
Проектирование систем потоковой аналитики и потоковой обработки данных имеет свои нюансы, свои проблемы и свой технологический стек. Об этом мы поговорили в очередном открытом уроке, прошедшим накануне запуска курса «Data Engineer».
На вебинаре обсудили:
- когда нужна потоковая обработка;
- какие элементы есть в СПОД, какие инструменты мы можем использовать для реализации этих элементов;
- как построить свою систему анализа кликстримов.
Преподаватель — Егор Матешук, Senior Data Engineer в MaximaTelecom.
Когда нужна потоковая обработка? Stream vs Batch
Прежде всего, следует разобраться, когда нам нужна потоковая, а когда пакетная обработка. Давайте поясним сильные и слабые стороны этих подходов.
Итак, минусы пакетной обработки (batch):
- данные доставляются с задержкой. Поскольку у нас есть некий период вычислений, то на этот период мы всегда отстаём от реального времени. И чем больше итерации, тем сильнее мы отстаём. Таким образом, мы получаем задержку по времени, что в некоторых случаях критично;
- создаётся пиковая нагрузка на железо. Если мы очень много вычисляем в пакетном режиме, у нас по окончании периода (дня, недели, месяца) наблюдается пик нагрузки, ведь посчитать нужно много всего. К чему это приводит? Во-первых, начинаем упираться в лимиты, которые, как известно, не бесконечны. В результате система периодически работает на пределе возможностей, что нередко заканчивается сбоями. Во-вторых, так как все эти job’ы начинаются одновременно, они конкурируют и рассчитываются довольно медленно, то есть на быстрый результат рассчитывать не приходится.
Но у пакетной обработки есть и плюсы:
- высокая эффективность. Углубляться не будем, так как эффективность связана и с компрессией, и с фреймворками, и с применением колоночных форматов и т. п. Факт заключается в том, что пакетная обработка, если брать количество обработанных записей на единицу времени, будет эффективнее;
- простота разработки и поддержки. Вы можете обрабатывать какую-нибудь часть данных, тестируя и пересчитывая по мере необходимости.
Плюсы потоковой обработки данных (streaming):
- результат в режиме реального времени. Мы не ждём конца каких-либо периодов: как только к нам приходят данные (пусть даже совсем небольшой объём), мы можем сразу их отпроцессить и передать дальше. То есть результат по определению стремится к реал-тайму;
- равномерная нагрузка на железо. Понятное дело, что есть суточные циклы и т. д., однако нагрузка всё равно распределяется на весь день и получается более равномерной и предсказуемой.
Главный минус потоковой обработки:
- сложность разработки и поддержки. Во-первых, тестироваться, управлять и получать данные несколько тяжелее, если сравнивать с batch. Вторая сложность (на самом деле, это самая основная проблема) связана с откатами. Если job’ы не отработали, и произошёл сбой, то очень трудно уловить именно тот момент, где всё сломалось. И решение проблемы потребует от вас больше усилий и ресурсов по сравнению с пакетной обработкой.
Итак, если вы думаете о том, нужны ли вам стримы, ответьте для себя на следующие вопросы:
- Действительно ли нужен real-time?
- Много ли потоковых источников?
- Критична ли потеря одной записи?
Рассмотрим два примера:
Пример 1. Аналитика запасов для ритейла:
- выкладка товара не меняется в реал-тайме;
- данные чаще всего доставляются в пакетном режиме;
- потери информации критичны.
В этом примере целесообразнее использовать batch.
Пример 2. Аналитика для веб-портала:
- скорость аналитики определяет время реакции на проблему;
- данные поступают в реальном времени;
- потери небольшого количества информации о пользовательской активности допустимы.
Представьте, что аналитика отражает, как посетители веб-портала себя чувствуют, используя ваш продукт. Например, вы выкатили новый релиз и вам нужно понять в течение 10-30 минут, всё ли в порядке, не сломались ли какие-нибудь пользовательские фичи. Допустим, пропал текст с кнопки «Заказать» — аналитика позволит быстро среагировать на резкое падение числа заказов, и вы сразу поймёте, что нужно откатываться.
Таким образом, во втором примере лучше использовать стримы.
Элементы СПОД
Инженеры обработки данных захватывают, перемещают, доставляют, преобразовывают и хранят эти самые данные (да-да, хранить данные — это тоже активный процесс!).
Следовательно, чтобы построить систему потоковой обработки данных (СПОД), нам будут нужны следующие элементы:
- загрузчик данных (средство доставки данных до хранилища);
- шина обмена данными (нужна не всегда, но в стримах без неё никак, т. к. вам потребуется система, через которую вы будете обмениваться данными в реал-тайме);
- хранилище данных (как же без него);
- ETL-движок (необходим, чтобы делать различные фильтрации, сортировки и прочие операции);
- BI (чтобы выводить результаты);
- оркестратор (связывает весь процесс воедино, организовывая многоэтапную обработку данных).
В нашем случае мы рассмотрим простейшую ситуацию и сфокусируемся только на первых трёх элементах.
Инструменты для обработки потоков данных
На роль загрузчика данных у нас есть несколько «кандидатов»:
- Apache Flume
- Apache NiFi
- StreamSets
Apache Flume
Первый, о ком поговорим — это Apache Flume — инструмент для транспортировки данных между различными источниками и хранилищами.

Плюсы:
- есть практически везде
- давно используется
- достаточно гибкий и расширяемый
Минусы:
- неудобная конфигурация
- сложно мониторить
Что касается его конфигурации, то она выглядит примерно так:

Выше мы создаём один простейший канал, который “сидит” на порту, берёт оттуда данные и просто их логирует. В принципе, для описания одного процесса это ещё нормально, но когда у вас таких процессов десятки, конфигурационный файл превращается в ад. Кто-то добавляет некие визуальные конфигураторы, но зачем мучиться, если есть инструменты, которые делают это из коробки? Например, те же NiFi и StreamSets.
Apache NiFi
По сути, выполняет ту же роль, что и Flume, но уже с визуальным интерфейсом, что большой плюс, особенно когда процессов много.
Пару фактов о NiFi
- изначально разработан в АНБ;
- сейчас поддерживается и развивается Hortonworks;
- входит в состав HDF от Hortonworks;
- имеет особую версию MiNiFi для сбора данных с устройств.
Система выглядит примерно следующим образом:
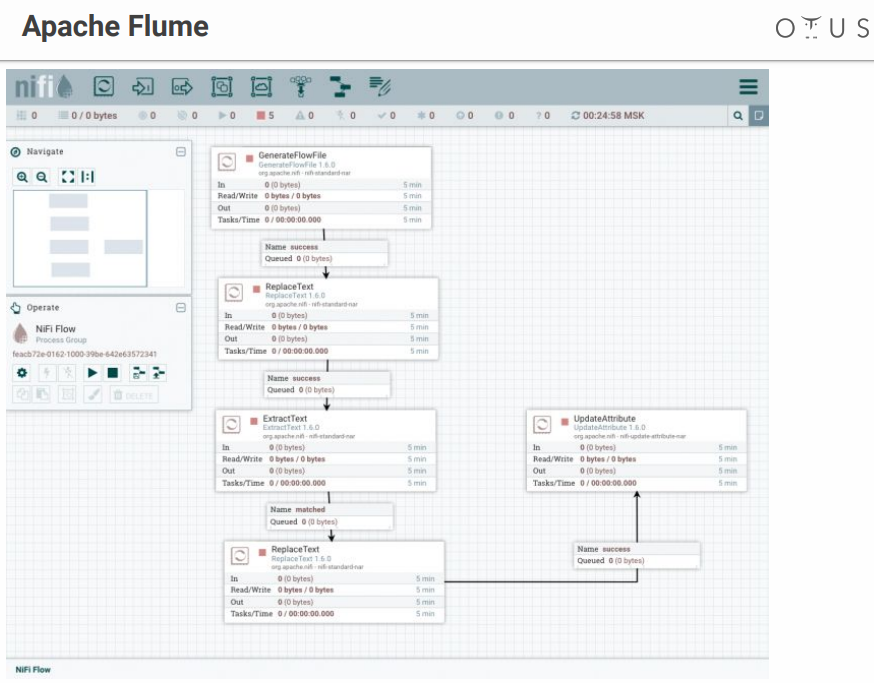
У нас есть поле для творчества и этапы обработки данных, которые мы туда накидываем. Есть много коннекторов на все возможные системы и т. д.
StreamSets
Это тоже система управления потоком данных с визуальным интерфейсом. Она разработана выходцами из Cloudera, легко устанавливается в виде Parcel на CDH, имеет особую версию SDC Edge для сбора данных с устройств.
Состоит из двух компонент:
- SDC — система, выполняющая непосредственно обработку данных (free);
- StreamSets Control Hub — центр управления несколькими SDC с дополнительными возможностями по разработке пайплайнов (paid).
Выглядит примерно так:

Неприятный момент — у StreamSets есть как бесплатная, так и платная части.
Шина обмена данными
Теперь давайте разберёмся, куда мы эти данные будем заливать. Претенденты:
- Apache Kafka
- RabbitMQ
- NATS
Apache Kafka — наилучший вариант, но если у вас в компании есть RabbitMQ или NATS, а вам нужно добавить чуть-чуть аналитики, то разворачивать Kafka с нуля будет не очень выгодно.
Во всех остальных случаях, Kafka — отличный выбор. По сути, это брокер сообщений с горизонтальным масштабированием и огромной пропускной способностью. Он отлично интегрирован во всю экосистему инструментов для работы с данными и выдерживает большие нагрузки. Обладает универсальнейшим интерфейсом и является кровеносной системой нашей обработки данных.
Внутри Kafka делится на Topic — некий отдельный поток данных из сообщений с одинаковой схемой или, хотя бы, с одинаковым назначением.
Чтобы обсудить следующий нюанс, нужно вспомнить, что источники данных могут немного различаться. Очень важен формат данных:

Отдельного упоминания заслуживает формат сериализации данных Apache Avro. Система использует JSON для определения структуры данных (схемы), которые сериализуются в компактный бинарный формат. Следовательно, мы экономим огромное количество данных, а сериализация/десериализация происходит дешевле.
Вроде бы всё неплохо, но наличие отдельных файлов со схемами порождает проблему, так как нам нужно между разными системами обмениваться файлами. Казалось бы, это просто, но когда вы работаете в разных отделах, ребята на другом конце могут что-нибудь поменять и успокоиться, а у вас всё поломается.
Чтобы не передавать все эти файлы на флешках, дискетах и наскальных рисунках, существует специальный сервис — Schema registry. Это сервис для синхронизации avro-схем между сервисами, которые пишут и читают из Kafka.

В терминах Kafka продюсер — это тот, кто пишет, консьюмер — тот, кто потребляет (читает) данные.
Хранилище данных
Претенденты (на самом деле вариантов много больше, но возьмем лишь несколько):
- HDFS + Hive
- Kudu + Impala
- ClickHouse
Прежде чем выбрать хранилище, вспомним, что такое идемпотентность. Википедия говорит, что идемпоте́нтность (лат. idem — тот же самый + potens — способный) — свойство объекта или операции при повторном применении операции к объекту давать тот же результат, что и при первом. В нашем случае процесс потоковой обработки должен быть построен так, чтобы при повторной заливке исходных данных результат оставался корректным.
Как этого добиться в стриминговых системах:
- выявить уникальный id (можно составной)
- использовать этот id для дедупликации данных
Хранилище HDFS + Hive не даёт идемпотентности для потоковой записи “из коробки”, поэтому у нас остаются:
- Kudu + Impala
- ClickHouse
Kudu — хранилище, подходящее для аналитических запросов, но с Primary Key — для дедупликации. Impala — SQL-интерфейс к этому хранилищу (и нескольким другим).
Что касается ClickHouse, то это аналитическая база данных от Yandex. Её главное назначение — аналитика на таблице, наполняемой большим потоком сырых данных. Из плюсов — есть движок ReplacingMergeTree для дедупликации по ключу (дедупликация предназначена для экономии места и может оставлять дубликаты в некоторых случаях, нужно учитывать нюансы).
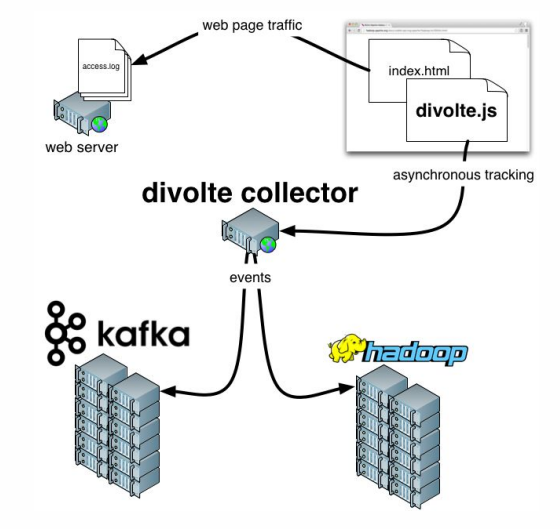
Остаётся добавить несколько слов про Divolte. Если помните, мы говорили о том, что некоторые данные нужно захватывать. Если вам нужно быстро и на коленке организовать аналитику для какого-нибудь портала, то Divolte — отличный сервис для захвата пользовательских событий на веб-странице через JavaScript.
Практический пример
Что попытаемся сделать? Попробуем построить пайплайн, чтобы в реальном времени собирать Clickstream-данные. Clickstream — виртуальный след, который пользователь оставляет во время нахождения на вашем сайте. Будем захватывать данные с помощью Divolte, а писать их в Kafka.

Для работы нужен Docker, плюс потребуется клонировать следующий репозиторий. Всё происходящее будет запущено в контейнерах. Чтобы согласованно запустить сразу несколько контейнеров будет использоваться docker-compose.yml. Кроме того, есть Dockerfile, собирающий наш StreamSets с определёнными зависимостями.
Также есть три папки:
- в clickhouse-data будут писаться данные clickhouse
- ровно такая же папочка (sdc-data) у нас будет для StreamSets, где система сможет хранить конфигурации
- третья папка (examples) включает в себя файл с запросами и файл с конфигурацией пайплайна для StreamSets

Для запуска вводим следующую команду:
docker-compose upИ наслаждаемся тем, как медленно, но верно запускаются контейнеры. После запуска мы можем перейти по адресу http://localhost:18630/ и сразу же потрогать Divolte:

Итак, у нас есть Divolte, который уже получил какие-то события и записал их в Kafka. Попробуем их высчитать с помощью StreamSets: http://localhost:18630/ (пароль/логин — admin/admin).

Чтобы не мучиться, лучше импортировать Pipeline, назвав его, к примеру, clickstream_pipeline. А из папки examples импортируем clickstream.json. Если всё ок, увидим следующую картину:

Итак, мы создали connection к Кафке, прописали, какая Кафка нам нужна, прописали, какой топик нас интересует, потом выбрали те поля, которые нас интересуют, потом поставили слив в Кафку, прописав, в какую Кафку и какой топик. Отличия в том, что в одном случае, Data format — это Avro, а во втором — просто JSON.
Идём дальше. Мы можем, например, сделать превью, которое захватит в реальном времени из Кафки определённые записи. Далее всё записываем.
Выполнив запуск, увидим, что у нас в Кафку летит поток событий, причём это происходит в реал-тайме:

Теперь можно сделать для этих данных хранилище в ClickHouse. Чтобы работать с ClickHouse, можно использовать простой нативный клиент, выполнив следующую команду:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouseОбратите внимание — в этой строке указана сеть, к которой нужно подключаться. И в зависимости от того, как у вас называется папка с репозиторием, название сети у вас может отличаться. В общем случае команда будет следующей:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouseСписок сетей можно посмотреть командой:
docker network lsЧто же, осталось всего ничего:
1. Сначала «подпишем» наш ClickHouse на Кафку, «объяснив ему», какого формата данные там нам нужны:
CREATE TABLE IF NOT EXISTS clickstream_topic (
firstInSession UInt8,
timestamp UInt64,
location String,
partyId String,
sessionId String,
pageViewId String,
eventType String,
userAgentString String
) ENGINE = Kafka
SETTINGS
kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'clickstream',
kafka_group_name = 'clickhouse',
kafka_format = 'JSONEachRow';
2. Теперь создадим реальную таблицу, куда будем класть итоговые данные:
CREATE TABLE clickstream (
firstInSession UInt8,
timestamp UInt64,
location String,
partyId String,
sessionId String,
pageViewId String,
eventType String,
userAgentString String
) ENGINE = ReplacingMergeTree()
ORDER BY (timestamp, pageViewId);3. А потом обеспечим связь между этими двумя таблицами:
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream
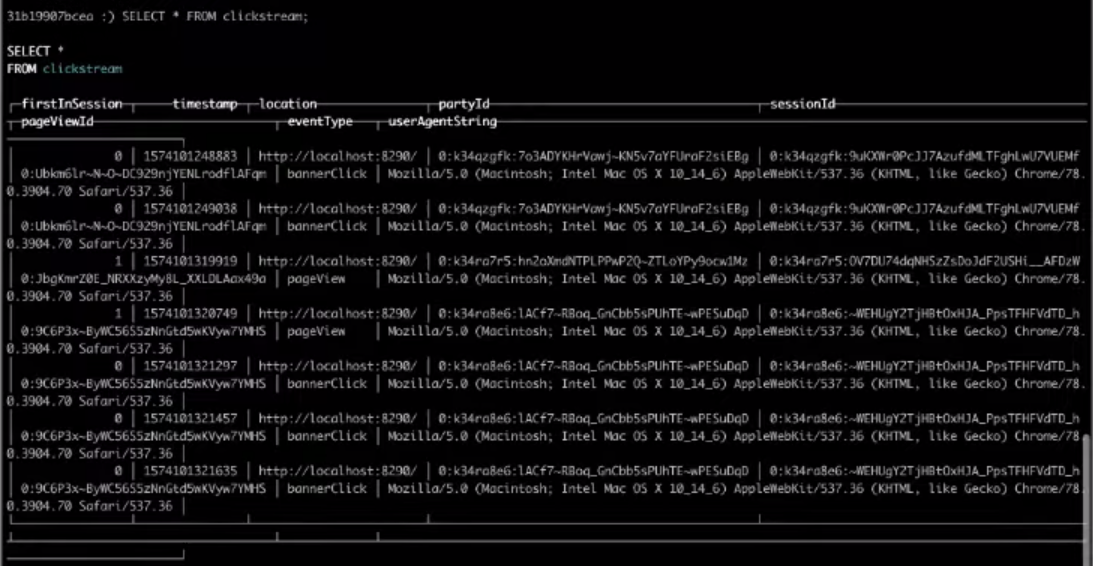
AS SELECT * FROM clickstream_topic;4. А теперь выберем необходимые поля:
SELECT * FROM clickstream;В итоге выбор из целевой таблицы даст нужный нам результат.
Вот и всё, это был простейший Clickstream, который можно построить. Если хотите выполнить вышеописанные шаги самостоятельно, смотрите видео целиком.
