Здравствуйте все!
На волне непрекращающихся дискуссий о Hadoop и прочих больших данных мы не могли пройти мимо замечательной публикации Джерри Овертона, рассказывающей о профессиональном подходе к анализу больших данных в компаниях любого размера. Понятные картинки, предоставленные автором, а также краткий парад технологий, без которых современному Data scientist'у не обойтись. Поэтому пусть статья и начинается с (ошибочной!) посылки: «Не читайте книги по Data Science», она заслуживает публикации в блоге нашего издательства.
Если среди уважаемых читателей найдутся те, кто захочет обсудить Hadoop и прочие технологии из его экосистемы, а также литературу по специфическим алгоритмам, затронутым автором — давайте побеседуем об этом в комментариях.
Мой опыт работы в качестве исследователя данных совсем не напоминает истории, которые можно прочитать в книгах и блогах. Там рассказывают о моих коллегах, которые трудятся в компаниях-сверхгигантах. Они кажутся супергероями, пишут автоматизированные (считай, одушевленные) алгоритмы, которые выдают непрекращающийся поток инсайтов. Я читал об исследователях данных, хитроумных как агент Мак-Гайвер, способных спасти положение, извлекая полезные данные практически из всего, что их окружает.
Решения для работы с данными, разрабатываемые в моей команде, не столь критичны, чтобы возводить ради них колоссальную инфраструктуру в масштабах всей компании. Гигантские инвестиции в сверхэффективную автоматизацию и управление производством в нашем случае просто не окупились бы. С другой стороны, наши продукты влияют на важные решения, принимаемые на предприятии, и, что особенно важно, наши решения масштабируются. Мы не можем себе позволить постоянно все делать вручную, и нам нужны эффективные механизмы, чтобы делиться результатами нашей работы с десятками тысяч людей.
На свете много «самых обычных исследователей данных», таких, как мы. Мы более организованны по сравнению с хакерами, но, в отличие от всяких супергероев, мы обходимся без «секретного штаба». Мы просто собираемся и устраиваем мозговой штурм, в ходе которого обсуждаем наилучшие способы создания надежного кода. В этой статье изложена квинтэссенция наших бесед; я попытался собрать наши знания, отсечь все лишнее и кратко представить наши наработки в одной публикации.
Как стать профессионалом
Исследователь данных должен обладать навыками программиста — но не всеми, которыми пользуется в работе программист. Я называю исследователей данных, обладающих основополагающими навыками разработки информационных продуктов, «программистами-датологами». Профессионализм – не просто навык, который можно подкрепить сертификатом или приобрести на опыте; я имею в виду профессионализм как образ действий.
Профессиональный программист-исследователь умеет сам себя исправлять при разработке решений для работы с данными. Он знает общие стратегии, позволяющие распознавать, где его продукт явно подкачал, и как исправить проблему.
Профессиональный исследователь данных должен уметь превратить гипотезу в программу, которая позволила бы проверить эту гипотезу. Такая специализация уникальна для всей IT-сферы, поскольку неповторимы проблемы, с которыми приходится иметь дело исследователям данных. Важнейший вызов связан с тем, что наука о данных по природе своей экспериментальна. Ее задачи зачастую сложны, а сами данные беспорядочны. Стратегии решения многих подобных проблем пока не проработаны, путь к решению заранее не известен, а возможные решения лучше всего поддаются объяснению в виде последовательности мелких этапов. Далее я опишу базовые стратегии, укладывающиеся в организованный и продуктивный метод проб и ошибок. Проблема раскладывается на небольшие этапы, опробуются варианты решений, по ходу работы вносятся исправления.
Мыслить как профессионал
Чтобы стать профессиональным программистом-исследователем данных, не достаточно знать общих принципов структурирования систем. Нужно представлять, как спроектировать решение, уметь распознавать, когда решение у вас есть, а также различать те случаи, в которых вы не полностью понимаете собственное решение. Последний пункт критически важен, чтобы вы могли корректировать собственную работу. Когда вы распознаете принципиальные пробелы в собственном подходе, то сами можете их заполнить. Чтобы подобрать такое решение проблемы, связанной с данными, которое можно корректировать по ходу работы, я предпочитаю придерживаться базовой парадигмы «смотреть, видеть, представлять, показывать».
Этап 1: Смотреть. Для начала сориентируйтесь на местности. Сделайте предварительное исследование, ознакомьтесь со всеми компонентами, которые могут быть связаны со стоящей перед вами задачей. Рассмотрите проблему в самом широком контексте. Постарайтесь разобраться с максимальным количеством аспектов поставленной задачи, приведите в порядок разрозненные фрагменты информации.
Этап 2: Видеть. Возьмите вышеупомянутые разрозненные фрагменты и обобщите их в виде абстракций, соответствующих элементам паттерна классной доски. На данном этапе вы преобразуете элементы проблемы в осмысленные технические концепции. Видение проблемы — важнейший подготовительный шаг на пути к созданию жизнеспособного проекта.
Этап 3: Вообразить. Опираясь на технические концепции, которые вы уже видите на данном этапе, вообразите реализацию, которая позволит перейти из исходного состояния к целевому. Если вообразить реализацию не удается, то, вероятно, вы что-то упустили при рассмотрении проблемы.
Этап 4: Показать. Объясните полученное решение сначала себе самому, затем коллеге, потом начальнику и, наконец, потенциальному пользователю. Для них требуется минимальная формализация — не более, чем нужно для донесения вашей идеи. Допустим, это можно сделать при беседе за кофе, по почте, во время недолгой прогулки. Это самая важная регулярная практика, помогающая профессиональному исследователю данных научиться корректировать собственную работу. Если в вашей стратегии есть изъяны, то они, вероятно, проявятся, как только вы попробуете ее объяснить. Именно на данном этапе можно устранить пробелы и убедиться, что вы можете досконально объяснить как проблему, так и ее решение.
Проектировать как профессионал
Работы по созданию и выпуску продукта для работы с данными разнообразные и сложные, однако, большинство из того, чем вам придется заниматься, соответствует определенному звену в «логистической цепочке больших данных», описанной Алистером Кроллом.
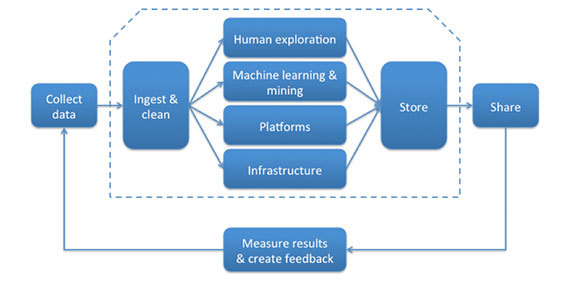
Поскольку продукты для работы с данными эксплуатируются в соответствии с определенной парадигмой (в реальном времени, в пакетном режиме или в соответствии с какой-либо гибридной моделью), то вы, вероятно, будете участвовать как в поддержке вышеупомянутой логистической цепочки, так и в реализации парадигмы этого продукта: выполнять прием и удаление пакетно-обновляемых данных, строить алгоритм для анализа данных в реальном времени, организовывать совместное использование данных и т.д. К счастью, архитектурный паттерн «классной доски» подобен базовому чертежу, помогающему качественно реализовать любой из этих сценариев на уровне программирования.
Паттерн классной доски
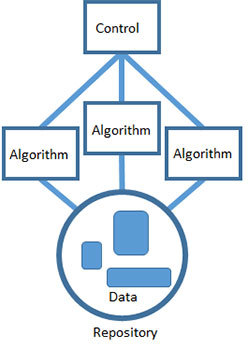
Согласно паттерну классной доски проблемы решаются таким образом: задача делится на множество мелких самодостаточных подзадач, а затем для каждой из них подбирается свое решение. Каждая подзадача приводит вашу гипотезу в более удобоваримый вид, а для некоторых таких гипотез уже известны готовые решения. Каждая задача постепенно улучшает решение и, вероятно, ведет к жизнеспособному итогу.
Наука о данных располагает множеством инструментов, у каждого из которых есть свои уникальные достоинства. Продуктивность — важная штука, и я предпочитаю, чтобы ребята из моей команды сами подбирали себе именно те инструменты, с которыми они лучше всего умеют обращаться. При применении паттерна классной доски вполне допустимо выстраивать продукты для работы с данными на основе сразу нескольких разных технологий. Взаимодействие между алгоритмами организуется через разделяемый репозиторий. Каждый алгоритм может получить доступ к данным, обработать их в качестве ввода и записать результаты обратно в репозиторий, где они вновь могут послужить вводом для другого алгоритма.
Наконец, работа всех алгоритмов координируется при помощи единого контрольного компонента, представляющего эвристику, выбранную вами для решения задачи. Контроль — это реализация стратегии, которую вы разработали. Это наивысший уровень абстрагирования и понимания проблемы, причем он воплощается при помощи технологии, которая может взаимодействовать со всеми другими алгоритмами и задавать порядок их выполнения. Контроль можно автоматизировать, задействовав для этого, к примеру, задачу cron или скрипт. Можно выполнять его вручную – пусть этим занимается человек, который будет выполнять различные шаги в нужном порядке. Но самое важное – это общая стратегия решения проблемы. Именно на уровне контроля можно окинуть взглядом все это решение от начала и до конца.
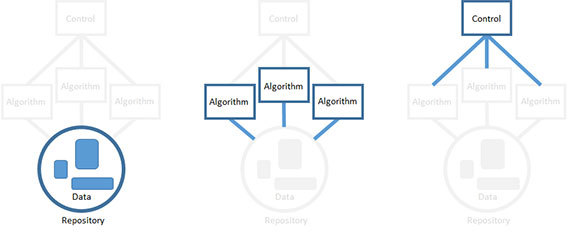
Такой базовый подход оправдал себя в создании софтверных систем, предназначенных для решения нечетких, гипотетических проблем на основании неполных данных. Самое важное, что таким образом мы можем продвигаться к решению нечеткой задачи, работая с четкими, детерминированными компонентами. К сожалению, не гарантируется, что ваши усилия действительно позволят решить проблему. Чем раньше вы узнаете, что идете по тупиковому пути – тем лучше.
Профессиональная сборка
Вы не обязаны собирать элементы вашего продукта в строго определенном порядке (то есть, сначала создать репозиторий, затем алгоритмы и, наконец, контроллер). Профессионалы организуют сборку в порядке снижения технического риска. То есть, сначала реализуется тот элемент, для которого такой риск наиболее высок. Элемент может представлять технический риск по множеству причин. Наиболее рискованной может быть компонент, находящийся под наивысшей нагрузкой, либо тот, который вы хуже всего понимаете.
Можно создавать компоненты в любом порядке, сосредоточившись на единственном из них, а для остальных оставляя заглушки. Например, если вы решите начать с разработки алгоритма, сделайте формальную реализацию вводимых данных, а также определите место, куда будет временно записываться вывод алгоритма.
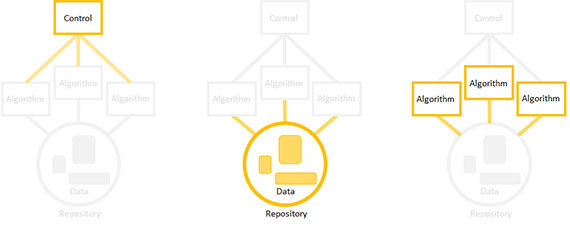
Далее реализуйте продукт в таком же порядке: сначала самые рискованные элементы. Сосредоточьтесь на одном элементе, для остальных поставьте заглушки, заменить их всегда успеете.
Ключ к успеху — организовать сборку и запуск небольшими порциями. Пишите алгоритмы мелкими частями, которые вы понимаете, добавляйте в репозиторий по одному источнику данных за раз, а каждый этап контроля должен захватывать один шаг алгоритма. Ваша цель — продукт для работы с данными, который будет работоспособен всегда, а полнофункционален — только к моменту окончательной реализации.
Инструменты для профессионала
Настоящему профессионалу не обойтись без набора качественных инструментов. Ниже приведен список самых распространенных языков и технологий, а также ссылки, по которым вы можете познакомиться с каждой из тем подробнее.
Визуализация
Контроль версий
Языки программирования
Экосистема Hadoop
На волне непрекращающихся дискуссий о Hadoop и прочих больших данных мы не могли пройти мимо замечательной публикации Джерри Овертона, рассказывающей о профессиональном подходе к анализу больших данных в компаниях любого размера. Понятные картинки, предоставленные автором, а также краткий парад технологий, без которых современному Data scientist'у не обойтись. Поэтому пусть статья и начинается с (ошибочной!) посылки: «Не читайте книги по Data Science», она заслуживает публикации в блоге нашего издательства.
Если среди уважаемых читателей найдутся те, кто захочет обсудить Hadoop и прочие технологии из его экосистемы, а также литературу по специфическим алгоритмам, затронутым автором — давайте побеседуем об этом в комментариях.
Мой опыт работы в качестве исследователя данных совсем не напоминает истории, которые можно прочитать в книгах и блогах. Там рассказывают о моих коллегах, которые трудятся в компаниях-сверхгигантах. Они кажутся супергероями, пишут автоматизированные (считай, одушевленные) алгоритмы, которые выдают непрекращающийся поток инсайтов. Я читал об исследователях данных, хитроумных как агент Мак-Гайвер, способных спасти положение, извлекая полезные данные практически из всего, что их окружает.
Решения для работы с данными, разрабатываемые в моей команде, не столь критичны, чтобы возводить ради них колоссальную инфраструктуру в масштабах всей компании. Гигантские инвестиции в сверхэффективную автоматизацию и управление производством в нашем случае просто не окупились бы. С другой стороны, наши продукты влияют на важные решения, принимаемые на предприятии, и, что особенно важно, наши решения масштабируются. Мы не можем себе позволить постоянно все делать вручную, и нам нужны эффективные механизмы, чтобы делиться результатами нашей работы с десятками тысяч людей.
На свете много «самых обычных исследователей данных», таких, как мы. Мы более организованны по сравнению с хакерами, но, в отличие от всяких супергероев, мы обходимся без «секретного штаба». Мы просто собираемся и устраиваем мозговой штурм, в ходе которого обсуждаем наилучшие способы создания надежного кода. В этой статье изложена квинтэссенция наших бесед; я попытался собрать наши знания, отсечь все лишнее и кратко представить наши наработки в одной публикации.
Как стать профессионалом
Исследователь данных должен обладать навыками программиста — но не всеми, которыми пользуется в работе программист. Я называю исследователей данных, обладающих основополагающими навыками разработки информационных продуктов, «программистами-датологами». Профессионализм – не просто навык, который можно подкрепить сертификатом или приобрести на опыте; я имею в виду профессионализм как образ действий.
Профессиональный программист-исследователь умеет сам себя исправлять при разработке решений для работы с данными. Он знает общие стратегии, позволяющие распознавать, где его продукт явно подкачал, и как исправить проблему.
Профессиональный исследователь данных должен уметь превратить гипотезу в программу, которая позволила бы проверить эту гипотезу. Такая специализация уникальна для всей IT-сферы, поскольку неповторимы проблемы, с которыми приходится иметь дело исследователям данных. Важнейший вызов связан с тем, что наука о данных по природе своей экспериментальна. Ее задачи зачастую сложны, а сами данные беспорядочны. Стратегии решения многих подобных проблем пока не проработаны, путь к решению заранее не известен, а возможные решения лучше всего поддаются объяснению в виде последовательности мелких этапов. Далее я опишу базовые стратегии, укладывающиеся в организованный и продуктивный метод проб и ошибок. Проблема раскладывается на небольшие этапы, опробуются варианты решений, по ходу работы вносятся исправления.
Мыслить как профессионал
Чтобы стать профессиональным программистом-исследователем данных, не достаточно знать общих принципов структурирования систем. Нужно представлять, как спроектировать решение, уметь распознавать, когда решение у вас есть, а также различать те случаи, в которых вы не полностью понимаете собственное решение. Последний пункт критически важен, чтобы вы могли корректировать собственную работу. Когда вы распознаете принципиальные пробелы в собственном подходе, то сами можете их заполнить. Чтобы подобрать такое решение проблемы, связанной с данными, которое можно корректировать по ходу работы, я предпочитаю придерживаться базовой парадигмы «смотреть, видеть, представлять, показывать».
Этап 1: Смотреть. Для начала сориентируйтесь на местности. Сделайте предварительное исследование, ознакомьтесь со всеми компонентами, которые могут быть связаны со стоящей перед вами задачей. Рассмотрите проблему в самом широком контексте. Постарайтесь разобраться с максимальным количеством аспектов поставленной задачи, приведите в порядок разрозненные фрагменты информации.
Этап 2: Видеть. Возьмите вышеупомянутые разрозненные фрагменты и обобщите их в виде абстракций, соответствующих элементам паттерна классной доски. На данном этапе вы преобразуете элементы проблемы в осмысленные технические концепции. Видение проблемы — важнейший подготовительный шаг на пути к созданию жизнеспособного проекта.
Этап 3: Вообразить. Опираясь на технические концепции, которые вы уже видите на данном этапе, вообразите реализацию, которая позволит перейти из исходного состояния к целевому. Если вообразить реализацию не удается, то, вероятно, вы что-то упустили при рассмотрении проблемы.
Этап 4: Показать. Объясните полученное решение сначала себе самому, затем коллеге, потом начальнику и, наконец, потенциальному пользователю. Для них требуется минимальная формализация — не более, чем нужно для донесения вашей идеи. Допустим, это можно сделать при беседе за кофе, по почте, во время недолгой прогулки. Это самая важная регулярная практика, помогающая профессиональному исследователю данных научиться корректировать собственную работу. Если в вашей стратегии есть изъяны, то они, вероятно, проявятся, как только вы попробуете ее объяснить. Именно на данном этапе можно устранить пробелы и убедиться, что вы можете досконально объяснить как проблему, так и ее решение.
Проектировать как профессионал
Работы по созданию и выпуску продукта для работы с данными разнообразные и сложные, однако, большинство из того, чем вам придется заниматься, соответствует определенному звену в «логистической цепочке больших данных», описанной Алистером Кроллом.
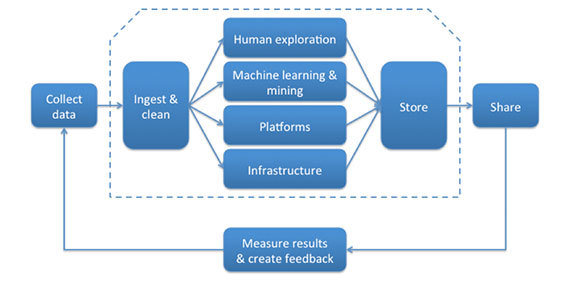
Поскольку продукты для работы с данными эксплуатируются в соответствии с определенной парадигмой (в реальном времени, в пакетном режиме или в соответствии с какой-либо гибридной моделью), то вы, вероятно, будете участвовать как в поддержке вышеупомянутой логистической цепочки, так и в реализации парадигмы этого продукта: выполнять прием и удаление пакетно-обновляемых данных, строить алгоритм для анализа данных в реальном времени, организовывать совместное использование данных и т.д. К счастью, архитектурный паттерн «классной доски» подобен базовому чертежу, помогающему качественно реализовать любой из этих сценариев на уровне программирования.
Паттерн классной доски
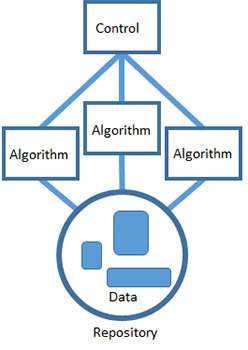
Согласно паттерну классной доски проблемы решаются таким образом: задача делится на множество мелких самодостаточных подзадач, а затем для каждой из них подбирается свое решение. Каждая подзадача приводит вашу гипотезу в более удобоваримый вид, а для некоторых таких гипотез уже известны готовые решения. Каждая задача постепенно улучшает решение и, вероятно, ведет к жизнеспособному итогу.
Наука о данных располагает множеством инструментов, у каждого из которых есть свои уникальные достоинства. Продуктивность — важная штука, и я предпочитаю, чтобы ребята из моей команды сами подбирали себе именно те инструменты, с которыми они лучше всего умеют обращаться. При применении паттерна классной доски вполне допустимо выстраивать продукты для работы с данными на основе сразу нескольких разных технологий. Взаимодействие между алгоритмами организуется через разделяемый репозиторий. Каждый алгоритм может получить доступ к данным, обработать их в качестве ввода и записать результаты обратно в репозиторий, где они вновь могут послужить вводом для другого алгоритма.
Наконец, работа всех алгоритмов координируется при помощи единого контрольного компонента, представляющего эвристику, выбранную вами для решения задачи. Контроль — это реализация стратегии, которую вы разработали. Это наивысший уровень абстрагирования и понимания проблемы, причем он воплощается при помощи технологии, которая может взаимодействовать со всеми другими алгоритмами и задавать порядок их выполнения. Контроль можно автоматизировать, задействовав для этого, к примеру, задачу cron или скрипт. Можно выполнять его вручную – пусть этим занимается человек, который будет выполнять различные шаги в нужном порядке. Но самое важное – это общая стратегия решения проблемы. Именно на уровне контроля можно окинуть взглядом все это решение от начала и до конца.
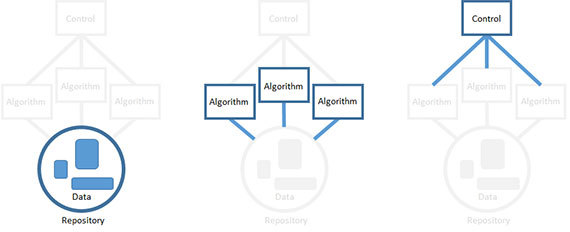
Такой базовый подход оправдал себя в создании софтверных систем, предназначенных для решения нечетких, гипотетических проблем на основании неполных данных. Самое важное, что таким образом мы можем продвигаться к решению нечеткой задачи, работая с четкими, детерминированными компонентами. К сожалению, не гарантируется, что ваши усилия действительно позволят решить проблему. Чем раньше вы узнаете, что идете по тупиковому пути – тем лучше.
Профессиональная сборка
Вы не обязаны собирать элементы вашего продукта в строго определенном порядке (то есть, сначала создать репозиторий, затем алгоритмы и, наконец, контроллер). Профессионалы организуют сборку в порядке снижения технического риска. То есть, сначала реализуется тот элемент, для которого такой риск наиболее высок. Элемент может представлять технический риск по множеству причин. Наиболее рискованной может быть компонент, находящийся под наивысшей нагрузкой, либо тот, который вы хуже всего понимаете.
Можно создавать компоненты в любом порядке, сосредоточившись на единственном из них, а для остальных оставляя заглушки. Например, если вы решите начать с разработки алгоритма, сделайте формальную реализацию вводимых данных, а также определите место, куда будет временно записываться вывод алгоритма.
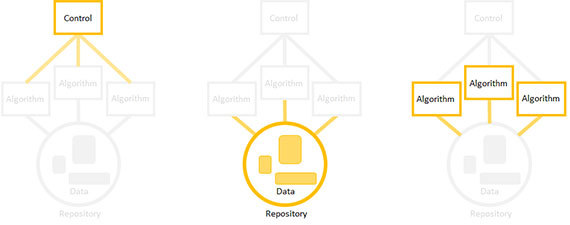
Далее реализуйте продукт в таком же порядке: сначала самые рискованные элементы. Сосредоточьтесь на одном элементе, для остальных поставьте заглушки, заменить их всегда успеете.
Ключ к успеху — организовать сборку и запуск небольшими порциями. Пишите алгоритмы мелкими частями, которые вы понимаете, добавляйте в репозиторий по одному источнику данных за раз, а каждый этап контроля должен захватывать один шаг алгоритма. Ваша цель — продукт для работы с данными, который будет работоспособен всегда, а полнофункционален — только к моменту окончательной реализации.
Инструменты для профессионала
Настоящему профессионалу не обойтись без набора качественных инструментов. Ниже приведен список самых распространенных языков и технологий, а также ссылки, по которым вы можете познакомиться с каждой из тем подробнее.
Визуализация
- D3.js: D3.js (или просто D3, Data-Driven Documents) — это библиотека JavaScript для создания динамичных, интерактивных визуализаций данных в браузере. В ней используются широко распространенные стандарты SVG, HTML5 и CSS.
Контроль версий
- GitHub это веб-хостинг репозиториев Git, обеспечивающий полный набор функций по распределенному контролю версий и управлению исходным кодом (SCM). При этом GitHub не только работает с Git, но и добавляет собственные возможности. GitHub предоставляет как браузерный веб-интерфейс, так и локальный интерфейс для ПК, а также интегрируется с мобильными платформами.
Языки программирования
- R: это язык программирования и программная среда для статистических вычислений и их графического представления. Язык R широко применяется специалистами по статистике и дата-майнингу как для разработки статистического ПО, так и для анализа данных.
- Python: это широко распространенный универсальный высокоуровневый язык программирования. В философии Python особое внимание уделяется удобочитаемости кода, а синтаксис позволяет программистам выражать концепции более лаконично, чем на языках вроде C++ или Java.
- Scala: это функциональный объектно-ориентированный язык общего назначения. В Scala полностью поддерживаются все возможности функционального программирования, имеется очень сильная статическая система типов. Поэтому программы, создаваемые на Scala, получаются очень краткими и более компактными, чем программы на других более распространенных универсальных языках.
- Java: это исключительно распространенный универсальный объектно-ориентированный язык программирования, обеспечивающий конкурентную обработку, имеющий систему классов, специально спроектированный с таким прицелом, чтобы программы на нем содержали как можно меньше зависимостей. Он предназначен для того, чтобы приложение можно было «написать однажды и запустить везде» (принцип WORA).
Экосистема Hadoop
- Hadoop: это свободный софтверный фреймворк, написанный на языке Java и предназначенный для распределенного хранения и распределенной обработки очень больших множеств данных в компьютерных кластерах, выстроенных из сравнительно дешевого аппаратного обеспечения.
- Pig: это высокоуровневая платформа для создания программ MapReduce, используемых с Hadoop.
- Hive: это инфраструктура хранилищ данных, выстраиваемая на основе Hadoop и обеспечивающая суммирование, запрашивание и анализ данных.
- Spark: примитивы Spark, хранимые в памяти, увеличивают производительность, для некоторых приложений – в 100 раз.
Only registered users can participate in poll. Log in, please.
Толковая книга на тему Big Data, которую я бы точно купил
31.65% Hadoop44
12.23% Hive17
28.06% MapReduce39
10.07% Pig14
48.2% Spark67
28.78% Ничего из вышеперечисленного40
139 users voted. 60 users abstained.
