хотим какое-то специфическое действие на инит мастер, на выход из нашего мастера и т.д. Тут, в принципе, думаю, тоже все понятно, вопросов нет. Просто дополнительные ручки для управления. К примеру, зачем это нужно? Давайте подумаем, если наш модуль использовал шаред мемори, мы бы безусловно захотели бы при выходе и убийстве потока ее разлочить. Для такого и существуют эти ручки – для дополнительных действий.
Исходя из этого пункта, думаю, все поняли, либо уже догадываются, как создавать nginx-модули. Все, что надо сделать – это, по сути, описать несколько статических переменных и объявить несколько callback’ов и все. И наш модуль подцепится. Но, это еще далеко не все, теперь самый главный нюанс – как добавить хэндлер в фазы и как сделать фильтры. Как раз, чтобы у нас на какие-то события внутри nginx вызывались наши функции.

И об этом сейчас и будем говорить. О хэндлерах и о фильтрах. Это две разные сущности.
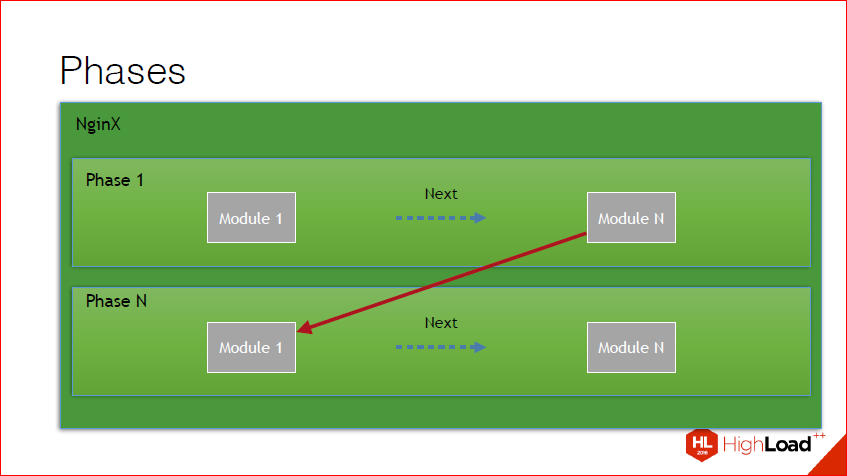
Я немного вернусь к фазам на всякий случай. Фазы вызывают определенный момент времени, вызывают некий chain, заканчивают chain и идут к следующей фазе, и так до тех пор, пока все фазы не пройдены, либо фаза не прервалась. И как раз хэндлеры работают с фазами. Т.е. что такое хэндлер? Вы можете забиндить любую функцию на любую из этих фаз. И сейчас я вам покажу, как это делается.

Как вы помните, у нас при объявлении модуля мы могли передать дополнительные ручки. Допустим, здесь на postconfiguration, т.е. когда у нас уже отработали директивы, мы получили переменные, заполнили их, мы должны сделать, если мы хотим прибиндить какую-то фазу, добавить функцию при инициализации и, соответственно, в этой функции описать следующее – что мы достаем, как видите, контент фаз из nginx core конфига, потому что это все в http core живет. И просто добавить туда свою функцию обычным array_push’ем. И все, у нас эта функция вызовется на контенте.
Другими словами, что такое контент фаз? Когда у нас кто-то возвращает ответ, у нас дергается контент фаз, и мы можем там сделать, что угодно, скажем, мы можем посчитать количество слов в ответе от сервера или дополнительно сжать его каким-то своим алгоритмом. И каждый раз, когда у нас кто-то возвращает ответ, будь то файл, будь то еще что-то, у нас вызовется эта функция. В ней мы можем уже поработать с http-реквест, выдернуть данные, которые нам нужны, добавить чего-то туда, либо, наоборот, удалить. И так можем делать с каждой фазой. Главное помнить, что все фазы вызываются в разное время. Другими словами, если вам надо поработать с контентом, то не надо добавлять свой хэндлер в лог-фазу. Потому что лог-фаза происходит, когда нужно чего-нибудь записать, грубо говоря. Там можно, наоборот, какую-то статистику дополнительную собирать, если вам интересно в такой фазе. А в такой фазе нужно обрабатывать контент.
Кстати, хороший пример вспомнил. Последний раз, когда я контент-фазу делал, мне надо было сгенерировать картинку на лету для счетчика у топ.mail.ru. Вот хороший пример. Т.е. я просто не делал ничего, я просто генерировал эту новую картинку в зависимости от query-параметров, в зависимости от id счетчика и т.д.

Фильтры. Это немного другая сущность. Что такое фильтры? Помните нашу chain? Фильтры, по сути, это обычный односвязный список каких-то фильтров.

И все, что нужно сделать, чтобы добавить в конкретный фильтр свой хэндлер – это просто взять статическую переменную nginx, которая называется top_header_filter, добавить туда свой хэндлер и все. В данном случае это у нас header_filter идет, и ваш хэндлер будет вызываться каждый раз в какой-то момент времени на этапе обработки header’ов.
Хороший практический пример. Нам нужно выставить свои куки для каунтера и проверить. Все, что надо сделать это добавить новый header-фильтр и проверить header’ы, которые поступают и как-то преобразовать в нормальную куку. Это хороший пример, зачем это используется.
Еще хороший пример, зачем это используется. Все знают такую директиву, как add_header –стандартную nginx-директиву. Она использует эти header’ы.
Т.е. она может делать, что угодно с header’ами http. И вся инсталляция выглядит всегда так. На самом деле, тут еще боди есть, я про него забыл. У него та же идеология, тот же список, но срабатывает он на этапе обработки контента.

И самое интересное. Наша структура реквест. Если вы будете когда-нибудь разрабатывать для nginx, эта структура станет вашим лучшим другом. Вы будете часто ходить в этот код, возможно, вы им чего-нибудь забиндите, чтоб быстро на нее прыгнуть. Она огромная, ее надо знать. Там очень много нюансов. Поэтому, если вы хотите чего-то разрабатывать, познакомьтесь с этой структурой, там нет ничего сложного, там просто надо прочитать и понять. Она в себе хранит конекшн, хэдеры, которые пришли от пользователя, которые уйдут пользователю, она хранит в себе все хэндлеры-обработчики, свой собственный pool, который работает на этом реквесте. Также она хранит body. Более того, когда вам надо вычитать гарантированно целые боди, либо послать гарантировано… потому что nginx все пайпит, по сути, он работает все время как пайп, он может не накопить до конца. Если вам надо чего-нибудь послать точно гарантировано, вам надо вызвать специальные функции и использовать конкретный реквест. Точнее, конкретную структуру реквеста, которая вам пришла в ваш хэндлер.

И тут мы подошли к самому интересному и самому сложному моменту nginx – это chain buffer. В nginx любая работа с любым буфером – это chain buffer. Это, по сути, односвязный список буферов. Он очень хитрый, он может быть в файле, это может быть shared memory, то может быть read only memory, это может быть temporary memory. Я подумал, что углубляться не буду в chain buffer, потому что там очень много нюансов. Главное, что надо о нем знать, что у вас сообщение может прийти, но вообще тело, не в одном куске, оно может прийти по буферам, маленьким-маленьким кусочками. Это особенно важно, когда вы разрабатываете upstream. Потому что в upstream вам может прийти по 4К или вообще по байтику, если вам надо это все запарсить, вам надо будет делать какой-то хитрый потоковый парсер, который работает именно с chain’ми. Я в примерах в read me ссылочку дам позже, я скинул примерно два таких upstream, кому будет интересно, как именно реализовать внутри nginx потоковый парсер. Потому что тут есть еще такое важное правило – nginx нельзя блокировать. У вас один воркер. Даже если там есть ThreadPool, им редко, кто пользуется, если вы этого воркера надолго заблокировали, вы потеряли очень много rps. Об этом тоже надо помнить всегда.
И вернемся опять, после этого лирического отступления, к Chain buffer. В принципе, вся структура вот как выглядит:

Т.е. у нас есть позиция, last, если это файл – file_pos, таги и куча флагов. И, в принципе, все эти комменты сейчас взяты из nginx. О них надо помнить. Представьте себе, в ваш фильтр или ваш хэндлер, в что угодно пришел кусок памяти, который помечен, что его нельзя модифицировать, то такой контент вы не имеете право модифицировать. Вы должны его скопировать себе, изменить его, как вы хотите, и отдать дальше. Поэтому эти флаги надо постоянно проверять.
Или еще вот хороший пример. Многие модули, которые я написал, не работают с chain buffer если там стоит галочка in_file. Потому что я хотел, было такое требование, чтобы это работало быстро. Если, не дай Бог, nginx начинает тянуть из файла, из своего кэша или еще откуда-нибудь, то это все умирает. Поэтому в таком случае, очень логично проверять chain buffer на то, что он не in_file, если вам это не нужно, и писать админу в лог: «Друг, выкрути размер буфера, пожалуйста». Это тоже хорошая структура, с которой вы должны подружиться.
А вот пример, это я из своего upstream-модуля.

Я написал 6 модулей для nginx. Только один opensource, и я из него код показал. То, о чем я рассказал. Т.е. здесь, правда, используется upstream chain buffer, а не реквест буфера, но логика та же. Что просто проверять надо флажки и на эти флажки надо как-то определенно реагировать. Это пример кода, который сейчас у многих работает. Здесь, в частности tp_transcode – это потоковый парсер, который я долго и мучительно делал.

Вот мы и дошли до Proxies. О проксях, как я и сказал, или upstream, или load-балансерах, я не знаю как их правильно охарактеризовать, потому что они все похожие с т.з. реализации. Поэтому расскажу только саму идею, зачем это существует. Но без деталей, потому что там очень много нюансов.

В принципе, что такое upstream? Это proxy pass. Что делает proxy pass? По сути, все, что он делает, это в chain-режиме отдает данные бэкендам, может на них балансировать по разным правилам. Ничего не мешает вам прикрутить туда любой протокол. Предположим, у нас есть какой-то демон, который работает на протобуфе, ничего не мешает в nginx сделать на него балансировку и с преобразованием протокола. Т.е. на вход – http, https с каким-то там json или даже сырым протобуфом. И вы можете его преобразовать в чистый протобуф и отдать application server’у либо в любой другой протокол. В этом вся идея у upstream.
И, по сути, upstream – это готовое API внутри nginx, которое позволяет: а) легко конфигурировать такую балансировку по ключу, скажем, еще каким-то критериям; б) делать бэкапы, т.е. в случае, если у вас отвалились все upstream’ы, он пойдет по другому url. И очень много разных ручек для upstream’ов. Сколько максимально фейлов может быть, какие таймауты и т.д. И все доступно из коробки.
Я пример не успел дописать, как делать upstream’ы, но я его закончу и выложу по ссылочке, которую я дам. Надеюсь, я понятно объяснил, что такое upstream и что с ним можно сделать.
Также, помимо того, если вам не нужно преобразований в другой протокол, вы можете их использовать для кастомной балансировки. Правда, на мой взгляд, сейчас это не требуется, потому что есть OpenResty, и там есть отличная директиваbalancer_by_lua, т.е. балансировку можно написать еще на lua с любой кастомной логикой, я не знаю, хоть в редиску ходи, правда, это все сдохнет под нагрузкой, но такое сделать можно. Сдохнет-сдохнет. Проверял. Я пробовал, у меня взлетело CPU в потолок, возможно, из-за lua-строк, я подозреваю, потому что там балансировка по url идет, когда я пробовал.

И самый больной вопрос, на нем были сломаны тонны копий, тысячи админов рыдали, тысячи разработчиков матерились на админов. Это деплойминг.

Я вначале о сборке забыл сказать. Здесь показан новый способ сборки. В nginx он недавно изменился. Я старый не стал показывать, и специально о нем не написал ни слова. Я просто взял из своего репозитория, как выглядит типичная конфигурация этого conf, nginx, чтобы добавить модуль. По сути, это баш, или шелл. Просто описывается несколько переменных на шелле и все. Вы можете даже прилинковать С++ runtime сюда вместо этой статической библиотеки, если хотите. В этом проблем никаких нет. Более того, скажу по-честному, я линковал в nginx ++ runtime. В этом проблем нет. Главное, чтобы эксепшн в nginx не проник из плюсов, потому что nginx разнесет в щи. Потому что Си не очень дружит с плюсовыми эксепшенами. Здесь просто описываем, что и где лежит.

А дальше просто заполняем этими переменными, что я писал выше, nginx-переменные, и вызываем автомодуль. Автомодуль находится внутри nginx-репозитория, там его можно увидеть. Это новый способ сборки и надо пользоваться им, потому что старого способа сборки скоро не станет, как только все переедут на свеженький nginx.

Доставка. Вот она больная тема, и я ее ждал долго и упорно.
На протяжении, наверное, трех лет мы все время просто собираем свой nginx с кучей модулей и просто его деплоим. Главное – в отдельное от системных nginx’ов путей. Это очень важно, потому что какой-нибудь админ спросонья захочет nginx со статусом поставить, напишет apt-get install nginx и полностью кладет твой сервер. Поэтому это очень важно.
Плюс у нас есть несколько проектов, где есть несколько совершенно разных nginx-модулей. Так получилось, потому что это разные проекты внутри mail.ru. И не знаю, почему это не объединить, там нет противоречий, просто так сложилось. И мы до того дошли, что просто дробим по имени проекта в пути, куда это все кладем. Это боль и страдание на самом деле, но сейчас оно так.
Второй путь, который появился относительно недавно, он, правда, пока нерабочий – это в nginx можно грузить SO’шки. Почему он нерабочий? Потому что nginx проверяет фингерпринт этой SO’шки бинарной. И чтобы он принял этот модуль, у вас большое количество флагов сборки nginx и вашего модуля должно совпадать.
Сейчас я придумал способ, как это решить. Вот у нас есть, допустим, система Debian, и там мы можем вытащить информацию, с какими флагами nginx был собран. И ничего не мешает свой модуль собрать с такими же флагами, а потом запаковать. Я еще не пробовал поставить это на рельсы, но сейчас думаю в таком направлении, потому что грузить модули проще. Но оно сейчас и больнее, потому что есть проблема с фингерпринтом. Вроде как, парни пытаются это решить, если верить их wiki.
И второй вариант, он менее популярен, по крайней мере, внутри mail.ru, может, в реальности он популярный. Это Docker. Люди берут обычный nginx, обычные пути и просто делают из него docker image, кладут на сервер и там запускают. Я не знаю, насколько это распространено, но у нас люди этим пользуются.

И теперь, наверное, самая провокационная вещь – зачем их создавать?

Самый ответ в лоб – это потому, что всегда появляются новые технологии, новые хотелки. Если вы хотите внести свою часть в контрибуцию nginx, хоть и сбоку, вы можете добавить какую-то классную фичу в nginx или внести новую технологию внутри nginx. Скажем, появится http 3.0, это будет новый модуль.

Вот, это мой аргумент, на котором заканчивались часто многие споры «Зачем нужен nginx-модуль?». Это то, что многие используют – nginx ReverseProxy – чтобы балансировать в какой-нибудь плюсы, которые все, что делают, это указывают nginx или клиенту, как работать. Т.е. в такой ситуации логичней, когда нет ни состояний, ничего, вместо ReverseProxy, написать nginx-модуль, особенно в высоконагруженных проектах. Конечно, если у вас application хранит состояния какие-то, это уже тяжелее, но, опять же, тут надо смотреть на задачу. И поэтому мы перешли к решению бизнес-задач.

Вот типичный пример, это были мои 3 предпоследних модуля для топ mail.ru. До этого у нас там был обычный http-сервер, написанный руками, никто не знает, когда он был написан, поддерживать его было почти нереально, постоянно ломался, были проблемы и т.д. И было волевое решение – просто взять и переписать всю логику на nginx. Сделать несколько модулей. Модуль, который раздает куки, модуль, который формирует JS-файл, который отдает счетчика, и два дополнительных image-модуля специальных для этого проекта. 4 модуля даже получилось.
Что он делает? По сути, он принимает эти данные от пользователя, формирует строчку и асинхронно это логирует на диск. После чего эти логи поднимаются каунтером и обсчитываются. Когда я сделал эти модули на nginx, у нас лучше стало по CPU, как выяснилось. Наконец-то завелся SSL правильно, потому что до этого он неправильно работал. Тяжело все-таки сделать кошерный SSL внутри своего приложения. Это больно. Особенно его проверять.
Так вот, хороший пример, статистика-аналитика. Идеально вписывается. Состояний нет, есть куки, все ваши состояния у пользователя, как правило, хранятся. Есть какой-то атомик инкремент, если у вас такая логика, это достаточно просто делается.

Рекламные системы. Вообще идеальный кейс. Тут либо OpenResty, либо прямо на nginx-модуле писать, зависит от ваших потребностей. Потому что это классика жанра, я даже туда добавлять не буду. Там вообще почти состояний нет, вам нужна какая-то мапка или шаред мемори между nginx и вашим демоном, которые будут уже связи иметь и все. Вообще, идеальный случай. Но я не уверен насчет OpenResty, если честно.

И конвертация протоколов. Признаемся, люди, у нас у всех http, у нас у всех браузеры и т.д. И когда мы пишем кучи бинарного протокола, у нас все это выливается, что где-то есть http, то зачем нам лишние прослойки? Можно же просто upstream написать, который будет преобразовывать http в протокол X. Все достаточно просто и на самом деле это не так сложно. Это на самом деле моей работы по вечерам 2 недели. Я думаю, у вас примерно столько же на это уйдет. Причем, это был еще тяжелый протокол со странными хэндшейками.
И вот ссылка на примеры, которые обещал, там 3 примера, немножечко ссылочек на пару upstream’ов. Там очень примитивный код, буквально в 100 строчек кода, там все то, о чем я говорил, плюс она делает дополнительную логику. К примеру, ворд каунт на боди при фильтрации, подмена контента и т.д. Т.е. это можно скопировать и даже побаловаться. Там есть специальный make файл, там описана инструкция как это собрать. Я постараюсь расширить это и написать комментарий в коде.
Контакты
→ github
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем Highload++, а конкретно — секции «Бэкенд».
На наш взгляд — отличным дополнением этого материала будет доклад "Проксирование HTTP-запросов web-акселератором", который смогут услышать через три недели посетители HighLoad++ Junior и прочитать читатели Хабра через несколько месяцев.
- Как работает HTTP-проксирование без кэша;
Что такое персистентные соединения и чем они отличаются от HTTP keep alive;
Как, когда и сколько соединений может устанавливать HTTP-акселератор с апстримом;
Что становится с запросами, которые ждут очереди на отправку в соединение с апстримом, но апстрим «из коробки» и сбрасывает соединения каждые 100 запросов;
Что такое HTTP pipelining, и как им пользуются современные HTTP-акселераторы;
Что такое неидемпотентные запросы, и почему нужно о них беспокоиться.
