Добрый вечер, коллеги.
Перевод статьи, который мы вам предложим сегодня, призван помочь ответить на вопрос: а назрела ли необходимость целой книги по оптимизации кода на Java? Надеемся, что материал не только покажется вам интересным, но и пригодится на практике. Пожалуйста, не забудьте проголосовать.
В этой статье я изложу несколько советов по оптимизации кода на Java. Я специально рассмотрю конкретные операции в реальных программах на Java. Эти советы, в сущности, применимы в конкретных сценариях, требующих высокой производительности, поэтому совершенно нет нужды писать весь код именно в такой манере, поскольку обычно выигрыш в скорости будет мизерным. Однако, на самых жарких участках разница может получиться существенной.
Прежде, чем приступать к какой-либо оптимизации, разработчик должен убедиться, что верно оценивает производительность. Может быть, тот фрагмент кода, который кажется нам тормознутым, на самом деле просто маскирует истинный источник пробуксовки, поэтому сколько бы мы не оптимизировали «явный» источник промедления, эффект будет почти нулевым. Кроме того, нужно выбрать контрольную точку, по которой можно было бы сравнивать, дает ли ваша оптимизация какой-либо эффект, и если да – то какой.
Для достижения обеих этих целей удобнее всего пользоваться профилировщиком. В нем предусмотрены инструменты, позволяющие определить, какая именно часть вашего кода выполняется медленно, сколько времени уходит на выполнение этого кода. Могу порекомендовать два профилировщика — VisualVM (бесплатный) и JProfiler (платный – но абсолютно стоит своих денег).
Вооружившись такой информацией, можете не сомневаться, что оптимизируете именно тот код, который требуется – и что эффект от вносимых вами изменений можно будет измерить
Вернемся на шаг назад и обдумаем, как подступиться к проблеме.
Прежде чем попытаться перейти к точечной оптимизации конкретного пути исполнения кода, нужно подумать, по какому пути код выполняется сейчас. Иногда избранный подход бывает фундаментально ущербным – например, вы ценой неимоверных усилий и всех мыслимых оптимизаций сможете ускорить этот код на 25%, однако, если изменить подход (подобрать иной алгоритм), выполнение кода может ускориться на порядок и даже более. Зачастую такое случается, когда резко меняются масштабы данных, которые требуется обрабатывать. Бывает несложно написать решение, которое сработает в данном конкретном случае, но для работы с реальными данными оно может оказаться непригодным.
Иногда выход бывает тривиальным – просто изменить структуру, в которой вы храните ваши данные. Вот вам воображаемый пример: если программа обычно обращается к вашим данным в произвольном порядке, а вы храните их в
Всегда целесообразно оглянуться назад и обдумать: эффективен ли сам по себе тот код, который вы пытаетесь оптимизировать, либо он притормаживает лишь потому, что коряво написан, либо потому, что для него подобран не лучший путь исполнения.
Потоки – замечательное нововведение в языке Java, при позволяющее без труда переделать барахлящие фрагменты кода, отказавшись от циклов for в пользу более универсальных многоразовых блоков кода, гарантирующих уверенное выполнение. Однако, за такие удобства приходится платить: при использовании потоков снижается производительность. К счастью, эта цена, по-видимому, не слишком высока. В случае с самыми ходовыми операциями можно получить как ускорение на несколько процентов, так и замедление на 10-30%, однако, этот момент следует иметь в виду.
В 99% случаев снижение производительности при использовании потоков более чем компенсируется благодаря тому, что код становится гораздо яснее. Но в том 1% случаев, когда поток у вас, возможно, будет использоваться в очень активном цикле, стоит задуматься о некоем компромиссе в пользу производительности. Это особенно касается приложений с высокой пропускной способностью, заставляет задуматься о том, что работа с потоковыми API сопряжена с активным выделением памяти (в этой теме на StackOverflow читаем, что каждый новый фильтр отъедает еще 88 байт памяти), поэтому давление на память может возрасти. В таком случае приходится чаще запускать сборщик мусора, что очень негативно сказывается на производительности.
С параллельными потоками – другая история. Несмотря на то, как легко с ними работать, их следует использовать лишь в редких случаях и только после того, как по результатам профилировки параллельных и последовательных операций вы убедились, что параллельная выполняется быстрее. При работе с небольшими множествами данных (размер множества данных определяется в зависимости от того, насколько затратны потоковые операции при работе над ним) издержки на распределение задач, планировку их между другими потоками, а затем сшивание результатов после того, как обработка потока закончится, несравнимо перекроет выигрыш в скорости, достигнутый благодаря распараллеливанию вычислений.
Также нужно обращать внимание, в какой именно среде выполняется ваш код. Если речь идет о сильно распараллеленном окружении (например, о сайте), то вряд ли вы ускорите его работу, добавив туда еще один поток. На самом деле, при высоких нагрузках такая ситуация может быть еще порочнее, чем непараллельное исполнение. Дело в том, что, если рабочая нагрузка по природе своей параллельна, то программа наверняка и так максимально эффективно использует оставшиеся ядра процессора – то есть, вы тратите ресурсы на разделение задач, а вычислительной мощности у вас при этом не прибавляется.
Я сделал ряд контрольных замеров.
Итак: потоки очень помогают при поддержке кода и повышают его удобочитаемость, и при этом в большинстве случаев пренебрежимо влияют на производительность. Однако, необходимо учитывать возможные издержки в тех редких случаях, когда действительно требуется выжать из нагруженного цикла всю производительность до капли.
Нельзя недооценивать издержек, возникающих, например, при парсинге строки с датой в объект даты и при форматировании объекта даты в строку с датой. Представьте себе ситуацию, когда у вас есть список из миллиона объектов (это либо обычные строки, либо некие объекты, представляющие элемент в виде поля данных, подкрепленного строкой) – и весь список нужно откорректировать по заданной дате. В случае, если эта дата представлена в виде строки, потребуется сначала разобрать эту строку, чтобы преобразовать ее в объект Date, обновить объект
Мои тесты показывают, что программа выполняется до 500 раз быстрее, если просто оперировать объектом даты, нежели если парсить его, преобразовывать в строку и обратно. Даже если просто исключить этап парсинга, все равно достигается стократное ускорение. Этот пример может показаться надуманным, но, уверен, вам известны случаи, когда значения даты хранились в базе данных в виде строк, а также возвращались в виде строк в откликах API
Итак, всегда учитывайте издержки, связанные с парсингом и форматированием объектов даты, и, если нет необходимости держать их в виде строк, гораздо разумнее представлять дату в виде временной метки Unix.
Манипуляция над строками – это, пожалуй, одна из самых распространенных операций в любой программе. Однако, если выполнять ее неправильно, она может получиться затратной. Именно поэтому я уделяю такое внимание работе со строками в этой статье, посвященной оптимизации Java. Ниже мы рассмотрим один из самых частых подводных камней. Однако, хочу дополнительно подчеркнуть, что такие проблемы проявляются лишь при выполнении самых скоростных фрагментов кода, либо когда приходится иметь дело с существенным количеством строк. В 99% случаев ничего из показанного ниже не случится. Однако, если такая проблема возникнет, она может убийственно сказаться на производительности.
Использование
Простейший вызов
Однако, есть один случай, когда
Второй случай (что на первый взгляд может показаться нелогичным) в продакшене, бывает, работает быстрее. Поскольку маловероятно, что на ваших продакшен-серверах будет включено журналирование отладочной информации, в первом случае программа выделяет новую строку, которая затем так и не используется (поскольку лог так и не выводится). Во втором случае требуется загрузить постоянную строку, после чего этап форматирования пропускается.
Если вы не пользуетесь построителем строк внутри цикла, то производительность кода сильно падает. В упрощенной реализации мы наращивали бы строку внутри цикла при помощи оператора
Также отмечу, что (почти) всегда использую
Мне попадались в Интернете рекомендации использовать построитель строк вне цикла – и это даже кажется целесообразным. Однако, мои опыты показали, что на самом деле код при этом выполняется втрое медленнее, чем при
Если у кого-нибудь есть версии, почему так происходит – поделитесь пожалуйста в комментариях.
Итак, создание строк связано с явственными издержками, поэтому в циклах следует по возможности избегать такой практики. Добиться этого легко – просто используйте
Надеюсь, вам пригодятся изложенные здесь советы по оптимизации кода на Java. Еще раз подчеркну, что в большинстве контекстов описанные здесь приемы вам не пригодятся. Нет разницы, сколько раз в секунду вы успеете отформатировать строку – миллион раз или 80 миллионов раз, если вам требуется проделать всего несколько таких операций.
Но в тех критических случаях, когда речь действительно может идти о миллионах таких операций, восьмидесятикратное ускорение кода может сэкономить вам массу времени.
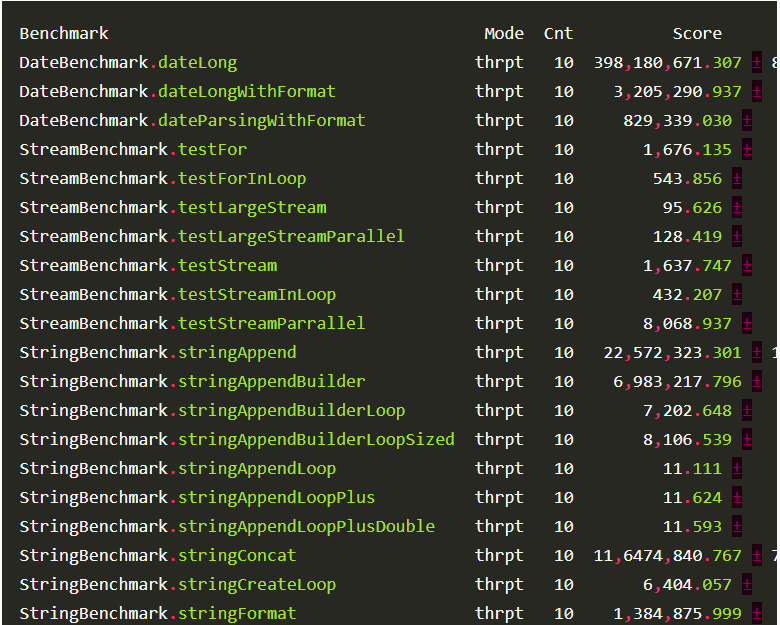
Написав эту статью, я собрал zip-архив со всеми упомянутыми здесь данными, и ниже привожу вывод после проверки всех контрольных точек. Все результаты получены на ПК с i5-6500. Код запускался с JDK 1.8.0_144, VM 25.144-b01 на Windows 10
Весь код можно скачать здесь на GitHub.
Перевод статьи, который мы вам предложим сегодня, призван помочь ответить на вопрос: а назрела ли необходимость целой книги по оптимизации кода на Java? Надеемся, что материал не только покажется вам интересным, но и пригодится на практике. Пожалуйста, не забудьте проголосовать.
В этой статье я изложу несколько советов по оптимизации кода на Java. Я специально рассмотрю конкретные операции в реальных программах на Java. Эти советы, в сущности, применимы в конкретных сценариях, требующих высокой производительности, поэтому совершенно нет нужды писать весь код именно в такой манере, поскольку обычно выигрыш в скорости будет мизерным. Однако, на самых жарких участках разница может получиться существенной.
Пользуйтесь профилировщиком!
Прежде, чем приступать к какой-либо оптимизации, разработчик должен убедиться, что верно оценивает производительность. Может быть, тот фрагмент кода, который кажется нам тормознутым, на самом деле просто маскирует истинный источник пробуксовки, поэтому сколько бы мы не оптимизировали «явный» источник промедления, эффект будет почти нулевым. Кроме того, нужно выбрать контрольную точку, по которой можно было бы сравнивать, дает ли ваша оптимизация какой-либо эффект, и если да – то какой.
Для достижения обеих этих целей удобнее всего пользоваться профилировщиком. В нем предусмотрены инструменты, позволяющие определить, какая именно часть вашего кода выполняется медленно, сколько времени уходит на выполнение этого кода. Могу порекомендовать два профилировщика — VisualVM (бесплатный) и JProfiler (платный – но абсолютно стоит своих денег).
Вооружившись такой информацией, можете не сомневаться, что оптимизируете именно тот код, который требуется – и что эффект от вносимых вами изменений можно будет измерить
Вернемся на шаг назад и обдумаем, как подступиться к проблеме.
Прежде чем попытаться перейти к точечной оптимизации конкретного пути исполнения кода, нужно подумать, по какому пути код выполняется сейчас. Иногда избранный подход бывает фундаментально ущербным – например, вы ценой неимоверных усилий и всех мыслимых оптимизаций сможете ускорить этот код на 25%, однако, если изменить подход (подобрать иной алгоритм), выполнение кода может ускориться на порядок и даже более. Зачастую такое случается, когда резко меняются масштабы данных, которые требуется обрабатывать. Бывает несложно написать решение, которое сработает в данном конкретном случае, но для работы с реальными данными оно может оказаться непригодным.
Иногда выход бывает тривиальным – просто изменить структуру, в которой вы храните ваши данные. Вот вам воображаемый пример: если программа обычно обращается к вашим данным в произвольном порядке, а вы храните их в
LinkedList, то бывает достаточно переключиться на ArrayList – и код станет выполняться гораздо быстрее. При работе с большими множествами данных и решении задач, где критична производительность, чрезвычайно важно правильно подобрать структуру данных, которая отвечает форме ваших данных и тем операциям, которые над ними осуществляются.Всегда целесообразно оглянуться назад и обдумать: эффективен ли сам по себе тот код, который вы пытаетесь оптимизировать, либо он притормаживает лишь потому, что коряво написан, либо потому, что для него подобран не лучший путь исполнения.
Сравнение потоковых API и старого доброго цикла for
Потоки – замечательное нововведение в языке Java, при позволяющее без труда переделать барахлящие фрагменты кода, отказавшись от циклов for в пользу более универсальных многоразовых блоков кода, гарантирующих уверенное выполнение. Однако, за такие удобства приходится платить: при использовании потоков снижается производительность. К счастью, эта цена, по-видимому, не слишком высока. В случае с самыми ходовыми операциями можно получить как ускорение на несколько процентов, так и замедление на 10-30%, однако, этот момент следует иметь в виду.
В 99% случаев снижение производительности при использовании потоков более чем компенсируется благодаря тому, что код становится гораздо яснее. Но в том 1% случаев, когда поток у вас, возможно, будет использоваться в очень активном цикле, стоит задуматься о некоем компромиссе в пользу производительности. Это особенно касается приложений с высокой пропускной способностью, заставляет задуматься о том, что работа с потоковыми API сопряжена с активным выделением памяти (в этой теме на StackOverflow читаем, что каждый новый фильтр отъедает еще 88 байт памяти), поэтому давление на память может возрасти. В таком случае приходится чаще запускать сборщик мусора, что очень негативно сказывается на производительности.
С параллельными потоками – другая история. Несмотря на то, как легко с ними работать, их следует использовать лишь в редких случаях и только после того, как по результатам профилировки параллельных и последовательных операций вы убедились, что параллельная выполняется быстрее. При работе с небольшими множествами данных (размер множества данных определяется в зависимости от того, насколько затратны потоковые операции при работе над ним) издержки на распределение задач, планировку их между другими потоками, а затем сшивание результатов после того, как обработка потока закончится, несравнимо перекроет выигрыш в скорости, достигнутый благодаря распараллеливанию вычислений.
Также нужно обращать внимание, в какой именно среде выполняется ваш код. Если речь идет о сильно распараллеленном окружении (например, о сайте), то вряд ли вы ускорите его работу, добавив туда еще один поток. На самом деле, при высоких нагрузках такая ситуация может быть еще порочнее, чем непараллельное исполнение. Дело в том, что, если рабочая нагрузка по природе своей параллельна, то программа наверняка и так максимально эффективно использует оставшиеся ядра процессора – то есть, вы тратите ресурсы на разделение задач, а вычислительной мощности у вас при этом не прибавляется.
Я сделал ряд контрольных замеров.
testList – это массив из 100 000 элементов, состоящий из чисел от 1 до 100 000, преобразованных в строки и затем перемешанных. // ~1 500 оп/с
public void testStream(ArrayState state) {
List<String> collect = state.testList
.stream()
.filter(s -> s.length() > 5)
.map(s -> "Value: " + s)
.sorted(String::compareTo)
.collect(Collectors.toList());
}
// ~1 500 оп/с
public void testFor(ArrayState state) {
ArrayList<String> results = new ArrayList<>();
for (int i = 0;i < state.testList.size();i++) {
String s = state.testList.get(i);
if (s.length() > 5) {
results.add("Value: " + s);
}
}
results.sort(String::compareTo);
}
// ~8 000 оп/с
// Обратите внимание: при размере массива от 10 000 элементов и переменной нагрузке на процессор этот код выполнялся втрое медленнее testStream
public void testStreamParrallel(ArrayState state) {
List<String> collect = state.testList
.stream()
.parallel()
.filter(s -> s.length() > 5)
.map(s -> "Value: " + s)
.sorted(String::compareTo)
.collect(Collectors.toList());
}Итак: потоки очень помогают при поддержке кода и повышают его удобочитаемость, и при этом в большинстве случаев пренебрежимо влияют на производительность. Однако, необходимо учитывать возможные издержки в тех редких случаях, когда действительно требуется выжать из нагруженного цикла всю производительность до капли.
Передача даты и операции с ней
Нельзя недооценивать издержек, возникающих, например, при парсинге строки с датой в объект даты и при форматировании объекта даты в строку с датой. Представьте себе ситуацию, когда у вас есть список из миллиона объектов (это либо обычные строки, либо некие объекты, представляющие элемент в виде поля данных, подкрепленного строкой) – и весь список нужно откорректировать по заданной дате. В случае, если эта дата представлена в виде строки, потребуется сначала разобрать эту строку, чтобы преобразовать ее в объект Date, обновить объект
Date, а затем вновь отформатировать его в виде строки. Если дата уже представлена в виде временной метки Unix (или в виде объекта Date, фактически, представляющего собой просто обертку вокруг временной метки Unix) – то вам останется сделать простую арифметическую операцию, сложение или вычитание.Мои тесты показывают, что программа выполняется до 500 раз быстрее, если просто оперировать объектом даты, нежели если парсить его, преобразовывать в строку и обратно. Даже если просто исключить этап парсинга, все равно достигается стократное ускорение. Этот пример может показаться надуманным, но, уверен, вам известны случаи, когда значения даты хранились в базе данных в виде строк, а также возвращались в виде строк в откликах API
// ~800 000 оп/c
public void dateParsingWithFormat(DateState state) throws ParseException {
Date date = state.formatter.parse("20-09-2017 00:00:00");
date = new Date(date.getTime() + 24 * state.oneHour);
state.formatter.format(date);
}
// ~3 200 000 оп/с
public void dateLongWithFormat(DateState state) {
long newTime = state.time + 24 * state.oneHour;
state.formatter.format(new Date(newTime));
}
// ~400 000 000 оп/с
public long dateLong(DateState state) {
long newTime = state.time + 24 * state.oneHour;
return newTime;
}Итак, всегда учитывайте издержки, связанные с парсингом и форматированием объектов даты, и, если нет необходимости держать их в виде строк, гораздо разумнее представлять дату в виде временной метки Unix.
Операции над строками
Манипуляция над строками – это, пожалуй, одна из самых распространенных операций в любой программе. Однако, если выполнять ее неправильно, она может получиться затратной. Именно поэтому я уделяю такое внимание работе со строками в этой статье, посвященной оптимизации Java. Ниже мы рассмотрим один из самых частых подводных камней. Однако, хочу дополнительно подчеркнуть, что такие проблемы проявляются лишь при выполнении самых скоростных фрагментов кода, либо когда приходится иметь дело с существенным количеством строк. В 99% случаев ничего из показанного ниже не случится. Однако, если такая проблема возникнет, она может убийственно сказаться на производительности.
Использование String.format, когда могла бы сработать простая конкатенация
Простейший вызов
String.format происходит примерно в 100 раз медленнее, чем при конкатенации значений в строку вручную. Как правило, это приемлемо, поскольку на моей машине мы здесь все равно имеем дело с миллионами операций в секунду. Однако, в случае загруженного цикла, оперирующего миллионами элементов, спад производительности может быть ощутимым. Однако, есть один случай, когда
_следует _использовать именно строковое форматирование, а не конкатенацию даже в среде с высокими требованиями к производительности – я говорю о журналировании отладочной информации. Рассмотрим два вызова, происходящих в таком контексте:logger.debug("the value is: " + x);
logger.debug("the value is: %d", x);Второй случай (что на первый взгляд может показаться нелогичным) в продакшене, бывает, работает быстрее. Поскольку маловероятно, что на ваших продакшен-серверах будет включено журналирование отладочной информации, в первом случае программа выделяет новую строку, которая затем так и не используется (поскольку лог так и не выводится). Во втором случае требуется загрузить постоянную строку, после чего этап форматирования пропускается.
// ~1 300 000 оп/с
public String stringFormat() {
String foo = "foo";
String formattedString = String.format("%s = %d", foo, 2);
return formattedString;
}
// ~115 000 000 оп/с
public String stringConcat() {
String foo = "foo";
String concattedString = foo + " = " + 2;
return concattedString;
}Неиспользование построителя строк внутри цикла
Если вы не пользуетесь построителем строк внутри цикла, то производительность кода сильно падает. В упрощенной реализации мы наращивали бы строку внутри цикла при помощи оператора
+=, прикрепляя таким образом новую часть строки к уже имеющейся. Проблема с данным подходом заключается в том, что при каждой итерации цикла будет выделяться новая строка, а старую строку на каждой итерации придется копировать в новую. Даже сама по себе эта операция затратна, не говоря уже о лишней нагрузке, связанной с дополнительной сборкой мусора, необходимой при создании и отбрасывании такого количества строк. Воспользовавшись StringBuilder, мы ограничим количество операций выделения памяти, что позволит нам сильно повысить производительность. В моих тестах таким образом удавалось ускорить программу более чем в 500 раз. Если при создании построителя строк вы можете, как минимум, достаточно уверенно предположить, какого размера будет результирующая строка, то можно ускорить код еще на 10%, заранее задав корректный размер (в таком случае не придется пересчитывать размер внутреннего буфера и избавиться от операций выделения и копирования). Также отмечу, что (почти) всегда использую
StringBuilder, а не StringBuffer. StringBuffer предназначен для работы в многопоточных средах и именно поэтому оснащен внутренней синхронизацией. Издержки за такую синхронизацию приходится нести даже в однопоточной среде. Если вам требуется наращивать строку данными, поступающими из многих потоков (допустим, в реализации с журналированием) – вот вам одна из немногих ситуаций, когда следует пользоваться именно StringBuffer, а не StringBuilder.// ~11 операций в секунду
public String stringAppendLoop() {
String s = "";
for (int i = 0;i < 10_000;i++) {
if (s.length() > 0) s += ", ";
s += "bar";
}
return s;
}
// ~7 000 операций в секунду
public String stringAppendBuilderLoop() {
StringBuilder sb = new StringBuilder();
for (int i = 0;i < 10_000;i++) {
if (sb.length() > 0) sb.append(", ");
sb.append("bar");
}
return sb.toString();
}
Использование построителя строк вне цикла
Мне попадались в Интернете рекомендации использовать построитель строк вне цикла – и это даже кажется целесообразным. Однако, мои опыты показали, что на самом деле код при этом выполняется втрое медленнее, чем при
+= — даже если StringBuilder находится вне цикла. Хотя += в данном контексте и превращается в вызовы StringBuilder, выполняемые javac, код получается гораздо быстрее, чем при непосредственном использовании StringBuilder, что меня удивило.Если у кого-нибудь есть версии, почему так происходит – поделитесь пожалуйста в комментариях.
// ~20 000 000 операций в секунду
public String stringAppend() {
String s = "foo";
s += ", bar";
s += ", baz";
s += ", qux";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", bar";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
s += ", baz";
s += ", qux";
return s;
}
// ~7 000 000 операций в секунду
public String stringAppendBuilder() {
StringBuilder sb = new StringBuilder();
sb.append("foo");
sb.append(", bar");
sb.append(", bar");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
sb.append(", baz");
sb.append(", qux");
return sb.toString();
}Итак, создание строк связано с явственными издержками, поэтому в циклах следует по возможности избегать такой практики. Добиться этого легко – просто используйте
StringBuilder внутри цикла.Надеюсь, вам пригодятся изложенные здесь советы по оптимизации кода на Java. Еще раз подчеркну, что в большинстве контекстов описанные здесь приемы вам не пригодятся. Нет разницы, сколько раз в секунду вы успеете отформатировать строку – миллион раз или 80 миллионов раз, если вам требуется проделать всего несколько таких операций.
Но в тех критических случаях, когда речь действительно может идти о миллионах таких операций, восьмидесятикратное ускорение кода может сэкономить вам массу времени.
Написав эту статью, я собрал zip-архив со всеми упомянутыми здесь данными, и ниже привожу вывод после проверки всех контрольных точек. Все результаты получены на ПК с i5-6500. Код запускался с JDK 1.8.0_144, VM 25.144-b01 на Windows 10

Весь код можно скачать здесь на GitHub.
Only registered users can participate in poll. Log in, please.
Мое мнение о книге на тему Java Performance Optimization
84.09% Думаю, давно назрел перевод такой книги111
15.91% Вряд ли мне пригодится21
132 users voted. 31 users abstained.
